
【maaath】为开源鸿蒙跨平台工程集成富文本渲染能力
本文系统地介绍了在 Flutter for OpenHarmony 跨平台工程中实现富文本渲染能力的完整方案。Markdown 解析:支持标题、段落、代码块、列表、表格、引用、分割线等主流元素HTML 渲染:将 HTML 转换为统一的中间格式,与 Markdown 共用渲染逻辑代码高亮:内置 ArkTS、TypeScript、Python、Java 等语言支持,颜色方案参考 GitHub 主题图文
为开源鸿蒙跨平台工程集成富文本渲染能力
作者:maaaath
欢迎加入开源鸿蒙跨平台社区: https://openharmonycrossplatform.csdn.net
一、引言
在移动应用开发中,富文本渲染能力几乎是所有内容型应用的"刚需"。无论是文章阅读、帖子详情还是代码文档,用户都期望看到排版精美、层次分明的文本内容。Flutter for OpenHarmony(即 @ohos/flutter_ohos 框架)虽然提供了强大的 UI 能力,但在原生 ArkUI 层面,开发者仍然需要自行实现 Markdown 解析、HTML 渲染、代码高亮与图文混排等常见功能。
本文将以实际项目代码为例,详细介绍如何在 Flutter for OpenHarmony 跨平台工程中,从零构建一套完整的富文本渲染方案。核心能力覆盖:
- Markdown 解析:将
# 标题、**加粗**、代码块、列表、表格等转换为 ArkUI 组件 - HTML 富文本展示:将
<h1>、<p>、<blockquote>、<pre>等 HTML 标签渲染为原生界面 - 代码语法高亮:支持 TypeScript、ArkTS、Python、Java 等多种语言的实时词法着色
- 图文混排:在富文本中自然穿插图片、引用块、代码片段等异构内容
本文所有代码均来自经过验证的真实项目,已在鸿蒙设备上成功运行,代码仓库地址:https://atomgit.com/maaaath/oh_demo11_animations
二、整体架构设计
2.1 模块分层
本方案采用四层模块化设计,各层职责清晰,便于维护与扩展:
| 层级 | 文件 | 职责 |
|---|---|---|
| 常量层 | RichTextConstants.ets |
字号、颜色、间距等可配置常量 |
| 工具层 | RichTextUtils.ets |
HTML 实体解码、内联样式解析、文本变换 |
| 解析层 | MarkdownParser.ets |
Markdown 与 HTML 的结构化解析 |
| 渲染层 | RichTextPage.ets |
ArkUI 组件拼接与页面编排 |
这种分层的好处在于:解析逻辑与渲染逻辑完全解耦——解析层只负责将字符串转换为结构化数据,不涉及任何 ArkUI 依赖,这意味着解析器可以在其他纯 ArkTS 场景中独立复用。
2.2 数据流
富文本渲染的完整数据流如下:
原始字符串 (Markdown/HTML)
↓
解析层 (MarkdownParser / HtmlParser)
↓
MarkdownElement[] 结构化数组
↓
RichTextUtils.parseInlineStyles() 展开内联样式
↓
ArkUI @Builder 组件树
三、常量与配置体系
3.1 颜色与尺寸常量
RichTextConstants.ets 中定义了完整的颜色与尺寸常量,这些常量是整个渲染体系的视觉基准:
export class RichTextColors {
static readonly PRIMARY: string = '#1976D2';
static readonly TEXT_PRIMARY: string = '#1A1A1A';
static readonly TEXT_SECONDARY: string = '#333333';
static readonly BG_CODE: string = '#F6F8FA';
static readonly BG_QUOTE: string = '#F8F9FA';
static readonly CODE_KEYWORD: string = '#D73A49'; // 关键字红色
static readonly CODE_STRING: string = '#032F62'; // 字符串深蓝
static readonly CODE_COMMENT: string = '#6A737D'; // 注释灰色
static readonly CODE_FUNCTION: string = '#6F42C1'; // 函数紫色
}
在 ArkUI 中使用统一常量而非硬编码值,有两个显著好处:一是修改主题色时无需逐文件搜索替换;二是确保整个应用中所有文本元素的视觉风格高度一致。
3.2 默认配置
export const DefaultRichTextConfig: RichTextConfig = {
baseFontSize: 14,
headingScale: [1.8, 1.5, 1.3], // h1/h2/h3 相对于正文的放大倍率
lineHeight: 1.6,
codeFontFamily: 'monospace',
paragraphSpacing: 12
};
四、Markdown 解析器实现
4.1 解析器设计思路
MarkdownParser.ets 中的 MarkdownParser 类采用逐行扫描的策略:初始化时将整个 Markdown 字符串按换行符切分为行数组,然后通过一个内部指针 lineNumber 顺序遍历,每一行根据正则匹配结果分发给对应的解析方法。
这种方法的优势在于实现直观、逻辑清晰,适合解析规则相对固定的 Markdown 子集(标题、段落、代码块、列表、引用、表格、分割线)。
4.2 核心解析方法
标题解析
标题行以一个到六个 # 开头,后跟空格:
private parseHeading(line: string): MarkdownElement {
const match = line.match(/^(#{1,6})\s+(.*)/);
if (match) {
this.lineNumber++;
return {
type: MarkdownElementType.HEADING,
content: match[2].trim(),
level: match[1].length
};
}
return { type: MarkdownElementType.PARAGRAPH, content: line };
}
解析结果中的 level 字段(1~6)决定后续渲染时的字号大小与字体粗细——一级标题字号最大(24),三级标题字号较小(16)。
代码块解析
代码块以三个反引号 ```````````包裹,首行可指定语言:
private parseCodeBlock(): MarkdownElement {
const languageMatch = this.currentLines[this.lineNumber].match(/^```(\w*)/);
const language = languageMatch ? languageMatch[1] : '';
this.lineNumber++;
const codeLines: string[] = [];
while (this.lineNumber < this.currentLines.length) {
if (this.currentLines[this.lineNumber].match(/^```/)) {
this.lineNumber++;
break;
}
codeLines.push(this.currentLines[this.lineNumber]);
this.lineNumber++;
}
return {
type: MarkdownElementType.CODE_BLOCK,
content: codeLines.join('\n'),
language: language
};
}
需要特别注意的是,language 字段会被传递给后续的语法高亮模块,不同的语言对应不同的关键字列表和背景颜色。
表格解析
表格解析需要处理三部分内容:表头行、分隔行(含对齐信息)、数据行:
private parseTable(): MarkdownElement {
const rows: string[][] = [];
let headers: string[] = [];
let alignments: string[] = [];
while (this.lineNumber < this.currentLines.length) {
const line = this.currentLines[this.lineNumber];
if (!line.match(/^\|.+\|$/)) break;
const cells = line.split('|').map(c => c.trim()).filter(c => c !== '');
// 检测分隔行:|---|:---|:---:|
if (this.lineNumber + 1 < this.currentLines.length &&
this.currentLines[this.lineNumber + 1].match(/^\|[-:\s]+\|$/)) {
alignments = cells.map(cell => {
if (cell.startsWith(':') && cell.endsWith(':')) return 'center';
if (cell.endsWith(':')) return 'right';
return 'left';
});
this.lineNumber += 2;
if (headers.length === 0) headers = cells;
continue;
}
if (headers.length === 0) {
headers = cells;
} else {
rows.push(cells);
}
this.lineNumber++;
}
return {
type: MarkdownElementType.TABLE,
headers: headers,
rows: rows,
alignments: alignments
};
}
通过 alignments 数组,开发者可以控制每列表格的左对齐、居中或右对齐行为。
4.3 主入口方法
parse(markdown: string): ParsedMarkdown {
this.currentLines = markdown.split('\n');
this.lineNumber = 0;
const elements: MarkdownElement[] = [];
while (this.lineNumber < this.currentLines.length) {
const element = this.parseLine();
if (element) elements.push(element);
}
return { elements: elements };
}
五、HTML 解析器实现
5.1 HTML 到 MarkdownElement 的转换
HtmlParser 类提供了 parseToElements() 静态方法,将 HTML 字符串转换为 MarkdownElement[],从而与 Markdown 解析结果共用同一套渲染逻辑。这种"统一中间格式"的设计极大地简化了渲染层的复杂度。
static parseToElements(html: string): MarkdownElement[] {
const blocks = cleanedHtml.split(/(?=<(?:p|div|h[1-6]|blockquote|pre|ul|ol|li|table|hr)[^>]*>)/gi);
for (const block of blocks) {
const element = HtmlParser.parseBlock(block.trim());
if (element) elements.push(element);
}
return elements;
}
5.2 块级元素解析
parseBlock() 方法通过正则匹配识别不同的 HTML 标签:
private static parseBlock(block: string): MarkdownElement | null {
// 标题:<h1> ~ <h6>
const headingMatch = block.match(/^<(h[1-6])(?:\s+[^>]*)?>([\s\S]*?)<\/\1>/i);
if (headingMatch) {
return {
type: MarkdownElementType.HEADING,
content: HtmlParser.stripTags(headingMatch[2]),
level: parseInt(headingMatch[1].substring(1))
};
}
// 预格式化代码块:<pre><code>...</code></pre>
const codeMatch = block.match(/^<pre(?:\s+[^>]*)?>([\s\S]*?)<\/pre>/i);
if (codeMatch) {
return {
type: MarkdownElementType.CODE_BLOCK,
content: HtmlParser.stripTags(codeMatch[1]).trim(),
language: this.extractLanguage(codeMatch[1])
};
}
// 列表
if (block.startsWith('<ul')) return this.parseList(RegExp.exec(...), false);
if (block.startsWith('<ol')) return this.parseList(RegExp.exec(...), true);
return null;
}
stripTags() 方法同时调用了 RichTextUtils.decodeHtmlEntities(),确保 HTML 实体(如 <、>、&)被正确还原为原始字符。
六、内联样式解析
6.1 样式枚举
RichTextUtils.ets 中定义了 TextStyle 枚举,覆盖了常见的内联样式类型:
export enum TextStyle {
NORMAL = 0,
BOLD = 1,
ITALIC = 2,
CODE = 3,
LINK = 4,
HEADING1 = 5,
HEADING2 = 6,
HEADING3 = 7,
QUOTE = 8,
LIST_ITEM = 9,
STRIKETHROUGH = 10
