
24小时不到,七芯已上!Qwen3.6-35B-A3B发布即获众智FlagOS全速护航
目前在 vLLM-plugin-FL 的支持下,平头哥、昆仑芯、天数、海光、华为昇腾、沐曦等多种 AI 芯片已经通过插件方式实现"零代码修改" 完成 Qwen3.6-35B-A3B 的推理部署及充分验证。成员单位包括北京智源研究院、中科院计算所、中科加禾、安谋科技、北京大学、北京师范大学、百度飞桨、硅基流动、寒武纪、海光信息、华为、基流科技、摩尔线程、沐曦科技、澎峰科技、清微智能、天数智芯、先进编
通义千问团队开源最新的多模态“智能体小钢炮” Qwen3.6-35B-A3B 大模型不到24小时,众智 FlagOS 社区就交出了一份“Day0 全量适配多芯片”的成绩单。目前,Qwen3.6-35B-A3B 已在平头哥、华为、海光、沐曦、昆仑芯、天数、英伟达等多种 AI芯片上完成基于众智FlagOS统一、开源技术栈的多芯适配、精度对齐与部署验证,开发者可直接获取对应芯片的开箱即用方案。
Qwen3.6-35B-A3B 是一个完全开源的稀疏 MoE 模型(总参数 35B / 激活参数 3B),在智能体编程方面表现卓越,大幅超越前代 Qwen3.5-35B-A3B,并可与 Qwen3.5-27B、Gemma4-31B 等稠密模型一较高下。主要特性包括:
-
卓越的智能体编程能力,可与大得多的模型相媲美
-
强大的多模态感知与推理能力
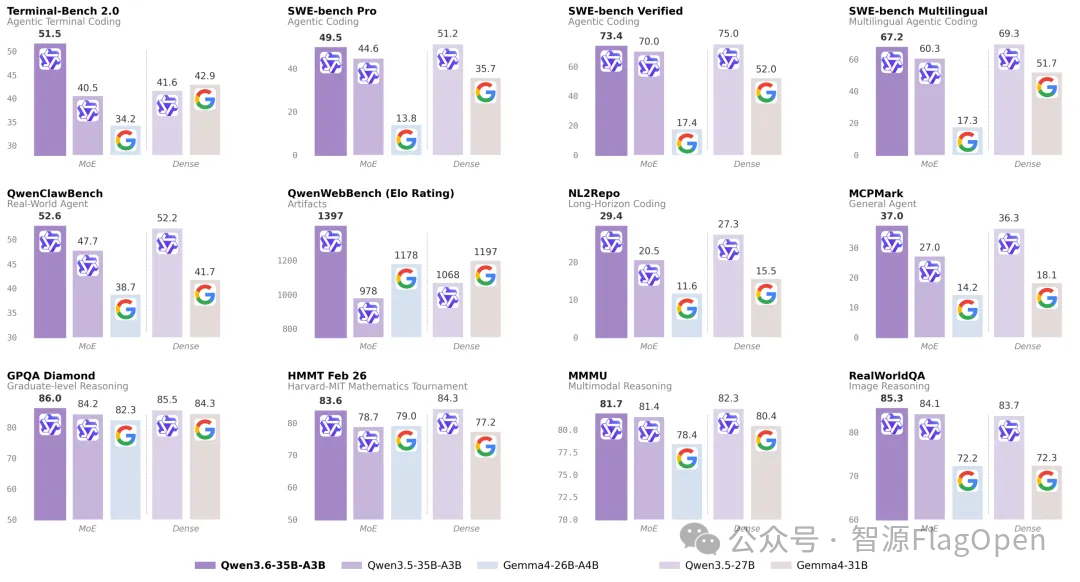
本次Qwen3.5升级到Qwen3.6,模型结构等并没有明显变化。由于此前FlagOS已经适配过英伟达、平头哥、海光、沐曦、天数等五款芯片,所以本次适配更多的是针对昆仑芯、华为这两款新增芯片完成,并针对新的模型权重重新进行一致性测试。基于FlagOS建立的从编译器、算子库、多芯片框架统一plugin等技术,FlagOS团队可以快速完成模型适配、跨芯迁移验证、精度对齐评测、开源版本发布等重要步骤。
开发者速用指南:Qwen3.6-35B-A3B 新模型多芯版本一键获取与部署
FlagOS 为 Qwen3.6-35B-A3B 新模型提供了统一支持多种 AI 芯片的 vLLM 插件--vLLM-plugin-FL,在保证高效推理的同时,为用户提供开箱即用的跨芯片 Qwen3.6-35B-A3B 版本。目前在 vLLM-plugin-FL 的支持下,平头哥、昆仑芯、天数、海光、华为昇腾、沐曦等多种 AI 芯片已经通过插件方式实现"零代码修改" 完成 Qwen3.6-35B-A3B 的推理部署及充分验证。使用源码进行安装部署,可参考以下官方一站式开发者文档,含详细代码示例与操作指引:
-
GitHub:
https://github.com/flagos-ai/vllm-plugin-FL/blob/main/README.md
-
GitCode:
https://gitcode.com/flagos-ai/vllm-plugin-FL/blob/main/README.md
快速安装
# 1. 安装 vLLM v0.13.0
pip install vllm==0.13.0
# 2. 安装 vllm-plugin-FL
git clone -b v0.1.0 https://github.com/flagos-ai/vllm-plugin-FL
