
收藏不亏!后端工程师转型AI大模型完整学习路径:薪资暴涨47%的核心秘诀
推理优化突破:关注投机解码、注意力优化算法(如FlashAttention),持续降低推理成本;软硬件协同:了解CUDA生态、专用AI芯片(如英伟达H100、华为昇腾),优化架构与硬件的适配性;多模态系统:掌握文本、图像、语音的统一处理管道,设计跨模态数据交互架构。为什么越来越多后端工程师选择转型AI大模型?供需缺口大、薪资溢价高、技能适配性强。智联招聘2025年Q1最新数据印证了这一趋势:AI领
你是否发现:近期的技术评审会、架构研讨中,“AI原生应用”早已从概念沦为高频热词?你深耕多年的RESTful接口,正被迫适配流式响应以匹配大模型的token逐段生成逻辑;你熟稔的Kafka消息管道,流转的数据不再只有用户行为日志,更充斥着向量化知识片段、模型推理请求等新型数据形态?
这绝非技术领域的小幅波动,而是软件工程范式的颠覆性变革。作为后端工程师,你正站在AGI(通用人工智能)革命的核心阵地——无需转型为AI研究员,因为AI系统的落地落地,恰恰需要你这样具备工程化思维的架构设计者。
一、为何后端工程师是AI工程化落地的核心支柱?
在开启学习之旅前,先看一组猎聘网2024-2025年的最新行业数据,直观感受转型价值:
- AI系统架构师平均薪资较传统后端架构师高出47%,部分大厂资深岗位年薪突破80W+;
- 招聘需求中明确要求“AI工程化能力”的后端岗位,同比增幅达213%,头部企业更是将其列为必备技能;
- 同时掌握分布式系统设计与大模型部署能力的工程师,面试邀请率是普通后端的3.2倍,Offer议价权显著提升。
你的后端技术积累从不是转型负担,而是通往AI领域的“加速器”,核心优势体现在四大维度:
1. 规模化系统思维的天然适配
日常深耕微服务拆分、数据一致性保障、高并发场景扩容的你,早已将“规模化思维”刻入工作习惯。大模型服务本质是一类新型分布式系统,拥有独特的负载波动(如峰值推理请求)、资源消耗特征(GPU算力依赖)及故障场景(token生成中断),而你的后端经验能直接迁移解决这些问题。
2. 性能与成本平衡的实战经验
优化数据库查询效率、设计多级缓存策略、选型性价比实例的后端工作,本质是“在有限资源下实现性能最大化”。这一能力直接对应AI时代的核心挑战——推理成本控制:如何在保证响应延迟、吞吐量的前提下,降低GPU算力消耗,正是生产级AI应用落地的关键,也是后端工程师的核心竞争力。
3. 数据处理能力的无缝迁移
ETL流程搭建、数据清洗去重、流水线自动化设计,这些后端日常工作,正是机器学习中特征工程与数据预处理的工程化落地版本。你比AI研究员更懂数据从原始形态到可用状态的转化逻辑,也更清楚如何适配大规模数据场景。
4. 系统集成与API设计的核心优势
大模型无法孤立运行,必然需要与现有业务系统、数据库、第三方服务集成。你在API契约设计、认证授权、版本兼容管理上的经验,是实现AI能力产品化的核心前提,能快速将模型能力封装为业务可用的服务。
二、阶段一:认知重构与基础奠基(1-2个月)
目标:从“AI工具使用者”升级为“AI系统思考者”
第一周:拆解AI技术栈,建立工程师视角认知
跳出媒体渲染的AI神话,从工程化角度拆解AI技术栈分层,明确自身定位与学习重点:
应用层:AI增强型业务应用(后端工程师当前业务场景)
API层:模型服务化接口(后端核心攻坚领域,可复用API设计经验)
运行时层:推理引擎/框架(需重点学习的新领域,如vLLM、Triton)
模型层:基础模型/微调模型(无需深耕,理解核心逻辑即可)
硬件层:GPU/专用AI芯片(了解算力约束,辅助架构选型)
行动清单(附实操细节):
- 精读OpenAI、Anthropic API文档,重点关注速率限制、token计数规则、成本核算逻辑,记录3类常见异常(如token超量、流式中断)的处理方案;
- 在Postman中完成3类AI API调用实战:文本生成(OpenAI GPT-4)、语义理解(智谱AI)、多模态生成(阿里云通义千问),对比接口设计差异与响应格式;
- 用Python写简易token成本计算器,支持按模型类型(GPT-3.5/GPT-4)、请求长度估算调用费用,集成基础缓存逻辑避免重复计算。
第二至四周:聚焦实用数学基础,搭建直觉认知
后端工程师无需深究数学理论证明,核心是建立“可落地的数学直觉”,适配模型相关的工程化工作:
- 线性代数核心:掌握矩阵乘法、转置、张量重塑,理解模型权重存储与激活值计算逻辑,这是后续理解模型推理流程的基础;
- 概率与统计实战:重点突破条件概率、最大似然估计,能评估模型输出的可信度,为业务决策提供依据;
- 微积分应用:直观理解梯度下降核心思想,无需推导公式,只需知道其是模型训练、参数优化的核心逻辑即可。
工程化学习法(用后端语言落地数学概念):
# 用NumPy模拟模型前向传播,类比后端多维数据处理
import numpy as np
# 模型权重类比后端服务的配置参数矩阵(规模放大后即大模型权重)
weights = np.random.randn(1000, 1000) # 简化版模型权重矩阵
activations = np.random.randn(1000, 1) # 输入数据(类比请求参数)
# 前向传播本质是矩阵运算,与后端数据转换逻辑高度相似
output = np.dot(weights.T, activations) # 模拟模型生成输出
print(f"输出维度:{output.shape}") # 理解张量维度变化,适配后续服务封装
第五至八周:深耕Python生态,扩展工程工具包
并非从零学习Python,而是基于后端经验,补充AI领域必备的Python工具与框架,实现技能迁移:
- 核心能力补充:异步编程(asyncio,适配模型流式响应)、类型提示(Type Hints,提升代码可维护性)、虚拟环境管理(Poetry,解决依赖冲突);
- AI专用库:优先掌握PyTorch(工程化场景更友好)、Hugging Face Transformers(快速调用开源模型),了解TensorFlow基础语法;
