
Transformer基础
作者:昇腾实战派 * 电子咸鱼Transformer 架构是一种基于自注意力机制(Self-Attention)的深度神经网络模型,该架构彻底摒弃了传统序列建模中依赖循环结构的设计范式,实现了对输入序列的全局并行化建模,显著提升了训练效率与模型表达能力。相较于循环神经网络(RNN)及其变体(如 LSTM、GRU)在处理长序列时存在的序列依赖瓶颈与梯度传播。
Transformer基础
多模态体系知识地图
关注公众号:AI模力圈
作者:昇腾实战派 * 电子咸鱼
Transformer 架构是一种基于自注意力机制(Self-Attention)的深度神经网络模型,该架构彻底摒弃了传统序列建模中依赖循环结构的设计范式,实现了对输入序列的全局并行化建模,显著提升了训练效率与模型表达能力。相较于循环神经网络(RNN)及其变体(如 LSTM、GRU)在处理长序列时存在的序列依赖瓶颈与梯度传播难题,Transformer 通过自注意力机制实现对任意位置词元之间依赖关系的高效建模,从而在机器翻译、文本生成、文本摘要等多个自然语言处理任务中展现出卓越性能。如今,Transformer 已成为现代大规模语言模型的核心架构基石,广泛应用于 GPT、BERT、T5、PaLM 等代表性模型体系中。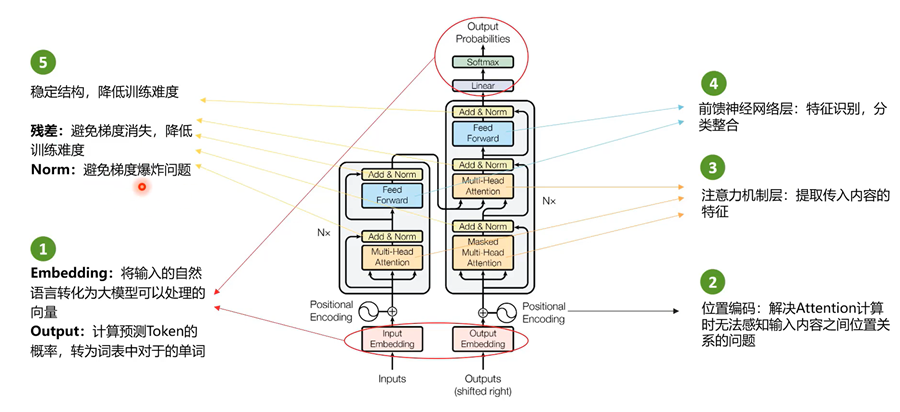
1. 词嵌入&位置编码
Embeddings(嵌入/投影层)
功能:将输入中的单词(或 token)转换成数字向量。给每个单词分配一个独有的ID(包含语义信息)。
Positional Encoding(位置编码)
由于Transformer没有循环结构,需要显式地注入位置信息。正弦位置编码公式如下(偶数维度(2i)& 奇数维(2i+1)):
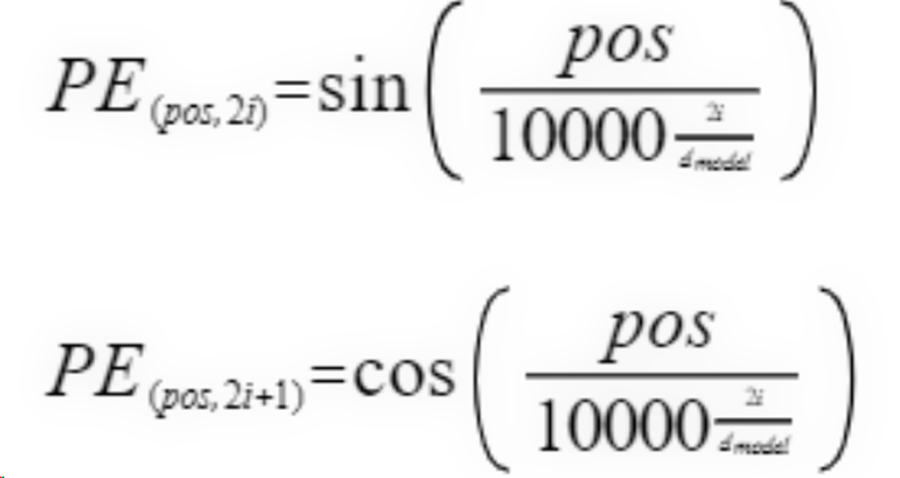
参数说明:pos是词在序列中的位置(如第 1 个词、第 2 个词等);i是位置编码向量的维度索引(0<=i<dmodel/2);dmodel是位置编码的维度(通常与词向量的维度相同,如 512、768 等)。
