
Flutter三方库适配OpenHarmony【doc_text】— Word 文档格式深度科普:从 OLE2 到 OOXML
前言
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net
要看懂 doc_text 的 OpenHarmony 实现代码,得先搞明白 Word 文档到底是怎么存数据的。很多开发者只知道 .doc 和 .docx 是"Word 文件",但对它们内部的存储结构一无所知。这篇文章不写代码,专门讲格式——把 OLE2 和 OOXML 两种格式的核心概念讲透。
一、微软 Word 文档格式的演进
1.1 历史时间线
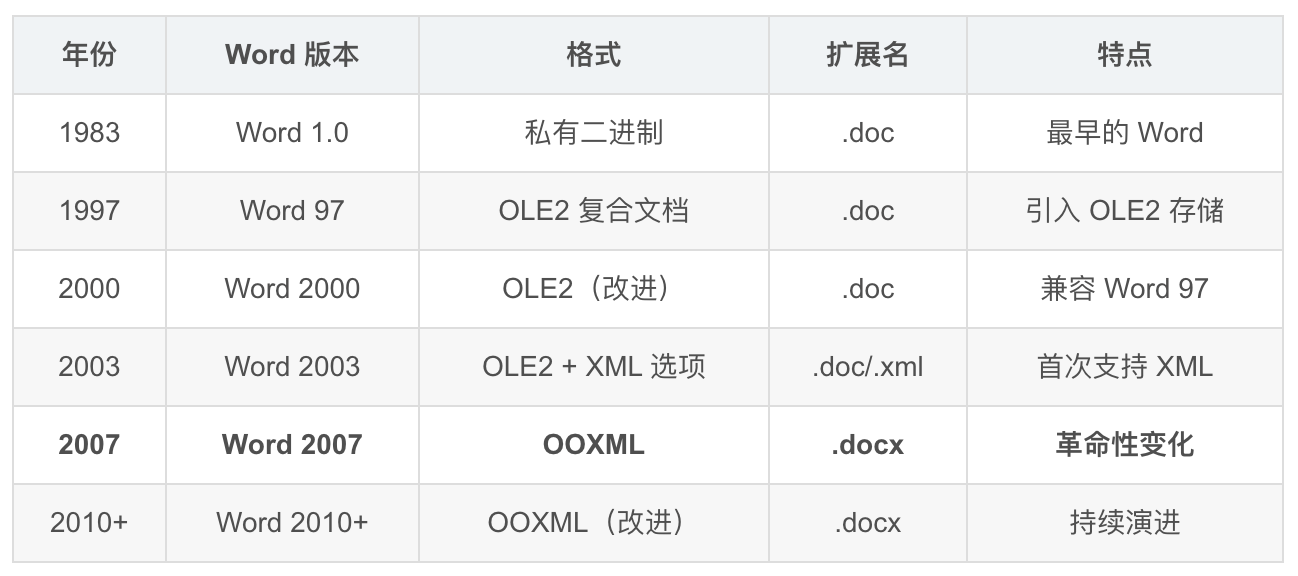
1.2 为什么微软要换格式
OLE2 的问题:
1. 二进制格式 → 人类不可读
2. 专有规范 → 第三方难以实现
3. 容易损坏 → 一个字节错误可能导致整个文件无法打开
4. 不利于版本控制 → diff 无意义
5. 安全隐患 → 宏病毒容易隐藏
OOXML 的改进:
1. XML 文本 → 人类可读
2. 开放标准 → ECMA-376 国际标准
3. ZIP 压缩 → 文件更小
4. 模块化 → 各部分独立,不容易整体损坏
5. 安全性 → 宏和内容分离
💡 2007 年是分水岭。从这一年开始,Word 默认保存格式从 .doc 变成了 .docx。但直到今天,仍然有大量 .doc 文件在流通——这就是 doc_text 必须同时支持两种格式的原因。
二、OLE2 复合文档格式
2.1 什么是 OLE2
OLE2(Object Linking and Embedding 2)复合文档格式,微软官方叫 Compound Binary File Format,规范编号 MS-CFB。
简单说,它就是一个文件中的文件系统。
普通文件系统:
硬盘 → 分区 → 文件夹 → 文件
OLE2 复合文档:
.doc 文件 → 扇区 → 目录 → 流(Stream)
2.2 扇区(Sector)
.doc 文件的物理结构:
偏移 0x000: ┌──────────────────┐
│ 文件头(512B) │ ← Header
偏移 0x200: ├──────────────────┤
│ 扇区 0(512B) │ ← Sector 0
偏移 0x400: ├──────────────────┤
│ 扇区 1(512B) │ ← Sector 1
偏移 0x600: ├──────────────────┤
│ 扇区 2(512B) │ ← Sector 2
│ ... │
└──────────────────┘
| 概念 | 说明 | 类比 |
|---|---|---|
| 扇区(Sector) | 512 字节的数据块 | 硬盘的扇区 |
| 扇区大小 | 由头部的 sectorShift 决定(通常 512) | 块大小 |
| 扇区编号 | 从 0 开始,头部不算 | 块号 |
| 扇区偏移 | 512 + sectorNumber × sectorSize | 物理地址 |
2.3 FAT(File Allocation Table)
FAT 是扇区的"链表"——告诉你一个流的下一个扇区在哪里。
FAT 表(数组):
索引: [0] [1] [2] [3] [4] [5] [6]
值: [1] [2] [END] [5] [END] [6] [END]
流 A 的扇区链:0 → 1 → 2 → END(读 FAT[0]=1, FAT[1]=2, FAT[2]=END)
流 B 的扇区链:3 → 5 → 6 → END(读 FAT[3]=5, FAT[5]=6, FAT[6]=END)
| FAT 值 | 含义 |
|---|---|
| 0x00000000 - 0xFFFFFFFA | 下一个扇区的编号 |
| 0xFFFFFFFE | 链结束(End of Chain) |
