
DeepSeek正式发布全新V4系列:百万上下文普惠时代的三大范式级突破
DeepSeek-V4系列重磅发布:国产大模型迎来三大突破 2026年4月,DeepSeek发布新一代旗舰大模型V4系列,带来三大革命性突破:1)首创CSA/HCA混合注意力架构,百万token长文本处理成为标配,计算量降至前代27%;2)深度适配国产算力,首次官方验证华为昇腾NPU平台;3)价格降至行业1/100,输入成本仅0.2元/百万token。实测显示,V4-Pro在SuperCLUE评测
2026年4月24日,DeepSeek无预警发布新一代旗舰大模型DeepSeek-V4系列并同步开源。这不是一次常规的模型迭代——它将百万token超长上下文打入全系标配,将推理成本降至“白菜价”,并首次在官方技术报告中将国产芯片与英伟达GPU并列写入硬件验证清单。本文系统梳理V4的核心升级、技术突破、实测表现与行业影响。
一、核心概要:V4带来了什么?
DeepSeek-V4推出两个版本:
| 版本 | 定位 | 适用场景 |
| V4-Pro | 旗舰版 | 高精度复杂任务、专业场景 |
| V4-Flash | 轻量版 | 高频日常使用、成本敏感场景 |
三大核心升级亮点:
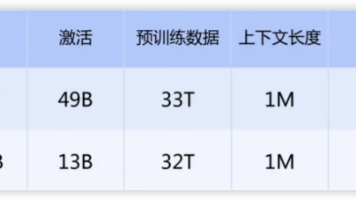
1.加量:标配100万token超长上下文,一次性处理《三体》三部曲体量2.提速:计算量降至前代27%,显存占用降至10%3.降价:Flash版输入最低0.2元/百万token,仅为海外模型的1/100
二、三大范式级技术突破
技术层面,V4实现了三项具有行业里程碑意义的技术创新。
2.1 突破一:注意力压缩革命——CSA/HCA混合架构
这是V4最核心的技术革新。
传统注意力机制的困境:处理长文本时,算力随长度呈二次方增长。100万token意味着约1万亿次计算操作,显存占用过高[ citation:5]。
V4的解决方案:独创CSA(压缩稀疏注意力)+ HCA(重度压缩注意力)混合架构。
| 机制 | 压缩比 | 功能 | 类比 |
| HCA | 128:1 | 暴力压缩,提供全局语境 | “超广角镜”扫视全貌 |
| CSA | 4:1 | 轻度压缩,保留细节 | “微距长焦镜”聚焦线索 |
实际效果:V4-Pro单token推理计算量仅为前代V3.2的27%,KV缓存占用仅10%;V4-Flash更分别降至10%和7%。
2.2 突破二:百万上下文成为标配
此前,超长上下文是高价专属功能。V4将其变为全系标配,不分版本、不加价。
实际意义:
•一次性处理整部《三体》三部曲(约75万字)•完整阅读300+页上市公司年报并精准定位数据•整份合同、代码库、合规材料一次性纳入分析
2.3 突破三:国产算力深度适配
V4首次在官方技术报告中明确写道:“我们验证了细粒度EP方案在英伟达GPU和华为昇腾NPU双平台上的表现”。
战略意义:
•V4选用的FP4精度格式,恰好是华为昇腾950芯片原生支持的精度•DeepSeek表示,下半年昇腾950超节点批量上市后,V4-Pro价格将大幅下调•从英伟达CUDA生态向华为CANN框架迁移启动
华为同日发文确认,“昇腾一直同步支持DeepSeek系列模型,本次通过双方芯模技术紧密协同,实现昇腾超节点全系列产品支持DeepSeek-V4系列模型”。
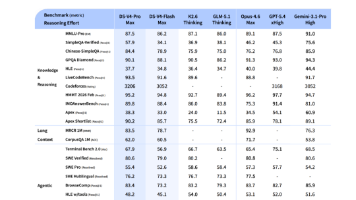
三、能力评测:Benchmark与实测
3.1 SuperCLUE综合测评
2026年4月28日,SuperCLUE发布V4系列测评结果:
| 模型 | 综合得分 | 排名 |
| DeepSeek-V4-Pro | 70.98 | 国产第一 |
| DeepSeek-V4-Flash | 68.82 | 国产第二 |
分维度表现:
•智能体能力:较V3.2提升超过20分•数学推理:提升近10分•指令遵循:提升近12分•幻觉控制:明显改善
3.2 实测一:长文本处理
实测材料:某上市公司324页年报。
第一层测试:提炼年报核心要点 → V4响应约19秒,答案完整准确。
第二层测试:定位两个藏在第212-213页和第311-313页的具体数据(回购股份数量与对价、管理人员酬金排名第三的人员与金额)→ V4完全准确定位,并精确到页码。
即使在关闭深度思考的快速模式下,V4同样准确找到短期银行借款利率区间数据。
3.3 实测二:代码生成与调试
测试设计:让V4生成含隐藏Bug代码 → 再让V4找出并修复。
