
大模型本地化部署:Ollama&vLLM&LMDeploy+ModelScope
团队推出的端到端推理框架,专注模型压缩与异构硬件部署,支持昇腾(提供行业数据集(如阿里电商数据),预训练模型免环境配置在线运行。输入nvitop可实时动态的显示CPU,GPU的设备信息。:闲置模型层自动转移至系统内存或磁盘,缓解显存压力。下载vscode,租服务器,通过远程资源管理器连接。)分页存储,类似操作系统虚拟内存管理,减少内存碎。(最高精度),用户可依硬件性能选择。:加州伯克利分校研发的推


一、Ollama:轻量级本地化部署框架
定位:专为本地设备设计的开源框架,支持macOS/Linux/Windows(需WSL),无需云端资源即可运行百亿级模型。
核心优势详解
1. 动态内存管理
![]() 分片加载机制:将大模型拆分为多个分片(Shards),仅在推理时按需加载到显存。例如70B 模型原生需140GB 显存,Ollama 通过分片可降至40GB,适配消费级显卡(如RTX4090)。
分片加载机制:将大模型拆分为多个分片(Shards),仅在推理时按需加载到显存。例如70B 模型原生需140GB 显存,Ollama 通过分片可降至40GB,适配消费级显卡(如RTX4090)。
