
lmdeploy v0.12.2 发布!全面支持 GLM5、Qwen3.5,性能与兼容性双升级,大模型部署再提速
模型支持更全面:覆盖GLM5、Qwen3.5、GLM-4.7等最新主流大模型,同时兼容Qwen、Internlm、Llama等经典模型,满足不同开发者的模型选型需求。推理性能更强劲:TurboMind引擎深度优化、MLA内核升级、FP8量化在线支持,大幅提升推理速度、降低显存占用,让大模型部署更高效、低成本。兼容性更广泛:适配Transformers 5.0、昇腾S1-Pro芯片、V100等主流硬

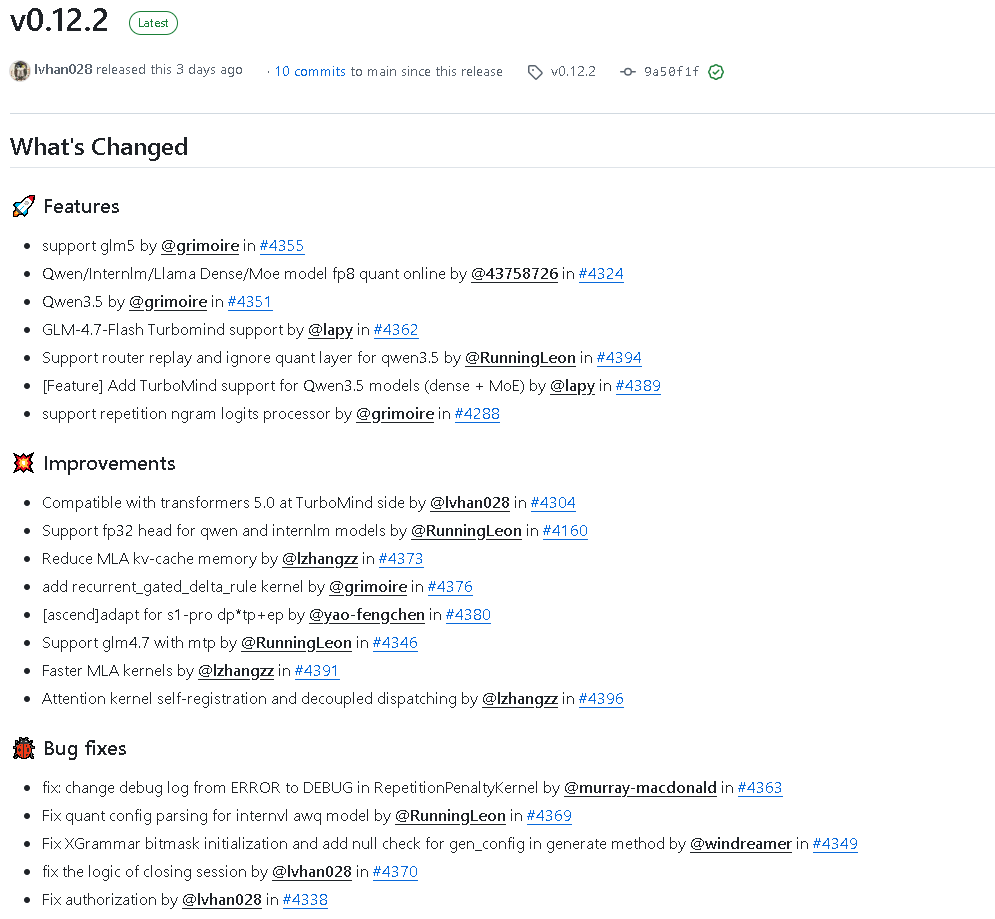
一、版本总览:2026开年关键迭代,大模型部署生态再进化
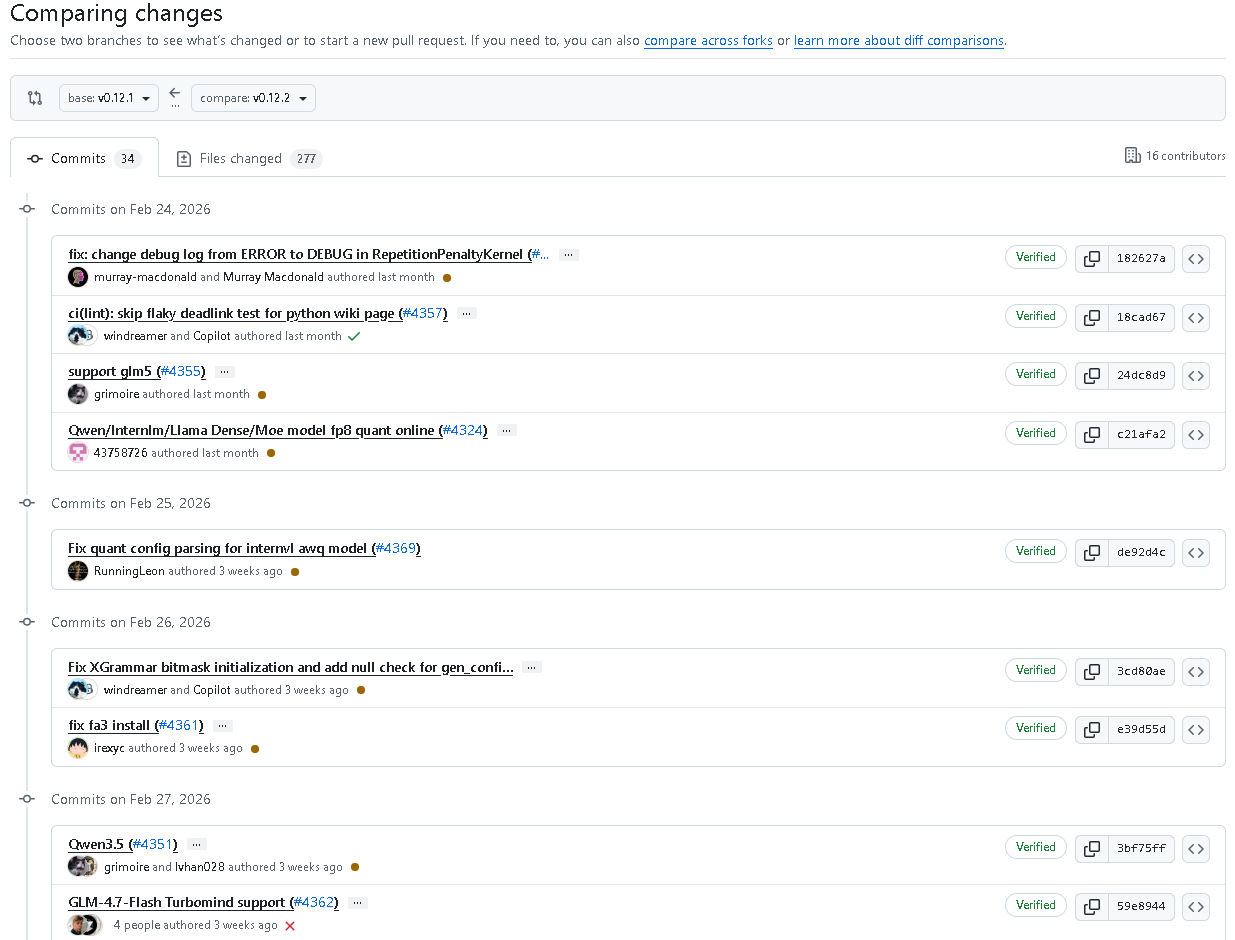
2026年3月18日,InternLM团队正式发布lmdeploy v0.12.2版本,作为开年以来的重要迭代,该版本聚焦模型支持广度、推理性能、量化能力、硬件兼容性、稳定性五大核心维度,完成34次提交、277个文件修改,由16位贡献者协同打磨,实现了对GLM5、Qwen3.5等主流大模型的全面适配,同时在TurboMind引擎优化、量化技术升级、Bug修复等方面实现突破性进展,为大模型高效、稳定、低成本部署提供了更强大的技术支撑。
lmdeploy作为覆盖大模型压缩、推理、服务的一体化部署工具包,凭借TurboMind高性能推理引擎、灵活的量化方案、多模型兼容能力,已成为大模型落地的核心基础设施。v0.12.2版本延续了工具的核心优势,进一步拓宽模型适配边界,强化性能与稳定性,无论是个人开发者的本地部署,还是企业级的大规模服务化,都能提供更优的解决方案。
二、核心新特性:模型支持全面扩容,推理能力再突破
(一)主流大模型全面适配,覆盖国产与开源生态
-
支持GLM5模型
作为本次版本的核心亮点之一,lmdeploy v0.12.2正式新增对GLM5模型的支持,补齐了对智谱AI主流大模型的部署能力。GLM5作为智谱AI推出的新一代大模型,在通用理解、逻辑推理、多轮对话等方面具备显著优势,此次适配让开发者可通过lmdeploy快速实现GLM5模型的本地推理与服务化部署,无需复杂的二次开发,即可将GLM5的能力集成到各类应用中。 -
新增Qwen3.5模型支持
紧跟通义千问模型迭代节奏,v0.12.2版本全面支持Qwen3.5系列模型,包括密集型(Dense)与混合专家型(MoE)架构。Qwen3.5作为阿里云推出的高性能大模型,在长文本处理、多模态交互、实时推理等场景表现突出,此次适配不仅实现基础推理支持,更通过TurboMind引擎深度优化,保障Qwen3.5模型在部署后的推理效率与稳定性。 -
