
2.5倍性能提升!看Triton-TLE如何用Compute-Shift GEMM释放清微RPU算力
作为FlagOS开源生态的核心组件,FlagTree致力于构建一个支持Triton语言、面向多种AI硬件架构的增强型编译器,通过统一的代码仓库和多后端支持机制,让开发者能够“一次开发,跨芯迁移”。Triton-TLE在保持与标准Triton语言兼容的同时,为用户提供三个层次的语言扩展,将单点的语言能力拓展到一个可以兼顾高性能、高开发效率及多架构适配的更广阔的多维空间。它的核心是RT,每个RT包含独
AI 芯片百花齐放,如何用一套统一的编程语言高效驾驭不同架构的硬件,始终是开发者面临的核心挑战。Triton语言凭借其优秀的可移植性获得了广泛关注,但当面对清微(TsingMicro)RPU这类具有分布式存储与计算流架构的芯片时,标准Triton的表达能力就显得力不从心了
这正是FlagTree统一AI编译器试图解决的问题。作为FlagOS开源生态的核心组件,FlagTree致力于构建一个支持Triton语言、面向多种AI硬件架构的增强型编译器,通过统一的代码仓库和多后端支持机制,让开发者能够“一次开发,跨芯迁移”。在此基础上,推出了Triton-TLE(Triton Language Extensions)——Triton的语言扩展体系。Triton-TLE在保持与标准Triton语言兼容的同时,为用户提供三个层次的语言扩展,将单点的语言能力拓展到一个可以兼顾高性能、高开发效率及多架构适配的更广阔的多维空间。
