
昇腾GE图模式基础简介
作者:昇腾实战派
背景概述
在PyTorch 2.0之前,PyTorch主要采用eager execution(即时执行)模式。这种模式虽然灵活易用,但也带来了一些性能瓶弱点: 传统PyTorch在运行时需要逐行执行Python代码,这涉及大量的Python解释器开销。每个操作都需要单独调度到device(如NPU,GPU),导致频繁的host-device通信。此外,PyTorch无法看到完整的计算图,因此难以进行全局优化,比如算子融合、内存布局优化等。 torch.compile的出现正是为了解决这些问题,它能够将PyTorch模型编译成优化的底层代码,显著提升性能。
1 计算图机制
- 静态计算图:TensorFlow早期版本(1.x)需先定义完整计算图再执行,调试困难(需通过
tf.Print等特殊接口)。 - 动态计算图(Eager Execution):也叫单算子模式,代码执行与计算过程同步,支持实时修改计算逻辑,代码更加直观易懂,调试也更加方便。TensorFlow2.x版本默认启用动态图,torch从一开始就采用动态图机制。
- **图模式(Graph Mode):**torch2.x之后通过torch.compile实现计算图的编译(即时编译,just-in-time,JIT)来进行性能优化,在1.x之前使用torch.jit.script/trace接口实现。
正是因为compile 图模式横空出世,将 PyTorch 从 1.0 直接跃升成 2.0。图模式也可以理解为之前动静态结合的产物。
