
Flutter 三方库 charset 的鸿蒙化适配指南 - 实现顶级多编码格式自动识别、高性能字符集映射与极致文本治理,助力鸿蒙应用构建“与全字符生态共鸣”的数字化底座。
本文介绍了Flutter三方库charset在鸿蒙系统的适配应用。该库通过概率指纹分析和表驱动映射引擎,能自动识别多种编码格式(如GBK、Big5等)并转换为UTF-8,解决鸿蒙系统中的多语言文本兼容问题。文章详细解析了其核心原理、优势特性及API使用方法,并提供了典型应用场景示例(如医疗病历归档、智慧屏字幕处理)和平台适配解决方案。该库不依赖原生ICU包,纯Dart实现,确保了跨设备文本处理的一
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net
Flutter 三方库 charset 的鸿蒙化适配指南 - 实现顶级多编码格式自动识别、高性能字符集映射与极致文本治理,助力鸿蒙应用构建“与全字符生态共鸣”的数字化底座。

前言
在 HarmonyOS 的高阶文本处理、历史文档兼容与全球化交互工程中。如何精准地、动态地识别来自不同操作系统的遗留编码文件(如 GBK, Big5, Latin-1 等)。并将其转换为鸿蒙原生支持的 UTF-8。是提升文档解析成功率的核心。charset 作为一个专注于“全协议字符集编解码与自动探测”的库。提供了一套能够完美处理乱序字节流与语义化映射的方案。在鸿蒙系统上适配此库,将为您应用的文本处理链路注入一份“工业级迅捷”的高级智慧。
