
华为AI产品和技术由浅入深巅峰解析
华为昇腾(Ascend)是自研AI处理器品牌,涵盖310/910/920等系列芯片,面向训练/推理场景,算力从16TOPS至376TFLOPS不等。Atlas是基于昇腾芯片的服务器产品线,包含加速卡(如300I)、边缘设备(500系列)及超算集群(900 SuperPod)。核心技术包含:DVPP硬件预处理单元(视频编解码/图像处理)、AI Core矩阵计算核心、统一内存管理架构,形成"
华为人工智能数据中心技术介绍系列 之一
Ascend(昇腾):芯片品牌
华为自研的 AI 处理器 / NPU 架构与芯片系列的品牌
Ascend的主要指标
- 算力(TOPS/TFLOPS)
- 精度(FP16/BF16/INT8)
- 内存带宽
- 功耗
- 芯片互联(HCCS)
可以理解为“这块硅到底能算多快”
Ascend的命名逻辑
按芯片代际 + 能力定位
| 芯片代际 | 定位 |
|---|---|
| 310 | 低功耗推理 |
| 910 | 高端训练 |
| 920 | 高端训练,目前产量少 |
后缀含义
| 后缀 | 定位 | 典型型号 |
|---|---|---|
| A | 初代量产 / 标准基线 | 910A, 910ProA, 910PreminumA |
| B | 主流量产优化 | 910B, 910B2/B3/B4 |
| C | Chiplet 双芯合封 | 910C1/C2/C3/C4 |
昇腾发展历史
1. 第一代昇腾(2018-2020)
昇腾310:面向边缘推理场景,采用12nm工艺,INT8算力16 TOPS,功耗8W,主打低延迟推理(如摄像头、车载设备)。