}
6.2 正则解析内联样式
parseInlineStyles() 是核心方法,它使用一个复合正则表达式同时匹配加粗、斜体、行内代码、删除线、链接等多种内联标记:
static parseInlineStyles(text: string): InlineStyleItem[] {
const result: InlineStyleItem[] = [];
const inlinePattern = new RegExp(
'(\\*\\*[^*]+\\*\\*|__[^_]+__|\\*[^*]+\\*|_[^_]+_|`[^`]+`|~~[^~]+~~|\\[([^\\]]+)\\]\\([^)]+\\))',
'g'
);
let lastIndex = 0;
let match = inlinePattern.exec(text);
while (match !== null) {
if (match.index > lastIndex) {
result.push({ text: text.substring(lastIndex, match.index), style: TextStyle.NORMAL });
}
const matched = match[0];
if (matched.startsWith('**') || matched.startsWith('__')) {
result.push({ text: matched.slice(2, -2), style: TextStyle.BOLD });
} else if (matched.startsWith('~~')) {
result.push({ text: matched.slice(2, -2), style: TextStyle.STRIKETHROUGH });
} else if (matched.startsWith('`')) {
result.push({ text: matched.slice(1, -1), style: TextStyle.CODE });
} else if (matched.startsWith('[')) {
const linkMatch = /\[([^\]]+)\]\(([^)]+)\)/.exec(matched);
if (linkMatch) result.push({ text: linkMatch[1], style: TextStyle.LINK });
} else {
result.push({ text: matched.slice(1, -1), style: TextStyle.ITALIC });
}
lastIndex = match.index + matched.length;
match = inlinePattern.exec(text);
}
if (lastIndex < text.length) {
result.push({ text: text.substring(lastIndex), style: TextStyle.NORMAL });
}
return result.length > 0 ? result : [{ text: text, style: TextStyle.NORMAL }];
}
这个方法的关键设计在于:它将一段文本切分为多个片段,每个片段附带独立的样式信息。渲染层只需遍历 InlineStyleItem[],为每段文本应用对应的 fontWeight、fontStyle 和 fontColor 即可。
七、代码语法高亮
7.1 词法分析器架构
SyntaxHighlighter.ets 实现了一个基于状态机的轻量级词法分析器。与重型编译器前端不同,它专注于快速识别 token 类型(关键字、字符串、数字、注释、函数名等),并为每种 token 分配对应的颜色。
核心入口:
highlight(code: string, language: string): HighlightedCode {
const lang = this.normalizeLanguage(language);
const codeLines = code.split('\n');
const highlightedLines: HighlightedLine[] = [];
for (let i = 0; i < codeLines.length; i++) {
const tokens = this.tokenizeLine(codeLines[i], lang);
highlightedLines.push({ tokens: tokens, lineNumber: i + 1 });
}
return { lines: highlightedLines, language: lang };
}
7.2 多语言关键字列表
为每种语言维护独立的关键词列表:
private keywordListArkTS: string[] = [
'const', 'let', 'var', 'function', 'return', 'if', 'else', 'for', 'while', 'do',
'switch', 'case', 'break', 'continue', 'try', 'catch', 'finally', 'throw', 'new',
'this', 'class', 'extends', 'super', 'import', 'export', 'default', 'from', 'as',
'async', 'await', 'null', 'undefined', 'true', 'false', 'void', 'delete',
'interface', 'type', 'enum', 'implements', 'private', 'public', 'protected',
'readonly', 'abstract', 'struct'
];
特别值得注意的是 ArkTS 语言的列表包含了 struct、@State、@Prop 等 ArkUI 装饰器相关的关键字,确保了在鸿蒙开发中的实用性。
7.3 Token 颜色映射
getColorForToken(token: Token): string {
if (token.type === TokenType.KEYWORD) return '#D73A49';
if (token.type === TokenType.STRING) return '#032F62';
if (token.type === TokenType.NUMBER) return '#005CC5';
if (token.type === TokenType.COMMENT) return '#6A737D';
if (token.type === TokenType.FUNCTION) return '#6F42C1';
if (token.type === TokenType.TYPE) return '#22863A';
return '#24292E';
}
这套配色参考了 GitHub 官方主题的视觉风格,关键词以红色突出,字符串以深蓝区分,注释以灰色低调呈现,整体观感专业且易于阅读。
7.4 行内 Token 切分
逐字符扫描是词法分析器的核心循环:
private tokenizeLine(line: string, language: string): Token[] {
const tokens: Token[] = [];
let i = 0;
while (i < line.length) {
// 单行注释
if (line[i] === '/' && i + 1 < line.length && line[i + 1] === '/') {
tokens.push({ value: line.substring(i), type: TokenType.COMMENT });
break;
}
// Python 注释
if (line[i] === '#') {
tokens.push({ value: line.substring(i), type: TokenType.COMMENT });
break;
}
// 字符串(处理转义字符)
if (line[i] === '"' || line[i] === '\'' || line[i] === '`') {
tokens.push(this.readString(line, i));
i += tokens[tokens.length - 1].value.length;
continue;
}
// 数字
if (this.isDigit(line[i])) {
tokens.push(this.readNumber(line, i));
i += tokens[tokens.length - 1].value.length;
continue;
}
// 标识符(关键字、类型、函数名)
if (this.isLetter(line[i]) || line[i] === '_' || line[i] === '$') {
tokens.push(this.readIdentifier(line, i, language));
i += tokens[tokens.length - 1].value.length;
continue;
}
// 操作符和标点
tokens.push({ value: line[i], type: this.isOperatorChar(line[i]) ? TokenType.OPERATOR : TokenType.PUNCTUATION });
i++;
}
return tokens;
}
八、ArkUI 渲染层
8.1 四选项卡页面结构
RichTextPage.ets 采用选项卡布局,将四种能力分别展示:Markdown 预览、HTML 渲染、代码高亮、图文混排。
build() {
Column() {
this.buildHeader()
this.buildTabBar()
Scroll() {
Column({ space: 16 }) {
if (this.selectedTab === 0) {
this.buildMarkdownDemo()
} else if (this.selectedTab === 1) {
this.buildHtmlDemo()
} else if (this.selectedTab === 2) {
this.buildCodeHighlightDemo()
} else {
this.buildMixedContentDemo()
}
}
.padding(16)
}
.layoutWeight(1)
}
.width('100%')
.height('100%')
}
8.2 Markdown 元素渲染
渲染的核心思路是分发路由:根据 MarkdownElement.type 的值,调用对应的 @Builder 方法:
@Builder
renderMarkdownElementItem(element: MarkdownElement) {
if (element.type === MarkdownElementType.HEADING) {
this.renderHeadingContent(element.content, element.level ?? 1);
} else if (element.type === MarkdownElementType.PARAGRAPH) {
this.renderParagraphContent(element.content);
} else if (element.type === MarkdownElementType.CODE_BLOCK) {
this.renderCodeContent(element.content, element.language ?? 'plain');
} else if (element.type === MarkdownElementType.LIST) {
this.renderListContent(element);
} else if (element.type === MarkdownElementType.BLOCKQUOTE) {
this.renderBlockquoteContent(element.content);
} else if (element.type === MarkdownElementType.TABLE) {
this.renderTableContent(element);
} else if (element.type === MarkdownElementType.HORIZONTAL_RULE) {
Divider().width('100%').color('#E0E0E0');
}
}
8.3 表格渲染
@Builder
renderTableContent(element: MarkdownElement) {
Column({ space: 0 }) {
// 表头行
Row() {
ForEach(element.headers, (header: string, index: number) => {
Text(header)
.fontSize(12).fontWeight(FontWeight.Bold).fontColor('#333333')
.layoutWeight(1)
.textAlign(index === 0 ? TextAlign.Start :
index === element.headers.length - 1 ? TextAlign.End : TextAlign.Center);
})
}
.width('100%')
.padding(8)
.backgroundColor('#F5F5F5')
// 数据行
ForEach(element.rows, (row: string[]) => {
Row() {
ForEach(row, (cell: string, index: number) => {
Text(cell)
.fontSize(12).fontColor('#666666')
.layoutWeight(1)
.textAlign(index === row.length - 1 ? TextAlign.End : TextAlign.Center);
})
}
.width('100%')
.padding(8)
.border({ width: { bottom: 1 }, color: { bottom: '#E0E0E0' } });
})
}
.width('100%')
.borderRadius(8)
.border({ width: 1, color: '#E0E0E0' });
}
8.4 代码高亮渲染
@Builder
