
鸿蒙首个双AI引擎饮食App:豆包+DeepSeek如何协同工作
本文是「食刻 (ShiKe)」—— HarmonyOS 6.0.2 原生 AI 饮食健康管家的技术系列第 1 篇,深入解析 AI 双引擎架构*的设计与实现。

本文是「食刻 (ShiKe)」—— HarmonyOS 6.0.2 原生 AI 饮食健康管家的技术系列第 1 篇,深入解析 AI 双引擎架构 的设计与实现。
一、为什么需要双 AI 引擎?
传统饮食 App 的痛点
用过 Keep、薄荷健康、MyFitnessPal 的同学都知道,记录一顿饭有多痛苦:
打开 App → 搜索食物 → 在几十个结果里找 → 选一个最接近的 → 再搜下一个食物 → 重复 3-5 次
一顿饭记录时间:2-5 分钟 😩
而且记录完之后呢?你只能看到一堆数字:
- 今日摄入:1450 kcal
- 蛋白质:45g
然后呢?碳水太高怎么办?蛋白质不够怎么补?App 告诉不了你。
我们的解法:双引擎分工
食刻引入了 两个 AI 引擎,各有专长:
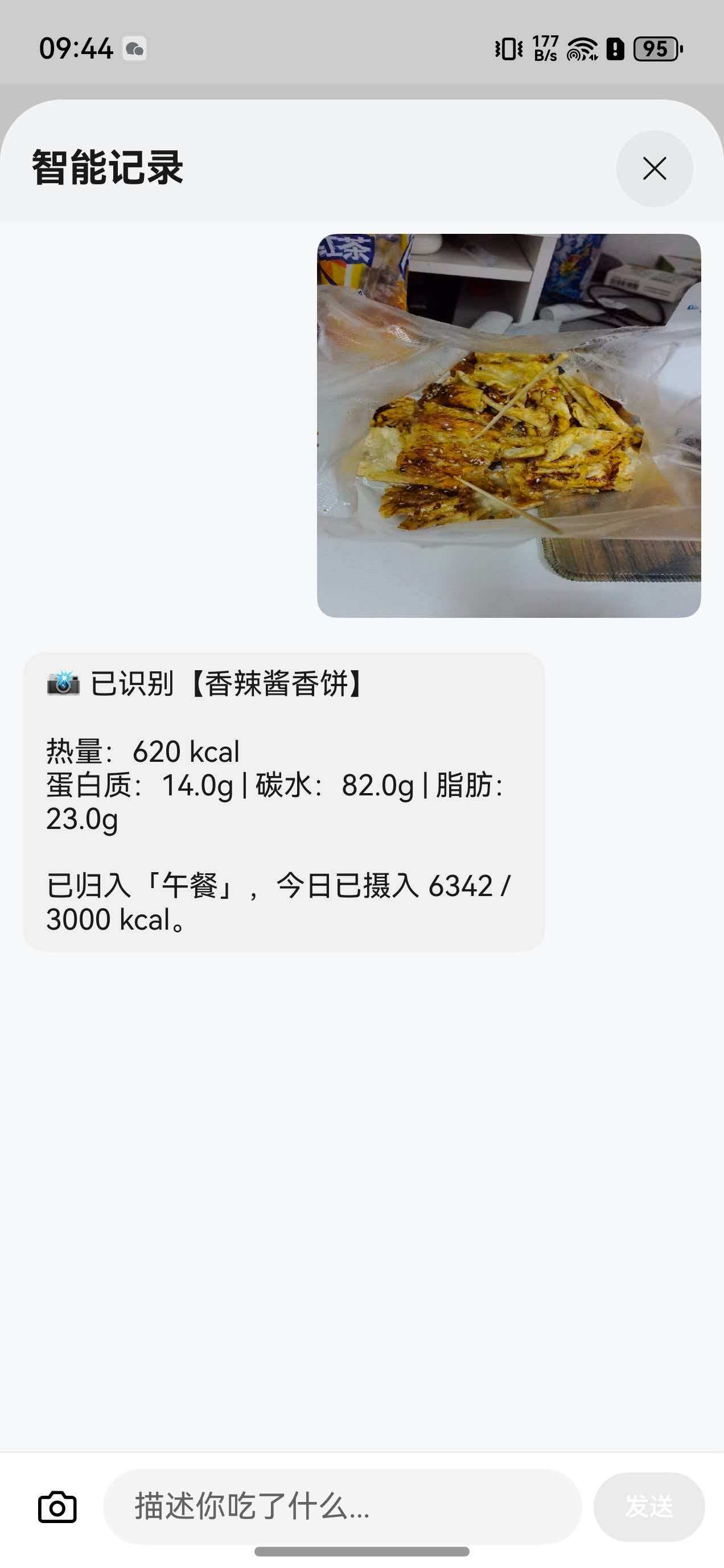
🧠 豆包 doubao-seed-2-0-pro
擅长:多模态识别
- 文字描述 → 识别食物
- 拍照图片 → 识别食物
- 返回结构化营养数据
🔮 DeepSeek v4-pro
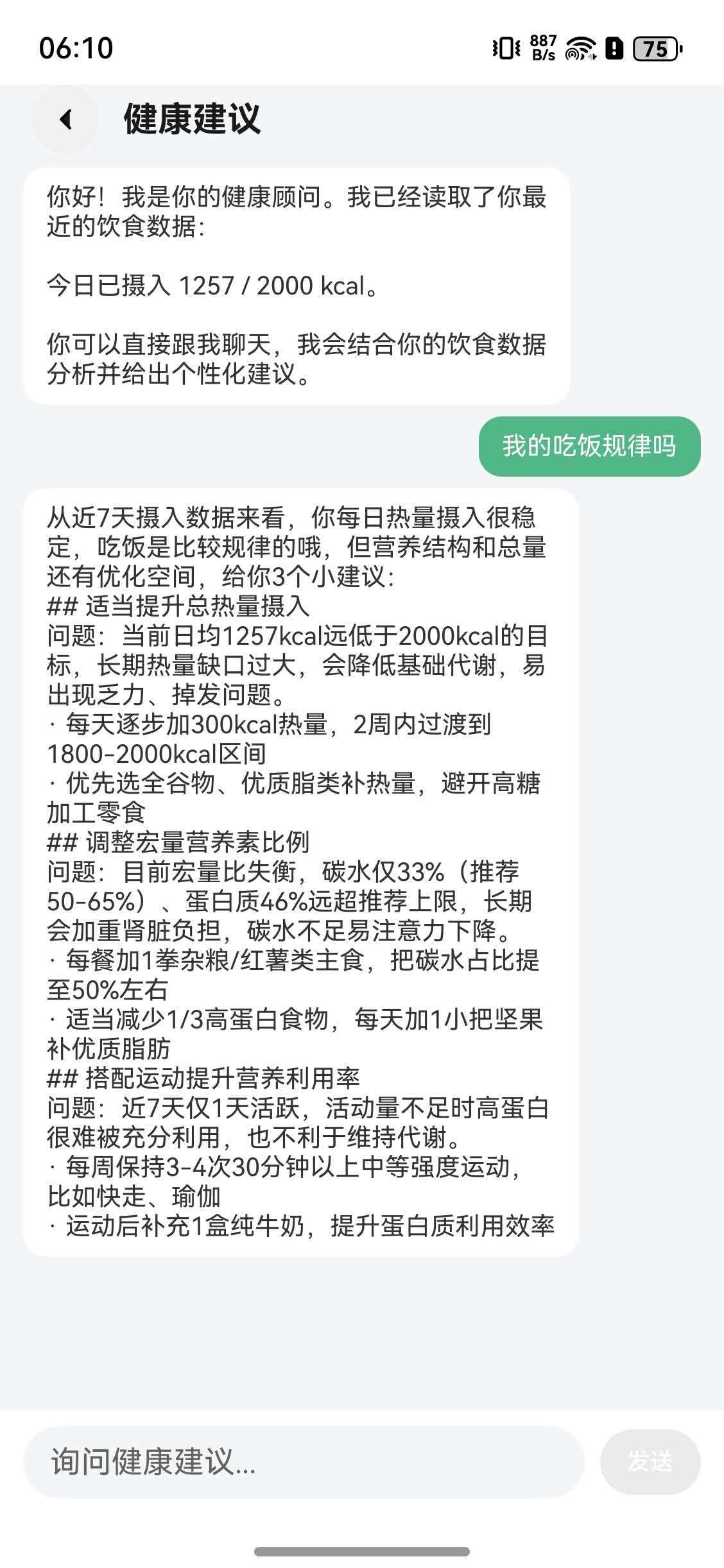
擅长:推理与对话
- 生成个性化饮食计划
- 分析健康数据给建议
- 体重趋势预测
- 智能报告生成
二、架构设计:统一抽象层
核心思路
两种模型通过统一的 DoubaoApiService 抽象层管理,各自独立配置 API Key、Endpoint 和 Model,互不干扰。
用户输入(文字/图片)
│
├── 食物识别场景 ──→ 豆包 doubao-seed-2-0-pro
│ ├── identifyFood(text)
│ └── identifyFoodFromImage(b64)
│
└── 智能对话场景 ──→ DeepSeek deepseek-v4-pro
├── generateDietPlan(profile)
├── generateHealthAdvice(data)
├── WeightTrendPage
└── SmartReportPage
关键代码:双请求方法
// DoubaoApiService.ets 核心结构
class DoubaoApiService {
// 豆包:食物识别(支持文字+图片)
async identifyFood(input: string | string[]): Promise<FoodResult> {
const isImage = Array.isArray(input);
const payload = isImage
? this.buildImagePayload(input[0]) // 图片 Base64
: this.buildTextPayload(input); // 文字描述
return this.doRequest(payload); // → 豆包 API
}
// DeepSeek:智能对话(纯文本推理)
async generateDietPlan(profile: UserProfile): Promise<string> {
const messages = this.buildDietPlanMessages(profile);
return this.doDeepSeekRequest({ // → DeepSeek API
model: 'deepseek-v4-pro',
messages,
systemPrompt: DIET_PLAN_SYSTEM_PROMPT
});
}
}
为什么不共用一个 API 方法?
