
鸿蒙中级课程笔记3—ArkUI进阶6—ArkUI性能优化实践(长列表加载性能优化)
使用LazyForEach懒加载这项技术后,相比ForEach这种加载方式,在列表数据量较小(100条内)且数据一次性全量加载不是性能瓶颈时,两者各项性能指标差异不大。但当列表数据较长特别是达到10000条数据量后,ForEach的上述4项性能指标会有“指数级别”的显著劣化,滑动会出现明显的卡顿,甚至会出现应用crash等现象;而LazyForEach因为采用了懒加载技术能明显减少首屏完全显示所用
长列表优化概述
对比案例1:10000条数据量下ForEach和LazyForEach启动对比。结果:ForEach情况下,明显有一个白屏的过程,而此时LazyForEach已经将页面加载出来。
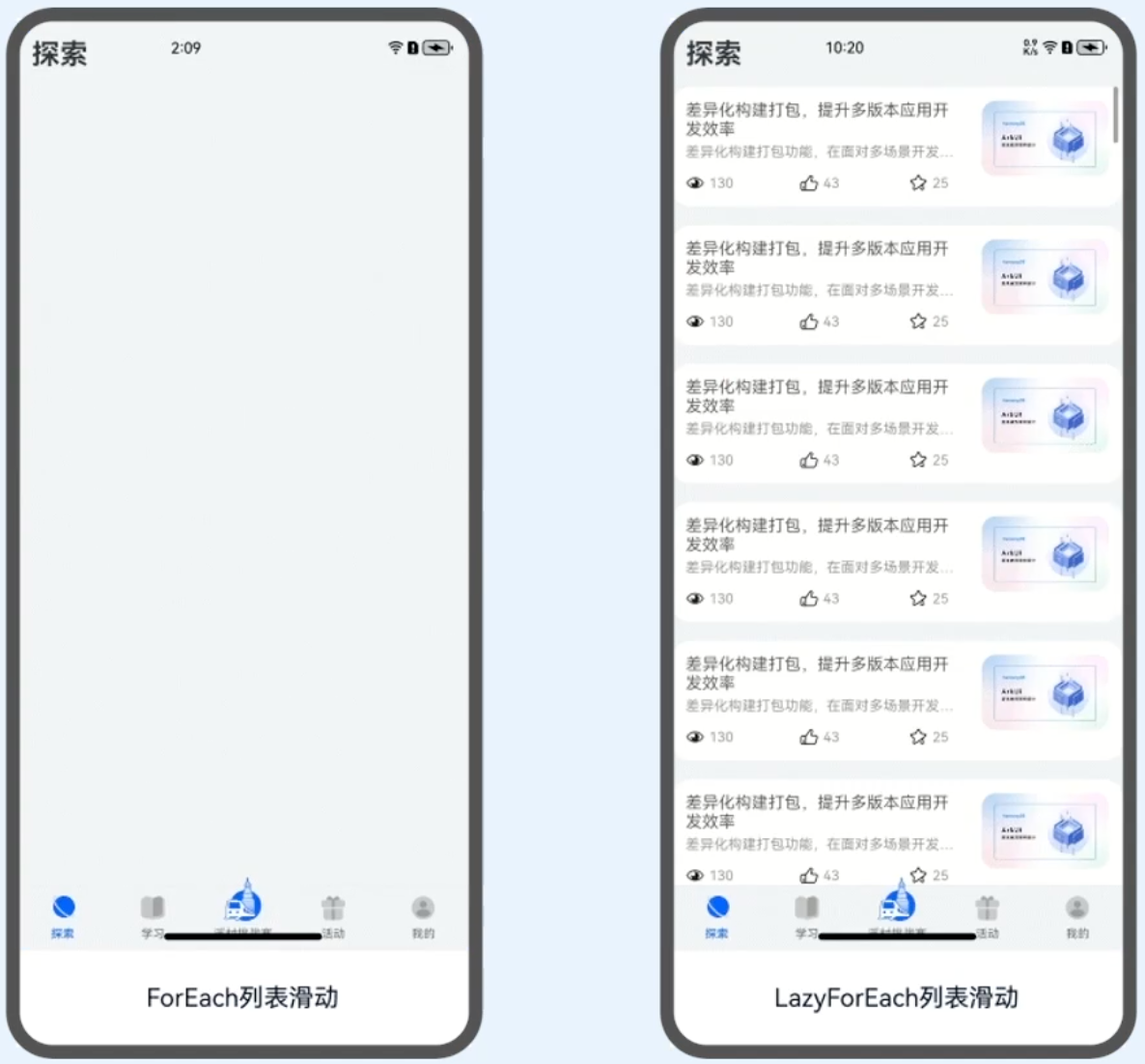
对比案例1:10000条数据量下ForEach和LazyForEach滑动对比。结果:ForEach情况下,滑动过程中会有白块出现,而LazyForEach则很丝滑。
针对长列表加载这一场景,对列表渲染时间、页面滑动帧率、应用内存占用等方面带来优化,提升性能和用户体验的手段有如下4种:
- 懒加载:提供列表数据按需加载能力,解决一次性加载长列表数据耗时长、占用过多资源的问题,可以提升页面响应速度。