- 工程化工具:Pydantic(数据校验,类比后端请求参数校验)、FastAPI(快速构建模型服务,支持异步与Swagger文档)。
迁移学习项目(高落地性):将Java/Go服务改造为AI增强服务
# 案例:将传统用户认证服务,升级为“意图识别+认证”双功能服务
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from transformers import pipeline
from datetime import datetime
import jwt # 保留后端原有认证逻辑
app = FastAPI(title="AI增强型用户服务")
# 初始化模型(类比后端初始化数据库连接池,添加异常捕获)
try:
classifier = pipeline("text-classification",
model="distilbert-base-uncased-finetuned-sst-2-english",
device=-1) # 无GPU时用CPU,适配本地开发
except Exception as e:
raise RuntimeError(f"模型初始化失败:{str(e)}")
# 定义请求模型(Pydantic校验,类比后端DTO)
class UserRequest(BaseModel):
text: str
user_id: str
token: str
# 原有认证逻辑封装(保留后端核心能力)
def verify_token(token: str) -> bool:
try:
jwt.decode(token, "secret_key", algorithms=["HS256"])
return True
except jwt.ExpiredSignatureError:
return False
@app.post("/analyze-intent")
async def analyze_intent(req: UserRequest):
# 1. 保留原有认证逻辑
if not verify_token(req.token):
raise HTTPException(status_code=401, detail="Token失效")
# 2. 新增AI意图识别能力
result = classifier(req.text)[0]
# 3. 组合返回结果(适配业务需求)
return {
"user_id": req.user_id,
"intent": result["label"],
"confidence": round(result["score"], 4),
"processed_at": datetime.now().isoformat(),
"is_auth": True
}
三、阶段二:深度学习系统化掌握(3-4个月)
目标:穿透模型黑盒,理解AI系统内部工作逻辑
第一月:数据处理→特征工程,迁移后端数据能力
将后端ETL、数据管道经验,转化为机器学习场景下的特征工程能力,打通数据到模型的链路:
- 特征工程核心:本质是“模型可理解的API设计”,需掌握特征提取、归一化、编码(如One-Hot、Embedding),适配不同模型输入需求;
- 数据版本控制:用DVC(Data Version Control)管理数据集,类比Git版本控制,解决“数据溯源、多版本对比”问题;
- 大规模数据处理:用Spark处理机器学习数据集,复用后端大数据处理经验,适配百万级样本场景。
后端视角解读神经网络(降低理解门槛):
神经网络层 ≈ 微服务节点(各司其职,负责特征转换)
激活函数 ≈ 服务间协议转换器(将前一层输出转为下一层可处理格式)
反向传播 ≈ 分布式系统错误追溯(定位参数问题,类似服务故障排查)
训练循环 ≈ CI/CD流水线(反复迭代优化,直至达到预期效果)
第二月:PyTorch深度实践,用架构思维设计模型
以后端微服务设计思路学习PyTorch,聚焦工程化落地而非理论研究:
- 张量操作:类比后端内存数据结构,掌握张量创建、切片、拼接,理解GPU加速原理;
- 自动微分:理解为“智能回溯系统”,无需手动计算梯度,重点掌握反向传播触发条件与梯度清零逻辑;
- 模块化设计:像拆分微服务一样拆分神经网络模块(如卷积层、全连接层),提升代码复用性与可维护性。
实践项目:传统推荐系统后端AI升级
将协同过滤推荐系统,升级为神经协同过滤(NCF)系统,完整覆盖“模型训练→服务化→线上对比”全流程:
- 用PyTorch实现神经协同过滤模型,加载公开数据集(如MovieLens)完成训练与评估;
- 将模型封装为gRPC服务(高并发场景优选),定义请求/响应协议,添加超时重试机制;
- 搭建A/B测试框架,对比新旧推荐算法的点击率、留存率,支持流量动态分配;
- 实现模型热更新机制,类比后端服务热部署,避免服务中断。
第三月:吃透Transformer架构,掌握AI时代“通信协议”
Transformer是现代大模型的核心架构,如同AI时代的“TCP/IP协议”,后端工程师需深入理解其工程化逻辑:
- 自注意力机制:类比“智能路由协议”,每个token可直接关联上下文相关token,理解多头注意力的并行处理逻辑;
- 位置编码:解决序列数据的时序依赖问题,类似后端分布式日志的时间戳,确保模型捕捉文本顺序信息;
- 预训练与微调:基础模型如同操作系统,微调如同安装业务专用应用,掌握LoRA微调(低资源高效微调)的工程化实践。
工程化解读Transformer核心模块:
# 简化版Transformer块,类比后端服务调用链
class TransformerBlock:
def __init__(self, d_model: int, nhead: int):
# 多头注意力:类比负载均衡器,并行处理多维度特征
self.attention = MultiHeadAttention(d_model=d_model, nhead=nhead)