举个例子:
torch.compile提供了三种编译模式,可以通过mode参数指定:
- default: 是默认模式,平衡编译时间和运行时性能,适合大多数场景。
- reduce-overhead:进一步减少框架开销,特别适合小模型或推理场景,但编译时间会更长。
- max-autotune:会尝试多种kernel实现并选择最快的,编译时间最长但性能最好,适合生产环境部署。
torch.compile提供了多种可选后端,可以通过backend参数指定:
- inductor:静态图模式,默认值,这个模式下无法调试,中间的print代码也将失效。生成部署阶段使用
- eager:动态图模式(eager),开发调试阶段使用
- torch_tensorrt:结合TensorRT加速JIT流程,支持CUDA模型优化
- torchair:华为昇腾NPU专用优化器
- triton:通过Triton库加速计算
torch的trace,scrpt,compile区别:
| 维度 | **torch.jit.trace** |
**torch.jit.script** |
**torch.compile** |
|---|---|---|---|
| 实现机制 | 记录前向传播操作(静态路径) | 解析模型代码(支持动态控制流) | 动态图(Eager模式)/静态图(Graph模式)优化 |
| 优化能力 | 静态图优化(如算子融合) | 支持复杂逻辑(需手动处理控制流) | 全局优化(如T+T融合)/实时调试 |