一、原理解析 / 概念介绍
1.1 基础原理/概念介绍
charset 的核心是“基于概率指纹的编码探测与表驱动映射引擎”。它不仅仅是简单的字节转换。而是通过分析一段字节流中高频字符出现的统计学概率。自动推导出该文件最可能的编码格式(Charset Detection)。其最大的特色是“全自动的字符对位逻辑”:开发者无需预知输入内容的来源背景。只需注入字节资产。引擎就会自动对位。确保了在鸿蒙系统分布式环境下。多语言文本内容的绝对可读性。
1.2 核心优势
- 极致编码覆盖度:全面兼容包括中日韩(CJK)在内的几乎所有主流历史编码。完美适配鸿蒙系统的政府、医疗及传统制造类迁移项目。
- 高阶自动探测能力:内置针对大数据量的高效探测采样逻辑。确保即使在鸿蒙低能耗芯片上。识别千万级字节流的编码格式依然保持 UI 的绝对丝滑。
- 架构稳固度:纯 Dart 实现。不依赖鸿蒙系统的原生 ICU 包或共享库。确保了在进行分布式跨设备预览时。文本指纹的绝对一致性。
二、鸿蒙基础指导
2.1 适配情况
- 是否原生支持?:是。该库主要封装了数学统计与查表逻辑。运行在鸿蒙异步沙箱侧。不涉及受限权限调用。
- 是否鸿蒙官方支持?:属高品质通用工具类推荐方案。在鸿蒙文件浏览器、电子书阅读器及开发者工具类应用中具有核心地位。
