
Flutter三方库适配OpenHarmony【doc_text】— Android 端 Apache POI 实现分析
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.netAndroid 端的 doc_text 实现非常"省事"——直接用Apache POI这个 Java 库,几十行代码就搞定了 .doc 和 .docx 的解析。但正是因为 OpenHarmony 上没有 POI 可用,才逼出了 684 行手写解析器。这篇分析 Android 端的实现,理解
前言
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net
Android 端的 doc_text 实现非常"省事"——直接用 Apache POI 这个 Java 库,几十行代码就搞定了 .doc 和 .docx 的解析。但正是因为 OpenHarmony 上没有 POI 可用,才逼出了 684 行手写解析器。这篇分析 Android 端的实现,理解它做了什么,才能更好地理解 OpenHarmony 端为什么要那样写。
一、Apache POI 简介
1.1 什么是 Apache POI
Apache POI 是 Apache 基金会维护的 Java 库,专门用于读写 Microsoft Office 格式的文件。POI 这个名字是 “Poor Obfuscation Implementation” 的缩写——对微软文件格式的一种调侃。
1.2 POI 的模块
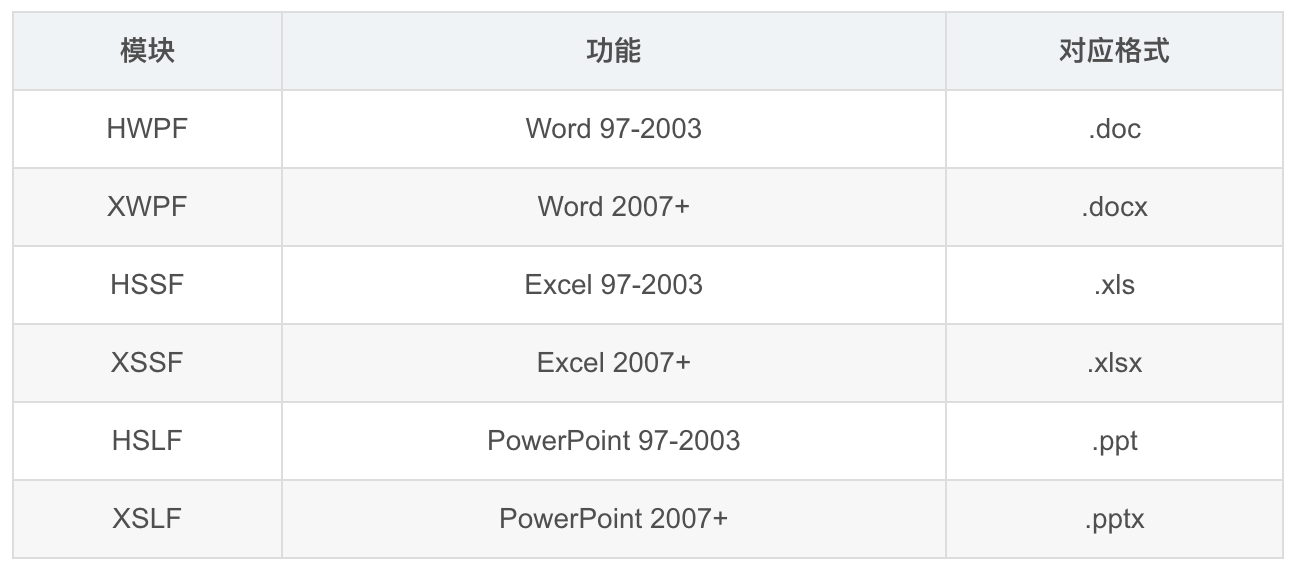
1.3 doc_text 用到的部分
// Android build.gradle
dependencies {
implementation 'org.apache.poi:poi:5.2.3' // HWPF (.doc)
implementation 'org.apache.poi:poi-ooxml:5.2.3' // XWPF (.docx)
}
💡 POI 的包体积不小。
poi+poi-ooxml加上它们的依赖(xmlbeans、commons-compress 等),可以给 APK 增加 5-10MB。对于只需要提取文本的场景来说,这个代价有点大。
二、HWPFDocument:.doc 文件解析
2.1 使用方式
import org.apache.poi.hwpf.HWPFDocument;
import org.apache.poi.hwpf.extractor.WordExtractor;
// 打开 .doc 文件
FileInputStream fis = new FileInputStream(filePath);
HWPFDocument doc = new HWPFDocument(fis);
// 提取文本
WordExtractor extractor = new WordExtractor(doc);
String text = extractor.getText();
// 关闭资源
extractor.close();
doc.close();
fis.close();
2.2 POI 内部做了什么
HWPFDocument 内部流程:
1. 读取文件到 byte[]
2. 验证 OLE2 魔数
3. 解析 OLE2 结构(FAT、目录、流)
4. 读取 WordDocument 流
5. 解析 FIB
6. 读取 Table 流
7. 解析 Piece Table
8. 构建文本内容
WordExtractor.getText() 内部流程:
1. 遍历所有段落
2. 拼接段落文本
3. 处理换行符
4. 返回完整文本
| 步骤 | POI 的实现 | doc_text OpenHarmony 的实现 |
|---|---|---|
| OLE2 解析 | POIFSFileSystem 类 | OLE2Parser 类(手写) |
| FIB 解析 | FIBAbstractType 类 | extractWordText 方法 |
| Piece Table | PieceTable 类 | extractTextWithPieceTable 方法 |
| 文本提取 | WordExtractor 类 | extractUnicodeChars / extractAnsiChars |
2.3 POI 的 OLE2 解析 vs doc_text 的手写解析
// POI:几千行代码,处理了所有边界情况
POIFSFileSystem fs = new POIFSFileSystem(new FileInputStream(filePath));
DirectoryEntry root = fs.getRoot();
DocumentEntry wordDoc = (DocumentEntry) root.getEntry("WordDocument");
// doc_text:200 行代码,处理了核心场景
const ole = new OLE2Parser(bytes);
const wordEntry = ole.findEntry("WordDocument");