| 使用场景 | 简单模型导出(如ResNet) | 复杂模型导出(如RNN) | 生产部署/开发调试 |
| 兼容性 | 通过torch.jit.load加载(需手动处理语法) |
通过torch.jit.load加载(需手动处理语法) |
与原生PyTorch兼容(需通过torch.compile启用) |
2 Pytorch框架Eager和图模式架构对比
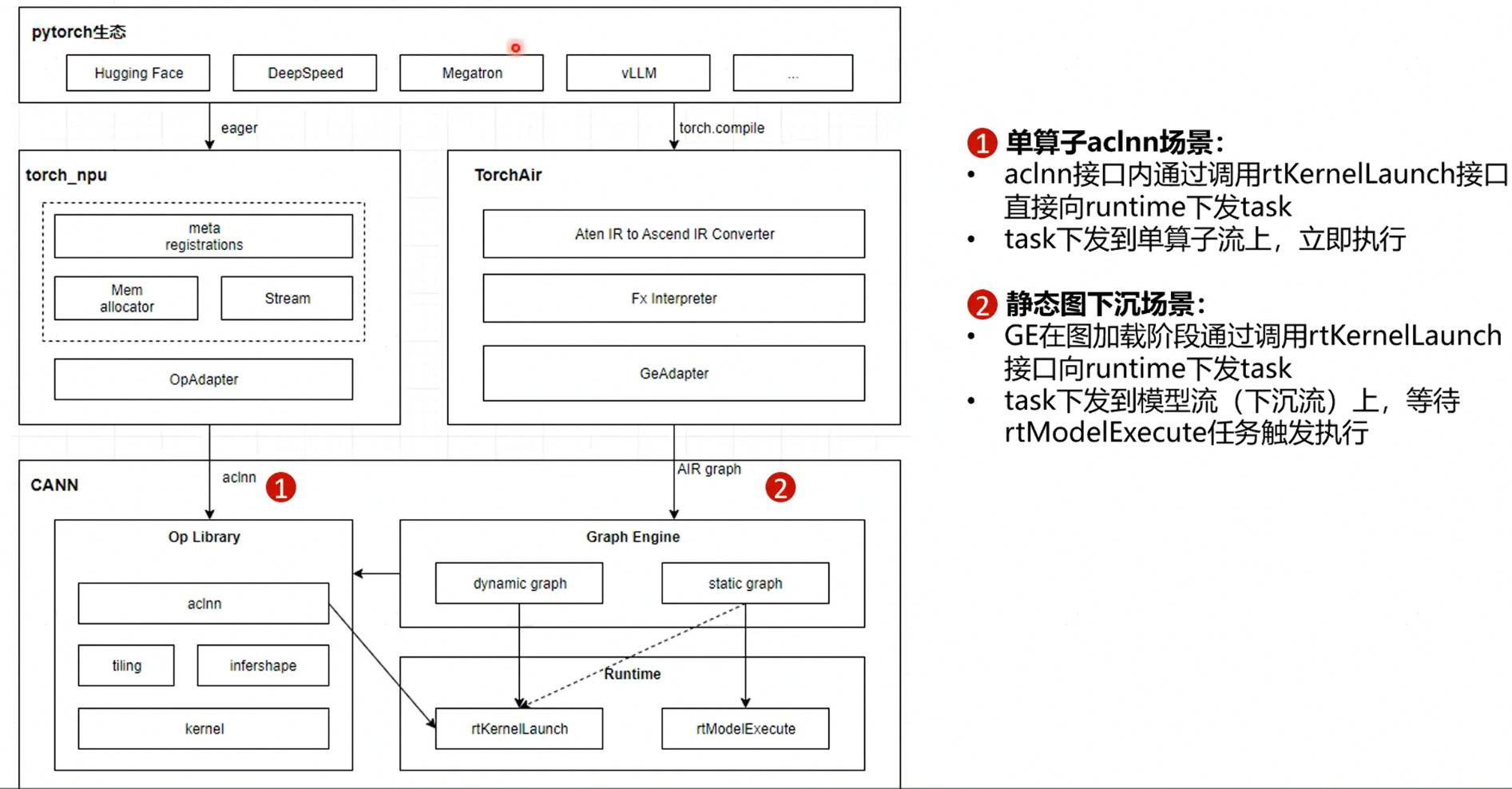
单算子模式
从torch下来调到aclnn。aclnn包括的tiling infershape kernel(算子实现)等都归属于算子库。需要在opp包中匹配到编译好的单算子,具体又分为动态算子实现和静态算子实现。
单算子的aclnn内部会去直接调用runtime的kernelLaunch接口,没有经过GE框架。
单算子模式是一种Host调度模式,由Host CPU逐个下发算子,一个算子的下发流程包含Python处理、Python到C++数据结构转换、Tiling计算,申请算子的Workspace内存和输出内存,Launch等Host操作。
为了加速单算子Host调度,在PyTorch中,昇腾适配层采用了生产者—消费者双线程模式加速,生产者线程主要负责Launch之前的处理动作,消费者线程主要负责Launch算子。
图模式
每一个Aten IR到每一个GE IR之间都有独立的converter函数。TorchAir会依次调用来完成整张图的转换。转换成GE图后,GE模块会区分是动态图还是静态图。
