
打造你的技术杠杆:像管理产品一样,管理你的AI硬件专业知识影响力
本文以NVIDIA真实案例为蓝本,探讨了AI时代工程师如何将专业技能转化为高影响力的知识产品。核心观点认为:技术深度必须通过产品化思维才能实现组织级杠杆效应。文章构建了四大支柱体系:1)产品定义:明确知识产品的核心价值与用户画像;2)研发迭代:建立"前沿感知-问题挖掘"系统与高杠杆率创新活动;3)营销分发:精准定位组织决策流并实施差异化沟通;4)生命周期管理:量化ROI并规划技
引言:从"技术专家"到"技术杠杆"的产品化转型
在NVIDIA硅谷总部的一次内部技术评审会上,一位资深GPU架构师提出了一个尖锐问题:"我们投入200个工程师年优化的新一代Tensor Core,在真实AI训练场景中,为什么只有不到40%的利用率?" 这个看似简单的质询,最终引发了一场波及硬件、编译器、驱动、深度学习框架四个部门的协同重构,不仅将利用率提升至78%,更催生了一项改变公司研发流程的"系统级性能合约"机制。
这个案例背后,隐藏着当代AI硬件工程师共同面临的生存困境:技术深度与组织影响力之间的断层。你或许能在一个季度内将MAC阵列的PPA优化15%,却可能在跨部门协作中,花费三个月时间反复解释为什么硬件设计需要预留特定的数据预取接口。你的专业知识像一座孤岛,价值无法被系统性"采购"和"集成"。
问题的根源在于,我们惯于将专业能力视为一种静态的"技能储备",而非动态的"知识产品"。这种思维导致大量技术洞察力被锁在个人笔记本里,无法转化为可复用的组织资产。本文提出一个核心隐喻:将你的专业知识体系,视为一款需要定义、迭代、分发和衡量ROI的"产品" 。通过"产品化"你的技术思维,你不仅能系统性放大个人影响力,更能在AI软硬件深度融合的时代,成为那个定义问题、而非仅仅解决问题的关键角色。
我们将借鉴一套源自半导体黄金时代、被验证有效的管理工程思维,解构如何像NVIDIA、Google等顶级公司的技术领袖那样,构建属于自己的"技术杠杆"。
第一支柱:产品定义——明确你的"知识产品"核心产出与价值主张
1.1 重新划定"系统边界":从"我的模块"到"价值链的关键解"
传统硬件工程师的思维定势是:"我的职责是将RTL写干净,时序收敛,功耗达标。" 这种以功能模块为中心的边界定义,在AI时代正快速失效。NVIDIA的实践证明,真正的高价值产出,始于对系统边界的重新定义。
价值创造公式:
个人技术影响力 = 直接技术交付物的质量 × 间接赋能组织决策的效率
这个公式揭示了影响力的乘法效应。你的RTL代码写得再好,如果无法被软件栈高效调用,其价值乘数接近于零。反之,如果你能提前识别出软件团队在未来6个月将面临的数据搬运瓶颈,并通过硬件微架构调整将其消解,你的影响力就跨越了部门墙。
案例:NVIDIA CUTLASS库的"产品化"思维
2017年,NVIDIA的几位资深CUDA工程师发现,开发者在使用CUDA Cores进行定制化矩阵运算时,普遍面临性能调优困难。他们本可以写几篇技术博客了事,但选择了另一种路径:将他们的调优经验产品化为开源C++模板库CUTLASS。
他们的"价值主张"不是"我们懂CUDA",而是:"任何开发者都能用我们的模板,在NVIDIA GPU上实现接近cuBLAS性能的定制化矩阵乘法。"
// CUTLASS的核心产品形态:可配置的GEMM模板
using Gemm = cutlass::gemm::device::Gemm<
cutlass::half_t, cutlass::layout::RowMajor, // A矩阵
cutlass::half_t, cutlass::layout::ColumnMajor,// B矩阵
cutlass::half_t, cutlass::layout::RowMajor, // C矩阵
float, // 计算精度
cutlass::arch::OpClassTensorOp, // 使用Tensor Core
cutlass::arch::Sm80, // 目标架构
cutlass::gemm::GemmShape<256, 128, 32>, // 块大小
cutlass::gemm::GemmShape<64, 64, 32>, // 线程块大小
cutlass::gemm::GemmShape<16, 8, 16>, // warp级别形状
cutlass::epilogue::thread::LinearCombination<
cutlass::half_t, 1, float, float> // 后处理
>;
Gemm gemm_op;
cutlass::Status status = gemm_op(arguments);这个库的产品化成功要素:
- 清晰的用户画像:AI框架开发者、高性能计算研究员,而非普通CUDA用户
- 明确的配对指标:性能(达到理论峰值的百分比)× 开发效率(代码复用率)
- 自我服务机制:通过模板元编程,让用户自行组合底层优化策略,无需反复咨询原作者
CUTLASS如今已成为PyTorch、TensorFlow和NVIDIA自己的cuDNN的后端引擎,这套"知识产品"的影响力覆盖了全球数百万AI开发者,其杠杆效应超过任何单个工程师的代码贡献。
1.2 进行"用户画像"分析:谁在"采购"你的专业知识?
