
鸿蒙PC - Unicode转义序列的致命陷阱 —— 一个字符引发79个编译错误
ArkTS 运行在 strict mode 下。这意味着很多在前端开发中被"宽容"处理的写法,到了这里会变成致命的编译错误。本文记录了一次因 Unicode 转义字符书写不完整导致的连锁灾难——一个\uBF9(少了前导数字5)最终引发了79 个编译错误。从问题复现到根因定位再到预防体系,希望能为正在或即将踏上 HarmonyOS 开发之路的你提供一份避坑指南。如果你正在经历"改了一个错冒出一片红"
踩坑记录01:Unicode转义序列的致命陷阱 —— 一个字符引发79个编译错误
阅读时长:约 8 分钟 | 难度等级:中级 | 适用版本:HarmonyOS NEXT (API 12+)
关键词:ArkTS、Unicode 转义、编译错误排查、级联错误链
声明:本文基于真实项目开发经历编写,所有代码片段均来自实际踩坑场景。
欢迎加入开源鸿蒙PC社区:https://harmonypc.csdn.net/
项目 Git 仓库:https://atomgit.com/Dgr111-space/HarmonyOS
📖 前言导读
在 HarmonyOS 的 ArkTS 开发中,我们习惯了 TypeScript/JavaScript 的字符串处理方式,但往往忽略了一个细节:ArkTS 运行在 strict mode 下。这意味着很多在前端开发中被"宽容"处理的写法,到了这里会变成致命的编译错误。
本文记录了一次因 Unicode 转义字符书写不完整导致的连锁灾难——一个 \uBF9(少了前导数字 5)最终引发了 79 个编译错误。从问题复现到根因定位再到预防体系,希望能为正在或即将踏上 HarmonyOS 开发之路的你提供一份避坑指南。
如果你正在经历"改了一个错冒出一片红"的绝望时刻,这篇文章就是为你准备的。
📑 目录
一、问题背景与现场还原
1.1 事故现场
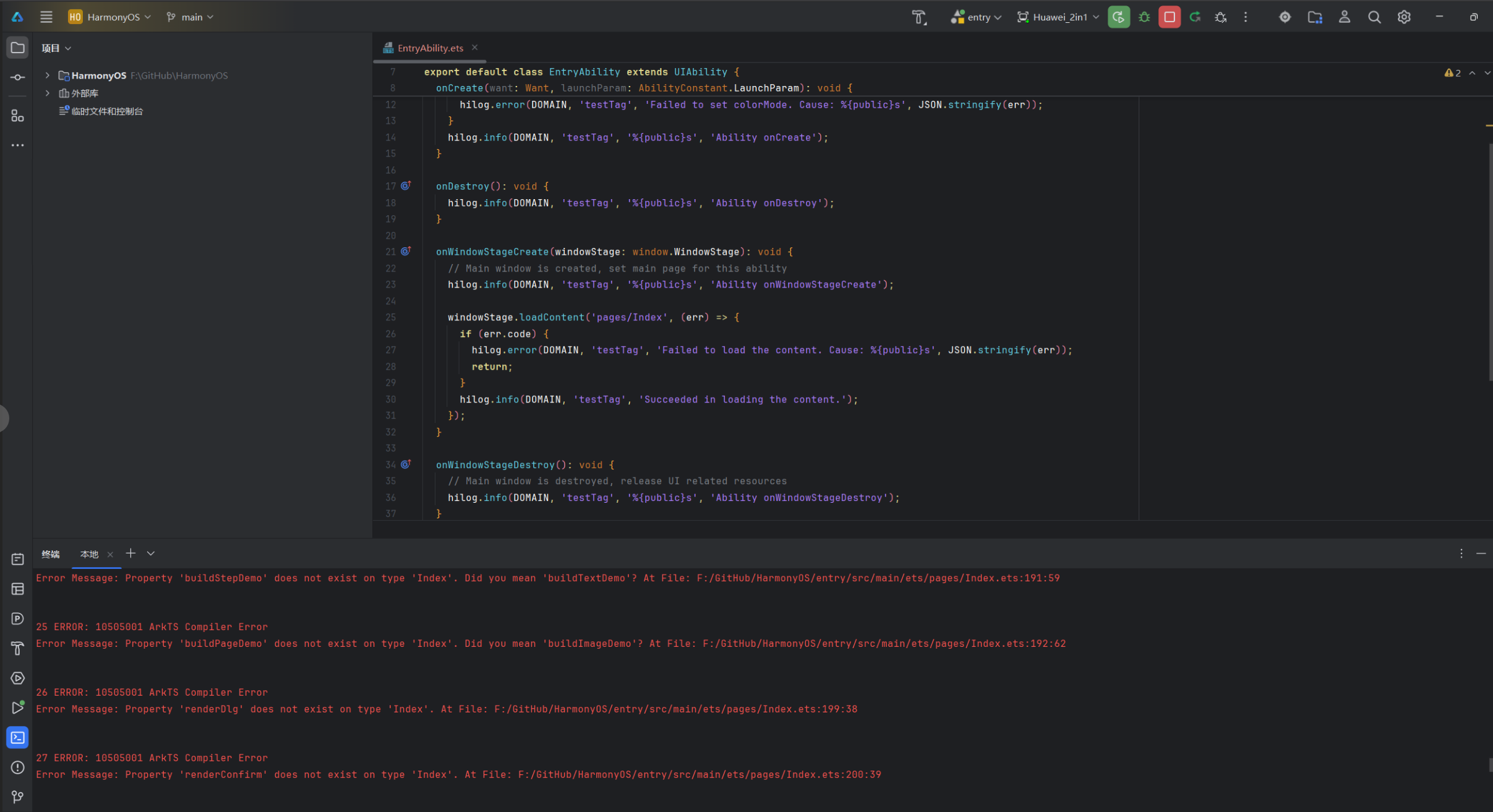
在开发一个 HarmonyOS 组件库(包含 HButton、HInput、HTag 等 20+ 自定义组件)的过程中,一次常规的构建操作突然报出了前所未有的错误量:
hvigor ERROR: Failed :entry:default@CompileArkTS...
