
小模型在昇腾NPU上的推理部署:【文生图Qwen-image-Edit服务化实践案例】
文生图、图生图类的模型使用越来越广泛,在金融领域中可以用于营销素材、广告生成等场景。当前Qwen-Image-Edit、Stable Diffusion、Wan等系列模型大多数是通过ComfyUI等方式进行本地部署体验,然而,在实际生产环境中,这类模型通常需要以服务化的方式对外提供API接口,而非仅支持本地体验。本文基于昇腾NPU硬件产品,探索Qwen-Image-Edit模型的服务化部署方案,通
作者:昇腾实战派
小模型在NPU上的推理部署: 【知识地图】
背景概述
文生图、图生图类的模型使用越来越广泛,在金融领域中可以用于营销素材、广告生成等场景。当前Qwen-Image-Edit、Stable Diffusion、Wan等系列模型大多数是通过ComfyUI等方式进行本地部署体验,然而,在实际生产环境中,这类模型通常需要以服务化的方式对外提供API接口,而非仅支持本地体验。本文基于昇腾NPU硬件产品,探索Qwen-Image-Edit模型的服务化部署方案,通过Flask框架搭建轻量级Web服务,并结合MindSD加速模块提升推理性能。
1 解决方案
1.1 方案介绍
本方案采用Flask作为Web应用框架,底层基于昇腾Atlas 800T/I A2服务器,使用配套的CANN架构和Mind SD加速模块。整体架构设计如下:
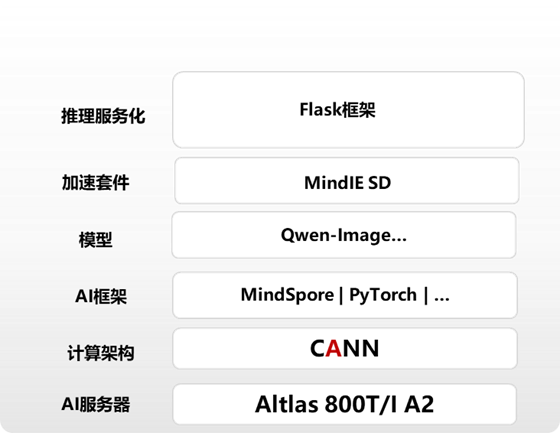
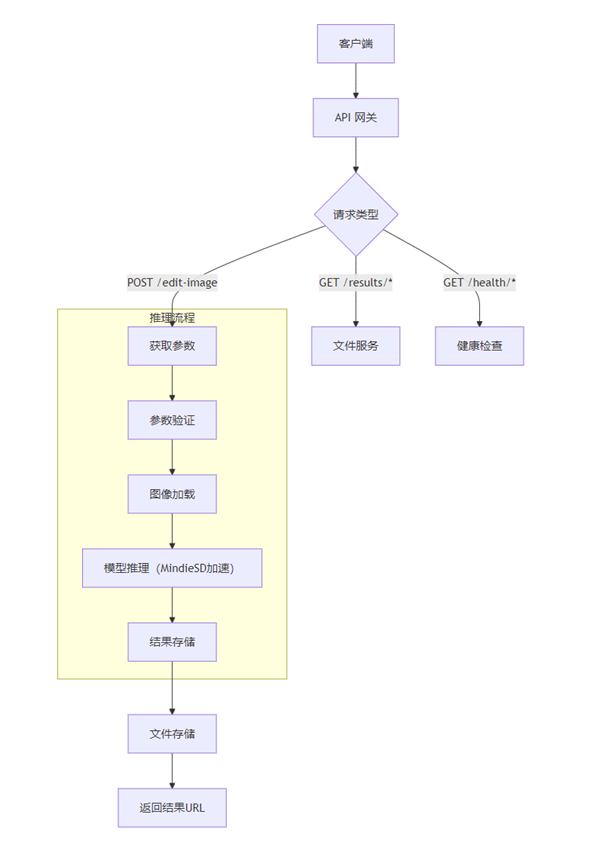
1.2 Flask服务化方案设计
用户通过客户端发起图像编辑请求 → 请求经网关路由到 Flask 应用 → 应用处理输入并调用模型推理(使用 Mindie SD 加速)→ 生成结果并存储 → 返回结果给用户。
Web层设计: Flask路由映射处理3个HTTP请求/响应:
1、健康查询接口;类型GET、路径/health
2、推理结果获取接口;类型GET、路径/results/
3、推理请求接口;类型POST、路径/edit-image
2 (实操)Qwen-Image-Edit模型服务化部署
2.1 模型介绍
Qwen-Image-Edit模型是基于200亿参数的Qwen-Image模型构建,成功将Qwen-Image独特的文本渲染能力延伸至图像编辑任务,实现了精准的文字编辑功能;
语义与外观双重编辑:Qwen-Image-Edit同时支持低层级的视觉外观编辑(如添加、删除或修改元素,且要求图像其他区域完全保持不变)和高层级的视觉语义编辑(如IP角色创作、物体旋转与风格迁移,在保持语义一致性的前提下允许整体像素变化)。
精准文字编辑能力:支持中英双语文本编辑,可直接对图像中的文字进行增删改操作,并有效保留原始字体、字号与风格特征。
卓越基准测试表现:在多项公开基准评估中,Qwen-Image-Edit在图像编辑任务上实现了最先进的性能表现,奠定了其作为强大图像编辑基础模型的地位。
Qwen-Image是阿里巴巴通义千问团队推出的前沿多模态大语言模型(MLLM),Qwen-Image在从复杂文本提示生成高质量图像以及执行精准、上下文感知的图像编辑两方面均展现出显著进展。该模型能够解析复杂的语言结构,并生成既符合语义意图又满足视觉约束、具有视觉吸引力的输出。
Qwen-Image架构主要有三个核心组件构成:
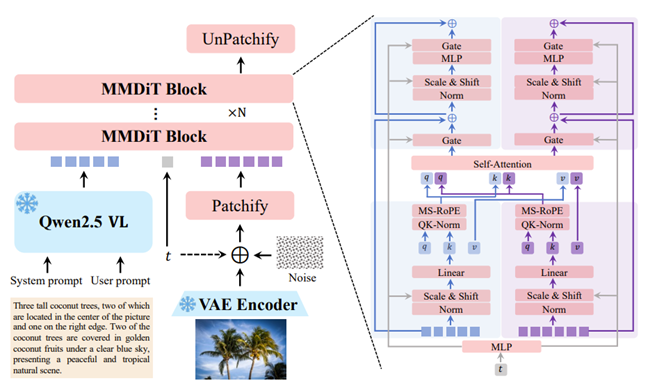
① 多模态大语言模型,使用的是Qwen2.5-VL作为条件编码器,负责从文本输入中提取特征。
② 变分自编码器,VAE作为图像分词器,负责将输入图像压缩成潜空间表示,并在推理时将其解码回图像。
③ 多模态扩散变换器,Multimodal Diffusion Transformer (MMDiT);作为骨干扩散模型,负责在文本引导下对噪声和图像潜变量之间的复杂联合分布进行建模。
模型采用了标准的双流MMDiT架构。其输入表示由冻结参数的Qwen2.5-VL和VAE编码器提供。QK归一化采用RMSNorm,其他归一化层均使用LayerNorm。同时,引入了一种新的位置编码方案MSRoPE(多模态可缩放RoPE),用于联合编码图像和文本两种模态的位置信息。
模型相关论文:Qwen-Image Technical Report
2.2 部署环境说明
设备支持:Atlas 800I/800T A2(8*64G)推理设备
运行环境:
| 配套 | 版本 |
|---|---|
| Python | 3.10 or 3.11 |
| Torch | 2.1.0 |
| MindIE镜像 | 2.1.RC1 |
组件下载:
| 模型下载地址 | https://huggingface.co/Qwen/Qwen-Image-Edithttps://www.modelscope.cn/models/Qwen/Qwen-Image-Edit/files |
|---|---|
| 下载方式 | pip install modelscopemodelscope download --model Qwen/Qwen-Image-Edit README.md --local_dir ./dir |
| 优化代码下载 | https://modelers.cn/models/MindIE/Qwen-Image-Edit |
2.3 Qwen-Image-Edit推理及服务化
2.3.1 推理前准备
1. 下载代码
git clone https://modelers.cn/MindIE/Qwen-Image-Edit.git && cd Qwen-Image-Edit
2. python相关依赖安装
pip install git+https://github.com/huggingface/diffusers
pip install transformers==4.52.4
3. 用 Python 获取 diffusers 的安装目录
DIFFUSERS_PATH=$(python -c “import diffusers; import os; print(os.path.dirname(diffusers.file))”)
注意:此处可能会出现报错:
解决方法:请进入/usr/local/lib/python3.11/site-packages/diffusers/utils/torch_utils.py,将涉及xpu 相关的代码进行删除
# 4. 替换pipeline_qwenimage_edit文件
cp -r pipeline_qwenimage_edit.py “$DIFFUSERS_PATH/pipelines/qwenimage/pipeline_qwenimage_edit.py”