如果是动态图,会经过GE的动态执行器,去调用runtime的kernelLaunch接口。
静态图分为加载阶段和执行阶段,加载阶段会去调用kernelLauch的接口下发task,把task保留在模型流(ModelStream)上,但不会立即执行。会等待rts提供的rtModelExecute接口触发流上的任务开始执行。
3 昇腾GE介绍
图引擎(Graph Engine,简称GE)作为昇腾平台计算图编译和运行的控制中心,提供了图构建、图编译优化及图执行控制等功能。借助GE图引擎能力,PyTorch、TensorFlow、MindSpore、PaddlePaddle等主流AI框架的算法模型可以统一转换为使用Ascend IR(Ascend Intermediate Representation)表示的计算图(Ascend Graph),并通过GE的图编译加速技术,显著提升计算图在昇腾硬件上的执行效率。此外,GE还提供统一的图开发接口,支持自定义图结构,帮助用户基于昇腾硬件快速部署神经网络业务。
3.1 常见GE接入路径
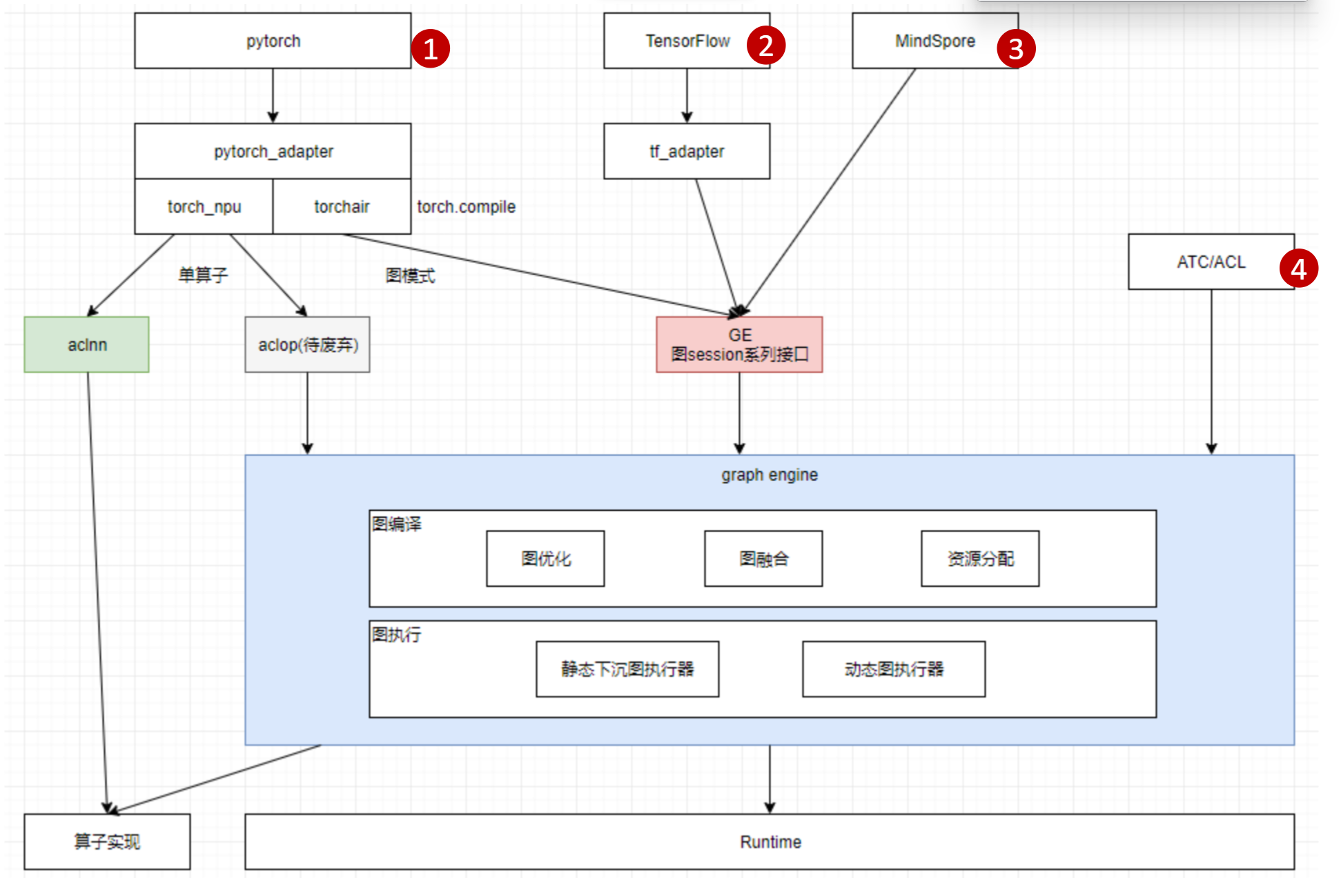
上图标注了图模式的4种接入的路径。
- 路径1 pytorch:是目前比较火的,在大模型的场景下用的最多的场景。适配层包含两路:
- torch_npu:单算子场景下的适配。会走到aclnn接口,直接去调用算子实现。
- torchair:图模式场景下的适配。会构造一张GE图,通过调用GE的图session系列接口进入GE模块。GE模块拿到图之后会做图编译和图执行,再往下会调用runtime模块的一些能力。
