
910B服务器使用Gpustack通过vllm-omni部署qwen-image2511
因为vllm-omni 是 vLLM-Omni 通过 vLLM Ascend 插件 (vllm-ascend) 支持 NPU。所以没有根据官方文档 vllm-Omini,如果要容器化,只能运行在vllm-ascend昇腾环境中,所以 我们需要在容器中安装成功 vLLM-Omni 并打包成可以一键在GPUstack启动中启动的docker镜像。打包方式:1.启动 ascend环境特别说明:这个目录是
基础环境:
- gpustack:v2.3
- 服务器:910B 显存:8*64
操作方式:
因为vllm-omni 是 vLLM-Omni 通过 vLLM Ascend 插件 (vllm-ascend) 支持 NPU。所以没有根据官方文档 vllm-Omini
,如果要容器化,只能运行在vllm-ascend昇腾环境中,所以 我们需要在容器中安装成功 vLLM-Omni 并打包成可以一键在GPUstack启动中启动的docker镜像。
打包方式:
1.启动 ascend环境
export IMAGE=quay.io/gpustack/runner:cann8.3-910b-vllm0.12.0 # vllm昇腾镜像
docker run --rm \
--name vllm-omni-npu \
--privileged \
--shm-size=1g \
-e ASCEND_VISIBLE_DEVICES=0-7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root/.cache:/root/.cache \
-v /home/xahp/qwen-images/vllm-omni/:/vllm-workspace/vllm-omni \
--ipc=host \
-p 8000:8000 \
-it $IMAGE bash
特别说明:
这个目录是/home/xahp/qwen-images/vllm-omni我提前将/vllm-omni的代码下载到宿主机上然后映射到容器内部,具体的版本vllm昇腾和vllm-omin 对照关系请参考 https://github.com/vllm-project/vllm-omni/issues/886
启动成功以后,将进入容器内部安装vllm-omni:
cd /vllm-workspace
cd vllm-omni
pip install -v .
echo "export VLLM_WORKER_MULTIPROC_METHOD=spawn" >> ~/.bashrc
echo "export VLLM_PLATFORM=ascend" >> ~/.bashrc
source ~/.bashrc
安装成功以后,将此容器打包成镜像
docker commit vllm-omni-npu vllm-omni-ascend:v0.12.0rc1
接下来,就可以离线去启动模型了:
export IMAGE=vllm-omni-ascend:v0.12.0rc1
docker run --rm \
--name vllm-omni-npu \
--privileged \
--shm-size=1g \
-e ASCEND_VISIBLE_DEVICES=0-7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root/.cache:/root/.cache \
-v /home/xahp/gpustack-data/cache/model_scope/Qwen/Qwen-Image-2512:/data/models/Qwen-Image-2512:ro \
--ipc=host \
-p 8000:8000 \
-it $IMAGE bash
参数说明:
模型权重映射: -v /home/xahp/gpustack-data/cache/model_scope/Qwen/Qwen-Image-2512:/data/models/Qwen-Image-2512:ro \
gpustack集成: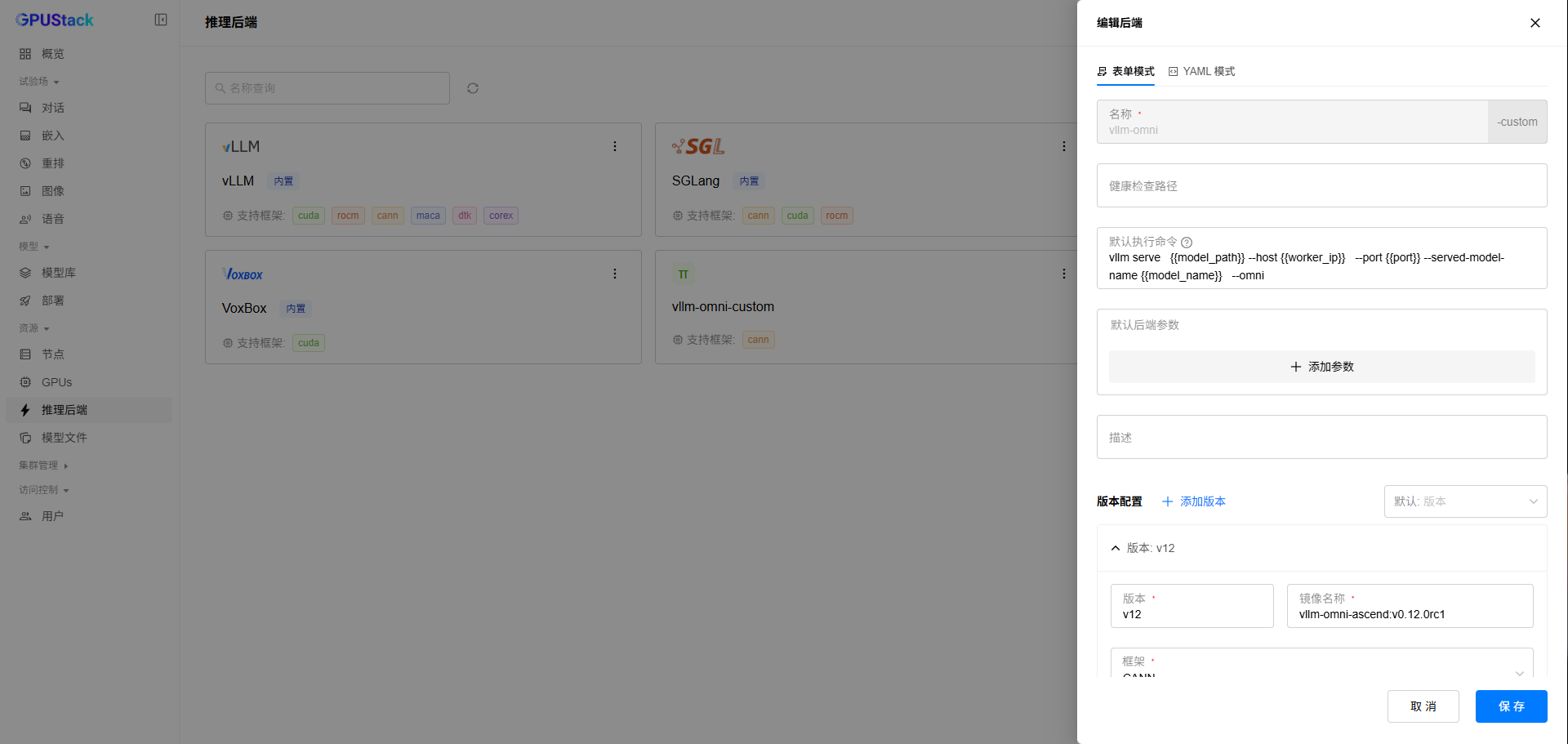

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)