词嵌入与位置编码相加,而不是拼接,两者效率差不多,但是拼接的话维度会变大。
位置编码的特点:
· 相对位置敏感:可以学习到相对位置关系;
· 长度可扩展:可以处理比训练时更长的序列;
· 确定性:不需要学习,直接计算得到。
2. 编码器Encoder
编码器结构: “多头注意力 → 层归一化+残差连接 → 前馈网络 → 层归一化+残差连接 ” 的顺序堆叠在每个编码器层中。每个编码器层都包含MHA 和 FFN两个子层,且每个子层都有自己的残差连接与层归一化。整体结构遵循“先子层归一化,再残差连接”的设计。
| 组件 | 功能描述 |
|---|---|
| 多头注意力(MHA) | 将输入序列映射到多个不同的表示子空间,分别计算注意力权重,捕捉不同位置之间多样化的语义关系(如主谓、修饰等),提升模型对复杂依赖关系的建模能力。 |
| 前馈网络(FFN) | 对每个位置的表示进行独立的非线性变换,增强模型的特征表达能力。通常由两层全连接层和一个激活函数(如ReLU)构成,用于提取局部特征。 |
| 残差连接(Residual Connection) | 在每一层的输出中加入输入值(即x + sublayer(x)),帮助梯度在深层网络中更顺畅传播,缓解深层网络中的梯度消失问题,提升训练稳定性。 |
| 层归一化(Layer Normalization) | 对每个样本在特征维度上进行归一化(均值为0,方差为1),稳定各层输入分布,加速训练收敛,减少对初始化的敏感性。 |
3. 解码器Decoder
解码器结构通常为:掩码多头注意力 → 残差连接 + 层归一化 → 编码器-解码器注意力 → 残差连接 + 层归一化 → 前馈网络 → 残差连接 + 层归一化。解码器在编码器基础上增加了:
| 组件 | 功能描述 |
|---|---|
| 掩码多头注意力(Masked Multi-Head Attention) | 在解码过程中,限制当前时刻只能关注之前已生成的词(即“过去和现在”),禁止查看未来的token信息。通过添加 因果掩码实现,确保自回归生成的合理性,防止信息泄露,是实现逐词生成的关键。 |