GLM-4.7-Flash Turbomind专项支持
针对GLM-4.7-Flash模型,版本新增专属的TurboMind支持能力。GLM-4.7-Flash主打低延迟、高吞吐推理,适配实时对话、智能客服等对响应速度要求严苛的场景,lmdeploy通过定制化的TurboMind引擎适配,充分释放该模型的性能潜力,实现推理延迟与吞吐量的双重优化。 -
Qwen/Internlm/Llama系列模型FP8量化在线支持
为解决大模型部署中的显存占用与推理速度矛盾,v0.12.2版本实现对Qwen、Internlm、Llama三大主流模型系列(含Dense与MoE架构)的FP8量化在线支持。FP8量化作为兼顾精度与效率的量化方案,可在几乎不损失模型推理精度的前提下,将显存占用降低约50%,同时提升推理速度,大幅降低大模型部署的硬件门槛,让中低端GPU也能流畅运行百亿参数级大模型。
(二)推理与生成能力升级,提升生成质量与灵活性
-
新增TurboMind对Qwen3.5全架构支持
除基础适配外,版本通过专项开发,实现TurboMind引擎对Qwen3.5 Dense与MoE架构的完整支持。TurboMind作为lmdeploy的核心推理引擎,基于C++/CUDA实现,具备连续批处理、分块KV缓存、高性能算子等优势,此次针对Qwen3.5的深度优化,可让该模型在lmdeploy部署后,吞吐量较原生推理提升数倍,同时降低推理延迟。 -
支持Router Replay与量化层忽略(Qwen3.5专属)
针对Qwen3.5模型的MoE架构特性,版本新增Router Replay(路由重放)与忽略量化层功能。Router Replay可优化MoE模型中专家路由的推理效率,减少重复计算;忽略量化层则允许开发者针对模型特定层跳过量化,平衡推理精度与速度,满足不同场景的部署需求,进一步提升Qwen3.5模型部署的灵活性。 -
新增Repetition Ngram Logits Processor
为解决大模型生成过程中的重复文本问题,v0.12.2版本新增Repetition Ngram Logits Processor(重复N元语法逻辑处理器)。该功能通过对生成文本的N元语法进行检测与惩罚,有效抑制重复片段的生成,提升生成文本的连贯性、多样性与质量,尤其适用于长文本生成、内容创作、对话交互等场景。
三、性能与兼容性优化:引擎升级,适配更广泛硬件与框架
(一)TurboMind引擎深度优化,适配最新技术栈
-
兼容Transformers 5.0框架