# 前馈网络:类比无状态服务,独立处理每个位置特征
self.feed_forward = FeedForward(d_model=d_model)
# 残差连接:类比服务降级策略,确保信息不丢失,提升模型稳定性
self.residual = ResidualConnection(dropout=0.1)
# 层归一化:类比数据标准化,避免梯度消失/爆炸
self.norm = LayerNormalization(d_model=d_model)
def forward(self, x, mask=None):
# 服务调用链:注意力计算 → 残差合并 → 前馈处理 → 最终输出
attn_output = self.attention(x, x, x, mask=mask)
x = self.residual(x, self.norm(attn_output))
ff_output = self.feed_forward(x)
return self.residual(x, self.norm(ff_output))
第四月:拥抱大模型生态,掌握开源模型选型与优化
- 开源模型选型:对比LLaMA 3、ChatGLM 4、Qwen 2等主流模型的架构差异、算力需求、中文支持度,建立选型决策框架(如中小场景选Qwen,高性能需求选LLaMA 3);
- 模型格式与运行时:掌握GGUF(本地部署优选)、AWQ/GPTQ(量化压缩格式),理解不同格式的推理速度与精度权衡;
- 推理优化入门:应用后端性能优化经验,实践模型量化(INT8/INT4)、剪枝,降低算力消耗。
四、阶段三:AI工程化与系统集成(3-4个月)
目标:构建生产级可用的AI系统,实现端到端落地
第一月:模型服务化部署,复用分布式系统经验
将模型视为“特殊微服务”,用后端分布式架构经验,解决模型部署的扩展、容错问题:
- 模型即服务(MaaS):封装模型为HTTP/gRPC服务,添加请求限流、熔断机制,类比后端服务治理;
- 动态批处理:类比数据库连接池,智能管理GPU内存,合并同类推理请求,提升GPU利用率;
- 负载均衡:设计模型实例路由策略,支持按请求类型(如文本/多模态)、优先级分配算力资源。
AI时代后端架构演进(对比传统架构):
传统三层架构:
客户端 → 应用服务器 → 关系型数据库
AI增强型架构(后端核心演进方向):
客户端 → AI网关(请求路由/限流) → 模型服务集群(推理核心) → 向量数据库(语义存储) → 传统数据库
↓
语义缓存层(缓存模型输出,降低重复推理成本)
↓
可观测平台(监控token、延迟、算力消耗)
第二月:掌握大模型应用核心架构模式
- RAG系统架构:检索增强生成,本质是“智能搜索引擎+大模型”,后端需负责文档解析、向量存储、检索优化,是当前最落地的大模型应用场景;
- AI代理(Agent)设计:类比后端任务调度系统,将复杂业务拆分为模型可执行的步骤链,实现自动化任务处理;
- 流式响应处理:复用WebSocket、流式API经验,处理token级逐段输出,优化用户体验。
实战项目:企业级知识库问答系统(完整架构落地)
# 架构封装,融合后端工程化最佳实践
import asyncio
from typing import AsyncGenerator
from pydantic import BaseModel
from chromadb import PersistentClient # 向量数据库
from langchain.retrievers import HybridRetriever # 混合检索
from llm_client import LLMClusterClient # 自定义模型集群客户端
from redis.asyncio import Redis # 语义缓存
# 向量数据库初始化(类比后端数据库连接)
vector_db = PersistentClient(path="./vector_db")
collection = vector_db.get_or_create_collection(name="enterprise_kb")
# 缓存初始化(降低重复推理成本)
redis_client = Redis(host="localhost", port=6379, db=0)
class UserContext(BaseModel):
department: str
role: str
user_id: str
class EnterpriseRAGSystem:
def __init__(self):
# 文档处理管道(复用后端ETL逻辑)
self.doc_processor = DocumentPipeline(chunk_size=512, chunk_overlap=50)
# 混合检索器(关键词+向量检索,提升准确率)
self.retriever = HybridRetriever(
vector_retriever=collection.as_retriever(),
keyword_retriever=KeywordRetriever()
)
# 模型集群客户端(支持多模型路由)
self.llm_client = LLMClusterClient()
# 提示词工程封装(类比API契约设计)
self.prompt_builder = PromptBuilder(template_path="./prompt_templates")
async def get_cache(self, question: str) -> str | None:
"""语义缓存查询,类比后端缓存逻辑"""
cache_key = f"rag:{hash(question)}"
return await redis_client.get(cache_key)
async def set_cache(self, question: str, answer: str, expire: int = 3600):