- 路径2 tensorflow:这条路径由来已久,以前的小模型一般都是用tensorflow的入口接入进来。通过tf_adapter适配层把tensorflow的图转化成GE的图。
- 路径3 MindSpore:hw自研框架,会直接调用GE的图session系列接口。
- 路径4 ATC/ACL:不带框架的场景。比如:离线场景、C++的一些客户的自研框架等会从此入口接入进来。
TorchAir:Torch Ascend Intermediate Representation,是昇腾的图模式能力扩展库,提供了昇腾设备亲和的torch.compile图模式后端,实现了PyTorch网络在昇腾NPU上的图模式推理加速以及性能优化。
ATC:Ascend Tensor Compiler,是异构计算架构CANN体系下的模型转换工具,它可以将开源框架的网络模型以及Ascend IR定义的单算子描述文件(JSON格式)转换为昇腾AI处理器支持的.om格式离线模型
ACL:Ascend Computing Language,是一套用于在昇腾平台上开发深度神经网络应用的C语言API库,提供运行资源管理、内存管理、模型加载与执行、算子加载与执行、媒体数据处理等API
3.2 GE与引擎的交互架构视图
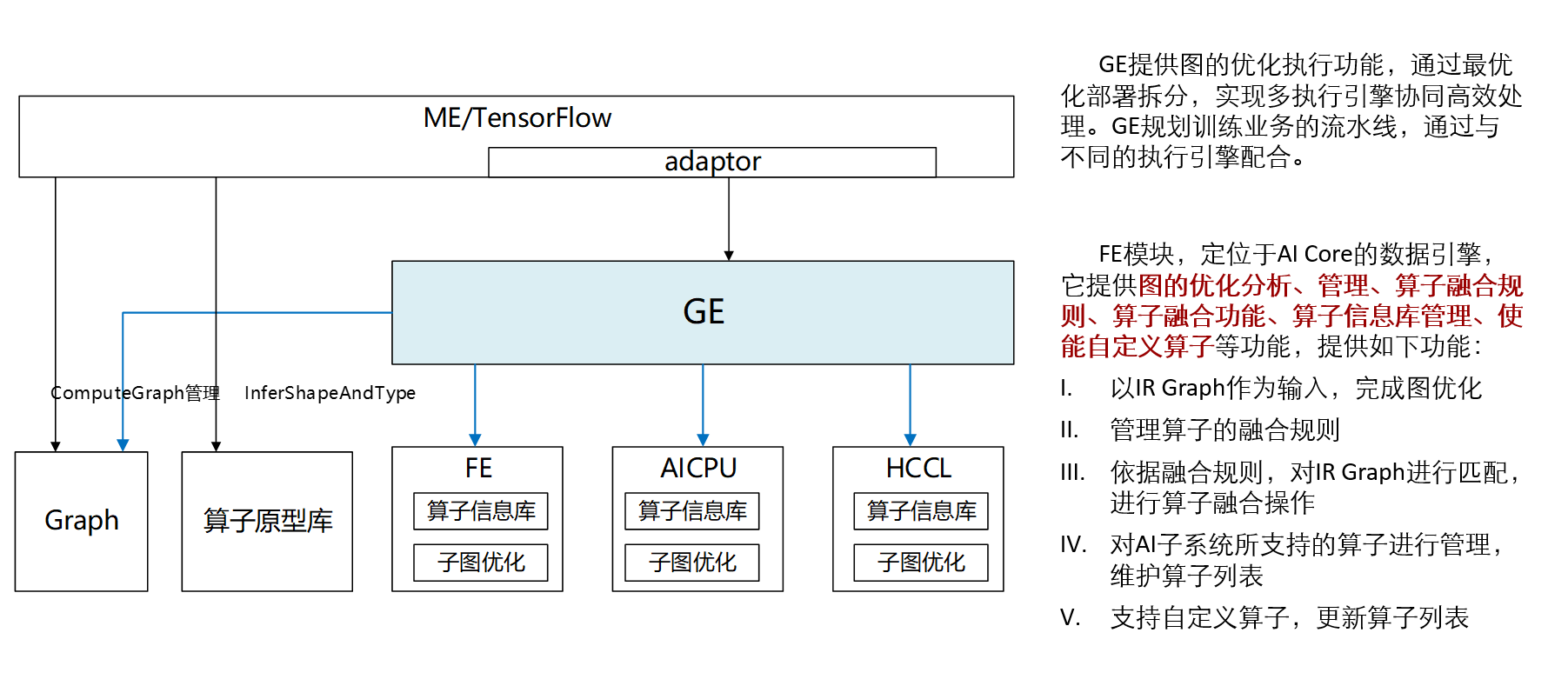

| 组件名称 | 主要功能 | 与GE的交互方式 |
