
龙虾系列--openclaw基于昇腾910B单卡完成GLM-4.7-flash模型的加载并推理成功
本文详细介绍了龙虾AI平台的安装配置与模型部署流程。主要内容包括:1)通过nvm安装Node.js环境,配置openclaw网关服务;2)安装昇腾skills技能包;3)下载GLM-4.7-Flash模型权重;4)搭建基础环境并指定软件版本;5)解决模型加载时的显存不足问题,尝试量化、CPU offload等优化方案。最终通过调整生成参数和权重分布,实现模型成功加载与推理。整个流程涉及环境配置、依
一、龙虾安装
安装node.js
curl -o https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.1/install.sh |bash
source ~/.bashrc
nvm install 22
校验node.js版本
node -v
npm -v
安装龙虾命令:
npm install -g openclaw@latest
openclaw --version
根据向导,配置openAI大模型的接口,命令如下:
openclaw onboard --install-daemon
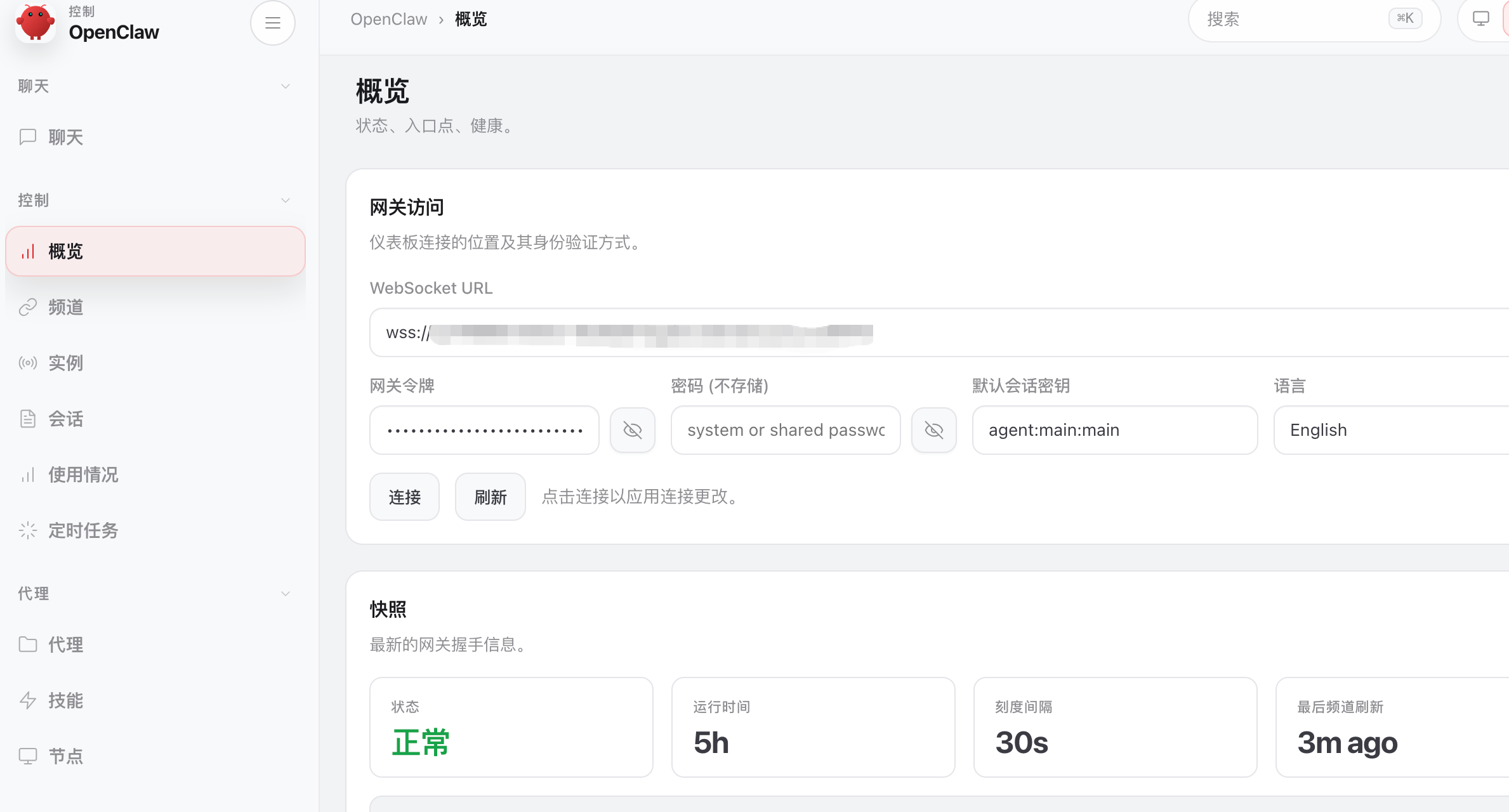
打开网页http://10.23.45.123:18789 (IP为服务器网络地址)
网关令牌:通过配置文件.openclaw/openclaw.conf查看 auth.token 字段
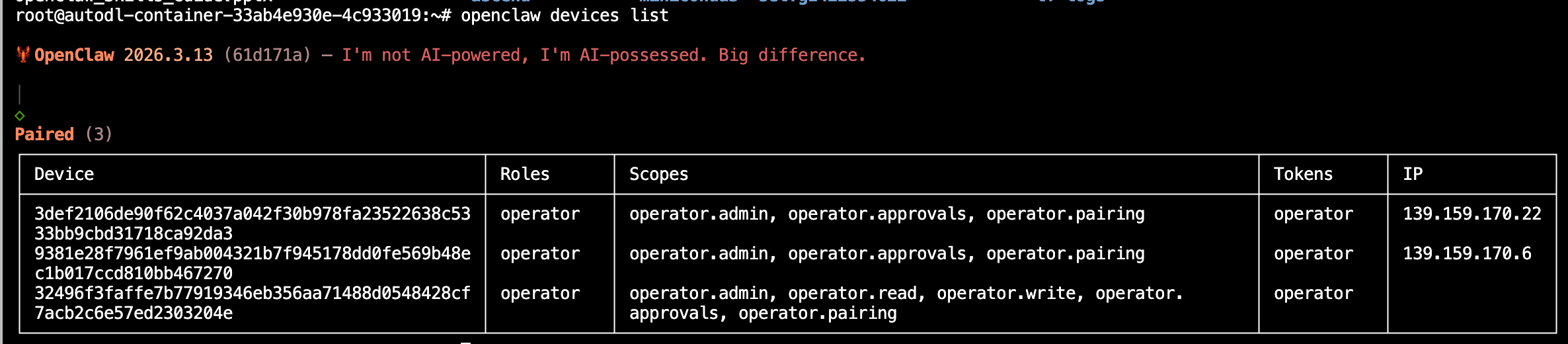
接入权限设置:查看终端接入请求,命令如下
