
DeepSeek V4价格暴降75%!Claude Code实战400万Tokens,终于可以爽用了
DeepSeek V4 这次降价,放在全行业涨价的背景下看,冲击力很大。短期:2.5 折是限时优惠,5 月 5 日到期。到期后价格大概率会回升,但下半年有再次降价的预期。长期:DeepSeek 的降价底气来自国产算力的崛起。昇腾 950 批量上市后,成本结构会进一步优化。如果国产芯片产能跟上,这个价位有望常态化。选型:Flash 是日常主力,性价比几乎无对手。Pro 在特惠期间是 Agent Co
最近几个月,国内大模型厂商基本都在涨价。DeepSeek 掀桌了,反手一刀砍了 75%。
4 月 24 日 V4 发布,V4-Pro 百万 token 输出定价 24 元,比上一代贵了好几倍,吐槽声一片——“这不像 DeepSeek 的风格”。结果不到 24 小时,官网直接上了 2.5 折特惠,输出价砍到 6 元。全行业在涨,就它在降,那个熟悉的 DeepSeek 又回来了。
先说结论,再展开细节。5 月 5 日前这几件事 Guide 建议马上做:
- 注册 DeepSeek API 账号,充点余额。
- 在 Claude Code 里配上 V4-Pro,趁 2.5 折特惠多跑几个项目。接入方式可以参考我周末写的:DeepSeek V4+Claude Code 一手实战!夯爆了还是拉完了?。
- 用 Claude Code 开 1M 上下文的话,模型名要写成
deepseek-v4-pro[1m],别搞错了。
下面是完整分析。本文接近 5000 字,建议收藏。这篇文章聊几件事:
- V4-Pro 和 V4-Flash 的降价细节:新旧价格对比,到底便宜了多少
- 两场 Claude Code 实战:用 V4-Pro 做代码审计 + 全项目扫描,真实成本和效果
