
一芯双构:华为昇腾950PR/DT命名背后的技术巧思


温馨提醒:数据中心4件套(服务器、存储、网络、SSD全解系列)姊妹篇已全部发布,之前购买过“架构师技术全店资料打包汇总(全)(已持续更新至48本)”的读者免费发放全店更新(请在发货的汇总链接下载),或请凭借购买记录在微店留言获取(PDF阅读版本)。
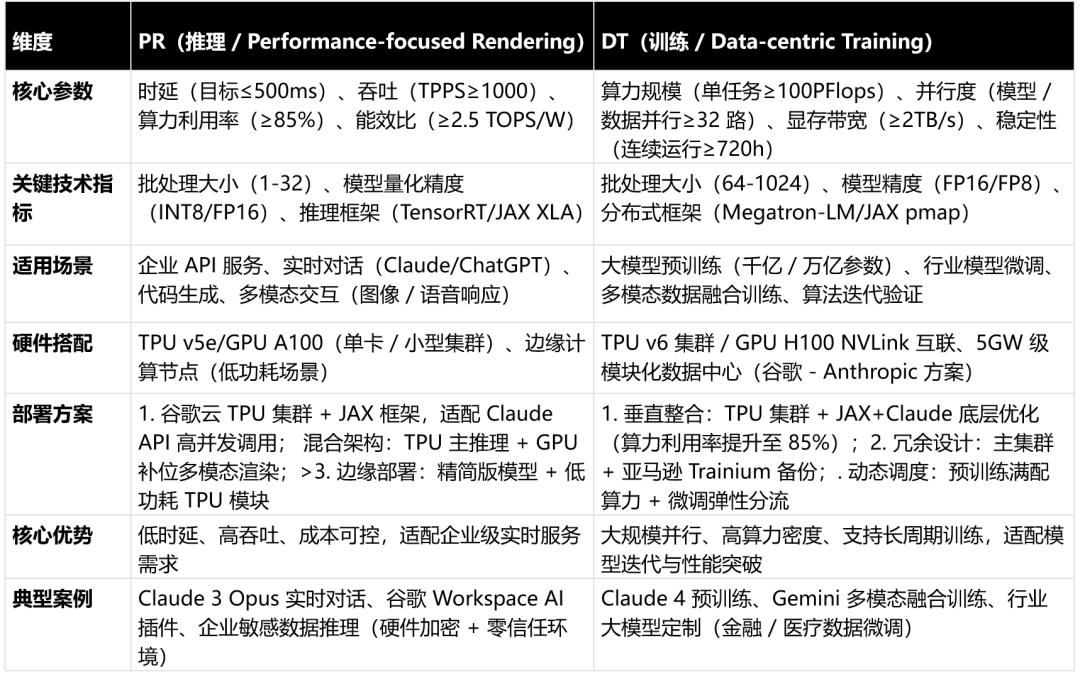
很多人看到昇腾 950 后面跟着 PR、DT,第一反应是字母代号,其实这不是简单后缀,而是华为对大模型算力的一次场景化重构。
PR=Prefill & Recommendation,预填充+推荐。
DT=Decode & Training,解码+训练。
两个缩写,直接把芯片的使命、场景、性能取向说透。
一、为什么要做 PR 和 DT 两款?
大模型推理有两个完全不同的阶段,用同一块芯片跑,等于让短跑运动员去跑马拉松,两头都不极致。
-
Prefill(预填充)用户输入一整段提示词,芯片一次性并行算完,建好 KV 缓存,准备输出第一个 Token。特点:计算密集、算力优先、带宽需求相对低。电商推荐、内容信息流,也是同款高吞吐、低时延需求。
-
Decode(解码)逐字逐句生成回答,一遍遍读写缓存。特点:访存密集、带宽优先、容量要大。模型训练更是吃带宽、吃容量的大户。



图片:码农修行录
华为没有做 “全能芯片”,而是一芯双构: same 950 核心 Die,搭配不同自研 HBM,精准匹配两段需求。
二、950PR:算力型选手,主打高性价比
PR 面向计算密集,追求低成本、高吞吐。
-
核心:Prefill + 推荐场景
-
内存:HiBL 1.0,128GB,带宽 1.6TB/s
-
定位:首 Token 快、并发强、成本友好
它就像大模型的 “前台”,快速处理输入、响应推荐请求,用更少成本跑出更高效率。
三、950DT:带宽型猛兽,主打高性能
DT 面向访存密集,要的是大带宽、大内存。
-
核心:Decode 生成 + 模型训练
-
内存:HiZQ 2.0,144GB,带宽高达 4TB/s
-
定位:长文本生成稳、训练速度快、不掉链子
它是大模型的 “后台引擎”,保证回答生成顺滑不卡顿,训练时扛得住海量参数读写。
四、命名逻辑:不玩虚的,一切为效率
PR、DT 不是随便起的。
- PR:Prefill+Recommendation,计算优先,性价比为王
- DT:Decode+Training,带宽优先,性能拉满
本质就是P/D 分离:把 “首字快” 和 “生成顺” 拆开,用专用芯片各司其职,避免资源争抢,把能效、成本、时延做到最优。
五、一点真实思考
这种设计,看似是产品细分,实则是架构成熟度的体现。
过去大家堆参数、堆算力,现在开始按场景切分、按负载优化。PR+DT 的组合,让昇腾 950 既能打推理,又能扛训练,还能把成本压下来。
对用户来说,不用再为用不上的性能买单;对行业来说,是务实的 AI 芯片路线。
![]()

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)