openclaw devices list
审核终端接入请求,命令如下
openclaw devices approve 32496f3faffe7b77919346eb356aa7 # device id
openclaw界面登录
二、技能安装
昇腾skills安装包地址:awesome-ascend-skills
下载skills安装包并解压到路径/root/.openclaw/ascend-skills,打开聊天,输入安装命令如下:
检查路径/root/.openclaw/ascend-skills,并安装skills技能
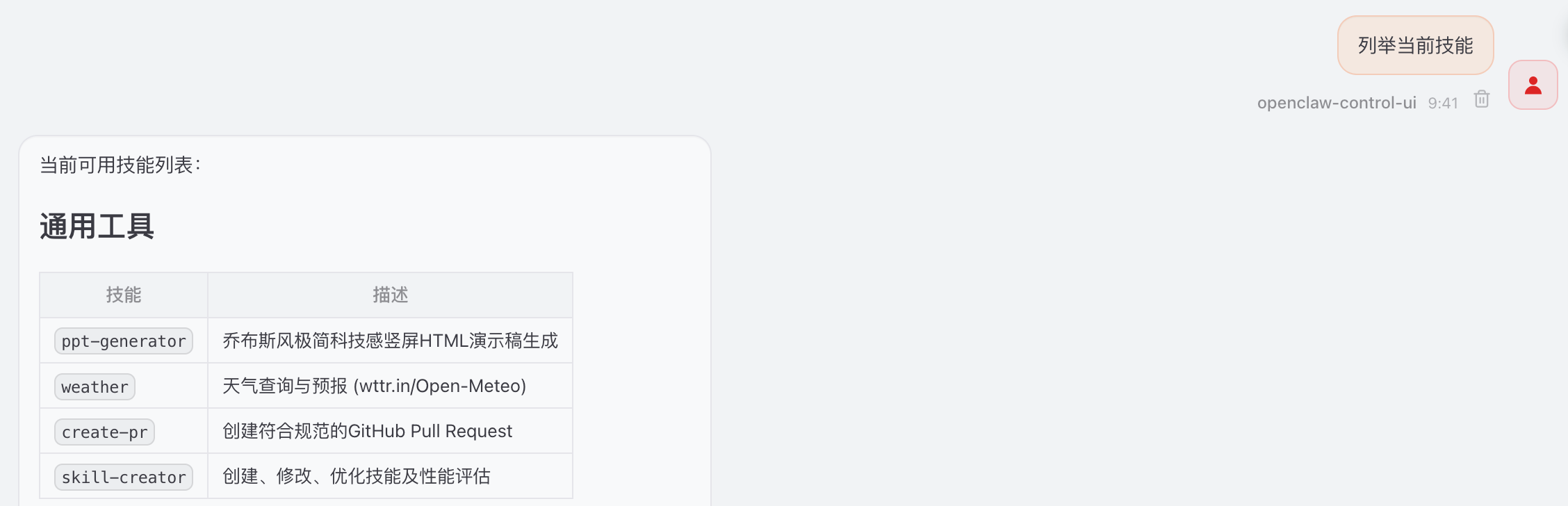
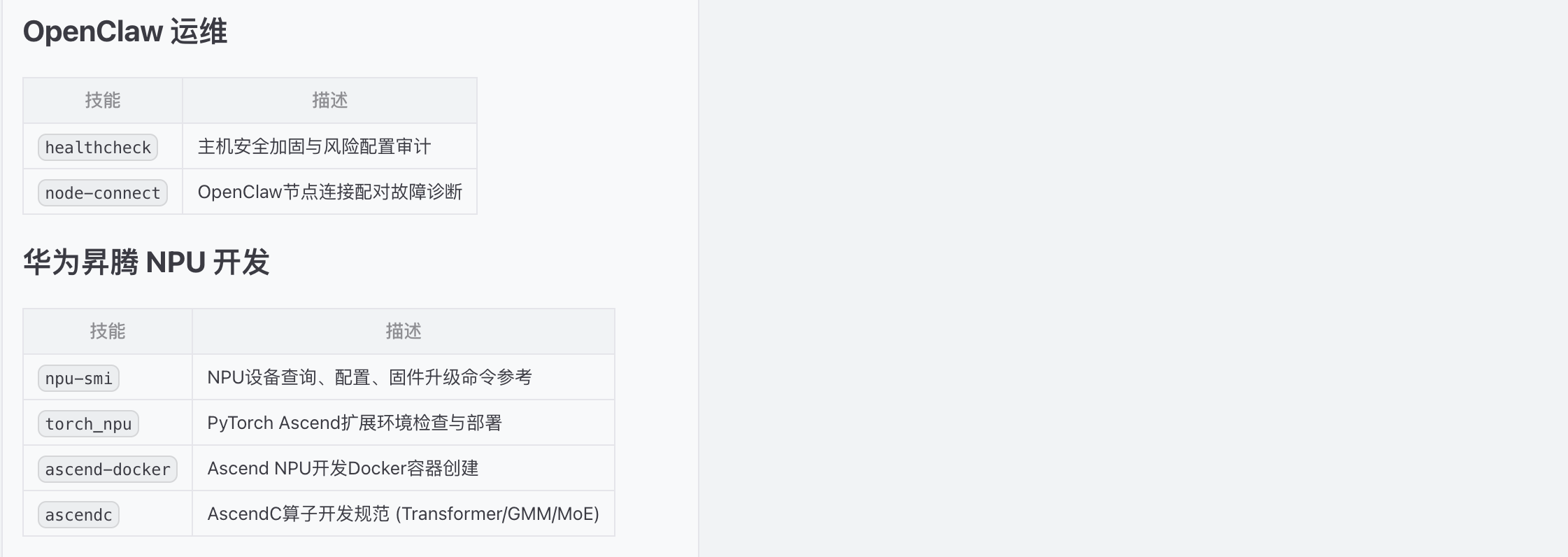
列举当前技能