昇腾910:首款数据中心级训练芯片,7nm工艺,FP16算力256 TFLOPS,功耗310W,支持华为全栈AI生态(MindSpore、ModelArts)。
2. 第二代昇腾(2021-2023)
昇腾910B:7nm+ EUV工艺优化,FP16算力提升至376 TFLOPS,支持更高效的大模型训练,适配华为云昇腾AI云服务。
昇腾310B:边缘端升级版,支持多模态推理(视觉、语音),集成轻量级MindSpore Lite框架。
3. 第三代昇腾(2024-2025)
昇腾910C:用于CloudMatrix 384超节点集群,单节点集成384颗芯片,支持万亿参数大模型训练,显存带宽优化至3TB/s以上。
昇腾320:面向边缘计算的下一代芯片,5nm工艺,能效比提升50%,支持端-边-云协同推理。
4. 未来规划(2026+)
昇腾920:预计采用3nm工艺,FP16算力目标突破1 PFLOPS,支持FP8精度和动态稀疏计算,适配MoE架构大模型。
Atlas:服务器品牌
使用 Ascend 芯片封装出来的具体产品(模块、加速卡、服务器、集群)的品牌
它是工程产品线,基于Ascend芯片做成的工程化交付
它包括:
- 模块
- PCIe设备
- 边缘盒子
- 服务器
- 超级节点/集群
Atlas主要关心的
- 怎么放进机房
- 怎么上架、供电、散热
- 怎么部署业务
- 怎么规模化交付
可以理解为“怎么把算力真正用起来”
Atlas的命名逻辑
按产品形态 + 场景
加速卡产品
| 产品类型 | 做什么 | 用什么芯片 |
