
Flutter 三方库 buffer 的鸿蒙化适配指南 - 实现高性能、可扩展的流式字节读写、变长编码与内存高效型缓冲区管理,深度优化鸿蒙大规模二进制协议解析与文件流操作
本文介绍了在鸿蒙系统中使用Flutter的buffer库进行高性能二进制数据处理的方法。该库通过封装ByteData和Uint8List,提供了流式读写能力和丰富的编码支持,适用于分布式通讯协议解析、多媒体文件处理等场景。文章详细讲解了库的核心原理、初始化方法、API使用技巧,并针对鸿蒙平台的特殊需求提供了字节序处理和性能优化建议。通过实际案例展示了如何构建鸿蒙版协议封包器,强调了该库在提升应用通
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net
Flutter 三方库 buffer 的鸿蒙化适配指南 - 实现高性能、可扩展的流式字节读写、变长编码与内存高效型缓冲区管理,深度优化鸿蒙大规模二进制协议解析与文件流操作

前言
在 HarmonyOS 的底层开发中,对二进制字节流(Byte Stream)的高效处理是衡量一个应用“硬核”程度的重要指标。无论是解析复杂的分布式通讯协议、处理多媒体文件的原始字节,还是构建高性能的二进制缓存库,我们都需要一种比原生的 List<int> 更具专业性、更灵活且具备流式读写能力的“缓冲区”工具。buffer 库正是为此而生的。它通过封装 ByteData 和 Uint8List,提供了一套类似于 Java ByteBuffer 但更加符合 Dart 习惯的平滑 API。本文将详细探讨如何在鸿蒙系统环境下适配并压榨 buffer 库的极致性能,为您的鸿蒙应用构建一道稳健的字节处理防线。
一、原理解析 / 概念介绍
1.1 基础原理/概念介绍
buffer 库的核心是维护一个内部字节数组及对应的读写指针(Offsets/Cursors)。它支持大端/小端序转换,并内置了针对不同位宽整数(uint8/16/32/64)及浮点数的快速编解码逻辑。