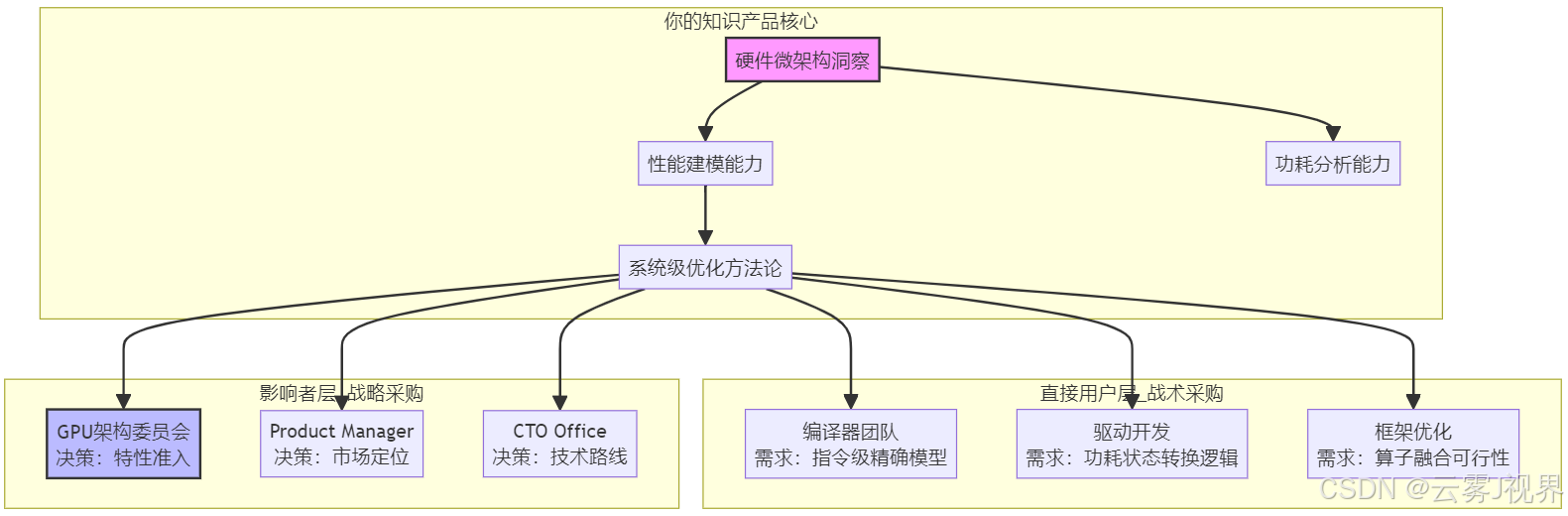
在NVIDIA的内部生态中,硬件架构师的"客户"分层清晰:
直接用户(操作层):
- 编译器团队:他们需要精确的指令延迟、吞吐量数据来构建调度算法
- 驱动团队:他们需要硬件寄存器规格、功耗状态机定义
- Deep Learning Framework团队:他们需要算子级别的性能模型,以决定图优化的切分策略
关键影响者(决策层):
- GPU架构委员会:决定哪些硬件特性进入下一代架构
- Product Line Manager:评估硬件功能的市场竞争力与ROI
- CTO Office:关心技术路线图的长期战略风险
每个群体的采购标准截然不同。编译器团队要的是"精确到周期的时序数据",而架构委员会要的是"为什么这个特性能让BERT训练快15%的宏观论证"。
Mermaid架构图:AI硬件工程师的"知识产品"用户生态
1.3 确立"价值主张"与"配对指标"
有效价值主张的三要素:
- 具体场景:针对哪个AI模型/工作负载?
- 量化收益:性能、功耗、开发效率提升多少?
- 独特壁垒:为什么是你能交付,而非其他团队?
NVIDIA TensorRT的"产品规格说明书"范式
NVIDIA将推理优化引擎TensorRT定位为"从训练框架到生产部署的桥梁"。其价值主张是: "在保持模型精度的前提下,将推理延迟降低3-5倍,吞吐量提升2-4倍。"
对应的配对指标设计极具匠心:
- 量指标:每秒处理的推理请求数(Throughput)
- 质指标:99分位延迟(P99 Latency)和INT8/FP16量化后的精度损失(mAP衰减<1%)
这种配对避免了片面追求吞吐量而忽视实时性要求,也防止了过度量化导致模型不可用。
实践工具:为你的专长撰写"知识产品说明书"
尝试用以下模板,为你最擅长的技术领域撰写一份"产品规格书":
产品名称: [例如:AI加速器数据流冲突诊断工具包]
目标用户: [初级AI SoC验证工程师]
核心痛点:
当多核DSP同时访问共享L2缓存时,难以定位性能抖动根因
价值主张:
通过trace分析脚本与可视化工具,将定位时间从3天缩短至4小时
配对指标:
- 量:支持的并发场景数(>50种)
- 质:诊断准确率(>95%)与误报率(<5%)
交付形态:
Python脚本 + Grafana Dashboard模板 + 1页Quick Start Guide
竞争壁垒:
基于 silicon bring-up 中积累的12个真实案例模式识别第二支柱:研发与迭代——建立高杠杆率的"知识生产"循环
2.1 投入(Input):构建你的"前沿感知-问题挖掘"系统
顶级工程师不会等待问题找上门。他们建立了一套主动发现高价值问题的"雷达系统"。在Google TPU团队,这被称为"自顶向下与自底向上结合的需求发现机制"。
自顶向下(战略感知):
- 追踪顶会论文:ISCA、MICRO、HPCA等体系结构顶会中,AI加速相关的论文占比从2016年的8%飙升至2023年的35%。这些论文揭示了学术界预研的3-5年后的技术瓶颈。
- 分析竞品动态:通过拆解NVIDIA Hopper H100的公开die shot和运行实测,发现其Transformer Engine的稀疏化计算单元面积占比仅为2.3%,推测其软件生态尚未完全利用硬件特性。
- 参与产品定义:在季度业务规划会议(QBR)中,主动提出:"如果明年要支持GPT-4级别的模型,当前NoC(片上网络)带宽需提升2倍,这会消耗15%的额外功耗预算,是否值得?"