| 编码器-解码器注意力(Cross-Attention) | 让解码器在生成每个输出词时,动态地“聚焦”于编码器输出的源语言上下文信息,对齐输入与输出序列。它将解码器的查询(Query)与编码器的键(Key)和值(Value)进行注意力计算,使解码过程能够有效融合源句语义,提升翻译准确性。 |
4. 注意力机制Attention
思想「从关注全部到关注重点」
在一个句子中,先计算出第一个字与句子中的每一个字的注意力分数(包括第一个字),再用计算出的注意力分数乘以对应字的信息,然后加在一起,得到的结果就是第一个字与句子中所有字的加权和,依次更新每一个字与句子的注意力信息。
4.1 自注意力机制Self-attention
自注意力的计算
Step1: 计算得到查询向量、键向量和值向量:
对输入文字进行Embedding(词嵌入)得到词向量,词向量进行位置信息编码后将词向量与位置信息相加,得到含有位置信息的词向量,作为自注意力层的输入。
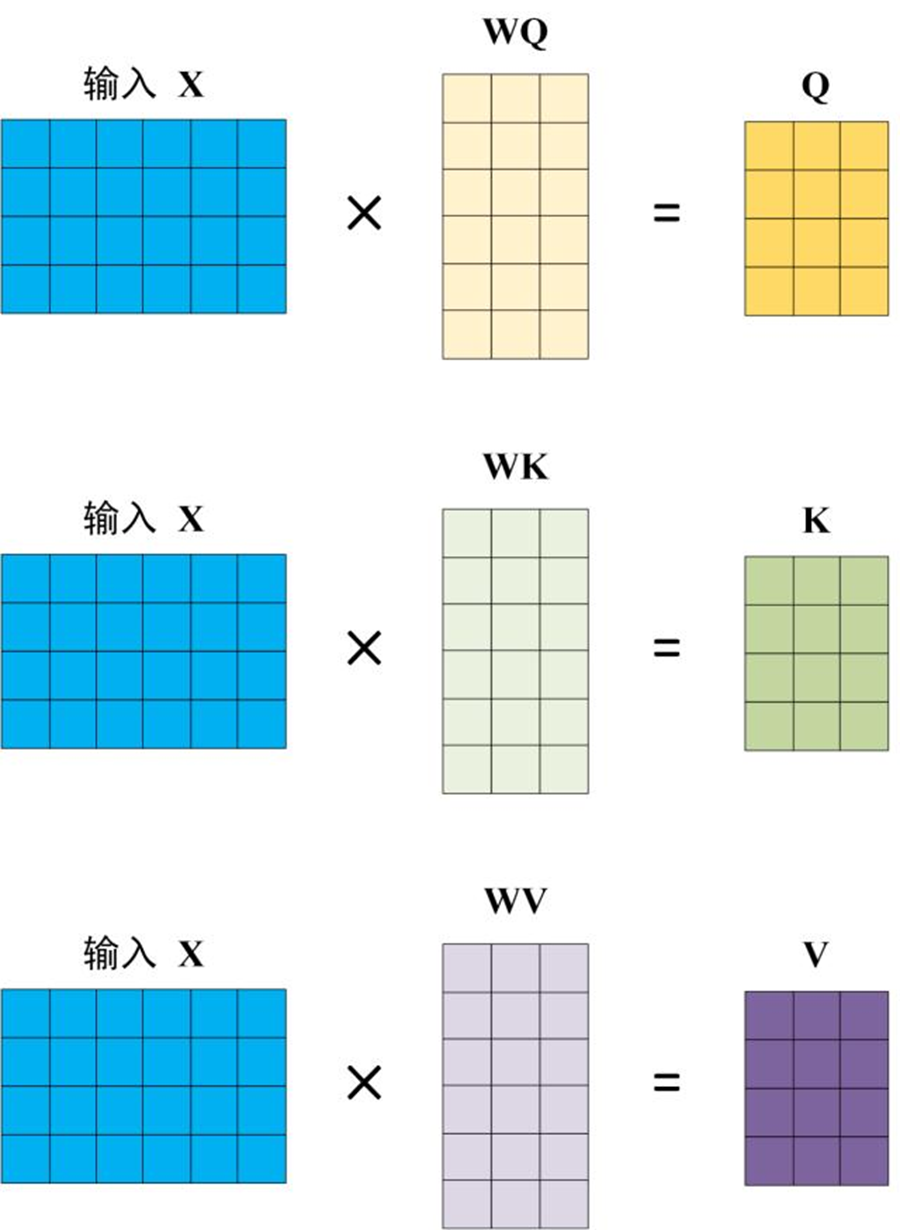
词向量可以理解为一句话中第i个字的词向量,将词向量分别乘以WQ、WK、WV三个矩阵,得到查询向量Q、键向量K和值向量V。(可以理解成词的“查询”向量; k 可以理解词的“被查”向量; v 可以理解成词的“内容”向量)。
Step2:计算注意力得分:

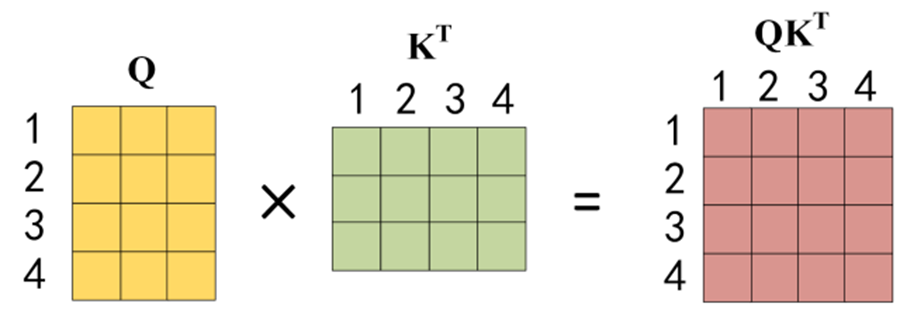
公式中计算矩阵Q和K每一行向量的内积,为了防止内积过大,因此除以 dk 的平方根。Q乘以K的转置后,得到的矩阵行列数都为 n,n 为句子单词数,这个矩阵可以表示单词之间的 attention 强度。下图为Q乘以 KT ,1234 表示的是句子中的单词。
假设要计算句子中第一个词的注意力得分,需要用句子中每个单词对第一个单词打分,通过第一个单词的查询向量q0与句子中所有词的键向量k点积运算得到。
假设句子中有4个词, 用q0分别乘以 k0,k1,k2,k3 (对应坐标相乘相加),得到4个常数 a00,a01,a02,a03注意力值。