本次,我们将展示清微智能如何基于Triton-TLE,实现Compute-Shift GEMM计算模式,通过将硬件特性自然融入高层编程模型,让开发者用熟悉的语言,轻松发挥芯片硬件极致性能!
瓶颈:当传统GEMM算子遇上分布式数据流架构
清微的RPU(可重构处理单元)采用了一种独特的循环存储与计算相结合的数据流架构。其核心组件包括:
RT(Reconfigurable Tile): 图中的 T 表示一个 RT。每个 RT 内部包含用于 Tensor 和 Vector 计算的 CGRA 单元,以及一部分 Scratchpad Memory(SPM)。RT 是 RPU 的基本计算与存储单元,不同 RT 之间可以进行数据通信。
NoC(Network on Chip): NoC 负责 RT、高速 IO 和存储设备之间的片上互联,是数据传输的核心通道。
LPDDR : LPDDR 是片外存储器,用于在片上存储空间不足时提供更大的容量支持。
High-speed IO : High-speed IO 用于实现芯片之间的高速互联,支持跨芯片的数据传输与协同计算。
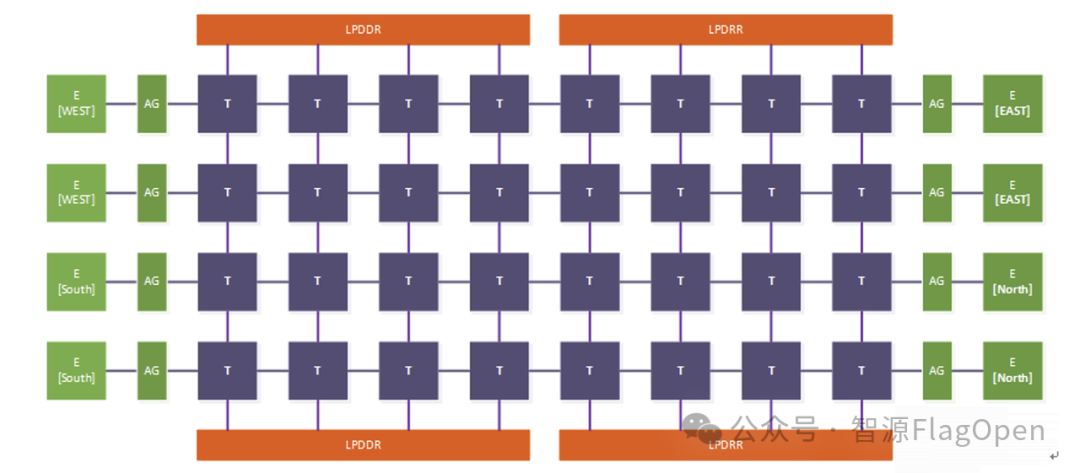