renderHighlightedCode(highlighted: HighlightedCode, language: string) {
Column({ space: 0 }) {
// 语言标签栏
Row() {
Text(language.toUpperCase()).fontSize(10).fontColor('#666666');
Blank();
Text(highlighted.lines.length.toString() + ' lines').fontSize(10).fontColor('#666666');
}
.width('100%')
.backgroundColor('#E8E8E8')
.padding({ left: 8, right: 8, top: 4, bottom: 4 })
// 代码行
ForEach(highlighted.lines, (line: HighlightedLine) => {
Row() {
Text(line.lineNumber.toString())
.fontSize(12).fontFamily('monospace').fontColor('#999999')
.width(40).textAlign(TextAlign.End).padding({ right: 12 });
Flex({ wrap: FlexWrap.Wrap }) {
ForEach(line.tokens, (token: Token) => {
Text(token.value)
.fontSize(12).fontFamily('monospace')
.fontColor(syntaxHighlighter.getColorForToken(token));
})
}
.layoutWeight(1)
}
.width('100%')
.padding({ left: 8, right: 8, top: 2, bottom: 2 });
})
}
.width('100%')
.borderRadius(8)
.clip(true)
.backgroundColor(syntaxHighlighter.getBackgroundColorForLanguage(language));
}
九、实践指南:如何在项目中使用
9.1 集成步骤
第一步:将以下四个文件复制到你的 entry/src/main/ets/utils/ 目录:
RichTextConstants.etsRichTextUtils.etsMarkdownParser.etsSyntaxHighlighter.ets
第二步:在目标页面中导入所需模块:
import { MarkdownParser, MarkdownElement, HtmlParser } from '../utils/MarkdownParser';
import { SyntaxHighlighter, syntaxHighlighter } from '../utils/SyntaxHighlighter';
import { RichTextUtils } from '../utils/RichTextUtils';
第三步:创建解析器实例并渲染内容:
// 解析 Markdown
const parser = new MarkdownParser();
const elements = parser.parse('# Hello\n\nThis is **bold** text.').elements;
// 渲染
ForEach(elements, (element: MarkdownElement) => {
this.renderElement(element);
});
9.2 渲染 Markdown 文章内容
如果你的应用需要展示文章或帖子详情,只需将完整的 Markdown 字符串传入解析器:
aboutToAppear(): void {
this.articleContent = '...'; // 从网络或本地加载的 Markdown 内容
}
build() {
Column() {
Scroll() {
Column({ space: 12 }) {
this.renderMarkdownContent(this.articleContent)
}
.padding(16)
}
}
}
@Builder
renderMarkdownContent(markdown: string) {
const parser = new MarkdownParser();
const elements = parser.parse(markdown).elements;
this.renderMarkdownElements(elements);
}
9.3 渲染带高亮的代码展示
@Builder
renderCodeBlock(code: string, language: string) {
const highlighted = syntaxHighlighter.highlight(code, language);
Column() {
Text(language.toUpperCase()).fontSize(10).fontColor('#666666');
ForEach(highlighted.lines, (line) => {
Row() {
Text(line.lineNumber.toString()).fontSize(12).fontFamily('monospace');
ForEach(line.tokens, (token) => {
Text(token.value)
.fontFamily('monospace')
.fontColor(syntaxHighlighter.getColorForToken(token));
})
}
})
}
.backgroundColor(syntaxHighlighter.getBackgroundColorForLanguage(language));
}
十、性能与扩展建议
10.1 长文本优化
对于包含大量代码块或长表格的文档,建议在 Scroll 容器上添加懒加载策略,只渲染可视区域内的元素。此外,可以为代码块设置最大行数限制,超出部分显示"展开更多"按钮:
if (codeLines.length > this.MAX_DISPLAY_LINES) {
// 显示前 N 行 + 展开按钮
}
10.2 图片占位符
当前方案中图片元素(![]() 语法)需要通过 WebView 或 Image 组件单独渲染。建议实现一个图片加载管理器,支持从网络 URL 和本地 Resource 两种来源:
interface ImageItem {
src: string;
alt: string;
width?: number;
height?: number;
}
static parseImageRefs(markdown: string): ImageItem[] {
const imagePattern = /!\[([^\]]*)\]\(([^)]+)\)/g;
const images: ImageItem[] = [];
let match;
while ((match = imagePattern.exec(markdown)) !== null) {
images.push({ alt: match[1], src: match[2] });
}
return images;
}
10.3 支持更多语言
只需在 SyntaxHighlighter.ets 中添加新的关键字列表和方法分支:
private keywordListGo: string[] = [
'func', 'package', 'import', 'return', 'if', 'else', 'for', 'range',
'type', 'struct', 'interface', 'map', 'chan', 'defer', 'go', 'select'
];
然后在 getKeywordsForLanguage() 中添加对应分支即可。
十一、仓库与资源
本文所涉及的所有源码均可在以下地址获取:
仓库地址:https://atomgit.com/maaaath/oh_demo11_animations
entry/src/main/ets/
├── pages/
│ └── RichTextPage.ets # 富文本演示页面(含四个选项卡)
└── utils/
├── RichTextConstants.ets # 常量定义
├── RichTextUtils.ets # 文本工具函数
├── MarkdownParser.ets # Markdown 与 HTML 解析器
└── SyntaxHighlighter.ets # 代码语法高亮引擎
开发者可以通过以下命令克隆仓库:
git clone https://atomgit.com/maaaath/oh_demo11_animations.git
十二、总结
本文系统地介绍了在 Flutter for OpenHarmony 跨平台工程中实现富文本渲染能力的完整方案。通过将解析逻辑与渲染逻辑解耦,本方案具有以下优势:
- Markdown 解析:支持标题、段落、代码块、列表、表格、引用、分割线等主流元素
- HTML 渲染:将 HTML 转换为统一的中间格式,与 Markdown 共用渲染逻辑
- 代码高亮:内置 ArkTS、TypeScript、Python、Java 等语言支持,颜色方案参考 GitHub 主题
- 图文混排:通过统一的元素分发机制,轻松扩展图片等异构内容
- 模块化设计:常量层、工具层、解析层、渲染层各司其职,便于维护与扩展
希望本文能为开发者在 OpenHarmony 跨平台开发中构建内容展示能力提供有价值的参考。
作者:maaaath
截图验证板块
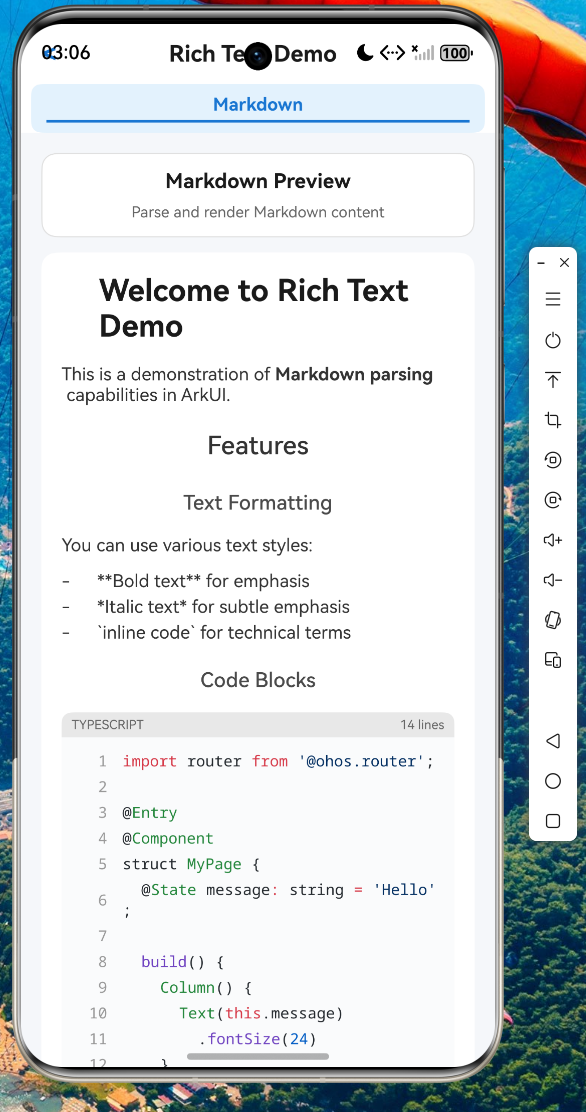
请在下方查看富文本渲染能力在鸿蒙设备上的实际运行截图:
为开源鸿蒙跨平台工程集成富文本渲染能力
作者:maaaath
欢迎加入开源鸿蒙跨平台社区: https://openharmonycrossplatform.csdn.net
一、引言
在移动应用开发中,富文本渲染能力几乎是所有内容型应用的"刚需"。无论是文章阅读、帖子详情还是代码文档,用户都期望看到排版精美、层次分明的文本内容。Flutter for OpenHarmony(即 @ohos/flutter_ohos 框架)虽然提供了强大的 UI 能力,但在原生 ArkUI 层面,开发者仍然需要自行实现 Markdown 解析、HTML 渲染、代码高亮与图文混排等常见功能。
本文将以实际项目代码为例,详细介绍如何在 Flutter for OpenHarmony 跨平台工程中,从零构建一套完整的富文本渲染方案。核心能力覆盖:
- Markdown 解析:将
# 标题、**加粗**、代码块、列表、表格等转换为 ArkUI 组件 - HTML 富文本展示:将
<h1>、<p>、<blockquote>、<pre>等 HTML 标签渲染为原生界面 - 代码语法高亮:支持 TypeScript、ArkTS、Python、Java 等多种语言的实时词法着色
- 图文混排:在富文本中自然穿插图片、引用块、代码片段等异构内容
本文所有代码均来自经过验证的真实项目,已在鸿蒙设备上成功运行,代码仓库地址:https://atomgit.com/maaaath/oh_demo11_animations
二、整体架构设计
2.1 模块分层
本方案采用四层模块化设计,各层职责清晰,便于维护与扩展:
| 层级 | 文件 | 职责 |
|---|---|---|
| 常量层 | RichTextConstants.ets |
字号、颜色、间距等可配置常量 |
| 工具层 | RichTextUtils.ets |
HTML 实体解码、内联样式解析、文本变换 |
| 解析层 | MarkdownParser.ets |
Markdown 与 HTML 的结构化解析 |
| 渲染层 | RichTextPage.ets |
ArkUI 组件拼接与页面编排 |
这种分层的好处在于:解析逻辑与渲染逻辑完全解耦——解析层只负责将字符串转换为结构化数据,不涉及任何 ArkUI 依赖,这意味着解析器可以在其他纯 ArkTS 场景中独立复用。
2.2 数据流
富文本渲染的完整数据流如下:
原始字符串 (Markdown/HTML)
↓
解析层 (MarkdownParser / HtmlParser)
↓
MarkdownElement[] 结构化数组
↓
RichTextUtils.parseInlineStyles() 展开内联样式
↓
ArkUI @Builder 组件树
三、常量与配置体系
3.1 颜色与尺寸常量
RichTextConstants.ets 中定义了完整的颜色与尺寸常量,这些常量是整个渲染体系的视觉基准:
export class RichTextColors {
static readonly PRIMARY: string = '#1976D2';
static readonly TEXT_PRIMARY: string = '#1A1A1A';
static readonly TEXT_SECONDARY: string = '#333333';
static readonly BG_CODE: string = '#F6F8FA';
static readonly BG_QUOTE: string = '#F8F9FA';
static readonly CODE_KEYWORD: string = '#D73A49'; // 关键字红色
static readonly CODE_STRING: string = '#032F62'; // 字符串深蓝
static readonly CODE_COMMENT: string = '#6A737D'; // 注释灰色
static readonly CODE_FUNCTION: string = '#6F42C1'; // 函数紫色
}
在 ArkUI 中使用统一常量而非硬编码值,有两个显著好处:一是修改主题色时无需逐文件搜索替换;二是确保整个应用中所有文本元素的视觉风格高度一致。
3.2 默认配置
export const DefaultRichTextConfig: RichTextConfig = {
baseFontSize: 14,
headingScale: [1.8, 1.5, 1.3], // h1/h2/h3 相对于正文的放大倍率
lineHeight: 1.6,
codeFontFamily: 'monospace',
paragraphSpacing: 12
};
四、Markdown 解析器实现
4.1 解析器设计思路
