
CANN NEXT系列干货:升级开发利器,释放Ascend 950算力
随着大模型训练与推理、推荐系统及多模态应用等AI场景的爆发式发展,新一代AI芯片的算力突破已成为行业刚需。Ascend 950作为面向AI计算的新一代芯片,通过第三代DaVinci Core架构、灵衢互联技术以及MXFP4/MXFP8等低精度计算等特性支持,为AI应用提供了强大的算力底座。然而,硬件算力的充分释放离不开高效的软件栈支持。CANN作为昇腾AI处理器的异构计算架构,通过持续演进,已经形
随着大模型训练与推理、推荐系统及多模态应用等AI场景的爆发式发展,新一代AI芯片的算力突破已成为行业刚需。Ascend 950作为面向AI计算的新一代芯片,通过第三代DaVinci Core架构、灵衢互联技术以及MXFP4/MXFP8等低精度计算等特性支持,为AI应用提供了强大的算力底座。然而,硬件算力的充分释放离不开高效的软件栈支持。CANN作为昇腾AI处理器的异构计算架构,通过持续演进,已经形成了一套完整的算子开发生态。CANN以深度适配硬件新特性为核心,全新升级Cube模板库、Vector模板库、算子直调工程、仿真工具四大算子开发利器,从算子开发、调试、部署全链路实现开发提效、生产力释放,让开发者低门槛发挥新一代芯片的算力潜能。本文将深度解析CANN算子开发的多项关键优化技术,揭示其背后的技术原理与优秀实践。
一、CATLASS:Cube 模板库适配张量算力新特性,让矩阵计算算子开发更高效
CATLASS(Cube Template Library for Ascend)作为昇腾CANN体系中专为Cube核(矩阵计算核心)打造的矩阵计算算子模板库,对用户提供了一套模块化的高性能计算框架,其核心价值在于屏蔽芯片底层硬件细节,让开发者无需深入掌握指令集与架构逻辑,即可快速开发高性能矩阵计算算子。
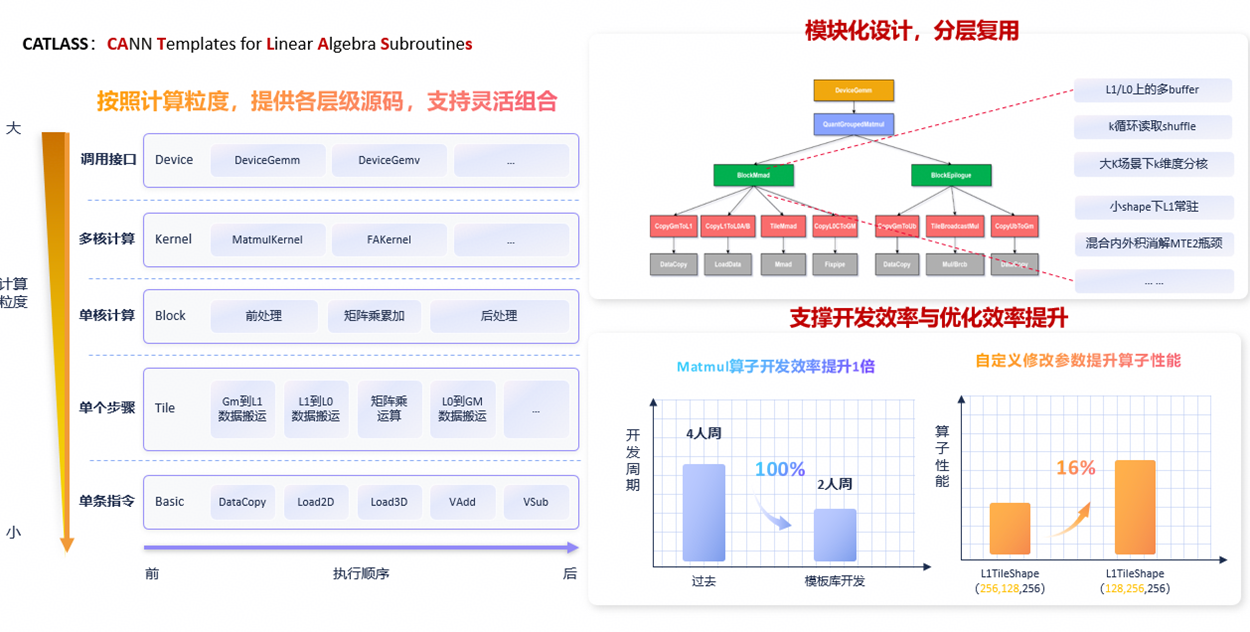
针对Ascend 950 PR/DT芯片的硬件升级,CATLASS以“深度贴合硬件新特性、充分释放算力、降低开发门槛”为核心,完成了全维度适配升级,覆盖硬件特性适配、分层架构优化、接口能力扩展、开发模式创新四大方向,全方位匹配Ascend 950的张量计算优势,以下是具体新特性的详细解析。
1、硬件新特性全维度适配,充分挖掘Cube核算力潜能
Ascend 950对Cube核进行了革命性升级,新增Fixpipe高效搬运指令、MXFP4/MXFP8低精度支持、C-V(Cube-Vector)直连通路三大核心硬件特性,CATLASS同步完成深度适配,通过软硬协同优化,将硬件潜力转化为实际算子性能,这也是本次适配的核心亮点。
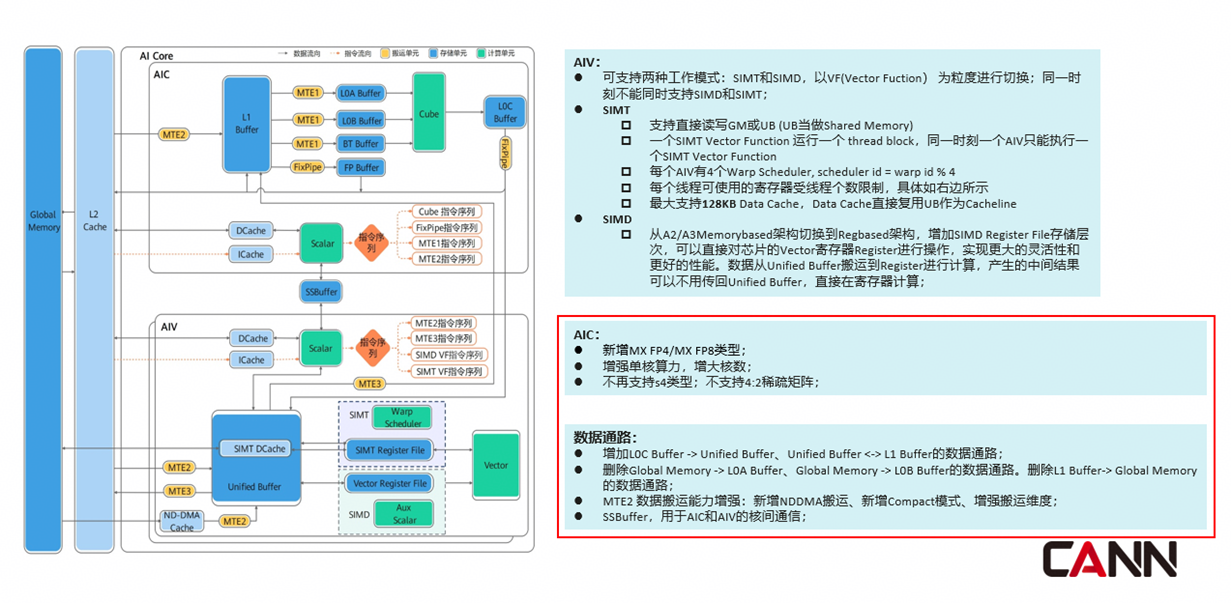
1.1 深度适配MXFP4/MXFP8低精度,构筑高效经济算力底座