它的核心是RT,每个RT包含独立的计算单元(CGRA)和SPM,RT之间通过NoC高速互联,形成分布式存储 + 分布式计算的体系结构。
这种分布式架构虽然优势明显,但也对算子实现提出了新的要求。由于每个RT的SPM容量有限,对于大 shape的GEMM往往需要多次计算,这就导致需要反复从LPDDR搬运数据,使得片外带宽成为性能瓶颈。
考虑一种最朴素的情况,一个AxB->C的矩阵乘, 如果只对左矩阵进行空间维度上的切分,则大概情况如下图所示:每个RT各自加载一整份右矩阵到本地SPM。若有16个RT,右矩阵对LPDDR的读取量就被放大了16倍。
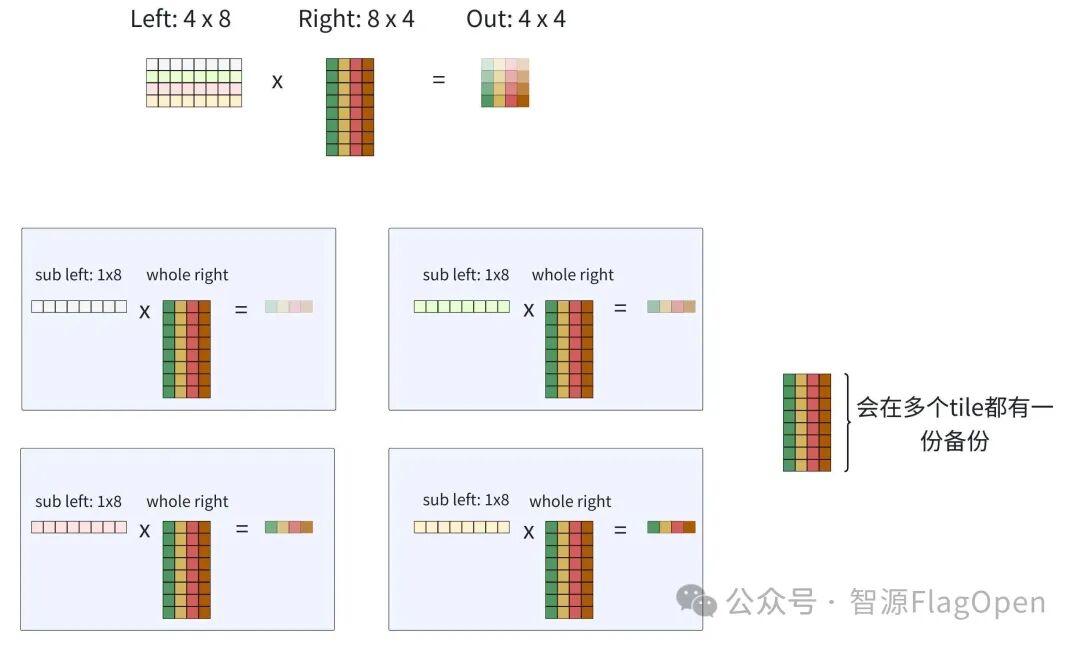
LPDDR 带宽迅速成为瓶颈,片上算力再强也难以充分释放。问题的本质在于:数据复用被忽视,RT间的高速互联未被用于削减外部访存。
破局:Compute-Shift GEMM的计算与通信协同
要突破这一瓶颈,就需要根据架构特点调整计算模式——让GEMM算子以RT协同的方式展开,每个RT在本地完成一部分计算的同时,将下一步所需的数据分片传递给其他RT。
这种将本地计算与RT间数据流转结合起来的执行方式,我们称之为Compute-Shift GEMM。其核心思想是 “compute + shift”协同进行,即一边计算、一边通信,从而提升片上数据复用率并降低外部访存压力。具体流程如下:
Step 0: 每个Tile Load一份右矩阵的子块, 计算得到当前输出的一部分;
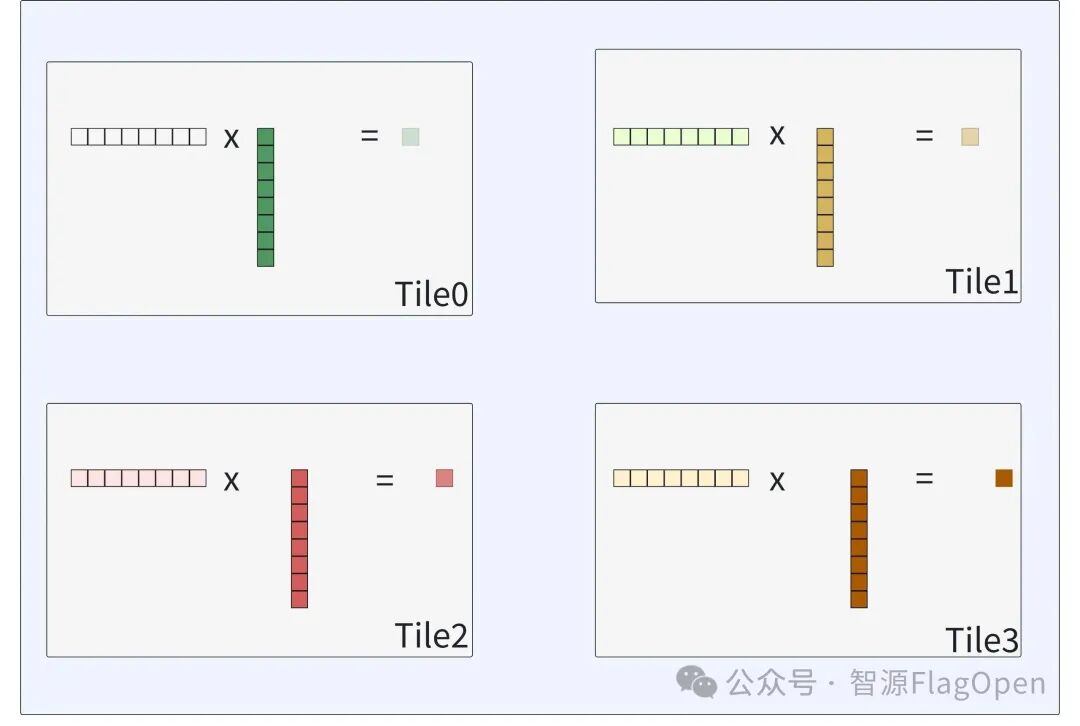
Step 1: 将当前加载的右矩阵子块通过Noc发送到下一个RT;
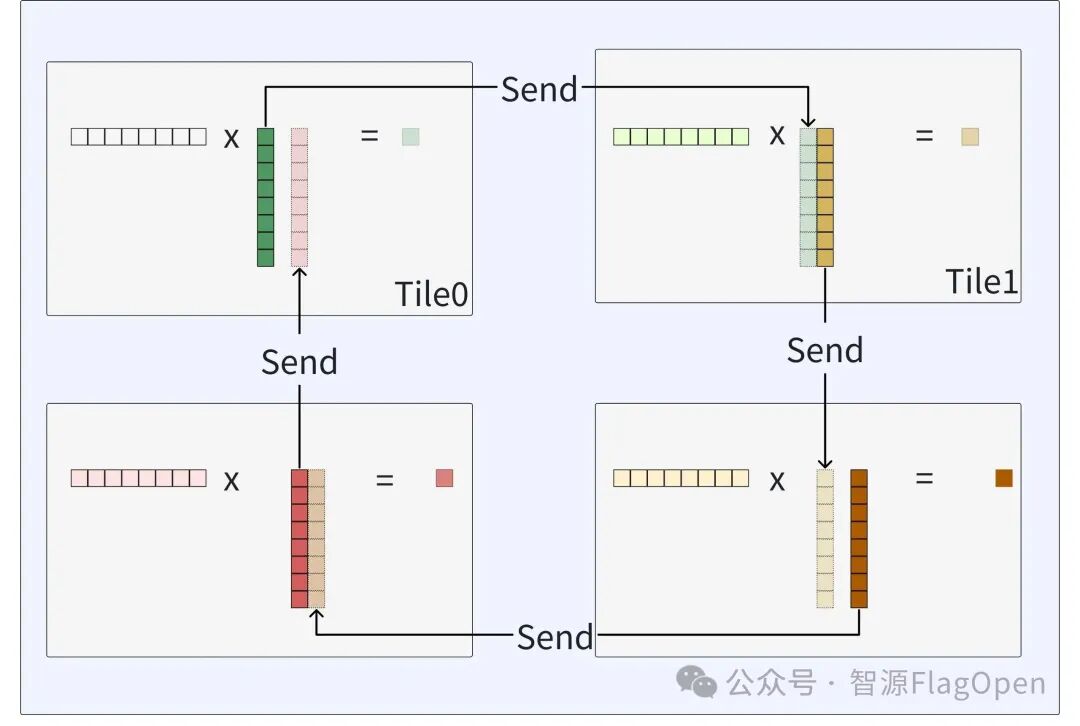
Step 2: 接收到上一个Tile发送到数据,和已加载到左矩阵做Compute得到部分输出;
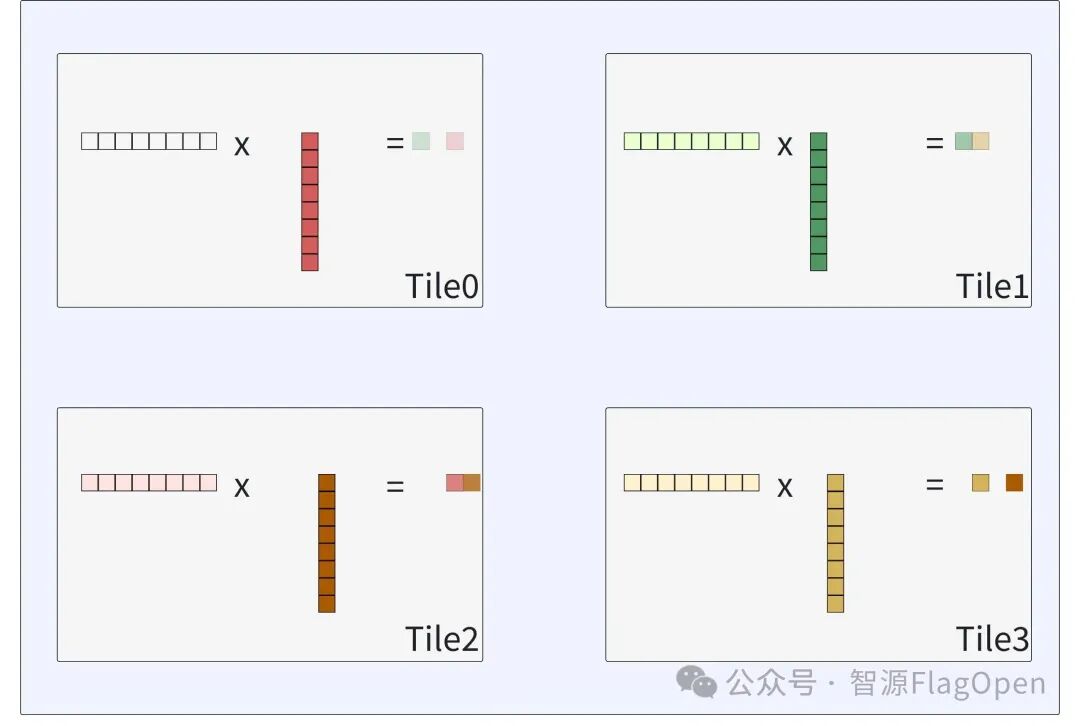
Step 3: 重复上述行为,直到一个RT获取完所有的右矩阵子块,完整流程如下:
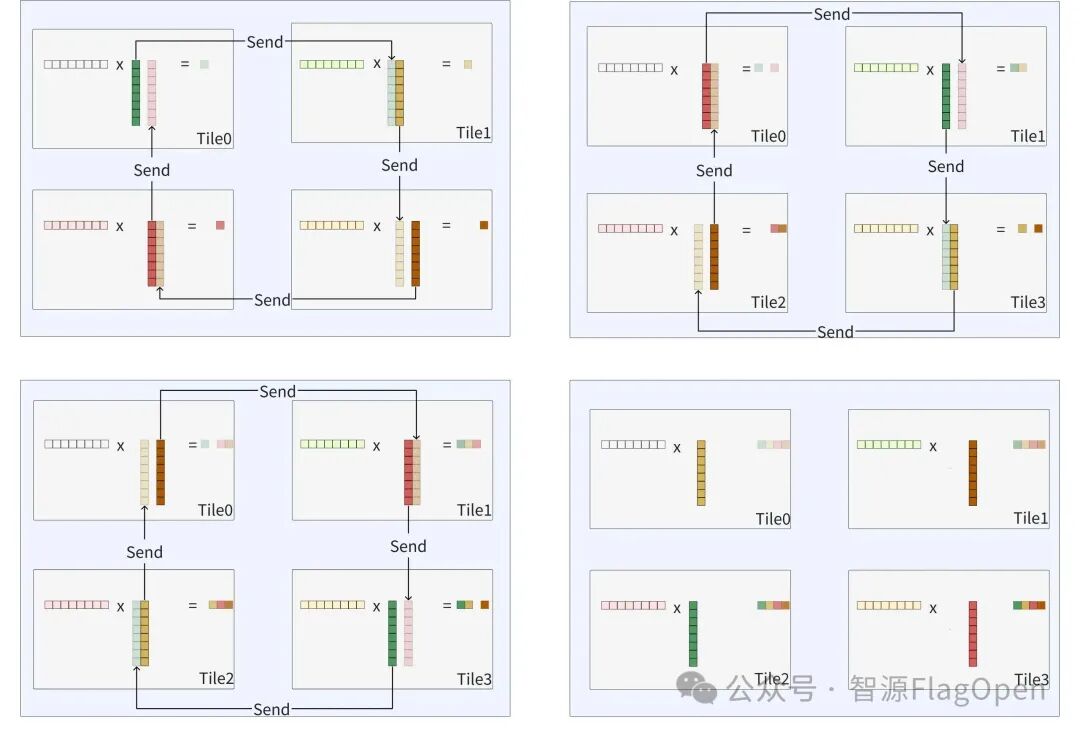
这种模式用片上通信换取了外部访存的大幅削减,尤其适合大Shape场景,能够有效缓解LPDDR带宽压力。
落地:Triton-TLE如何将硬件特性融入高层编程模型
实现Compute-Shift GEMM需要解决一个核心问题:如何在高层编程模型中自然地描述“RT 间数据流动”,而不陷入底层硬件细节?而这正是Triton-TLE的价值所在。
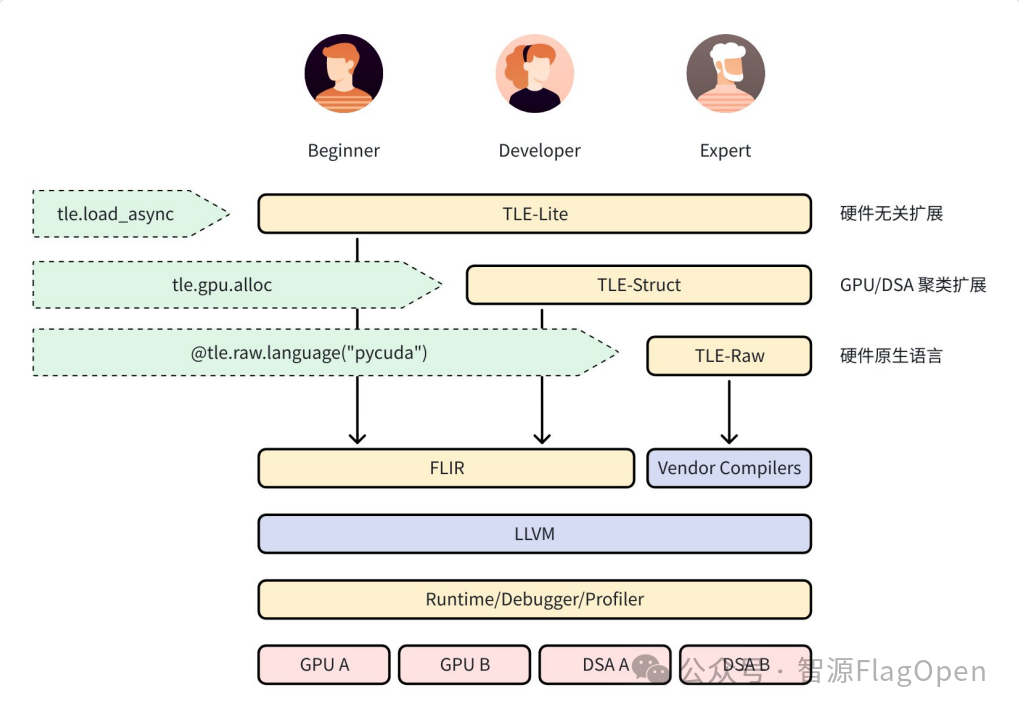
Triton-TLE 三层接口
Triton-TLE 提供了三种架构的接口抽象,满足不同背景的开发者需求:
TLE-Lite:对 Triton 的轻量级扩展,所有特性兼容各类硬件后端,仅需对原有 Triton kernels 少量修改即可拿到大幅性能提升。主要面向算法工程师和快速性能优化场景。
TLE-Struct:按硬件的架构聚类抽象,分类(如 GPGPU、DSA)提供扩展,满足进一步性能优化的需求。需要开发人员对目标硬件的特性和优化技巧有一定了解。
TLE-Raw:提供对硬件最直接的控制,支持使用硬件厂商的原生编程语言获取最极致的性能。需要开发人员对目标硬件的深入了解,主要面向性能优化专家。
其中 TLE-Lite 和 TLE-Struct 会通过 FLIR最终 Lowering到 LLVM IR,而TLE-Raw 则通过语言对应的编译管线(如厂商的私有编译器)Lowering到 LLVM IR。最后它们会被 Link到一起,共同生成一个完整的 kernel供 Runtime 加载和执行。
核心原语:从“标记”到“通信”
Triton-TLE目前已实现了部分公用接口用于做通信模式的描述, 为了实现上述的Compute-Shift GEMM计算模式, 清微智能复用了Triton-TLE 中已有的通信接口语义,并对其后端Lowering做了合适的适配,主要采用到的接口大致有:
-
tle.dsa.alloc(...)
-
tle.dsa.local_ptr(...)
-
tle.remote()...
