
多层感知机(MLP):深度学习中的基础构建模块
本文将系统介绍 MLP 的结构原理、核心特性、典型应用场景,并结合昇腾 NPU 的硬件优势,探讨其在实际部署中的优化路径。
作者:昇腾实战派 * Ming_L
关注公众号:AI模力圈
背景概述
在深度学习的发展历程中,多层感知机(Multi-Layer Perceptron, MLP)作为最早期且最具代表性的神经网络结构之一,奠定了现代深度学习的理论基础。尽管近年来模型架构不断演进,MLP 仍广泛应用于各类任务中,尤其在特征提取、非线性建模与维度变换等场景中发挥着核心作用。随着模型规模的持续扩大,如何高效实现 MLP 的全连接层计算,成为影响训练效率与推理性能的关键挑战。
本文将系统介绍 MLP 的结构原理、核心特性、典型应用场景,并结合昇腾 NPU 的硬件优势,探讨其在实际部署中的优化路径。
一、MLP 基本结构与核心特性
多层感知机由输入层、一个或多个隐藏层以及输出层构成,是最基础的前馈神经网络(Feed-Forward Network, FFN)形式。其典型结构如下图所示,为单隐藏层的最简 MLP 模型:
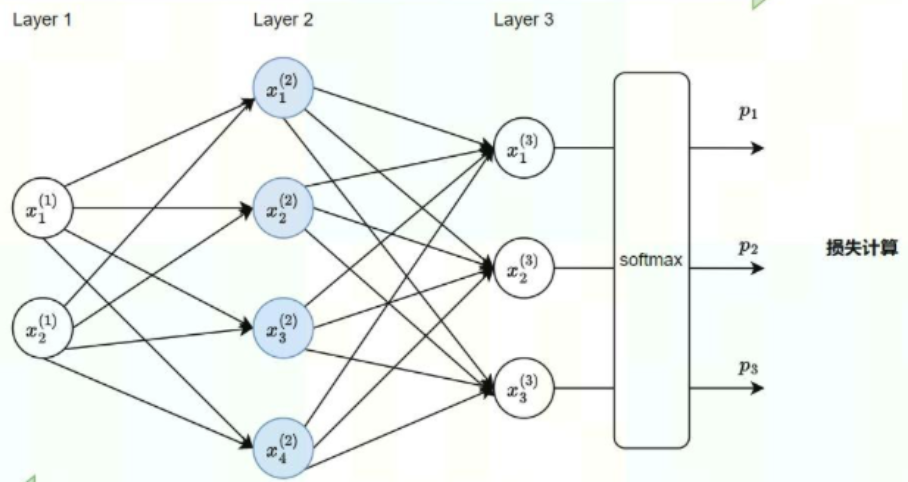
核心特性
- 多层结构
MLP 至少包含三层:输入层、至少一个隐藏层、输出层。隐藏层数量可灵活扩展,通常在两层及以上以增强模型表达能力。 - 全连接设计
每一层的神经元与上一层所有神经元实现完全连接,形成密集的权重矩阵。该结构支持全局信息交互,但同时也带来较高的参数量与计算开销。 - 非线性激活函数
全连接操作本身为线性变换,无法拟合复杂非线性关系。因此,在每一层输出后引入非线性激活函数(如 ReLU、tanh、sigmoid),使网络具备学习复杂模式的能力。 - 训练机制
采用反向传播算法(Backpropagation)结合优化器(如 SGD、Adam)进行参数更新,通过最小化损失函数实现模型学习。
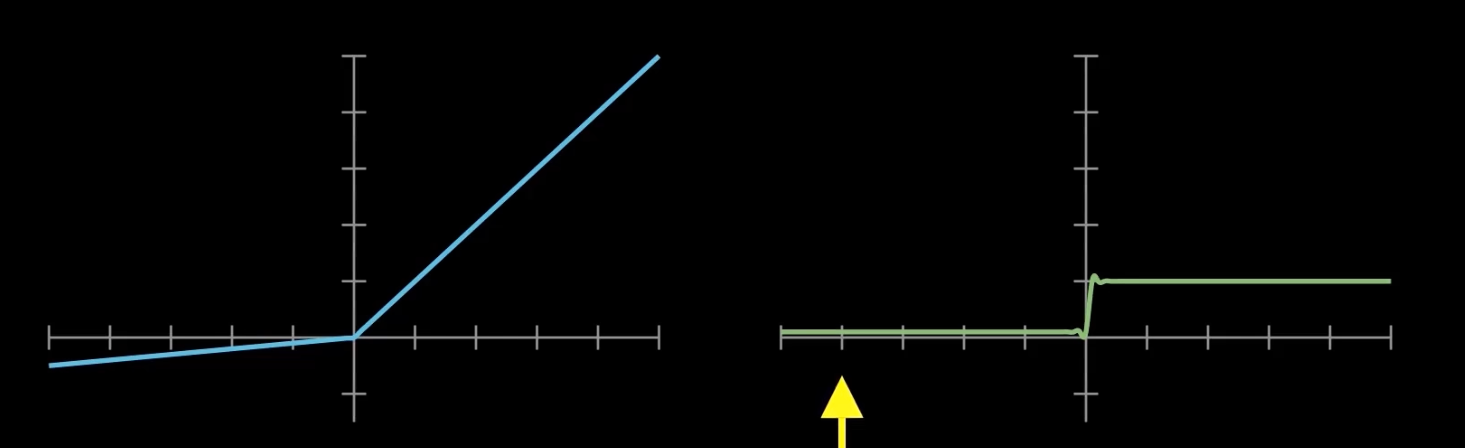
二、常见激活函数对比分析
由于线性层无法捕捉非线性特征,激活函数是 MLP 实现复杂建模能力的关键。以下是几种主流激活函数的特性分析:
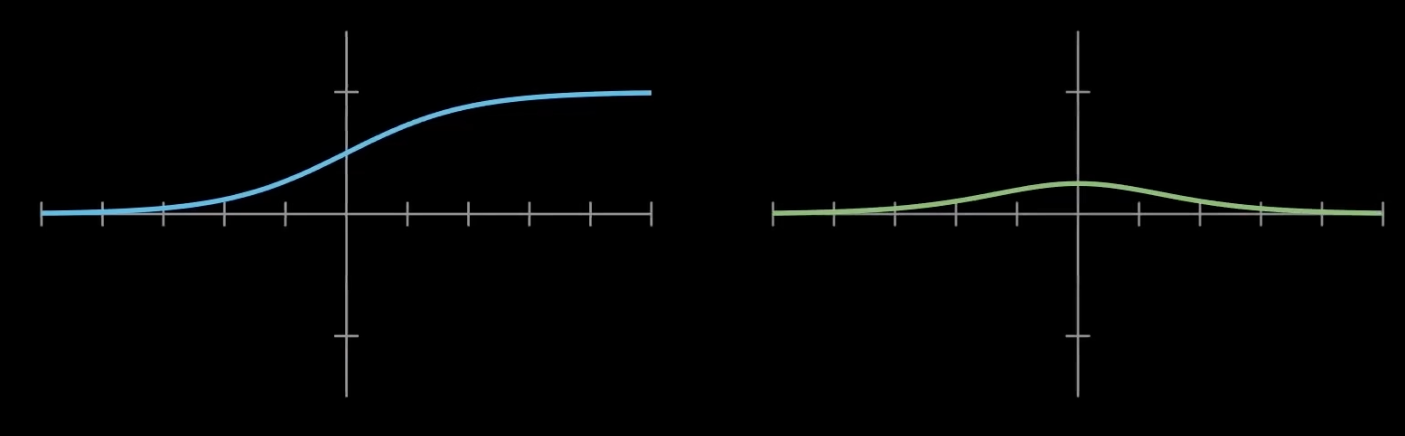
Sigmoid