"""设置缓存,添加过期时间"""
cache_key = f"rag:{hash(question)}"
await redis_client.setex(cache_key, expire, answer)
async def query(self, question: str, user_context: UserContext) -> AsyncGenerator[str, None]:
# 1. 缓存优先,减少推理成本
cached_answer = await self.get_cache(question)
if cached_answer:
yield cached_answer
return
# 2. 查询优化(类比SQL优化,提升检索准确率)
optimized_query = self.prompt_builder.optimize_query(question, user_context.role)
# 3. 混合检索(按部门过滤数据,保证权限合规)
relevant_chunks = await self.retriever.async_search(
query=optimized_query,
top_k=5,
filters={"department": user_context.department}
)
# 4. 构建提示词(注入上下文与用户角色)
prompt = self.prompt_builder.assemble(
question=question,
context=[chunk.page_content for chunk in relevant_chunks],
user_role=user_context.role
)
# 5. 流式调用模型(适配大模型token生成逻辑)
response_stream = await self.llm_client.generate_stream(
prompt=prompt,
temperature=0.6,
max_tokens=1200,
model="qwen-7b-chat" # 中小场景选型,平衡性能与成本
)
# 6. 流式返回与缓存存储
full_answer = []
async for token in response_stream:
full_answer.append(token)
yield token
await self.set_cache(question, "".join(full_answer))
# 7. 可观测性埋点(复用后端监控经验)
await self.monitor.log(
user_id=user_context.user_id,
question=question,
answer_length=len(full_answer),
latency=asyncio.get_event_loop().time() - start_time
)
第三月:性能优化与成本控制,后端核心竞争力落地
- 推理优化进阶:深入实践KV缓存(提升对话场景推理速度)、连续批处理(vLLM核心特性),对比不同优化方案的效果与成本;
- 成本核算体系:建立多维度成本模型,涵盖token调用成本、GPU时成本、数据传输成本,设计成本阈值告警机制;
- 混合推理策略:实现“小模型路由+大模型回退”,简单查询用开源小模型处理,复杂查询调用大模型,最大化性价比。
第四月:AI系统可观测性,保障线上稳定运行
- AI专属监控指标:除传统延迟、吞吐量,新增token使用量、推理成功率、输出质量评分(人工标注+自动化评估);
- 可解释性工具:集成注意力可视化工具,辅助定位模型输出异常原因,类比后端日志排查;
- 全链路监控:用Prometheus+Grafana搭建监控面板,覆盖“请求接入→模型推理→响应返回”全流程,添加异常告警。
五、阶段四:深入AGI基础设施(2-3个月)
目标:掌握下一代AI基础设施,提升架构话语权
大规模训练基础设施核心
- 分布式训练框架:学习DeepSpeed、Megatron-LM,理解数据并行、模型并行原理,类比后端分布式计算模式;
- 训练集群管理:掌握Kubernetes+NVIDIA GPU Operator部署GPU集群,实现训练任务的自动调度与资源隔离;
- 数据并行优化:解决训练数据分片、梯度同步问题,类比后端分布式事务的数据一致性保障。
模型部署平台深度实践
- 推理服务器选型:精通vLLM(开源高性能)、NVIDIA Triton(企业级,支持多模型部署),掌握服务配置与性能调优;
- 服务网格集成:将模型服务纳入Istio管理,实现流量控制、熔断、链路追踪,与现有后端服务体系打通;
- 智能扩缩容:基于GPU利用率、推理请求量设计扩缩容策略,避免资源浪费与性能瓶颈。
MLOps全流程落地
- 模型版本管理:用MLflow、Weights & Biases追踪模型版本、训练参数、评估指标,实现模型溯源;
- 持续训练(CT):搭建数据漂移检测系统,当数据分布变化时自动触发模型重训练,类比后端持续集成;
- 模型治理:落实合规要求,记录模型训练数据来源、部署范围,添加模型访问权限控制与操作审计。
六、阶段五:成为AI时代架构师(持续演进)
目标:从适配AI架构,到定义AI架构
前沿技术追踪重点(后端视角)
- 推理优化突破:关注投机解码、注意力优化算法(如FlashAttention),持续降低推理成本;
- 软硬件协同:了解CUDA生态、专用AI芯片(如英伟达H100、华为昇腾),优化架构与硬件的适配性;
- 多模态系统:掌握文本、图像、语音的统一处理管道,设计跨模态数据交互架构。
AI架构决策框架(后端工程师专属)
面对AI业务需求,按以下逻辑决策:
1. 实时性要求 → 决定模型大小(小模型低延迟/大模型高精度)与部署位置(云端/边缘);
2. 成本预算约束 → 选择模型类型(开源/闭源)、量化级别(INT4/INT8/FP16);