|---|---|---|
| Atlas 200I DK A2 | 学校教学课程、算法验证 | Ascend 310B3 |
| Atlas 200I A2加速模块 | 集成于边端智能设备、机器人、无人机中,提供AI算力 | 昇腾 310/ 910 |
| Atlas 300I A2 推理卡 | 小规模推理 | 昇腾 310B |
| Atlas 300I Duo 推理卡 | 小规模推理 | 两颗昇腾 310P3 |
| Atlas 300V Pro 视频解析卡 | 推理+视频解析 | 昇腾 310P3 |
| Atlas 300I Pro 推理卡 | 小规模推理 | 昇腾 310P3 |
| Atlas 300V 视频解析卡 | 推理+视频解析 |
整机产品
| 产品类型 | 做什么 | 用什么芯片 |
|---|---|---|
| Atlas 500 A2 智能小站 | 面向边缘应用的产品,形似机顶盒,可室外部署 | |
| Atlas 800T A3 超节点服务器 | 预训练/后训练服务器 | 单机8 * 昇腾910, 多机可组成384卡超节点 |
| Atlas 800I A3 超节点服务器 | 推理服务器 | 单机8 * 昇腾910,多机可组成最大384卡超节点 |
| Atlas 800T A2 训练服务器 | 训练 | 8 * 昇腾910 |
| Atlas 800I A2 推理服务器 | 推理 | 8 * 昇腾910 |
| Atlas 800 推理服务器 (型号:3000) | 实时推理,视频分析 | 最大可支持8个Atlas 300I/V Pro |
