
Tiiny AI Pocket Lab深度拆解:口袋里的AI超级计算机,是未来还是极客玩具?
tiiny ai硬件
目录
一、 市场定位:云AI的“叛逃者”,隐私与成本控制者的专属引擎
前言
当AI Pin、Rabbit R1等设备在“替代手机”的交互革命中艰难探索时,
另一条赛道正悄然兴起:
与其争夺交互入口,不如成为驱动智能的“引擎”。
Tiiny AI Pocket Lab正是这一理念的激进实践者。
它宣称是全球最小的AI超级计算机,能以30W的功耗在本地运行高达1200亿参数的模型,将云端的智能与隐私“装进口袋”。
本文将从系统架构视角,拆解这款“计算胶囊”如何实现服务器级性能,并审视其在当下AI硬件浪潮中的真实定位与挑战。
一、 市场定位:云AI的“叛逃者”,隐私与成本控制者的专属引擎
Tiiny AI Pocket Lab的定位清晰且锋利:
为拒绝云服务成本、担忧数据隐私、且需要高性能本地AI算力的用户,提供一个即插即用的“个人AI基础设施”。

图片来源:Tiiny AI宣传图
其目标用户画像明确:
核心用户:
AI开发者、研究人员、数据科学家。
他们需要频繁进行模型推理、测试Agent,对云API token成本敏感,且实验数据涉密。
扩展用户:
高度注重隐私的企业(法律、金融、医疗)、技术极客、以及渴望完全掌控个人数据的资深用户。
购买决策者与使用者合一: 决策完全基于个人或企业的技术需求与成本核算。
其核心卖点直击云服务的三大痛点:
成本不可控:
“直到账单寄到,你才真正知道每项操作需要消耗多少Tokens”。
Tiiny提供一次性硬件购买,实现“无限Token,零成本运行”。