-
tl.store(...) #搭配remote pointer
-
tle.dsa.alloc
tle.dsa.alloc
tle.dsa.alloc用于在spm上分配一块buffer, 后续用于存储接收到的数据。
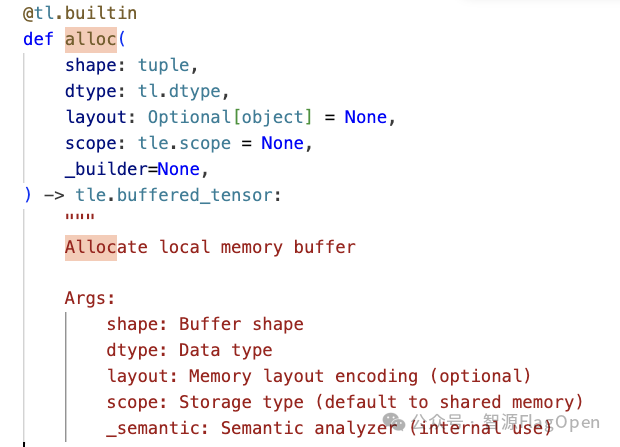
tle.remote
用于声明一块buffer为远端buffer(所有tile都分配了相同的一块buffer),返回相应的写地址
延迟物化: 远程信息只是作为元数据附着在 Python对象上,真正的IR生成推迟到后续调用 local_ptr() 时才发生。
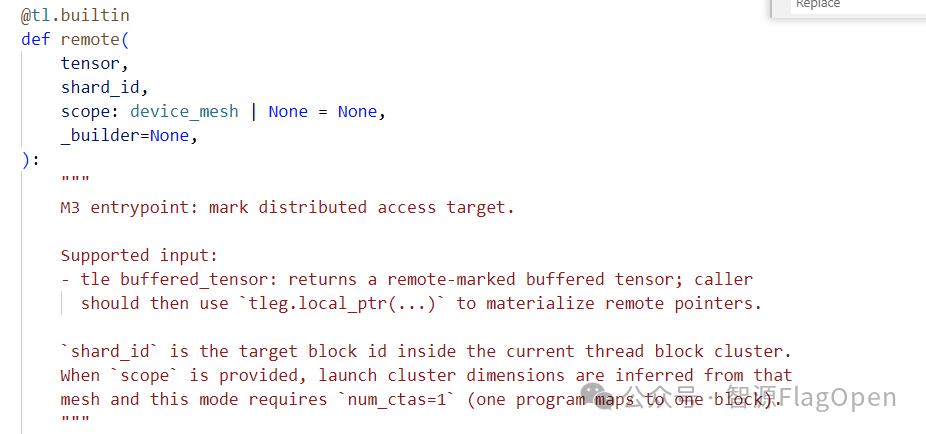
# user code
remote_recv_buf = tle.remote(recv_buf, remote_id)tle.remote() 不生成任何 IR op。它是一个纯 Python 层的标记操作:
1) 对 buffered_tensor 做浅拷贝;
2) 在拷贝的 .type 上设置 _tle_remote_shard_id = send_next_tile;
3) 在拷贝的 .type 上设置 _tle_remote_scope = mesh;
4) 返回标记后的 buffered_tensor。
tle.dsa.local_ptr
根据标记选择不同的create分支
# user code
send_ptr = tle.language.dsa.local_ptr(send_buf, [offs_buf_k, offs_buf_n])前面提过,remote会标记tensor属性(remote_buffer_marker), 若local_ptr的输入tensor:
-
无remote_buffer_marker
获取本地alloc出来的buffer的地址
# creater
_builder.create_dsa_local_pointers(buffer.handle, idx_handles)
# ttir
%send_ptr = dsa.local_pointers %send_buf, [%offs_k, %offs_n]
: memref<4096x256xf16, 3>, tensor<4096x256xi32>, tensor<4096x256xi32> -> tensor<4096x256x!tt.ptr<f16>>
-
有remote_buffer_marker
获取远端读写地址, 通过tl.store可以直接触发通信
编译流程:从高层语义到硬件指令的降级
# creater
_builder.create_dsa_remote_pointers(buffer.handle, shard_id, idx_handles)
# ttir
%remote_ptr = dsa.remote_pointers %recv_buf, %send_next_tile, [%offs_k, %offs_n]
: memref<4096x256xf16, 3>, i32, tensor<4096x256xi32>, tensor<4096x256xi32>
-> tensor<4096x256x!tt.ptr<f16>>编译流程:从高层语义到硬件指令的降级
Triton-TLE 的编译器后端完成了关键的“降级”过程,这是整个方案能够“用统一语言驾驭异构硬件”的技术基石:
1.Remote只对tensor进行标记,后续local_ptr识别到被标记的tensor会额外生成一个remote_pointers去修饰local_pointers;
2.remote_pointers+tl.store的组合会被合并优化为mk.remote_store。