- 全行业涨价背景下的横向对比:和国内云厂商、海外模型的价差有多大
- 降价背后:昇腾 950 和国产算力的关系
![Claude Code 配置 deepseek-v4-pro[1m]](https://i-blog.csdnimg.cn/img_convert/74551244adac558f046324f4d950e1ff.png)
V4-Pro 降价:从“有点贵”到“真香”只用了一天
先看数据。
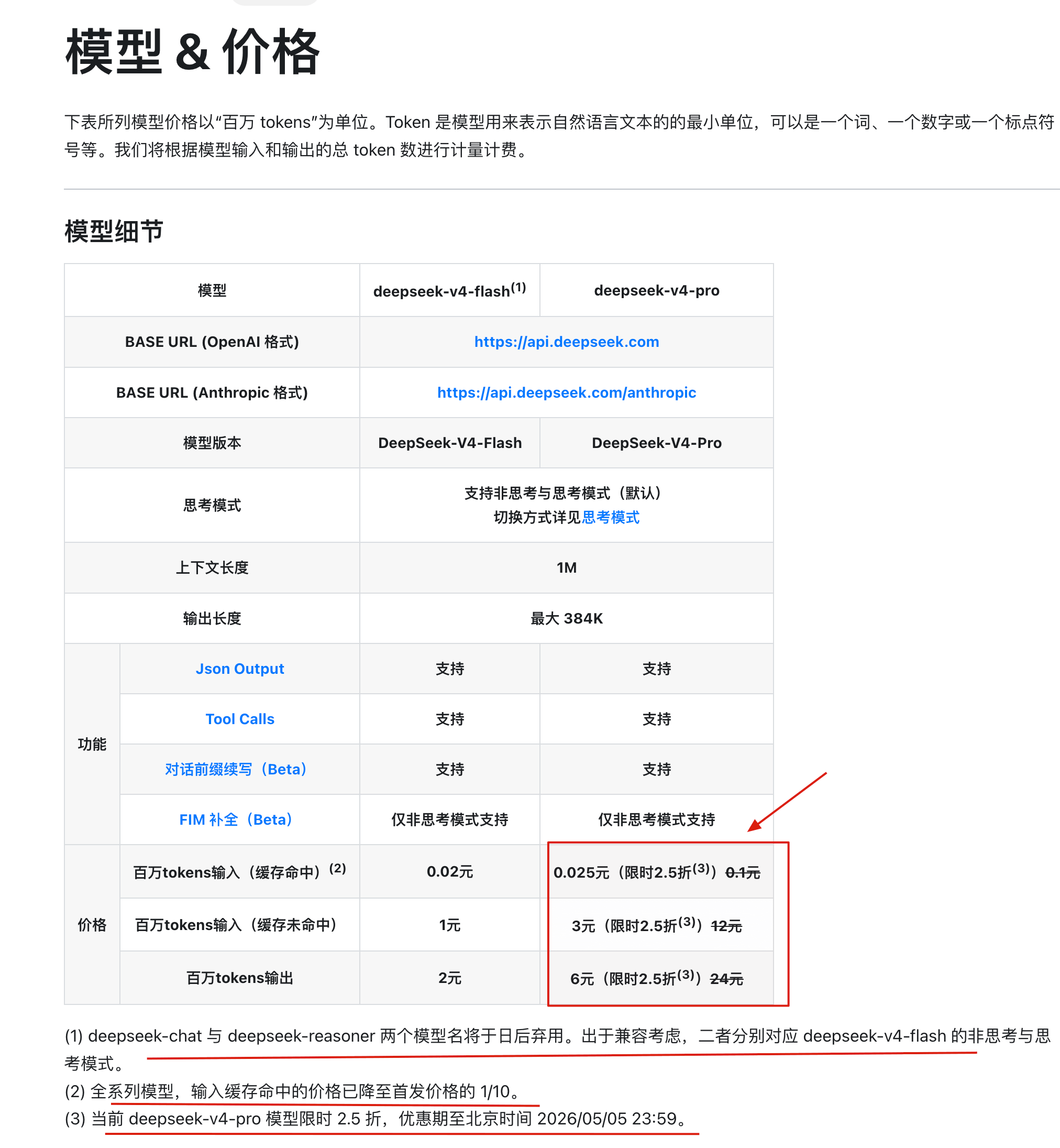
| 定价项(每百万 token) | V4-Pro 原价 | V4-Pro 特惠价(2.5 折) | 降幅 |
|---|---|---|---|
| 输入(缓存命中) | 1 元 | 0.25 元 | 75% |
| 输入(缓存未命中) | 12 元 | 3 元 | 75% |
| 输出 | 24 元 | 6 元 | 75% |
特惠期截至 2026 年 5 月 5 日 23:59。
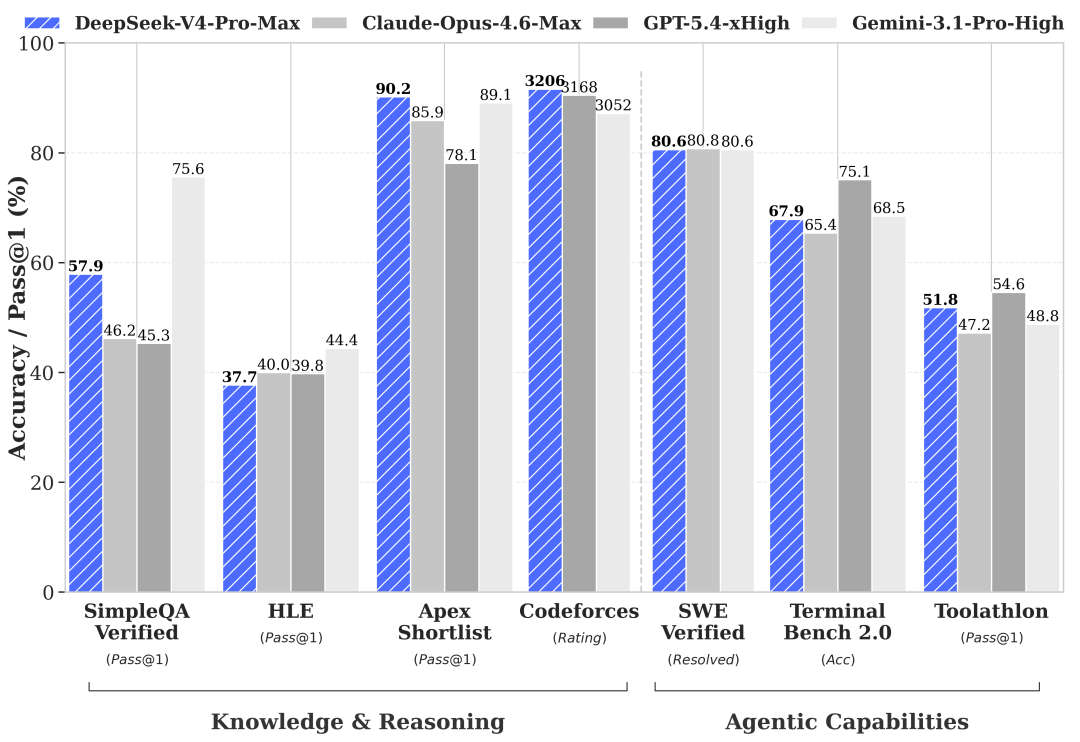
降完之后是什么概念?V4-Pro 的缓存命中输入价格只要 0.25 元/百万 token,基本上等于白送。输出 6 元/百万 token,和 V3.2 时代的 3 元/百万 token 相比虽然翻了一倍,但考虑到 V4-Pro 在 SWE-bench Verified 上拿到了 80.6%(和 Claude Opus 4.6 的 80.8% 几乎打平),这个价格的性价比已经很高了。
说白了,之前 V4-Pro 的原价确实有点不符合 DeepSeek 的风格,吐槽声一片。DeepSeek 反应也快,不到一天直接 2.5 折,算是给了一个明确的回应。
不过要注意:这是限时优惠。5 月 5 日之后价格会回到原价吗?DeepSeek 官方没有明确说,但他们在技术报告里提了一句:“预计下半年昇腾 950 超节点批量上市后,Pro 价格会大幅下调”。