低精度计算是平衡AI算力与显存开销的核心方向,Ascend 950作为国内首款原生支持MXFP4/MXFP8低精度格式的AI芯片,其MXFP4格式可将70B参数大模型的显存需求从FP16的140GB降至35GB,实现单卡加载大模型推理,同时推理延迟降低50%以上;MXFP8格式则兼顾精度与性能,适配中高精度推理、训练场景。此外,Ascend 950还支持带缩放功能的矩阵乘计算,核心公式为:C=(ScaleA⊗A)*(ScaleB⊗B)+C,其中ScaleA和ScaleB为缩放矩阵,需通过LoadData2DMX接口载入,且ScaleA采用小Z大Z分形格式(shape为(16,2)),ScaleB采用小N大N分形格式(shape为(2,16)),二者数据类型均为fp8_e8m0_t,与MXFP4/MXFP8低精度格式完美适配。
CATLASS针对MXFP4、MXFP8低精度格式完成了全面适配,将低精度数据的存储规则、带缩放矩阵乘的计算逻辑、精度控制策略全部封装进模板库,开发者无需关注低精度格式的底层实现细节,只需传入矩阵尺寸、缩放参数等基础配置,即可快速开发低精度矩阵计算算子。比如,向开发者提供了用于构造MxScale 输入排布的MakeMxScaleLayout、以及对GMToL1、L1ToL0等关键数据路径进行的TileCopyTla特化,以及更高层的封装。
1.2 适配C-V新通路,消除张量-向量计算数据中转冗余
在传统昇腾芯片中,Cube核(张量计算核心)与Vector核(向量计算核心)之间的数据传输需经由GM全局内存中转,存在“Cube核→GM→Vector核”的冗余操作,严重影响融合算子(如矩阵乘+激活)的性能。Ascend 950新增L0C→UB、UB→L1专用数据通路,直接打通了Cube核与Vector核间的直连传输通道:Cube核可将L0C内的计算数据高效分发至对应Vector核的UB中,Vector核的处理结果也可直接从UB搬运至L1缓存,全程无需GM参与,大幅缩短数据传输路径。
CATLASS已对这一C-V直连新通路完成深度适配,将新通路的数传逻辑、数据格式转换、同步机制全部融入融合算子开发模板,让矩阵计算与向量计算的融合算子彻底摆脱GM中转的冗余。例如,在大模型融合算子开发中,Cube核完成矩阵乘计算后,可通过C-V新通路直接将结果传输至Vector核进行激活处理,无需将数据写回GM再读取,大幅优化了后处理融合场景的算子执行效率。
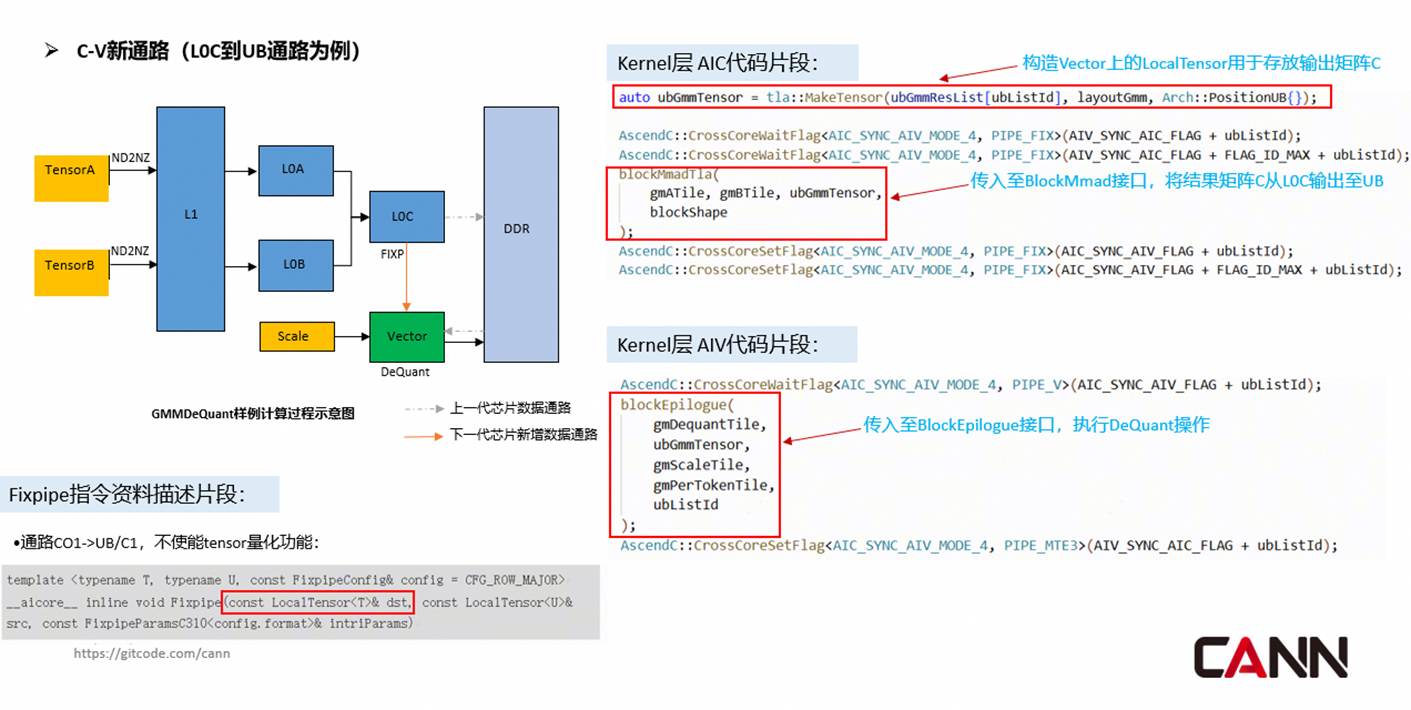
同时,针对Ascend 950全新引入的SIMD VF编程架构,我们在Epilogue后处理模块预置了多种高性能通用辅助函数,支持开发者直接复用、灵活扩展Tile层能力,比如集成输入/输出精度转换等常用算子能力,助力开发者从传统Memory-Base编码模式,平滑迁移至新一代Register-Base编程范式,快速完成高性能代码适配,降低架构迁移成本。
同样,UB -> L1 通路的补齐,也让数据在片上层级之间的回流和重组更自然,为BlockPrologue等能力提供了基础支撑。
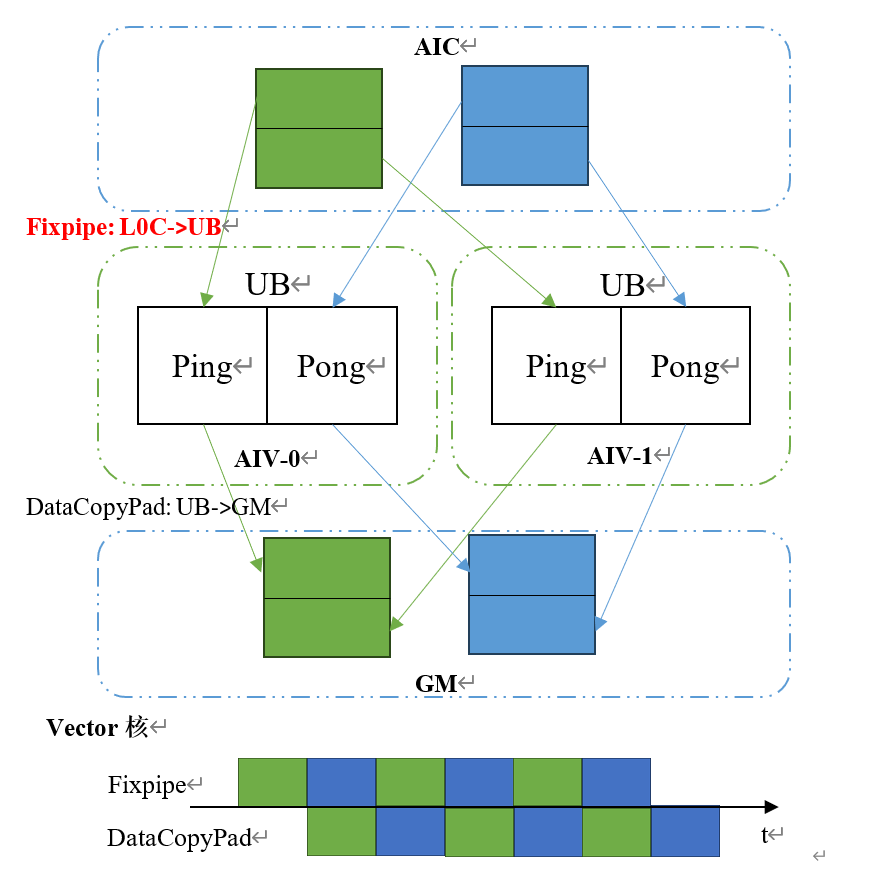
1.3 适配Fixpipe指令+Double Buffer机制,数据搬运效率翻倍