![]() 智能卸载:闲置模型层自动转移至系统内存或磁盘,缓解显存压力。
智能卸载:闲置模型层自动转移至系统内存或磁盘,缓解显存压力。
2. 量化压缩支持
![]() 原生支持GGUF 格式的4-bit/5-bit 量化(如Q4_K_M),70B 模型体积从140GB 压缩至 ~40GB,精度损失低于2%。
原生支持GGUF 格式的4-bit/5-bit 量化(如Q4_K_M),70B 模型体积从140GB 压缩至 ~40GB,精度损失低于2%。
![]() 支持多级量化策略:Q2_K(最小体积)→Q6_K(最高精度),用户可依硬件性能选择。
支持多级量化策略:Q2_K(最小体积)→Q6_K(最高精度),用户可依硬件性能选择。
3. 跨平台硬件加速
![]() 后端支持CUDA(NVIDIA GPU)、Metal(Apple M 系列)、Vulkan(AMD/Intel GPU)及纯CPU 推理,同一模型无需修改即可跨设备运行14。
后端支持CUDA(NVIDIA GPU)、Metal(Apple M 系列)、Vulkan(AMD/Intel GPU)及纯CPU 推理,同一模型无需修改即可跨设备运行14。
![]() 集成OpenBLAS/cuBLAS 加速库,优化矩阵运算效率。