- 特点:输出范围为 (0, 1),适用于二分类输出。
- 问题:在输入极大或极小时梯度趋近于零,易引发梯度消失,影响训练收敛速度。
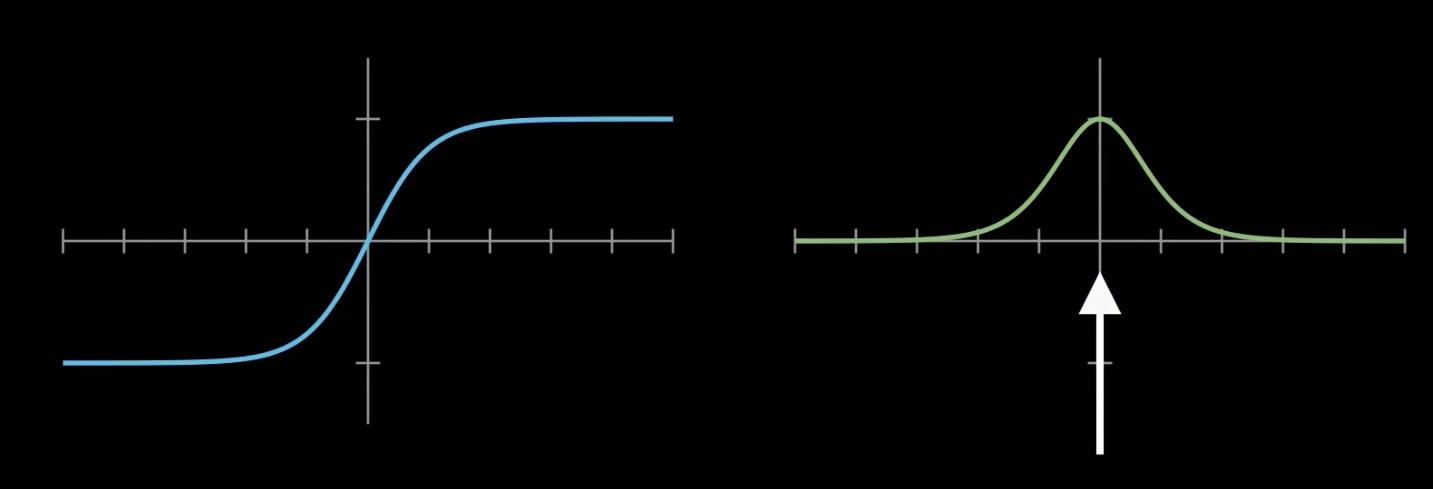
Tanh
- 特点:输出范围为 (-1, 1),中心对称,有助于加速收敛。
- 问题:仍存在输入极端时梯度趋零的问题,且计算成本略高于 ReLU。
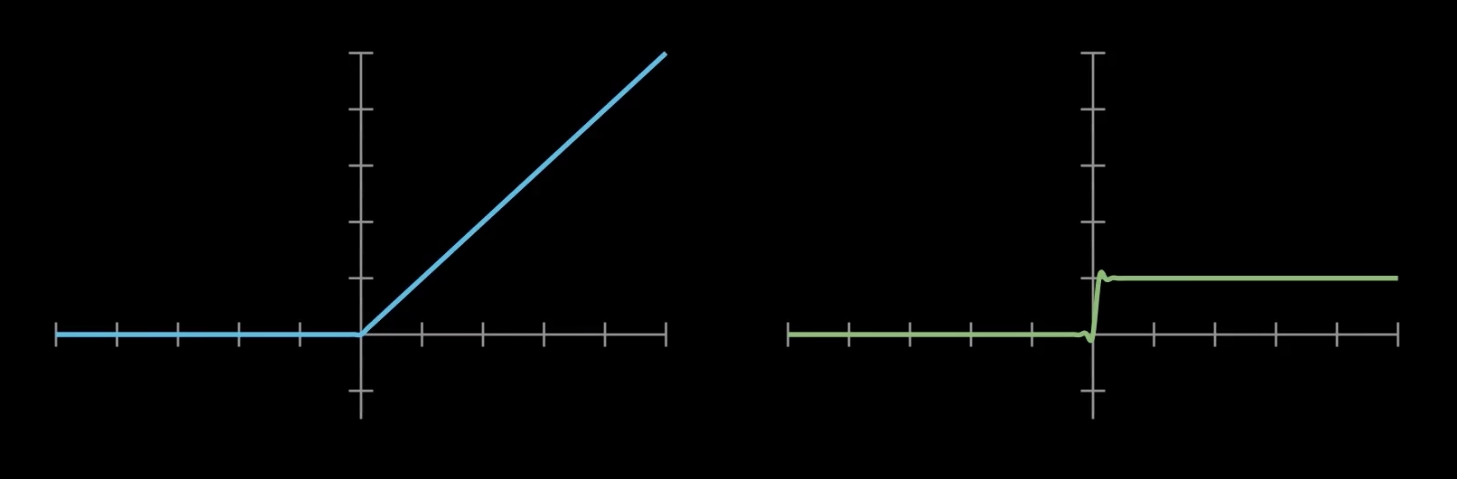
ReLU(Rectified Linear Unit)
- 特点:计算简单,有效缓解梯度消失问题,广泛用于隐藏层。
- 问题:负半轴输出恒为零,可能导致神经元“死亡”。
Leaky ReLU
- 特点:在负区间引入小斜率(如 0.01),避免神经元“死亡”问题,兼顾稳定性与非线性表达。
- 优势:在复杂任务中表现更鲁棒。
三、典型应用场景
MLP 作为通用函数逼近器,在多种任务中展现出强大适应性:
- 非线性分类
可有效处理线性不可分数据,如 MNIST 手写数字识别、图像分类等任务。 - 回归预测
适用于连续值输出场景,如房价预测、股票走势建模等。 - 模式识别与特征学习
