
周红伟:梁文峰交卷DeepSeek V4,能给几分?DeepSeek V4重磅发布,百万上下文成标配,华为昇腾率先适配!
同时,它与领先的闭源模型 Gemini-3.1-Pro 的差距已经大幅缩小,但在这些知识类测试中仍略逊一筹。在广义世界知识评估中,DeepSeek-V4-Pro 的最高推理模式 DeepSeek-V4-Pro-Max,在 SimpleQA 和 Chinese-SimpleQA 等基准测试上,显著优于主流开源模型。在推理维度,通过增加推理 token 的投入,DeepSeek-V4-Pro-Max
就在 OpenAI 于凌晨刚推出 GPT-5.5 版本之后的几个小时,国产大模型也迎来了重磅时刻——DeepSeek-V4 预览版官宣上线,并同步开源。
官方发布 58 页完整技术报告,让开源大模型迈入百万 token 高效上下文时代,彻底重构长文本大模型的效率与能力边界。

开源地址:
-
https://huggingface.co/collections/deepseek-ai/deepseek-v4
-
https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
技术报告:
-
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf

双模型齐发:1.6T 旗舰与 284B 轻量版,均支持百万字上下文
最新发布的 DeepSeek-V4 系列一次性推出两款全新的 MoE 架构大模型,全部支持百万字超长上下文,按照模型大小来分:
-
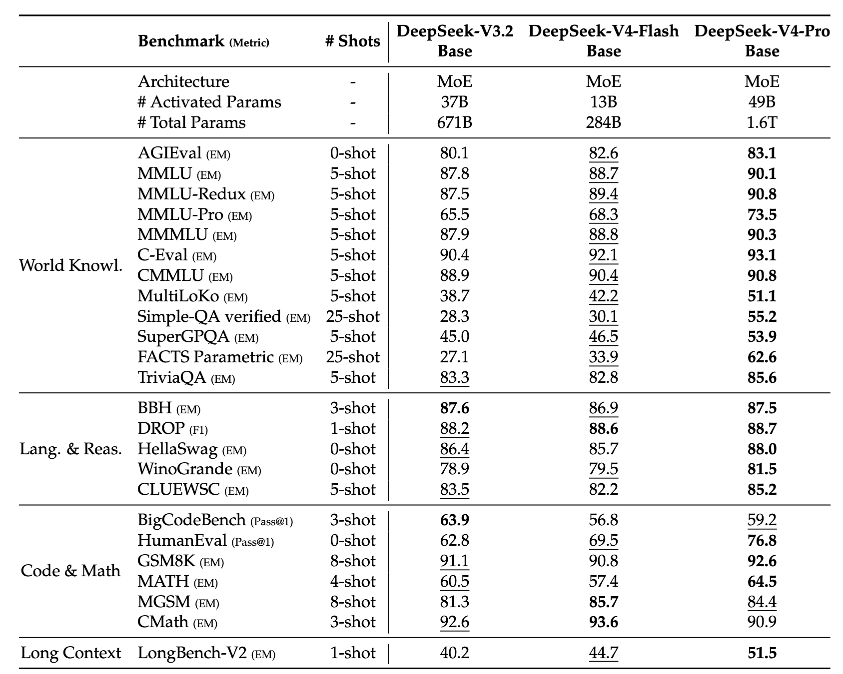
DeepSeek-V4-Pro:总参数量为 1.6T、激活参数为 49B,在知识、推理、代码、智能体、长文档理解上比肩顶级闭源模型;
