
揭秘CANN算子库:从ops-nn仓库解读AIGC的底层加速引擎
下面我们通过一个完整的自定义Add算子开发案例,演示CANN算子开发的实战流程。我们将基于ops-nn仓库的代码结构,使用Ascend C语言开发一个高性能的Add算子。CANN算子库(特别是ops-nn仓库)为AIGC模型的加速提供了强大的底层支持。通过深入理解CANN的算子开发流程和优化技术,开发者可以充分发挥昇腾硬件的性能优势,构建高效、可靠的AIGC应用。随着CANN开源生态的不断完善,越
cann组织链接:https://atomgit.com/cann
ops-nn仓库链接:https://atomgit.com/cann/ops-nn
在人工智能生成内容(AIGC)时代,算子的性能优化已成为提升模型推理效率的关键。华为CANN(Compute Architecture for Neural Networks)作为昇腾AI处理器的异构计算架构,其ops-nn算子库提供了丰富的高性能神经网络算子,为AIGC模型的加速奠定了坚实基础。本文将深入剖析CANN算子库的技术架构,并通过自定义算子的实战开发,揭示AIGC底层加速的奥秘。
一、CANN算子库:AIGC加速的基石
CANN采用分层架构设计,为不同层次的开发者提供了差异化的开发接口。其算子库(如ops-nn)提供了大量深度优化、硬件亲和的高性能算子,为神经网络在昇腾硬件上加速计算提供基础。CANN算子体系主要包含两类算子:
| 算子类型 | 执行单元 | 适用场景 | 技术特点 |
|---|---|---|---|
| AI Core算子 | 昇腾AI Core | 矩阵、向量、标量计算密集型任务 | 高并行、向量化、低精度计算 |
| AI CPU算子 | 昇腾AI CPU | 非矩阵类复杂计算、控制逻辑 | 灵活控制、分支处理、标量运算 |
ops-nn仓库主要聚焦于神经网络(NN)相关的基础算子,包括卷积、池化、激活函数等,这些算子是构建深度学习模型的基础。CANN算子库的核心价值在于:
- 计算效率的系统性提升:通过深度图优化、自动图拆分与融合、数据Pipeline智能优化等技术,支撑极致性能的发挥。
- 多层次开发支持体系:提供从应用层到算子层的完整开发支持,满足不同层次的开发需求。
- 硬件亲和的算子实现:针对昇腾硬件架构特点进行优化,充分发挥AI Core的矩阵计算能力。
二、算子开发原理:从TIK到Ascend C
在CANN框架中,算子开发者可以选择不同的开发方式。TIK(Tensor Iterator Kernel)是算子开发者最常用也最核心的底层编程模型之一。它构建在TBE(Tensor Boost Engine)之上,通过一套接近硬件执行模型的Python DSL,开发者可以直接操控Unified Buffer、L1 Buffer、AI Core指令等底层资源。
2.1 TIK算子开发流程
一个典型的TIK算子Python程序由以下步骤构成:
TIK的核心优势在于当高性能计算需要复杂访存策略、非常规数据布局、跨核流水并行时,它能让开发者获得足够的硬件控制权。它允许开发者:
- 管控UB/L1/GM的内存布局
- 控制数据搬运细粒度行为
- 直接调度AI Core指令
- 精确规划循环展开、tile分块与buffer reuse
- 利用DMA pipeline与算子流水最大化吞吐
2.2 Ascend C算子开发进阶
Ascend C是昇腾AI异构计算架构CANN针对算子开发场景推出的编程语言,原生支持C和C++标准规范,最大化匹配用户开发习惯。通过多层接口抽象、自动并行计算、孪生调试等关键技术,它极大提高了算子开发效率。
Ascend C编程采用流水线式的编程范式,基于编程范式可以快速搭建算子实现的代码框架,实现流水并行。流水并行把算子核内的处理程序,分成多个流水任务:“搬入、计算、搬出”,通过队列(Queue)完成任务间通信和同步,并通过统一的内存管理模块(Pipe)管理任务间通信内存。
// Ascend C核函数示例
__global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z, AddCustomTilingData tiling) {
KERNEL_TASK_TYPE_DEFAULT(KERNEL_TYPE_AIV_ONLY);
KernelAdd op;
op.Init(x, y, z, tiling.totalLength, tiling.tileNum);
op.Process();
}
// KernelAdd类实现
class KernelAdd {
public:
__aicore__ inline KernelAdd(){}
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z, uint32_t totalLength, uint32_t tileNum);
__aicore__ inline void Process();
private:
__aicore__ inline void CopyIn(int32_t progress); // 数据搬入
__aicore__ inline void Compute(int32_t progress); // 向量计算
__aicore__ inline void CopyOut(int32_t progress); // 数据搬出
// 内存和队列管理对象
};
三、实战开发:自定义Add算子
下面我们通过一个完整的自定义Add算子开发案例,演示CANN算子开发的实战流程。我们将基于ops-nn仓库的代码结构,使用Ascend C语言开发一个高性能的Add算子。
3.1 算子分析
首先进行算子分析,明确数学表达式、输入输出规格及计算逻辑:
-
数学表达式:
z = x + y -
计算逻辑:将输入数据从Global Memory搬运到Local Memory,在Local Memory中进行矢量加法计算,将计算结果搬运回Global Memory
-
输入输出规格:
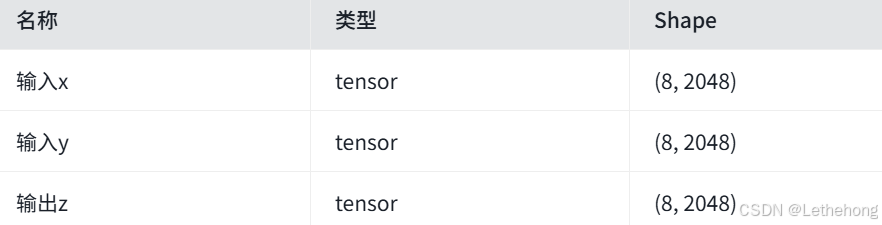
-
核函数与接口选择:使用
DataCopy接口进行Global Memory与Local Memory的数据搬运,Add接口进行矢量加法计算,AllocTensor/FreeTensor进行内存申请与释放,EnQue/DeQue进行多核并行队列管理
3.2 工程创建
使用msopgen工具生成算子工程结构:
${INSTALL_DIR}/python/site-packages/bin/msopgen gen -i add_custom.json -c ai_core-Ascend910 -lan cpp -out AddCustom
生成后的工程结构如下:
AddCustom/
├── build.sh # 编译入口脚本
├── CMakeLists.txt # 编译配置文件
├── op_host/
│ ├── add_custom.cpp # Host侧实现(含Shape推导)
│ └── add_custom_tiling.h # Tiling策略定义
├── op_kernel/
│ └── add_custom.cpp # Kernel侧核函数实现
└── scripts/
├── gen_data.py # 输入数据生成脚本
└── verify_result.py # 结果验证脚本
3.3 核心代码实现
3.3.1 Kernel侧实现
在op_kernel/add_custom.cpp中实现核函数的核心计算逻辑:
#include "acl/acl_base.h"
#include "kernel_operator.h"
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z, GM_ADDR workspace, GM_ADDR tiling) {
// 获取Tiling参数
TilingData tilingData;
GET_TILING_DATA(tilingData, tiling);
// 初始化算子类
KernelAdd addOp;
addOp.Init(x, y, z, tilingData.totalLength);
// 执行三级流水
addOp.Process(); // 包含CopyIn, Compute, CopyOut
}
3.3.2 Host侧实现
在op_host/add_custom.cpp中实现Host侧逻辑,包括算子原型注册、Shape推导和Tiling实现:
#include "register/register.h"
#include "add_custom_tiling.h"
namespace ge {
// 算子原型注册
IMPLEMT_COMMON_INFERFUNC(AddCustomInferShape)
{
auto shape_x = op.GetInputDescByName("x").GetShape().GetDims();
auto shape_y = op.GetInputDescByName("y").GetShape().GetDims();
// 输入shape校验
if (shape_x != shape_y) {
OP_LOGE(op.GetName().c_str(), "Input shapes must be the same");
return GRAPH_FAILED;
}
// 设置输出shape
TensorDesc output_desc = op.GetOutputDescByName("z");
output_desc.SetShape(shape_x);
op.UpdateOutputDesc("z", output_desc);
return GRAPH_SUCCESS;
}
COMMON_INFER_FUNC_REG(AddCustom, AddCustomInferShape);
}
3.4 编译与部署
编译算子工程:
cd AddCustom
./build.sh
打包算子:
cd output
./CANN_OP_CONTRIB_linux-aarch64.run --install
部署完成后,算子将安装到tool-kit/opp/vendors/目录下,可在网络中直接调用。
四、算子性能优化技术
高性能算子实现需要深度理解硬件架构并进行精细优化。以下是CANN算子性能优化的关键技术:
4.1 Tiling策略优化
Tiling数据分块策略是性能优化的关键,需要根据硬件特点(如AI Core数量、L1/L2 Cache大小)进行精细设计:
TilingData ComputeTiling(const Shape& input_shape) {
TilingData tiling;
// 获取AI Core数量
uint32_t aicore_num = AscendC::GetBlockNum();
// 按向量宽度分片
tiling.tile_count = aicore_num * 8;
tiling.tile_size = input_shape[0] / tiling.tile_count;
return tiling;
}
4.2 内存层次利用
充分利用内存层次结构,减少数据搬运开销:
void MemoryOptimizedCompute() {
CopyFromL2ToL1(data); // L2→L1 搬运
CopyFromL1ToL0(data); // L1→L0 搬运
Compute(); // L0计算
CopyFromL0ToL1(result);
CopyFromL1ToL2(result);
}
4.3 算子融合技术
算子融合是一种深度学习模型优化技术,旨在将多个算子融合为一个算子,从而减少计算量和参数数量,提高模型性能和效率。通过算子融合,可以:
- 减少计算量和参数数量
- 提高计算速度和内存使用效率
- 有助于减少模型大小,便于在资源受限的设备上部署
五、ops-nn仓库在AIGC中的应用
ops-nn算子库在AIGC模型中发挥着至关重要的作用。现代AIGC模型(如GPT、Stable Diffusion、Sora等)主要由以下几个关键算子构成:
| AIGC模型类型 | 关键算子需求 | ops-nn支持情况 | 性能影响 |
|---|---|---|---|
| 文本生成模型 | 自注意力矩阵乘算子、层归一化算子、激活函数 | ✅ 已支持 | 高性能矩阵运算是Transformer模型的基础 |
| 图像生成模型 | 卷积算子、上采样算子、激活函数、归一化算子 | ✅ 已支持 | 卷积和上采样算子的性能直接影响生成速度 |
| 视频生成模型 | 时空3D卷积算子、注意力算子、视频解码器 | ⚠️ 部分支持 | 需要针对视频数据的特殊算子进行优化 |
| 音频生成模型 | 1D卷积算子、GRU/LSTM算子、声码器算子 | ⚠️ 部分支持 | 需要针对音频数据的时序特性进行优化 |
ops-nn仓库通过提供这些基础算子的高性能实现,为AIGC模型的推理加速提供了坚实基础。开发者可以基于这些算子快速构建和优化AIGC模型,而不需要从零开始开发每个算子。
六、未来展望:CANN算子生态的发展
CANN算子共建仓(cann-ops)已经正式上线Gitee社区,这是国内首个面向昇腾开发者的算子共建平台。通过这一平台,开发者可以:
- 零门槛学习:算子源码开放共享,开发者可以直接获取学习参考
- 创新技术共享:鼓励开发者分享在算子上的优化、创新成果
- 丰富的社区项目:CANN训练营、算子挑战赛、众智计划等专题活动
目前,昇腾已联合互联网、运营商、大模型厂商等20+客户伙伴创新孵化出200多个高性能算子,实现技术创新和商业落地的双重突破。
未来,CANN算子生态的发展将聚焦于以下几个方面:
- 大模型融合算子:针对大模型(如GPT、DeepSeek)的特殊需求,开发专门的融合算子,提高推理效率
- 领域专用加速库:开发针对特定领域的加速库(如ATB、SiP),提供更高层次的抽象
- 异构计算协同:实现GPU和NPU的统一管理和调度,屏蔽底层硬件差异,确保不同架构的处理器无缝协作
- 自动化算子开发:结合AI技术,实现算子开发的自动化和智能化,进一步降低开发门槛
结语
CANN算子库(特别是ops-nn仓库)为AIGC模型的加速提供了强大的底层支持。通过深入理解CANN的算子开发流程和优化技术,开发者可以充分发挥昇腾硬件的性能优势,构建高效、可靠的AIGC应用。
随着CANN开源生态的不断完善,越来越多的开发者将参与到算子共建的行列中,共同推动AI根技术的发展。从“跟随”走向“引领”,CANN算子生态正在为中国的AI产业发展注入新的活力。
参考资料:
- 华为CANN官方文档
- ops-nn仓库源码
- Ascend C算子开发指南
- CANN训练营课程材料
- 异构计算资源管理创新技术

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 14
14 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)