|---|---|---|
| ME(Model Engine)/TensorFlow | TensorFlow作为前端框架,用于构建和训练模型;ME负责将TensorFlow图转换为GE可识别的格式(如OM模型)。 | TensorFlow → ME → GE:ME对TF图进行解析、优化后,传递给GE进行图编译与调度。 |
| Adaptor | 框架适配器,用于连接不同AI框架(如TensorFlow、PyTorch)与GE,屏蔽框架差异。 | Adaptor将不同框架的图表示统一转换为GE内部格式,确保兼容性。 |
| Graph Register | 图注册模块,负责管理GE支持的图结构、算子及其版本信息。 | GE在接收图时会查询Graph Register,验证算子合法性并获取执行策略。 |
| 算子原型库(Op Prototype Lib) | 存储算子的定义、输入输出规范、属性约束等元信息。 | GE在图编译阶段调用原型库,校验算子参数并选择最优实现。 |
| FE(Fusion Engine) | 包含算子信息库(Op Info DB)和子图优化器,负责算子融合、内存优化等。 | GE将子图传递给FE进行优化(如Conv+BN融合),返回优化后的子图。 |
| RTS Runtime | 运行时系统,负责任务调度、内存管理、设备通信等底层操作。 | GE将编译后的任务下发至RTS Runtime,由其调度到昇腾AI处理器执行。 |