| 0xFFFFFFFF | 空闲扇区 |
| 0xFFFFFFFD | FAT 扇区自身 |
📌 FAT 的设计和 DOS 时代的 FAT 文件系统几乎一样。如果你理解 FAT16/FAT32 文件系统,OLE2 的 FAT 就很容易理解。
2.4 迷你扇区(Mini Sector)
对于小于 4096 字节的流,OLE2 不使用普通扇区,而是使用迷你扇区(64 字节一个)。
普通扇区:512 字节 → 适合大文件
迷你扇区:64 字节 → 适合小文件
如果一个流 < 4096 字节 → 存在迷你流中
如果一个流 >= 4096 字节 → 存在普通扇区中
| 参数 | 普通扇区 | 迷你扇区 |
|---|---|---|
| 大小 | 512 字节 | 64 字节 |
| FAT | 主 FAT | Mini FAT |
| 存储位置 | 文件直接扇区 | Root Entry 的流数据中 |
| 适用场景 | 大流(≥4096B) | 小流(<4096B) |
2.5 目录流(Directory Stream)
目录流记录了文件中所有"流"的元信息,每个条目 128 字节。
目录条目结构(128 字节):
偏移 0x00: 名称(UTF-16LE,最长 32 字符,64 字节)
偏移 0x40: 名称长度(2 字节)
偏移 0x42: 条目类型(1 字节):0=空 1=Storage 2=Stream 5=Root
偏移 0x43: 颜色(红黑树)
偏移 0x44: 左兄弟 ID
偏移 0x48: 右兄弟 ID
偏移 0x4C: 子节点 ID
偏移 0x74: 起始扇区(4 字节)
偏移 0x78: 流大小(4 字节)
2.6 Word 文档中的关键流
.doc 文件的目录结构:
Root Entry (type=5)
├── WordDocument (type=2) ← 文本数据 + FIB
├── 1Table (type=2) ← 格式信息(Piece Table 在这里)
├── 0Table (type=2) ← 备用格式信息
├── Data (type=2) ← 嵌入对象数据
├── CompObj (type=2) ← 复合对象信息
└── SummaryInformation ← 文档属性
三、OOXML 格式
3.1 OOXML 的本质
# .docx 文件就是一个 ZIP 包
$ unzip -l document.docx
Archive: document.docx
Length Date Time Name
--------- ---------- ----- ----
1312 2024-01-15 10:30 [Content_Types].xml
590 2024-01-15 10:30 _rels/.rels
12456 2024-01-15 10:30 word/document.xml
8234 2024-01-15 10:30 word/styles.xml
1024 2024-01-15 10:30 word/fontTable.xml
768 2024-01-15 10:30 word/settings.xml
456 2024-01-15 10:30 word/_rels/document.xml.rels
234 2024-01-15 10:30 docProps/core.xml
567 2024-01-15 10:30 docProps/app.xml
3.2 word/document.xml 的结构
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<w:document xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<w:body>
<w:p> <!-- 段落 (paragraph) -->
<w:pPr> <!-- 段落属性 -->