- 缓存列表项:提供屏幕可视区域外列表项长度的自定义调节能力,配合懒加载设置可缓存列表项参数,通过预加载数据提升列表滑动体验。
- 组件复用:提供可复用组件对象的缓存资源池,通过重复使用已经创建过并缓存的组件对象,降低相同组件短时间内频繁创建和销毁的开销,提升组件渲染效率。
- 布局优化:使用扁平化布局方案,减少视图嵌套层级和组件数,避免过度绘制,提升页面渲染效率。
下面以“HarmonyOS世界”中首屏的长列表加载为例,对比分析如下三个关键指标:
- 完全显示所用时间(Time To Full Display, TTFD) :表示应用生成具有完整内容的第一帧所用的时间,包括在第一帧之后异步加载的内容。
- 丢帧率(Janky Frames) :表示一个时间周期内的丢帧比率,是指一个时间周期内有问题的帧比例。HarmonyOS系统要求每一帧都要在11.1ms (90Hz刷新率)内绘制完成,如果页面没有在11.1ms内完成这一帧的绘制,就会出现丢帧。部分丢帧一般用户肉眼是感知不到的,只有出现连续丢帧用户才有明显感知。
- 独占内存(Unique Set Size, USS) :一个进程所占用的私有内存,即该进程独占的内存。它反映了运行一个特定进程真实的边际成本(增量成本)。
对比案例:不同数据量下ForEach和LazyForEach性能对比
针对长列表这一场景,在本地模拟了10、100、1000、10000条数据,分别使用ForEach、LazyForEach,来测试关闭和开启懒加载情况下的完全显示所用时间、列表挂载时间、独占内存、丢帧率。得到的数据如下所示:
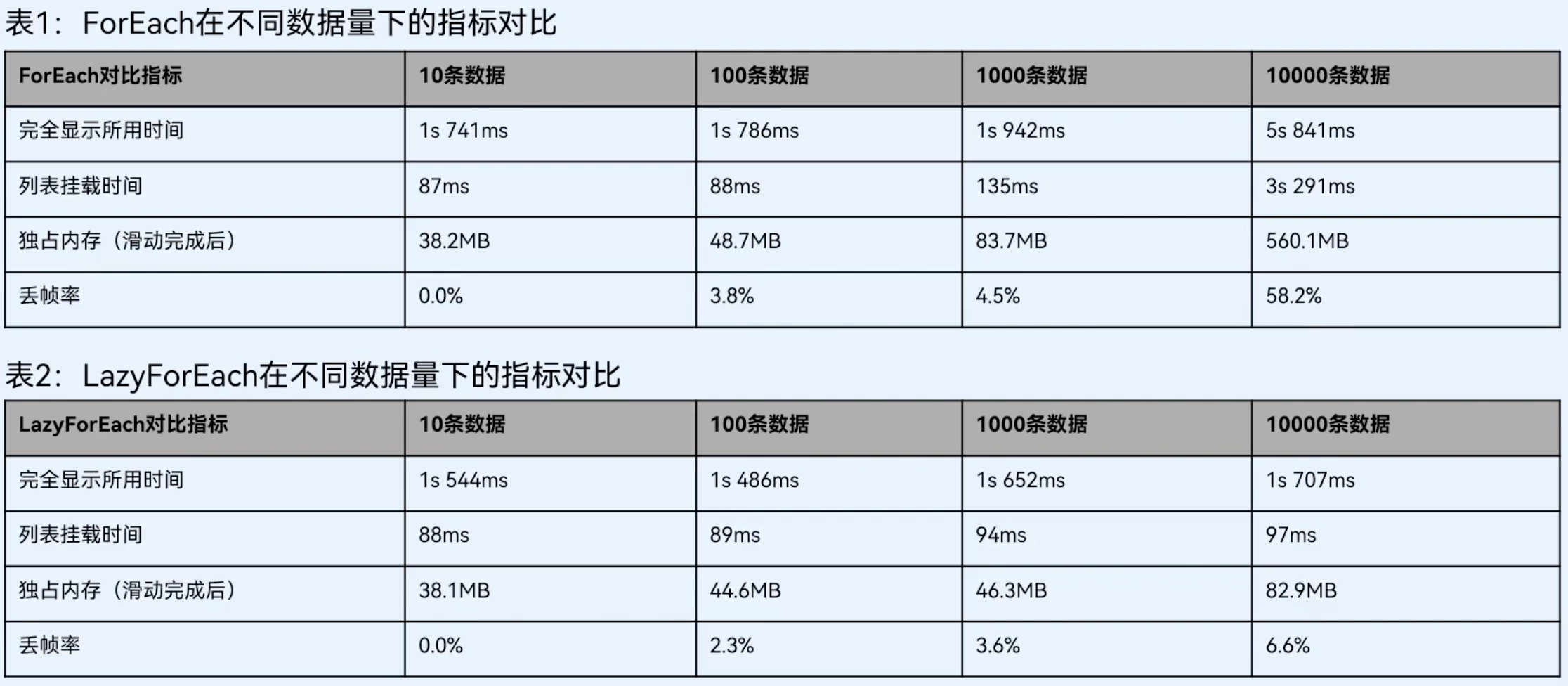
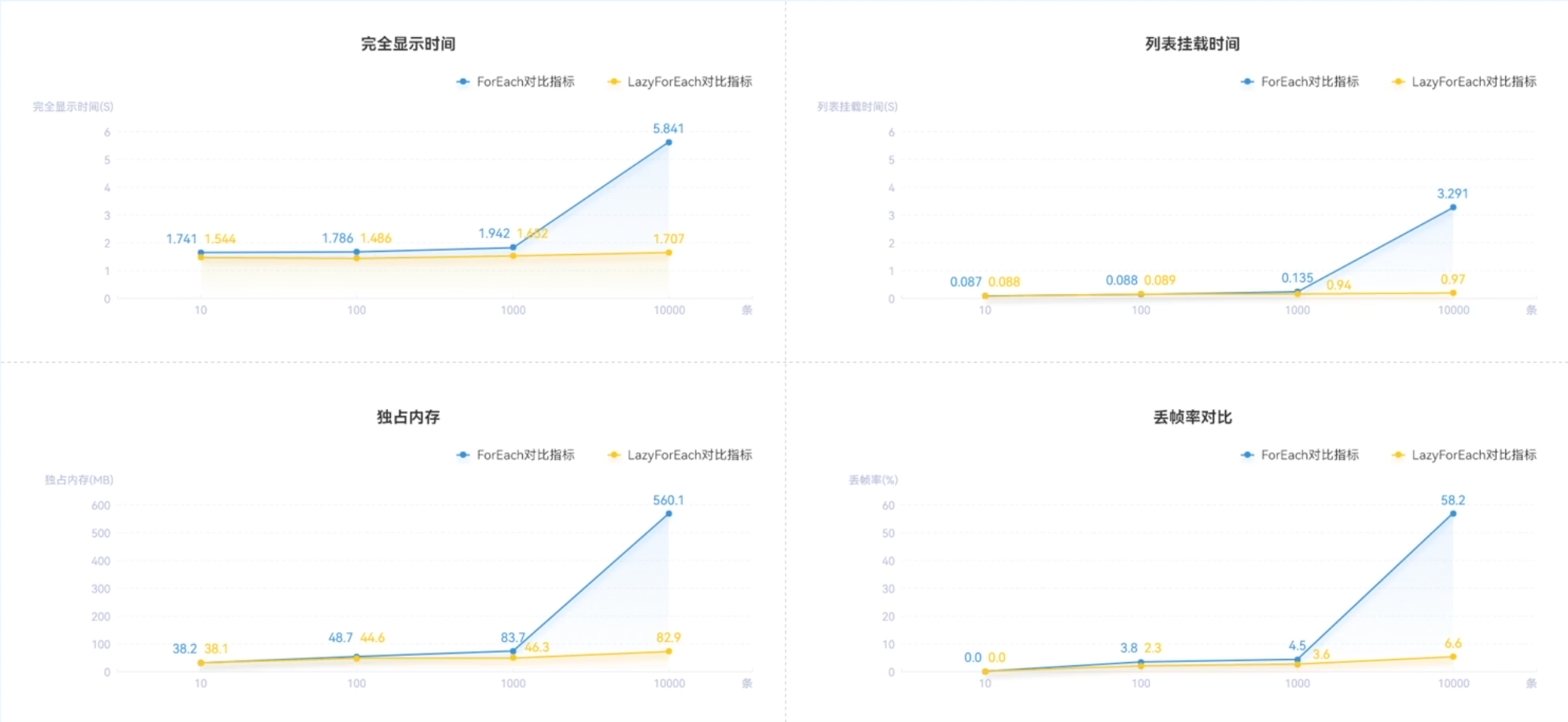
从上图可以看出数据量很小(小于1000)时,可以使用ForEach加载列表,因为ForEach使用上简洁一点。
优化1:懒加载
鸿蒙提供2种渲染方式
LazyForEach
LazyForEach完整语法如下:
LazyForEach( dataSource: IDataSource, // 数据源 itemGenerator: (item: any, index?: number) => void, // 生成子组件 keyGenerator?: (item: any, index?: number) => string // 生成唯一键值 )
三个关键参数说明如下:
| 参数 | 类型 | 是否必填 | 说明与核心作用 |
|---|---|---|---|
dataSource |
IDataSource |
是 | 数据源。需要开发者自行实现 IDataSource 接口,这是 LazyForEach 能动态加载数据的基础。 |
itemGenerator |
(item: any, index?: number) => void |