也就是说,现在的 2.5 折很可能是一次预演,下半年算力跟上之后,这个价位有望常态化。
V4-Flash:真正的日常主力,性能更强价格更低
V4-Pro 降价吸引了所有眼球,但 V4-Flash 才是大多数人应该关注的那个。
V4-Flash 直接平替 V3.2(即 deepseek-chat),性能更强,价格反而更低:
| 定价项(每百万 token) | V3.2 原价 | V4-Flash 现价 | 变化 |
|---|---|---|---|
| 输入(缓存命中) | 0.2 元 | 0.2 元 | 不变 |
| 输入(缓存未命中) | 2 元 | 1 元 | 降 50% |
| 输出 | 3 元 | 2 元 | 降 33% |
Flash 的定位是“高性价比日常主力”,每百万 token 输出只要 2 元,缓存命中输入只要 0.2 元。对比 Claude Sonnet 4.6 的输出 $15/百万 token(约合 108 元),Flash 的输出价格不到 Sonnet 的 1/50。
我在《DeepSeek V4 + Claude Code 一手实战!夯爆了还是拉完了?》里用 V4-Flash 在 AI 面试平台上跑了一轮完整面试流程,非思考模式下面试题和评估报告的生成质量已经不错了,放到这个定价体系里看几乎没什么对手。
如果你的使用场景主要是对话、内容生成、简单问答,V4-Flash 几乎没有对手。
实战一:用 V4-Pro 做项目代码审计,再交给 GPT-5.5 复核修复
我手头的多智能体股票分析项目,MVP 版本已经跑起来了,支持股票分析、多策略、告警、技能、多模型、通知等功能。但开发过程中赶进度,代码质量没顾上好好把关。
这次我试了一个思路:用便宜的模型做审计,用贵的模型做决策和修复。