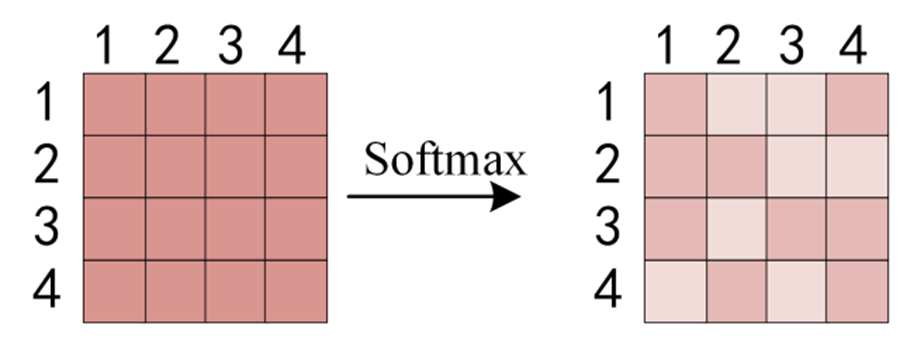
得到QKT 之后,使用 Softmax 计算每一个单词对于其他单词的 attention 系数,公式中的 Softmax 是对矩阵的每一行进行 Softmax,即每一行的和都变为 1。再把4个数经过Softmax,得到第0个字与句子中所有字的注意力分数 a00’,a01’,a02’,a03’ 。softmax的作用是使所有单词的分数归一化,得到的分数都是正值且和为1。
Step3:对加权向量求和,得到 Softmax 矩阵后与V相乘,得到最终的自注意力输出Z。
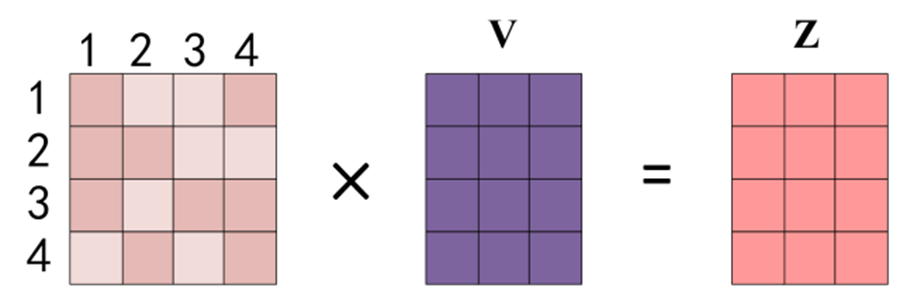
用注意力分数乘以词的值向量v0,v1,v2,v3 ,得到第0个字与句子中所有字加权信息b0, 同样的计算得到第2、3、4个词的所有注意力信息b1、b2、b3。
4.1.1 多头注意力Multi-Head Attention(MHA)
Multi-Head Attention 是由多个 Self-Attention 组合形成
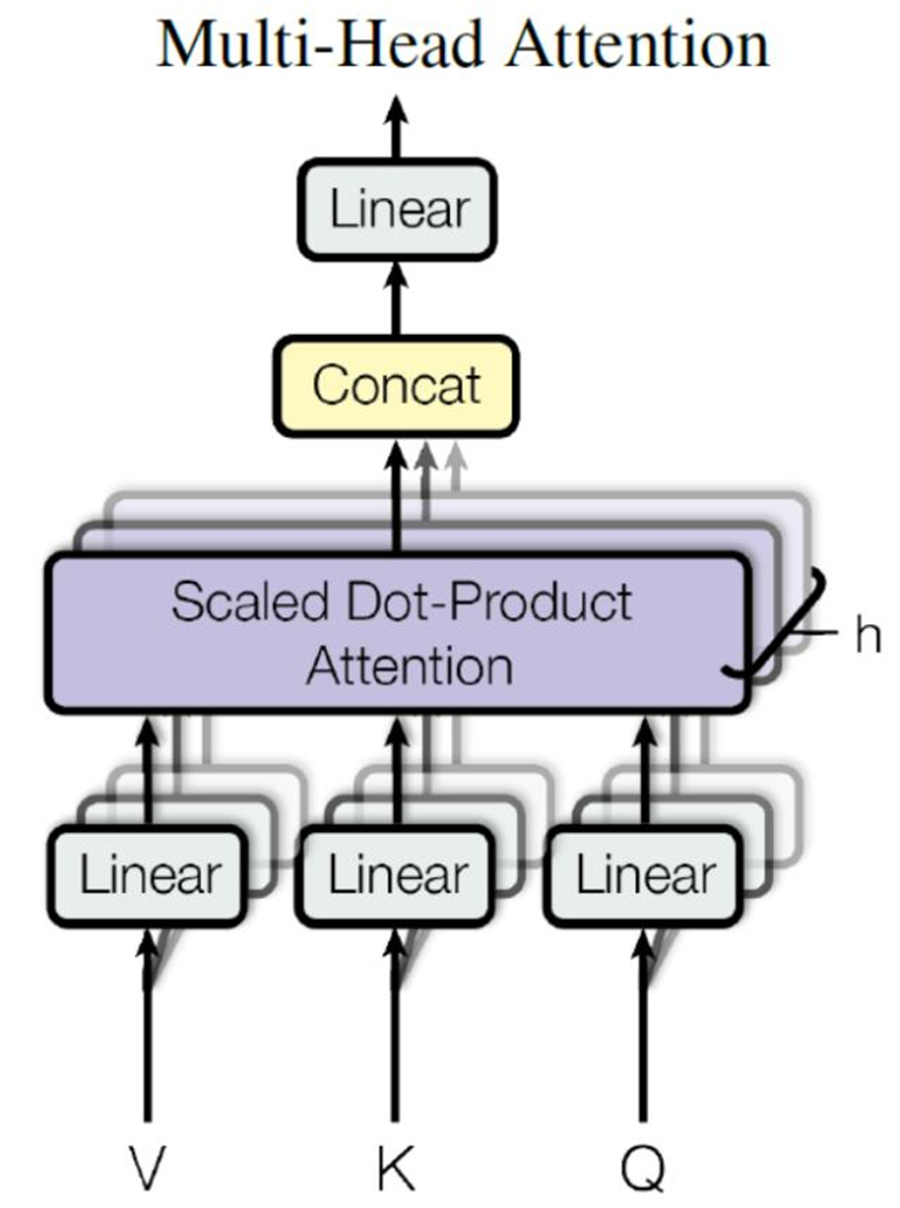
从上图可以看到 Multi-Head Attention 包含多个 Self-Attention 层,首先将输入X分别传递到 h 个不同的 Self-Attention 中,计算得到 h 个输出矩阵Z。
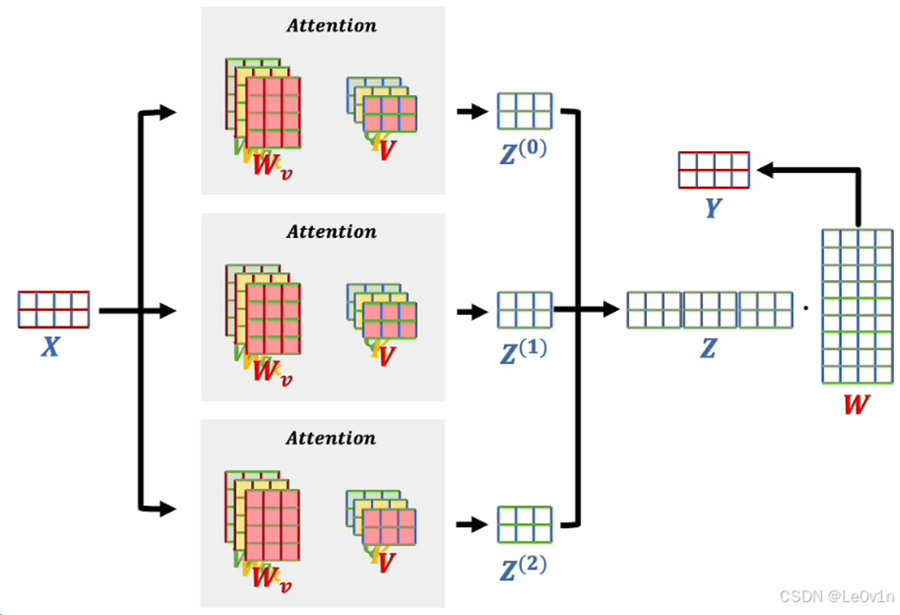
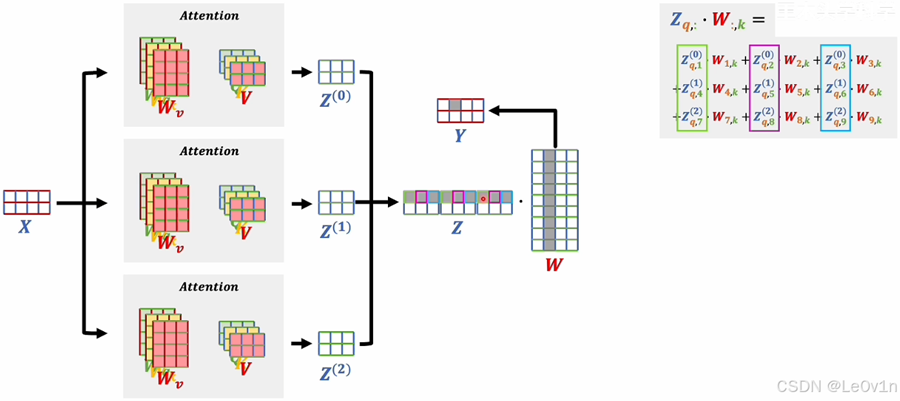
输入数据X是两个词向量组成的矩阵,之前我们在介绍注意力机制的时候,输入数据只经过一个注意力机制,计算出一个得分矩阵A ,而在多头注意力机制中,输入数据会经过多个注意力机制(多头注意力机制中的参数是独立的),得到3个得分矩阵A;之后把三个结果拼接在一起形成一个大矩阵,这个大矩阵的行数和输入的词向量个数相同,列数是单个注意力输出的维度×头的个数。得到大矩阵之后还会和一个W矩阵相乘,最后得到输出的词向量。