cd vllm-plugin-FL
pip install --no-build-isolation -e .
# 3. 安装 FlagGems
git clone https://github.com/flagos-ai/FlagGems
cd FlagGems && git checkout v5.0.0
pip install --no-build-isolation -e .
# 4. (可选) 安装 FlagCX 统一通信库
# 详见 https://github.com/flagos-ai/FlagCX运行推理
from vllm import LLM, SamplingParams
prompts = ["Hello, my name is"]
sampling_params = SamplingParams(max_tokens=10, temperature=0.0)
llm = LLM(model="FlagRelease/Qwen3.6-35B-A3B-nomtp-nvidia-FlagOS",
max_num_batched_tokens=16384,
max_num_seqs=2048)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
print(f"Prompt: {output.prompt!r}")
print(f"Generated: {output.outputs[0].text!r}")如果环境中存在多个 vLLM 插件,可通过环境变量指定:
export VLLM_PLUGINS='fl'用户也可以直接拉取在 FlagRelease 上发布的迁移后的模型文件、代码和镜像。以下是迁移适配后的几种 AI 芯片的模型版本,开箱即用、无需迁移。
魔搭平台
|
芯片 |
模型 |
下载链接 |
|---|---|---|
|
英伟达 |
Qwen3.6-35B-A3B |
https://modelscope.cn/models/FlagRelease/Qwen3.6-35B-A3B-nomtp-nvidia-FlagOS |
|
沐曦 |
https://modelscope.cn/models/FlagRelease/Qwen3.6-35B-A3B-nomtp-metax-FlagOS |
|
|
海光 |
https://modelscope.cn/models/FlagRelease/Qwen3.6-35B-A3B-nomtp-hygon-FlagOS |
|
|
平头哥 |
https://modelscope.cn/models/FlagRelease/Qwen3.6-35B-A3B-nomtp-zhenwu-FlagOS |
|
|
昆仑芯 |
https://modelscope.cn/models/FlagRelease/Qwen3.6-35B-A3B-nomtp-kunlunxin-FlagOS |
|
|
华为 |
https://modelscope.cn/models/FlagRelease/Qwen3.6-35B-A3B-nomtp-ascend-FlagOS |
|
|
天数 |
https://modelscope.cn/models/FlagRelease/Qwen3.6-35B-A3B-nomtp-iluvatar-FlagOS |