在 Claude Code 里直接让 DeepSeek V4-Pro 启动多个 Agent,从安全性、功能正确性、代码质量等不同维度扫描整个项目,把发现的问题汇总写入文档。

V4-Pro 确实找出来不少问题,最紧急的 TOP 5:
- API Key 明文存储 — 加密器已实现但未接入
- 系统管理接口无权限控制 — 普通用户可修改 LLM 配置
- Redis 反序列化漏洞 —
activateDefaultTyping允许任意类实例化 - 硬编码第三方 API Key — Bocha 真实密钥提交在代码中
- 功能 Bug — History 页“重新分析”按钮因路由参数未读取而失效
我大概过了一遍,基本都是合理的。安全类问题尤其值得重视,第 3 条 Redis 反序列化漏洞如果被利用,后果很严重。
接下来我把 V4-Pro 找出来的问题直接丢给 GPT-5.5 复核。

为什么不让 V4-Pro 自己修? 因为代码审计和代码修复是两种能力,用不同模型交叉验证更靠谱——一个负责找问题,一个负责确认问题并执行修复。
这也是我在《从夯爆开始锐评我用过的 AI 编程模型》里说的:GPT-5.5 和 Claude Opus 4.6 双王并列,复杂任务交给它们更稳。
GPT-5.5 复核后直接执行了修复,整个过程很顺。
这个案例的重点不是 V4-Pro 有多强,而是用便宜模型干活、用贵模型把关这个思路。
V4-Pro 特惠期做代码扫描的成本几乎可以忽略,同样的事交给 GPT-5.5 或 Claude Opus 4.6 来做,费用至少高出两个数量级。
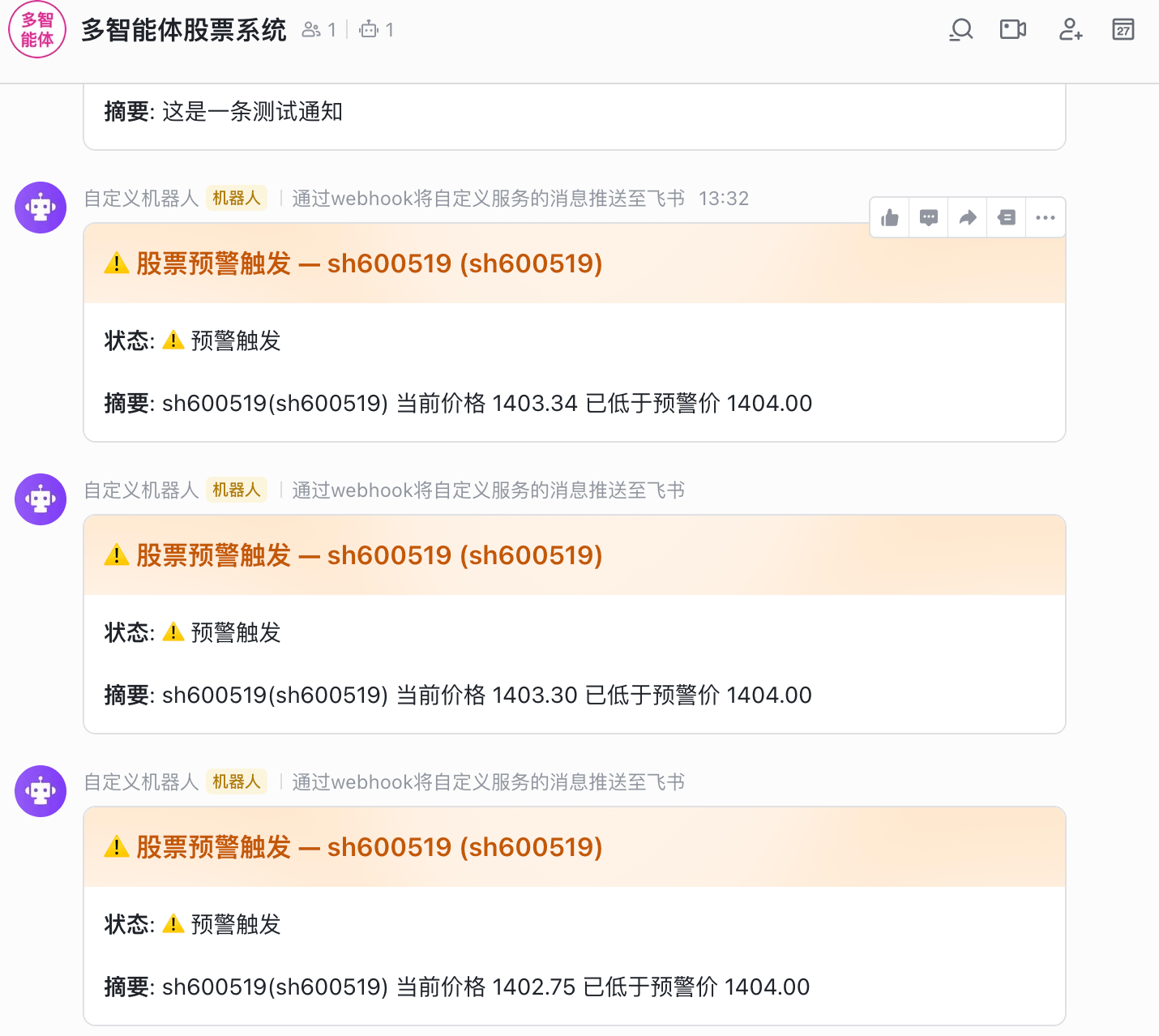
顺便说一下,这是昨天只会 V4-Pro 做的预警通知功能,也已经生效了,对接飞书收到了通知。不过,整个过程,我没有记录,就很难受!