集成OpenBLAS/cuBLAS 加速库,优化矩阵运算效率。
4. 隐私与易用性
![]() 数据完全本地处理,符合GDPR 隐私规范,适合医疗、金融等敏感场景。
数据完全本地处理,符合GDPR 隐私规范,适合医疗、金融等敏感场景。
![]() 类OpenAI API 设计,支持/v1/chat/completions 等端点,无缝对接LangChain、 LlamaIndex 等生态。
类OpenAI API 设计,支持/v1/chat/completions 等端点,无缝对接LangChain、 LlamaIndex 等生态。
下载vscode,租服务器,通过远程资源管理器连接
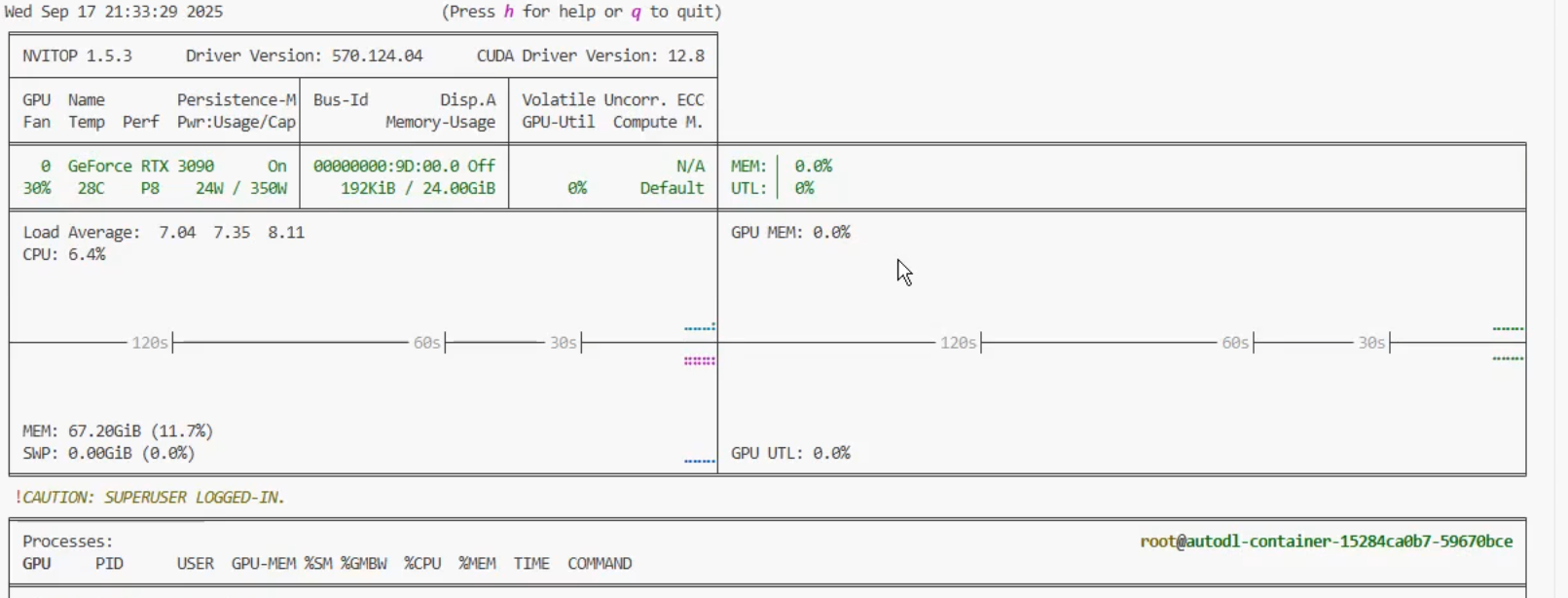
在终端输入pip install nvitop
输入nvitop可实时动态的显示CPU,GPU的设备信息
安装ollama,推荐通过魔搭安装
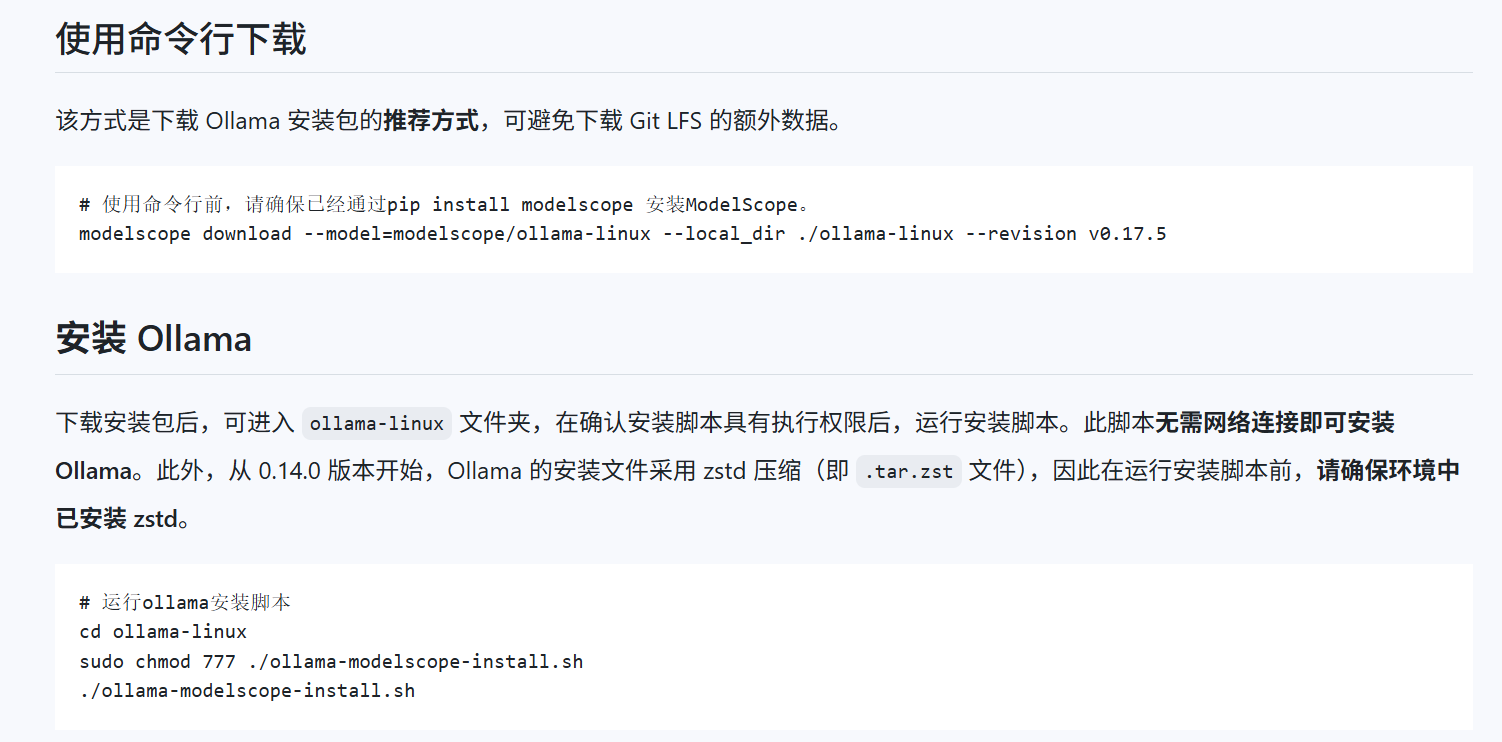
在魔塔社区下载千问3-.06B
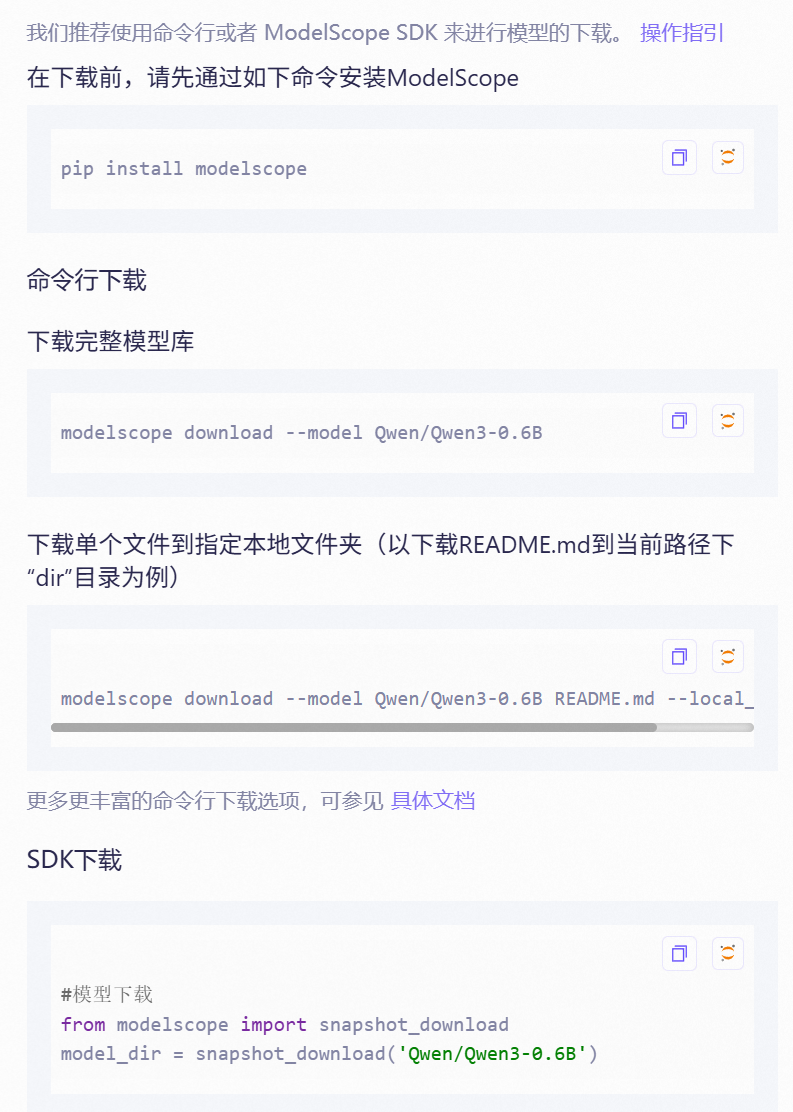
SDK下载后面加一个cache_dir指定一个保存路径