| Atlas 500 Pro 智能边缘服务器 (型号:3000) | 实时推理,视频分析,面向边缘应用的产品,具有高环境适应性 | 最大支持3个Atlas 300I/V Pro |
集群产品
| 产品类型 | 做什么 | 用什么芯片 |
|---|---|---|
| Atlas 900 A3 SuperPoD | 384张NPU像一台计算机一样工作 | 384 * 昇腾910 |
| Atlas 900 A2 PoD | 极致算力密度、极高AI能效、极简交付部署 | 64 * 昇腾910 |
| Atlas 900 SuperCluster AI 集群 | 支撑单集群最大12.8w卡规模 | 384* 昇腾910 |
生态组件
MindSpore MindIE CANN(Compute Architecture for Neural Networks)
华为HDK(Hardware Develop Kit)
服务器操作

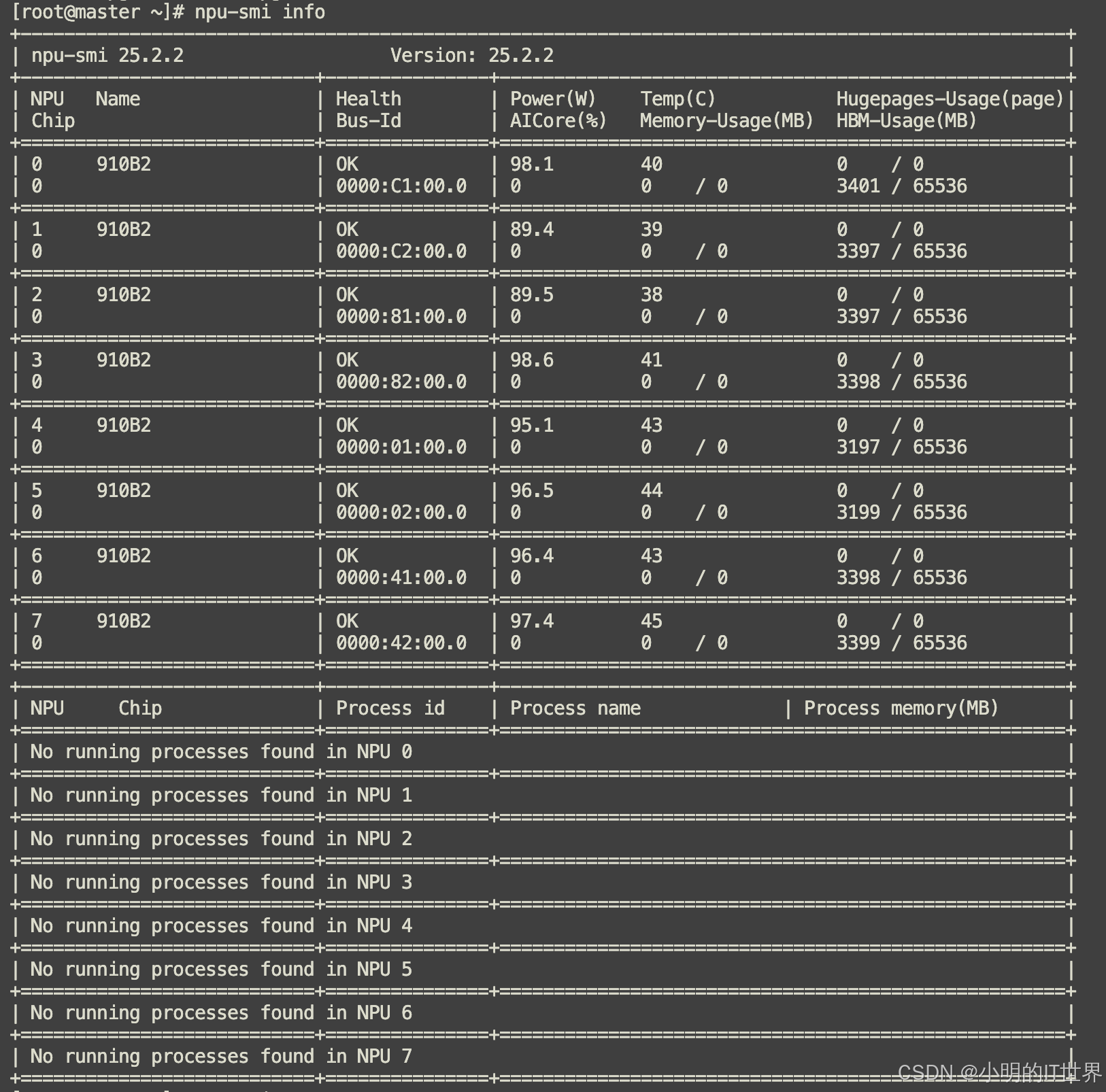
每个芯片里有24个AI core。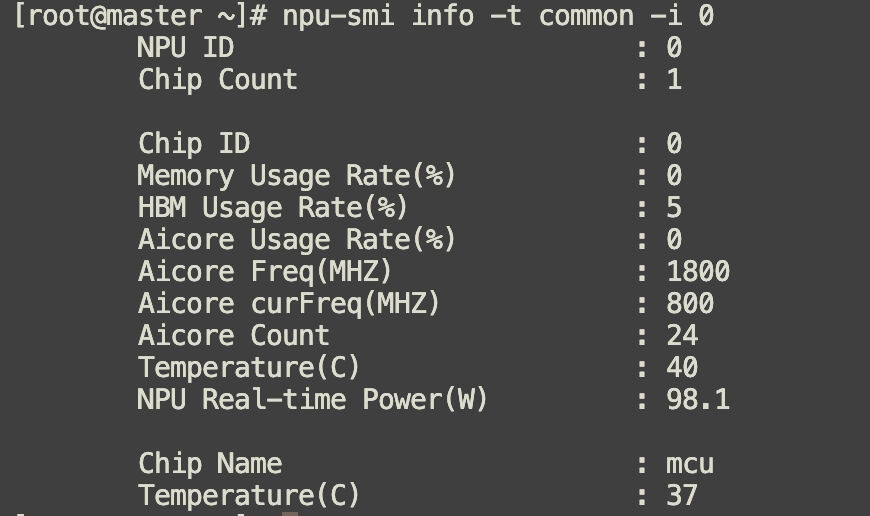
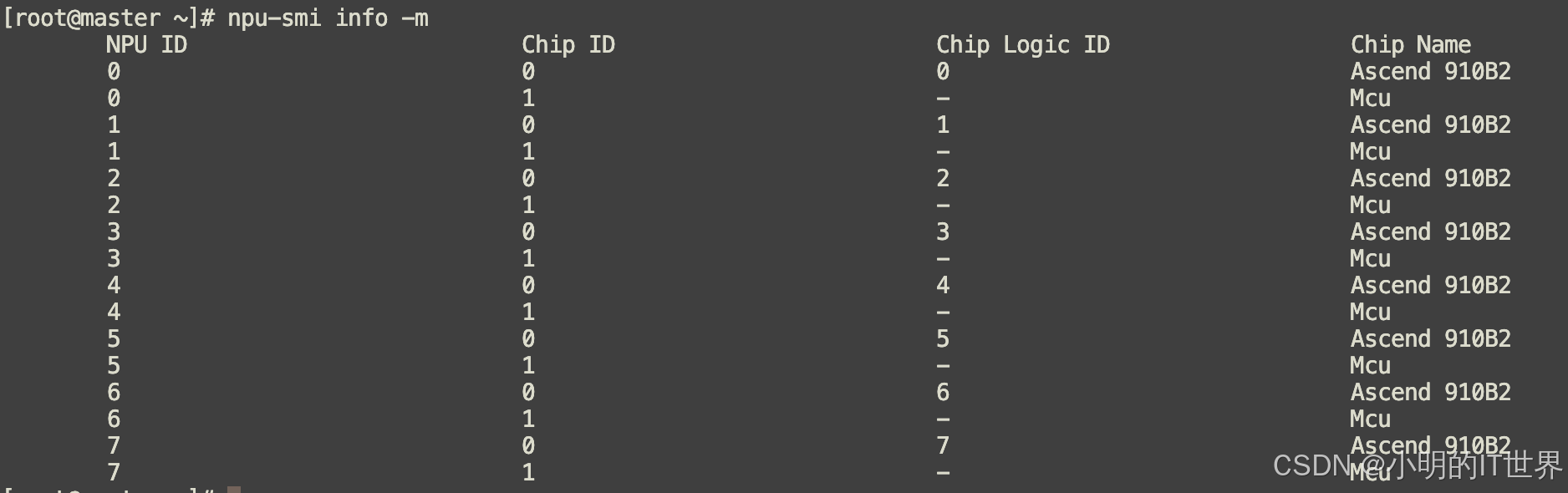
可以看到,每个NPU都配有一块MCU。MCU(Micro Controller Unit)是MCU 是一个独立的、低功耗的微处理器,它主要负责以下带外管理(Out-of-Band Management) 任务:
-