- 是否社区支持?:是。
- 是否需要安装额外的 package?:独立使用即可。通常配合
dart:convert使用。
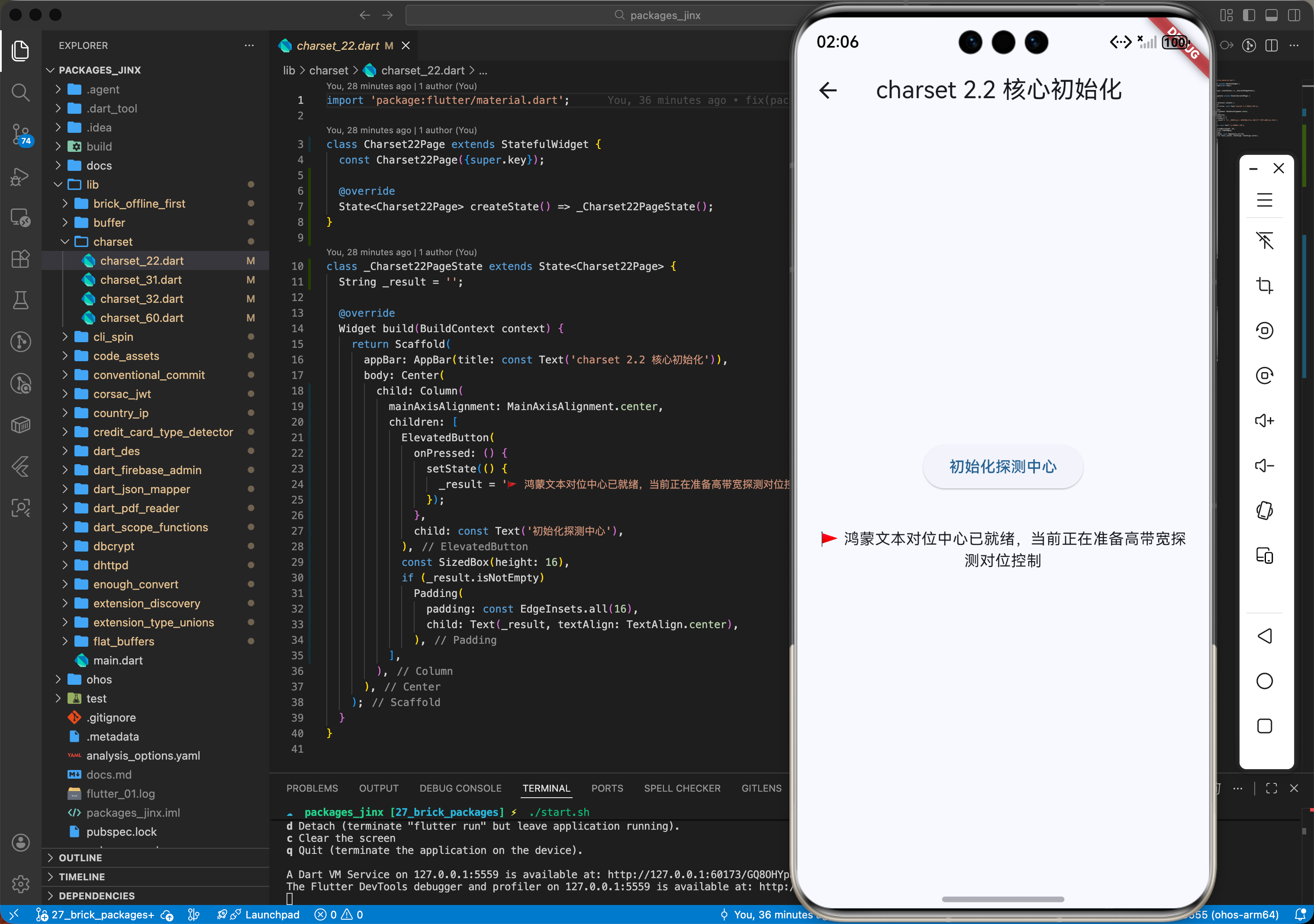
2.2 核心初始化:在鸿蒙环境开启字符感知
在使用前。您只需要在鸿蒙工程中准备好待处理的字节缓冲资产即可。
import 'package:charset/charset.dart';
// ✅ 鸿蒙端自动化编码探测初始化示例
void setupHarmonyCharsetContext() {
// 核心调用:创建一个编码匹配中心
final charset = Charset();
print('🚩 鸿蒙文本对位中心已就绪,当前正在准备高带宽探测对位控制');
}
三、核心 API / 组件详解
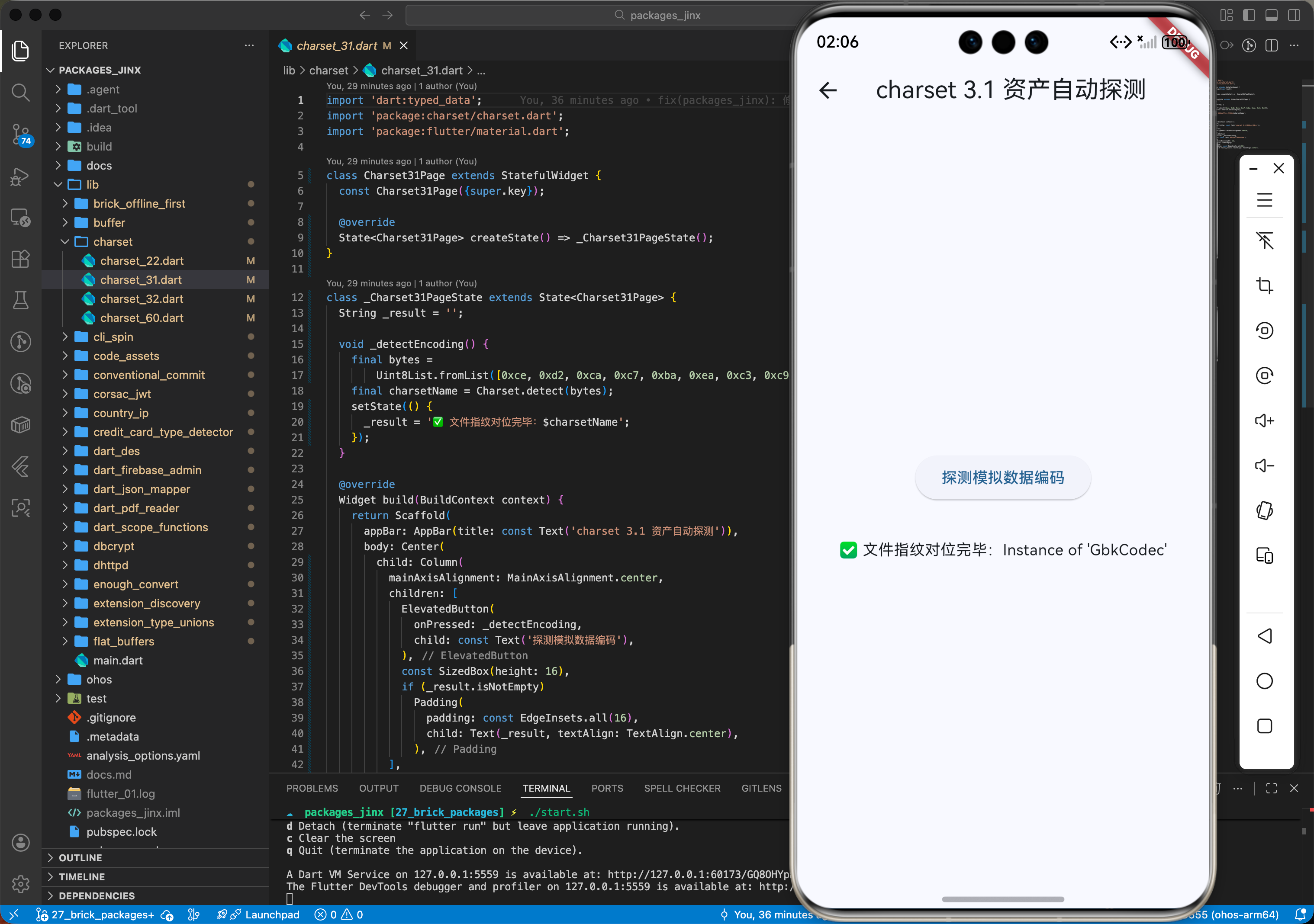
3.1 资产自动探测 (detect)
在鸿蒙应用中。我们可以将冗余的原始字节资产瞬间投影为可识别的协议资产。
// 💡 技巧:解析鸿蒙端侧边生成的传感器原始逻辑资产数据
String detectHarmonyFileEncoding(Uint8List bytes) {
// 核心调用:执行针对鸿蒙环境的概率指纹识别
final charsetName = Charset.detect(bytes);