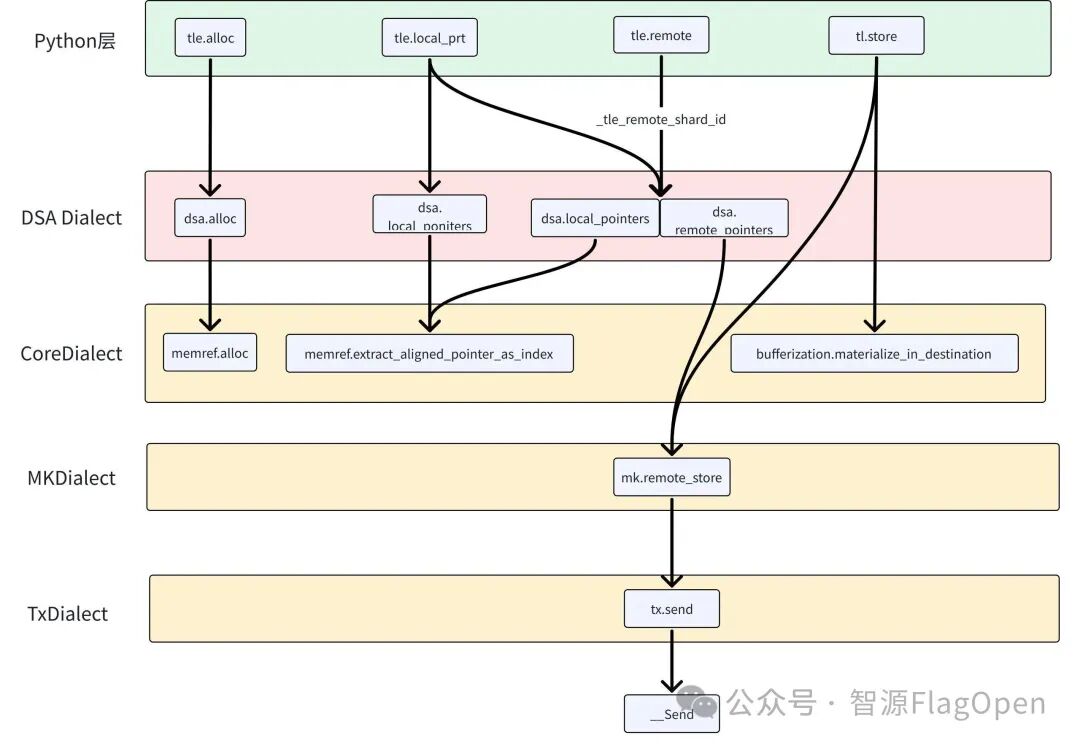
通过这种设计,开发者用“声明式”的代码描述了RT间的数据流转,而编译器负责将其精确映射到底层硬件。远程通信不再需要显式调用发送原语,而是通过“对远程 buffer 的 store 操作”自然触发——这正是Triton-TLE抽象能力的关键体现。
Kernel 实现:循环移位结构的代码表达
完整的Compute-Shift GEMM kernel 采用循环移位结构,代码逻辑清晰体现了“计算-发送-接收-移位”的流水:
@triton.jit
def dsa_shift_n_gemm_kernel(
A_ptr, B_ptr, C_ptr,
send_next_tile_lut_ptr, ring_index_lut_ptr,
M: tl.constexpr, N: tl.constexpr, K: tl.constexpr,
BLOCK_M: tl.constexpr, BLOCK_K: tl.constexpr,
SUB_N: tl.constexpr, TILE_NUM: tl.constexpr,
):
pid = tl.program_id(0)
send_next_tile = tl.load(send_next_tile_lut_ptr + pid)
ring_index = tl.load(ring_index_lut_ptr + pid)
offs_m = pid * BLOCK_M + tl.arange(0, BLOCK_M)
offs_k = tl.arange(0, BLOCK_K)
a_ptrs = A_ptr + offs_m[:, None] * K + offs_k[None, :]
a = tl.load(a_ptrs)
shard_idx = ring_index
offs_sub_n = shard_idx * SUB_N + tl.arange(0, SUB_N)
b_ptrs = B_ptr + offs_k[:, None] * N + offs_sub_n[None, :]
b_init = tl.load(b_ptrs)
# alloc buffer
send_buf = tle.language.dsa.alloc((BLOCK_K, SUB_N), tl.float16)
recv_buf = tle.language.dsa.alloc((BLOCK_K, SUB_N), tl.float16)
# make load range
offs_buf_k = tl.arange(0, BLOCK_K)[:, None] + tl.zeros((1, SUB_N), dtype=tl.int32)
offs_buf_n = tl.arange(0, SUB_N)[None, :] + tl.zeros((BLOCK_K, 1), dtype=tl.int32)
# get buffer ptr
send_ptr = tle.language.dsa.local_ptr(send_buf, [offs_buf_k, offs_buf_n])
recv_ptr = tle.language.dsa.local_ptr(recv_buf, [offs_buf_k, offs_buf_n])
# mark recv_buf as remote_recv_buf
remote_recv_buf = tle.remote(recv_buf, send_next_tile)
# get remote buffer ptr
remote_recv_ptr = tle.language.dsa.local_ptr(remote_recv_buf, [offs_buf_k, offs_buf_n])
tl.store(send_ptr, b_init)