const wordData = ole.readEntryData(wordEntry);
📌 POI 的 OLE2 实现大约有几千行代码,覆盖了各种边界情况和异常格式。doc_text 的 OLE2Parser 只有 200 行,只实现了读取 Word 文档所需的最小子集。
三、XWPFDocument:.docx 文件解析
3.1 使用方式
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.extractor.XWPFWordExtractor;
// 打开 .docx 文件
FileInputStream fis = new FileInputStream(filePath);
XWPFDocument docx = new XWPFDocument(fis);
// 提取文本
XWPFWordExtractor extractor = new XWPFWordExtractor(docx);
String text = extractor.getText();
// 关闭资源
extractor.close();
docx.close();
fis.close();
3.2 POI 内部做了什么
XWPFDocument 内部流程:
1. 用 ZipInputStream 解压 .docx
2. 解析 [Content_Types].xml 确定各部分类型
3. 解析 _rels/.rels 确定关系
4. 用 SAX/DOM 解析 word/document.xml
5. 构建段落、表格、图片等对象模型
XWPFWordExtractor.getText() 内部流程:
1. 遍历所有段落(包括表格中的段落)
2. 遍历每个段落的 Run
3. 拼接 Run 中的文本
4. 处理页眉、页脚、脚注
5. 返回完整文本
3.3 POI vs doc_text 的 docx 解析
| 维度 | POI | doc_text (OpenHarmony) |
|---|---|---|
| ZIP 解压 | ZipInputStream(Java 标准库) | zlib.decompressFile(系统 API) |
| XML 解析 | SAX/DOM 解析器 | 正则表达式 |
| 内容覆盖 | 段落 + 表格 + 页眉页脚 + 脚注 | 只有 <w:t> 标签 |
| 代码量 | 几百行(加上依赖几千行) | ~70 行 |
四、minSdkVersion 26 的限制
4.1 为什么需要 API 26
android {
defaultConfig {
minSdkVersion 26 // Android 8.0 (Oreo)
}
}
POI 5.x 依赖了一些 Java 8 的 API,这些 API 在 Android 上需要 API 26 才能使用:
| Java API | 用途 | Android API 要求 |
|---|---|---|
| java.util.stream | 集合流操作 | API 24 |
| java.time | 日期时间 | API 26 |
| java.util.Optional | 可选值 | API 24 |
| try-with-resources | 资源管理 | API 19 |
4.2 兼容性影响
Android 版本分布(2024年):
API 26+ (Android 8.0+): ~95% 的设备
API 24+ (Android 7.0+): ~98% 的设备
API 21+ (Android 5.0+): ~99% 的设备
minSdkVersion 26 意味着放弃了约 5% 的旧设备。
对于大多数应用来说,这是可以接受的。
4.3 OpenHarmony 没有这个问题
// OpenHarmony 端不依赖任何外部库
// 没有 minSdkVersion 的限制
// 只要设备支持 Flutter-OHOS 就能运行
💡 OpenHarmony 端的零依赖设计反而成了优势——不需要担心第三方库的版本兼容性问题。
五、从文件路径到纯文本的完整数据流
5.1 Android 端数据流
Dart: DocText().extractTextFromDoc("/storage/emulated/0/test.docx")
↓
MethodChannel: invokeMethod('extractTextFromDoc', {'filePath': ...})
↓
Android: DocTextPlugin.onMethodCall(call, result)
↓
Android: val filePath = call.argument<String>("filePath")
↓
Android: 判断文件扩展名
├── .doc → HWPFDocument → WordExtractor → getText()
└── .docx → XWPFDocument → XWPFWordExtractor → getText()
↓
Android: result.success(text)
↓
Dart: 返回 "提取的文本内容"
5.2 OpenHarmony 端数据流
Dart: DocText().extractTextFromDoc("/data/storage/test.docx")