是 | 子组件生成函数。接收数据和索引,每次迭代必须且只能生成一个子组件(通常放在 ListItem 中)。函数体必须使用大括号 {}。 |
keyGenerator |
(item: any, index?: number) => string |
否 | 键值生成函数。为每个数据项生成唯一且固定的键值(key),用于高效识别和复用组件。强烈建议提供,否则默认使用索引生成键值,可能导致数据位置变化时不必要的组件重建。 |
关键使用须知
-
必须实现
IDataSource接口:你需要创建一个类,实现totalCount()、getData(index)、registerDataChangeListener()和unregisterDataChangeListener()方法。这是使用LazyForEach的前提。 -
键值(Key)的重要性:
keyGenerator生成的键值应确保唯一性和一致性。唯一性指不同数据项的键值不同;一致性指数据项内容不变时,其键值也应不变。这能最大化组件复用效率。 -
性能优化提示:
-
避免耗时操作:不应在
keyGenerator或itemGenerator函数中执行JSON.stringify等耗时操作,以免引起滑动卡顿。 -
使用缓存:可以为
List组件设置.cachedCount(数值)属性,用于预加载屏幕可视区域外的列表项,以提升快速滑动时的体验。 -
组件轻量化:
itemGenerator生成的子组件应尽量保持结构简单,避免过深的嵌套。
-
进阶应用与排查
为了帮你更系统地掌握 LazyForEach,这里整理了一些重要的技术点:
-
数据更新监听:
IDataSource接口中的DataChangeListener提供了一系列方法(如onDataAdd,onDataDelete,onDataChange),用于在数据变化时精确通知 UI 更新,这是实现动态列表的关键。 -
常见问题排查:
-
列表滑动白屏:通常是加载速度跟不上滚动速度,可以尝试增加
.cachedCount的数值。 -
数据更新后UI不变:检查是否在数据源修改后,正确调用了
DataChangeListener中对应的通知方法(如notifyDataChange)。
-
ForEach
ForEach语法结构如下:
ForEach( arr: Array<any>, // 数据源数组或对象 itemGenerator: (item: any, index?: number) => void, // 生成子组件 keyGenerator?: (item: any, index?: number) => string // 生成唯一键值 )
三个参数说明:
| 参数 | 类型 | 是否必填 | 说明与核心作用 |
|---|---|---|---|
arr |
Array<any> |