隐私风险:
“更好的响应往往以牺牲您的隐私为代价”。
Tiiny主张100%设备端处理,数据不出设备,并提供硬件级AES-256全盘加密。
依赖性与延迟:
摆脱网络依赖,获得稳定低延迟的推理体验。
竞争环境:
1. 直接竞品:
高端消费级显卡(如RTX 4090)、苹果Mac Studio(M系列芯片)、以及NVIDIA Jetson等边缘计算设备。
Tiiny的差异化在于极致的便携性(142x80x22mm,300克)和开箱即用的AI软件栈。
2. 替代方案:
各类云AI服务(OpenAI、Claude、Azure等)。
Tiiny的挑战在于其本地模型性能能否持续追赶云端最新模型。
二、 产品体验与交互解构:从“调用API”到“拥有算力”
Tiiny的本质不是一个交互终端,而是一个计算加速器。
其核心体验围绕 “部署-运行-集成” 展开,而非“对话-响应”。
极简部署流程(Plug & Play):
通过Type-C连接电脑(支持macOS/Windows),即可被识别为外部AI算力设备。
大幅降低了本地部署大模型的环境配置复杂度。
丰富的模型与Agent生态:
预置并支持转换超过50个开源大语言模型和100多个智能体,涵盖从Qwen、Llama到专业代码模型。
用户可以在本地运行一个私有的“模型市场”。
无缝开发集成:
通过提供与OpenAI API兼容的接口,开发者可以几乎零成本地将现有基于LangChain、AutoGPT等框架的工作流,从云端迁移到本地Tiiny上,只需修改API的base_url和密钥。
专属应用场景:
作为AI编程助手(如辅助编写Flappy Bird游戏)、自动文件整理Agent、以及文生图应用的能力,体现了其作为“通用AI计算单元”的定位。
体验瓶颈:
其体验高度依赖于用户的技术能力。
普通消费者难以直接使用,它更像是一个面向B端或开发者群体的生产力工具。
三、 硬件与系统架构拆解:袖珍体积内的异构计算革命
Tiiny的硬件设计目标是:在移动电源般的体积内,塞入能运行百亿参数模型的服务器级算力与存储。
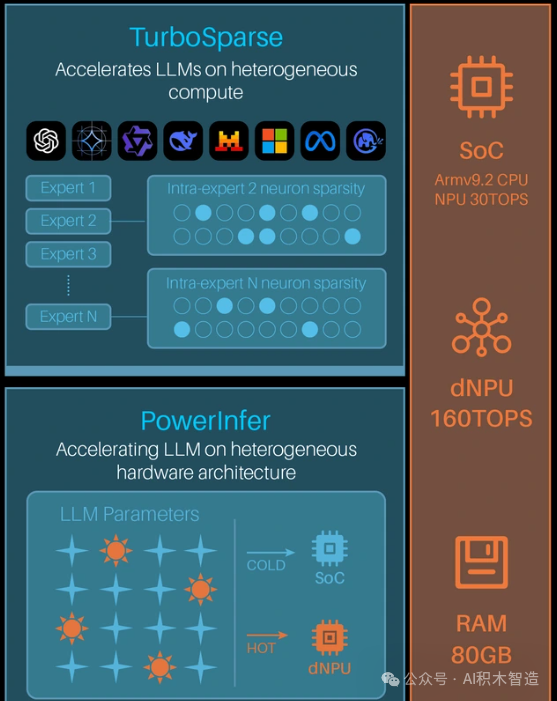
架构解析:
核心创新:PowerInfer + TurboSparse
这是Tiiny的灵魂。
传统大模型推理需要将全部千亿参数加载到内存,功耗和硬件成本极高。
PowerInfer 是一种基于稀疏激活的推理引擎。
在每次推理(解码)时,只有一小部分神经元(“热”神经元)被频繁激活,大部分(“冷”神经元)处于休眠。
TurboSparse 算法能智能识别这种稀疏性,并配合硬件架构,将“热”权重放在低功耗、快速的SoC NPU上,将海量的“冷”权重放在大容量的dNPU内存中。
仅在需要时,通过高效的PCle总线(文档计算仅需传输~5.6KB/步骤)调用“冷”权重。
结果:
以30W的超低功耗,实现了对120B模型20+ token/秒的推理速度,首令牌延迟仅0.5秒。
硬件堆叠:
双芯异构:SoC(CPU+NPU)负责通用计算与高频权重;
独立的dNPU芯片提供强大的专用算力和大容量权重存储。
这种设计类似AI Pin的“端云协同”思想,但在单设备内实现了“冷热数据协同”。
80GB LPDDR5X内存和1TB SSD,远超任何消费级手机或便携设备,确保了大型模型的加载和运行空间。
散热设计:
为了在紧凑空间内压制30W TDP,采用了超薄均热板、双风扇和散热鳍片,将运行噪音控制在35分贝以下。
四、 批判性评估:技术奇迹与市场现实的碰撞
优势(颠覆性价值):
1. 隐私安全的终极解决方案:
实现了真正意义上的“数据不出户”,为金融、法律、医疗等高敏感行业提供了可行的本地化AI部署方案,这与知识库中强调的隐私担忧痛点完美契合。
2. 总拥有成本(TCO)可能更低:
对于高频使用AI的开发者和企业,一次性硬件投入可能在未来1-2年内低于持续的云API订阅费用。
3. 技术架构的前瞻性:
其“稀疏激活+异构计算”架构,为边缘侧高效运行大模型指明了方向,是真正的硬科技创新。
短板与根本性挑战:
1. 高昂的入门门槛:
1399美元起的售价,将其牢牢限定在专业市场和极客群体,无法触及大众消费者。
这与Meta Ray-Ban智能眼镜299美元起的亲民定价形成鲜明对比。
2. 使用场景狭窄且专业:
它不是一个完整的产品,而是一个“组件”。
用户必须已经具备明确的、高频的本地AI推理需求,否则就是“屠龙技”。
3. 性能与生态的持续追赶:
本地开源模型的性能与体验,需要团队持续优化以追赶日新月异的云端闭源模型(如GPT-4o)。
其软件生态的丰富性也远不及成熟的云平台。
4. “移动性”的伪命题:
虽然便携,但必须连接主机电源和电脑使用,并非真正的“移动独立设备”。
其定位更像是一个外置的、专用的AI计算卡。
五、 未来展望与建议
Tiiny AI Pocket Lab的价值,不在于它今天能卖多少台,而在于它验证了“个人拥有高性能AI算力”在工程上的可行性。
它的发展路径应更偏向企业级和开发者生态,而非消费级。
坚定拥抱B端与开发者,做深垂直场景:
不应盲目追求消费级市场。
应重点攻克金融分析、代码生成、法律文书审核、医疗影像辅助分析等对隐私和成本极度敏感的垂直行业,提供行业定制化的模型包与解决方案。
大力投入开发者社区建设,成为AI应用开发者的“标准测试与部署平台”。
探索“算力订阅”或“硬件即服务”新模式:
对于中小企业,高昂的初次硬件投入仍是障碍。
可探索类似“显卡租赁”的算力订阅模式,降低初始使用门槛。
与云厂商合作,形成“混合云”方案:
敏感数据在Tiiny本地处理,非敏感任务或需要超大算力的训练任务仍可调用云端。
持续优化核心软件栈,降低使用门槛:
开发更友好的图形化管理界面,让非开发者用户也能轻松管理模型、部署智能体。
建立更自动化的模型优化与转换流水线,让用户能更容易地将自定义模型部署到Tiiny上。
审慎规划下一代形态,而非盲目小型化:
下一代产品不应单纯追求更小,而应在成本、功耗、性能三角中取得更优平衡,推出不同档次的产品线(如入门版、专业版)。
可考虑与OEM厂商合作,将Tiiny的核心板卡集成到高端笔记本、工作站甚至机器人中,作为其内置的AI大脑,拓展生态边界。
作者简介
卫朋,《硬件产品经理》作者,人人都是产品经理受邀专栏作家,CSDN认证博客专家、嵌入式领域优质创作者,阿里云开发者社区专家博主

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)