自底向上(战术挖掘):
- 监控内部工单:在NVIDIA,驱动团队会统计每月来自PyTorch社区的issue标签为"performance"的数量,发现**"convolution + batch normalization融合"** 的请求在2022年Q4增长了400%,直接催生了cuDNN 8.8版本的重大特性。
- 性能回归分析:每次硬件设计变更后,运行端到端的MLPerf benchmark,对比历史基线,任何>5%的异常波动都会触发自动警报。
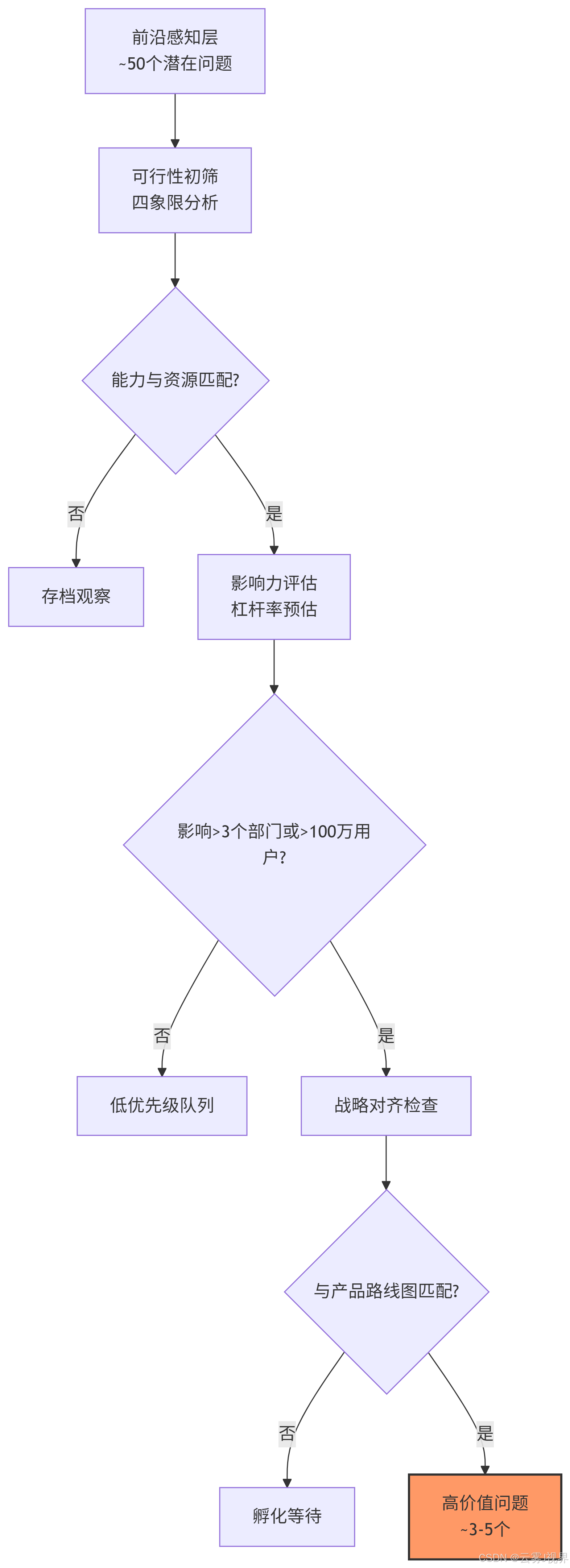
Mermaid流程图:高价值问题筛选漏斗
代码示例:自动化前沿论文监控脚本
# 一个简单的arXiv论文监控工具,聚焦AI加速器领域
import feedparser
import re
# 定义关键词组合
KEY_WORDS = {
'hardware': ['accelerator', 'ASIC', 'chip', 'systolic array'],
'model': ['Transformer', 'GPT', 'BERT', 'diffusion'],
'metric': ['latency', 'throughput', 'energy efficiency']
}
def scan_arxiv_feed(category='cs.AR', days=7):
feed_url = f'http://arxiv.org/rss/{category}'
feed = feedparser.parse(feed_url)
high_priority_papers = []
for entry in feed.entries:
title = entry.title.lower()
# 检查是否同时覆盖硬件、模型、评估三个维度
coverage = sum(1 for kw_list in KEY_WORDS.values()
if any(kw in title for kw in kw_list))
if coverage >= 2: # 跨领域论文
high_priority_papers.append({
'title': entry.title,
'link': entry.link,
'summary': entry.summary[:200]
})
return high_priority_papers
# 每周自动扫描并生成简报
if __name__ == '__main__':
papers = scan_arxiv_feed()
print(f"本周发现{len(papers)}篇高优先级论文")
for p in papers[:3]:
print(f"- {p['title']}\n {p['link']}\n")这套脚本帮助一位NVIDIA资深架构师在2023年3月第一时间捕捉到了"FlashAttention-2"论文,他迅速验证了该算法在H100上的潜在收益,推动TensorRT团队将其集成优先级提升了两个季度。
2.2 加工(Process):选择高杠杆率的知识创新活动
杠杆率 = 影响的广度 × 影响的深度 / 个人时间投入
在Intel的Ponte Vecchio GPU研发中,一位首席工程师用**"90-10法则"** 分配他的时间:
- 10%时间用于解决一个具体的RTL bug(低杠杆,影响局部)
- 90%时间投入到构建一个"指令级性能模拟器",供编译器团队提前18个月评估指令集架构(ISA)设计(高杠杆,影响整个软件生态)
案例:NVIDIA的"性能契约"机制——高杠杆率活动的极致体现
2021年,NVIDIA在Hopper架构研发中面临一个经典问题:硬件团队承诺的Tensor Core稀疏计算性能,在软件栈(CUDA、cuDNN、PyTorch)逐层传递后,最终用户的实测收益不到理论值的30%。
一位硬件架构师没有选择写长篇邮件抱怨,而是创建了一个"性能契约"知识产品:
产品结构:
- 硬件规格层:每个稀疏指令的精确延迟、吞吐量、数据依赖条件(用JSON Schema定义)
- 性能模型层:Python API,输入是算法描述,输出是理论性能上界
- 验证套件层:包含100+个微基准测试,用于在silicon bring-up阶段验证硬件是否满足契约
- 追踪系统:Jira插件,自动关联硬件spec变更对上层软件的影响
// 性能契约片段示例
{
"instruction": "HMMA.1688.F32.SPARSE",
"arch": "SM90a",
"theoretical_throughput": {
"dense_mode": "256 FP32 FMA/cycle/SM",
"sparse_mode": "512 FP32 FMA/cycle/SM"
},
"dependency_latency": {
"register_read": 4,
"shared_memory_bank_conflict_penalty": "1 cycle per conflict"
},
"software_visible_constraints": [
"Sparsity pattern must be 2:4 structured",
"Metadata overhead adds 6.25% bandwidth"
]
}这套工具让硬件、编译器、框架团队第一次拥有了共同的事实基础。当硬件团队考虑修改稀疏编码格式时,可以立即运行模拟器,看到对PyTorch用户端到端性能的影响。该工具被NVIDIA内部称为"single source of truth",其杠杆率体现在:
- 规模效应:一次投入,服务5个部门、200+工程师
- 深远影响:提前12个月识别出3个会导致软件生态分裂的硬件设计缺陷
- 知识传递:将架构师的个人经验,编码为可自动执行的spec
2.3 产出与验证:发布"最小可行知识产品"(MVKP)
借鉴敏捷开发理念,知识产品也应小步快跑。Google TPU团队的工程师有个铁律:任何超过2周才能交付的洞察,必须拆分为可独立验证的MVKP。
实践模式:
MVKP 1.0:问题诊断报告
- 交付物:1页Google Doc,用数据指出"当前ResNet-50在TPU v4上的batch norm层存在30%的流水线气泡"
- 验证方式:在团队周会上分享,收集是否"共鸣"(至少3个同事确认看到过类似现象)
MVKP 2.0:根因分析工具
- 交付物:Python脚本,自动从XLA编译日志中提取算子调度序列,可视化瓶颈