Ascend 950推出的Fixpipe增强数据搬运指令支持双目标搬运模式,打破了传统Cube核单路数据搬运的限制,其核心逻辑是将Cube核L0C缓存(本地缓存)中的单份数据拆分为两路,并行写入两个Vector核各自的UB(Unified Buffer)统一缓冲区。相较于前代芯片需要将完整的一个基本块搬运到UB上才能启动AIV核的Vec操作,新搬运模式下Fixpipe只需搬运原来一半的数据即可触发后续Vec操作,由两个AIV核共同分担L0C上一个基本块的后处理操作,最后汇总到GM上,实现更紧密的流水。
同时,Ascend 950为每块L0C缓存、UB缓冲区都支持独立开启Double Buffer(双缓冲,简称DB)机制,在DB模式下,UB可实现数据读写的流水线重叠——即在将数据向GM(Global Memory,全局内存)传输的同时,持续接收来自L0C的新数据,彻底消除数据搬运与计算之间的等待间隙,最大化隐藏数据传输延迟。
针对这一硬件特性,CATLASS已完成全流程适配,不仅将Fixpipe指令与Double Buffer机制深度融合进模板底层逻辑,还推出了专门的优化样例,尤其针对K 值较小、MN 值较大的Fixpipe Bound场景能够实现较大的性能收益,并且开发者无需手动编写复杂的流水编排、缓冲区调度代码,只需复用模板即可直接调用这两项优化能力。
2、TLA接口扩展,强化张量语义表达,降低编程门槛
在大模型场景中,复杂性往往不是来自"算子公式本身",而是来自"数据到底怎么摆、怎么切、怎么搬"。同样是一个 Tensor,从开发者的视角看,它是一个逻辑上的多维数组;
但从硬件执行的角度看,它可能带着对齐、分块、分形排布、边界裁剪和多层存储位置差异。如果这些信息混在一起,代码就会迅速变成"逻辑 + 地址 + 特判 + 尾块处理"的混合体,既难写,也难复用。本次针对Ascend 950的硬件特性,CATLASS对TLA接口进行了全面扩展,进一步强化了张量语义表达能力,简化了算子开发流程。

TLA,也就是 Tensor Layout Abstraction,做的正是这件事:把复杂张量表达拆开,并给开发者一套统一的语义。
在 TLA 中,Tensor 由四部分组成:BuiltinTensor、Layout、Coord、Position。
- BuiltinTensor 表示底层存储对象,比如 GlobalTensor 或 LocalTensor
- Layout 表示逻辑坐标如何映射到内存,以及逻辑有效范围如何表达
- Position 表示数据位于 GM、L1、L0 等哪一层存储
- Coord 表示当前 Tensor 相对原始表示的元素级偏移
这一组接口共同指向一种更清晰的开发方式:
先用 TileView 把 tile 的逻辑切分讲清楚,再用 MakeTensorLike 把不同层级上的数据视图对齐起来,让布局、位置、偏移与有效范围保持统一语义。
3、EVG声明式Epilogue开发,简化后处理逻辑,兼顾性能与便捷性