-
DeepSeek‑V4‑Flash:总参数 284B,激活参数为 13B,以极小激活参数量实现逼近旗舰的推理性能。

官方表示,两款模型在 Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。即日起,登录 DeepSeek 官网 chat.deepseek.com 或官方App,就可以直接体验最新的 DeepSeek-V4 能力。
此外,API 服务已同步更新,通过修改 model_name 为 deepseek-v4-pro 或 deepseek-v4-flash 即可调用。
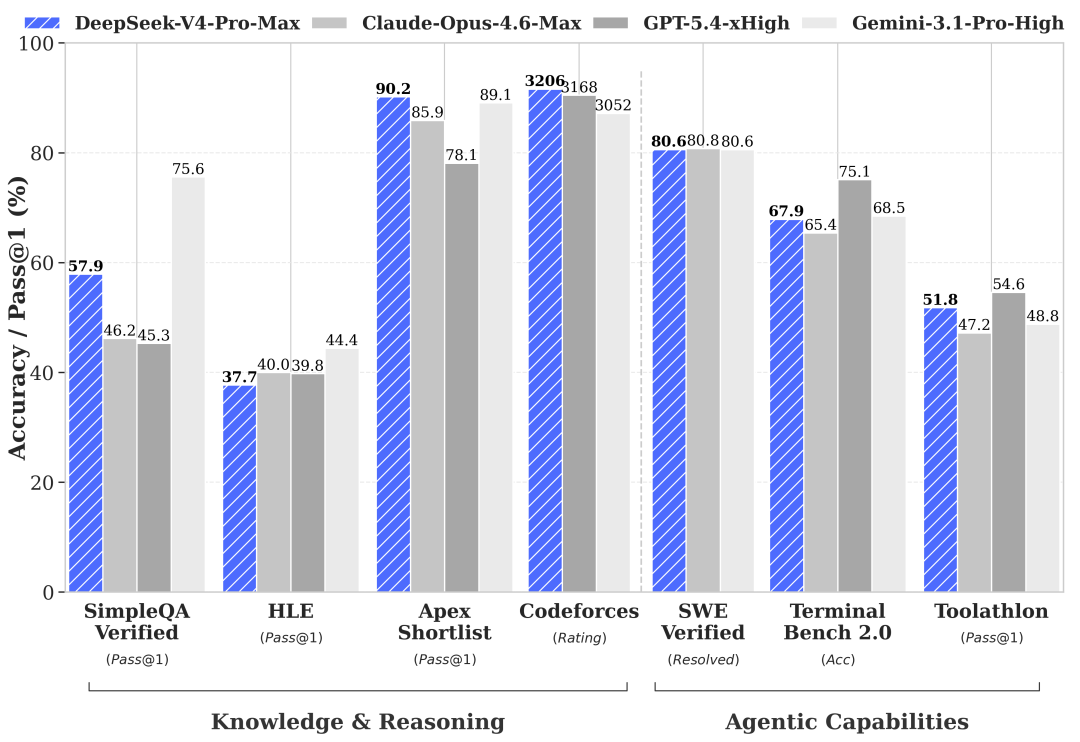

架构升级,关键技术创新大幅提高上下文效率
从技术架构层面来看,DeepSeek‑V4 没有停留在堆参数、扩数据的传统路线,而是从注意力机制、残差连接、优化器三大底层维度,进行了技术升级。
简单来看,与 DeepSeek-V3 架构相比,DeepSeek-V4 系列保留了 DeepSeekMoE 框架和多词元预测(MTP)策略,同时在架构和优化方面引入了多项关键创新:
-
采用混合注意力架构,将压缩稀疏注意力(CSA)和重压缩注意力(HCA)结合,用于提升长上下文处理效率。CSA 沿序列维度压缩键值缓存,然后执行 DeepSeek 稀疏注意力(DSA),而 HCA 对键值缓存应用更激进的压缩,但保持了密集注意力;
-
为了增强建模能力,DeepSeek 也在架构中引入了流形约束超连接(mHC),在传统残差连接基础上进一步增强信息传递能力;
-
以及 Muon 优化器被引入了 DeepSeek-V4 系列的训练中,用于加快收敛速度并提升训练稳定性。