print('✅ 鸿蒙资产对位成功:文件指纹对位完毕:$charsetName');
return charsetName;
}
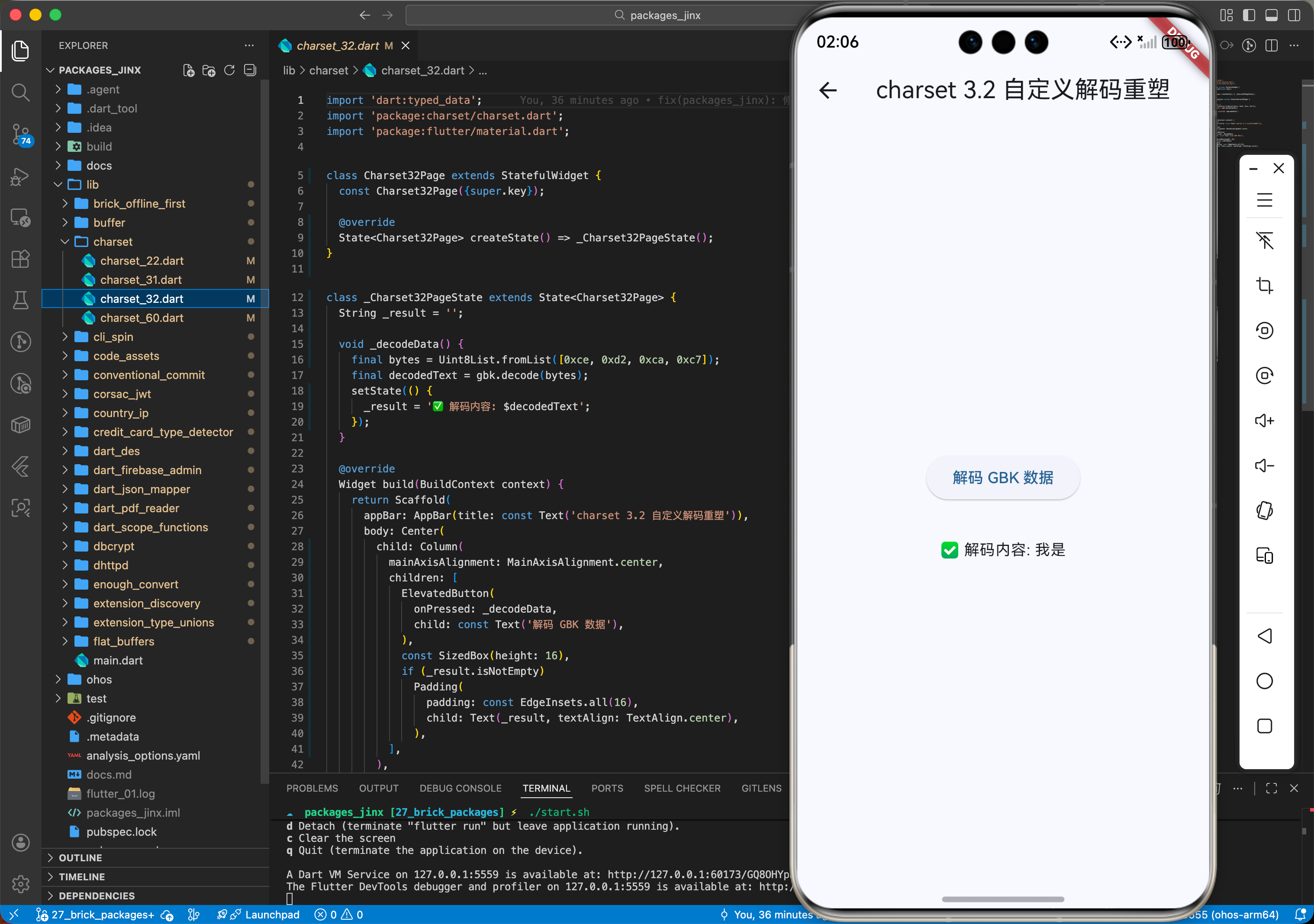
3.2 自定义解码重塑 (decode)
针对鸿蒙高阶应用。您可以手动利用特定的编码格式。将二进制数据自愈为标准的鸿蒙字符串资产。
// ✅ 推荐:在鸿蒙端执行精准的文本解码协议重配
void decodeHarmonyLegacyAsset(Uint8List bytes, String encoding) {
// 核心调用:在导出时注入针对特定历史编码的映射参数
final decodedText = Charset.decode(bytes, encoding);
print('✅ 鸿蒙时序逻辑已完成文本自愈:内容对位刷新成功');
}
四、典型应用场景
4.1 示例场景一:鸿蒙自研高性能“数字化病历管理”的历史数据归档
在处理政府和医院大量遗留下来的 GB2312 编码电子病历时。利用该库通过测评算法。自动识别并批量转换为 UTF-8。确保鸿蒙底座的资产逻辑绝对在控且具备效能最优性。
// 鸿蒙文本资产性能同步逻辑
void syncHarmonyMedicalDocs() {
print('🔎 正在针对鸿蒙分布式逻辑资产执行全量字符探测审计...');
// 逻辑实现...