如果说TLA解决的是"前半段的数据组织",那么EVG解决的,就是"后半段的后处理组织"。大模型时代,GEMM 后面跟着的,往往已经不是一个简单写回。
加法、类型转换、广播、规约、融合计算,这些后处理逻辑越来越多,而且越写越复杂。
过去,很多这类代码之所以难写,不是因为算式难,而是因为开发者要自己处理太多执行细节:数据从哪来、UB 空间怎么分、事件怎么同步、流水怎么排、什么时候写回。本次CATLASS针对Ascend 950的计算特性,新增EVG(Epilogue Visitor Graph)声明式开发方式,彻底改变了传统的手写后处理模式,实现后处理逻辑的“声明式组合、零手动优化”。

EVG,全称Epilogue Visitor Graph,是CATLASS面向GEMM Epilogue的声明式框架。它把后处理操作抽象成可组合的模板节点,再通过树形结构或拓扑结构把这些节点拼成一张计算图。
这意味着,开发者不再需要一边写计算、一边手搓GM/UB搬运和同步逻辑,而是可以直接站在"表达式"层面描述需求。
比如,D = C + X,只要把对应的Load、Compute、Store节点连起来,框架就能自动处理数据搬运、UB空间分配、事件同步和流水调度。
这种抽象带来的最大变化,不是"少写几行代码",而是后处理终于可以像主计算一样,被组织成一种可复用的结构能力。
EVG当前支持两类主要组织方式:
- TreeVisitor:适合树形组合,没有共享子表达式时更简单、更直观
- TopologicalVisitor:适合 DAG 结构,当中间结果会被多个节点复用时,可以用拓扑方式表达依赖关系
这使复杂Epilogue不再是"流程写死的模板代码",而是"可以按阶段、按节点、按依赖关系灵活拼装的图"。
相比手工组织GM/UB拷贝和事件同步,EVG能显著降低开发复杂度,同时以尽量保持接近手写实现的性能为目标,并支持图和节点复用。
这句话其实非常关键,因为它点出了EVG的真正价值:不是只为了让代码更优雅,而是为了让复杂融合逻辑既更容易写,也更有机会沉淀为长期可复用的能力。
因为模型和业务逻辑还会继续变化,后处理融合需求只会越来越多。如果每次都从头手工编排,那开发成本几乎注定越来越高;而如果可以把这些逻辑变成图、变成节点、变成结构化复用能力,CATLASS 的价值就不再只是"提供若干实现",而是在提供一套后处理编程方法。
二、ATVOSS:Vector 模板库让算子开发更简洁、性能再提升
为释放Ascend 950在算子侧的价值,CANN 围绕“开发提效 + 性能可预期”的链路做了升级。其中,Vector 模板库 ATVOSS 的改进重点在于:让 Vector 类融合算子的数学表达与工程调度解耦,并通过资源调度与冗余开销消减,让运行效率和稳定性同步提升。
ATVOSS(Ascend C Templates for Vector Operator Subroutines)可理解为:面向昇腾 Vector 单元的算子模板库。它把 Vector 融合算子常见的工程复杂度(如切分、流水、片上缓冲区 UB 的管理、中间结果停留、同步编排等)封装在框架内部,让开发者更聚焦“要算什么”(数学逻辑与融合结构),而不是每次都从底层手写调度与内存细节。