随着Hugging Face Transformers框架迭代至5.0版本,lmdeploy v0.12.2同步完成TurboMind引擎的兼容性升级,确保基于最新Transformers框架训练或导出的模型,可无缝通过lmdeploy部署。此次兼容覆盖模型加载、权重解析、推理流程等全链路,避免因框架版本不匹配导致的部署失败,保障开发者使用最新模型与工具链的顺畅性。 -
支持Qwen与Internlm模型FP32 Head
针对Qwen与Internlm系列模型,版本新增FP32精度的输出头(Head)支持。在部分对推理精度要求极高的场景(如金融分析、医疗诊断、科学计算),FP32精度可避免量化带来的精度损失,保障输出结果的准确性;同时,该功能可与模型其他部分的量化方案灵活搭配,实现精度与效率的动态平衡。 -
MLA KV缓存内存占用优化
通过核心算法优化,版本实现MLA(Multi-Head Latent Attention)结构的KV缓存内存占用大幅降低。KV缓存作为大模型推理中显存占用的核心部分,其优化直接影响模型可部署的上下文长度与并发数,此次优化可在相同硬件条件下,支持更长的上下文窗口或更多的并发请求,显著提升长文本、多轮对话场景的部署能力。 -
新增Recurrent Gated Delta Rule内核
引入全新的Recurrent Gated Delta Rule(循环门控增量规则)计算内核,针对循环神经网络相关结构的推理进行专项加速。该内核通过优化门控机制与增量计算逻辑,减少冗余计算步骤,提升循环结构的推理速度,适配具备循环特性的大模型架构,进一步拓宽lmdeploy的模型适配范围与性能边界。 -
MLA内核性能再提升
在原有MLA内核优化基础上,版本推出更快的MLA计算内核,通过算子融合、内存访问优化、并行计算调度等手段,进一步提升MLA结构的推理效率。对于广泛采用MLA结构的现代大模型,该优化可直接降低推理延迟、提升吞吐量,让模型在高并发场景下更流畅运行。 -
注意力内核自注册与解耦调度
重构注意力内核的注册与调度机制,实现注意力内核的自注册与解耦调度。自注册机制简化了新内核的集成流程,降低开发者扩展内核的门槛;解耦调度则让注意力计算与其他推理步骤分离,提升计算调度的灵活性与效率,同时为后续多硬件、多架构的注意力内核适配奠定基础。
(二)硬件兼容性拓展,覆盖国产与主流算力平台
-
昇腾(Ascend)S1-Pro适配优化
针对国产昇腾S1-Pro芯片,版本完成深度适配,支持数据并行+张量并行+专家并行(dp*tp+ep) 混合并行策略。昇腾芯片作为国产算力的核心代表,此次适配让lmdeploy可在昇腾硬件上实现大模型的高效分布式部署,充分发挥国产芯片的算力优势,满足国产化替代场景的大模型部署需求。 -
GLM4.7模型MTP支持
新增对GLM4.7模型的MTP(Multi-Token Prediction,多令牌预测)支持。MTP技术可让模型单次推理生成多个令牌,大幅提升生成速度,尤其适用于长文本生成、批量内容处理等场景,结合lmdeploy的推理优化,GLM4.7模型部署后可实现更高的生成效率。