🤔 𝑸𝒖𝒆𝒔𝒕𝒊𝒐𝒏:多头注意力的形式看起来比较简单,但这么做有什么意义呢?为什么要分别计算再拼接在一起,而不是直接就使用一个9维的矩阵进行训练呢?
🥳 𝑨𝒏𝒔𝒘𝒆𝒓:下图对计算过程进行了分组(绿、红、蓝),这里的分组其实是按照词向量的维度进行分组的,词向量的维度某种程度上可以理解为是通道(图片的RGB通道是类似的)。现在因为有3个头,所以每个头计算出来的结果都会有3个维度。对于三个结果的第一个维度,如果定性的去想,那么它们在语义上应该是比较接近的,那么把语义解决的维度组成一组是比较合理的想法。那么一旦组成一组后,我们就可以理解为这个维度是在多头的情况下的一个比较综合的语义。其它维度也是类似的,因为输入的词向量有三个维度,所以3个头最后综合起来的三个维度就可以理解为图片里的RGB三个通道。那么这三个通道经过一个系数相乘后在相加就会得到一个具体的值。
𝑸𝒖𝒆𝒔𝒕𝒊𝒐𝒏:多头注意力机制和卷积核它们的差别是什么?
🥳 𝑨𝒏𝒔𝒘𝒆𝒓:卷积核在计算的时候基本上只能是基于中心的几圈,但多头注意力机制就不再局限于一个中心的周围了,而是可以跨越无穷远的地方。
4.1.2 分组查询注意力Grouped Query Attention(GQA)
GQA(Grouped Query Attention)是一种注意力机制,介于MHA(Multi-Head Attention)和MQA(Multi-Query Attention)(n个Query头分别和同一份 、K、V 进行attention计算)之间,旨在结合两者的优点,以实现在保持MQA推理速度的同时接近MHA的精度。
GQA作为MHA和MQA的折中方案,它将查询头(query heads)分组,每组共享一个键和值,而不是所有头都共享。这样,GQA能够在减少计算量的同时,保持更多的多样性,从而在推理速度和模型精度之间取得平衡 。
GQA-1:分成一个单独的组,等同于 Multi-Query Attention (MQA)。
GQA-H:组数等于头数,基本上与 Multi-Head Attention (MHA) 相同。
GQA-G:一个中间配置,具有G个组,平衡了效率和表达能力。