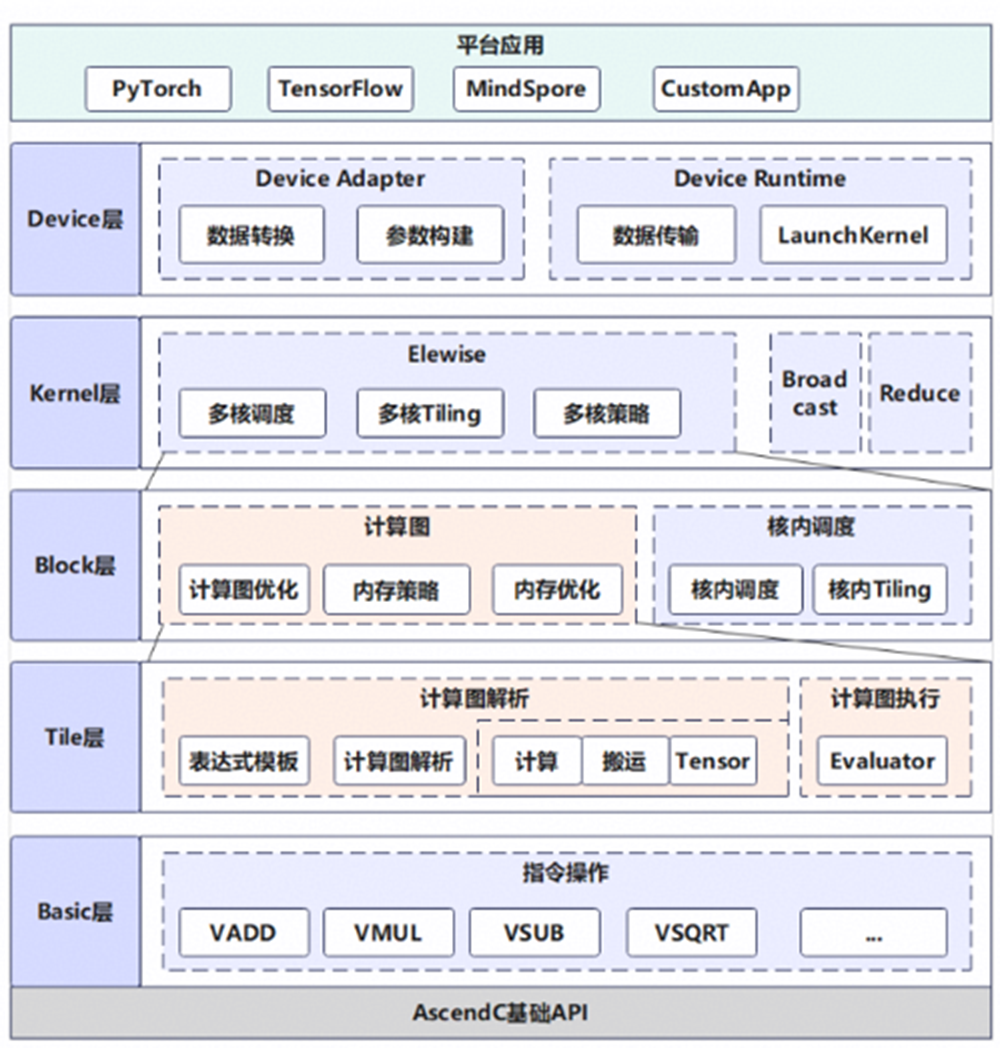
|
层级 |
职责 |
主要功能 |
|
Device 层 |
Host 侧调用总入口 |
参数校验、ACL 资源管理、Host 与 Device 数据管理、切分计算、Workspace 管理、Kernel 调用 |
|
Kernel 层 |
Kernel 函数总入口 |
多核间任务分解,控制 Block 调度 |
|
Block 层 |
单核任务分解 |
将任务分解到多个 Tile 块,控制数据搬运/计算流水编排 |
|
Tile 层 |
Ascend C 封装 |
封装基础 API,提供大 Tile 块的搬运、计算能力 |
|
Basic 层 |
基础操作 |
使用 Ascend C 基础 API 完成数据搬运计算 |
这种分层的意义在于:不同粒度的问题在不同层解决,开发接口更统一;同时,性能相关的控制点(切分策略、流水、UB占用与复用等)也能在框架内形成可复用的实现路径。
本次 ATVOSS 在原有高效开发框架的基础上,从开发体验、性能优化、场景适配等多个维度完成全面升级,通过语法简化、资源智能调度、零开销抽象等核心机制,实现了向量算子 “开发简化” 与 “性能提升” 的双重目标,为 Ascend C 向量算子开发带来全新体验。
1、“算子开发更简洁”:表达更直观、buffer 更自动、抽象更轻量
-
数学表达写法更简化
ATVOSS 对数学表达式编写进行了深度简化,通过模板与表达式建模设计了更贴近自然语义的编程接口,开发者无需编写复杂的循环、索引等冗余代码,只需以简洁直观的方式描述核心数学逻辑,模板即可自动将其转换为适配 Vector 核的底层指令,大幅降低了代码编写成本。

1.1 buffer 自动分配能力
Vector 算子常常需要在片上 UB 中规划输入/输出/临时缓冲区。ATVOSS 引入框架级的 buffer 管理,降低开发者手动配置与反复调整的负担,让“能跑”更容易、“稳定跑”更省力。
1.2 零运行时开销的模板化抽象
框架使用 C++ 模板元编程思想,把不少结构与关系在编译期表达出来,从而减少运行时分支与额外开销;开发者得到的是更统一的接口体验,而不是把底层硬件细节暴露到每一行业务代码里。
2、“性能再提升”:资源调度更精准、冗余开销更少、片上闭环更完整
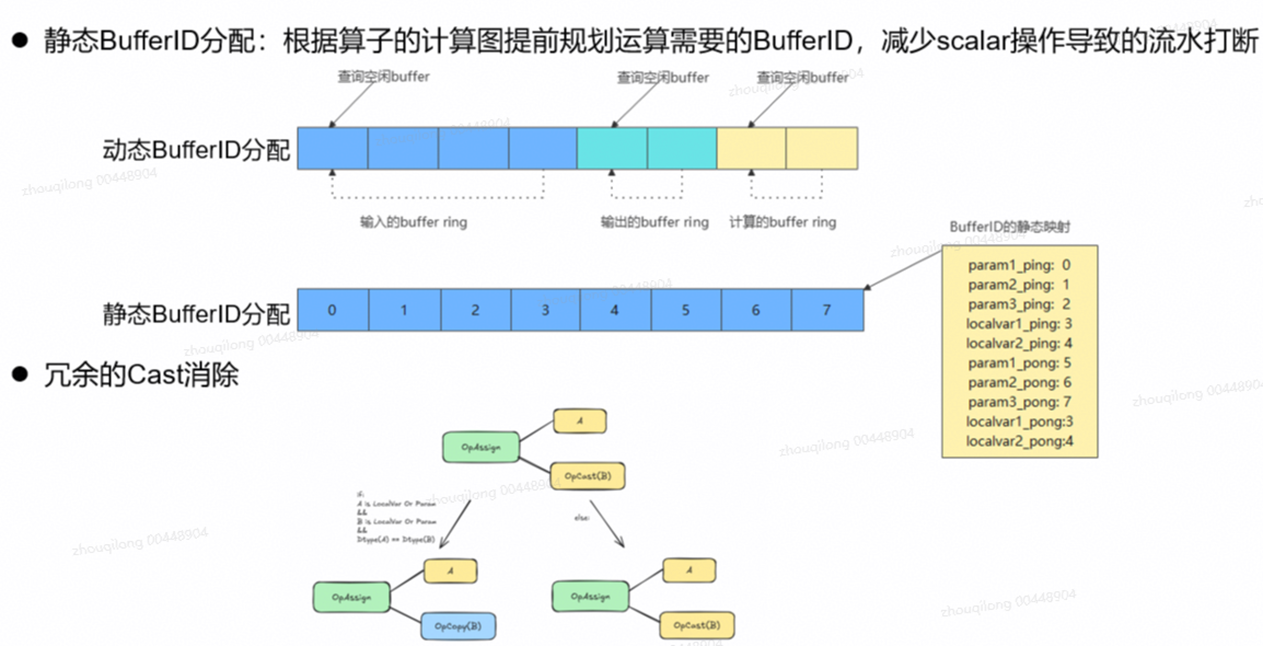
2.1 bufferid 静态分配机制:资源调度更精准
相比依赖更动态的资源分配,静态分配更有利于形成确定的调度路径,减少运行过程中的不必要变化,让执行更稳定、可预期。
2.2 冗余 cast 消除:减少无效类型转换
融合算子里类型转换常见且容易形成“看不见的开销”。通过识别与消除冗余 cast,减少不必要的转换链路,让计算路径更干净。
2.3 片上 UB 驻留与融合闭环:中间结果就地完成
ATVOSS 支持向量类融合算子的灵活组合,使中间结果尽量在片上完成后续计算,减少中间张量在全局内存(GM)与片上之间的往返。