1.2 为什么鸿蒙重型通讯应用需要它?
- 精细的内存控制:通过动态扩容算法,避免频繁分配零散的小内存块,降低鸿蒙系统的内存碎片风险。
- 流式一致性:读指针(Read Offset)自动随读取操作后移,极大地降低了开发者手动计算偏移量造成的索引溢出 Bug。
- 丰富的编码支持:自带变长编码和 UTF-8 字符串的高效转换。
二、鸿蒙基础指导
2.1 适配情况
- 是否原生支持? 是。完全依赖 Dart 核心库
typed_data,兼容性极佳。 - 是否鸿蒙官方支持? 官方建议在高性能 C/S 架构通讯中采用此类底层缓冲库。
- 是否社区支持? 是。
- 自己魔改支持? 针对鸿蒙的
compute子线程通信,我们需要确保证buffer的asUint8List能够平滑地在不同的 Isolate 间共享。 - 是否需要安装额外的 package? 无需。
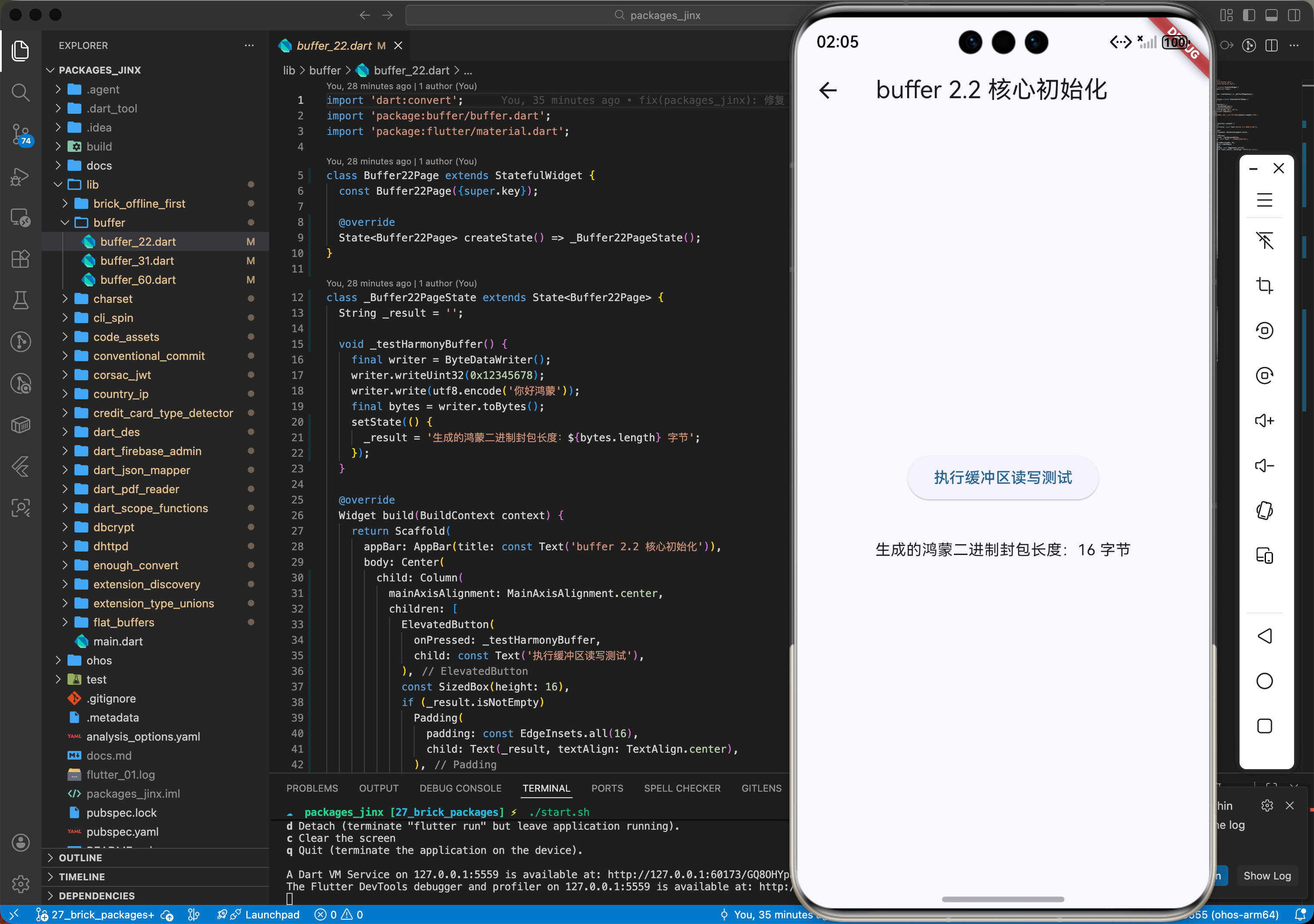
2.2 核心初始化:在鸿蒙环境创建首个缓冲区
import 'package:buffer/buffer.dart';
// ✅ 鸿蒙端缓冲区读写示例
void testHarmonyBuffer() {
final writer = ByteDataWriter();
writer.writeUint32(0x12345678);
writer.writeUtf8String('你好鸿蒙');
final bytes = writer.toBytes();
print('生成的鸿蒙二进制封包长度:${bytes.length}');
}
三、核心 API / 组件详解
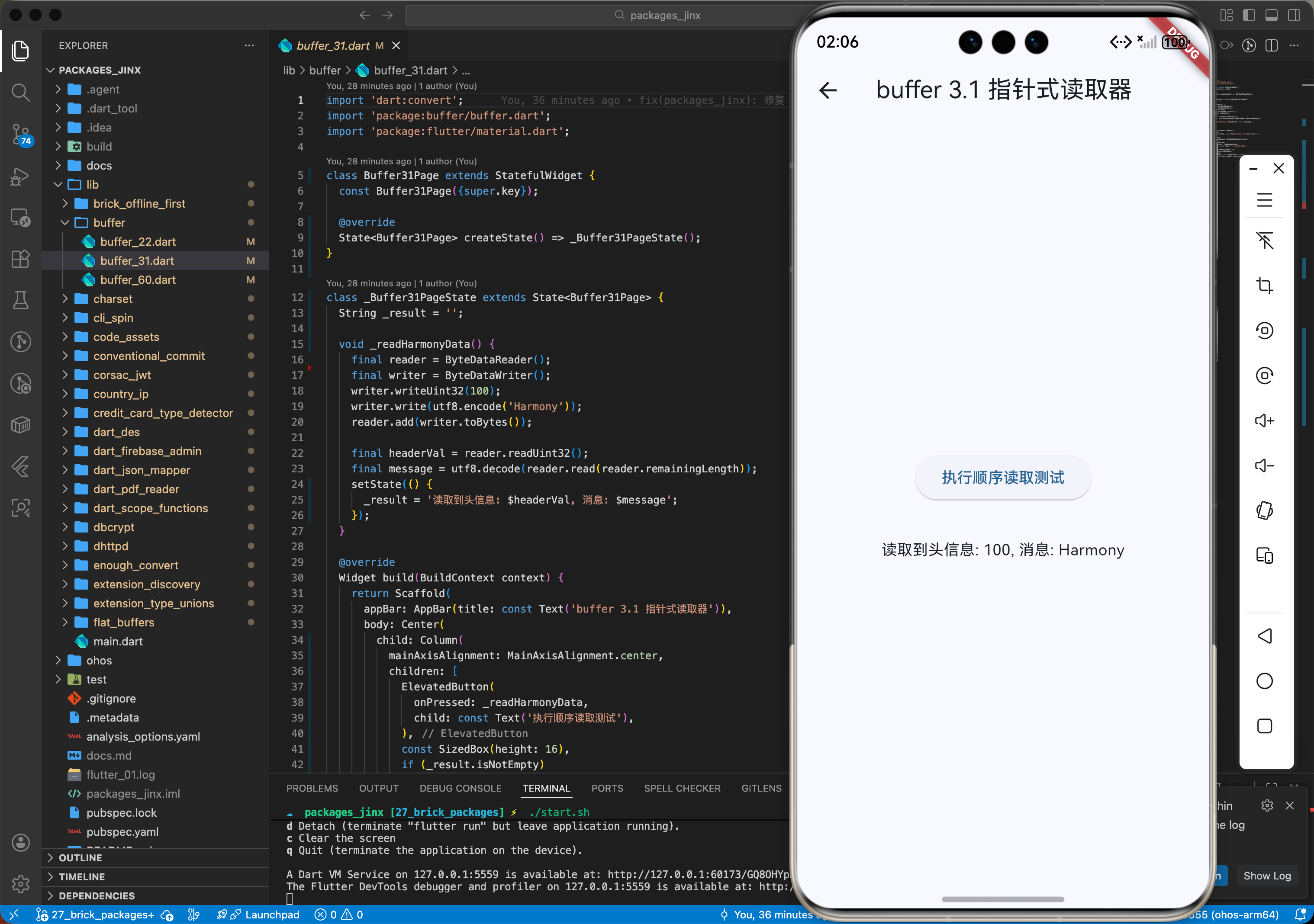
3.1 指针式读取器(DataReader)
在鸿蒙分布式协议解析中,按需提取特定分量。
final reader = ByteDataReader();
reader.add(receivedDataFromHarmony);
