
开源鸿蒙跨平台训练营DAY15-16:Flutter for OpenHarmony从单一模型到职责分离的优化
前言
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net
本文深入分析了在 Flutter 猫咪健康管理项目中,如何通过数据模型分层设计解决业务逻辑复杂化问题。通过引入 CatModel来代表具体的猫咪个体,与原有的 CatBreed形成互补关系,详细探讨了数据耦合解耦、扩展性提升和状态管理优化的实现原理和设计思路。
1.背景原因
在项目初期架构中,采用单一的 Cat模型来承载所有猫咪相关信息。这种设计在项目初期确实简化了开发流程,但随着"我的猫咪"功能的引入,原有模型无法区分“品种信息”和“具体猫咪个体”这两个概念,架构缺陷逐渐暴露:
// 原有设计的问题示例
class CatBreed {
// 品种属性
final String breedName;
final List<String> breedHealthRisks;
// 个体属性 - 这里出现了设计问题
final String catNickname; // 个体属性混入品种模型
final DateTime catBirthday; // 生日是个体属性
// 这种设计导致的问题:
// 1. 一个品种对象包含多个猫咪的个体信息?
// 2. 数据冗余:相同品种的猫咪重复存储品种信息
// 3. 查询困难:无法快速获取用户的所有猫咪
}
具体表现为:
1.数据范式违反:违反了数据库设计的第一范式,一个模型承担过多职责
2.内存浪费:每只猫咪都完整存储品种信息,造成内存冗余
3.业务逻辑混乱:在品种模型中处理个体业务逻辑,代码可读性差
4.扩展瓶颈:新增猫咪个性化属性(如疫苗记录、饮食偏好)需要修改品种模型
2.解决方案:基于组合模式的双模型设计
2.1 猫咪品种模型 (CatBreed) - 静态数据容器
- 设计理念:将品种信息设计为不可变的静态数据容器,专注于描述品种的固有特征。
- 功能定位:描述猫咪的品种特征,如健康风险、性格特点等,属于静态数据
- 架构分析:
class CatBreed {
// 核心标识属性
final int id;
final String name;
// 品种特征属性 - 所有该品种猫咪共享
final String desc;
final List<String> healthRisks; // 健康风险特征
final String groomingNeeds; // 护理特征
final String activityLevel; // 行为特征
// 设计模式应用:使用工厂模式进行安全构造
factory CatBreed.fromJson(Map<String, dynamic> json) {
// 空安全处理策略
List<String> safeHealthRisks = _safeListConversion(json['healthRisks']);
List<String> safeSuitableFor = _safeListConversion(json['suitableFor']);
return CatBreed(
id: json['id'] ?? 0,
name: json['name'] ?? '未知品种',
desc: json['desc'] ?? '',
// 使用防御性拷贝防止外部修改
healthRisks: List<String>.from(safeHealthRisks),
groomingNeeds: json['groomingNeeds'] ?? '未知',
activityLevel: json['activityLevel'] ?? '中等',
lifeExpectancy: json['lifeExpectancy'] ?? '',
suitableFor: List<String>.from(safeSuitableFor),
difficultyLevel: json['difficultyLevel'] ?? '中等',
);
}
// 辅助方法:封装列表转换逻辑
static List<String> _safeListConversion(dynamic data) {
if (data == null) return [];
if (data is List) return List<String>.from(data);
return [];
}
}
设计模式应用分析:
1.工厂模式:通过 fromJson工厂方法封装对象创建逻辑,保证构造安全性
2.不可变对象模式:所有字段均为 final,确保线程安全和状态一致性
3.防御性编程:对输入数据进行验证和清理,提高代码健壮性
2.2 猫咪个体模型 (CatModel) - 动态业务实体
- 设计理念:将猫咪个体设计为业务核心实体,通过组合关系引用品种信息。
- 功能定位:描述用户拥有的具体猫咪,包含昵称、生日等个性化属性,属于动态数据。
- 架构深度分析:
class CatModel {
// 个体标识属性
final String id;
final String name;
final String nickname;
// 组合关系:个体拥有一个品种 - 体现"is-a"关系
final CatBreed breed;
// 个体特有属性
final DateTime birthday;
final String gender;
final double weight;
final String avatarUrl;
// 计算属性设计:避免存储冗余数据
int get ageInMonths {
final now = DateTime.now();
int months = (now.year - birthday.year) * 12 + (now.month - birthday.month);
// 处理天数差异
if (now.day < birthday.day) months--;
return months > 0 ? months : 0;
}
// 业务逻辑方法:年龄分类
String get ageCategory {
final months = ageInMonths;
return switch (months) {
< 3 => '幼猫',
< 12 => '青年猫',
< 84 => '成年猫', // 7年
_ => '老年猫',
};
}
// 依赖注入构造:显式要求品种对象