2.4 流水线调度与双缓冲:计算与搬运重叠
在数据搬运与 Vector Unit 计算之间建立更有效的重叠关系(例如双缓冲流水),用更充分的并行度提升吞吐,并降低因访存等待引起的气泡。
3、ATVOSS 算子的调用流程与代码示例

示例请参考:
https://gitcode.com/cann/atvoss/tree/master/examples
https://gitcode.com/cann/atvoss/tree/master/tests/st
三、算子直调工程:打通新特性适配最后一公里,实现算子调用部署零门槛
算子开发完成后的调用与部署,是异构计算的传统痛点。由于 CPU 和 NPU 拥有独立的内存空间和指令集,传统的 NPU 核函数调用需要经过初始化上下文、手动管理队列、显式绑定内核镜像、调用底层 ACL API等一系列繁琐步骤,且底层 API 需要处理复杂的 void** 指针数组和内存偏移,开发门槛高、易出错,严重影响了 Ascend 950 新特性算子的落地效率。
本次昇腾 CANN 推出的算子直调工程,通过编译器层面的创新设计,彻底解决了这一痛点,其核心是引入了 **<<<>>>** 专属语法符号,将极其复杂的设备端初始化、参数压栈、指令调度等逻辑全部封装进这一符号,让开发者调用 NPU 核函数变得像 “调用普通 C++ 函数” 一样自然,真正实现了算子调用与部署的零门槛,打通了 Ascend 950 新特性适配的最后一公里。
1、 <<<>>> 符号:编译器的语法 “后门”,封装底层所有复杂逻辑
<<<>>> 符号的本质,是昇腾编译器在 C++ 语法层面为异构计算开发开设的专属 “后门”。编译器在编译阶段会对这一符号进行特殊解析,将其背后的设备端上下文初始化、核函数参数压栈、NPU 队列调度、内核镜像绑定等一系列复杂逻辑自动生成并执行,开发者无需编写任何相关代码,只需在调用核函数时添加这一符号,即可完成从 CPU 到 NPU 的核函数调用。
例如,传统调用 NPU 核函数需要数十行代码完成底层 API 的调用与参数处理,而基于算子直调工程,开发者只需通过kernel <<<>>>(params)的简单形式,即可实现核函数的快速调用,代码量大幅减少,开发效率呈指数级提升。
2、 三大核心能力,打造极简且安全的异构编程体验
算子直调工程并非简单的语法简化,其围绕 <<<>>> 符号构建了三大核心能力,让异构编程更简洁、更安全、更高效:
2.1全类型泛型编程,编译期严格类型检查
开发者可通过kernel <<<>>>(params)直接传递任意 C++ 类型的参数,包括自定义结构体、复杂的指针组合、各类数值类型、模板类等,编译器会在编译阶段对所有参数进行严格的类型检查,及时发现类型不匹配、参数缺失等问题,避免了运行时的类型错误,大幅提升了代码的健壮性。相比传统底层 API 的 void** 指针传参(丢失类型信息),泛型编程让异构编程的类型安全性得到了充分保障。
2.2告别底层 ACL API,摆脱繁琐的指针与内存处理