开启深度思考:V4识别出6项错误,超出原题预设的2-3个范围,额外识别出除零错误、KeyError等边界问题。
关闭深度思考:核心结论基本一致,识别出文件未正确关闭、数据类型错误等问题,速度更快。
结论:日常调试关闭深度思考已够用;生产环境审查建议开启深度思考获得更完整分析。
3.4 实测三:复杂商业推理
测试场景:护肤品公司净利润率从12%腰斩至6%,伴随库存积压、营销费用失控等问题。
V4首先完成问题拆解:将所有负面信号归类为现金流威胁、盈利能力恶化、市场结构性风险三个维度;再依据“若不立即处理会导致现金流断裂或持续亏损”的紧迫性标准完成排序。
最终排序:
1.库存积压与现金流风险(若不立即处理将直接威胁生存)2.盈利能力持续恶化3.中端市场被抢占与渠道结构性短板
连贯推理能力验证:追问“若优先发力电商渠道可能面临哪些新风险”,V4仅用3秒直接在第一轮分析基础上继续推导,识别出五项新风险,并给出“止损时间窗口”等具体建议。
四、定价策略:把AI成本打到“白菜价”
V4延续DeepSeek一贯的激进定价策略:
| 计费场景 | V4-Pro | V4-Flash | 竞品参考 |
| 输入(缓存命中) | 0.025元/百万token* | 0.02元/百万token | ~2-3元 |
| 输入(缓存未命中) | 12元/百万token | 1元/百万token | ~40-60元 |
| 输出 | 24元/百万token | 2元/百万token | ~60-120元 |
*注:Pro版0.025元为2026年5月5日前限时2.5折优惠价
横向对比:Flash版价格仅为海外顶级模型的约1/100。DeepSeek表示,下半年昇腾950量产上线后,Pro版价格还将大幅下调。
此外,V4同时支持OpenAI和Anthropic两种API接口格式,开发者切换只需改一个参数,迁移成本几乎为零。
五、行业影响:V4为何成为“冲击波”?
5.1 资本市场反应
V4发布后,港股AI明星股应声大跌:
•MiniMax:连续三日大跌,从1330港元高点腰斩至660港元
•智谱:跌破千元大关
摩根大通认为市场存在“过度反应”,维持对两家公司“增持”评级,理由包括:
1.V4缓解了算力供给约束——这是妨碍这些公司全面扩张的主要障碍
2.昇腾芯片广泛应用将改善推理成本曲线,开辟新的收入路径
3.最大的短期竞争不确定性已出清
5.2 竞争格局重塑
海通国际分析师张晓飞指出,V4的发布深刻重塑了行业格局:
1.打破“开源落后闭源”魔咒:闭源厂商很难再用“性能壁垒”维持高价
2.打破CUDA生态依赖:全栈适配华为昇腾、寒武纪等国产AI芯片
3.定价权转移:从少数闭源巨头流向开源社区
5.3 生态响应
V4发布后迅速获得广泛接入:
•南京市政务大模型平台:率先完成政务外网私有化部署
•网易有道龙虾:率先接入V4与Kimi K2.6
•中关村科金得助平台:完成V4基础能力对接
六、限制与差距:客观评估
6.1 与国际顶尖模型的差距
DeepSeek在技术报告中主动承认:“DeepSeek-V4-Pro-Max的表现小幅超越当前领先开源模型,但仍落后于GPT-5.4和Gemini-3.1-Pro,差距约三到六个月”。
在代码生成质量与复杂多步指令执行等环节,距国际领先水平仍有差距。
6.2 功能局限
V4为纯文本模型,暂不支持多模态识别(如图像、音频、视频输入)。相比之下,Gemini 3.1 Pro已实现全模态,GPT-5.4支持文本+图片+音频+视频。
6.3 算力限制
V4-Pro当前服务吞吐有限。DeepSeek明确表示,受限于高端算力,Pro版本高峰期服务能力受到一定限制。
七、V4的行业坐标意义
DeepSeek-V4的发布,作用不局限于产品本身。
对普通用户:百万长上下文成为标配,无需分段处理长文档;价格大幅降低,AI真正变得“好用不贵”。
对开发者:开源+适配国产芯片+极低API成本,让顶级AI能力门槛降至历史最低。
对行业:首次实现国产大模型与国产算力底座的系统级协同,“用国产算力跑国产模型”进入实践阶段。
一位从业者评价称:“当一个开源模型把百万上下文变成标配、把API价格打到竞品的三分之一,闭源模型的护城河其实没有想象中那么宽”。
本文数据来源:DeepSeek官方技术报告、SuperCLUE测评报告(2026年4月28日)、南京日报、证券时报、36氪、钛媒体等多家媒体实测与报道。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)