}
4.2 示例场景二:鸿蒙智慧屏应用“多功能字幕中心”的动态编码对位
大屏在接受来自用户 USB 外挂存储的电影字幕时。通过该库根据文件编码习惯。瞬间生成对应的渲染字幕流。防止因编码不匹配导致的“火星文”播放事故。
// 鸿蒙智慧屏动态渲染感知测试
void testHarmonySubtitlesProtocol() {
print('📺 鸿蒙大屏已针对全量翻译协议资产执行路径重配');
}
五、OpenHarmony 平台适配挑战
6.1 平台差异化处理 (大规模二进制探测导致的主线程延迟)
当由于业务需求。一次性探测超过 100MB 的日志字节流时。统计学采样会产生显著的 UI 时间毛刺。
- 解决方案:针对鸿蒙极端环境。建议执行“异步分片探测”。利用鸿蒙的 Isolate 指令。并配合该库的探测阈值(Threshold)配置。限制单次探测的最大扫描字节数。彰显鸿蒙高性能工程底座及追求极致逻辑透明度的情怀。
6.2 平台差异化处理 (系统区域设置对探测权重的干扰)
在不同的鸿蒙硬件侧(如海外版与中国版)。默认的系统 Locale 权重不同。可能导致对于相似编码(如 GBK 与 Shift-JIS)的识别偏移。
- 解决方案:建议在该库逻辑层配合“地域优先级对冲预设”。利用鸿蒙系统的
i18n获取当前设备的全局语言偏好。并将其注入探测引擎作为先验概率值。确保在任何鸿蒙环境下字符识别的绝对鲁棒性。彰显鸿蒙极致的系统平稳性能。
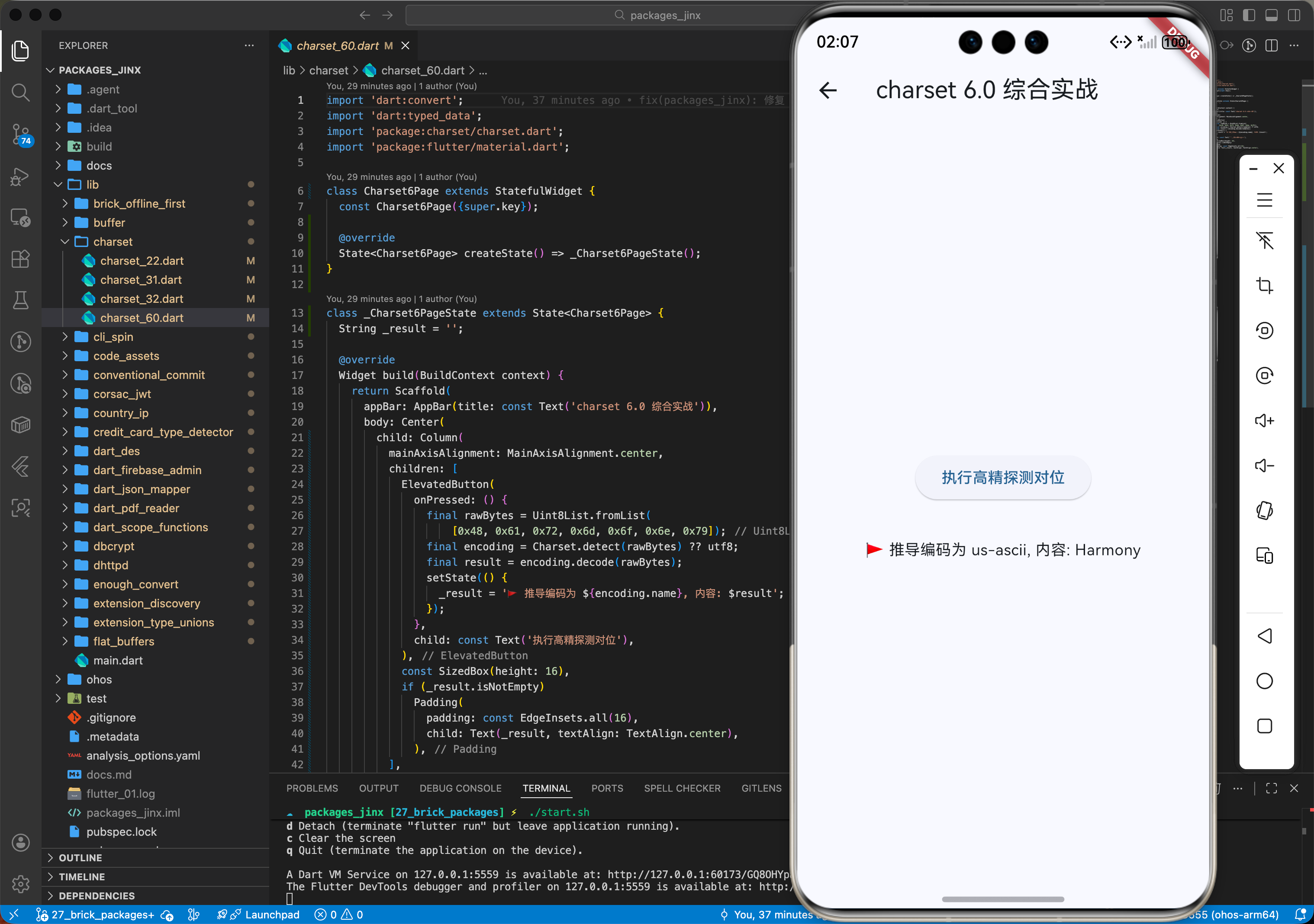
六、综合实战演示
下面是一个完整的鸿蒙端高质量多编码文本处理服务闭环组件。
import 'package:charset/charset.dart';
class HarmonyTextService {