3. 数据隐私合规 → 确定部署模式(公有云/私有部署/混合云),设计数据脱敏方案;
4. 负载特征 → 制定缓存策略、动态批处理规则、扩缩容阈值;
5. 系统集成需求 → 设计API契约、异常处理机制、与现有系统的适配方案。
职业发展路径规划(后端转型专属)
路径一:AI系统架构师(核心推荐)
中级后端工程师 → AI后端开发工程师 → AI系统架构师 → AI基础设施负责人
核心能力:分布式系统+模型工程化+架构设计
路径二:MLOps专家(DevOps后端转型优选)
后端DevOps工程师 → MLOps工程师 → AI平台负责人
核心能力:CI/CD+GPU集群管理+模型全生命周期管理
路径三:全栈AI产品架构师(业务导向)
后端工程师 → AI业务集成专家 → AI产品技术负责人
核心能力:业务理解+模型选型+跨团队协同
七、全栈学习资源图谱(精选适配后端)
核心免费资源(优先实操类)
课程类
- 《Full Stack Deep Learning》(UC Berkeley):最贴近工程实践,覆盖模型训练、部署全流程,配套代码可直接复用;
- 《Machine Learning Engineering for Production (MLOps)》(Coursera):Andrew Ng团队出品,聚焦生产级AI系统构建;
- Hugging Face官方课程:实战导向,快速掌握Transformers、Diffusers等工具,同步业界最新实践;
- Microsoft AI Bootcamp:免费企业级教程,覆盖Azure AI服务与后端集成场景。
中文精选(降低入门门槛)
- 李沐《动手学深度学习》(PyTorch版):书籍+视频配套,用代码落地理论,适合后端工程师;
- 知乎“AI工程化”话题精华:汇聚一线工程师实战分享,解决落地痛点;
- 极客时间《AI大模型应用开发实战》:前几章免费,聚焦大模型服务化与系统集成。
实践平台(低成本入门)
- Kaggle Learn LLM专项:免费实操环境,可练习RAG、提示词工程;
- Google Colab Pro(按需付费):提供GPU资源,适合初期模型训练与调试;
- 阿里云/腾讯云AI体验平台:免费额度充足,可测试国内开源模型与云服务集成。
高性价比付费资源(投资回报率优先)
系统课程
- 《LLM Bootcamp》(Full Stack Deep Learning团队):$299,含大模型部署、优化实战,配套企业级案例;
- 《Building AI-Powered Applications》(DeepLearning.AI):完整讲解大模型应用构建,从原型到生产;
- 极客时间《AI大模型企业级应用实战》:国内一线大厂经验总结,适配国内业务场景。
书籍推荐(后端视角优先)
- 《Designing Machine Learning Systems》:AI系统设计圣经,覆盖架构选型、性能优化、成本控制;
- 《Building Large Language Model Applications》:聚焦LLM应用落地,含大量工程化技巧;
- 《机器学习系统:设计与实现》:中文原创精品,用工程化思维解读机器学习系统。
工具与服务(必备刚需)
- GitHub Copilot Business:不仅是代码助手,可辅助理解AI框架源码,提升开发效率;
- RunPod/Circle GPU租用:低成本GPU资源,适合本地无GPU时的大规模模型测试;
- Weights & Biases团队版:实验跟踪与协作工具,适配多人AI项目开发。
后端友好型工具栈推荐(分层适配)
推理与部署层
- 生产级推理:vLLM(开源首选,高性能)、NVIDIA Triton(企业级,多模型管理);
- 模型服务框架:Text Generation Inference(Hugging Face出品,适配开源模型);
- 边缘部署:ONNX Runtime(跨平台)、TensorRT(GPU加速推理)。
开发与编排层
- 编排框架:LangChain(快速原型搭建)、LlamaIndex(RAG场景专用);
- 工作流引擎:Prefect(ML工作流,比Airflow轻量)、Airflow(传统但生态完善);
- 实验跟踪:MLflow(开源,易集成)、Weights & Biases(功能全面)。
基础设施层
- GPU管理:Kubernetes + NVIDIA GPU Operator;
- 向量数据库:Qdrant(开源高性能)、Pinecone(云服务,开箱即用)、Weaviate(全功能);
- 监控告警:Prometheus + Grafana + 自定义AI指标导出器(监控token、GPU利用率)。
后端集成层
- API网关:Kong(AI插件丰富)、Apache APISIX(轻量高性能);
- 缓存策略:Redis(传统缓存)、GPTCache(语义缓存,适配大模型);
- 消息队列:Kafka(大规模数据流)、NATS(实时性要求高的推理请求)。
最后唠两句:后端转型AI,顺势而为的薪资跃迁
为什么越来越多后端工程师选择转型AI大模型?核心原因只有一个:供需缺口大、薪资溢价高、技能适配性强。
智联招聘2025年Q1最新数据印证了这一趋势:AI领域求职人数同比增幅超200%,但仍远低于岗位供给增速;人工智能行业整体求职热度达33.4%,位居各行业榜首,其中AI工程化相关岗位(如AI后端、模型部署)求职热度飙升69.6%,竞争压力相对较小。
麦肯锡报告更是明确预测:到2030年,中国AI专业人才需求将达600万人,人才缺口高达400万人。这一缺口不仅集中在AI算法研发领域,更大量分布在AI工程化、系统集成等环节——而这,正是后端工程师的核心优势所在。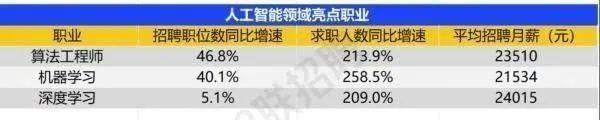
与其被动适应技术变革,不如主动抓住机遇。你的后端经验不是“过去时”,而是转型AI大模型的“护城河”,跟着这份路径稳步推进,就能在AI时代实现职业跃迁与薪资暴涨。
小白/程序员如何系统学习大模型LLM?