COMPILE RESULT:FAIL {ERROR:79}
79 个编译错误——这对于一个之前一直正常通过的项目来说无异于晴天霹雳。
1.2 错误分布初探
仔细观察错误列表后,发现它们呈现出明显的聚集特征:
| 错误类型 | 出现次数 | 首次出现行号 |
|---|---|---|
; expected |
17 次 | 第 262 行附近 |
| Declaration expected | 16 次 | 第 390 行起连续爆发 |
| Property does not exist on type ‘Index’ | 11 次 | 第 185-192 行 |
| Only UI component syntax | 9 行 | 同上区域 |
'} expected |
1 行(文件末尾) | 第 454 行 |
关键线索:所有错误的起始点都指向第 262 行。这强烈暗示第 262 行存在某个根因性的语法破坏点。
二、错误复现——最小可复现用例
2.1 根因代码
第 262 行的原始代码如下:
// ❌ 致命错误写法
Text('\u53F3\uBF9').textAlign(TextAlign.End).layoutWeight(1).backgroundColor('#FEF0F0').padding(8)
开发者本意是显示文字"右对齐",对应的正确 Unicode 转义应为:
KaTeX parse error: Undefined control sequence: \backscriptstyle at position 170: …{齐} &= \mathtt{\̲b̲a̲c̲k̲s̲c̲r̲i̲p̲t̲s̲t̲y̲l̲e̲{u5F}}\text{...…
\u5BF9 被漏写了首位的 5,变成了 \uBF9——而 BF9 只有 3 位十六进制数,不符合 \uXXXX 要求的严格 4 位格式。
2.2 编译器反馈
# ArkTS Compiler Error #1(真正的根因)
ERROR: Bad character escape sequence
Hexadecimal digit expected.
At File: F:/GitHub/HarmonyOS/entry/src/main/ets/pages/Index.ets:262:30
但这个错误只是冰山一角。由于解析器在第 262 行处进入了异常状态,后续的代码解析全部偏离了预期轨道。
2.3 正确写法对比
// ❌ 错误:\uBF9 不是合法4位十六进制
Text('\u53F3\uBF9')
// ✅ 方案一:补全为正确的4位
Text('\u53F3\u5BF9')
// ✅ 方案二:直接使用中文(最推荐!)