在语音识别、人脸识别等任务中,通过多层非线性变换提取高级语义特征。 - 序列数据建模(变体支持)
虽传统 MLP 不直接支持序列建模,但可通过与 CNN、RNN 结合,用于时间序列分析与自然语言处理。 - 噪声鲁棒性处理
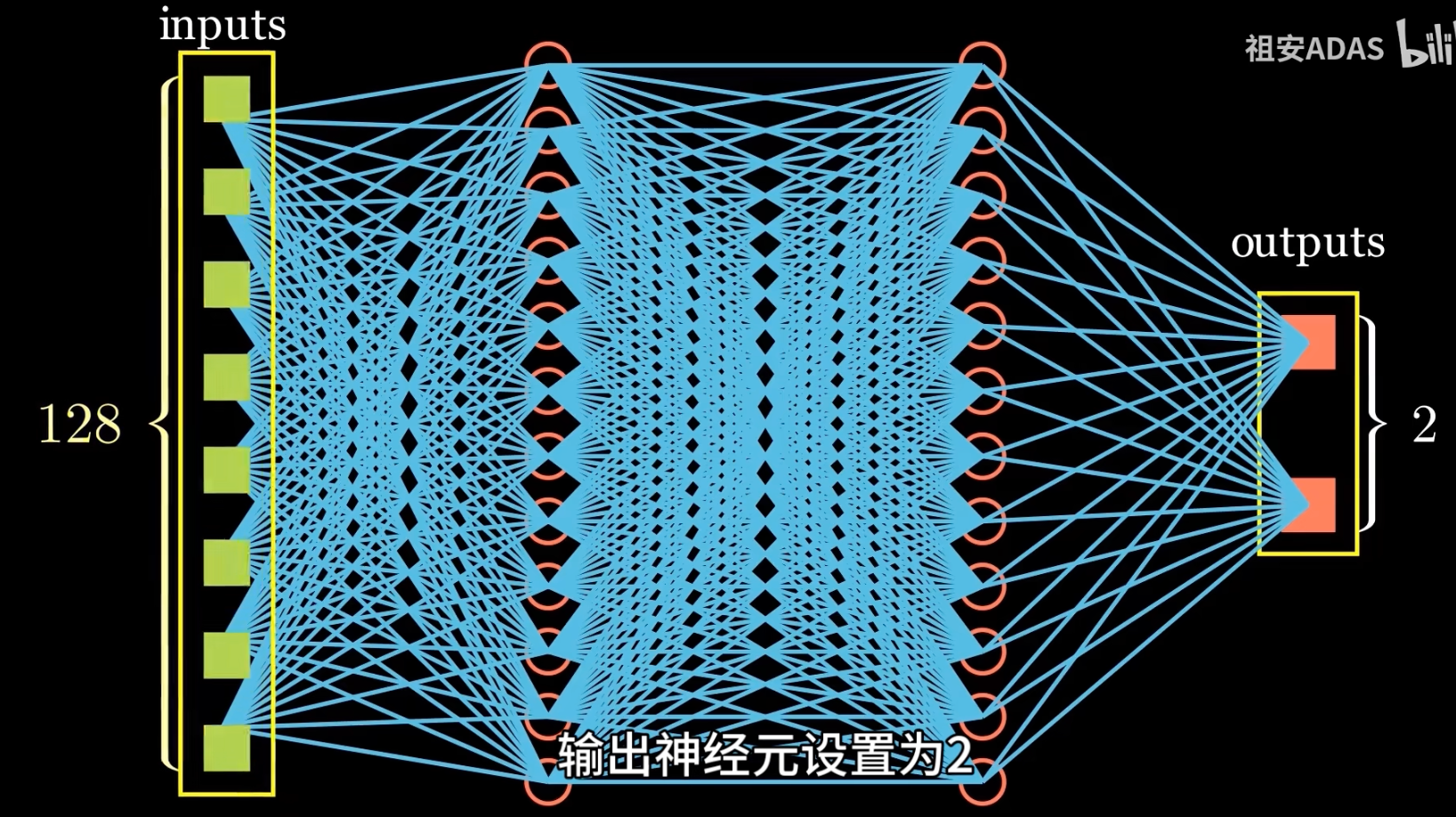
经过充分训练后,MLP 能在含噪声数据中保持良好泛化能力。 - 张量维度对齐
常用于实现输入与输出维度的映射转换,例如将 128 维向量映射为 2 维输出:
四、高性能部署:基于昇腾 NPU 的加速实践
尽管 MLP 理论简洁,其核心计算——密集矩阵乘法(GEMM)——在面对大规模模型与海量数据时,对底层算力提出极高要求。为应对这一挑战,华为昇腾(Ascend)NPU 依托自研达芬奇架构,内置专用 Cube 计算单元,专为高吞吐矩阵运算优化,天然适配 MLP 中的全连接层计算。
通过 CANN 计算架构的深度优化,昇腾平台可显著提升 MLP 的训练与推理效率。开发者可借助 MindSpore 框架,快速构建并部署基于昇腾硬件的神经网络模型:
推荐实践:
MindSpore 基础网络构建实战
—— 内含基于昇腾环境的经典神经网络实现与跑通示例,涵盖 MLP、Transformer 等主流结构。
五、小结
多层感知机作为深度学习的基石,凭借其简洁而强大的非线性建模能力,持续在各类 AI 任务中扮演关键角色。随着模型复杂度提升,高效执行 MLP 的全连接计算成为性能瓶颈。借助昇腾 NPU 的硬件加速能力与 MindSpore 框架的生态支持,开发者可实现从模型设计到高性能部署的全链路优化,为构建下一代智能系统提供坚实支撑。
如果你对多模态大模型、强化学习、昇腾 NPU 部署、模型性能优化感兴趣,欢迎持续关注【AI模力圈】。
我们会持续更新:
- 多模态模型结构拆解
- 强化学习算法原理与实践
- 昇腾 NPU 迁移部署与踩坑复盘
- 模型训练与推理性能优化
图解版、速读版内容也会同步更新到公众号 / 小红书。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐



 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)