for step in range(TILE_NUM):
b_cur = tl.load(send_ptr)
c_part = tl.dot(a, b_cur, out_dtype=tl.float32)
offs_n = shard_idx * SUB_N + tl.arange(0, SUB_N)
c_ptrs = C_ptr + offs_m[:, None] * N + offs_n[None, :]
tl.store(c_ptrs, c_part.to(tl.float16))
if step < TILE_NUM - 1:
# remote store
tl.store(remote_recv_ptr, tl.load(send_ptr)) # send
# copy
tl.store(send_ptr, tl.load(recv_ptr))
shard_idx = tl.where(shard_idx == 0, TILE_NUM - 1, shard_idx - 1)
收益:性能实测与数据解读
我们在清微RPU上对Compute-Shift GEMM进行了实测,并与标准Triton实现及清微原生算子进行对比。得出以下结论:
-
相比标准Triton原生实现,Triton-TLE版本性能提升达2.5倍;
-
相比清微原生Compute-Shift手工优化版本,达到其性能的1.12倍,证明Triton-TLE的表达能力已接近手调极致。
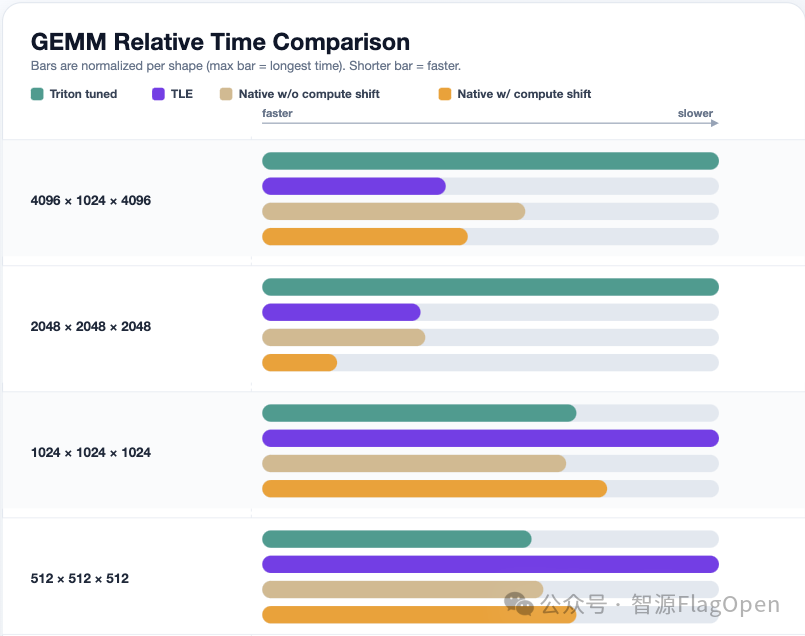
虽然通信会带来额外开销,但随着数据量增大,Compute-Shift减少访存带来的收益会越来越高,是大规模深度学习任务的理想方案 。
清微RPU的分布式数据流架构,代表了面向大算力场景的一种重要硬件方向。而Triton-TLE的出现,让我们不再需要为每一种硬件架构维护一套独立的底层代码库。通过Compute-Shift GEMM这一典型案例,我们看到:
-
Triton-TLE Struct层接口能够以简洁的语义表达RT间通信与计算并行;
-
“标记 + 延迟物化”的编译流程设计让远程通信自然融入store操作,开发者无需手动管理NoC传输细节;
-
编译器后端的合并优化将高层语义精确降级为硬件指令,在保持代码可读性的同时逼近手调性能上限。
未来,我们将继续扩展Triton-TLE对更多数据流模式的支持,让“用一套语言驾驭多样硬件”的愿景在更广泛的场景中落地。
关于众智FlagOS社区
为解决不同 AI 芯片大规模落地应用,北京智源研究院联合众多科研机构、芯片企业、系统厂商、算法和软件相关单位等国内外机构共同发起并创立了众智 FlagOS 社区。成员单位包括北京智源研究院、中科院计算所、中科加禾、安谋科技、北京大学、北京师范大学、百度飞桨、硅基流动、寒武纪、海光信息、华为、基流科技、摩尔线程、沐曦科技、澎峰科技、清微智能、天数智芯、先进编译实验室、移动研究院、中国矿业大学(北京)等多家在 FlagOS 软件栈研发中做出卓越贡献的单位。
FlagOS 是一款专为异构 AI 芯片打造的开源、统一系统软件栈,支持 AI 模型一次开发即可无缝移植至各类硬件平台,大幅降低迁移与适配成本。它包括大型算子库、统一AI编译器、并行训推框架、统一通信库等核心开源项目,致力于构建「模型-系统-芯片」三层贯通的开放技术生态,通过“一次开发跨芯迁移”释放硬件计算潜力,打破不同芯片软件栈之间生态隔离。
官网:https://flagos.io
GitHub 项目地址:https://github.com/flagos-ai
GitCode 项目地址:https://gitcode.com/flagos-ai

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)