Text('右对齐')
// ArkTS 源文件编码为 UTF-8,中文可以直接书写,无需转义
三、连锁反应机制——为什么1个错误变61个
3.1 解析器状态偏移模型
这是本文最有价值的部分。理解了连锁反应机制,你就能在面对大量级联错误时保持冷静和方向感:
Unicode 解析失败 ⏟ 根因 → 解析器进入异常状态 后续 token 定位偏移 ⏟ 传播 → @Builder 函数边界识别失败 嵌套层级计算混乱 ⏟ 放大 → 61 个虚假级联错误 结果 \underbrace{\text{Unicode 解析失败}}_{\text{根因}} \xrightarrow{\text{解析器进入异常状态}} \underbrace{\text{后续 token 定位偏移}}_{\text{传播}} \xrightarrow{\text{@Builder 函数边界识别失败}} \underbrace{\text{嵌套层级计算混乱}}_{\text{放大}} \xrightarrow{\text{61 个虚假级联错误}}_{\text{结果}} 根因 Unicode 解析失败解析器进入异常状态传播 后续 token 定位偏移@Builder 函数边界识别失败放大 嵌套层级计算混乱61 个虚假级联错误结果
3.2 错误链条可视化
3.3 经验法则
黄金规则:当编译器一次性抛出超过 10 个错误时,只关注第一个错误。后面的绝大多数都是级联虚假错误,修复了根因后它们会自动消失。
四、更多 Unicode 相关坑点合集
除了上述的主坑之外,还有几个相关的"小坑"值得注意:
坑点 1:八进制字面量冲突(strict mode)
// ❌ 报错:Octal literal in strict mode
'完善' // 如果误写成 '\u5B8C\5584'
// ^^ \55 被解析为八进制字面量 0o55 = 十进制 45
// strict mode 下禁止八进制字面量
// ✅ 正确写法
'完善' // 直接写中文
'\u5B8C\u5584' // 或确保每个 \u 后恰好 4 位
报错信息:
Octal literal in strict mode
At File: Index.ets:536
坑点 2:字符串中混合转义的隐患
// ⚠️ 能工作但极易出错——不推荐
let msg = '\u6309\u94AE\u70B9\u51FB' // "按钮点击"
// 问题:
// 1. 可读性极差,无法直观看出内容
// 2. 容易出现位数遗漏(如本次踩坑)
// 3. 复制粘贴时可能丢失转义符
// ✅ 推荐:始终优先使用直接文本
let msg = '按钮点击'
// ✅ 如确实需要动态拼接 Unicode
const charCode = 0x5BF9
let ch = String.fromCharCode(charCode) // "对"
坑点汇总表
| 场景 | 危险写法 | 安全写法 | 风险评级 |
|---|---|---|---|
| UI 文本常量 | \uXXXX 格式 |
直接写中文 | 🔴 高 |
| 动态字符生成 | 手动拼 \u + hex |
String.fromCodePoint() |
🟡 中 |
| 从外部复制代码 | 直接粘贴 | 粘贴后在编辑器重新输入关键字符 | 🟡 中 |
| JSON 配置文件中的中文 | 取决于 JSON 规范 | 确保 UTF-8 BOM 正确 | 🟢 低 |
五、避坑指南与工具推荐
5.1 决策流程图
5.2 预防性检查脚本
将以下脚本加入项目的 scripts/ 目录,每次修改含中文字符串的文件后运行:
// scripts/check_unicode.js — Unicode 转义安全检查
const fs = require('fs')
const path = require('path')
function checkFile(filePath) {
const content = fs.readFileSync(filePath, 'utf8')
const lines = content.split('\n')
let hasIssue = false
lines.forEach((line, idx) => {
// 匹配 \u 后跟非4位十六进制的模式
const badPattern = /\\u([0-9a-fA-F]{1,3})([^0-9a-fA-F]|$)/g
let match
while ((match = badPattern.exec(line)) !== null) {
if (match[1].length !== 4) {
console.warn(` ⚠️ L${idx + 1}: 不完整的Unicode转义: \\u${match[1]}`)
hasIssue = true
}
}
// 匹配疑似八进制冲突 (\d+ 且前面有反斜杠)
const octalPattern = /\\(\d{2,3})(?![0-9a-fA-F])/g
while ((match = octalPattern.exec(line)) !== null) {
if (parseInt(match[1]) < 100 && !line.includes('\\u')) {
console.warn(` ⚠️ L${idx + 1}: 可能的八进制字面量: \\${match[1]}`)
hasIssue = true
}
}
})
return !hasIssue
}
// 使用方式: node scripts/check_unicode.js entry/src/main/ets/pages/Index.ets
const targetFile = process.argv[2]
if (targetFile) {
console.log(`🔍 检查文件: ${targetFile}`)
const ok = checkFile(targetFile)
console.log(ok ? ' ✅ 未发现问题' : ' ❌ 发现上述问题请检查')
} else {
console.log('用法: node check_unicode.js <file-path>')
}
六、总结与行动清单
6.1 核心要点回顾
| 维度 | 关键结论 |
|---|---|
| 严重程度 | 🔴 高危——一个字符错误可导致数十个级联编译错误 |
| 排查难度 | 🔴 高——级联错误严重误导排查方向 |
| 预防成本 | 🟢 极低——直接写中文即可完全规避 |
| 修复策略 | 始终从第一个错误开始修复,忽略后面的级联噪声 |
6.2 开发团队 Checklist
在 Code Review 和日常开发中,建议将以下条目纳入团队的检查清单:
## Unicode 安全检查
- [ ] 所有 UI 展示文本优先使用中文直写,不手动写 \u 转义
- [ ] 必须使用 Unicode 时,确保每个 \u 后恰好跟 4 位十六进制数字
- [ ] 从外部复制粘贴的代码在 IDE 中检查是否有隐藏非法字符
- [ ] 编译出错超过 10 个时,先聚焦修复第一个错误
- [ ] 团队内约定:禁止在业务代码中出现手动 \uXXXX 转义(除非必要)
参考资源与延伸阅读
官方文档
系列导航
本文属于「HarmonyOS 开发踩坑记录」系列,该系列记录了从 0 到 1 构建 HarmonyOS 项目过程中的真实经验与教训。
工具与资源
👇 如果这篇对你有帮助,欢迎点赞、收藏、评论!
你的支持是我持续输出高质量技术内容的动力 💪

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)