模型下载到这个路径
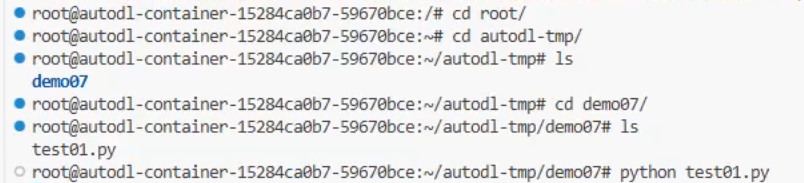
方法一

方法二
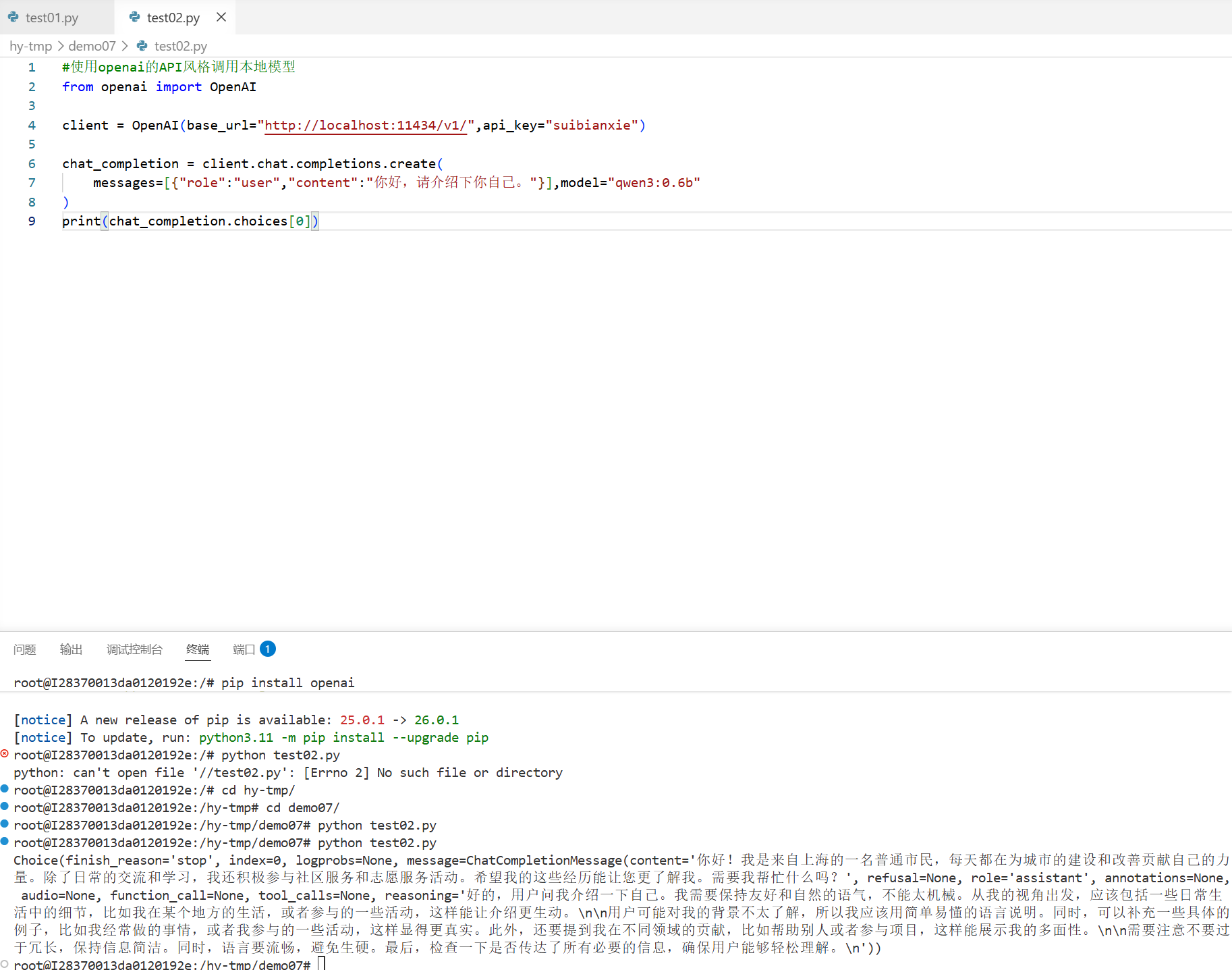
详细部署流程
1. 安装与环境配置

2. 模型加载与交互
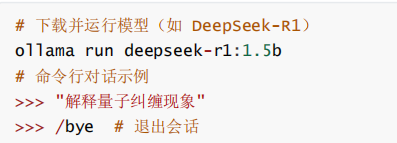
3. API 服务化部署
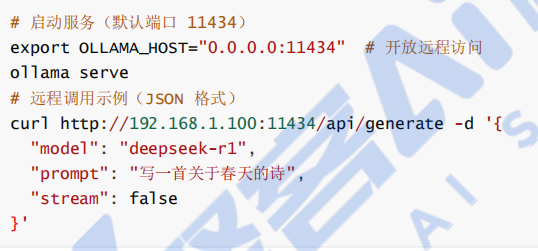
二、vLLM:高性能分布式推理框架
定位:加州伯克利分校研发的推理引擎,通过PagedAttention 算法优化KV 缓存,吞吐量较 HuggingFace 提升24 倍,适合高并发生产环境。