作为在一线互联网企业深耕十余年的技术老兵,我经常收到小白和程序员朋友的提问:“零基础怎么入门大模型?”“自学没有方向怎么办?”“实战项目怎么找?”等问题。难以高效入门。
这里为了帮助大家少走弯路,我整理了一套全网最全最细的大模型零基础教程。涵盖入门思维导图、经典书籍手册、实战视频教程、项目源码等核心内容。免费分享给需要的朋友!

👇👇扫码免费领取全部内容👇👇

1、我们为什么要学大模型?
很多开发者会问:大模型值得花时间学吗?答案是肯定的——学大模型不是跟风追热点,而是抓住数字经济时代的核心机遇,其背后是明确的行业需求和实打实的个人优势:
第一,行业刚需驱动,并非突发热潮。大模型是AI规模化落地的核心引擎,互联网产品迭代、传统行业转型、新兴领域创新均离不开它,掌握大模型就是拿到高需求赛道入场券。
第二,人才缺口巨大,职业机会稀缺。2023年我国大模型人才缺口超百万,2025年预计达400万,具备相关能力的开发者岗位多、薪资高,是职场核心竞争力。
第三,技术赋能增效,提升个人价值。大模型可大幅提升开发效率,还能拓展职业边界,让开发者从“写代码”升级为“AI解决方案设计者”,对接更高价值业务。
对于开发者而言,现在入门大模型,不仅能搭上行业发展的快车,还能为自己的职业发展增添核心竞争力——无论是互联网大厂的AI相关岗位,还是传统行业的AI转型需求,都在争抢具备大模型技术能力的人才。


人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
2、大模型入门到实战全套学习大礼包分享
最后再跟大家说几句:只要你是真心想系统学习AI大模型技术,这份我耗时许久精心整理的学习资料,愿意无偿分享给每一位志同道合的朋友。
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
部分资料展示
2.1、 AI大模型学习路线图,厘清要学哪些