如果没有算子直调工程,开发者需要直接调用aclrtLaunchKernel等底层 ACL API,处理繁琐的 void** 指针数组、内存偏移计算、参数序列化等工作,不仅开发难度大,且容易因指针操作失误导致程序崩溃。算子直调工程彻底屏蔽了底层 API 的细节,开发者无需关注指针与内存的底层处理,只需专注于核心业务逻辑,大幅降低了异构编程的学习与开发成本。
2.3 Host/Device 代码混合编译,无需手动隔离文件
传统昇腾开发需要将 Host 侧(CPU)代码和 Device 侧(NPU)代码分别编写在不同的文件中,通过独立编译后再进行链接,开发流程繁琐,代码维护难度大。算子直调工程支持Host 侧代码和 Device 侧代码混写在一个编译单元,开发者可在同一个文件中编写 CPU 的逻辑控制代码和 NPU 的核函数代码,编译器会自动完成 Host/Device 代码的分离与编译,无需手动隔离文件,让异构编程的代码组织更简洁,维护更高效。

四、CANNSIM 仿真工具:深度适配 Ascend 950,实现无硬件依赖的全链路调优
算子开发与优化的传统模式高度依赖物理硬件,开发者需要将算子部署到实际的 Ascend 芯片上才能进行精度验证与性能调优,不仅存在 “上板试错” 的高时间成本,还受限于硬件资源的可用性,严重影响了开发迭代效率。
昇腾 CANN 旗下的CANNSIM 仿真工具本次正式完成对 Ascend 950 的深度适配,成为 Ascend 950 硬件平台算子开发、调试与性能优化的全流程仿真利器。CANNSIM 通过精准的硬件行为仿真,让开发者无需依赖物理硬件,即可完成算子的精度验证、性能分析与瓶颈定位,大幅降低了开发门槛,加速了 Ascend 950 新特性算子的创新迭代。
1. 双核心仿真能力,实现精度与性能的全维度验证
本次 CANNSIM 对 Ascend 950 的适配,聚焦于精准仿真与高效调优两大核心需求,打造了精度仿真与性能仿真双核心能力,覆盖算子开发的核心验证需求:
1.1 精度仿真:bit 级结果输出,精准验证算子精度
精度是算子开发的基础要求,尤其是在 MXFP4/MXFP8 低精度场景中,精度损失控制至关重要。CANNSIM 的精度仿真能力可模拟 Ascend 950 的硬件计算逻辑,输出与实际芯片完全一致的bit 级精度计算结果,开发者可直接将仿真结果与理论结果、CPU 计算结果进行比对,精准验证算子的精度是否符合要求,及时发现低精度转换、计算逻辑等方面的精度问题。相比传统的上板精度验证,CANNSIM 的仿真验证无需部署硬件,可在开发早期快速完成精度排查,大幅降低了精度问题的修复成本。
1.2 性能仿真:生成指令流水图,精准定位性能瓶颈
性能优化是算子开发的核心目标,而性能瓶颈的定位需要深入到指令执行层面。CANNSIM 的性能仿真能力可模拟 Ascend 950 的指令执行流程,生成详细的指令流水图,清晰展示算子在 Cube 核、Vector 核中的指令执行顺序、数据搬运时机、流水打断位置等关键信息。开发者可通过指令流水图快速定位算子的性能瓶颈,如数据搬运耗时过长、流水打断、计算资源利用率不足等,并针对性地进行优化。结合昇腾 CANN 的 msprof 性能分析工具,开发者可实现 “仿真预判瓶颈 - 针对性优化 - 仿真验证效果” 的闭环,大幅提升性能优化效率。
