
鸿蒙:LazyForEach迁移Repeat两者对比与避坑指南
一、背景
在鸿蒙开发中,长列表渲染一直是性能优化的重点;从API 12开始支持Repeat,用来统一替换ForEach + LazyForEach,成为鸿蒙下一代循环渲染标准组件
从LazyForEach迁移到Repeat会遇到以下问题:
1、两者到底有什么区别?
2、懒加载怎么开?
3、数据更新、子属性监听、组件复用、多模板怎么写?
4、为什么官方推荐 Repeat?
本文基于官方文档,总结出两者之间的差异,方便快速迁移
二、核心前提
Repeat只支持V2组件(Stage模型)
LazyForEach支持V1和V2两种组件
若是新项目且Stage模型,建议直接使用V2组件Repeat
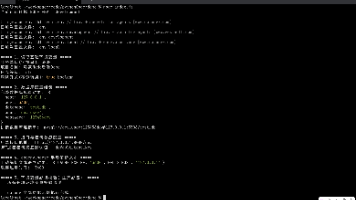
三、LazyForEach与LazyForEach七大核心区别
3.1、数据源不同
LazyForEach:
使用专用的数据结构IDataSource
需要自己实现类,重写getData()、pushData()等方法
Repeat:
直接使用V2装饰的普通数组
无需实现任何接口,写法更简单
3.2、组件生成函数&键值生成函数不同
LazyForEach:
三个参数:数据源、组件生成函数、键值生成函数
键值用于标识唯一item,优化更新
Repeat:
使用.each()或.template()设置组件生成函数
使用.key()设置键值生成函数
3.3、懒加载模式不同
LazyForEach:
本身具备懒加载功能,默认只渲染屏幕 + 预加载区域
Repeat:
具有两种模式:
全量加载(默认) —> 对标ForEach,渲染所有节点
懒加载 —> 对标LazyForEach,需手动开启
Repeat(data)
.virtualScroll() // 使能懒加载懒加载时同样只渲染:可见区域 + 前后预加载区域
滚动性能与 LazyForEach 一致
3.4、数据更新方式不同
LazyForEach:
修改数据源后需要调用对应的接口通知其更新
如:notifyDataAdd()、notifyDataChange()
Repeat:
由V2监听其数据源变化并触发更新
直接修改数组即可,无需任何通知方法
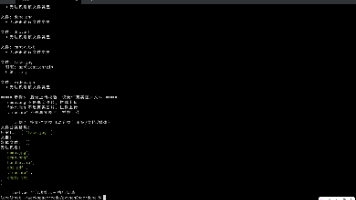
3.5、修改数据子属性监听不同
LazyForEach(状态V1):
使用@Observed与@ObjectLink实现对数据子属性的观测
@ObjectLink是 “绑定整个对象”
Repeat(状态V2)
使用@Observed V2与@Trace实现对数据子属性进行深度观测
@Trace可以精准标记 “需要观测的子属性”,减少不必要的观测开销,性能更高
3.6、组件复用机制不同
LazyForEach:
本身不具备复用能力
必须配合 @Reusable 装饰器才能复用
Repeat:
自带组件复用(默认开启,优先级最高)
两种方案:
1、直接使用自带复用(推荐)
2、使用 @ReusableV2,但必须先关闭自带复用
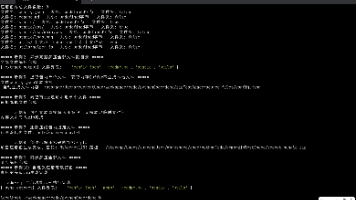
.virtualScroll({ reusable: false })3.7、多模版渲染能力不同
LazyForEach:
无原生模板支持
只能通过 if/else 条件判断渲染不同模板
Repeat:
原生支持多模板渲染(官方推荐)
两种方案:
1、使用 .templateId() + .template()(性能最优)
2、使用 if/else 手动判断(需手动关闭自身复用能力)
.virtualScroll({ reusable: false })四、总结:为啥主推Repeat替代LazyForEach
1、统一循环渲染API
ForEach / LazyForEach 二合一 → 只用 Repeat 搞定所有场景
2、使用更简单
普通数组+状态自动监听,不再使用IDataSource
3、性能更佳
@Trace 精准监听子属性
自带组件复用
原生多模板渲染
4、官方主推,新特性、新优化直接给到Repeat

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)