核心技术解析
1. PagedAttention 机制
![]() 将注意力计算的键值对(KV Cache)分页存储,类似操作系统虚拟内存管理,减少内存碎片,显存利用率提升3 倍以上。
将注意力计算的键值对(KV Cache)分页存储,类似操作系统虚拟内存管理,减少内存碎片,显存利用率提升3 倍以上。
![]() 支持动态批处理(Dynamic Batching),自动合并请求提升GPU 利用率8。
支持动态批处理(Dynamic Batching),自动合并请求提升GPU 利用率8。
2. 多硬件与量化支持
![]() 适配CUDA 12 .4+,支持FP8/BF16 量化及张量并行(Tensor Parallelism),单卡可运行7B模型,多卡扩展至200B+。
适配CUDA 12 .4+,支持FP8/BF16 量化及张量并行(Tensor Parallelism),单卡可运行7B模型,多卡扩展至200B+。
![]() 兼容HuggingFace 模型库,无需转换格式直接加载5。
兼容HuggingFace 模型库,无需转换格式直接加载5。
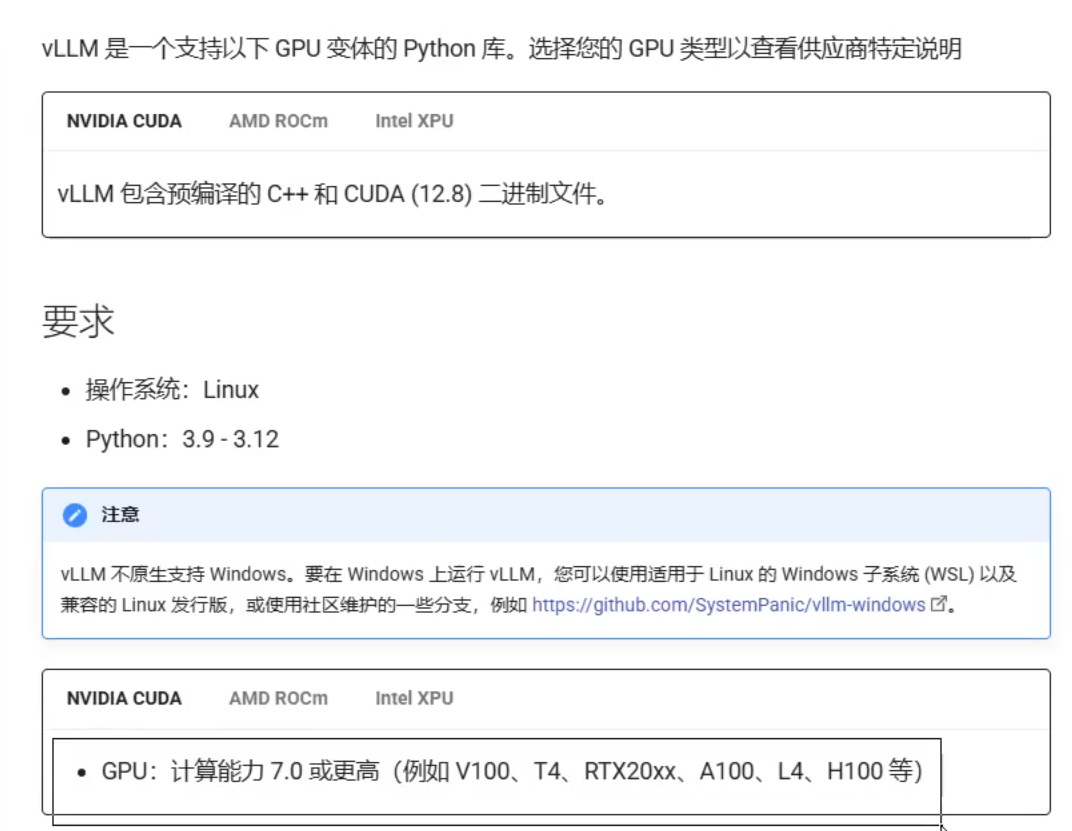
只能在Linux操作
在conda环境隔离操作
详细部署流程
1. 环境依赖安装
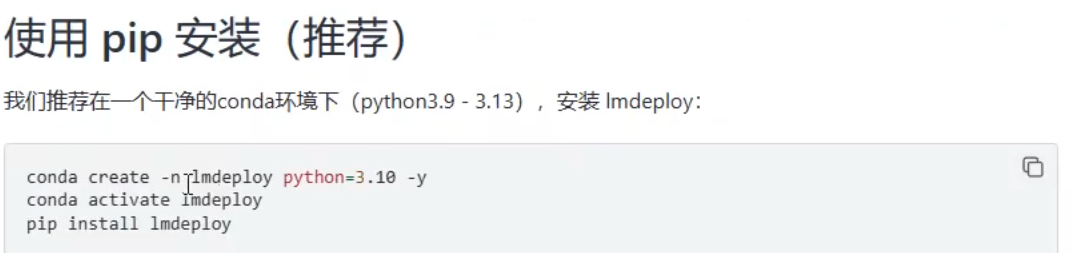
创建conda环境