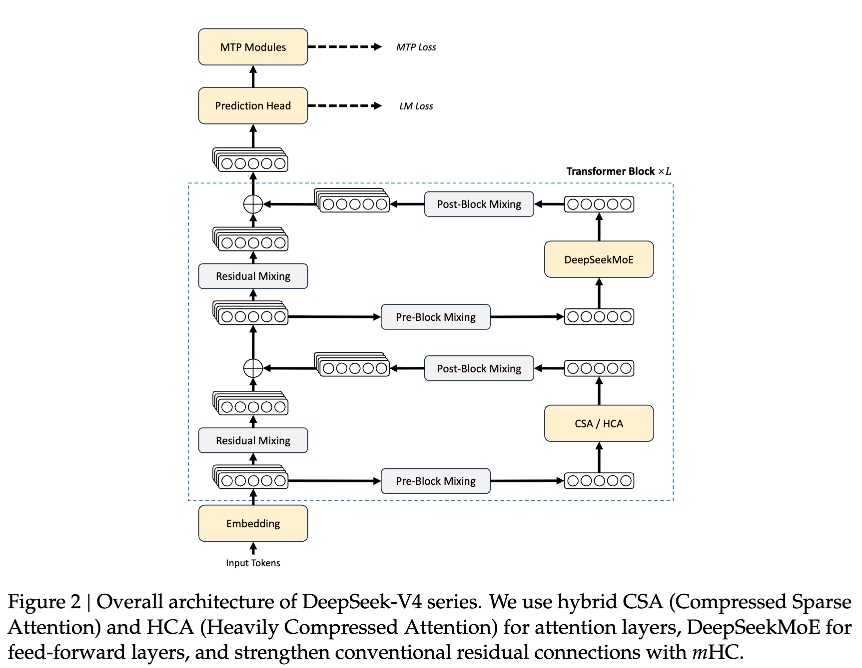
在训练维度,DeepSeek 在超过 32T 高质量、多样化的 token 上对两个模型进行了预训练,并在此基础上引入了一整套完整的后训练流程,进一步增强模型能力。
同时,据技术报告显示,DeepSeek-V4 系列在长上下文场景下也表现出极高的效率。在百万 Token 的上下文设置下,DeepSeek-V4-Pro 仅需 DeepSeek-V3.2 的 27% 单 Token 推理 FLOP,KV cache 占用仅为 10%。
正因此,DeepSeek 能够将“百万 token 上下文”作为常规能力来支持,从而显著提升长时序任务的可行性,并为测试阶段的进一步扩展提供了空间。正如官方所说:“从现在开始,1M(一百万)上下文将是 DeepSeek 所有官方服务的标配。”
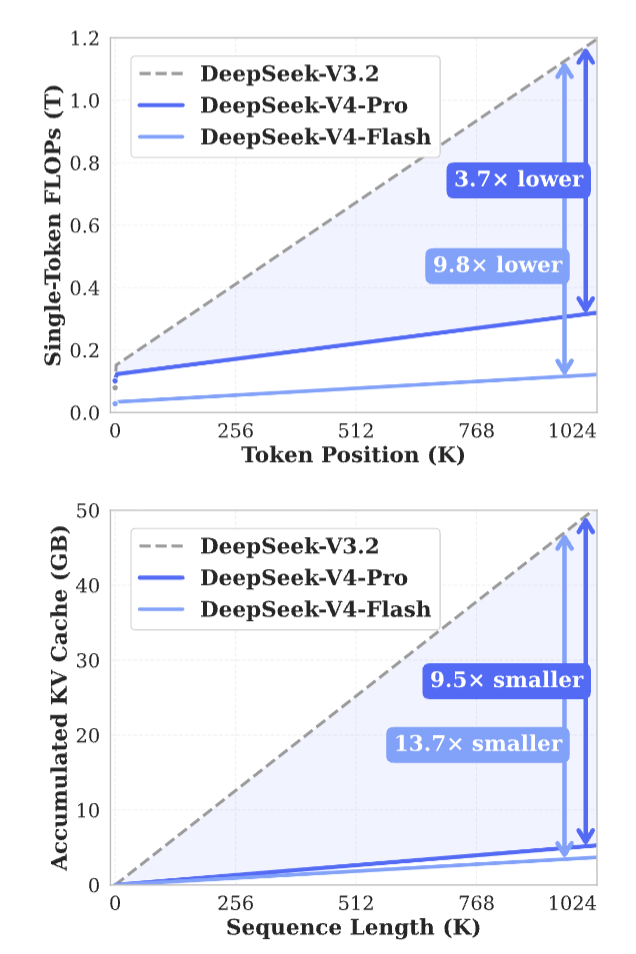

性能比肩顶级闭源模型
值得注意的是,DeepSeek-V4-ProMax 是 DeepSeek-V4-Pro 的最高推理模式,重新定义了开放模型的性能标准,在核心任务上超越了其前代产品。
另外,DeepSeek-V4 系列的性能在多个维度都有了全面的提升:
-
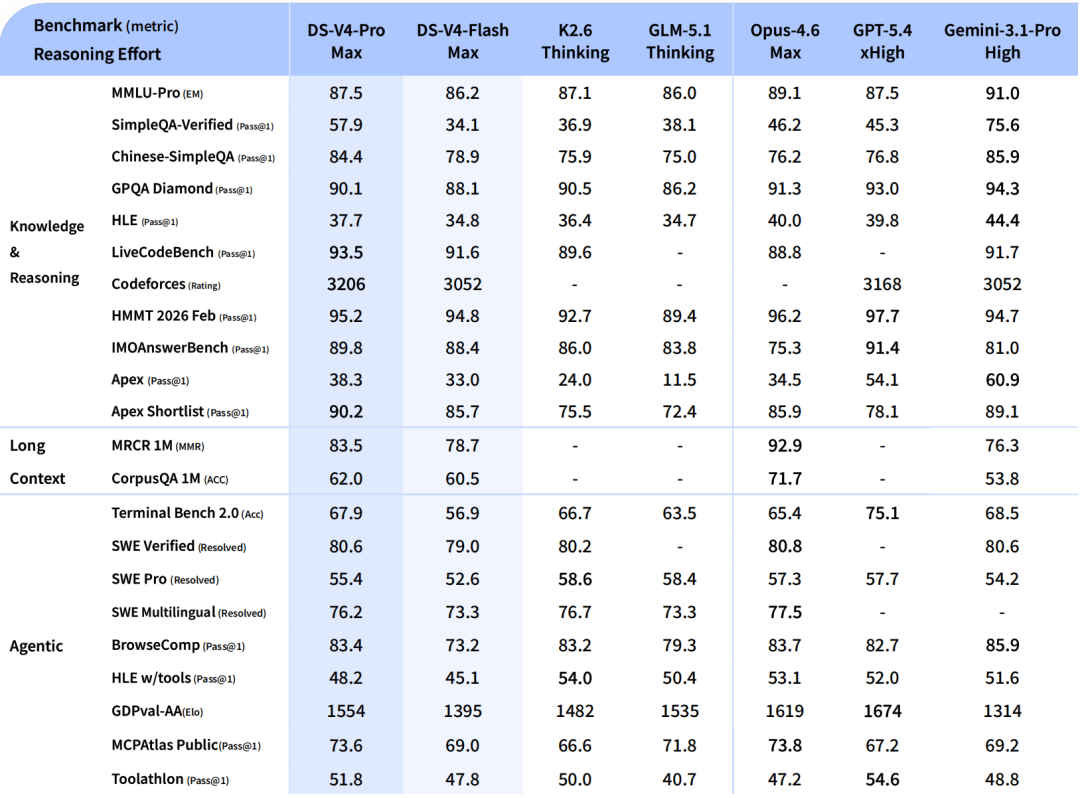
在广义世界知识评估中,DeepSeek-V4-Pro 的最高推理模式 DeepSeek-V4-Pro-Max,在 SimpleQA 和 Chinese-SimpleQA 等基准测试上,显著优于主流开源模型。
在教育类知识评估方面(包括 MMLU-Pro、HLE 和 GPQA),DeepSeek-V4-Pro-Max 相较开源模型仍保持小幅领先。同时,它与领先的闭源模型 Gemini-3.1-Pro 的差距已经大幅缩小,但在这些知识类测试中仍略逊一筹。