是 | 数据源。可以是普通数组或实现了 Iterable 接口的对象,如 [‘A’, ‘B’, ‘C’]。这是 ForEach 渲染的基础。 |
itemGenerator |
(item: any, index?: number) => void |
是 | 子组件生成函数。接收当前数据项 item 和可选的 index 索引,每次调用必须返回一个且仅一个组件。 |
keyGenerator |
(item: any, index?: number) => string |
强烈建议提供 | 键值生成函数。为每个数据项生成一个唯一、稳定的字符串键值(key),用于ArkUI框架内部高效识别和复用组件。如果不提供,则默认使用 index 作为key。 |
ForEach数据加载流程
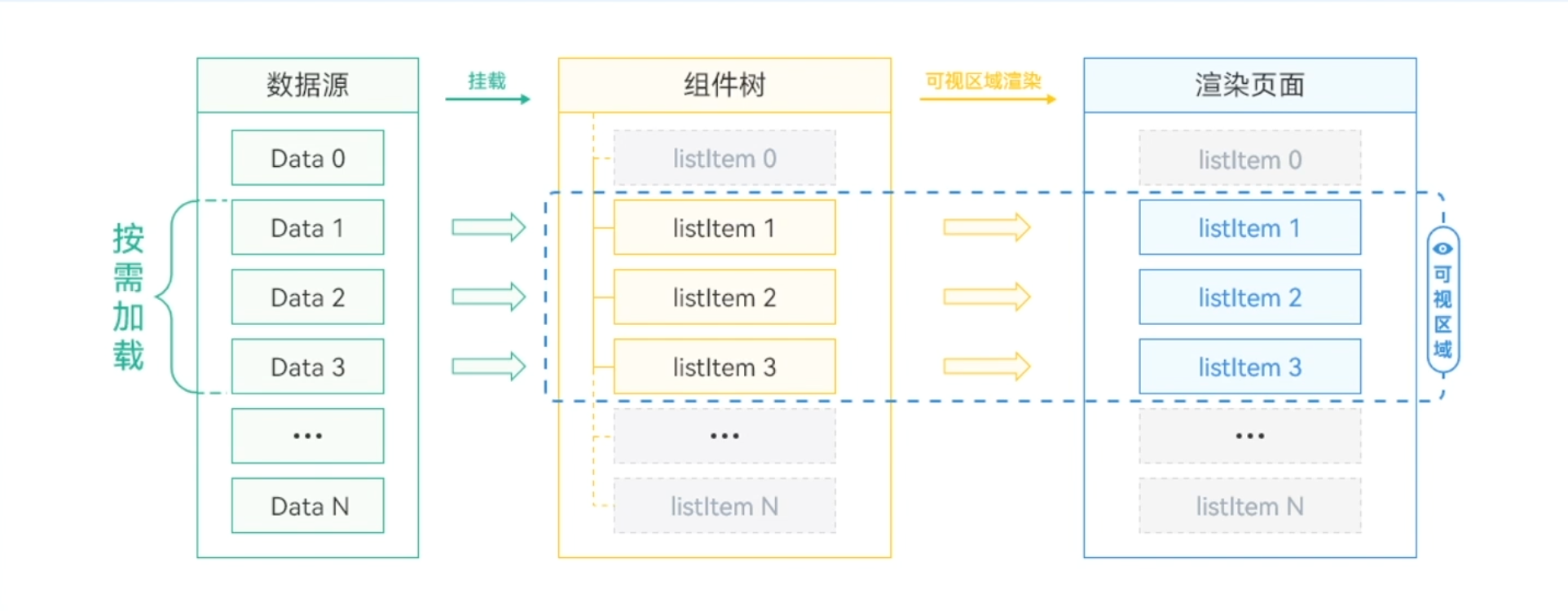
如果列表数据较少,数据一次性全量加载不是性能瓶颈时,可以直接使用ForEach。ForEach会从列表数据源一次性加载全量数据。
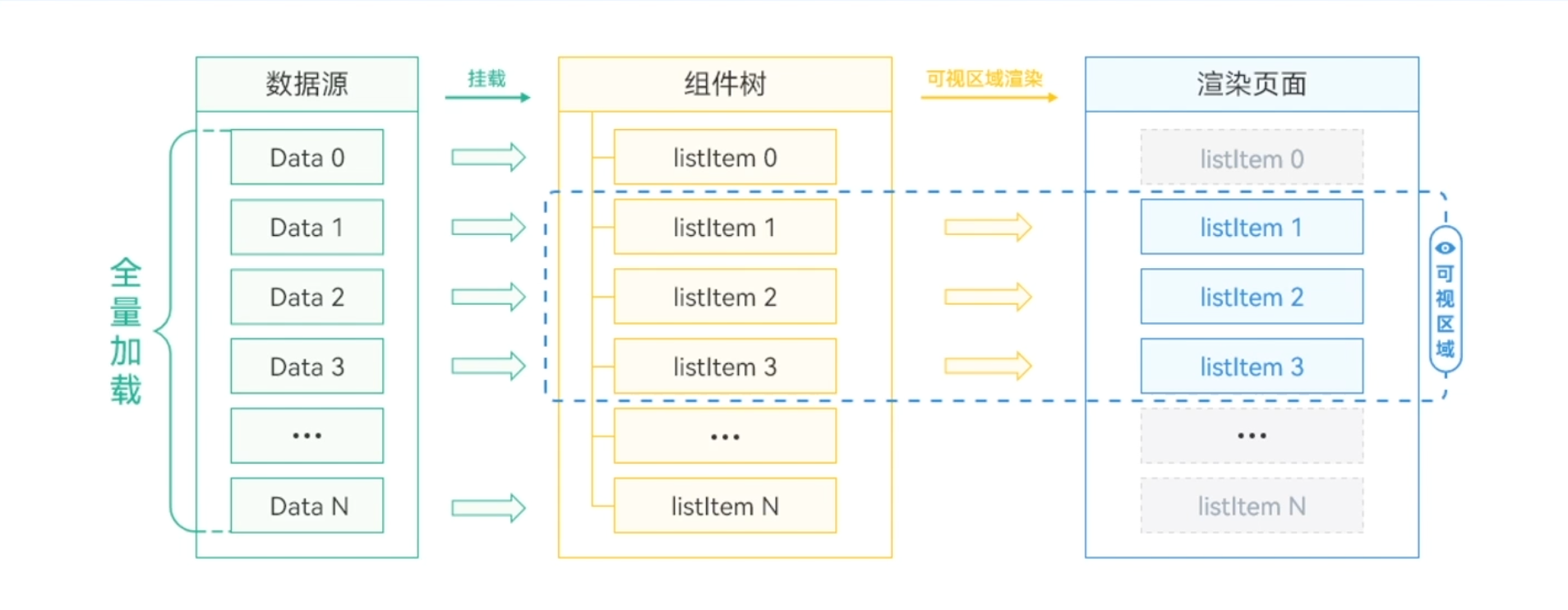
LazyForEach数据加载流程
LazyForEach实现了按需加载,针对列表数据量大、列表组件复杂的场景,减少了页面首次启动时一次性加载数据的时间消耗,减少了内存峰值。
优化2:缓存列表项