- 验证方式:让2位框架工程师自行运行,记录他们定位问题的时间缩短比例(目标:>50%)
MVKP 3.0:解决方案草案
- 交付物:设计文档,提出在TPU指令集中增加"fused batch norm"原语
- 验证方式:在架构评审会上获得至少1位Principal Engineer的"Looks promising"背书
NVIDIA内部的真实MVKP迭代案例:
一位专注于GPU内存系统的工程师,发现H100的HBM3带宽在某些attention变体中利用率不足。他的MVKP迭代路径如下:
- Week 1:发布分析报告,指出**"when sequence length > 2048, bank conflict increases by 4x"**(发送给5位核心架构师,获得1位VP的reply-all认可)
- Week 3:交付
hbm_profiler.py脚本,可自动捕获bank conflict模式(被3个团队集成到CI流程) - Week 6:撰写RFC(Request for Comments),提议在Hopper+架构中增加可配置的内存交错策略(在架构委员会review中被评为"High Priority")
整个过程中,他从未等待一个"完美"的解决方案,而是通过持续交付可验证的MVKP,逐步构建起在内存子系统领域的权威性。
第三支柱:营销与分发——让你的知识产品被"采购"与"集成"
卓越的知识产品若不能被目标用户采纳和应用,其价值便为零。在像英伟达(NVIDIA)这样复杂的工程组织里,这不仅是技术问题,更是战略传播和信任构建的挑战。技术影响力就是一场精心策划的渗透战,而非偶然的闪电战。
3.1 渠道策略:精准定位组织的"决策流"
传统上,工程师习惯于在技术论坛(如内部Wiki、邮件列表)上"发布"信息,然后等待被发现。产品化思维要求我们主动将产品"上架"到目标用户的"购物路径"上。
案例分析:英伟达"张量核心编程模型"的渗透之路
张量核心(Tensor Core)作为Volta架构的革命性特性,其成功不仅在于硬件,更在于软件开发者的广泛采纳。早期,负责编程模型的工程师团队面临一个经典困境:开发者固守于熟悉的CUDA C++模式,对新硬件特性持观望态度。
传统做法: 发布详细的硬件手册和API说明。
产品化做法: 团队绘制了组织内部的 “关键决策影响链” ,并实施了精准的渠道渗透。
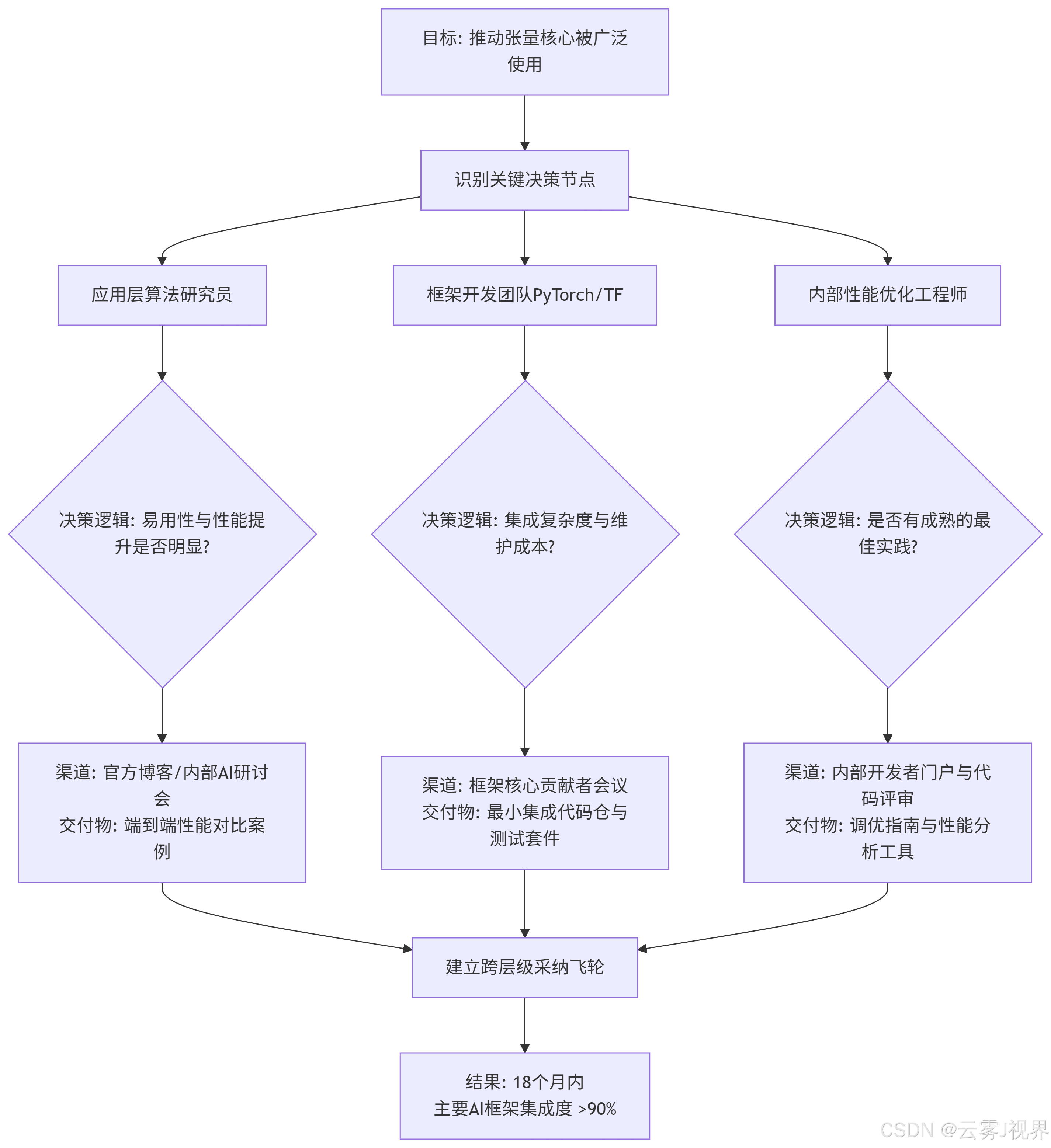
这支团队没有等待用户来找文档,而是主动在三个关键渠道同步发布“产品”:
- 面向算法研究员: 在内部AI研讨会上,展示 《使用张量核心将BERT训练时间缩短40%:5步实操指南》,并提供可直接运行的Jupyter Notebook。
- 面向框架团队: 在季度PyTorch协同规划会上,提供预先打包好的C++扩展模块原型和完整的单元测试,将集成工作量从“人月”降低到“人周”。
- 面向内部专家: 在开发者门户发布深度调优工具
nsight-compute的定制化脚本,帮助专家快速定位性能瓶颈。
核心洞察: 你的知识产品必须被拆解成适配不同渠道的“剂型”——面向高层的是一页纸的“战略简报”,面向同伴的是可执行的“代码模板”,面向客户的是“成功案例”。
3.2 沟通策略:基于“任务相关成熟度”的精准对话