-
在推理维度,通过增加推理 token 的投入,DeepSeek-V4-Pro-Max 在标准推理基准上展现出优于 GPT-5.2 和 Gemini-3.0-Pro 的表现。
不过,其性能仍略低于 GPT-5.4 和 Gemini-3.1-Pro,这表明其整体发展水平大约落后最前沿模型 3 到 6 个月。
此外,DeepSeek-V4-Flash-Max 在复杂推理任务中达到了接近 GPT-5.2 和 Gemini-3.0-Pro 的表现,体现出较高的性价比。
-
Agent 能力上,在公开基准测试中,DeepSeek-V4-Pro-Max 与领先开源模型(如 Kimi-K2.6 和 GLM-5.1)表现相当,但略逊于顶级闭源模型。在内部评测中,DeepSeek-V4-Pro-Max 超过了 Claude Sonnet 4.5,并接近 Claude Opus 4.5 的水平。
-
在支持 100 万 token 上下文窗口的情况下,DeepSeek-V4-Pro-Max 在合成任务和真实场景中均表现出色,甚至在学术基准测试中超过了 Gemini-3.1-Pro。
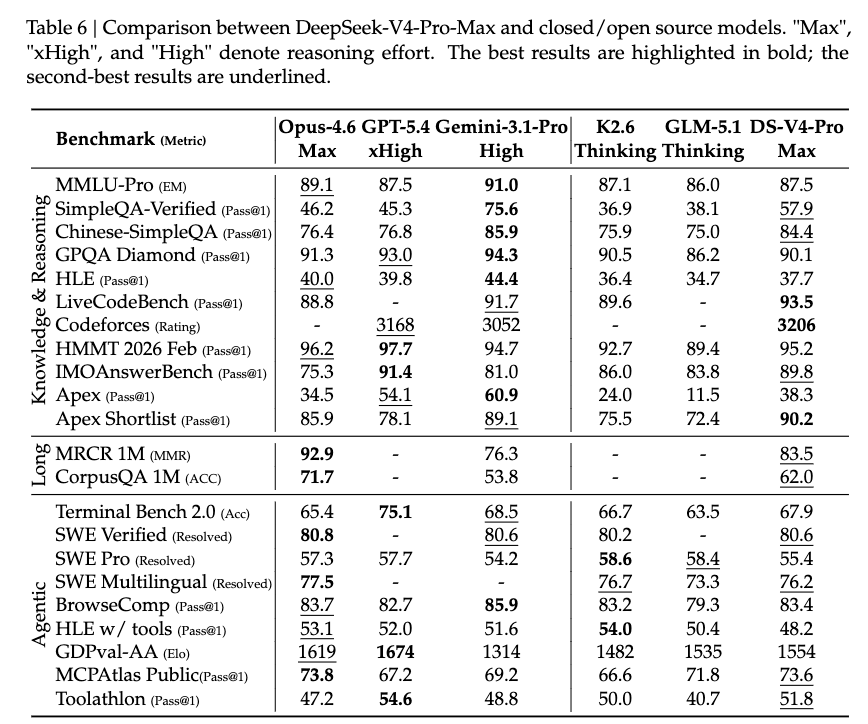
相比 DeepSeek-V4-Pro-Max,DeepSeek-V4-Flash-Max 由于参数规模更小, 在知识类评估中的表现略低。但在给予更大思考预算时,其推理任务表现可以接近 DeepSeek-V4-Pro-Max。
在 Agent 评测中,DeepSeek-V4-Flash-Max 在部分基准上能够与 DeepSeek-V4-Pro-Max 持平,但在更复杂、高难度任务中仍存在差距。

算力支持