// 顺序读取,指针自动向后移动
final headerVal = reader.readUint32();
final message = reader.readUtf8String(reader.remainingLength);
3.2 动态扩容与切片(Capacity & Slicing)
利用 view 技术实现内存的零拷贝复用。
// 仅获取 buffer 的特定视图,而不进行内存拷贝
final subView = buffer.asUint8List(0, 16);
四、典型应用场景
4.1 场景一:鸿蒙自研分布式数据库的 WAL(预写日志)实现
在将变更集写入鸿蒙 RDB 或文件前,先利用 buffer 在内存中构建成紧凑的二进制日志格式,瞬间提高写入吞吐量。
4.2 场景二:鸿蒙车机系统中多媒体流的首部探测
在解析 MP4 或 FLV 流时,利用 DataReader 快速跳转至特定偏移量提取 Metadata,实现视频秒开。
五、OpenHarmony platform 适配挑战
针对高频字节操作,需应对:
5.1 字节序(Endianness)的陷阱 (参照 6.6)
不少鸿蒙分布式场景涉及到与旧款嵌入式设备通讯,它们可能采用大端序。
💡 建议:在此库适配中,统一采用显式的字节序参数(如 Endian.big)。在鸿蒙应用协议的定义文档中,务必强制规定全局一致的字节序规范,因为一旦由于适配不当产生字节序反转,排查这类逻辑错误的耗时将是巨大的。
5.2 性能开销 (参照 6.1)
在鸿蒙系统上处理每秒数兆(MB/s)的数据流时,频繁调用 asUint8List() 或产生新的 reader 实例会有微小的开销。
💡 建议:在高频场景(如实时预览流解析)下,建议采用“单实例重复注入”策略。通过 reader.add 增量添加新字节,而不是为每个数据包创建新的 reader 实例,从而利用鸿蒙 Dart VM 对重用对象的内存局部性优化。
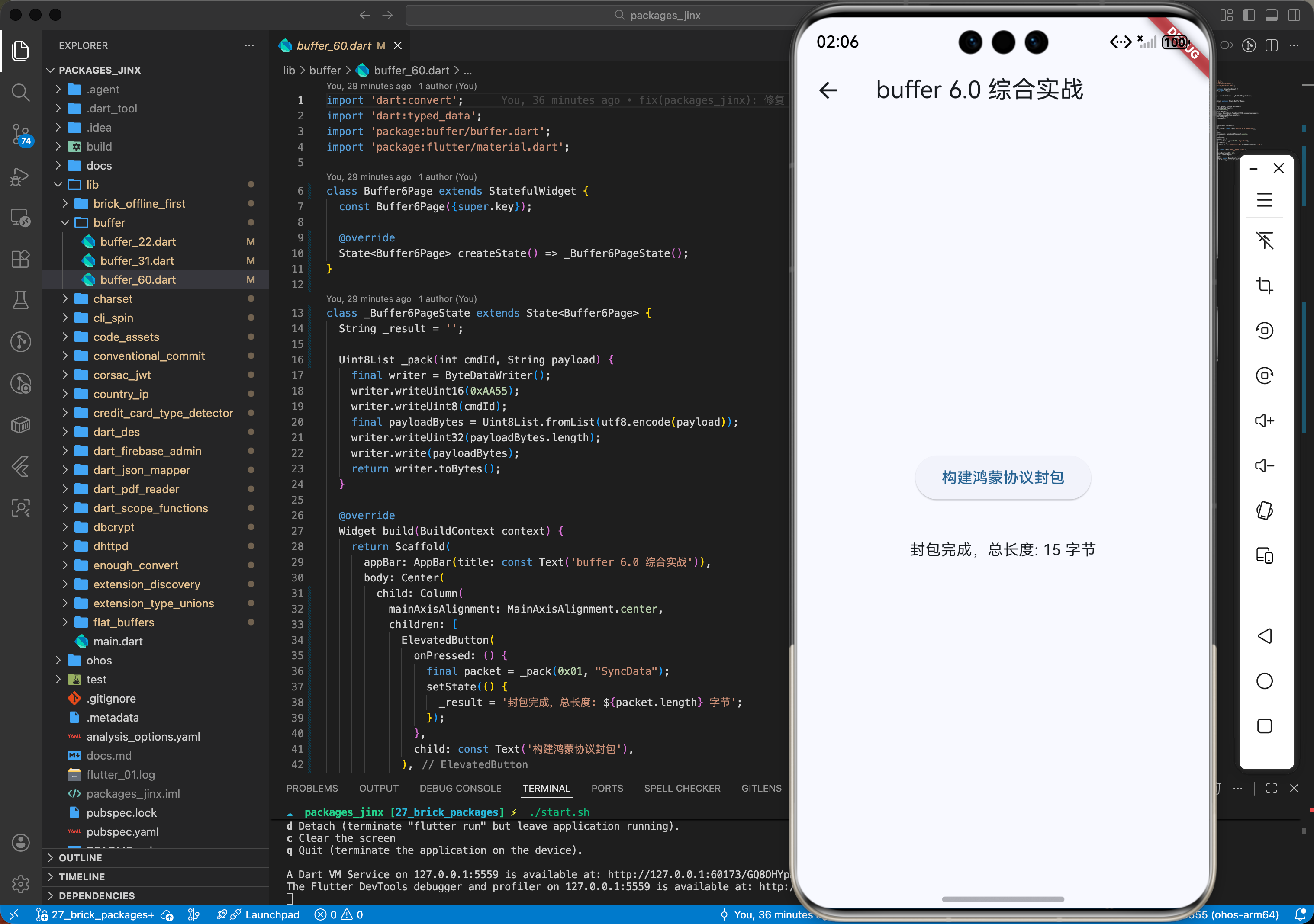