实战二:让 V4-Pro 扫描分析整个项目
这个就简单了,我主要是想验证一下 V4-Pro 的分析质量,顺便看看最后的 Token 消耗。
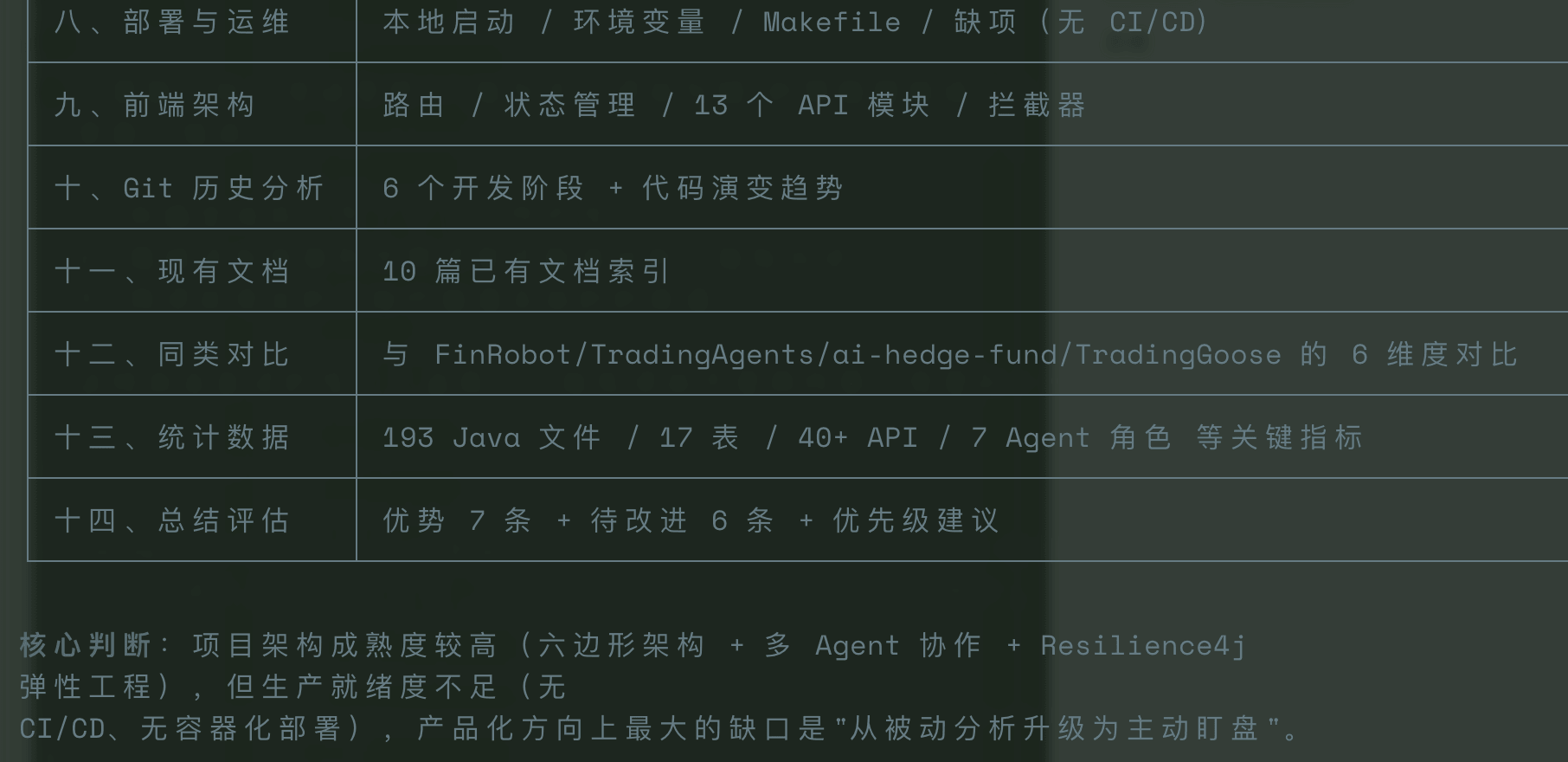
这是 V4-Pro 最终输出的文档,整体质量还是非常高的,很全面:
这是这两个实战所耗费的价钱,大家感受一下如何?一共耗费了 3,957,098 Tokens,接近 400 万。

全行业都在涨,只有 DeepSeek 在降
来看国内云厂商和模型厂商 2026 年的涨价时间线:
| 厂商 | 时间 | 涨价内容 | 幅度 |
|---|---|---|---|
| 百度智能云 | 4 月 18 日 | AI 算力相关产品上调 | 5-30% |
| 腾讯云 | 3 月 11 日 | 部分模型启动正式收费及涨价 | — |
| 腾讯云 | 5 月 9 日(预计) | AI 算力、容器服务、EMR 调整 | — |
| 智谱 | 2 月 12 日 | GLM Coding Plan 结构性调价 | +30% |
| 智谱 | 3 月 16 日 | GLM-5-Turbo API 调价 | +20% |
| 智谱 | 4 月 8 日 | GLM-5.1 API 调价 | +10% |
智谱一年涨了三次,累计涨幅超过 60%。涨完之后,GLM-5.1 在 Coding 场景的缓存命中 token 价格已经接近 Anthropic 的 Claude Sonnet 4.6 水平。
各家涨价的理由基本一样:全球 AI 算力需求激增,核心硬件供应链成本大幅上涨。 这确实是事实——GPU 短缺、电力成本上升、基础设施扩容压力大。
但在同样的行业背景下,DeepSeek 不但没涨,反而在降价。
放到国际舞台上对比,差距更明显。
| 模型 | 输入价格(每百万 token) | 输出价格(每百万 token) |
|---|---|---|
| DeepSeek V4-Pro(特惠) | $0.44 | $0.87 |
| DeepSeek V4-Flash | $0.14 | $0.28 |
| Claude Sonnet 4.6/4.7 | $3.00 | $15.00 |
| Claude Opus 4.6/4.7 | $5.00 | $25.00 |
| GPT-5.5 | $5 | $30.00 |
| GPT-5.5 Pro(加权平均) | ~$30.00 | ~$180.00 |
V4-Pro 特惠价和 GPT-5.5 Pro 相比,输入端差了约 70 倍,输出端差了约 200 倍。和 Claude Sonnet 4.6 比,输出端差了约 17 倍。