值得注意的是,对于行业最关注的国产算力落地,DeepSeek 在技术报告中指出,他们在 NVIDIA GPU 和华为 Ascend NPU 平台上,对细粒度 EP(Expert Parallelism)方案进行了验证。
另一方面,华为昇腾超节点系列产品也宣布全面支持,本次通过双方芯模技术紧密协同,实现异腾超节点全系列产品支持 DeepSeek V4 系列模型。


API 同步开放:无缝兼容主流接口,一键接入最强开源长上下文
时下 DeepSeek‑V4 API 已同步上线,支持 OpenAI ChatCompletions 与 Anthropic 接口规范。
访问新模型时,base_url 不变, model 参数需要改为 deepseek-v4-pro 或 deepseek-v4-flash。
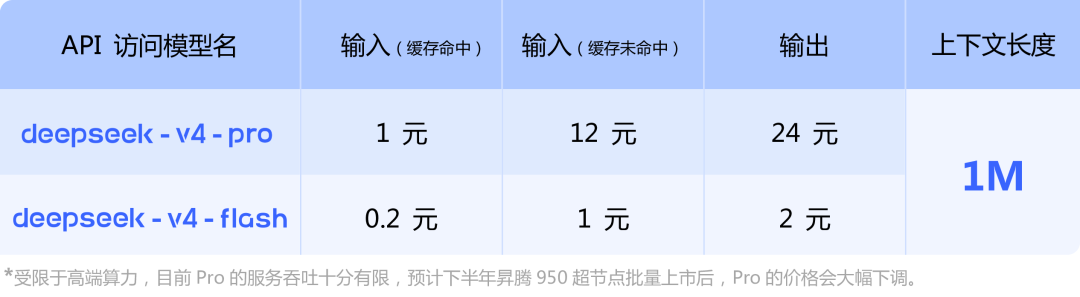
另外,DeepSeek 官方还提到,旧有的 API 接口的两个模型名 deepseek-chat 与deepseek-reasoner 将于三个月后(2026-07-24)停止使用。当前阶段内,这两个模型名分别指向 deepseek-v4-flash 的非思考模式与思考模式。
普通用户可直接登录 DeepSeek 官网或官方 App,体验 100 万 Token 上下文带来的震撼能力:一次性上传整本书、整个项目代码、整份合同文档,实现真正的 “一次性读懂、全程记忆、深度推理”。
DeepSeek‑V4 的到来,不只是一次模型升级,更是开源大模型进入 “百万上下文高效时代” 的标志。它用架构创新证明:超长上下文不必靠暴力算力,小激活参数也能拥有顶级推理。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)