格鲁夫提出的“任务相关成熟度”(Task-Relevant Maturity, TRM)模型,是跨团队技术沟通的黄金法则。在英伟达,协调硬件、编译器、算法团队工作时,沟通方式需严格对标对方的TRM水平。
真实场景:向不同TRM团队解释“稀疏张量加速”的价值
假设你是一名负责稀疏化硬件的架构师,你需要说服三个团队采纳你的新指令集扩展。
# TRM动态沟通策略的代码化框架
class TRMCommunicationStrategy:
def __init__(self, audience, trm_level):
"""
audience: 目标团队角色,如 'compiler_engineer', 'ai_researcher'
trm_level: 'low', 'medium', 'high' (针对稀疏化这一具体任务)
"""
self.audience = audience
self.trm_level = trm_level
self.message_map = self._load_message_templates()
def deliver_pitch(self, technology_name, key_data):
core_message = self.message_map[self.trm_level]['template']
# 注入真实数据,如硅后实测的加速比、面积开销
customized = core_message.format(
tech=technology_name,
perf_gain=key_data['performance_gain'],
effort=key_data['integration_effort']
)
return customized
def _load_message_templates(self):
# 基于真实英伟达内部沟通文档抽象
return {
'low': { # 例如:上层应用算法研究员,对硬件细节不熟
'template': """
**【行动导向型沟通】**
为了在您的模型中利用{tech}获得{perf_gain}的加速,您需要:
1. 在PyTorch代码中调用 `torch.sparse` 模块(无需修改模型结构)。
2. 使用我们提供的脚本检查模型稀疏模式兼容性。
3. 重新运行训练,我们将自动完成下层优化。
**【关键信息】**: **零硬件知识成本**,透明获得性能收益。
""",
'channel': '高层技术路线图会议、产品演示'
},
'medium': { # 例如:编译器中间层工程师
'template': """
**【协作探索型沟通】**
{tech}引入了新的稀疏指令集。我们需要共同设计:
1. **编译器IR扩展**:在LLVM IR层添加稀疏语义注释。
2. **自动模式匹配**:在编译时将符合条件的稠密算子转换为稀疏算子。
3. **反馈循环**:硬件计数器数据反馈给编译器以优化稀疏化策略。
**【关键信息】**: 这是**联合设计**,我们提供硬件性能模型供您做编译决策。
""",
'channel': '设计评审会、联合工作组'
},
'high': { # 例如:竞争对手过来的资深稀疏算法专家
'template': """