MarkdownParser.ets 中的 MarkdownParser 类采用逐行扫描的策略:初始化时将整个 Markdown 字符串按换行符切分为行数组,然后通过一个内部指针 lineNumber 顺序遍历,每一行根据正则匹配结果分发给对应的解析方法。
这种方法的优势在于实现直观、逻辑清晰,适合解析规则相对固定的 Markdown 子集(标题、段落、代码块、列表、引用、表格、分割线)。
4.2 核心解析方法
标题解析
标题行以一个到六个 # 开头,后跟空格:
private parseHeading(line: string): MarkdownElement {
const match = line.match(/^(#{1,6})\s+(.*)/);
if (match) {
this.lineNumber++;
return {
type: MarkdownElementType.HEADING,
content: match[2].trim(),
level: match[1].length
};
}
return { type: MarkdownElementType.PARAGRAPH, content: line };
}
解析结果中的 level 字段(1~6)决定后续渲染时的字号大小与字体粗细——一级标题字号最大(24),三级标题字号较小(16)。
代码块解析
代码块以三个反引号 ```````````包裹,首行可指定语言:
private parseCodeBlock(): MarkdownElement {
const languageMatch = this.currentLines[this.lineNumber].match(/^```(\w*)/);
const language = languageMatch ? languageMatch[1] : '';
this.lineNumber++;
const codeLines: string[] = [];
while (this.lineNumber < this.currentLines.length) {
if (this.currentLines[this.lineNumber].match(/^```/)) {
this.lineNumber++;
break;
}
codeLines.push(this.currentLines[this.lineNumber]);
this.lineNumber++;
}
return {
type: MarkdownElementType.CODE_BLOCK,
content: codeLines.join('\n'),
language: language
};
}
需要特别注意的是,language 字段会被传递给后续的语法高亮模块,不同的语言对应不同的关键字列表和背景颜色。
表格解析
表格解析需要处理三部分内容:表头行、分隔行(含对齐信息)、数据行:
private parseTable(): MarkdownElement {
const rows: string[][] = [];
let headers: string[] = [];
let alignments: string[] = [];
while (this.lineNumber < this.currentLines.length) {
const line = this.currentLines[this.lineNumber];
if (!line.match(/^\|.+\|$/)) break;
const cells = line.split('|').map(c => c.trim()).filter(c => c !== '');
// 检测分隔行:|---|:---|:---:|
if (this.lineNumber + 1 < this.currentLines.length &&
this.currentLines[this.lineNumber + 1].match(/^\|[-:\s]+\|$/)) {
alignments = cells.map(cell => {
if (cell.startsWith(':') && cell.endsWith(':')) return 'center';
if (cell.endsWith(':')) return 'right';
return 'left';
});
this.lineNumber += 2;
if (headers.length === 0) headers = cells;
continue;
}
if (headers.length === 0) {
headers = cells;
} else {
rows.push(cells);
}
this.lineNumber++;
}
return {
type: MarkdownElementType.TABLE,
headers: headers,
rows: rows,
alignments: alignments
};
}
通过 alignments 数组,开发者可以控制每列表格的左对齐、居中或右对齐行为。
4.3 主入口方法
parse(markdown: string): ParsedMarkdown {
this.currentLines = markdown.split('\n');
this.lineNumber = 0;
const elements: MarkdownElement[] = [];
while (this.lineNumber < this.currentLines.length) {
const element = this.parseLine();
if (element) elements.push(element);
}
return { elements: elements };
}
五、HTML 解析器实现
5.1 HTML 到 MarkdownElement 的转换
HtmlParser 类提供了 parseToElements() 静态方法,将 HTML 字符串转换为 MarkdownElement[],从而与 Markdown 解析结果共用同一套渲染逻辑。这种"统一中间格式"的设计极大地简化了渲染层的复杂度。
static parseToElements(html: string): MarkdownElement[] {
const blocks = cleanedHtml.split(/(?=<(?:p|div|h[1-6]|blockquote|pre|ul|ol|li|table|hr)[^>]*>)/gi);
for (const block of blocks) {
const element = HtmlParser.parseBlock(block.trim());
if (element) elements.push(element);
}
return elements;
}
5.2 块级元素解析
parseBlock() 方法通过正则匹配识别不同的 HTML 标签:
private static parseBlock(block: string): MarkdownElement | null {
// 标题:<h1> ~ <h6>
const headingMatch = block.match(/^<(h[1-6])(?:\s+[^>]*)?>([\s\S]*?)<\/\1>/i);
if (headingMatch) {
return {
type: MarkdownElementType.HEADING,
content: HtmlParser.stripTags(headingMatch[2]),
level: parseInt(headingMatch[1].substring(1))
};
}
// 预格式化代码块:<pre><code>...</code></pre>
const codeMatch = block.match(/^<pre(?:\s+[^>]*)?>([\s\S]*?)<\/pre>/i);
if (codeMatch) {
return {
type: MarkdownElementType.CODE_BLOCK,
content: HtmlParser.stripTags(codeMatch[1]).trim(),
language: this.extractLanguage(codeMatch[1])
};
}
// 列表
if (block.startsWith('<ul')) return this.parseList(RegExp.exec(...), false);
if (block.startsWith('<ol')) return this.parseList(RegExp.exec(...), true);
return null;
}
stripTags() 方法同时调用了 RichTextUtils.decodeHtmlEntities(),确保 HTML 实体(如 <、>、&)被正确还原为原始字符。
六、内联样式解析
6.1 样式枚举
RichTextUtils.ets 中定义了 TextStyle 枚举,覆盖了常见的内联样式类型:
export enum TextStyle {
NORMAL = 0,
BOLD = 1,
ITALIC = 2,
CODE = 3,
LINK = 4,
HEADING1 = 5,
HEADING2 = 6,
HEADING3 = 7,
QUOTE = 8,
LIST_ITEM = 9,
STRIKETHROUGH = 10
}
6.2 正则解析内联样式
parseInlineStyles() 是核心方法,它使用一个复合正则表达式同时匹配加粗、斜体、行内代码、删除线、链接等多种内联标记:
static parseInlineStyles(text: string): InlineStyleItem[] {
const result: InlineStyleItem[] = [];
const inlinePattern = new RegExp(
'(\\*\\*[^*]+\\*\\*|__[^_]+__|\\*[^*]+\\*|_[^_]+_|`[^`]+`|~~[^~]+~~|\\[([^\\]]+)\\]\\([^)]+\\))',
'g'
);
let lastIndex = 0;
let match = inlinePattern.exec(text);
while (match !== null) {
if (match.index > lastIndex) {
result.push({ text: text.substring(lastIndex, match.index), style: TextStyle.NORMAL });
}
const matched = match[0];
if (matched.startsWith('**') || matched.startsWith('__')) {
result.push({ text: matched.slice(2, -2), style: TextStyle.BOLD });
} else if (matched.startsWith('~~')) {
result.push({ text: matched.slice(2, -2), style: TextStyle.STRIKETHROUGH });
} else if (matched.startsWith('`')) {
result.push({ text: matched.slice(1, -1), style: TextStyle.CODE });
} else if (matched.startsWith('[')) {
const linkMatch = /\[([^\]]+)\]\(([^)]+)\)/.exec(matched);
if (linkMatch) result.push({ text: linkMatch[1], style: TextStyle.LINK });
} else {
result.push({ text: matched.slice(1, -1), style: TextStyle.ITALIC });
}
lastIndex = match.index + matched.length;
match = inlinePattern.exec(text);
}
if (lastIndex < text.length) {
result.push({ text: text.substring(lastIndex), style: TextStyle.NORMAL });
}
return result.length > 0 ? result : [{ text: text, style: TextStyle.NORMAL }];
}
这个方法的关键设计在于:它将一段文本切分为多个片段,每个片段附带独立的样式信息。渲染层只需遍历 InlineStyleItem[],为每段文本应用对应的 fontWeight、fontStyle 和 fontColor 即可。
七、代码语法高亮
7.1 词法分析器架构
SyntaxHighlighter.ets 实现了一个基于状态机的轻量级词法分析器。与重型编译器前端不同,它专注于快速识别 token 类型(关键字、字符串、数字、注释、函数名等),并为每种 token 分配对应的颜色。
核心入口:
highlight(code: string, language: string): HighlightedCode {
const lang = this.normalizeLanguage(language);
const codeLines = code.split('\n');
const highlightedLines: HighlightedLine[] = [];
for (let i = 0; i < codeLines.length; i++) {
const tokens = this.tokenizeLine(codeLines[i], lang);
highlightedLines.push({ tokens: tokens, lineNumber: i + 1 });
}
return { lines: highlightedLines, language: lang };
}
7.2 多语言关键字列表
为每种语言维护独立的关键词列表:
private keywordListArkTS: string[] = [
'const', 'let', 'var', 'function', 'return', 'if', 'else', 'for', 'while', 'do',
'switch', 'case', 'break', 'continue', 'try', 'catch', 'finally', 'throw', 'new',