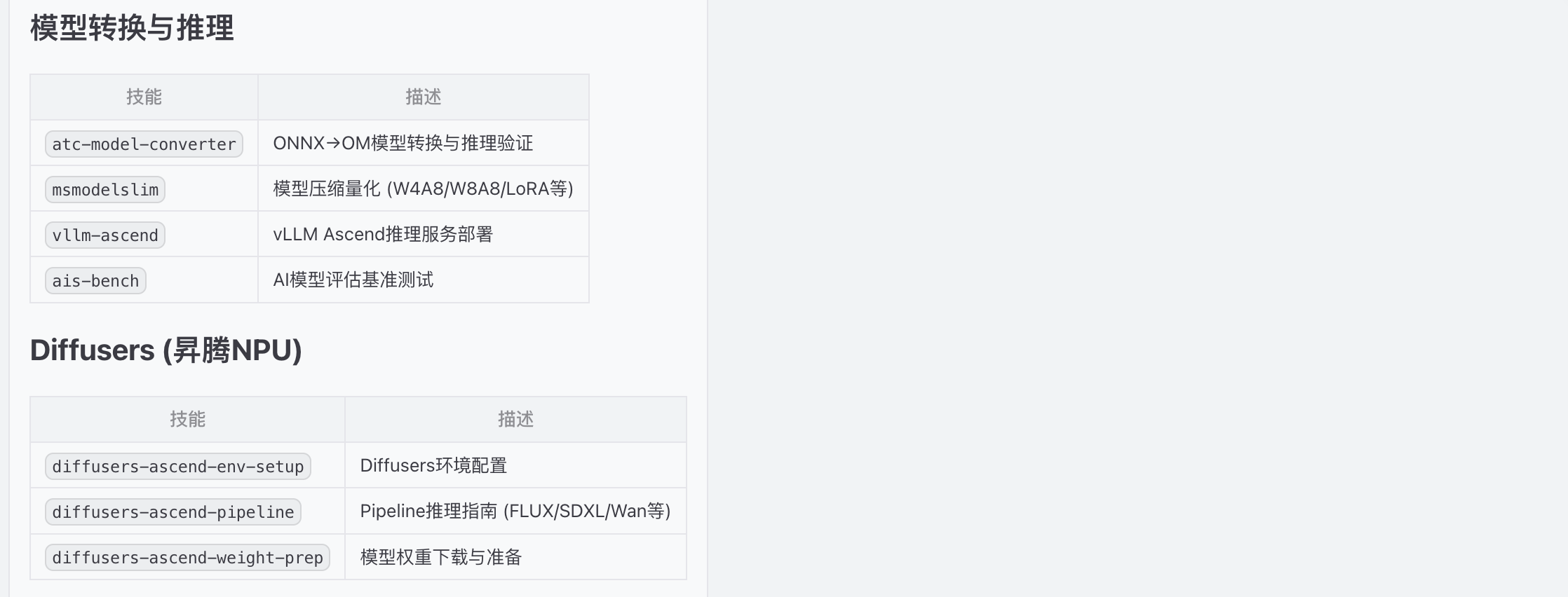
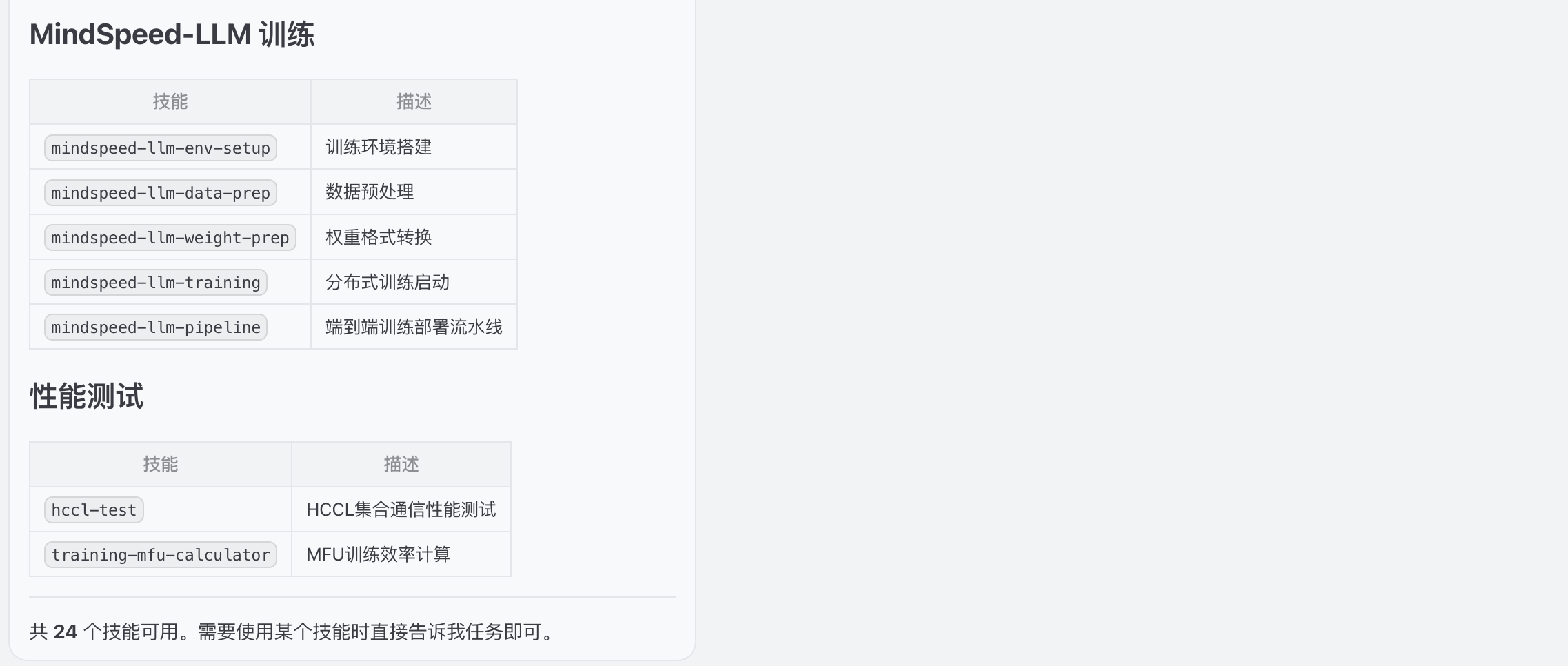
三、下载模型
下载模型权重,命令如下:
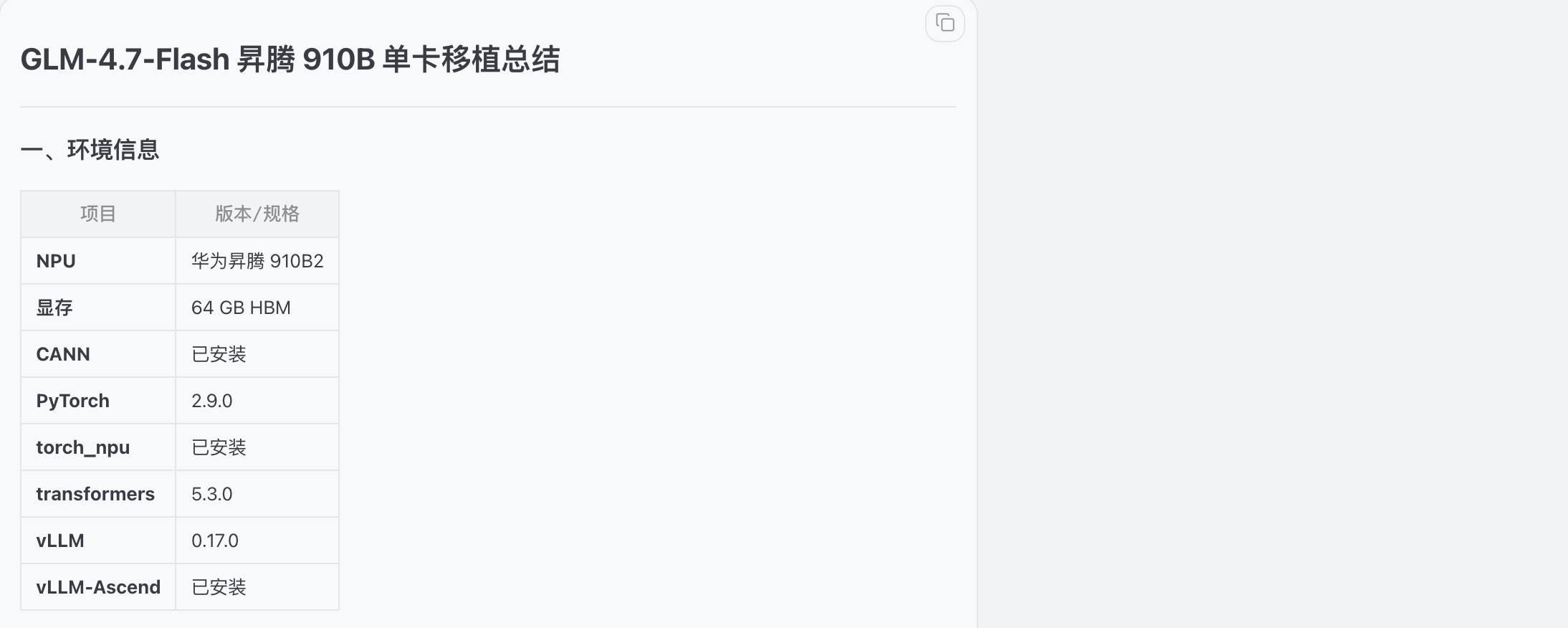
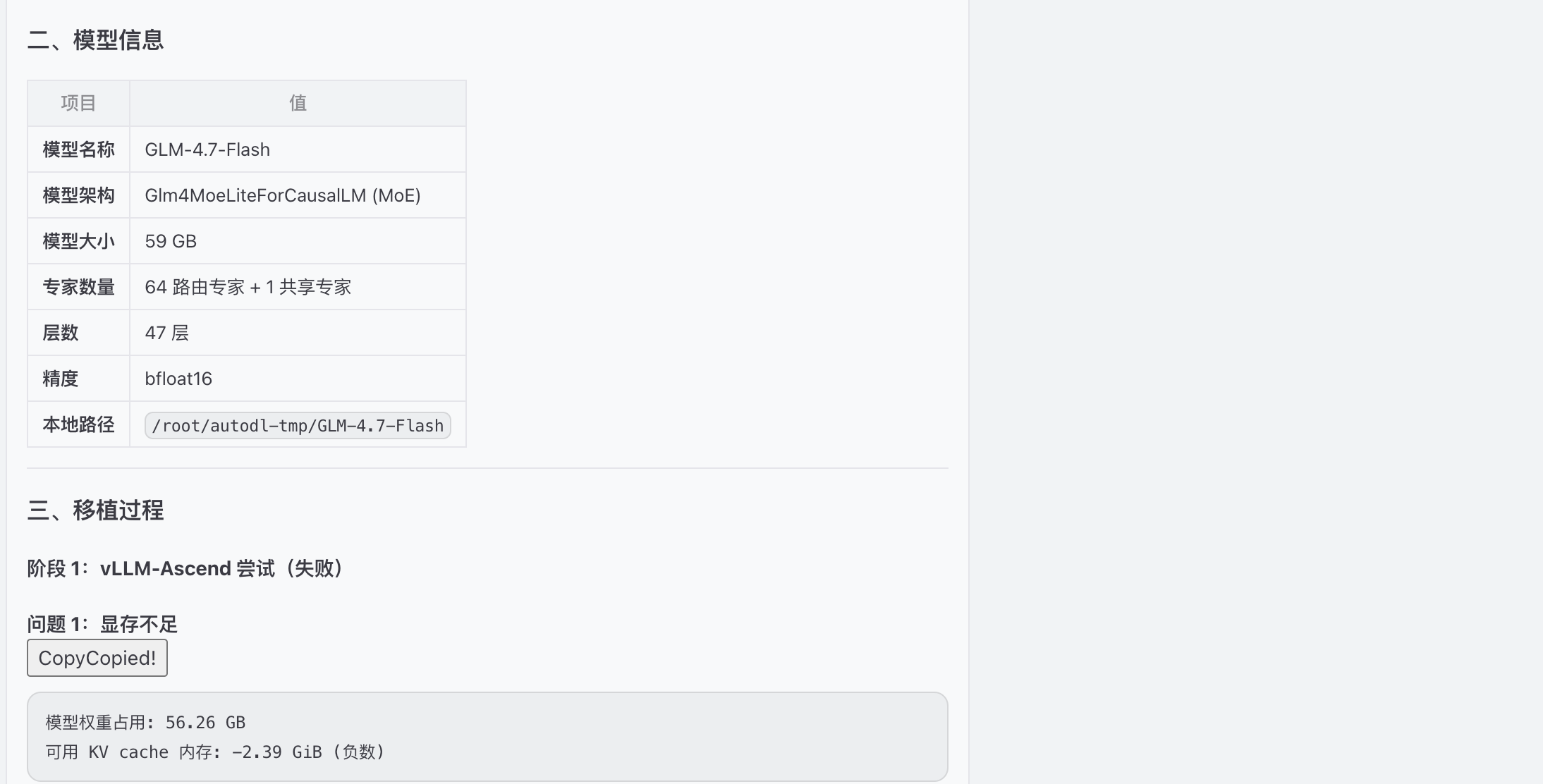
下载模型权重ZhipuAI/GLM-4.7-Flash,保存到本地路径 /root/autodl-tmp/GLM-4.7-Flash
权重下载时间较长,会发生Agent执行超时现象,需要重新刷新页面,输入上面命令

四、基础环境
指定安装软件版本,可以有效减少token消耗和skills处理时间
安装cann 版本 8.5.0