HuggingFace 平台
|
芯片 |
模型 |
下载链接 |
|---|---|---|
|
英伟达 |
Qwen3.6-35B-A3B |
https://huggingface.co/FlagRelease/Qwen3.6-35B-A3B-nomtp-nvidia-FlagOS |
|
沐曦 |
https://huggingface.co/FlagRelease/Qwen3.6-35B-A3B-nomtp-metax-FlagOS |
|
|
海光 |
https://huggingface.co/FlagRelease/Qwen3.6-35B-A3B-nomtp-hygon-FlagOS |
|
|
平头哥 |
https://huggingface.co/FlagRelease/Qwen3.6-35B-A3B-nomtp-zhenwu-FlagOS |
|
|
昆仑芯 |
https://huggingface.co/FlagRelease/Qwen3.6-35B-A3B-nomtp-kunlunxin-FlagOS |
|
|
华为 |
https://huggingface.co/FlagRelease/Qwen3.6-35B-A3B-nomtp-ascend-FlagOS |
|
|
天数 |
https://huggingface.co/FlagRelease/Qwen3.6-35B-A3B-nomtp-iluvatar-FlagOS |
开发者极致体验:"发布即多芯" + "零改码"
Qwen3.6-35B-A3B 新模型的跨芯适配版本从开发到部署,全程围绕开发者友好设计,解决了大模型落地过程中多芯片适配复杂、推理框架割裂、精度对齐困难、部署成本高等四大核心痛点,让开发者真正实现"一次开发,多芯运行"。
1. 零改码适配:不改变原有开发与调用习惯
无论是模型原有接口、vLLM 推理引擎使用逻辑,还是开发者的日常调用代码,均无需做任何修改。FlagOS 通过底层插件与算子替换实现适配,开发者专注业务开发即可,无需重新学习硬件相关开发知识,大幅降低迁移与部署门槛。
2. 核心能力与原生版本对齐
经 GPQA_Diamond、ERQA等权威评测集验证,FlagOS 适配后的 Qwen3.6-35B-A3B,在 Agentic Coding 能力、复杂推理等核心能力上,与 CUDA 原生版本对齐,可放心应用于代码生成、日志分析、Bug 排查、复杂文档编辑等生产场景,无需担心适配导致业务效果折损。
特意说明,为了能在统一的实测环节中对齐迁移前后的精度,我们对模型的英伟达CUDA版本也进行了重新测试。但由于使用的prompt、过滤规则等并未进行细致优化(也不是本次验证的重点),所以导致“NV-原生”的实测效果在GPQA_Diamond数据集上略低。所以,本测试结果仅用于在同一测试环境下的对齐验证,并不代表Qwen模型的官方性能。Qwen 模型的官方性能以 Qwen 官方公布数据为准。
评测数据:

注:由于华为、天数智芯的硬件评测开始较晚,目前只完成了一部分的测试,我们将持续更新结果
3. 极简部署:开箱即用,底层优化无感知