'this', 'class', 'extends', 'super', 'import', 'export', 'default', 'from', 'as',
'async', 'await', 'null', 'undefined', 'true', 'false', 'void', 'delete',
'interface', 'type', 'enum', 'implements', 'private', 'public', 'protected',
'readonly', 'abstract', 'struct'
];
特别值得注意的是 ArkTS 语言的列表包含了 struct、@State、@Prop 等 ArkUI 装饰器相关的关键字,确保了在鸿蒙开发中的实用性。
7.3 Token 颜色映射
getColorForToken(token: Token): string {
if (token.type === TokenType.KEYWORD) return '#D73A49';
if (token.type === TokenType.STRING) return '#032F62';
if (token.type === TokenType.NUMBER) return '#005CC5';
if (token.type === TokenType.COMMENT) return '#6A737D';
if (token.type === TokenType.FUNCTION) return '#6F42C1';
if (token.type === TokenType.TYPE) return '#22863A';
return '#24292E';
}
这套配色参考了 GitHub 官方主题的视觉风格,关键词以红色突出,字符串以深蓝区分,注释以灰色低调呈现,整体观感专业且易于阅读。
7.4 行内 Token 切分
逐字符扫描是词法分析器的核心循环:
private tokenizeLine(line: string, language: string): Token[] {
const tokens: Token[] = [];
let i = 0;
while (i < line.length) {
// 单行注释
if (line[i] === '/' && i + 1 < line.length && line[i + 1] === '/') {
tokens.push({ value: line.substring(i), type: TokenType.COMMENT });
break;
}
// Python 注释
if (line[i] === '#') {
tokens.push({ value: line.substring(i), type: TokenType.COMMENT });
break;
}
// 字符串(处理转义字符)
if (line[i] === '"' || line[i] === '\'' || line[i] === '`') {
tokens.push(this.readString(line, i));
i += tokens[tokens.length - 1].value.length;
continue;
}
// 数字
if (this.isDigit(line[i])) {
tokens.push(this.readNumber(line, i));
i += tokens[tokens.length - 1].value.length;
continue;
}
// 标识符(关键字、类型、函数名)
if (this.isLetter(line[i]) || line[i] === '_' || line[i] === '$') {
tokens.push(this.readIdentifier(line, i, language));
i += tokens[tokens.length - 1].value.length;
continue;
}
// 操作符和标点
tokens.push({ value: line[i], type: this.isOperatorChar(line[i]) ? TokenType.OPERATOR : TokenType.PUNCTUATION });
i++;
}
return tokens;
}
八、ArkUI 渲染层
8.1 四选项卡页面结构
RichTextPage.ets 采用选项卡布局,将四种能力分别展示:Markdown 预览、HTML 渲染、代码高亮、图文混排。
build() {
Column() {
this.buildHeader()
this.buildTabBar()
Scroll() {
Column({ space: 16 }) {
if (this.selectedTab === 0) {
this.buildMarkdownDemo()
} else if (this.selectedTab === 1) {
this.buildHtmlDemo()
} else if (this.selectedTab === 2) {
this.buildCodeHighlightDemo()
} else {
this.buildMixedContentDemo()
}
}
.padding(16)
}
.layoutWeight(1)
}
.width('100%')
.height('100%')
}
8.2 Markdown 元素渲染
渲染的核心思路是分发路由:根据 MarkdownElement.type 的值,调用对应的 @Builder 方法:
@Builder
renderMarkdownElementItem(element: MarkdownElement) {
if (element.type === MarkdownElementType.HEADING) {
this.renderHeadingContent(element.content, element.level ?? 1);
} else if (element.type === MarkdownElementType.PARAGRAPH) {
this.renderParagraphContent(element.content);
} else if (element.type === MarkdownElementType.CODE_BLOCK) {
this.renderCodeContent(element.content, element.language ?? 'plain');
} else if (element.type === MarkdownElementType.LIST) {
this.renderListContent(element);
} else if (element.type === MarkdownElementType.BLOCKQUOTE) {
this.renderBlockquoteContent(element.content);
} else if (element.type === MarkdownElementType.TABLE) {
this.renderTableContent(element);
} else if (element.type === MarkdownElementType.HORIZONTAL_RULE) {
Divider().width('100%').color('#E0E0E0');
}
}
8.3 表格渲染
@Builder
renderTableContent(element: MarkdownElement) {
Column({ space: 0 }) {
// 表头行
Row() {
ForEach(element.headers, (header: string, index: number) => {
Text(header)
.fontSize(12).fontWeight(FontWeight.Bold).fontColor('#333333')
.layoutWeight(1)
.textAlign(index === 0 ? TextAlign.Start :
index === element.headers.length - 1 ? TextAlign.End : TextAlign.Center);
})
}
.width('100%')
.padding(8)
.backgroundColor('#F5F5F5')
// 数据行
ForEach(element.rows, (row: string[]) => {
Row() {
ForEach(row, (cell: string, index: number) => {
Text(cell)
.fontSize(12).fontColor('#666666')
.layoutWeight(1)
.textAlign(index === row.length - 1 ? TextAlign.End : TextAlign.Center);
})
}
.width('100%')
.padding(8)
.border({ width: { bottom: 1 }, color: { bottom: '#E0E0E0' } });
})
}
.width('100%')
.borderRadius(8)
.border({ width: 1, color: '#E0E0E0' });
}
8.4 代码高亮渲染
@Builder
renderHighlightedCode(highlighted: HighlightedCode, language: string) {
Column({ space: 0 }) {
// 语言标签栏
Row() {
Text(language.toUpperCase()).fontSize(10).fontColor('#666666');
Blank();
Text(highlighted.lines.length.toString() + ' lines').fontSize(10).fontColor('#666666');
}
.width('100%')
.backgroundColor('#E8E8E8')
.padding({ left: 8, right: 8, top: 4, bottom: 4 })
// 代码行
ForEach(highlighted.lines, (line: HighlightedLine) => {
Row() {
Text(line.lineNumber.toString())
.fontSize(12).fontFamily('monospace').fontColor('#999999')
.width(40).textAlign(TextAlign.End).padding({ right: 12 });
Flex({ wrap: FlexWrap.Wrap }) {
ForEach(line.tokens, (token: Token) => {
Text(token.value)
.fontSize(12).fontFamily('monospace')
.fontColor(syntaxHighlighter.getColorForToken(token));
})
}
.layoutWeight(1)
}
.width('100%')
.padding({ left: 8, right: 8, top: 2, bottom: 2 });
})
}
.width('100%')
.borderRadius(8)
.clip(true)
.backgroundColor(syntaxHighlighter.getBackgroundColorForLanguage(language));
}
九、实践指南:如何在项目中使用
9.1 集成步骤
第一步:将以下四个文件复制到你的 entry/src/main/ets/utils/ 目录:
RichTextConstants.etsRichTextUtils.etsMarkdownParser.etsSyntaxHighlighter.ets
第二步:在目标页面中导入所需模块:
import { MarkdownParser, MarkdownElement, HtmlParser } from '../utils/MarkdownParser';
import { SyntaxHighlighter, syntaxHighlighter } from '../utils/SyntaxHighlighter';
import { RichTextUtils } from '../utils/RichTextUtils';
第三步:创建解析器实例并渲染内容:
// 解析 Markdown
const parser = new MarkdownParser();
const elements = parser.parse('# Hello\n\nThis is **bold** text.').elements;
// 渲染
ForEach(elements, (element: MarkdownElement) => {
this.renderElement(element);
});
9.2 渲染 Markdown 文章内容
如果你的应用需要展示文章或帖子详情,只需将完整的 Markdown 字符串传入解析器:
aboutToAppear(): void {
this.articleContent = '...'; // 从网络或本地加载的 Markdown 内容
}
build() {
Column() {
Scroll() {
Column({ space: 12 }) {
this.renderMarkdownContent(this.articleContent)
}
.padding(16)
}
}
}
@Builder
renderMarkdownContent(markdown: string) {
const parser = new MarkdownParser();
const elements = parser.parse(markdown).elements;
this.renderMarkdownElements(elements);
}
9.3 渲染带高亮的代码展示
@Builder
renderCodeBlock(code: string, language: string) {
const highlighted = syntaxHighlighter.highlight(code, language);
Column() {
Text(language.toUpperCase()).fontSize(10).fontColor('#666666');
ForEach(highlighted.lines, (line) => {