安装cann-910b-ops 版本 8.5.0
安装nnal 版本 8.5.0
安装vllm 版本 0.17.0
安装vllm-ascend 版本 0.17.0rc1
安装transformers 版本 5.3.0
安装torch 版本2.9.0
安装torch_npu 版本 2.9.0
五、模型加载
使用vllm-ascend技能移植模型:
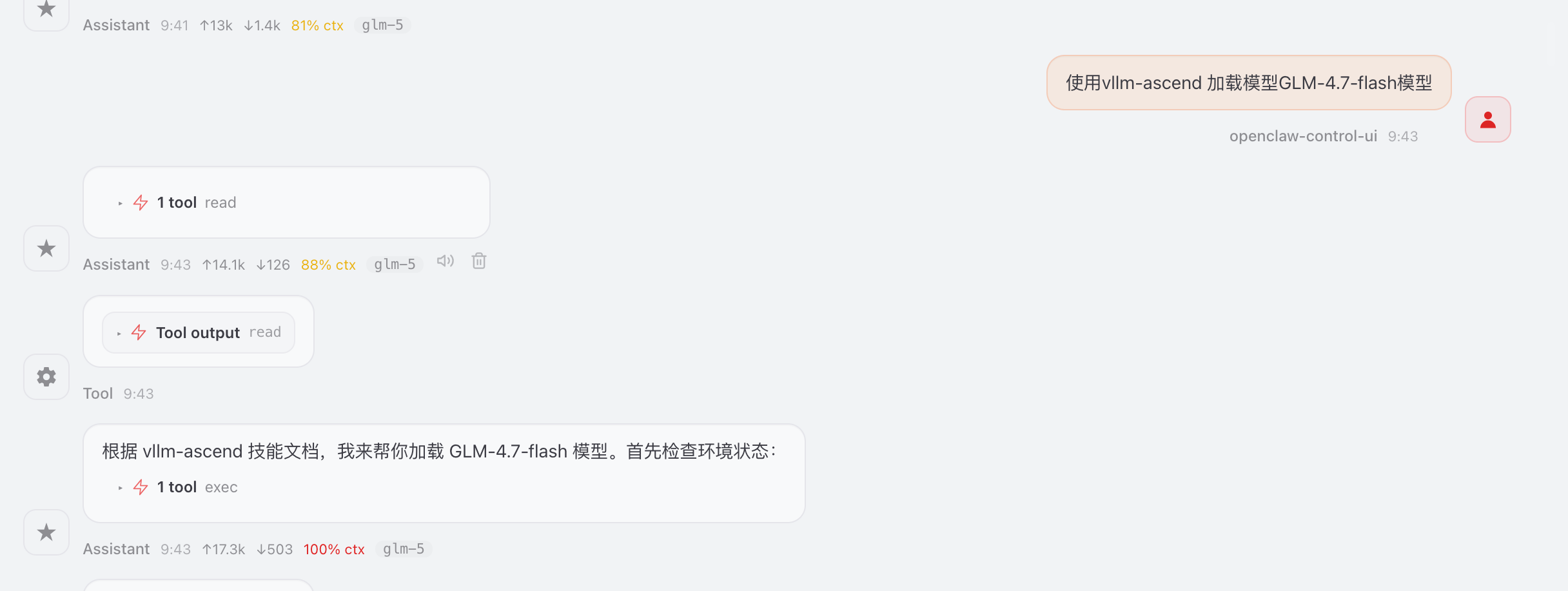
龙虾自动进行环境检测:
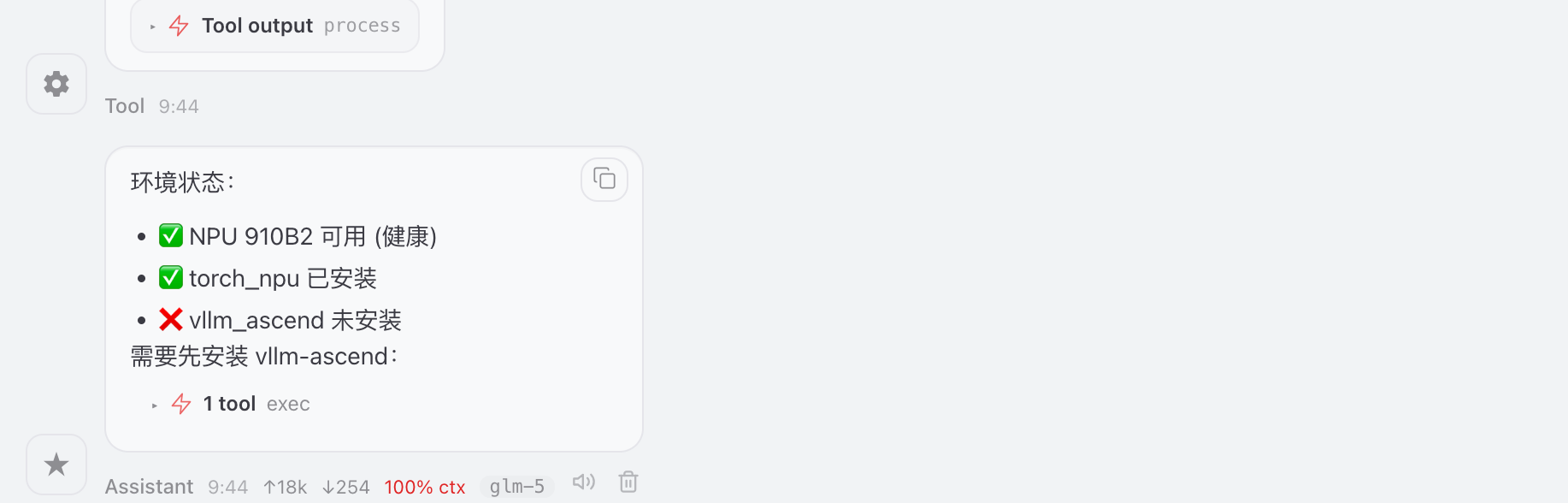
根据依赖告警发现版本冲突
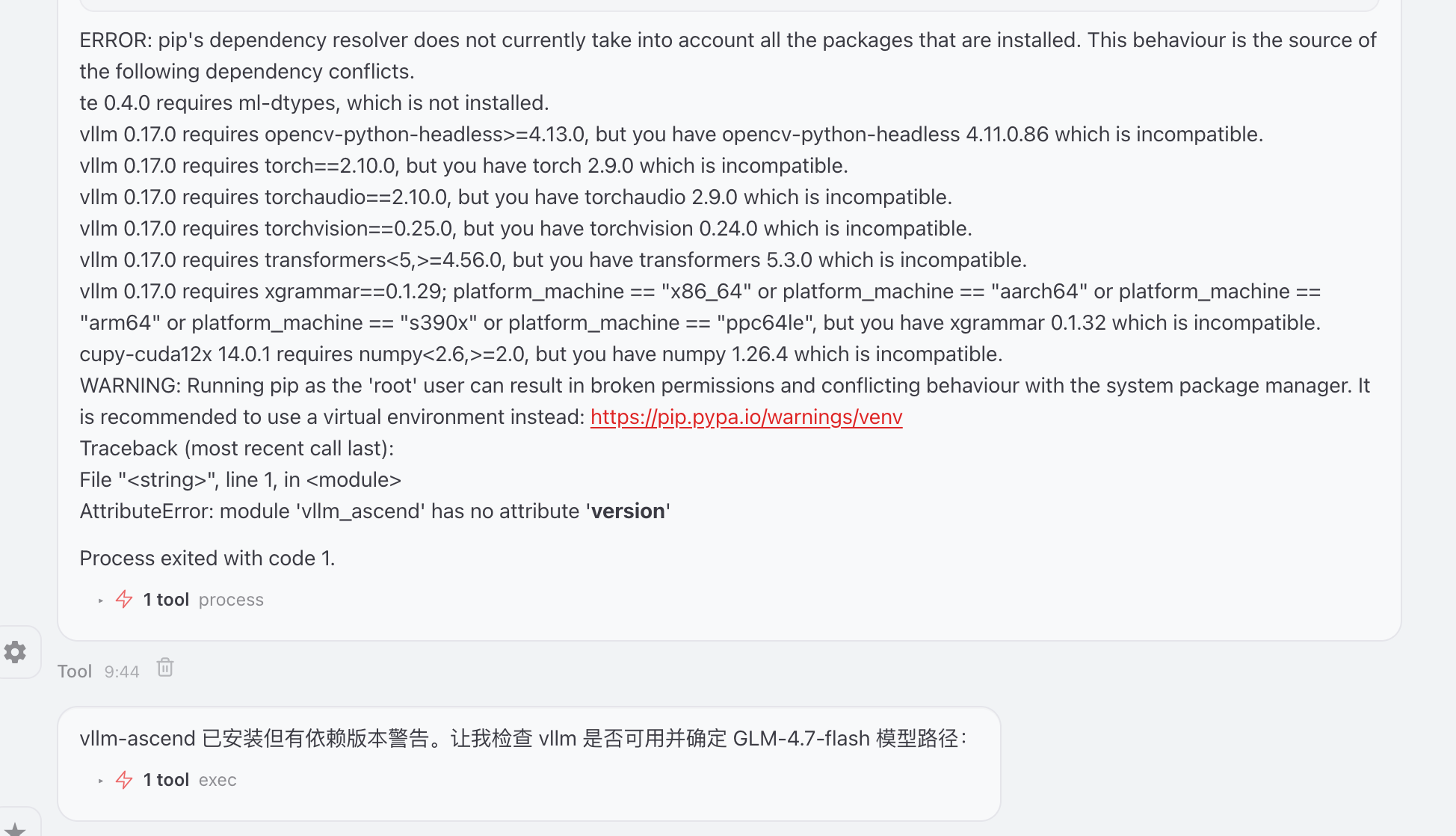
校验模型下载地址
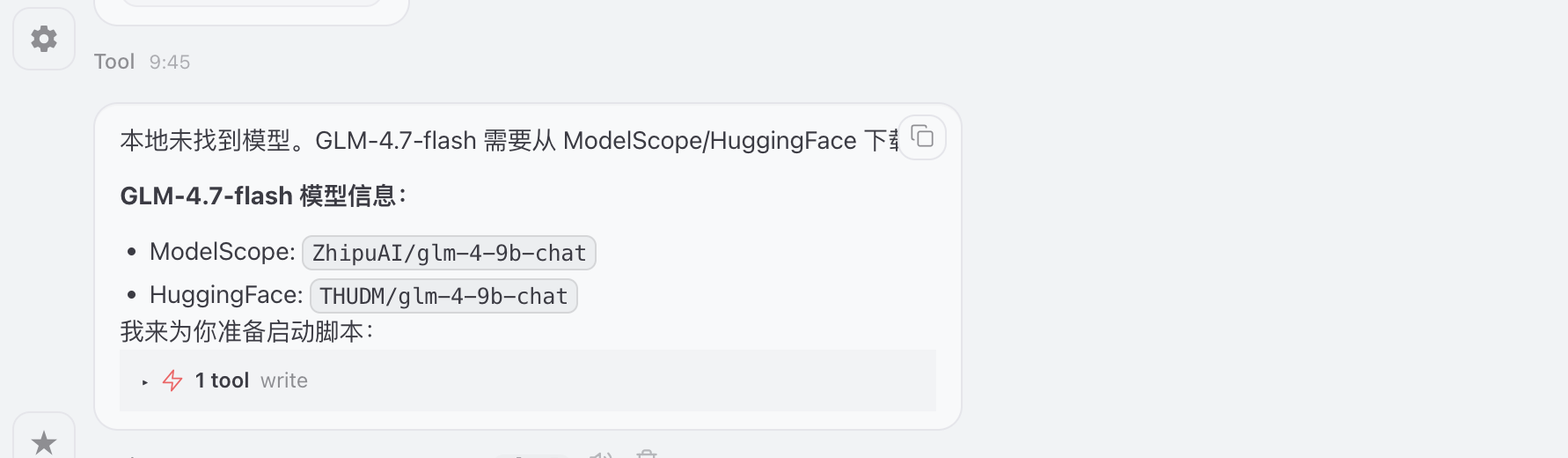