四、Bug修复:全链路问题解决,提升部署稳定性
(一)日志与内核问题修复
- 修复RepetitionPenaltyKernel中日志级别错误问题,将调试日志从ERROR级别调整为DEBUG级别,避免非错误日志干扰系统运行,同时保留调试信息的可追溯性。
- 修复InternVL AWQ模型的量化配置解析错误,解决AWQ量化模型加载时的配置解析异常,保障量化模型的正常部署与推理。
(二)生成与配置问题修复
- 修复XGrammar位掩码初始化错误,同时在生成方法中新增对生成配置(gen_config)的空值检查,避免因配置异常导致的推理崩溃,提升生成流程的稳定性。
- 修复会话关闭逻辑错误,优化会话资源释放流程,避免会话关闭时的资源泄漏与异常,保障多会话场景下的系统稳定性。
(三)授权与推理流程修复
- 修复授权机制异常,解决模型部署与推理过程中的授权验证问题,保障合规使用模型的同时,避免授权错误导致的服务中断。
- 修复Pipeline模块的多个 minor 问题,并补充完善测试用例,提升Pipeline离线推理与批量处理的稳定性,覆盖更多边缘场景。
- 修复dllm mask在set_step操作中的逻辑错误,解决掩码设置异常导致的推理结果偏差,保障生成文本的正确性。
(四)框架兼容与硬件适配修复
- 修复与Transformers 5.0及以上版本的模型兼容问题,解决因框架接口变更导致的模型加载失败,确保新旧版本模型均可正常部署。
- 修复请求中止时的异常抛出问题,优化请求中断处理逻辑,避免中止请求引发的系统崩溃,提升服务的健壮性。
- 修复V100显卡运行Qwen3.5-0.8B模型时的推理崩溃问题,解决特定硬件与模型组合的兼容性异常,保障主流显卡的部署可用性。
五、其他优化:工程化与生态完善,提升开发与部署体验
(一)CI与开发流程优化
- 优化CI lint流程,跳过Python维基页面中不稳定的死链接测试,避免因外部链接异常导致的CI构建失败,提升持续集成的稳定性与效率。
- 集成clang-format代码格式化工具到pre-commit钩子,强制统一代码风格,减少团队开发中的代码格式冲突,提升代码质量与可维护性。
- 修复FA3安装问题,解决FA3库安装过程中的依赖与编译异常,保障依赖库的正常安装与使用。
- 修复代码 lint 错误,清理代码中的语法、格式与潜在逻辑问题,提升代码的健壮性。
(二)依赖与环境升级
- 升级Triton与PyTorch依赖版本,适配最新的算子优化与硬件支持,借助新版本的性能特性,进一步提升推理引擎的效率。