<w:jc w:val="center"/> <!-- 居中对齐 -->
</w:pPr>
<w:r> <!-- 文本运行 (run) -->
<w:rPr> <!-- 运行属性 -->
<w:b/> <!-- 加粗 -->
</w:rPr>
<w:t>Hello World</w:t> <!-- 实际文本 ← 我们要提取的 -->
</w:r>
</w:p>
<w:p>
<w:r>
<w:t xml:space="preserve">这是第二段文字</w:t>
</w:r>
</w:p>
</w:body>
</w:document>
3.3 标签层级
| 标签 | 全称 | 含义 |
|---|---|---|
<w:document> |
Document | 文档根元素 |
<w:body> |
Body | 文档正文 |
<w:p> |
Paragraph | 段落 |
<w:r> |
Run | 文本运行(一段连续格式的文本) |
<w:t> |
Text | 实际的文本内容 |
<w:pPr> |
Paragraph Properties | 段落格式 |
<w:rPr> |
Run Properties | 文本格式 |
💡 doc_text 只需要提取
<w:t>标签中的内容。段落格式、字体、颜色等信息全部忽略——因为我们只要纯文本。
3.4 OOXML 中的特殊内容
<!-- 表格 -->
<w:tbl>
<w:tr> <!-- 表格行 -->
<w:tc> <!-- 表格单元格 -->
<w:p><w:r><w:t>单元格内容</w:t></w:r></w:p>
</w:tc>
</w:tr>
</w:tbl>
<!-- 超链接 -->
<w:hyperlink r:id="rId1">
<w:r><w:t>链接文字</w:t></w:r>
</w:hyperlink>
<!-- 图片(只有引用,没有文本) -->
<w:drawing>
<wp:inline>
<a:blip r:embed="rId2"/>
</wp:inline>
</w:drawing>
表格和超链接中的文本仍然在 <w:t> 标签里,所以正则提取可以覆盖。但图片没有文本内容,会被自然忽略。
四、为什么解析 .doc 比 .docx 难 10 倍
4.1 获取文本的步骤对比
.docx 解析步骤:
1. 解压 ZIP
2. 读取 word/document.xml
3. 用正则提取 <w:t> 标签内容
→ 3 步搞定
.doc 解析步骤:
1. 验证 OLE2 魔数
2. 解析文件头(扇区大小、FAT 位置等)
3. 构建 FAT 表
4. 构建 Mini FAT 表
5. 读取目录流
6. 遍历目录找到 WordDocument 流
7. 读取 WordDocument 流数据
8. 解析 FIB(File Information Block)
9. 检查是否加密
10. 获取文本长度(ccpText)
11. 找到 1Table 或 0Table 流
12. 定位 CLX 结构
13. 解析 Piece Table
14. 根据 Piece Descriptor 的编码标志判断 Unicode/ANSI
15. 逐段提取文本
16. 如果 Piece Table 失败,尝试直接提取(多偏移量探测)
→ 16 步,每一步都可能失败
4.2 错误容忍度对比
| 维度 | .docx | .doc |
|---|---|---|
| 一个字节错误 | XML 解析失败,但其他部分不受影响 | 可能导致 FAT 链断裂,整个文件不可读 |
| 格式不标准 | XML 有明确的错误提示 | 二进制偏移错一位就全乱了 |
| 调试难度 | 用文本编辑器就能看 | 需要十六进制编辑器 |
4.3 编码问题对比
.docx:统一使用 UTF-8(XML 声明中指定)
.doc:可能是 Unicode(UTF-16LE)或 ANSI(取决于 Piece Table 标志)
同一个文档中可能混用两种编码