| TBE(Tensor Boost Engine) | 算子开发框架,支持自定义算子实现(通过DSL或CCE语言)。 | GE调用TBE生成的算子二进制(.o/.json),集成到执行图中。 |
| CCE(Cube Compute Engine) | 昇腾AI处理器的底层计算引擎,提供高性能矩阵/向量运算。 | TBE编译后的算子最终由CCE在芯片上执行,GE通过RTS管理CCE资源。 |
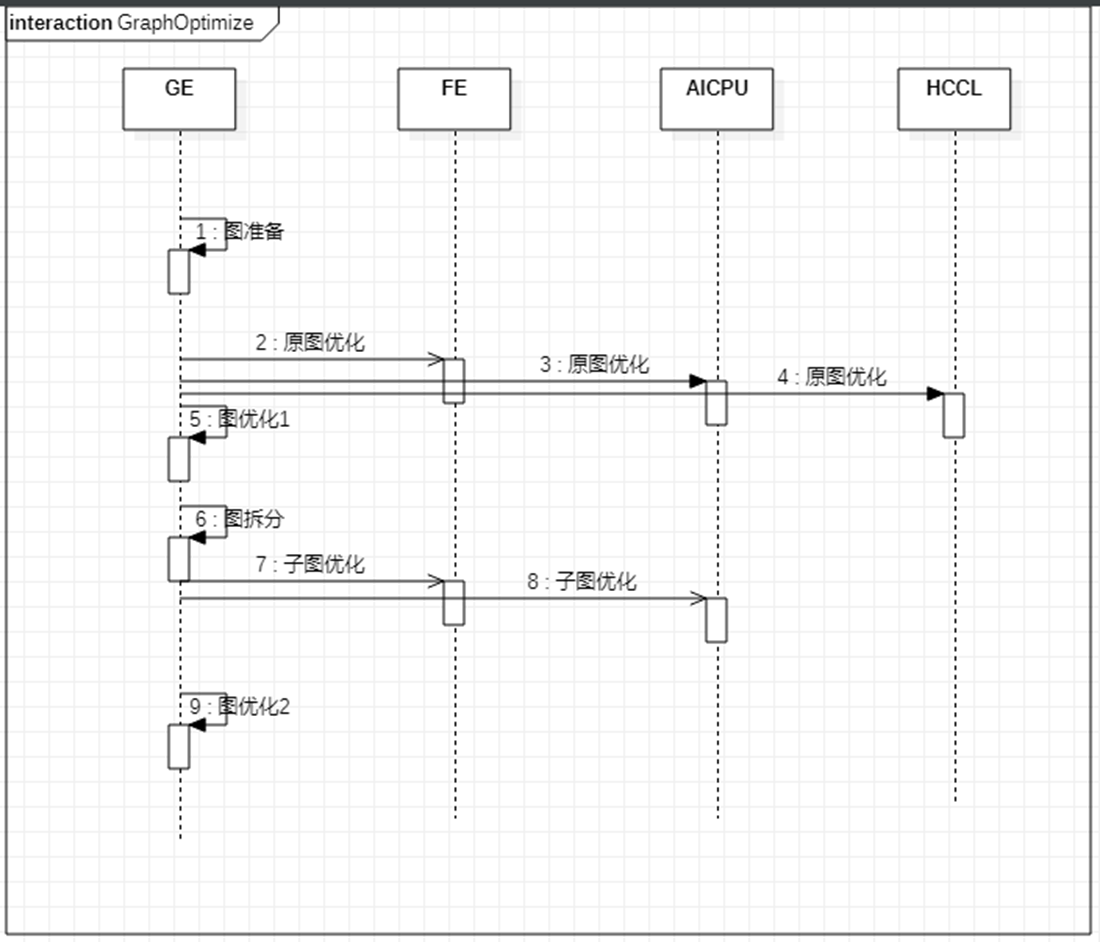
与引擎的交互流程:
3.3 GE架构视图
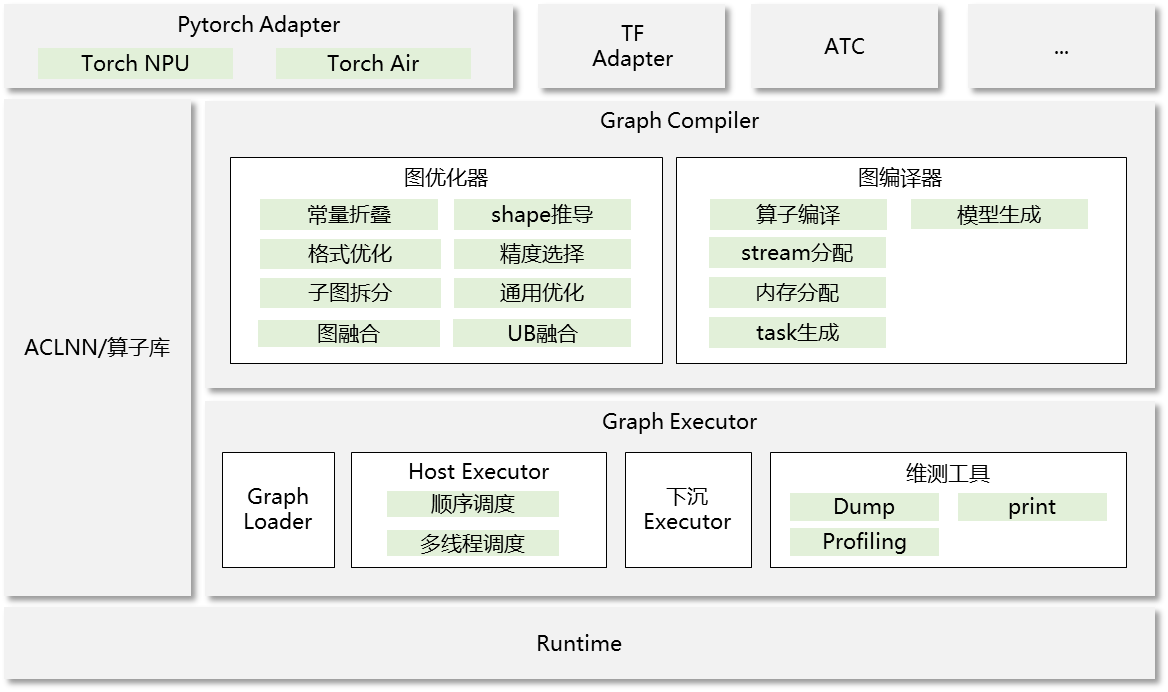
3.4 GE图的构成
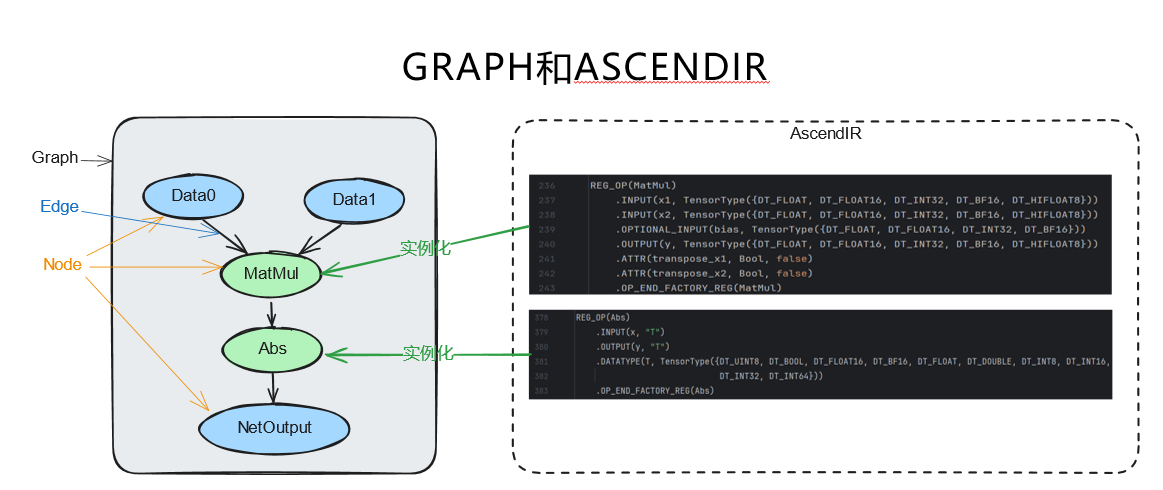
1、GE图是一种有向无环图(DAG:Directed Acyclic Graph)是由有向边连接的节点Node构成、且不存在任何循环路径的图结构,DAG 是描述 “计算流程 / 依赖关系” 的标准范式。
2、图中左侧的每个Node节点,可以理解为每种AscendIR算子的实例化表达,类似类和对象的关系。例如当matmul算子的输入输出确定后,相关属性,可选参数等确定后,就对应成为GE图中的node。一个ascendIR可以实例化多个Node。
3、通过REG_OP向GE注册算子原型,这里的AscendIR就可以理解为GE IR。
4、NODE之间通过Anchor(锚点)连接,指定了该算子对应的数据依赖或者控制依赖,连接关系是Edge(边),两个Anchor决定了一条Edge。
3.5 GE编译优化