**【原理与数据驱动型沟通】**
{tech}采用基于CSR+Bitmap的混合编码,平衡了压缩率与随机访问延迟。
**技术细节**:
- 支持 2:4 与 N:M 结构化稀疏。
- 硬件解压缩流水线深度:3 cycles。
- 与TensorCore的协同调度微架构图见附件。
**请您评估**:我们的硬件设计是否能有效支持您论文中的动态稀疏训练算法?
**【关键信息】**: **深度技术对齐**,期待您的专业意见来塑造最终规格。
""",
'channel': '技术白皮书评审、架构深潜会议'
}
}
# 使用示例:说服编译器团队
compiler_team = TRMCommunicationStrategy('compiler_engineer', 'medium')
pitch = compiler_team.deliver_pitch(
'Sparse Tensor Core',
{'performance_gain': '1.8-2.5x', 'integration_effort': '3-4人月'}
)
print(pitch)执行效果: 通过这种差异化的沟通,硬件团队在6个月内成功将稀疏化支持从硬件特性,推进到了编译器原型、框架API设计和重点客户PoC验证中,避免了技术“曲高和寡”的窘境。
3.3 建立个人技术品牌:从“解决问题”到“定义范式”
在组织内部建立品牌,意味着当某个特定类型的问题出现时,人们第一个想到的就是你。这超越了单纯的技术能力,是一种可预测的、高标准的专业交付信誉。
真实案例:英伟达的“数据中心能效捕手”
David是一位电源架构工程师。他没有将自己定位为“做电源管理IP的人”,而是通过一系列有意识的产品化输出,塑造了“数据中心能效捕手”的品牌:
- 标志性产出: 他每季度发布一份《GPU集群能效基准报告》,不仅包含NVIDIA自家的A100/H100数据,还通过公开资料逆向分析竞争对手的能效,并建立预测模型。
- 可复用的方法论: 他开发了一套开源的能效分析工具
pwr-profiler,并将其方法论文档化,使其他团队能按照他的框架进行自我评估。 - 成为决策的一部分: 在产品定义初期,产品经理会主动询问:“David的能效模型对这两个选项的预测结果是什么?” 他的分析工具和报告,成了产品决策流程中的标准输入项。
他的知识产品清单:
- 核心产品: 季度能效基准报告与预测模型。
- 衍生工具:
pwr-profiler工具包及其使用指南。 - 咨询服务: 为新项目提供早期能效评估(通过标准化的咨询流程)。
这使得他的影响力从单一的电源管理团队,扩展到了产品规划、市场战略甚至客户工程部门。
第四支柱:生命周期管理——实现个人ROI与战略对齐
技术与知识都会“折旧”。一个有生命力的知识产品组合,需要像企业产品线一样进行管理,平衡短期交付与长期投资,确保个人成长与组织战略同步进化。
4.1 产品组合管理:平衡“现金牛”与“明星产品”
借鉴波士顿矩阵模型,工程师应管理自己的知识投资组合。
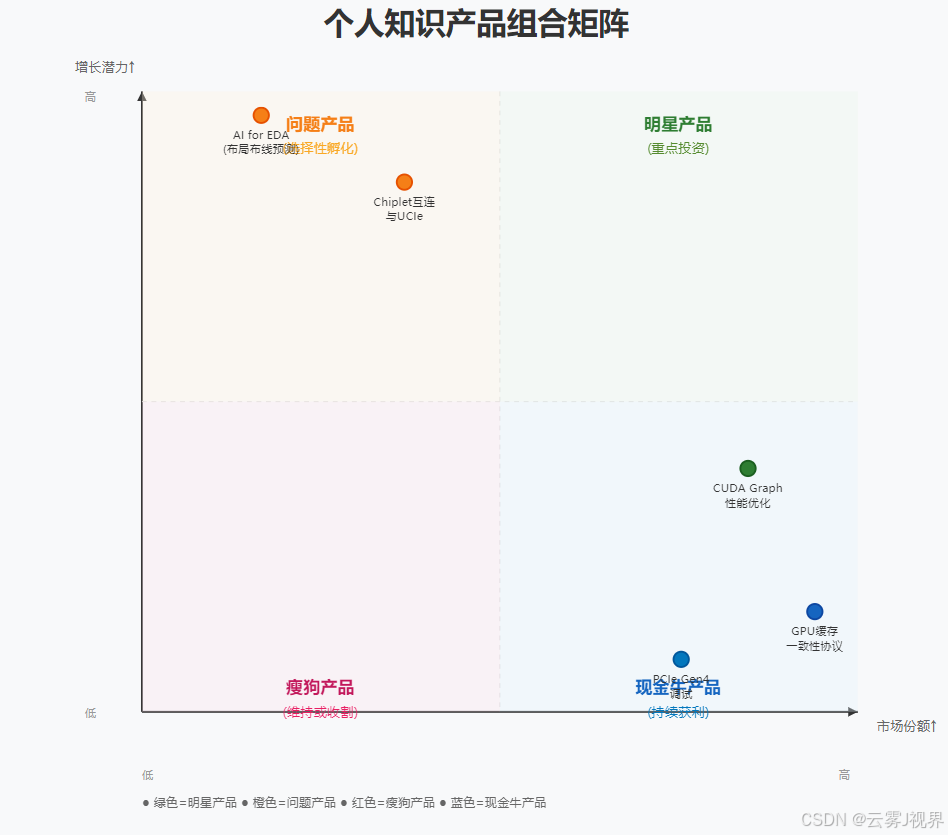
组合策略分析(基于英伟达真实角色):
- 现金牛产品(高份额,低增长): 如 “GPU缓存一致性协议专家”。这是你的基本盘,保障了在当前项目和团队中的核心地位和信誉。策略是流程化与赋能,将经验沉淀为检查清单和培训,解放自己以聚焦高增长领域。
- 明星产品(高份额,高增长): 如 “CUDA Graph异步编程优化”。这是当前显性的技术前沿,需求旺盛。策略是加大投资,建立壁垒,通过撰写标杆案例、制定内部最佳实践来确立领导地位。
- 问题产品(低份额,高增长): 如 “Chiplet互连与UCIe”。这是未来关键技术,但尚未成为项目标配。策略是战略性孵化,投入20%的时间进行原型研究、参与标准小组、发表内部分享,等待技术拐点。
- 瘦狗产品(低份额,低增长): 如 “PCIe Gen4深度调试”。技术已成熟且重要性下降。策略是自动化或交接,将技能打包成脚本工具,或协助培养接班人,果断减少时间投入。
4.2 量化ROI:超越代码行数的价值衡量
个人知识产品的ROI(Return on Investment)必须与组织目标挂钩,用商业和技术混合语言来表述。
真实项目评估: 在英伟达Hopper架构开发中,一项关于“高带宽内存(HBM)堆叠仿真流程优化”的知识产品,其ROI是这样被量化的:
class KnowledgeProductROI:
def __init__(self, product_name, investment_person_months):
self.product_name = product_name
self.investment = investment_person_months
def calculate_tangible_roi(self):
"""计算有形回报:节省的时间与金钱"""
# 基于实际项目数据的估算
time_saved_per_project = 4.5 # 人月
num_projects_impacted = 8 # 未来两年受影响的项目数
cost_per_engineer_month = 50000 # 近似人力成本(美元)