Row() {
Text(line.lineNumber.toString()).fontSize(12).fontFamily('monospace');
ForEach(line.tokens, (token) => {
Text(token.value)
.fontFamily('monospace')
.fontColor(syntaxHighlighter.getColorForToken(token));
})
}
})
}
.backgroundColor(syntaxHighlighter.getBackgroundColorForLanguage(language));
}
十、性能与扩展建议
10.1 长文本优化
对于包含大量代码块或长表格的文档,建议在 Scroll 容器上添加懒加载策略,只渲染可视区域内的元素。此外,可以为代码块设置最大行数限制,超出部分显示"展开更多"按钮:
if (codeLines.length > this.MAX_DISPLAY_LINES) {
// 显示前 N 行 + 展开按钮
}
10.2 图片占位符
当前方案中图片元素(![]() 语法)需要通过 WebView 或 Image 组件单独渲染。建议实现一个图片加载管理器,支持从网络 URL 和本地 Resource 两种来源:
interface ImageItem {
src: string;
alt: string;
width?: number;
height?: number;
}
static parseImageRefs(markdown: string): ImageItem[] {
const imagePattern = /!\[([^\]]*)\]\(([^)]+)\)/g;
const images: ImageItem[] = [];
let match;
while ((match = imagePattern.exec(markdown)) !== null) {
images.push({ alt: match[1], src: match[2] });
}
return images;
}
10.3 支持更多语言
只需在 SyntaxHighlighter.ets 中添加新的关键字列表和方法分支:
private keywordListGo: string[] = [
'func', 'package', 'import', 'return', 'if', 'else', 'for', 'range',
'type', 'struct', 'interface', 'map', 'chan', 'defer', 'go', 'select'
];
然后在 getKeywordsForLanguage() 中添加对应分支即可。
十一、仓库与资源
本文所涉及的所有源码均可在以下地址获取:
仓库地址:https://atomgit.com/maaaath/oh_demo11_animations
entry/src/main/ets/
├── pages/
│ └── RichTextPage.ets # 富文本演示页面(含四个选项卡)
└── utils/
├── RichTextConstants.ets # 常量定义
├── RichTextUtils.ets # 文本工具函数
├── MarkdownParser.ets # Markdown 与 HTML 解析器
└── SyntaxHighlighter.ets # 代码语法高亮引擎
开发者可以通过以下命令克隆仓库:
git clone https://atomgit.com/maaaath/oh_demo11_animations.git
十二、总结
本文系统地介绍了在 Flutter for OpenHarmony 跨平台工程中实现富文本渲染能力的完整方案。通过将解析逻辑与渲染逻辑解耦,本方案具有以下优势:
- Markdown 解析:支持标题、段落、代码块、列表、表格、引用、分割线等主流元素
- HTML 渲染:将 HTML 转换为统一的中间格式,与 Markdown 共用渲染逻辑
- 代码高亮:内置 ArkTS、TypeScript、Python、Java 等语言支持,颜色方案参考 GitHub 主题
- 图文混排:通过统一的元素分发机制,轻松扩展图片等异构内容
- 模块化设计:常量层、工具层、解析层、渲染层各司其职,便于维护与扩展
希望本文能为开发者在 OpenHarmony 跨平台开发中构建内容展示能力提供有价值的参考。
作者:maaaath
参考资料
- OpenHarmony 应用开发文档:https://developer.huawei.com/consumer/cn/doc/
- Flutter for OpenHarmony 官方仓库:https://atomgit.com/maaaath/oh_demo11_animations
截图验证板块
请在下方查看富文本渲染能力在鸿蒙设备上的实际运行截图:
为开源鸿蒙跨平台工程集成富文本渲染能力
作者:maaaath
欢迎加入开源鸿蒙跨平台社区: https://openharmonycrossplatform.csdn.net
一、引言
在移动应用开发中,富文本渲染能力几乎是所有内容型应用的"刚需"。无论是文章阅读、帖子详情还是代码文档,用户都期望看到排版精美、层次分明的文本内容。Flutter for OpenHarmony(即 @ohos/flutter_ohos 框架)虽然提供了强大的 UI 能力,但在原生 ArkUI 层面,开发者仍然需要自行实现 Markdown 解析、HTML 渲染、代码高亮与图文混排等常见功能。
本文将以实际项目代码为例,详细介绍如何在 Flutter for OpenHarmony 跨平台工程中,从零构建一套完整的富文本渲染方案。核心能力覆盖:
- Markdown 解析:将
# 标题、**加粗**、代码块、列表、表格等转换为 ArkUI 组件 - HTML 富文本展示:将
<h1>、<p>、<blockquote>、<pre>等 HTML 标签渲染为原生界面 - 代码语法高亮:支持 TypeScript、ArkTS、Python、Java 等多种语言的实时词法着色
- 图文混排:在富文本中自然穿插图片、引用块、代码片段等异构内容
本文所有代码均来自经过验证的真实项目,已在鸿蒙设备上成功运行,代码仓库地址:https://atomgit.com/maaaath/oh_demo11_animations
二、整体架构设计
2.1 模块分层
本方案采用四层模块化设计,各层职责清晰,便于维护与扩展:
| 层级 | 文件 | 职责 |
|---|---|---|
| 常量层 | RichTextConstants.ets |
字号、颜色、间距等可配置常量 |
| 工具层 | RichTextUtils.ets |
HTML 实体解码、内联样式解析、文本变换 |
| 解析层 | MarkdownParser.ets |
Markdown 与 HTML 的结构化解析 |
| 渲染层 | RichTextPage.ets |
ArkUI 组件拼接与页面编排 |
这种分层的好处在于:解析逻辑与渲染逻辑完全解耦——解析层只负责将字符串转换为结构化数据,不涉及任何 ArkUI 依赖,这意味着解析器可以在其他纯 ArkTS 场景中独立复用。
2.2 数据流
富文本渲染的完整数据流如下:
原始字符串 (Markdown/HTML)
↓
解析层 (MarkdownParser / HtmlParser)
↓
MarkdownElement[] 结构化数组
↓
RichTextUtils.parseInlineStyles() 展开内联样式
↓
ArkUI @Builder 组件树
三、常量与配置体系
3.1 颜色与尺寸常量
RichTextConstants.ets 中定义了完整的颜色与尺寸常量,这些常量是整个渲染体系的视觉基准:
export class RichTextColors {
static readonly PRIMARY: string = '#1976D2';
static readonly TEXT_PRIMARY: string = '#1A1A1A';
static readonly TEXT_SECONDARY: string = '#333333';
static readonly BG_CODE: string = '#F6F8FA';
static readonly BG_QUOTE: string = '#F8F9FA';
static readonly CODE_KEYWORD: string = '#D73A49'; // 关键字红色
static readonly CODE_STRING: string = '#032F62'; // 字符串深蓝
static readonly CODE_COMMENT: string = '#6A737D'; // 注释灰色
static readonly CODE_FUNCTION: string = '#6F42C1'; // 函数紫色
}
在 ArkUI 中使用统一常量而非硬编码值,有两个显著好处:一是修改主题色时无需逐文件搜索替换;二是确保整个应用中所有文本元素的视觉风格高度一致。
3.2 默认配置
export const DefaultRichTextConfig: RichTextConfig = {
baseFontSize: 14,
headingScale: [1.8, 1.5, 1.3], // h1/h2/h3 相对于正文的放大倍率
lineHeight: 1.6,
codeFontFamily: 'monospace',
paragraphSpacing: 12
};
四、Markdown 解析器实现
4.1 解析器设计思路
MarkdownParser.ets 中的 MarkdownParser 类采用逐行扫描的策略:初始化时将整个 Markdown 字符串按换行符切分为行数组,然后通过一个内部指针 lineNumber 顺序遍历,每一行根据正则匹配结果分发给对应的解析方法。
这种方法的优势在于实现直观、逻辑清晰,适合解析规则相对固定的 Markdown 子集(标题、段落、代码块、列表、引用、表格、分割线)。
4.2 核心解析方法
标题解析
标题行以一个到六个 # 开头,后跟空格:
private parseHeading(line: string): MarkdownElement {
const match = line.match(/^(#{1,6})\s+(.*)/);
if (match) {
this.lineNumber++;
return {
type: MarkdownElementType.HEADING,
content: match[2].trim(),
level: match[1].length
};
}
return { type: MarkdownElementType.PARAGRAPH, content: line };
}
解析结果中的 level 字段(1~6)决定后续渲染时的字号大小与字体粗细——一级标题字号最大(24),三级标题字号较小(16)。
代码块解析
代码块以三个反引号 ```````````包裹,首行可指定语言:
private parseCodeBlock(): MarkdownElement {
const languageMatch = this.currentLines[this.lineNumber].match(/^```(\w*)/);
const language = languageMatch ? languageMatch[1] : '';
this.lineNumber++;
const codeLines: string[] = [];
while (this.lineNumber < this.currentLines.length) {
if (this.currentLines[this.lineNumber].match(/^```/)) {
this.lineNumber++;
break;
}
codeLines.push(this.currentLines[this.lineNumber]);
this.lineNumber++;
}
return {
type: MarkdownElementType.CODE_BLOCK,
content: codeLines.join('\n'),
language: language
};
}
需要特别注意的是,language 字段会被传递给后续的语法高亮模块,不同的语言对应不同的关键字列表和背景颜色。
表格解析
表格解析需要处理三部分内容:表头行、分隔行(含对齐信息)、数据行:
private parseTable(): MarkdownElement {
const rows: string[][] = [];
let headers: string[] = [];
let alignments: string[] = [];
while (this.lineNumber < this.currentLines.length) {
const line = this.currentLines[this.lineNumber];
if (!line.match(/^\|.+\|$/)) break;
const cells = line.split('|').map(c => c.trim()).filter(c => c !== '');
// 检测分隔行:|---|:---|:---:|
if (this.lineNumber + 1 < this.currentLines.length &&
this.currentLines[this.lineNumber + 1].match(/^\|[-:\s]+\|$/)) {
alignments = cells.map(cell => {
if (cell.startsWith(':') && cell.endsWith(':')) return 'center';
if (cell.endsWith(':')) return 'right';
return 'left';
});
this.lineNumber += 2;
if (headers.length === 0) headers = cells;
continue;
}
if (headers.length === 0) {
headers = cells;
} else {
rows.push(cells);
}
this.lineNumber++;
}
return {
type: MarkdownElementType.TABLE,
headers: headers,
rows: rows,
alignments: alignments
};
}
通过 alignments 数组,开发者可以控制每列表格的左对齐、居中或右对齐行为。