- 新增 speculative decoding(推测解码)测试用例,完善测试覆盖范围,保障推测解码功能的稳定性与正确性,为后续该功能的正式上线奠定基础。
(三)Docker镜像与构建优化
- 更新Dockerfile,移除CUDA 11相关支持,将CUDA 12.4升级为CUDA 12.6,适配最新的NVIDIA显卡驱动与CUDA生态,提升Docker部署的兼容性与性能。
- 调整开发镜像构建策略,改为手动构建开发镜像,而非每个版本自动发布,减少不必要的镜像构建与存储开销,优化CI/CD流程。
(四)版本收尾工作
完成版本号从v0.12.1升级至v0.12.2的收尾工作,同步更新相关配置文件与文档,确保版本标识的一致性,方便开发者识别与使用。
六、版本价值与应用场景总结
(一)核心价值提炼
- 模型支持更全面:覆盖GLM5、Qwen3.5、GLM-4.7等最新主流大模型,同时兼容Qwen、Internlm、Llama等经典模型,满足不同开发者的模型选型需求。
- 推理性能更强劲:TurboMind引擎深度优化、MLA内核升级、FP8量化在线支持,大幅提升推理速度、降低显存占用,让大模型部署更高效、低成本。
- 兼容性更广泛:适配Transformers 5.0、昇腾S1-Pro芯片、V100等主流硬件与框架,打通国产化与通用化部署路径。
- 稳定性更可靠:全链路Bug修复,覆盖日志、配置、推理、授权等多个环节,解决部署与运行中的各类异常,保障服务稳定运行。
- 开发体验更友好:CI流程优化、依赖升级、Docker镜像调整,降低开发与部署门槛,提升团队协作效率。
(二)核心应用场景
- 企业级大模型服务部署:支持多模型、高并发、长文本场景,适配智能客服、内容生成、数据分析等企业应用,保障服务的稳定性与效率。
- 国产化算力部署:昇腾芯片深度适配,满足金融、政务等领域的国产化替代需求,实现安全、自主的大模型落地。
- 个人开发者本地部署:FP8量化降低硬件门槛,中低端GPU即可运行大模型,方便个人开发者快速验证模型效果、开发原型应用。
- 前沿模型快速适配:对GLM5、Qwen3.5等最新模型的即时支持,让开发者可第一时间体验并部署前沿大模型能力。
七、总结与展望
代码地址:github.com/InternLM/lmdeploy
lmdeploy v0.12.2版本作为2026年的关键迭代,以模型适配、性能优化、兼容性拓展、稳定性提升为核心,完成了一次全面且深入的升级,进一步巩固了其在大模型部署领域的领先地位。无论是模型支持的广度,还是推理性能的深度,亦或是工程化的完善度,都实现了质的飞跃,为大模型的规模化落地提供了更强大的工具支撑。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)