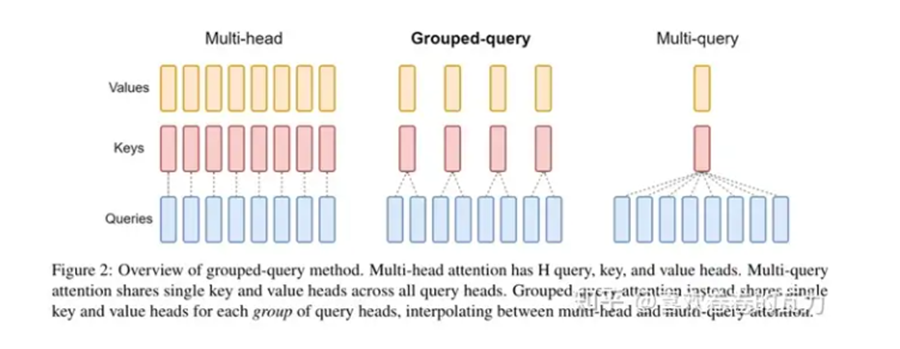

在llama2/3-70B中,GQA的g=8,其他用了GQA的同体量模型基本上也保持了这个设置。根据推理效率的考虑,70B体量的模型,除非进行极端的量化,不然不可能部署到单卡(A100/H100 80G)上。单卡不行,那么就能单机了,在一机8卡的情况下,Attention的每个Head实际上是独立运算然后拼接起来的,当g=8时,正好可以每张卡负责计算一组K、V对应的Attention Head,这样可以在保证K、V多样性的同时最大程度上减少卡间通信。
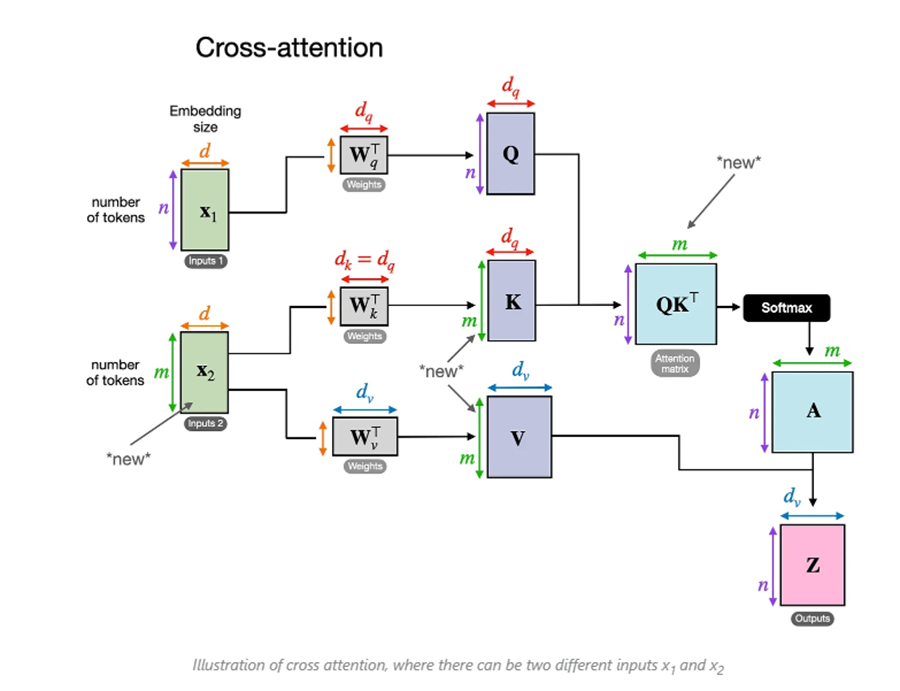
4.2 交叉注意力机制Cross-attention
Cross Attention,顾名思义,是一种“交叉”的注意力机制。与 Self-Attention 不同,Self-Attention 是让一个序列自己内部的元素相互关注(比如一个句子中的单词互相计算关系),而 Cross Attention 则是让两个不同的序列(或者数据来源)之间建立关注关系,允许一个序列(称为 Query,查询)去关注另一个序列(称为 Key 和 Value,键和值),从而实现信息的融合。
Transformer结构中Multi-Headed Cross-Attention 多头交叉注意力
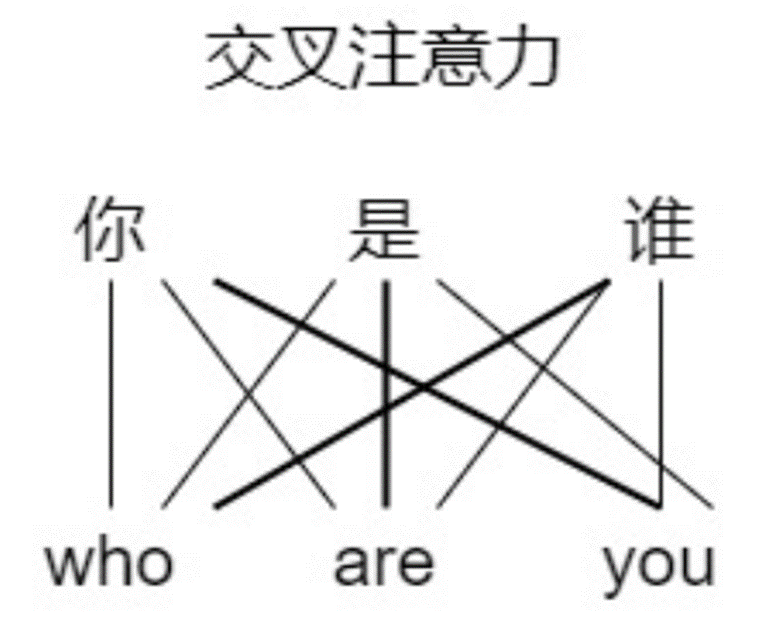
● 作用:让解码器询问编码器:“关于输入,我应该重点关注什么?”
● 场景:翻译任务中,解码器生成英文时,会参考编码器处理的中文输入。
Transformer中的多头编码器-解码器注意力(cross-attention)中的K,V矩阵不是上一个解码器的输出计算出来的,而是使用编码器输出的信息矩阵。在解码器中看不到后面的词的信息,但是利用cross-attention可以在编码器和解码器之间传递信息。(此阶段的查询向量V,分别与编码器输出的键值向量K、值向量V做计算。)
🤔 𝑸𝒖𝒆𝒔𝒕𝒊𝒐𝒏:自注意力、交叉注意力、多头注意力有什么区别?