环境监控(Health Monitoring)🌡️
实时监测芯片的温度、电压和电流。
如果温度过高,MCU 会触发保护机制(如降频或关机),防止硬件烧毁。 -
功耗管理(Power Management)⚡
统计整片的功耗数据。
控制电源轨的开启和关闭序列。 -
上报与通信 📡
通过特定的总线(如 I2C 或串口)与服务器的主板管理控制器(BMC)通信。
这就是为什么即使 NPU 还没加载驱动,你有时也能通过主板查看到 NPU 的基本健康状态。 -
固件管理 💾
负责 NPU 启动时的引导安全校验,管理加载芯片内部的微码。
查看MCU 采集的各项指标:
npu-smi info -t health -i 0
npu-smi info -t power -i 0
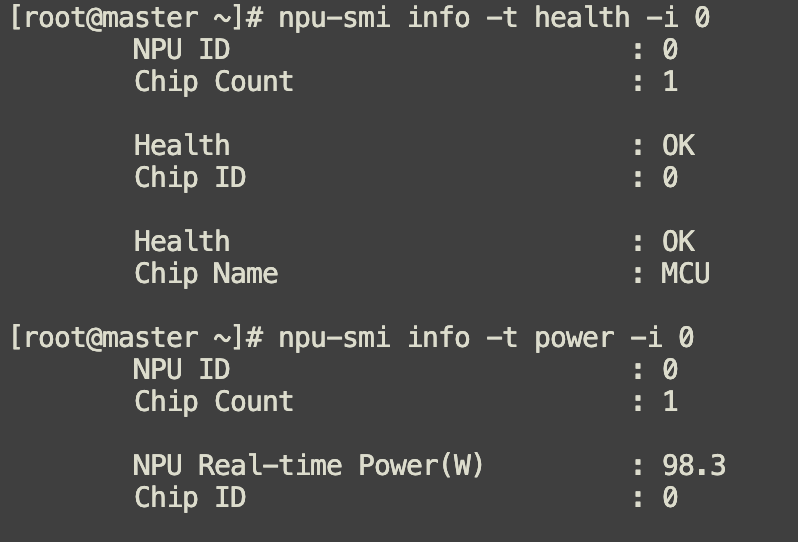
npu-smi info返回结果的具体解释:
-
AICORE (AI Core):是昇腾AI处理器的核心计算单元,专门负责执行神经网络中的密集型计算任务。
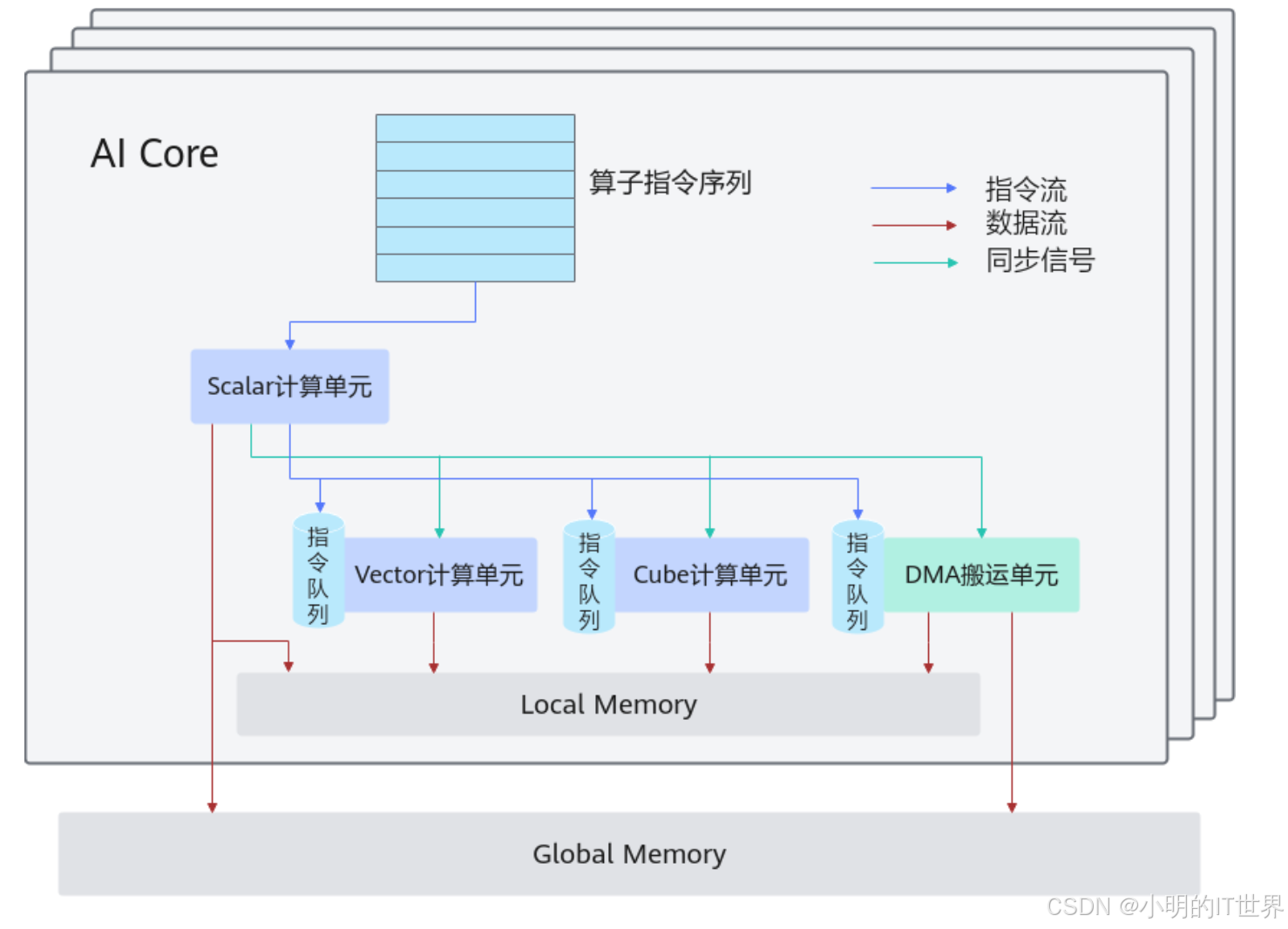
它内部集成了Cube单元(负责矩阵运算)、Vector单元(负责向量运算)以及Scalar单元(负责标量运算和程序控制)。
DMA负责Global Memory和Local Memory之间的数据搬运以及不同层级Local Memory之间的数据搬运。 -
AICPU (AI CPU):是AI处理器内部负责非矩阵类复杂计算的通用处理器单元。它通常用于处理AI Core不擅长的控制逻辑、复杂的非并行运算或作为整个系统的任务调度补充