图编译阶段做的事情:图准备、图优化、图融合、图拆分等;
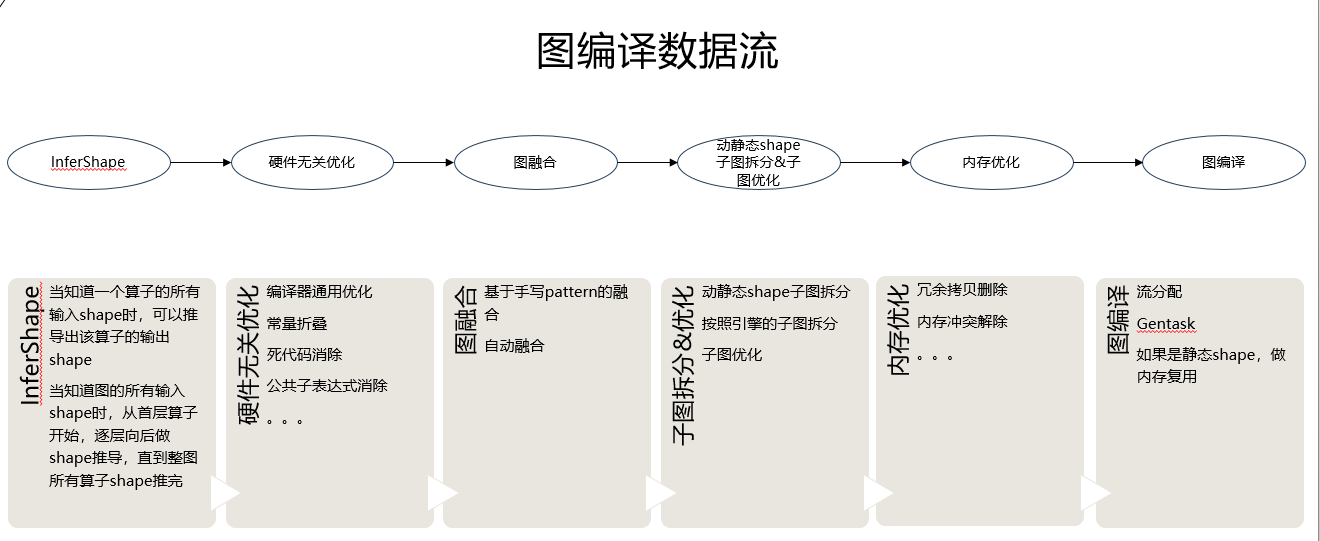
| 阶段 | 主要功能描述 |
|---|---|
| 图准备 | 图标准化:输入输出node插入、动态多档位改图、图的等价转换(for->while等)、无用算子删除原始格式、shape推导:推导流程、常量折叠、条件算子死边删除 |
| 原图优化 | 主要做图融合,与引擎及算子库相关的融合, 基于手写pattern的融合自动融合 |
| 运行时格式推导准备 | variable回边插入、输入输出运行时格式刷新 |
| 运行时格式推导 | AICPU、FE分别刷新各自node的运行时格式,插入转换算子 |
| 图优化阶段1 | 硬件无关的图优化:转换算子消除、CSE、常量折叠、剪枝 |
| 图拆分 | 为下沉调度做基于动静态shape的子图拆分为子图优化做基于引擎的子图拆分 |
| 子图优化 | 各引擎子图优化,包含AICPU、FE等Aicore的算子编译在此阶段发生 |
| 图优化阶段2 | 图编译强相关的改图动作在这里完成:variable回边删除、atomic清零算子插入、解决内存冲突、流标签的刷新等子图优化产生的新的优化机会需要做:常量折叠 |
参考文档
https://zhuanlan.zhihu.com/p/1921889729026172253 # PyTorch 图模式技术概览

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)