FlagOS 将核心算子库、编译器等技术组件前置内置到 Qwen3.6-35B-A3B 代码框架中,开发者加载官方模型时,底层优化代码自动生效,无需手动添加任何 FlagOS 初始化代码。同时,基于 FlagOS 的大模型跨芯半自动迁移及发版工具 FlagRelease,直接提供了多芯片版本的 Qwen3.6-35B-A3B-FlagOS 模型版本,无需用户迁移,真正实现"开箱即用";同时标准化 Docker 镜像 + 一键加速命令,解决了开发者最头疼的环境配置、效果对齐、性能优化等问题。
大模型核心基座:FlagOS 四大技术支撑,实现 Qwen3.6-35B-A3B 极速跨芯适配
Qwen3.6-35B-A3B 新模型能实现"发布即多芯"并非偶然,而是依托众智 FlagOS 打造的统一多芯片 AI 系统软件栈,从算子层、编译层、框架层到工具层,全链路为大模型跨芯适配提供技术支撑,将原本数周的适配周期缩短至数天,真正实现极速落地。
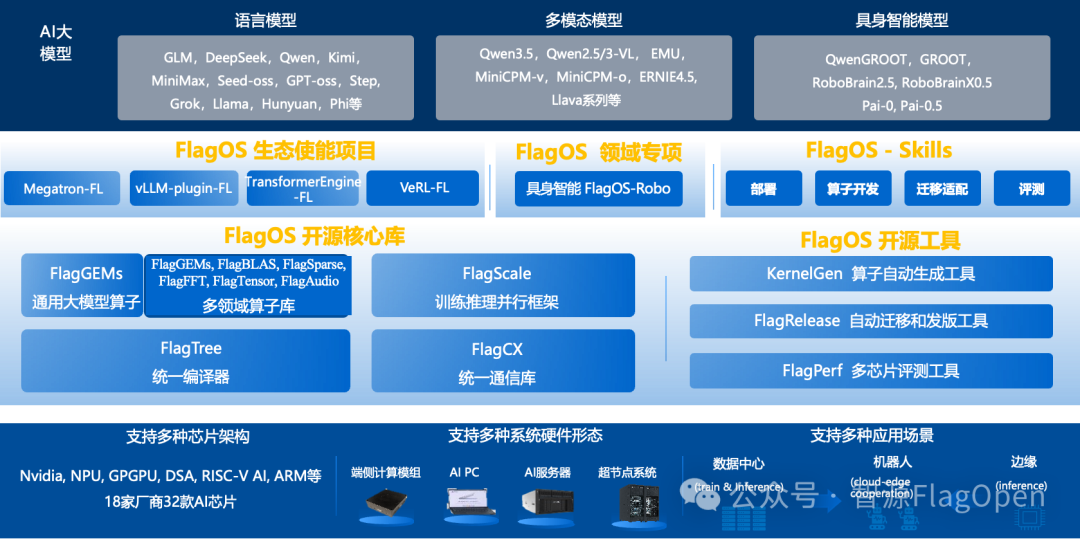
FlagOS:面向多种 AI 芯片的系统软件栈
1. 统一多芯片接入插件 vLLM-plugin-FL:无缝兼容原生使用习惯
vLLM-plugin-FL 是 FlagOS 为 vLLM 推理服务框架打造的专属插件,基于 FlagOS 统一多芯片后端开发,在完全不改变 vLLM 原生接口与用户使用习惯的前提下,实现 Qwen3.6-35B-A3B 的多芯片推理部署。目前 vLLM-plugin-FL 已经支持了英伟达、摩尔线程、海光、沐曦、平头哥真武、天数智芯等多家芯片。
2. 高性能算子库 FlagGems:核心算子深度适配,释放硬件算力
FlagGems 作为 FlagOS 核心的高性能通用大模型算子库,基于 Triton 语言实现,针对 Qwen3.6-35B-A3B 推理链路的核心算子进行了深度适配与优化,包括 MoE 专家调度、Attention 计算、RMSNorm 等关键计算模块,同时原生支持 NVIDIA、摩尔线程、沐曦、清微智能、天数等接近 20 家 AI 芯片。
3. 统一 AI 编译器 FlagTree:一次编写,多芯编译
FlagTree 是 FlagOS 面向多 AI 芯片后端的统一编译器,基于 Triton 深度定制,可将 Qwen3.6-35B-A3B 的核心算子编译为英伟达、摩尔线程等十多种不同 AI 芯片后端可识别的指令,彻底解决不同芯片编译器生态割裂的问题,大幅降低算子跨芯片适配的开发成本。
4. 模型跨芯迁移发布工具 FlagRelease:半自动实现模型跨芯迁移与版本发布
依托 FlagOS 全栈技术能力,FlagRelease 已完成 Qwen3.6-35B-A3B 在多种芯片上的模型迁移、精度对齐与版本发布,覆盖 HuggingFace、魔搭等开源社区平台。开发者可直接下载使用,无需自行迁移。截至本文发布,FlagRelease 已发布覆盖 10+ 家芯片厂商、12+ 款硬件、70+ 个开源模型实例的跨芯适配版本。
开源共建:FlagOS 持续做开发者的"跨芯适配后盾"
当下,"异构算力协同、大模型普惠落地"已成为全球开源开发者社区的核心热点,打破硬件生态隔离、让大模型在不同算力平台高效低成本运行,是无数开发者的核心诉求。FlagOS 从诞生之初就将开源开放、众智共建刻入技术基因,始终以开发者为中心,通过全栈开源的统一系统软件栈,把复杂的"M×N"硬件适配问题降维为"M+N",做每一位开发者最可靠的跨芯适配后盾。
全栈开源无保留,把技术主动权交给开发者