| 维度 | 豆包请求 | DeepSeek 请求 |
|---|---|---|
| Endpoint | ark.cn-beijing.volces.com |
api.deepseek.com |
| 鉴权 | Bearer Token (火山引擎) | Bearer Token (DeepSeek) |
| 请求格式 | 自定义 JSON 结构 | OpenAI 兼容格式 |
| 响应解析 | 提取 foodName/calories 等 |
直接返回 Markdown 文本 |
| 超时设置 | 10s(识别要快) | 30s(推理可以慢) |
结论:两套方法的参数、解析逻辑完全不同,强行合并只会让代码更难维护。
三、AI 对话数据流:历史记录如何持久化?
问题场景
用户在「饮食计划」页面和 DeepSeek 对话了 10 轮,然后切到首页看热量环,再回来时 —— 对话历史还在吗?
答案:在的。 我们用 Preferences 本地持久化了每一轮对话。
完整数据流
DietPlanPage.aboutToAppear()
↓
loadHistory()
↓
Preferences.getSync('chat_diet_plan') // 从本地磁盘读取
↓
恢复历史消息(含时间戳) // 渲染到 UI
── 用户发送新消息 ──
DietPlanPage.send()
↓
DoubaoApiService.generateDietPlan(profile)
↓
doDeepSeekRequest({
model: 'deepseek-v4-pro',
messages: [...history, userMessage], // 携带完整上下文
})
↓
返回 AI 生成计划
↓
saveHistory()
↓
Preferences.putSync('chat_diet_plan', [...history, aiReply]) // 写回磁盘
每个 AI 场景独立存储
| 页面 | Preferences Key | 用途 |
|---|---|---|
| DietPlanPage | chat_diet_plan |
饮食计划对话 |
| HealthAdvicePage | chat_health_advice |
健康建议对话 |
| WeightTrendPage | chat_weight_trend |
体重趋势分析 |
| SmartReportPage | chat_smart_report |
智能报告生成 |
关键设计决策:为什么不存云端?
- 饮食数据属于高度隐私信息
- 用户不希望自己的饮食习惯被上传
- 本地存储 = 零网络延迟 = 切页瞬间恢复
四、实际效果:3 秒 vs 3 分钟
记录效率对比
**实测数据**:AI 文字/拍照识别 **3 秒**完成全部食物识别和营养估算,相比传统手动查库方式,**时间降低 40 倍**。| 操作步骤 | 传统方式 (Keep/薄荷) | 食刻 AI 方式 |
|---|---|---|
| 打开记录入口 | ✅ 1s | ✅ 1s |
| 输入/选择食物 | ❌ 搜索+筛选 30-60s/个 | ✅ 输入"鸡腿饭" 2s |
| 营养计算 | ✅ 自动 | ✅ AI 自动返回 |
| 归类餐段 | ❌ 手动选 | ✅ AI 自动判断 |
| 一顿饭总耗时 | 2-5 分钟 | ≤ 10 秒 |
DeepSeek 的数据驱动建议
传统 App 的"建议"是模板化的通用文案:
“建议您多吃蔬菜,减少油腻食物摄入”
食刻的 DeepSeek 会读取你近 7 天的真实数据:
“您近 7 天碳水占比 62%(偏高),建议降至 50-55%。
可将晚餐米饭替换为糙米,或减少 1/3 份量。
当前蛋白质 22g/天(偏低),建议加餐鸡蛋或希腊酸奶。”
这就是"数据驱动"vs"模板化"的区别。
五、竞品全景对比
| 功能 | Keep | 薄荷健康 | MyFitnessPal | 食刻 |
|---|---|---|---|---|
| AI 食物识别 | ❌ | ❌ | ❌ | ✅ 双引擎 |
| AI 饮食计划 | ❌ | ❌ | ❌ | ✅ DeepSeek |
| AI 健康分析 | ❌ | ❌ | ❌ | ✅ 数据驱动 |
| 桌面 Widget | 基础 | 基础 | ❌ | ✅ 3 张卡片 |
| 3D 视觉效果 | 2D | 2D | 2D | ✅ Neumorphism |
六、总结与下篇预告
核心要点回顾
- 双引擎不是炫技,而是场景驱动的工程选择:识别要快→豆包,推理要深→DeepSeek
- 统一抽象层 (
DoubaoApiService) 让替换 AI 引擎只需改 3 处配置 - Preferences 持久化保证离开再回来不丢失上下文
- 全量本地存储,饮食数据不出设备
下一篇:《纯 ArkUI 实现 7 层拟物 3D 环形进度图:零依赖的视觉革命》
我们将揭秘食刻首页那个令人印象深刻的 Neumorphism 环形进度图是如何用纯 ArkUI 组件手工打造出来的 —— 没有 Canvas、没有 3D 引擎、没有第三方依赖,只有 7 层组件的创意叠加。
📌 项目仓库:https://atomgit.com/VON-/cxs-demo1*

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 1
1 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)