对于刚接触AI大模型的小白来说,最头疼的问题莫过于“不知道从哪学起”,没有清晰的方向很容易陷入“东学一点、西补一块”的低效困境,甚至中途放弃。
为了解决这个痛点,我把完整的学习路径拆解成了L1到L4四个循序渐进的阶段,从最基础的入门认知,到核心理论夯实,再到实战项目演练,最后到进阶优化与落地,每一步都明确了学习目标、核心知识点和配套实操任务,带你一步步从“零基础”成长为“能落地”的大模型学习者。后续还会陆续拆解每个阶段的具体学习内容,大家可以先收藏起来,跟着路线逐步推进。

L1级别:大模型核心原理与Prompt
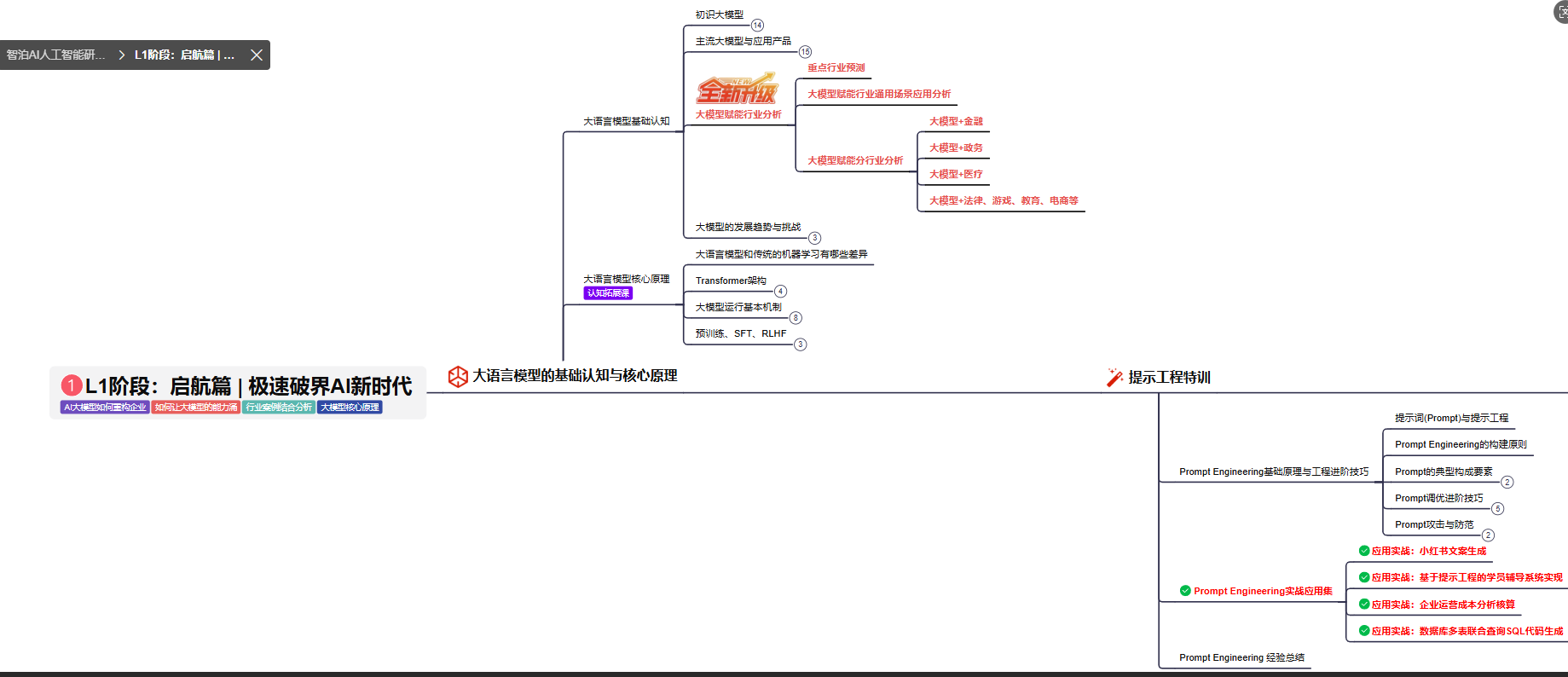
L1阶段: 将全面介绍大语言模型的基本概念、发展历程、核心原理及行业应用。从A11.0到A12.0的变迁,深入解析大模型与通用人工智能的关系。同时,详解OpenAl模型、国产大模型等,并探讨大模型的未来趋势与挑战。此外,还涵盖Pvthon基础、提示工程等内容。
目标与收益:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为AI应用开发打下坚实基础。
L2级别:RAG应用开发工程
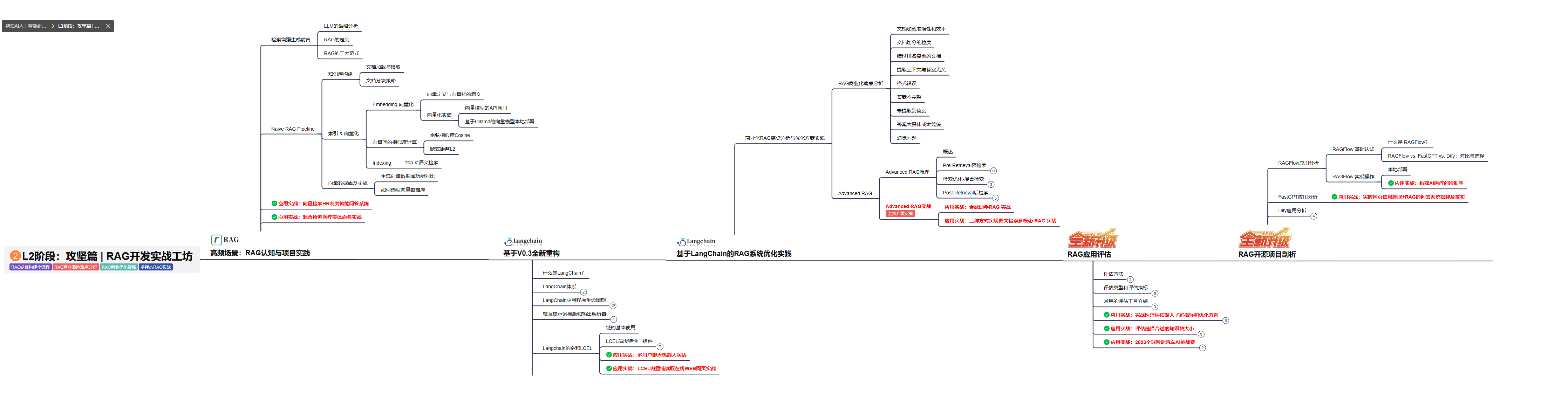
L2阶段: 将深入讲解AI大模型RAG应用开发工程,涵盖Naive RAGPipeline构建、AdvancedRAG前治技术解读、商业化分析与优化方案,以及项目评估与热门项目精讲。通过实战项目,提升RAG应用开发能力。
目标与收益: 掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
L3级别:Agent应用架构进阶实践
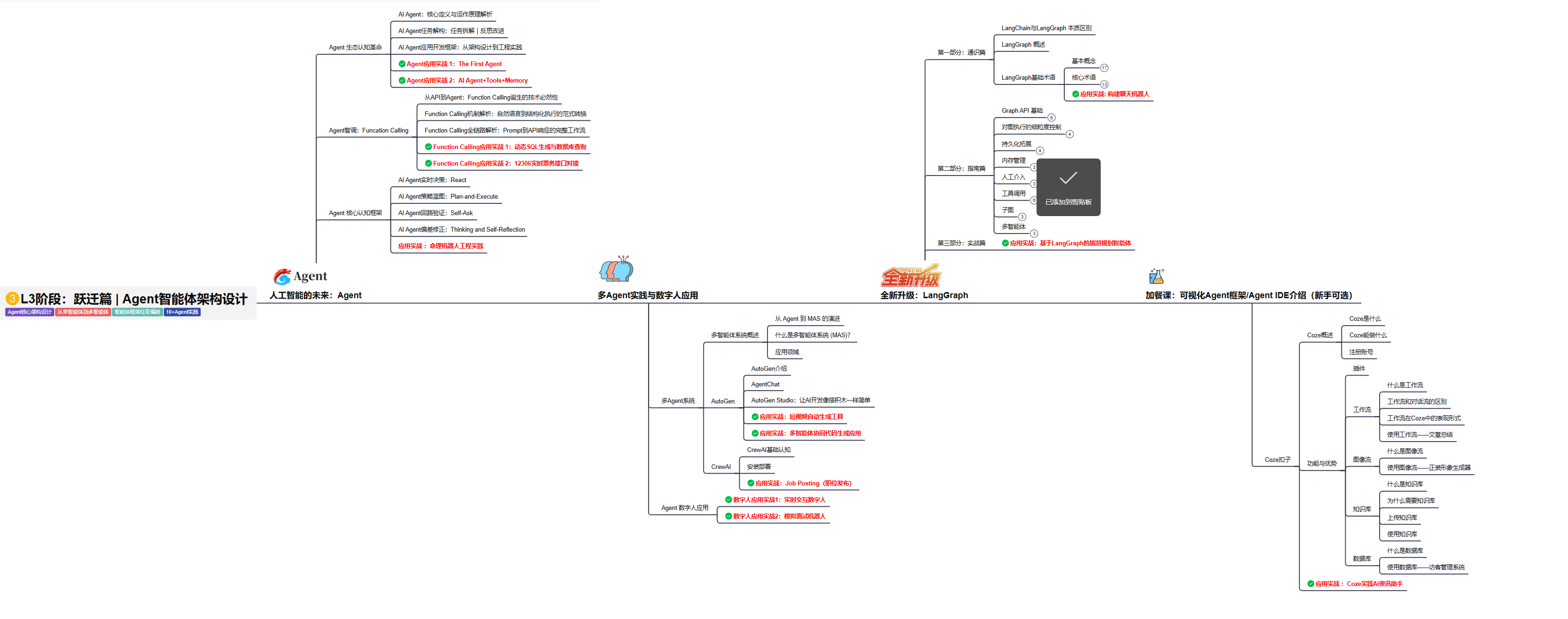