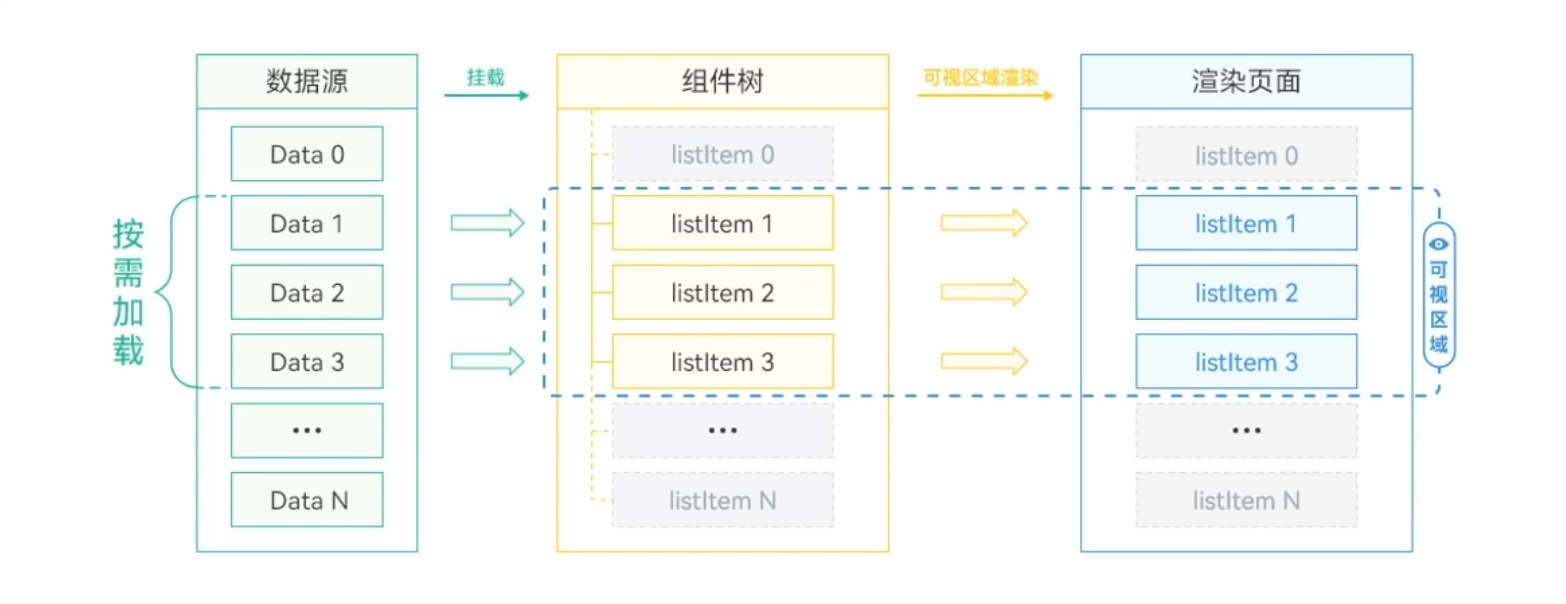
滑动白块现象分析
下图示意图中,页面一次可以显示3条数据,如果不提前缓存部分数据,当下滑到列表最底端时,再快速下滑,可能会引起“滑动白块”的现象。这是因为上一次只请求了屏幕上的3条数据,如果滑动速度过快,则会导致数据来不及加载而出现白块。在追求极致性能的同时,应该避免这样糟糕的用户体验。
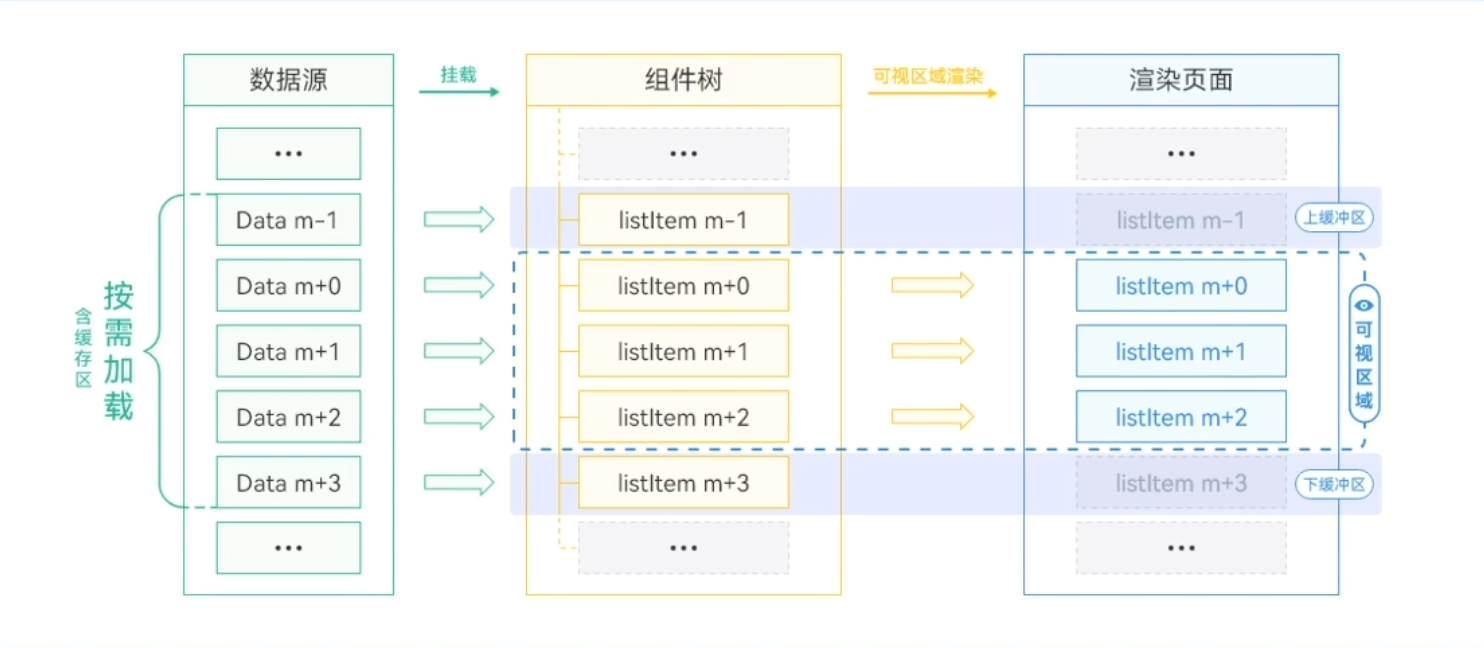
缓存列表项
LazyForEach懒加载可以通过设置cachedCount来指定缓存数量,在设置cachedCount后,除屏幕内显示的Listltem组件外,还会预先将屏幕可视区外指定数量的列表项数据缓存。这样当一个屏幕数据加载完成后,再次向下滑动时,会先加载上一次请求的数据,加载完成后,再加载本次请求的数据。
cachedCount建议值
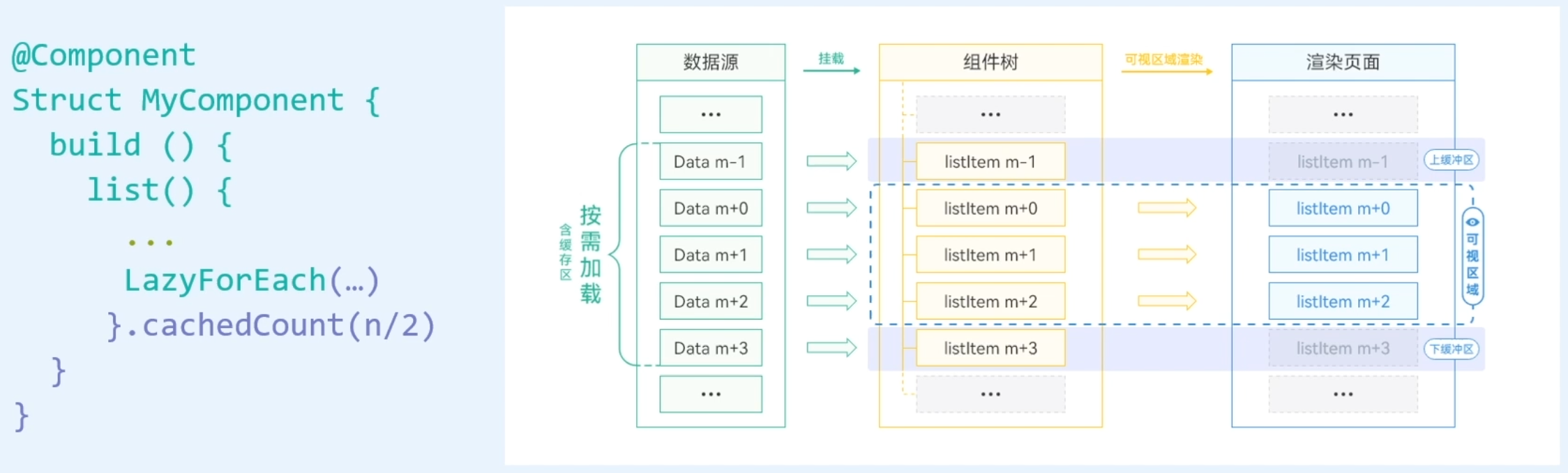
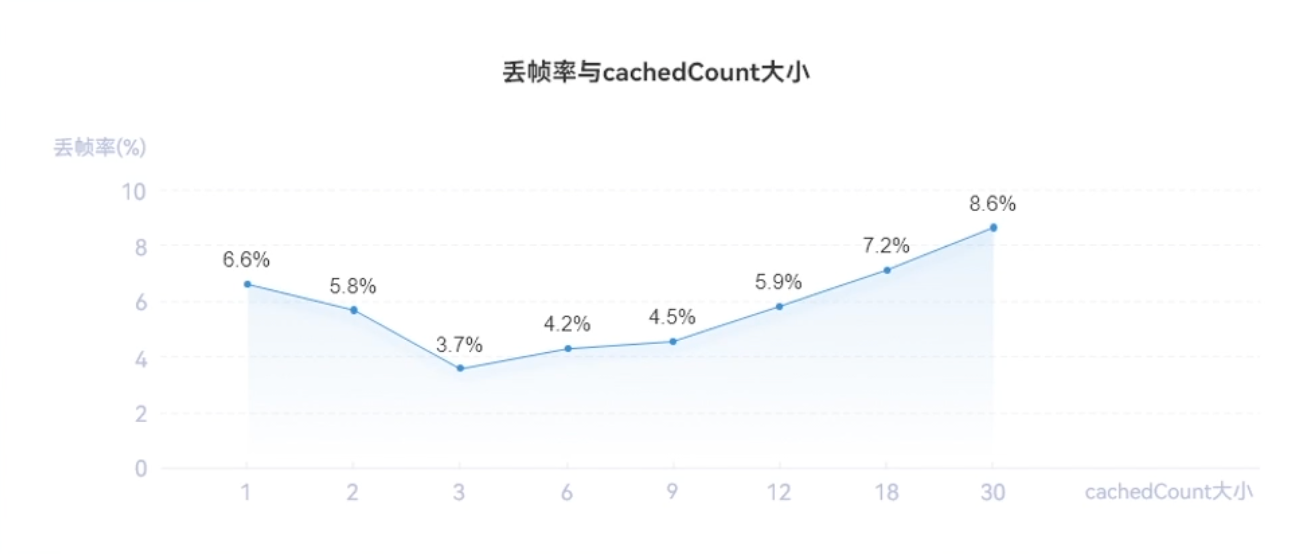
一般而言,缓存的cachedCount=n/2(n为一屏显示的列表数)的时候,效果较好。在实际开发中也要根据实际场景合理去设置缓存数量:
- 例如列表项中需要显示网络数据,而网络数据加载较慢,为了提升列表信息的浏览效率和浏览体验,我们可以适当的多设置一些缓存数量(cachedCount大于n/2);