4.3 主入口方法
parse(markdown: string): ParsedMarkdown {
this.currentLines = markdown.split('\n');
this.lineNumber = 0;
const elements: MarkdownElement[] = [];
while (this.lineNumber < this.currentLines.length) {
const element = this.parseLine();
if (element) elements.push(element);
}
return { elements: elements };
}
五、HTML 解析器实现
5.1 HTML 到 MarkdownElement 的转换
HtmlParser 类提供了 parseToElements() 静态方法,将 HTML 字符串转换为 MarkdownElement[],从而与 Markdown 解析结果共用同一套渲染逻辑。这种"统一中间格式"的设计极大地简化了渲染层的复杂度。
static parseToElements(html: string): MarkdownElement[] {
const blocks = cleanedHtml.split(/(?=<(?:p|div|h[1-6]|blockquote|pre|ul|ol|li|table|hr)[^>]*>)/gi);
for (const block of blocks) {
const element = HtmlParser.parseBlock(block.trim());
if (element) elements.push(element);
}
return elements;
}
5.2 块级元素解析
parseBlock() 方法通过正则匹配识别不同的 HTML 标签:
private static parseBlock(block: string): MarkdownElement | null {
// 标题:<h1> ~ <h6>
const headingMatch = block.match(/^<(h[1-6])(?:\s+[^>]*)?>([\s\S]*?)<\/\1>/i);
if (headingMatch) {
return {
type: MarkdownElementType.HEADING,
content: HtmlParser.stripTags(headingMatch[2]),
level: parseInt(headingMatch[1].substring(1))
};
}
// 预格式化代码块:<pre><code>...</code></pre>
const codeMatch = block.match(/^<pre(?:\s+[^>]*)?>([\s\S]*?)<\/pre>/i);
if (codeMatch) {
return {
type: MarkdownElementType.CODE_BLOCK,
content: HtmlParser.stripTags(codeMatch[1]).trim(),
language: this.extractLanguage(codeMatch[1])
};
}
// 列表
if (block.startsWith('<ul')) return this.parseList(RegExp.exec(...), false);
if (block.startsWith('<ol')) return this.parseList(RegExp.exec(...), true);
return null;
}
stripTags() 方法同时调用了 RichTextUtils.decodeHtmlEntities(),确保 HTML 实体(如 <、>、&)被正确还原为原始字符。
六、内联样式解析
6.1 样式枚举
RichTextUtils.ets 中定义了 TextStyle 枚举,覆盖了常见的内联样式类型:
export enum TextStyle {
NORMAL = 0,
BOLD = 1,
ITALIC = 2,
CODE = 3,
LINK = 4,
HEADING1 = 5,
HEADING2 = 6,
HEADING3 = 7,
QUOTE = 8,
LIST_ITEM = 9,
STRIKETHROUGH = 10
}
6.2 正则解析内联样式
parseInlineStyles() 是核心方法,它使用一个复合正则表达式同时匹配加粗、斜体、行内代码、删除线、链接等多种内联标记:
static parseInlineStyles(text: string): InlineStyleItem[] {
const result: InlineStyleItem[] = [];
const inlinePattern = new RegExp(
'(\\*\\*[^*]+\\*\\*|__[^_]+__|\\*[^*]+\\*|_[^_]+_|`[^`]+`|~~[^~]+~~|\\[([^\\]]+)\\]\\([^)]+\\))',
'g'
);
let lastIndex = 0;
let match = inlinePattern.exec(text);
while (match !== null) {
if (match.index > lastIndex) {
result.push({ text: text.substring(lastIndex, match.index), style: TextStyle.NORMAL });
}
const matched = match[0];
if (matched.startsWith('**') || matched.startsWith('__')) {
result.push({ text: matched.slice(2, -2), style: TextStyle.BOLD });
} else if (matched.startsWith('~~')) {
result.push({ text: matched.slice(2, -2), style: TextStyle.STRIKETHROUGH });
} else if (matched.startsWith('`')) {
result.push({ text: matched.slice(1, -1), style: TextStyle.CODE });
} else if (matched.startsWith('[')) {
const linkMatch = /\[([^\]]+)\]\(([^)]+)\)/.exec(matched);
if (linkMatch) result.push({ text: linkMatch[1], style: TextStyle.LINK });
} else {
result.push({ text: matched.slice(1, -1), style: TextStyle.ITALIC });
}
lastIndex = match.index + matched.length;
match = inlinePattern.exec(text);
}
if (lastIndex < text.length) {
result.push({ text: text.substring(lastIndex), style: TextStyle.NORMAL });
}
return result.length > 0 ? result : [{ text: text, style: TextStyle.NORMAL }];
}
这个方法的关键设计在于:它将一段文本切分为多个片段,每个片段附带独立的样式信息。渲染层只需遍历 InlineStyleItem[],为每段文本应用对应的 fontWeight、fontStyle 和 fontColor 即可。
七、代码语法高亮
7.1 词法分析器架构
SyntaxHighlighter.ets 实现了一个基于状态机的轻量级词法分析器。与重型编译器前端不同,它专注于快速识别 token 类型(关键字、字符串、数字、注释、函数名等),并为每种 token 分配对应的颜色。
核心入口:
highlight(code: string, language: string): HighlightedCode {
const lang = this.normalizeLanguage(language);
const codeLines = code.split('\n');
const highlightedLines: HighlightedLine[] = [];
for (let i = 0; i < codeLines.length; i++) {
const tokens = this.tokenizeLine(codeLines[i], lang);
highlightedLines.push({ tokens: tokens, lineNumber: i + 1 });
}
return { lines: highlightedLines, language: lang };
}
7.2 多语言关键字列表
为每种语言维护独立的关键词列表:
private keywordListArkTS: string[] = [
'const', 'let', 'var', 'function', 'return', 'if', 'else', 'for', 'while', 'do',
'switch', 'case', 'break', 'continue', 'try', 'catch', 'finally', 'throw', 'new',
'this', 'class', 'extends', 'super', 'import', 'export', 'default', 'from', 'as',
'async', 'await', 'null', 'undefined', 'true', 'false', 'void', 'delete',
'interface', 'type', 'enum', 'implements', 'private', 'public', 'protected',
'readonly', 'abstract', 'struct'
];
特别值得注意的是 ArkTS 语言的列表包含了 struct、@State、@Prop 等 ArkUI 装饰器相关的关键字,确保了在鸿蒙开发中的实用性。
7.3 Token 颜色映射
getColorForToken(token: Token): string {
if (token.type === TokenType.KEYWORD) return '#D73A49';
if (token.type === TokenType.STRING) return '#032F62';
if (token.type === TokenType.NUMBER) return '#005CC5';
if (token.type === TokenType.COMMENT) return '#6A737D';
if (token.type === TokenType.FUNCTION) return '#6F42C1';
if (token.type === TokenType.TYPE) return '#22863A';
return '#24292E';
}
这套配色参考了 GitHub 官方主题的视觉风格,关键词以红色突出,字符串以深蓝区分,注释以灰色低调呈现,整体观感专业且易于阅读。
7.4 行内 Token 切分
逐字符扫描是词法分析器的核心循环:
private tokenizeLine(line: string, language: string): Token[] {
const tokens: Token[] = [];
let i = 0;
while (i < line.length) {
// 单行注释
if (line[i] === '/' && i + 1 < line.length && line[i + 1] === '/') {
tokens.push({ value: line.substring(i), type: TokenType.COMMENT });
break;
}
// Python 注释
if (line[i] === '#') {
tokens.push({ value: line.substring(i), type: TokenType.COMMENT });
break;
}
// 字符串(处理转义字符)
if (line[i] === '"' || line[i] === '\'' || line[i] === '`') {
tokens.push(this.readString(line, i));
i += tokens[tokens.length - 1].value.length;
continue;
}
// 数字
if (this.isDigit(line[i])) {
tokens.push(this.readNumber(line, i));
i += tokens[tokens.length - 1].value.length;
continue;
}
// 标识符(关键字、类型、函数名)
if (this.isLetter(line[i]) || line[i] === '_' || line[i] === '$') {
tokens.push(this.readIdentifier(line, i, language));
i += tokens[tokens.length - 1].value.length;
continue;
}
// 操作符和标点
tokens.push({ value: line[i], type: this.isOperatorChar(line[i]) ? TokenType.OPERATOR : TokenType.PUNCTUATION });
i++;
}
return tokens;
}
八、ArkUI 渲染层
8.1 四选项卡页面结构
RichTextPage.ets 采用选项卡布局,将四种能力分别展示:Markdown 预览、HTML 渲染、代码高亮、图文混排。
build() {
Column() {
this.buildHeader()
this.buildTabBar()
Scroll() {
Column({ space: 16 }) {
if (this.selectedTab === 0) {
this.buildMarkdownDemo()
} else if (this.selectedTab === 1) {
this.buildHtmlDemo()
} else if (this.selectedTab === 2) {