# 5. 替换transformer_qwenimage文件
cp -r transformer_qwenimage.py “$DIFFUSERS_PATH/models/transformers/transformer_qwenimage.py”
2.3.2 纯模型推理
由官方提供的推理执行代码(基于GPU)参考:https://huggingface.co/Qwen/Qwen-Image-Edit
基于Altlas 800T/I A2推理迁移步骤及性能可参考魔乐社区链接:https://modelers.cn/models/MindIE/Qwen-Image-Edit
模型迁移注意点:
1、由GPU迁移至NPU,需将官方提供的pipeline.to(“cuda”)需要修改为pipeline.to(“cpu”);
2、pytorch框架的模型迁移至NPU需增加torch_npu插件,import torch/import torch_npu/from torch_npu.contrib import transfer_to_npu;
算子优化配置:
方式一:等价优化(融合算子优化)
export ROPE_FUSE=1
export ADALN_FUSE=1
python run_edit.py --model_name ./Qwen-Image-Edit --device_id 0
参数说明:
model_name: 权重路径
device_id: 执行模型推理的芯片id
方式二:算法优化(cache近似算法有损优化)
export ROPE_FUSE=1
export ADALN_FUSE=1
export COND_CACHE=1
export UNCOND_CACHE=1
python run_edit.py --model_name ./Qwen-Image-Edit --device_id 0
model_name: 权重路径
device_id: 执行模型推理的芯片id
2.3.3 服务化调用
在Qwen-Image-Edit代码路径下,放入qwen_image_flask.py文件,并使用python3 qwen_image_flask.py进行拉起flask服务。
服务拉起成功示例:
调用服务;重新开启一个页面,并使用curl 命令进行调用,示例如下:
curl -X POST http://localhost:5000/edit-image \
-H "Content-Type: application/json" \
-d '{
"prompt": "请把图片改成卡通风格",
"image_url": "https://picsum.photos/800/600"
}'
下图为执行的结果:

4 价值与效果
本实践验证了在昇腾A2系列服务器上部署Qwen-Image-Edit模型并通过Flask实现服务化的可行性,具有以下价值:
- 完整的服务化方案:提供从模型推理到API服务的端到端解决方案
- 性能优化保障:通过Mind SD加速模块确保推理效率
- 易于部署维护:基于标准Web框架,降低运维复杂度
- 业务场景适配:满足实际生产环境中的服务化调用需求
该方案为类似文生图模型的服务化部署提供了可复用的技术路径,具有较强的实践指导意义。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)