factory CatModel.fromJson(Map<String, dynamic> json, CatBreed breed) {
// 参数验证
assert(breed != null, 'CatBreed cannot be null');
return CatModel(
id: json['id'] ?? _generateId(),
name: json['name']?.trim() ?? '未命名',
nickname: json['nickname']?.trim() ?? '',
breed: breed,
birthday: _parseBirthday(json['birthday']),
gender: _validateGender(json['gender']),
weight: _validateWeight(json['weight']),
avatarUrl: json['avatarUrl'] ?? '',
);
}
// 私有辅助方法:封装验证逻辑
static DateTime _parseBirthday(dynamic birthdayData) {
try {
if (birthdayData is String) return DateTime.parse(birthdayData);
return DateTime.now().subtract(Duration(days: 365)); // 默认1岁
} catch (e) {
return DateTime.now().subtract(Duration(days: 365));
}
}
}
架构优势分析:
1.组合优于继承:通过组合关系实现代码复用,避免继承的脆弱性
2.单一职责原则:每个模型只关注自己的核心职责
3.开闭原则:扩展新功能时不需要修改现有模型
4.依赖倒置:高层模块不依赖低层模块,都依赖抽象
3. 数据关系设计与性能优化
3.1 数据关联策略
// 数据关联管理类
class CatDataManager {
final Map<int, CatBreed> _breedCache = {}; // 品种缓存
final List<CatModel> _userCats = []; // 用户猫咪
// 通过ID关联品种和个体
CatModel? createCatFromData(Map<String, dynamic> catData, int breedId) {
final breed = _breedCache[breedId];
if (breed == null) return null;
return CatModel.fromJson(catData, breed);
}
// 批量操作优化
List<CatModel> filterCatsByHealthRisk(String risk) {
return _userCats.where((cat) => cat.breed.healthRisks.contains(risk)).toList();
}
}
3.2 内存优化策略
// 使用享元模式共享品种对象
class BreedFlyweightFactory {
static final Map<int, CatBreed> _breedPool = {};
static CatBreed getBreed(int id, Map<String, dynamic> data) {
return _breedPool.putIfAbsent(id, () => CatBreed.fromJson(data));
}
static void clearCache() => _breedPool.clear();
}
4. 设计模式综合应用分析
4.1 模型层的设计模式组合
| 设计模式 | 应用场景 | 具体实现 | 架构收益 |
|---|---|---|---|
| 工厂模式 | 对象创建 | fromJson工厂方法 |
封装构造逻辑,保证对象一致性 |
| 享元模式 | 资源共享 | 品种对象缓存池 | 减少内存占用,提高性能 |
| 策略模式 | 算法封装 | 验证策略、计算策略 | 提高可扩展性和可测试性 |
| 组合模式 | 层次结构 | 品种-个体组合关系 | 建立清晰的业务领域模型 |
| 仓库模式 | 数据访问 | CatDataRepository | 分离数据访问与业务逻辑 |
4.2 性能与可维护性平衡
// 性能优化示例:懒加载计算属性
class CatModel {
// ... 其他属性
// 懒加载缓存
int? _cachedAge;
int get ageInMonths {
_cachedAge ??= _calculateAge();
return _cachedAge!;
}
void updateBirthday(DateTime newBirthday) {
birthday = newBirthday;
_cachedAge = null; // 清除缓存
}
}
5. 架构演进的价值体现
5.1量化收益分析:
- 内存占用:从 O(n×m) 降低到 O(n+m),n为猫咪数量,m为品种数量
- 代码复用率:品种数据复用率达到 100%
- 维护成本:修改个体属性不影响品种逻辑,降低回归测试范围
5.2质量属性提升:
- 职责分离:CatBreed负责品种通用属性,CatModel负责个体特有属性,代码结构清晰。
- 数据复用:多个猫咪可以共享同一个品种对象,减少了内存占用和数据冗余。
- 扩展性强:新增猫咪属性(如疫苗接种记录)只需修改 CatModel,不影响品种数据的稳定性。
总结
关键架构决策的启示:
1.早重构,常重构:在技术债务积累前及时重构
2.领域驱动设计:按照业务领域而非技术实现划分模块
3.性能与可维护性平衡:在架构设计阶段考虑性能优化
4.测试驱动开发:良好的架构自然支持高质量的测试
最后的model架构如图,但是因为规范模型的操作,导致其他文件出现报错,是因为原本的文件名称和位置发生了改变,规范后breeds涉及但是品种列表,cat为个体的所有信息,根据不同文件的需求修改,项目可以完整运行,数据模型得到优化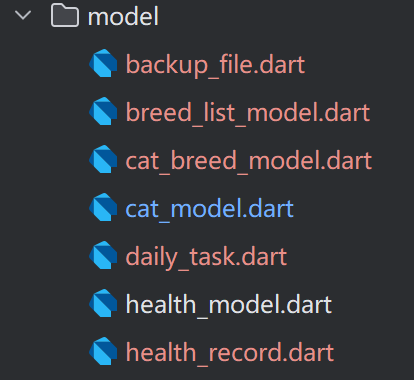
这种架构设计不仅解决了当前的业务需求,更为后续的功能扩展(如多猫咪管理、健康记录追踪等)奠定了坚实的技术基础。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 6
6 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)