↓
MethodChannel: invokeMethod('extractTextFromDoc', {'filePath': ...})
↓
ArkTS: DocTextPlugin.onMethodCall(call, result)
↓
ArkTS: const filePath = args.get("filePath") as string
↓
ArkTS: 判断文件扩展名
├── .doc → OLE2Parser → extractWordText → Piece Table / Direct
└── .docx → zlib.decompressFile → parseDocxXml → 正则提取
↓
ArkTS: result.success(text)
↓
Dart: 返回 "提取的文本内容"
5.3 对比
| 环节 | Android | OpenHarmony |
|---|---|---|
| 文件读取 | FileInputStream | fs.openSync + readSync |
| .doc 解析 | Apache POI | 手写 OLE2Parser |
| .docx 解析 | Apache POI | zlib + 正则 |
| 文本清洗 | POI 内置 | cleanText 方法 |
| 错误处理 | try-catch + POI 异常 | try-catch + 自定义错误码 |
六、Android 方案的优势与局限
6.1 优势
- 代码量少:几十行就搞定
- 功能完整:POI 支持段落、表格、页眉页脚、脚注等
- 格式兼容性好:POI 经过多年打磨,处理了各种异常格式
- 社区支持:遇到问题容易找到解决方案
6.2 局限
- 包体积大:POI + 依赖可能增加 5-10MB
- minSdkVersion 限制:需要 API 26
- 内存占用高:POI 会把整个文档加载到内存
- 启动慢:首次加载 POI 类需要时间
6.3 为什么 OpenHarmony 不能用 POI
POI 是 Java 库:
- 依赖 java.io.* / java.util.* / javax.xml.* 等 Java 标准库
- OpenHarmony 的运行时是 ArkTS(基于 TypeScript)
- 没有 JVM,无法运行 Java 字节码
- 没有 Java 标准库
所以 OpenHarmony 端必须用 ArkTS 重新实现所有解析逻辑。
| 平台 | 运行时 | 可用的 Word 解析库 |
|---|---|---|
| Android | JVM (ART) | Apache POI ✅ |
| iOS | Objective-C/Swift | 无成熟库 ❌ |
| OpenHarmony | ArkTS | 无 ❌ |
| Web | JavaScript | mammoth.js ✅ |
📌 这就是 doc_text 适配 OpenHarmony 最大的挑战——不是 API 不兼容,不是权限不够,而是根本没有可用的 Word 解析库。一切都要从零开始。
七、POI 的替代方案
7.1 如果不用 POI
| 方案 | 语言 | 优点 | 缺点 |
|---|---|---|---|
| Apache POI | Java | 功能最全 | 包体积大 |
| docx4j | Java | OOXML 专精 | 只支持 .docx |
| 手写解析 | 任意 | 零依赖、体积小 | 开发成本高 |
| 调用系统 API | 平台相关 | 无额外依赖 | 功能受限 |
7.2 doc_text 的选择
Android 端:选择 Apache POI
→ 理由:Java 生态成熟,POI 功能完整
OpenHarmony 端:选择手写解析
→ 理由:没有其他选择,ArkTS 生态中没有 Word 解析库
7.3 手写解析的取舍
POI 能做的:
✅ 提取文本
✅ 提取格式(字体、颜色、大小)
✅ 提取表格结构
✅ 提取图片
✅ 提取页眉页脚
✅ 提取批注
✅ 提取修订记录
doc_text 手写解析能做的:
✅ 提取文本
❌ 其他全部不支持
这是一个合理的取舍——doc_text 的定位就是"提取纯文本",不需要格式信息。
总结
本文分析了 doc_text 的 Android 端实现:
- Apache POI:Java 生态最成熟的 Office 文档处理库
- HWPFDocument / XWPFDocument:分别处理 .doc 和 .docx
- minSdkVersion 26:POI 5.x 的 Java API 要求
- 包体积代价:5-10MB 的额外依赖
- OpenHarmony 无法使用:ArkTS 运行时没有 JVM,无法运行 Java 库
下一篇我们开始 OpenHarmony 端的工程搭建——从零创建插件项目。
如果这篇文章对你有帮助,欢迎点赞👍、收藏⭐、关注🔔,你的支持是我持续创作的动力!
相关资源:

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 34
34 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)