2. CANNSIM使用示例
2.1 编译生成算子测试的可执行文件
编译命令:bash scripts/build.sh -soc=ascend950 --example abs
生成的文件:output/bin/abs
2.2 利用仿真工具进行验证
设置环境变量:source ~/Ascend/cann/bin/setenv.bash
执行命令:cannsim record ./abs -u "--shape=32,32 --type_input=f32" -s Ascend950 --gen-report
执行结果查看:view cannsim_20260305150418_abs/cannsim.log
tips:如果cannsim的版本还不支持-u参数,那就把./abs --shape=32,32 --type_input=f32 放到一个shell脚本中(abs.sh),执行cannsim record ./abs.sh -s Ascend950 --gen-report
执行结果示意图:

流水图文件:xxxx/cannsim_xxx_abs/report/trace_core0.json
在edge浏览器中输入"edge://tracing/"或是在Chrome浏览器中输入"chrome://tracing", 把trace_core0.json文件拖进去
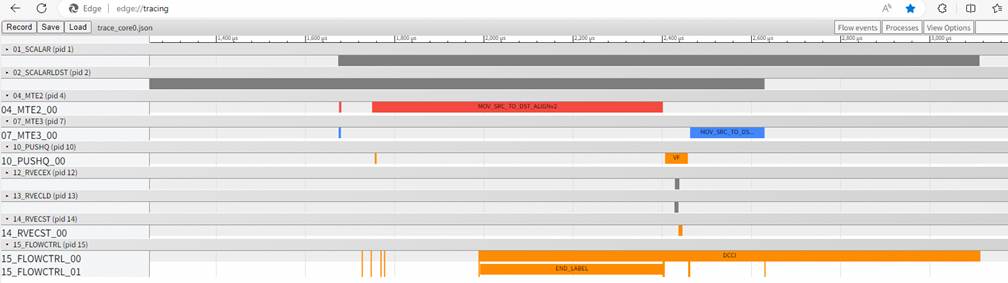
可以根据流水图分析算子性能的改进点。
五、全链路软硬协同:四大利器构筑 Ascend 950 算子开发新体系
昇腾CANN本次的四大核心利器升级,并非孤立的工具优化,而是围绕Ascend 950的硬件新特性,在算子开发、调试、部署等关键维度上实现了工具能力与硬件特性的深度协同。每一处升级都紧扣硬件特性、针对开发者痛点,实现了工具与硬件的深度融合,让Ascend 950的算力能够真正转化为实际的应用性能。
从开发环节来看,CATLASS与ATVOSS形成“矩阵计算 + 向量计算”的全覆盖模板体系,分别适配Ascend 950的Cube核与Vector核硬件新特性,将底层硬件细节全部封装进模板,让开发者通过模板复用即可快速实现高性能算子开发,彻底告别“从零手写”的低效模式;从调试环节来看,CANNSIM实现了无硬件依赖的精准仿真,将调试验证从“上板试错”变为“仿真预判”,大幅缩短了迭代周期;从部署环节来看,算子直调工程打通了异构编程的最后一公里,将算子部署从“复杂适配”变为“一键直达”,让新特性算子能够快速落地。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐



 0
0 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)