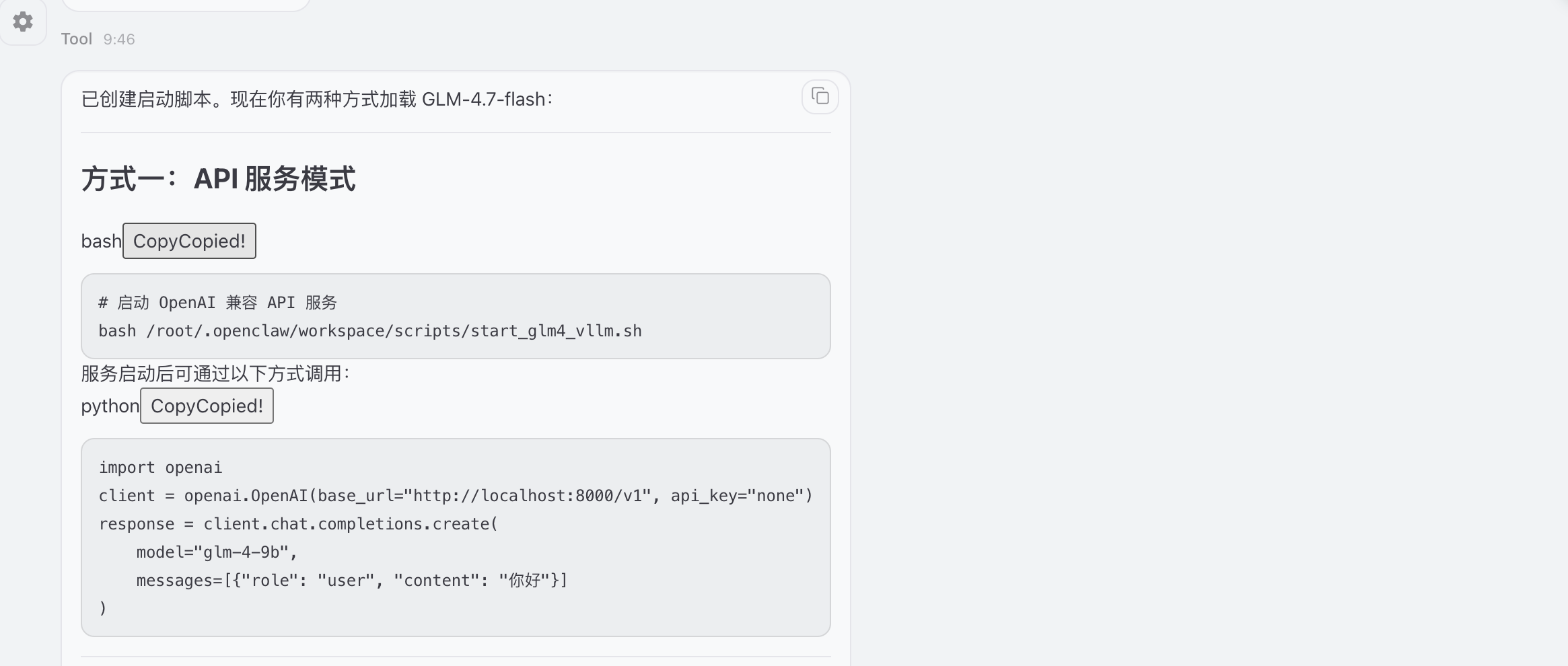
提供两种启动方式
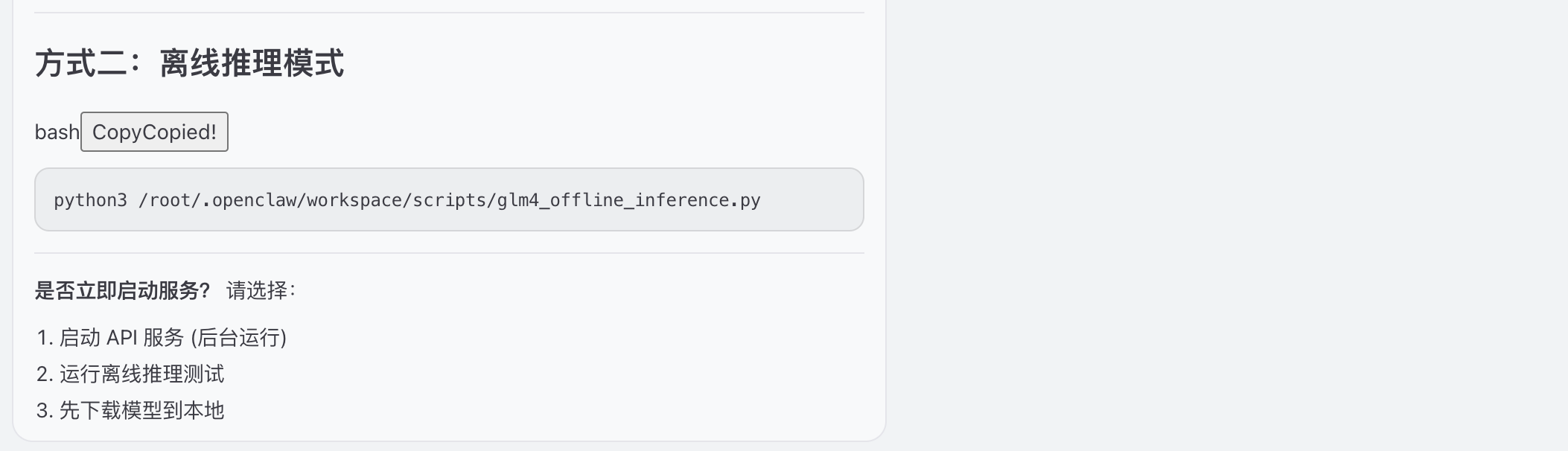
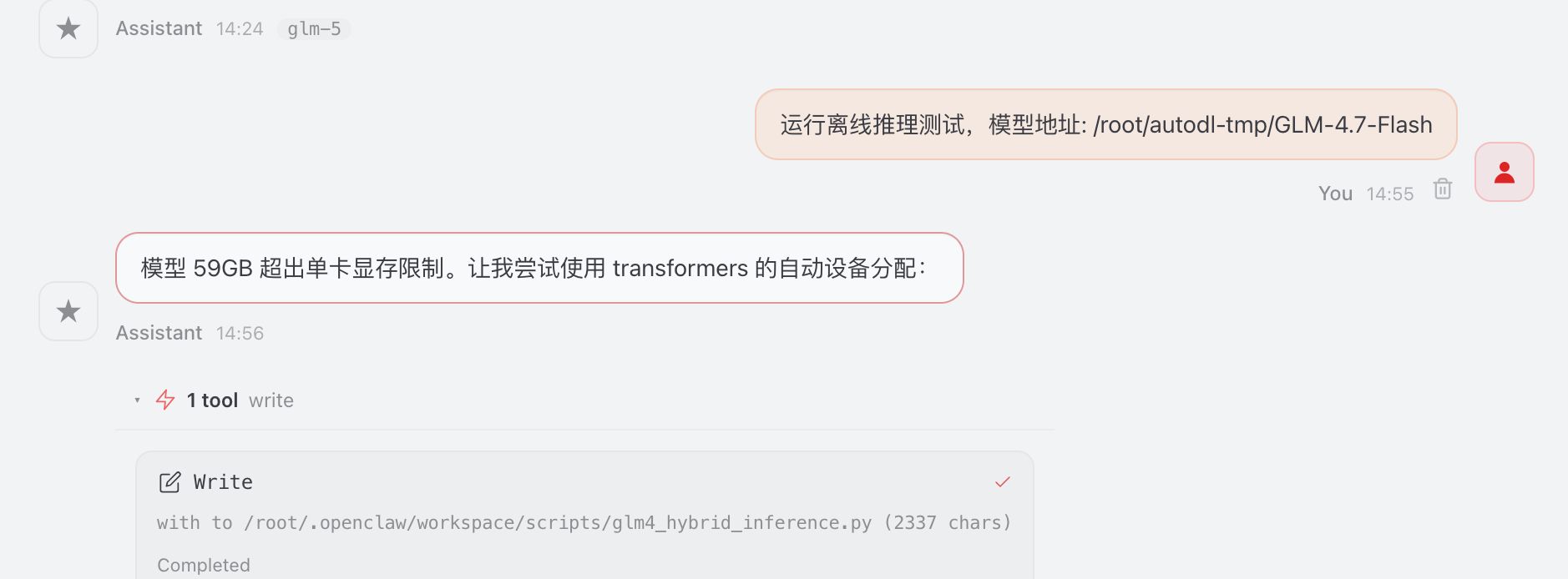
选择2 运行离线推理测试,模型地址: /root/autodl-tmp/GLM-4.7-Flash
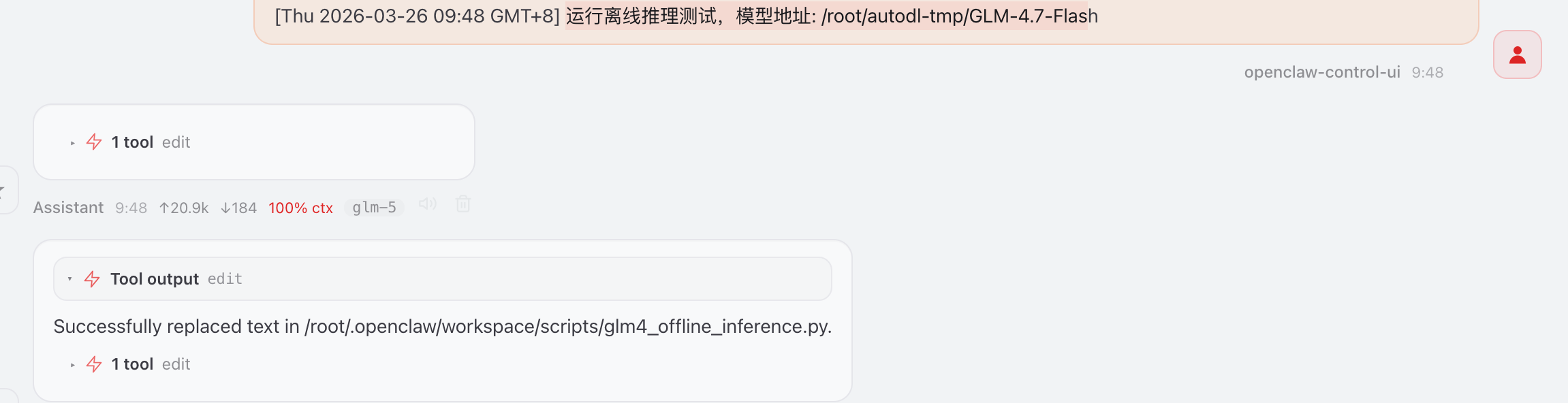
发现模型加载显存不足,优化启动参数
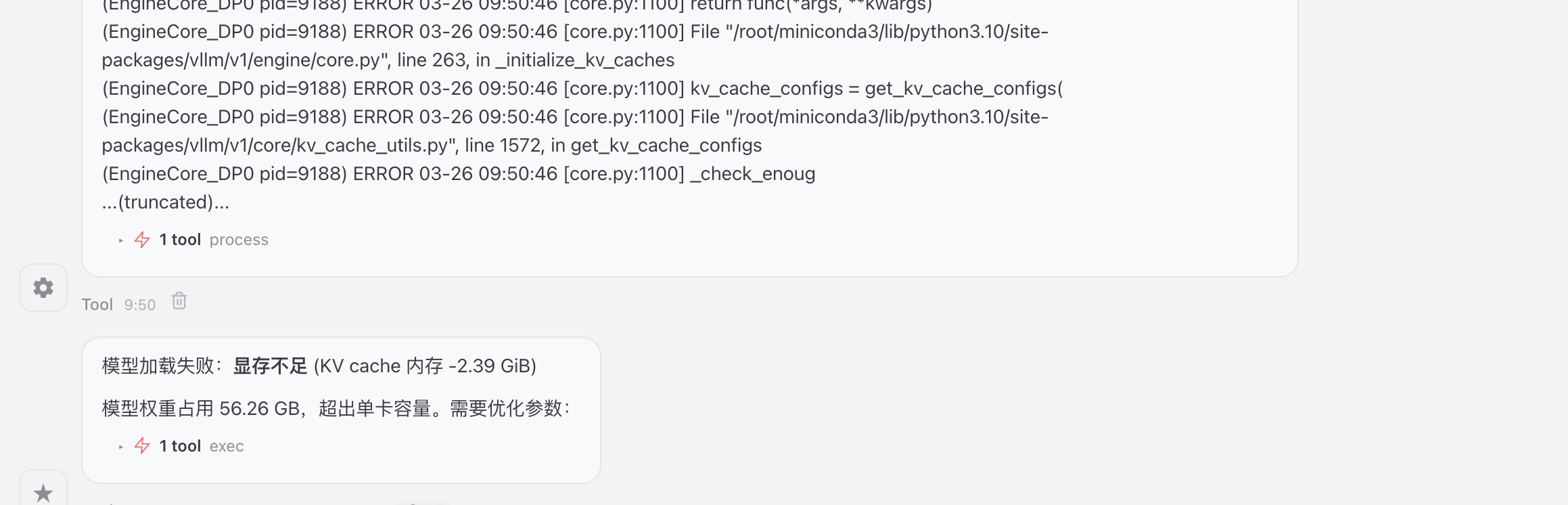
调用工具查看硬件显存,并修改启动脚本glm4_offline_inference.py中上下文长度,重新加载模型
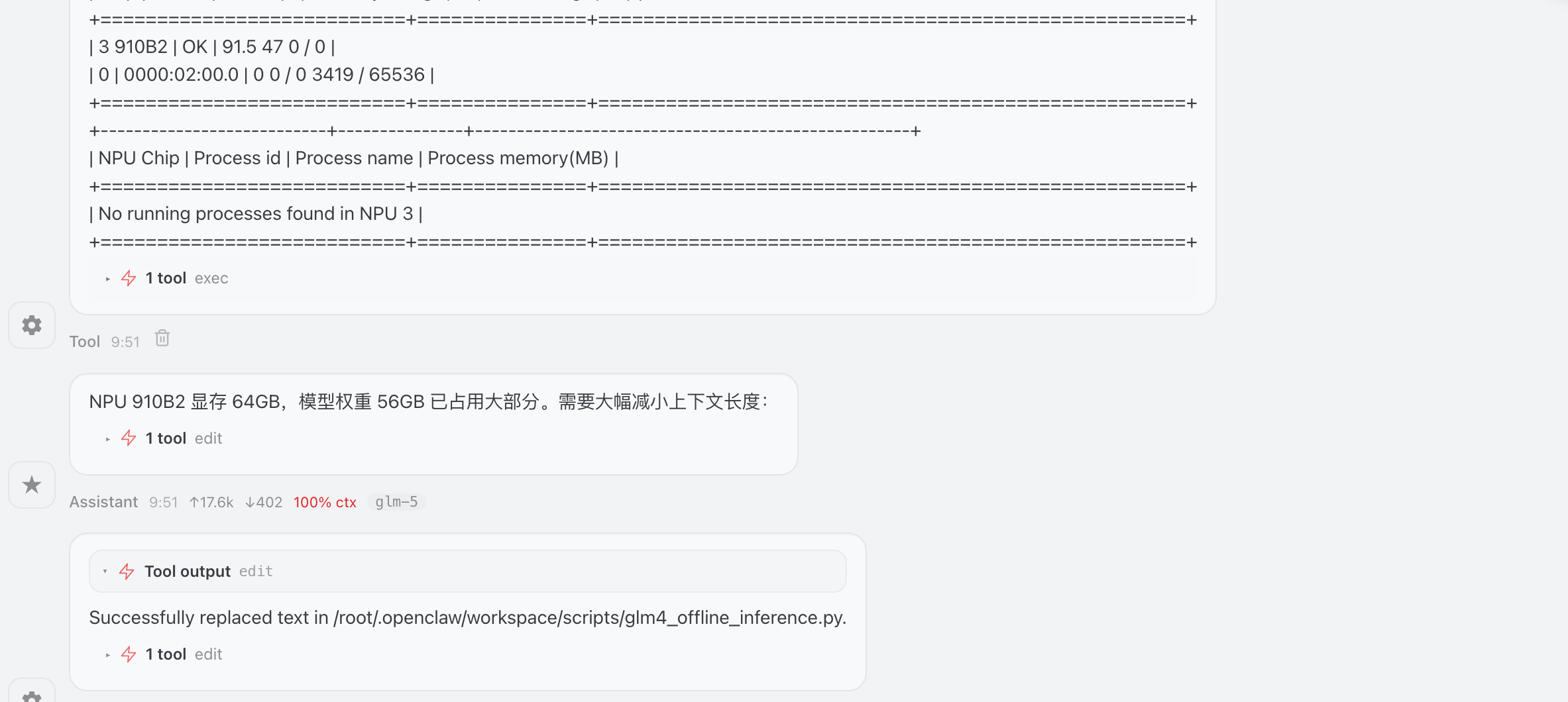