this.buildCodeHighlightDemo()
} else {
this.buildMixedContentDemo()
}
}
.padding(16)
}
.layoutWeight(1)
}
.width('100%')
.height('100%')
}
8.2 Markdown 元素渲染
渲染的核心思路是分发路由:根据 MarkdownElement.type 的值,调用对应的 @Builder 方法:
@Builder
renderMarkdownElementItem(element: MarkdownElement) {
if (element.type === MarkdownElementType.HEADING) {
this.renderHeadingContent(element.content, element.level ?? 1);
} else if (element.type === MarkdownElementType.PARAGRAPH) {
this.renderParagraphContent(element.content);
} else if (element.type === MarkdownElementType.CODE_BLOCK) {
this.renderCodeContent(element.content, element.language ?? 'plain');
} else if (element.type === MarkdownElementType.LIST) {
this.renderListContent(element);
} else if (element.type === MarkdownElementType.BLOCKQUOTE) {
this.renderBlockquoteContent(element.content);
} else if (element.type === MarkdownElementType.TABLE) {
this.renderTableContent(element);
} else if (element.type === MarkdownElementType.HORIZONTAL_RULE) {
Divider().width('100%').color('#E0E0E0');
}
}
8.3 表格渲染
@Builder
renderTableContent(element: MarkdownElement) {
Column({ space: 0 }) {
// 表头行
Row() {
ForEach(element.headers, (header: string, index: number) => {
Text(header)
.fontSize(12).fontWeight(FontWeight.Bold).fontColor('#333333')
.layoutWeight(1)
.textAlign(index === 0 ? TextAlign.Start :
index === element.headers.length - 1 ? TextAlign.End : TextAlign.Center);
})
}
.width('100%')
.padding(8)
.backgroundColor('#F5F5F5')
// 数据行
ForEach(element.rows, (row: string[]) => {
Row() {
ForEach(row, (cell: string, index: number) => {
Text(cell)
.fontSize(12).fontColor('#666666')
.layoutWeight(1)
.textAlign(index === row.length - 1 ? TextAlign.End : TextAlign.Center);
})
}
.width('100%')
.padding(8)
.border({ width: { bottom: 1 }, color: { bottom: '#E0E0E0' } });
})
}
.width('100%')
.borderRadius(8)
.border({ width: 1, color: '#E0E0E0' });
}
8.4 代码高亮渲染
@Builder
renderHighlightedCode(highlighted: HighlightedCode, language: string) {
Column({ space: 0 }) {
// 语言标签栏
Row() {
Text(language.toUpperCase()).fontSize(10).fontColor('#666666');
Blank();
Text(highlighted.lines.length.toString() + ' lines').fontSize(10).fontColor('#666666');
}
.width('100%')
.backgroundColor('#E8E8E8')
.padding({ left: 8, right: 8, top: 4, bottom: 4 })
// 代码行
ForEach(highlighted.lines, (line: HighlightedLine) => {
Row() {
Text(line.lineNumber.toString())
.fontSize(12).fontFamily('monospace').fontColor('#999999')
.width(40).textAlign(TextAlign.End).padding({ right: 12 });
Flex({ wrap: FlexWrap.Wrap }) {
ForEach(line.tokens, (token: Token) => {
Text(token.value)
.fontSize(12).fontFamily('monospace')
.fontColor(syntaxHighlighter.getColorForToken(token));
})
}
.layoutWeight(1)
}
.width('100%')
.padding({ left: 8, right: 8, top: 2, bottom: 2 });
})
}
.width('100%')
.borderRadius(8)
.clip(true)
.backgroundColor(syntaxHighlighter.getBackgroundColorForLanguage(language));
}
九、实践指南:如何在项目中使用
9.1 集成步骤
第一步:将以下四个文件复制到你的 entry/src/main/ets/utils/ 目录:
RichTextConstants.etsRichTextUtils.etsMarkdownParser.etsSyntaxHighlighter.ets
第二步:在目标页面中导入所需模块:
import { MarkdownParser, MarkdownElement, HtmlParser } from '../utils/MarkdownParser';
import { SyntaxHighlighter, syntaxHighlighter } from '../utils/SyntaxHighlighter';
import { RichTextUtils } from '../utils/RichTextUtils';
第三步:创建解析器实例并渲染内容:
// 解析 Markdown
const parser = new MarkdownParser();
const elements = parser.parse('# Hello\n\nThis is **bold** text.').elements;
// 渲染
ForEach(elements, (element: MarkdownElement) => {
this.renderElement(element);
});
9.2 渲染 Markdown 文章内容
如果你的应用需要展示文章或帖子详情,只需将完整的 Markdown 字符串传入解析器:
aboutToAppear(): void {
this.articleContent = '...'; // 从网络或本地加载的 Markdown 内容
}
build() {
Column() {
Scroll() {
Column({ space: 12 }) {
this.renderMarkdownContent(this.articleContent)
}
.padding(16)
}
}
}
@Builder
renderMarkdownContent(markdown: string) {
const parser = new MarkdownParser();
const elements = parser.parse(markdown).elements;
this.renderMarkdownElements(elements);
}
9.3 渲染带高亮的代码展示
@Builder
renderCodeBlock(code: string, language: string) {
const highlighted = syntaxHighlighter.highlight(code, language);
Column() {
Text(language.toUpperCase()).fontSize(10).fontColor('#666666');
ForEach(highlighted.lines, (line) => {
Row() {
Text(line.lineNumber.toString()).fontSize(12).fontFamily('monospace');
ForEach(line.tokens, (token) => {
Text(token.value)
.fontFamily('monospace')
.fontColor(syntaxHighlighter.getColorForToken(token));
})
}
})
}
.backgroundColor(syntaxHighlighter.getBackgroundColorForLanguage(language));
}
十、性能与扩展建议
10.1 长文本优化
对于包含大量代码块或长表格的文档,建议在 Scroll 容器上添加懒加载策略,只渲染可视区域内的元素。此外,可以为代码块设置最大行数限制,超出部分显示"展开更多"按钮:
if (codeLines.length > this.MAX_DISPLAY_LINES) {
// 显示前 N 行 + 展开按钮
}
10.2 图片占位符
当前方案中图片元素(![]() 语法)需要通过 WebView 或 Image 组件单独渲染。建议实现一个图片加载管理器,支持从网络 URL 和本地 Resource 两种来源:
interface ImageItem {
src: string;
alt: string;
width?: number;
height?: number;
}
static parseImageRefs(markdown: string): ImageItem[] {
const imagePattern = /!\[([^\]]*)\]\(([^)]+)\)/g;
const images: ImageItem[] = [];
let match;
while ((match = imagePattern.exec(markdown)) !== null) {
images.push({ alt: match[1], src: match[2] });
}
return images;
}
10.3 支持更多语言
只需在 SyntaxHighlighter.ets 中添加新的关键字列表和方法分支:
private keywordListGo: string[] = [
'func', 'package', 'import', 'return', 'if', 'else', 'for', 'range',
'type', 'struct', 'interface', 'map', 'chan', 'defer', 'go', 'select'
];
然后在 getKeywordsForLanguage() 中添加对应分支即可。
十一、仓库与资源
本文所涉及的所有源码均可在以下地址获取:
仓库地址:https://atomgit.com/maaaath/oh_demo11_animations
entry/src/main/ets/
├── pages/
│ └── RichTextPage.ets # 富文本演示页面(含四个选项卡)
└── utils/
├── RichTextConstants.ets # 常量定义
├── RichTextUtils.ets # 文本工具函数
├── MarkdownParser.ets # Markdown 与 HTML 解析器
└── SyntaxHighlighter.ets # 代码语法高亮引擎
开发者可以通过以下命令克隆仓库:
git clone https://atomgit.com/maaaath/oh_demo11_animations.git
十二、总结
本文系统地介绍了在 Flutter for OpenHarmony 跨平台工程中实现富文本渲染能力的完整方案。通过将解析逻辑与渲染逻辑解耦,本方案具有以下优势:
- Markdown 解析:支持标题、段落、代码块、列表、表格、引用、分割线等主流元素
- HTML 渲染:将 HTML 转换为统一的中间格式,与 Markdown 共用渲染逻辑
- 代码高亮:内置 ArkTS、TypeScript、Python、Java 等语言支持,颜色方案参考 GitHub 主题
- 图文混排:通过统一的元素分发机制,轻松扩展图片等异构内容
- 模块化设计:常量层、工具层、解析层、渲染层各司其职,便于维护与扩展
希望本文能为开发者在 OpenHarmony 跨平台开发中构建内容展示能力提供有价值的参考。
作者:maaaath
参考资料
- OpenHarmony 应用开发文档:https://developer.huawei.com/consumer/cn/doc/
- Flutter for OpenHarmony 官方仓库:https://atomgit.com/maaaath/oh_demo11_animations
截图验证板块
请在下方查看富文本渲染能力在鸿蒙设备上的实际运行截图:

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)