L3阶段: 将 深入探索大模型Agent技术的进阶实践,从Langchain框架的核心组件到Agents的关键技术分析,再到funcation calling与Agent认知框架的深入探讨。同时,通过多个实战项目,如企业知识库、命理Agent机器人、多智能体协同代码生成应用等,以及可视化开发框架与IDE的介绍,全面展示大模型Agent技术的应用与构建。
目标与收益:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
L4级别:模型微调与私有化大模型
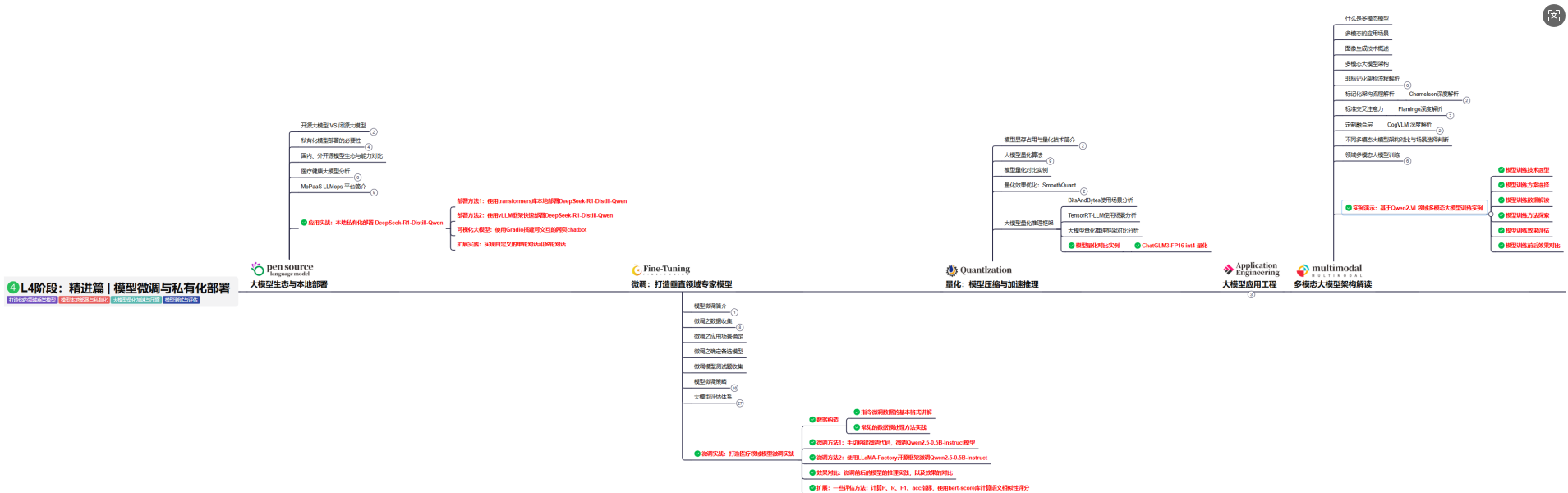
L4级别: 将聚焦大模型微调技术与私有化部署,涵盖开源模型评估、微调方法、PEFT主流技术、LORA及其扩展、模型量化技术、大模型应用引警以及多模态模型。通过chatGlM与Lama3的实战案例,深化理论与实践结合。
目标与收益:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。
2.2、 全套AI大模型应用开发视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

2.3、 大模型学习书籍&文档
收录《从零做大模型》《动手做AI Agent》等经典著作,搭配阿里云、腾讯云官方技术白皮书,帮你夯实理论基础。

2.4、 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

2.5、大模型大厂面试真题
整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题,涵盖基础理论、技术实操、项目经验等维度,每道题都配有详细解析和答题思路,帮你针对性提升面试竞争力。

【大厂 AI 岗位面经分享(107 道)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

2.6、大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)