当然,纯粹比价格没意义,还得看能力。但 V4-Pro 在 SWE-bench Verified 上拿了 80.6%,Codeforces 评分 3206 排第一,这个实力对应这个价格,性价比确实到位了。我在《从夯爆开始锐评我用过的 AI 编程模型》里把主流编程模型排了个梯队,V4-Pro 的代码能力放在第一梯队旁边,价格却差了两个数量级。
降价背后:昇腾 950 和国产算力
DeepSeek 为什么能逆势降价?官方给出的答案是:国产算力。
V4 系列首次实现了对华为昇腾 NPU 的全面适配。
DeepSeek 在技术论文中披露,细粒度专家并行(EP)方案同时在英伟达 GPU 和昇腾 NPU 上完成了验证。
官方 API 页面明确提到:“受限于高端算力,目前 V4-Pro 的服务吞吐仍有限。预计下半年昇腾 950 超节点批量上市后,Pro 价格会大幅下调。”
所以这次 2.5 折特惠可以理解为一次“压力测试”——在算力受限的情况下先用低价验证市场需求,等下半年国产算力产能上来,这个价位有望常态化。
昇腾 950 批量上市后,DeepSeek 将不再完全依赖英伟达 GPU,算力成本会进一步下降。这也是为什么 DeepSeek 敢在行业涨价潮里逆行的底气——它的成本结构在变,而其他厂商的成本结构在恶化。
实战建议:怎么用最划算
| 场景 | 推荐 | 理由 |
|---|---|---|
| 日常对话、内容生成、简单问答 | V4-Flash | 价格极低,性能足够 |
| Agent Coding、代码重构 | V4-Pro(特惠) | SWE-bench 80.6%,复杂任务成功率高 |
注意: deepseek-chat 和 deepseek-reasoner 将在 7 月 24 日后停用。V4-Flash 直接替代 deepseek-chat,模型名改为 deepseek-v4-flash。尽早切换,迁移零成本,改个模型名就行。
总结
DeepSeek V4 这次降价,放在全行业涨价的背景下看,冲击力很大。但 Guide 建议理性看待几点:
-
短期:2.5 折是限时优惠,5 月 5 日到期。到期后价格大概率会回升,但下半年有再次降价的预期。
-
长期:DeepSeek 的降价底气来自国产算力的崛起。昇腾 950 批量上市后,成本结构会进一步优化。如果国产芯片产能跟上,这个价位有望常态化。
-
选型:Flash 是日常主力,性价比几乎无对手。Pro 在特惠期间是 Agent Coding 的最优选之一,性价比拉满,就是造!

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)