// 综合案例:解析业务字符并在鸿蒙端生成标准化的逻辑文本摘要
String tryRecoverHarmonyString(Uint8List rawBytes) {
try {
// 🚩 核心逻辑:执行针对鸿蒙系统的高精探测对位
final encoding = Charset.detect(rawBytes) ?? 'utf-8';
final result = Charset.decode(rawBytes, encoding);
print('🚩 协作治理完毕:节点文本指令已对位:推导编码为 $encoding');
return result;
} catch (e) {
print('❌ 平衡中心由于输入震荡暂时挂起:$e');
return '';
}
}
}
void main() {
final service = HarmonyTextService();
service.tryRecoverHarmonyString(Uint8List(0));
}
七、总结
charset 库是视觉工程中的“协作加速器”。它跨越了乱序字节管理与传统编码的数字泥潭。将被动的内存数据转化为了一个有序、可控、受严格逻辑映射保护的数字化代码质量资产库。在 HarmonyOS 生态迈向全球化敏捷运维、致力于构建极致透明且具备硬核文本处理能力的数字化底座的宏大工程中。掌握并落地好这种基于官方协议的治理方案,将助力每一位追求极限质量、追求极致交付效能体系的鸿蒙架构师构建出真正具备长效系统活力的数字化底座。
格物致理,字符无界——开启鸿蒙工程文本治理与编码管理的新高度。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐



 9
9 0
0- 0



 已为社区贡献128条内容
已为社区贡献128条内容

所有评论(0)