2. 模型加载与离线推理(不推荐)

3. 启动OpenAI 兼容API 服务(推荐)
|
|

三、LMDeploy:生产级量化与国产硬件适配
定位:由InternLM 团队推出的端到端推理框架,专注模型压缩与异构硬件部署,支持昇腾(Ascend)NPU,显存优化达90%+。
关键技术特性
1. 量化策略组合

2. 昇腾NPU 适配
![]() 通过DLInfer 引擎支持华为昇腾芯片,需在启智平台配置CANN 8.0 环境。
通过DLInfer 引擎支持华为昇腾芯片,需在启智平台配置CANN 8.0 环境。
![]() 提供昇腾专用镜像:openmind_cann8,预装MindSpore 框架。
提供昇腾专用镜像:openmind_cann8,预装MindSpore 框架。
详细部署流程
1. 环境配置与安装

2. 模型量化实战

3. API 服务部署

四、ModelScope:一站式中文模型平台
定位:阿里达摩院开源的模型即服务(MaaS)平台,集成300+ 中文优化模型,覆盖NLP/CV/多模态任务。
核心功能详解
1. 模型生态
![]() 覆盖InternVL2-26B(多模态)、Qwen、DeepSeek 等国产SOTA 模型,支持免费下载与微调。
覆盖InternVL2-26B(多模态)、Qwen、DeepSeek 等国产SOTA 模型,支持免费下载与微调。
![]() 提供行业数据集(如阿里电商数据),预训练模型免环境配置在线运行。
提供行业数据集(如阿里电商数据),预训练模型免环境配置在线运行。
2. 高效推理API

部署方案对比与选型建议
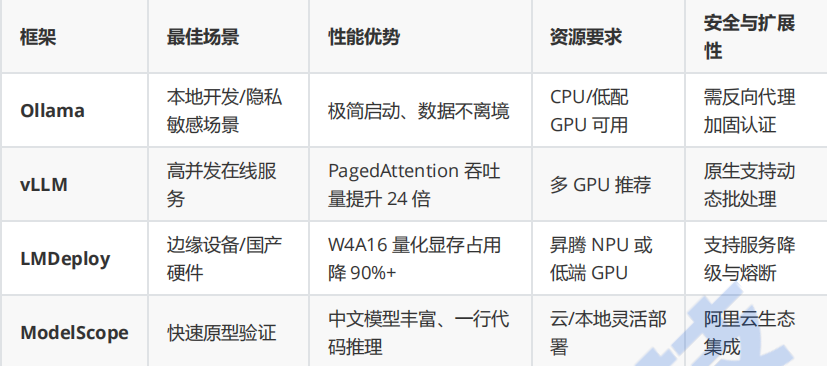
💡场景化选型指南:
![]() 个人开发者:首选Ollama(本地隐私)或ModelScope(快速验证)
个人开发者:首选Ollama(本地隐私)或ModelScope(快速验证)
![]() 企业API 服务:vLLM(高并发)或LMDeploy(资源受限场景)
企业API 服务:vLLM(高并发)或LMDeploy(资源受限场景)
![]() 国产信创环境:LMDeploy + 昇腾NPU(兼容性最佳)
国产信创环境:LMDeploy + 昇腾NPU(兼容性最佳)
各框架官方资源:
![]() Ollama 模型库| vLLM 文档
Ollama 模型库| vLLM 文档
![]() LMDeploy 昇腾指南| ModelScope 官网
LMDeploy 昇腾指南| ModelScope 官网

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)