-
数字视觉预处理 DVPP(Digital Video Pre-Processing)
这是专门负责“原材料加工”的。在处理视觉任务时,它能快速进行视频解码、图片缩放和色域转换,确保送入 AI Core 的数据格式是标准的。
虽然 AI Core 的矩阵运算能力极强,但让它处理图像预处理(如 JPEG 解码、缩放)效率其实并不高。AI Core 运行速度极快,如果它还要分心去搬运原始数据、处理不规则的图像格式,会频繁导致流水线停顿。为了让 AI Core 全神贯注于神经网络推理,DVPP 内部集成了一系列**硬核(Hardwired)**加速单元,专门负责图像和视频的全流程处理:
| 单元名称 | 全称 | 核心职责 |
|---|---|---|
| VDEC 🎞️ | Video Decoder | 视频解码:支持 H.264/H.265 等格式硬件解码,将视频流转为 YUV 格式原始图像。常用于实时视频流分析场景。 |
| VENC 📹 | Video Encoder | 视频编码:将处理好的结果重新编码为视频流格式(如H.264或H.265)。 |
| JPEGD 🖼️ | JPEG Decoder | 图片解码:将常见的 JPEG/JPG 图片解码为 YUV 或 RGB 格式。 |
| JPEGE ✉️ | JPEG Encoder | 图片编码:将结果编码保存为JPEG图片。 |
| VPC ✂️ | Video Pre-Processing | 图像处理核心:负责缩放(Resize)、裁剪(Crop)、色域转换(如 YUV 转 RGB)。 |