🥳 𝑨𝒏𝒔𝒘𝒆𝒓:
自注意力:输入是一个X,这个X 会生成Q , K , V 三个矩阵,最终再生成注意力得分矩阵A ,之后注意力得分矩阵A 再和V VV进行矩阵乘法得到加权后的输出
多头注意力:就是多个自注意力,得到的结果会进行拼接和矩阵运算,最终得到多头注意力的得分矩阵,之后注意力得分矩阵再和W进行矩阵乘法得到加权后的输出
交叉注意力:输入是两个X 1 和X 2 ,其中X 1 负责生成Q矩阵,X 2 负责生成K , V矩阵,最终再生成注意力得分矩阵A之后注意力得分矩阵A 再和V 进行矩阵乘法得到加权后的输出
4.3 掩码MASK
在解码器(Decoder)中会有一个Masked Multi-Head Attention(带有掩码的多头注意力机制),为什么要给多头注意力机制添加掩码呢?这是因为在推理的时候,解码器部分是一个词一个词生成的,这也就说明,当模型生成到某个词的时候,这个词按理来说只应该受到之前词的影响,不应该被未来生成的词所影响。
前面说过注意力机制生成的得分矩阵是可以表示一个词和所有上下文之间的关系的,这个上下文针对模型生成的词而言,既包含了之前的词,也包含了之后的词,但是不想让生成的词被未来会生成的词所影响,所以需要添加一个掩码,即给注意力得分中的某些部分屏蔽掉,如下图所示:

屏蔽的方法就是在特定的位置上分别加上一个无穷小,这样在进行逐行的Softmax计算时,这些被屏蔽的地方的分数为0。
Masked Multi-Head Attention
Decoder block 的第一个 Multi-Head Attention 采用了 Masked 操作,因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。 在预测第 i 个输出时,就要将第 i+1 之后的单词掩盖住。注意 Mask 操作是在 Self-Attention 的 Softmax 之前使用的, 在得到 QKT 之后需要进行 Softmax,计算 attention score,在 Softmax 之前需要使用Mask矩阵遮挡住每一个单词之后的信息,Masked矩阵的大小与目标序列大小相同,遮挡操作如下:
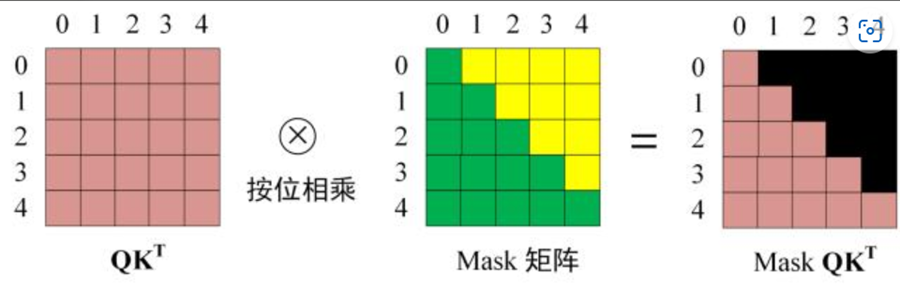
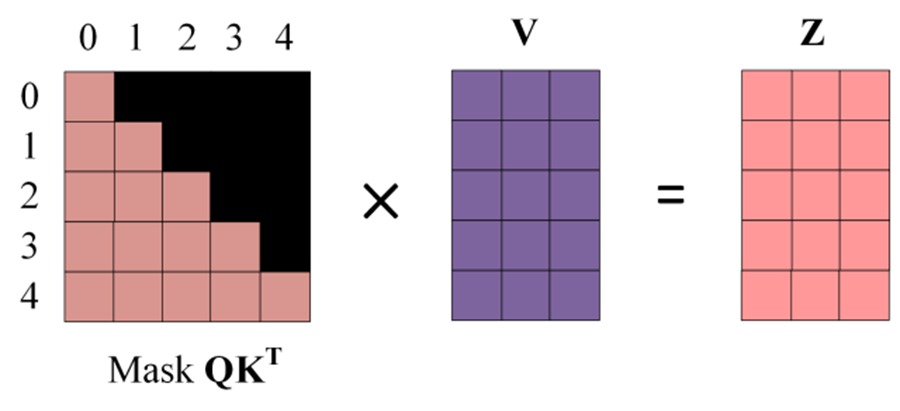
得到 Mask QKT之后在 Mask QKT上进行 Softmax,每一行的和都为 1。 使用 Mask QKT与矩阵 V相乘,得到输出 Z,则单词 1 的输出向量 Z1 是只包含单词 1 信息的。
关于第一次输入的补充
从上面分析可以得知多个Encoder和多个Decoder是顺序执行的,即后一个Encoder和Decoder的输入是前一个Encoder和Decoder的输出,但第一个Encoder和Decoder的输入是怎样的呢。 这要分为训练阶段和推理应用阶段,以“我爱你”和“I love you”举例说明。