目前,FlagOS 已形成完整的开源技术体系,所有核心组件均已开源在 GitHub,同时开放了数十款最新的主流基础大模型、十多款 AI 芯片的适配方案与最佳实践,开发者可自由获取、深度定制:
-
四大核心技术库: FlagGems 通用大模型算子库、FlagTree 统一 AI 编译器、FlagScale 训练推理并行框架、FlagCX 统一通信库,覆盖算子开发、编译优化、并行计算、跨芯片通信全链路;
-
三大开源工具平台: FlagRelease 大模型自动迁移发版平台、KernelGen 算子自动生成工具、FlagPerf 多芯片评测工具,提供从模型适配、性能评测到工程落地的一站式工具链;
-
全场景扩展生态: vLLM-plugin-FL、Megatron-LM-FL、TransformerEngine-FL 等框架增强组件,以及 FlagOS-Robo 具身智能工具包,覆盖大模型训练、推理、应用全场景。
多路径参与共建,全层级开发者均可入局
我们为不同技术方向、不同经验层级的开发者,设计了低门槛、多路径的共建方式,无论你是 AI 开发新手,还是深耕系统软件的资深专家,都能在 FlagOS 社区找到自己的位置。
-
新手友好型参与: 可在对应仓库提交 Issue 反馈 bug、优化建议,或是补充完善文档、撰写入门教程与最佳实践,也可参与社区技术交流、分享使用经验,零门槛开启开源之旅;(社区文档参考:https://docs.flagos.io/en/latest/)
-
深度技术共建: 开发者可直接参与 FlagGems 算子开发与优化(新增算子 / 性能调优 / 新芯片后端支持)、KernelGen 算子生成流程增强、FlagTree 编译器后端扩展等核心模块,与社区核心开发者一起推动技术演进。
-
生态工具贡献: 开发者可基于 FlagOS Skills 开发面向国产芯片的 AI Agent 专业技能,帮助更多开发者通过自然语言完成芯片适配、模型部署等操作。
关于众智FlagOS社区
为解决不同 AI 芯片大规模落地应用,北京智源研究院联合众多科研机构、芯片企业、系统厂商、算法和软件相关单位等国内外机构共同发起并创立了众智 FlagOS 社区。成员单位包括北京智源研究院、中科院计算所、中科加禾、安谋科技、北京大学、北京师范大学、百度飞桨、硅基流动、寒武纪、海光信息、华为、基流科技、摩尔线程、沐曦科技、澎峰科技、清微智能、天数智芯、先进编译实验室、移动研究院、中国矿业大学(北京)等多家在 FlagOS 软件栈研发中做出卓越贡献的单位。
FlagOS 是一款专为异构 AI 芯片打造的开源、统一系统软件栈,支持 AI 模型一次开发即可无缝移植至各类硬件平台,大幅降低迁移与适配成本。它包括大型算子库、统一AI编译器、并行训推框架、统一通信库等核心开源项目,致力于构建「模型-系统-芯片」三层贯通的开放技术生态,通过“一次开发跨芯迁移”释放硬件计算潜力,打破不同芯片软件栈之间生态隔离。
官网:https://flagos.io
GitHub 项目地址:
https://github.com/flagos-ai
GitCode 项目地址:
https://gitcode.com/flagos-ai
SkillHub:https://skillhub.flagos.io

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)