| PNGD 📂 | PNG Decoder | PNG 解码:专门负责将PNG格式图像数据解码为原始像素数据的硬解码单元。 |
解决的是“从文件到张量”的硬核转换(如从 MP4/JPG 到 YUV 图像)。
这些模块共同构成了昇腾处理器的 数字视觉预处理(DVPP) 系统,通过专用硬件加速,极大减轻了AI Core和CPU在处理多媒体数据时的负担。
总结来说,DVPP 负责重体力活(编解码、大跨度缩放),AIPP 负责精细调校(归一化、色域转换),而 AI Core 负责终极推理。这种分工明确的异构架构,正是昇腾芯片能高效处理海量视频流的关键。
为了把 DVPP 处理好的图像高效的送给 AI Core 进行深度学习推理,昇腾 NPU 采用了一套高效的内存管理机制:
- 统一寻址空间:DVPP、AI Core 和 AI CPU 虽然功能不同,但它们可以访问同一片连续的物理内存。
- 内存池管理:开发者通过 hi_mpi_dvpp_malloc 申请的内存,其物理地址对于所有硬件单元都是透明且可达的。
- 指令链衔接:当你调用完 DVPP 的缩放接口后,DVPP 会把结果写回内存,并发送一个信号通知 Task Scheduler。随后,Task Scheduler 直接把这个内存地址指针发给 AI Core 启动计算。
至此为止,整个数据处理流程形成了一个完美数据漏斗:
总结一下“四驾马车”:
| 单元 | 角色 | 比喻 |
|---|---|---|
| AI Core | 算力核心 | 生产线工人 |
| AI CPU | 逻辑/任务管理 | 车间主任 |