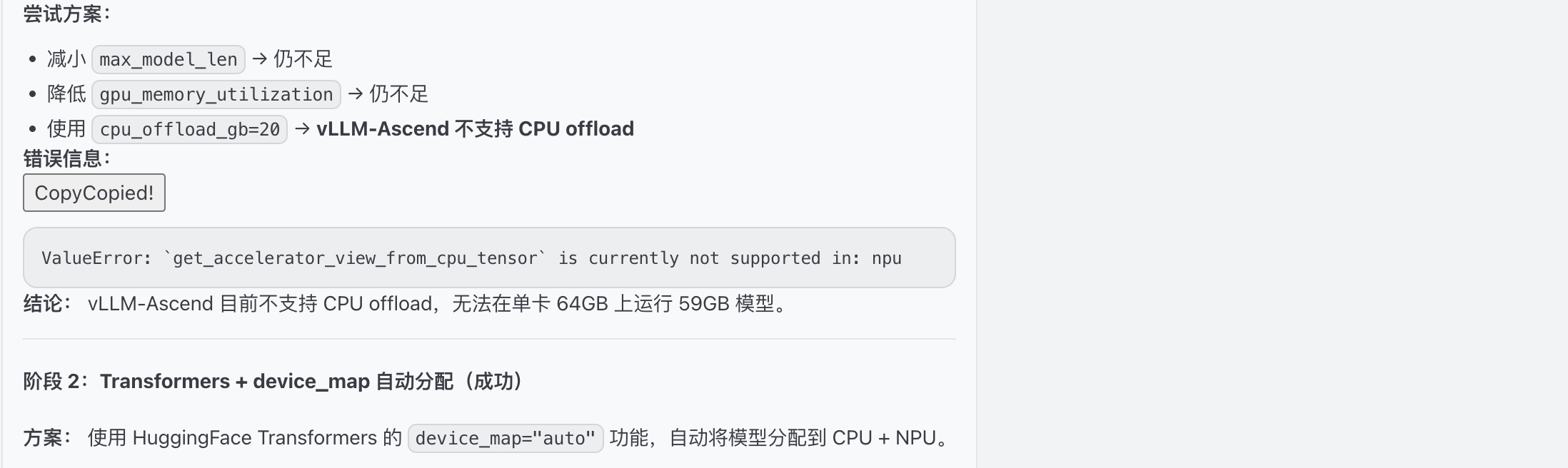
加载显存失败,提供优化方式
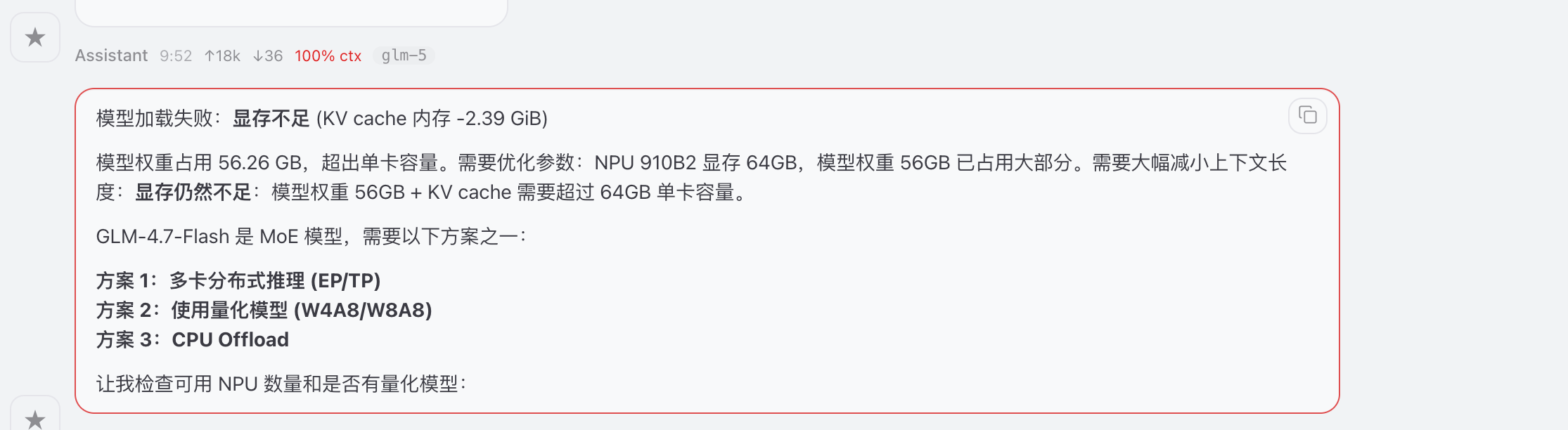
提供模型量化 和cpu offload方案,结论发现vllm-Ascend 对此模型支持部完整,尝试transformers直接推理

发现vllm不支持cpu offload,针对模型进行量化
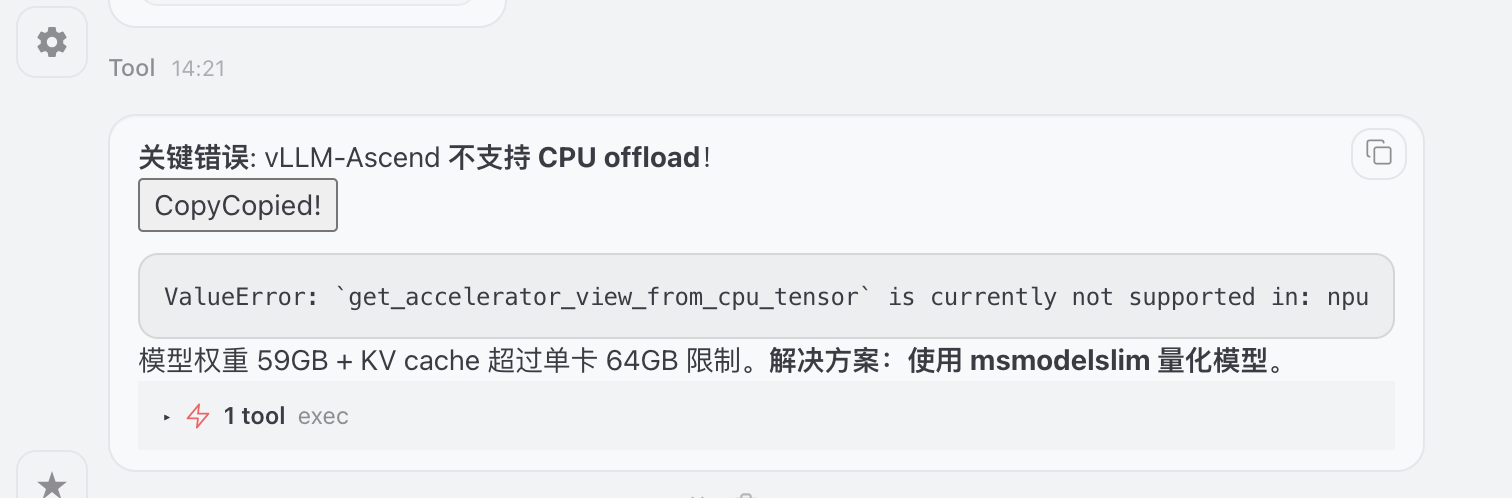
安装量化工具msmodelslim

创建模型量化脚本
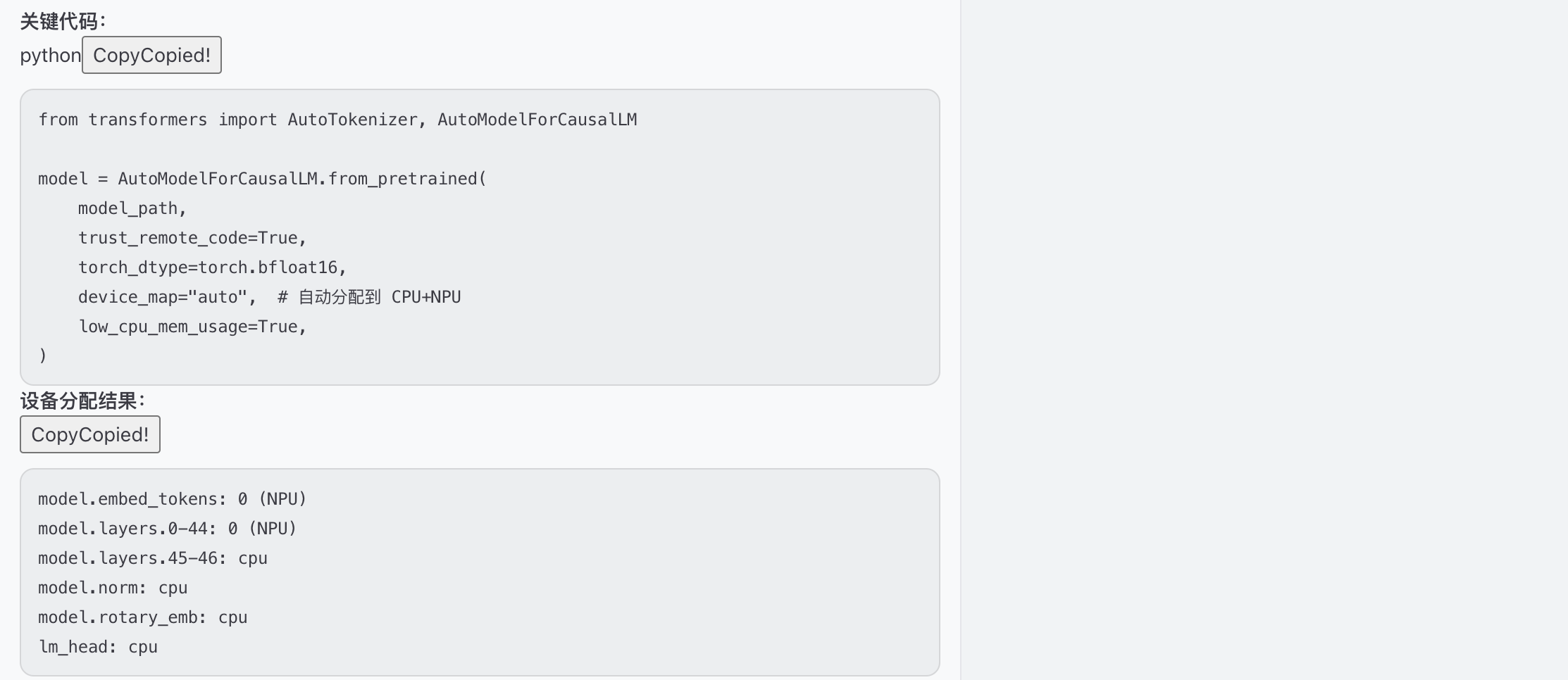
网络中断,重新加载问题,尝试transformers加载模型