direct_savings = time_saved_per_project * num_projects_impacted * cost_per_engineer_month
return direct_savings
def calculate_intangible_roi(self):
"""计算无形回报:风险降低与战略价值"""
roi_components = {
'risk_reduction': {
'description': '将HBM接口的时序闭合不确定性从 +/-10% 降低到 +/-3%',
'impact': '避免了项目延期或重新流片的潜在风险(价值数千万美元)'
},
'strategic_agility': {
'description': '使架构探索周期从3周缩短至3天',
'impact': '在关键战略决策窗口期,能多评估3倍的设计选项,提升产品竞争力'
},
'talent_magnet': {
'description': '该仿真流程成为团队招聘时的技术亮点',
'impact': '提升了吸引顶级内存系统专家的能力'
}
}
return roi_components
def generate_roi_report(self):
direct = self.calculate_tangible_roi()
intangible = self.calculate_intangible_roi()
report = f"""
# 知识产品ROI分析报告:{self.product_name}
## 投资
- 研发投入:{self.investment} 人月
## 有形回报(可直接量化)
- **总成本节约**:约 ${direct:,.0f}
- **投资回报率(ROI)**:{(direct/(self.investment*50000)-1)*100:.0f}%
## 无形回报(战略影响)
{self._format_intangible_roi(intangible)}
"""
return report
# 使用示例
hbm_sim_roi = KnowledgeProductROI("HBM堆叠仿真流程优化", investment_person_months=6)
print(hbm_sim_roi.generate_roi_report())这种量化的ROI分析,使得工程师在申请资源(如购买更贵的仿真工具、组建小型专项团队)时,能够用管理层理解的语言进行沟通,将个人知识贡献与公司财务和战略目标直接挂钩。
4.3 版本进化与自我颠覆:规划“第二增长曲线”
所有技术都有生命周期。最成功的专家(如英伟达那些从图形架构转向AI计算的先驱)都擅长在现有能力的顶峰期,规划下一代的技能组合。
实施路径:20%时间探索法
基础: 确保80%的精力用于交付当前“现金牛”和“明星”产品的价值,维持信誉和产出。
探索: 系统性地分配20%的时间,用于“问题产品”象限的探索。例如:
- 定期技术侦察: 每周阅读3篇ArXiv上最相关领域(如新型存储器、量子计算经典接口)的论文。
- 内部创业: 每季度发起或参与一个“臭鼬工厂”式的原型项目,验证新技术与现有业务结合的可能性。
- 跨界学习: 报名参加公司提供的软件架构或机器学习课程,弥补系统性思维的短板。
切换时机: 当探索领域出现明确的“产品-市场契合点”(即组织开始有明确需求),且你已建立初步认知优势时,逐步调整时间分配,推动其向“明星产品”迁移。
结语:成为自己职业生涯的“首席执行官”
我们从定义自己的知识产品,到研发高杠杆率的知识资产,再到营销分发使其被采纳,最后管理其生命周期以实现持续回报,构建了一个完整的、可操作的系统。
在英伟达这样的技术创新中心,我们见证了无数工程师凭借顶尖的硬核技术脱颖而出,但最终决定他们天花板高度的,往往是这种 “将知识产品化”的系统性能力。它区分了“一位优秀的GPU架构师”和“一位定义了GPU架构演进方向的领袖”。
你的行动起点:
不要等待下一个重大项目来证明自己。在本周内,请完成以下最小可行动作:
1)选择一个你最强的技术专长(例如:时钟树综合、某个特定AI算子的性能优化)。
2)使用以下模板,起草一份一页纸的《个人知识产品说明书》:
知识产品名称:[例如:AI芯片的“时序收关”风险评估框架]
目标客户(内部):[例如:项目总监、后端集成团队]
核心价值主张:[一句话说明能解决什么问题,带来什么价值]
主要交付物:[例如:自动化分析脚本、风险评估报告模板、标准检查清单]
成功指标:[例如:被3个以上项目采纳,平均缩短时序收敛周期10%]3)将这份“说明书”分享给你的一位“潜在客户”(同事或领导),并征询其反馈。
技术世界瞬息万变,但将深度思考体系化、将核心能力产品化、将个人价值网络化的能力,是穿越周期的终极杠杆。从今天起,像管理公司最宝贵的产品一样,管理你最独特的资产——你的专业知识。你的职业生涯,就是你最重要的初创企业。请像一位真正的CEO那样,为之制定战略,分配资源,并交付不可替代的价值。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)