| DVPP | 图像预处理 | 原料加工间 |
| MCU | 芯片监控管理 | 安保+电工 |
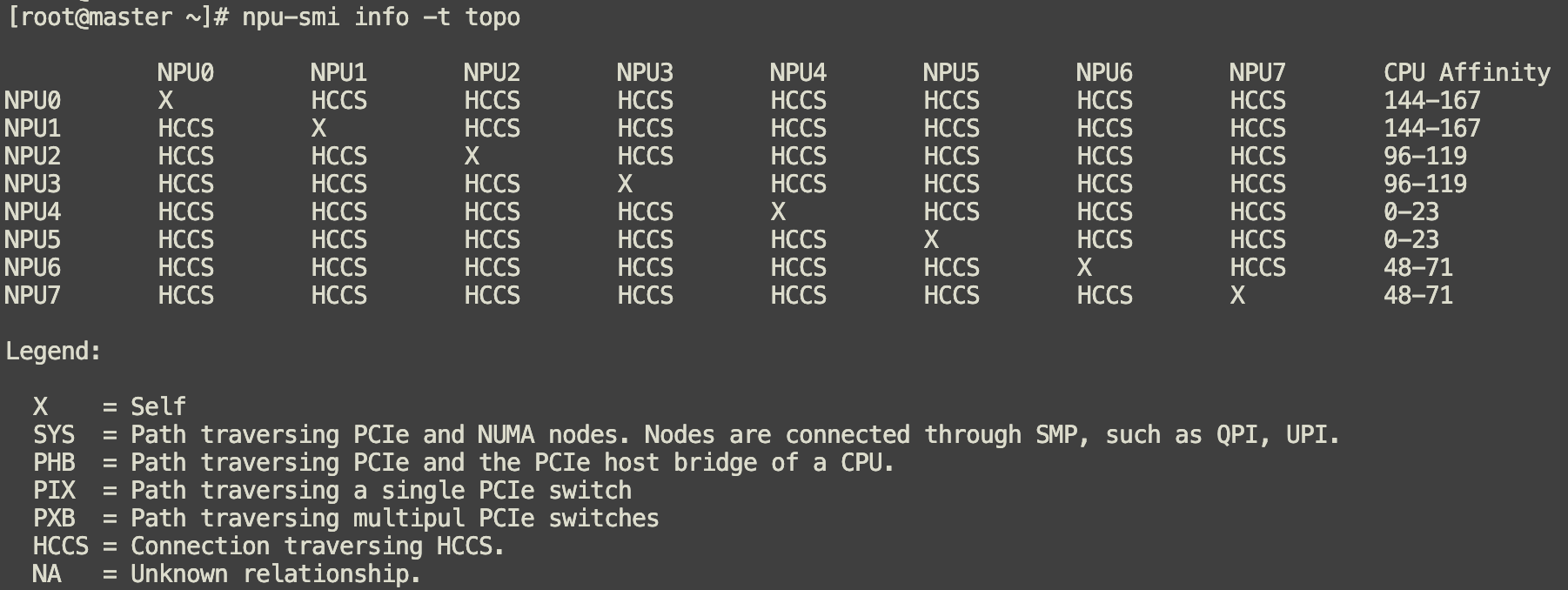
NPU之间的拓扑连接信息
硬切分
硬切分(Hardware Partitioning) 通常指通过 Virtual NPU (vNPU) 技术,将一颗物理 NPU 划分为多个相互隔离的逻辑资源实例。这种切分是在硬件资源(AI Core、存储带宽等)层面进行的物理隔离,能够确保不同任务之间的性能互不干扰。
910B支持硬切分,查询当前型号支持的切分模板。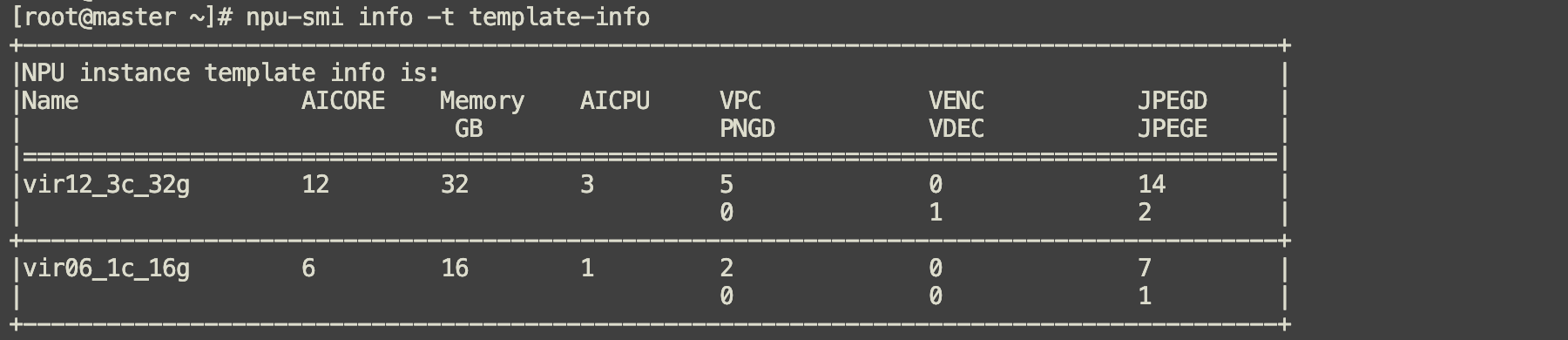
结果显示,这张NPU支持两个硬切分模板:
vir12_3c_32g (一张910B2 NPU最多可以划分成2个这个规格的实例)
vir06_1c_16g (一张910B2 NPU最多可以划分成4个这个规格的实例)
查询0号NPU的0号chip的vNPU信息,目前0号NPU在未做切分之前的算力和存储情况,可以看到910B2 NPU是没有VENC和PNGD的。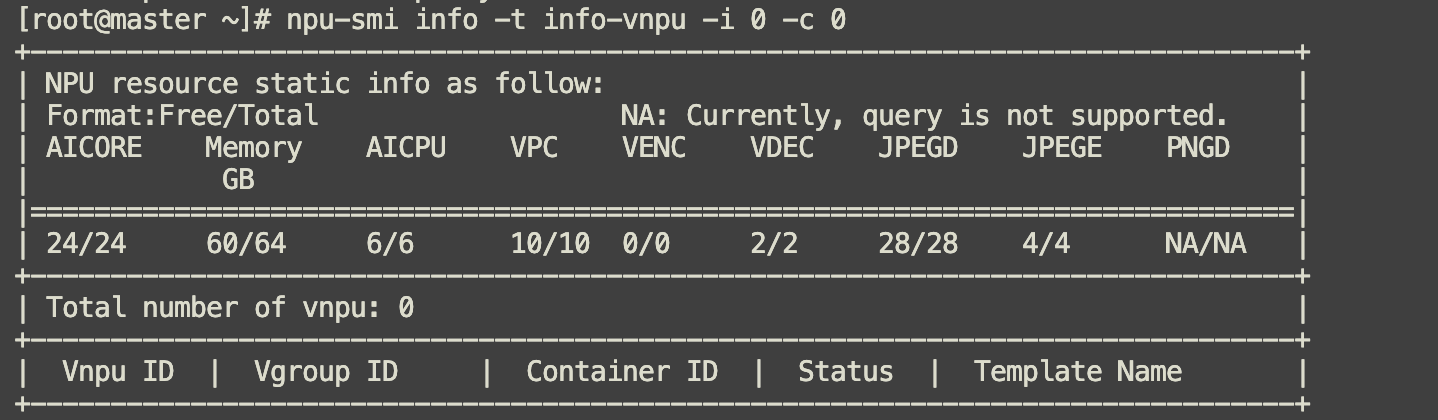
vNPU算力切分有两种模式:
- 0: 容器模式算力切分
- 1: 虚拟机模式算力切分

# 设置为容器算力切分模式
npu-smi set -t vnpu-mode -d 0
更多精彩内容,关注微信公众号 小明的IT世界

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)