五、用十六进制编辑器看 .doc 文件
5.1 文件头
偏移 十六进制 ASCII
0000: D0 CF 11 E0 A1 B1 1A E1 ← OLE2 魔数
0008: 00 00 00 00 00 00 00 00
0010: 00 00 00 00 00 00 00 00
0018: 3E 00 ← 版本号 0x003E
001A: 03 00 ← 主版本 0x0003
001C: FE FF ← 字节序(小端)
001E: 09 00 ← sectorShift = 9 → 2^9 = 512
0020: 06 00 ← miniShift = 6 → 2^6 = 64
5.2 魔数的故事
D0 CF 11 E0 A1 B1 1A E1
如果你把这 8 个字节"念"出来,听起来像:
"DOCFILE" + 一些填充
D0CF11E0 → 看起来像 "DOCFILE0"
A1B11AE1 → 签名的后半部分
📌 每种文件格式都有自己的魔数。PNG 是
89 50 4E 47,PDF 是25 50 44 46(%PDF),ZIP 是50 4B 03 04(PK)。doc_text 的 OLE2Parser 第一步就是验证这 8 个字节。
六、.docx 文件的手动解析演示
6.1 用命令行解压
# 把 .docx 改名为 .zip 然后解压
cp document.docx document.zip
unzip document.zip -d document_extracted/
# 查看目录结构
tree document_extracted/
6.2 查看 document.xml
# 格式化 XML 方便阅读
xmllint --format document_extracted/word/document.xml
6.3 手动提取文本
# 用 grep 提取所有 <w:t> 标签的内容
grep -oP '(?<=<w:t[^>]*>)[^<]+' document_extracted/word/document.xml
这个 grep 命令做的事情,和 doc_text 的 parseDocxXml 方法本质上是一样的——用正则提取 <w:t> 标签中的文本。
七、格式选择对开发者的影响
7.1 如果你只需要支持 .docx
// 只需要 ~100 行代码
// 1. zlib 解压
// 2. 读取 XML
// 3. 正则提取
7.2 如果你还需要支持 .doc
// 需要额外 ~500 行代码
// 包含一个完整的 OLE2 解析器
// 和 Piece Table 文本提取逻辑
7.3 实际项目中的建议
| 场景 | 建议 |
|---|---|
| 只处理新文档 | 只支持 .docx |
| 需要兼容旧文档 | 两种都支持(像 doc_text 一样) |
| 需要格式信息 | 考虑更完整的库(如 Android 上的 POI) |
| 只需要纯文本 | doc_text 足够 |
总结
本文科普了 Word 文档的两种格式:
- OLE2(.doc):1997 年的二进制格式,内部是一个迷你文件系统(扇区 + FAT + 目录)
- OOXML(.docx):2007 年的开放格式,本质是 ZIP + XML
- 文本位置:.docx 在
<w:t>标签中,.doc 在 WordDocument 流的 Piece Table 中 - 解析难度:.doc 比 .docx 难 10 倍,doc_text 的 OLE2Parser 就是为此而写
下一篇我们回到代码层面,分析 doc_text 的 Dart 层架构。
如果这篇文章对你有帮助,欢迎点赞👍、收藏⭐、关注🔔,你的支持是我持续创作的动力!
相关资源:

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 22
22 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)