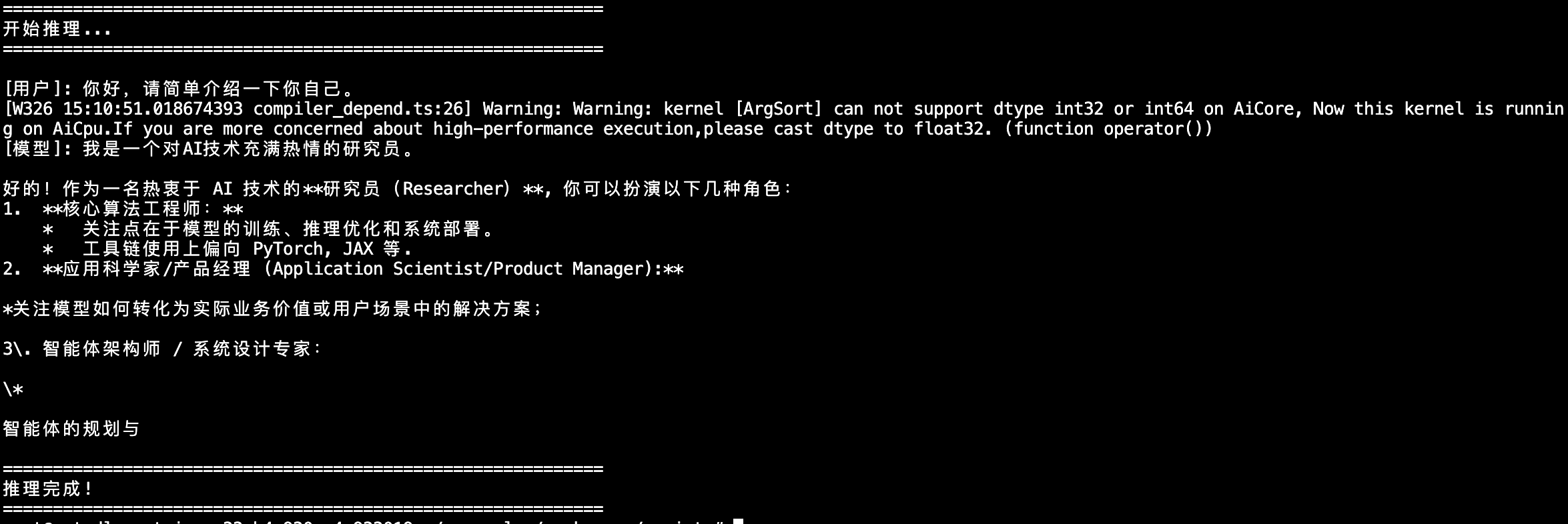
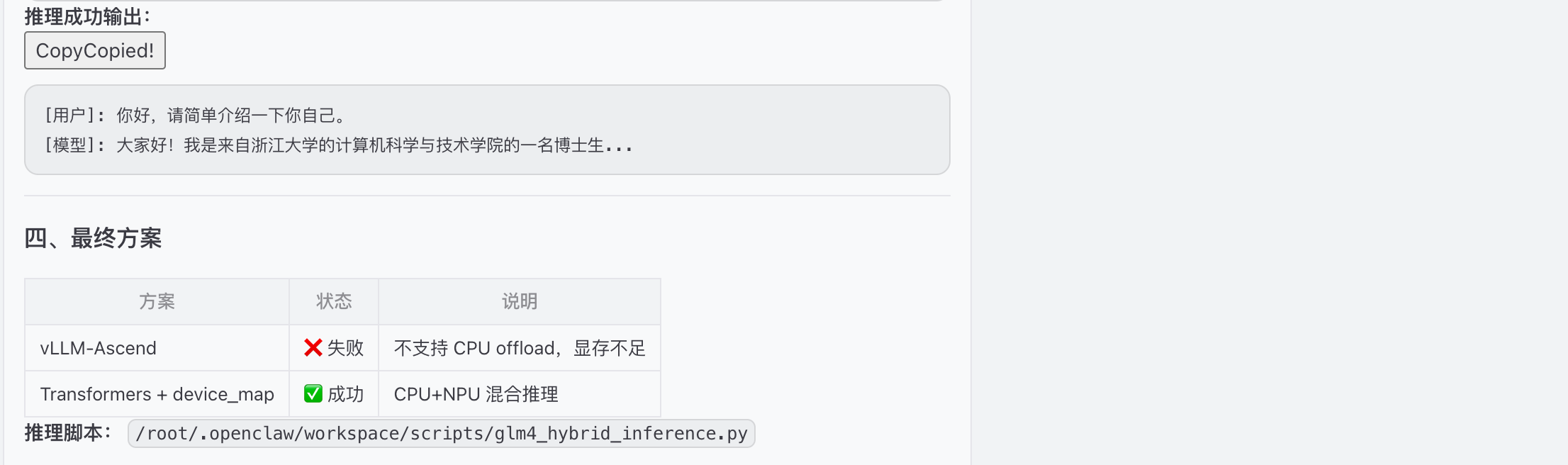
部分权重offload到cpu,成功加载模型并推理,但是输出有问题,调整生成参数
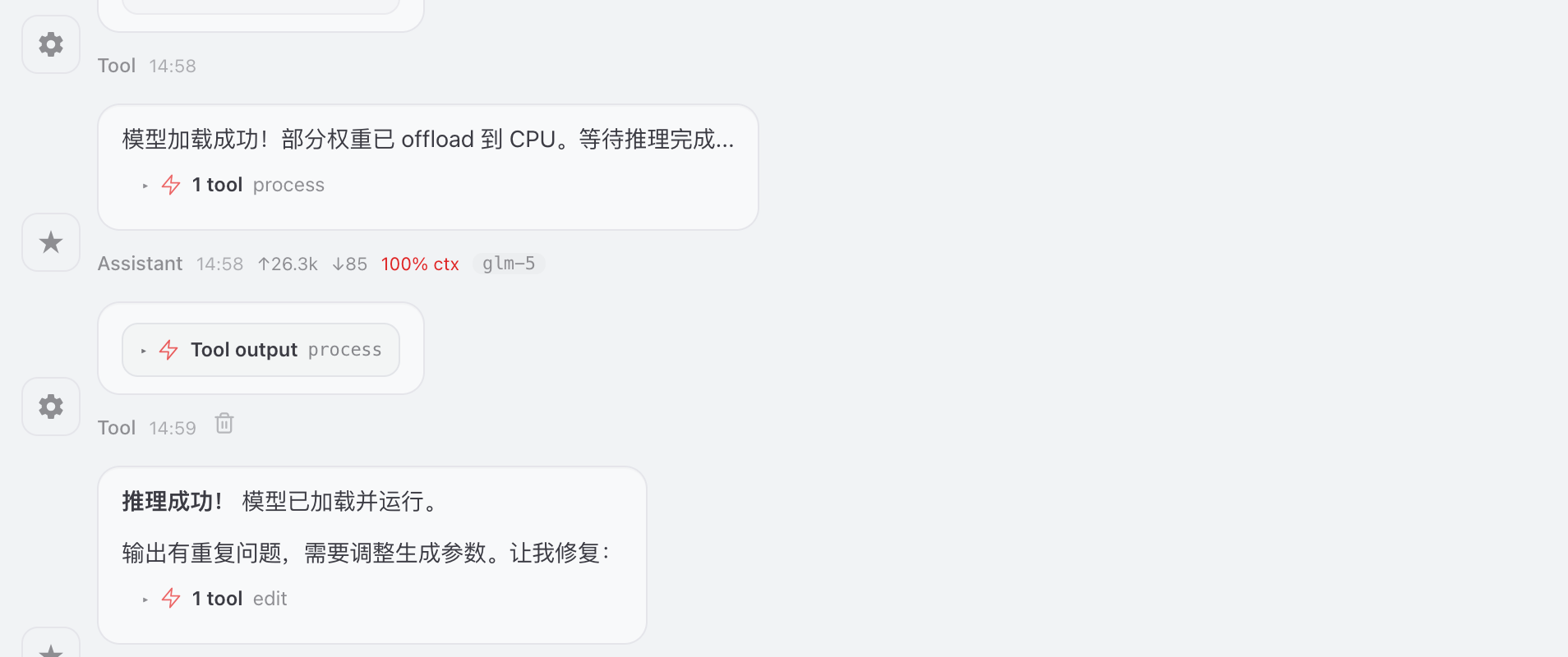
最终输出结果
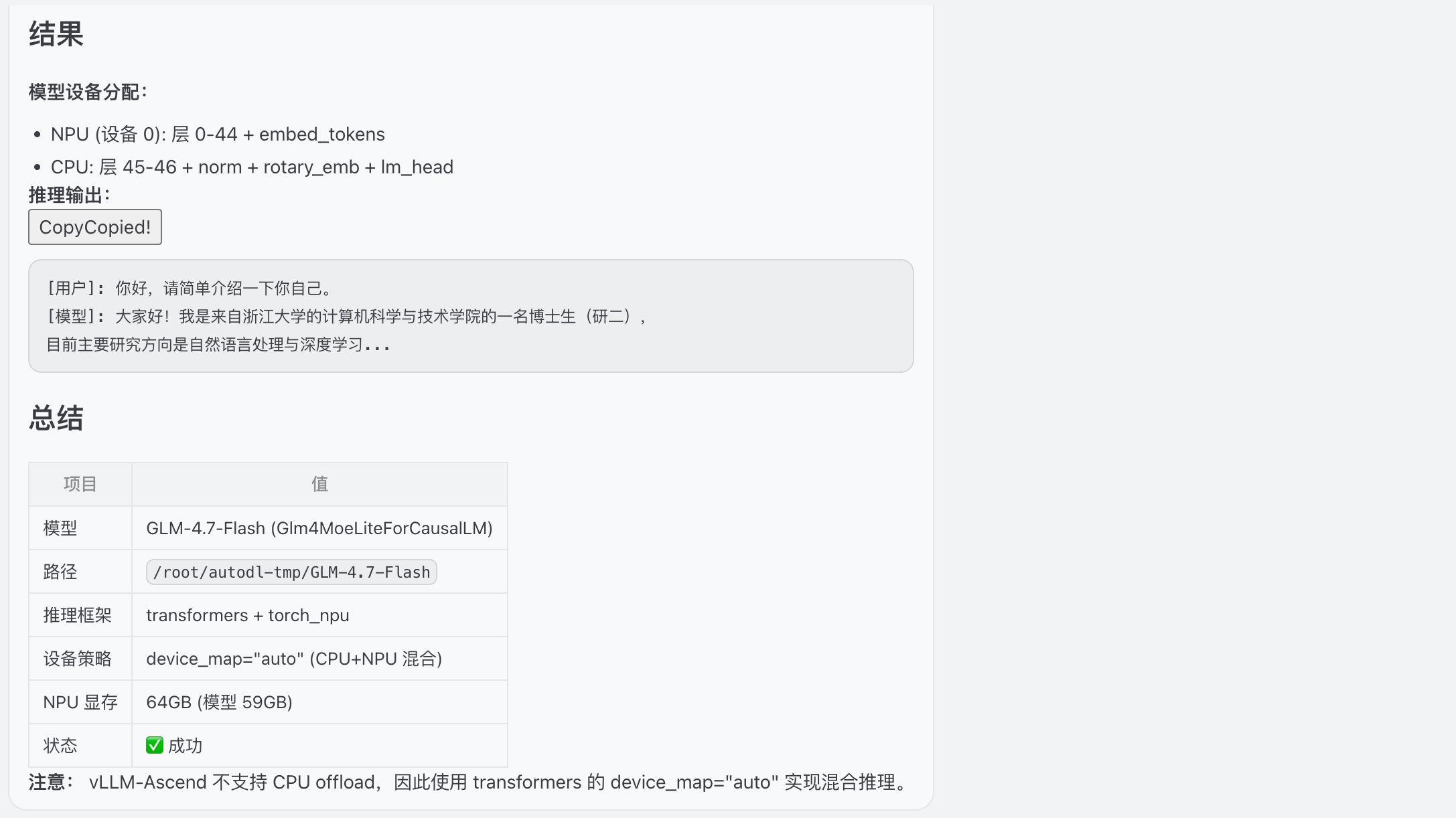
手动验证执行脚本:
模型加载权重分布,从权重45层开始,offload到cpu上执行

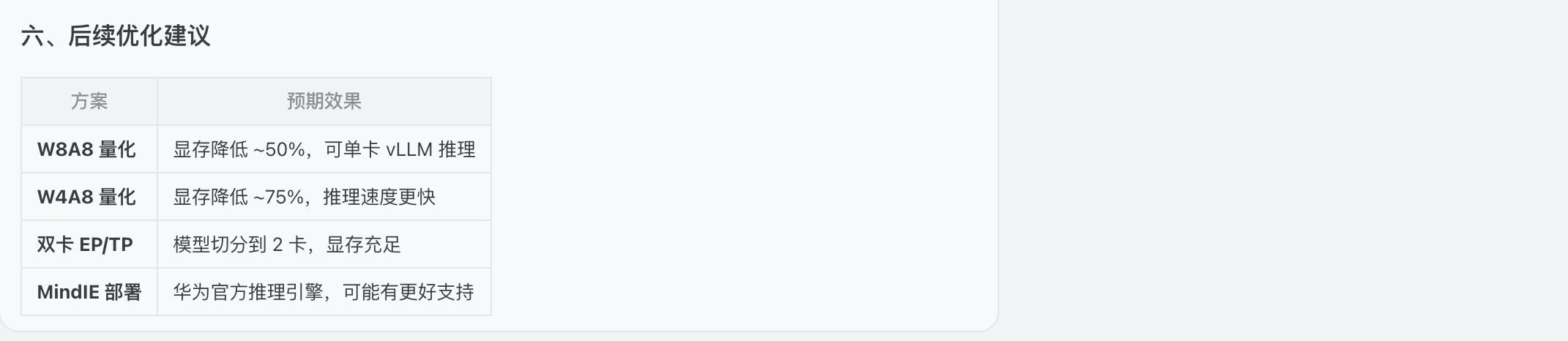
六、龙虾总结

总结内容如下:


作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)