训练阶段 此时训练集中有一组数据是“我爱你”对应“I love you”,则此时第一个Encoder的输入为“我爱你”对应的词嵌入矩阵,第一个“Decoder”的输入为“I love you”的词嵌入矩阵。
推理应用阶段 第一个Encoder的输入仍然为源序列“我爱你”的词嵌入矩阵,而第一个Decoder的输入为表示句子开始的特殊字符“[bos]”对应的词嵌入矩阵。
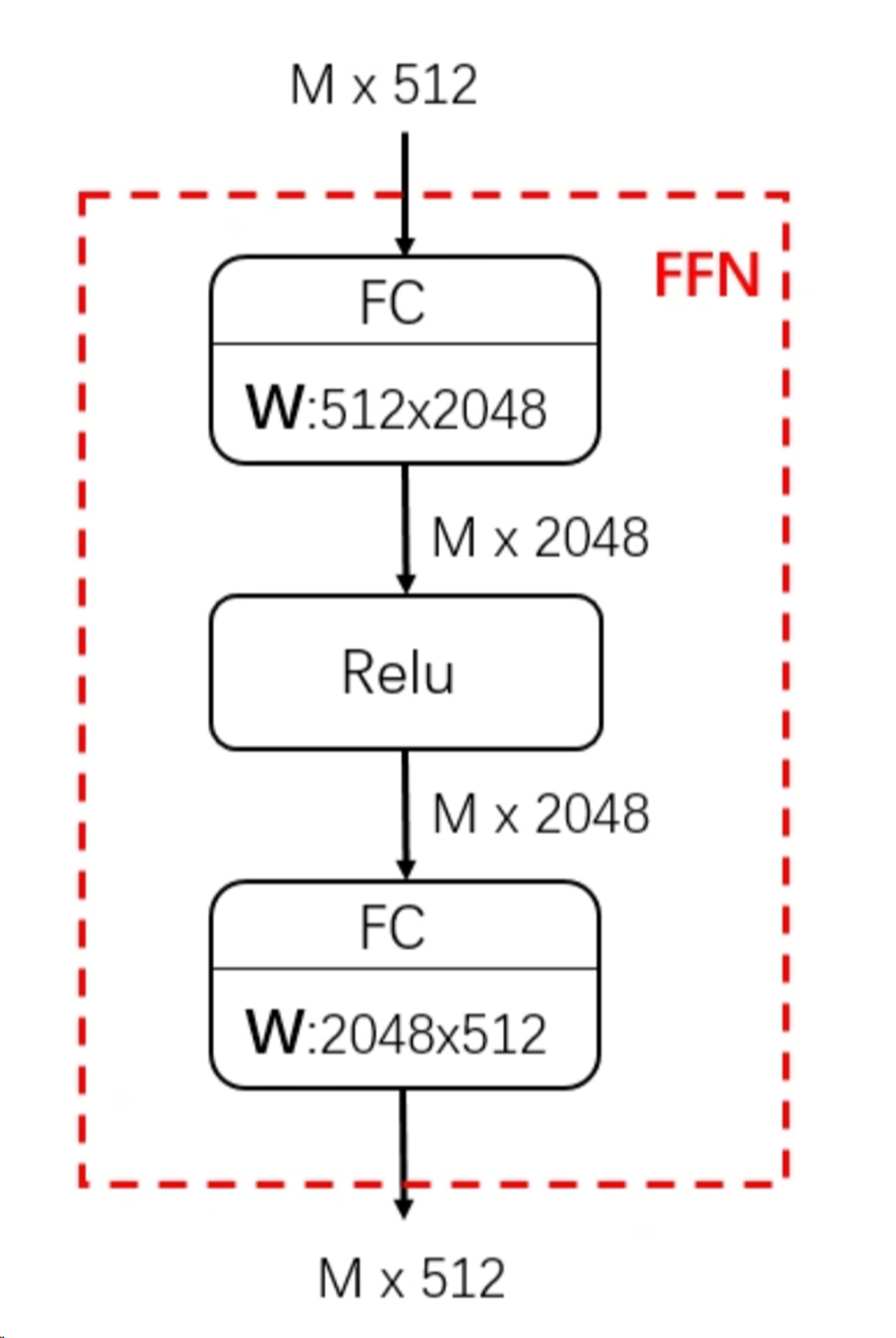
5. 前馈网络FFN
由两个线性变换层和一个非线性激活函数组成 :先用一个线性层将维度扩大,再relu,再用一个线性层将维度缩回原状。因为同一个数据是由多种信息叠加起来的,可以理解为先把大块信息拆成小块,然后relu,然后再把信息拼装回去,以提升relu的细粒度。
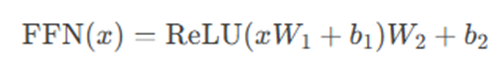
其中 x 是自注意力层的输出,形状为 [batch_size , seq_len, d_model],
W1和W2是可学习的权重矩阵,维度通常为 [d_model, d_ff] 和 [d_ff, d_model];b1 和 b2 是偏置项。
ReLU 是激活函数(部分变体使用GELU,如BERT)
作用:
(1) 引入非线性表达能力:自注意力层本质上是线性变换(加权求和)的堆叠,FFN通过激活函数(如ReLU)为模型注入非线性,使其能够拟合更复杂的函数。
(2) 特征空间变换与信息整合
● 升维与降维:FFN先将输入映射到高维空间(如 d_model=512 → d_ff=2048),再压缩回原始维度,输出的512维比输入的512维具有更加丰富和准确的特征表示。
● 跨维度交互:自注意力主要处理序列内 token 之间的关系,而FFN在特征维度(d_model)上混合信息,补充自注意力的不足。
(3) 缓解自注意力的局限性
● 自注意力层对局部细节(如词序、短语结构)的捕捉较弱,FFN通过逐位置(position-wise)操作增强局部模式的建模能力。
● 逐位置特性:FFN对序列中的每个 token 独立处理(但参数共享),类似卷积的“1x1卷积”操作。
如果你对多模态大模型、强化学习、昇腾 NPU 部署、模型性能优化感兴趣,欢迎持续关注【AI模力圈】。
我们会持续更新:
- 多模态模型结构拆解
- 强化学习算法原理与实践
- 昇腾 NPU 迁移部署与踩坑复盘
- 模型训练与推理性能优化
图解版、速读版内容也会同步更新到公众号 / 小红书。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)