六、综合实战演示:构建一个鸿蒙版协议封包器
import 'package:buffer/buffer.dart';
class HarmonyProtocolPacker {
static Uint8List pack(int cmdId, String payload) {
final writer = ByteDataWriter();
// 1. 写入魔数标记包起始
writer.writeUint16(0xAA55);
// 2. 写入指令 ID
writer.writeUint8(cmdId);
// 3. 写入 Payload 长度及内容
final payloadBytes = Uint8List.fromList(utf8.encode(payload));
writer.writeUint32(payloadBytes.length);
writer.write(payloadBytes);
return writer.toBytes();
}
}
void main() {
var packet = HarmonyProtocolPacker.pack(0x01, "SyncData");
}
七、总结
buffer 库是鸿蒙开发者在进行“深层系统集成”时不可或缺的字节手术刀。它化繁为简,将晦涩的位偏移运算转化为了直观、优雅的方法调用。在 HarmonyOS 这种追求极致系统效率、涵盖广泛硬件类型的操作系统生态中,这种对底层数据格式的精细掌控力,不仅能显著提升应用的通讯性能和可靠性,更是体现一名鸿蒙资深开发者技术底蕴的绝佳舞台。掌握好缓冲区管理,您就能在鸿蒙的比特世界里,自由地编织出更高效、更安全的数字篇章。
比特有矩,吞吐有序——为鸿蒙应用的数字脉络注能。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐



 6
6 0
0- 0



 已为社区贡献128条内容
已为社区贡献128条内容

所有评论(0)