- 如果列表中需要加载一些大图或者视频等,这些数据占用的内存较大,为了减少内存占用,我们需要适当减少缓存数量的设置(cachedCount小于n/2)
因此,在实际场景中,需要不断尝试验证,设置适当的缓存数量,来达到体验和内存的平衡。
对于n=6的页面,我们做了cachedCount对列表滑动帧率影响的实验对比,结果如下:
优化3:组件复用
组件复用原理
HarmonyOS应用框架提供了组件复用能力,可复用组件从组件树上移除时,会进入到一个回收缓存区。后续创建新组件节点时,会复用缓存区中的节点,节约组件重新创建的时间。尤其在列表等场景下,其自定义子组件具有相同的组件布局结构,列表更新时仅有状态变量等数据差异。通过组件复用可以提高列表页面的加载速度和响应速度。
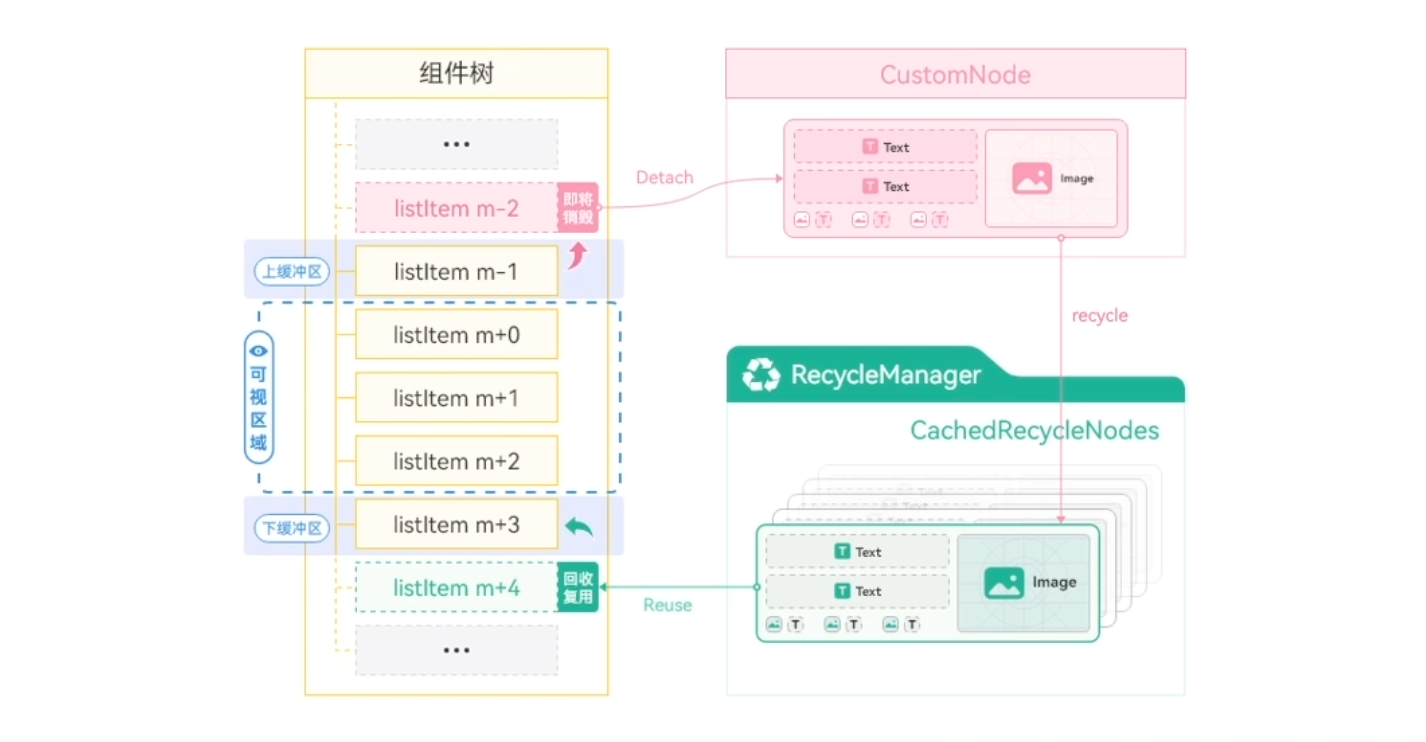
组件复用关键代码
以ArticleCardView组件为例,说明组件复用步骤:

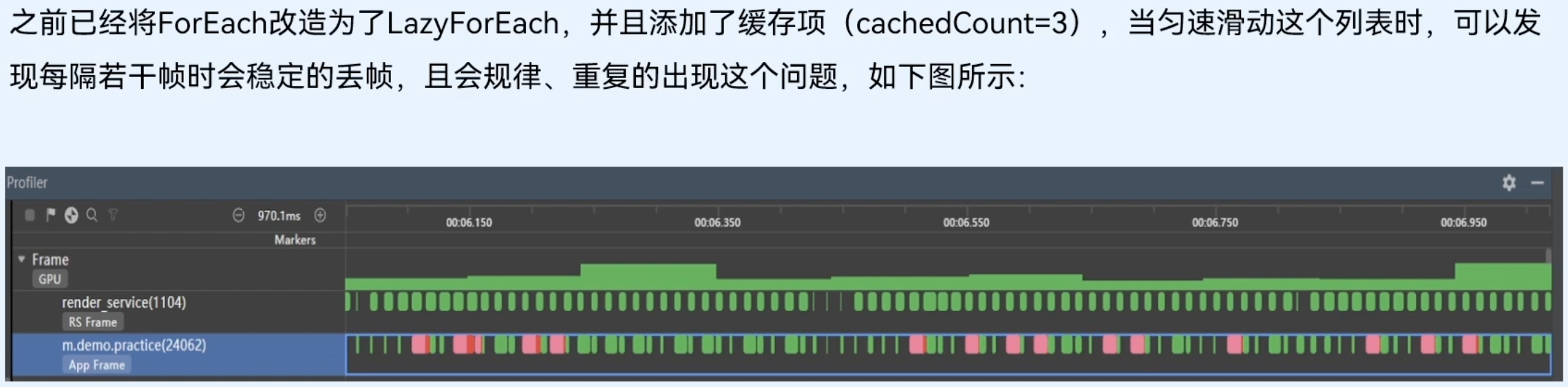
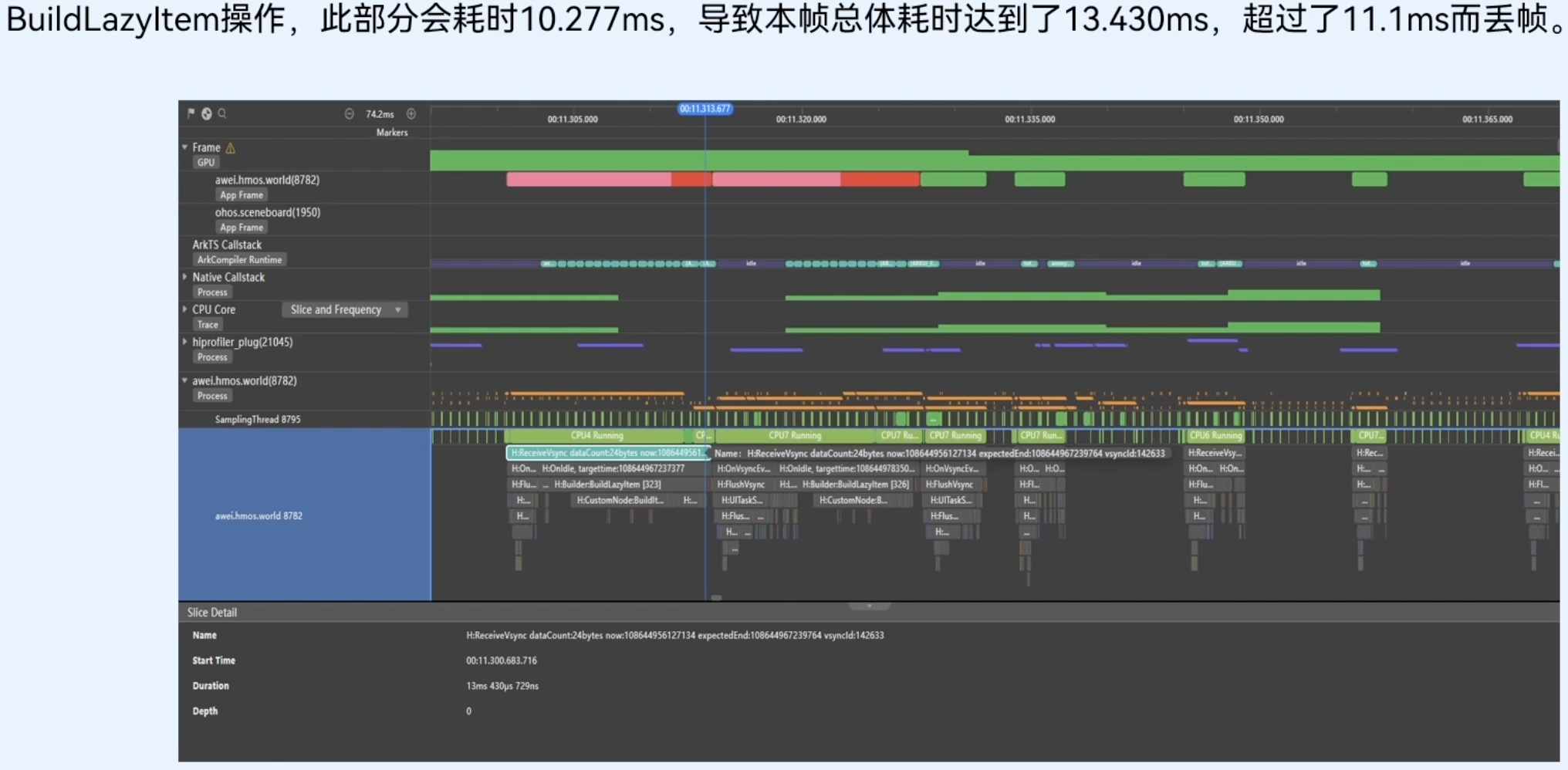
组件复用前长列表性能分析
组件复用后长列表性能分析
将代码进行改造,对复用组件ArticleCardView添加@Reusable注解,启用组件复用的相关代码后,以相同均匀速度滑动这个列表,得到的应用帧率检测情况如下:
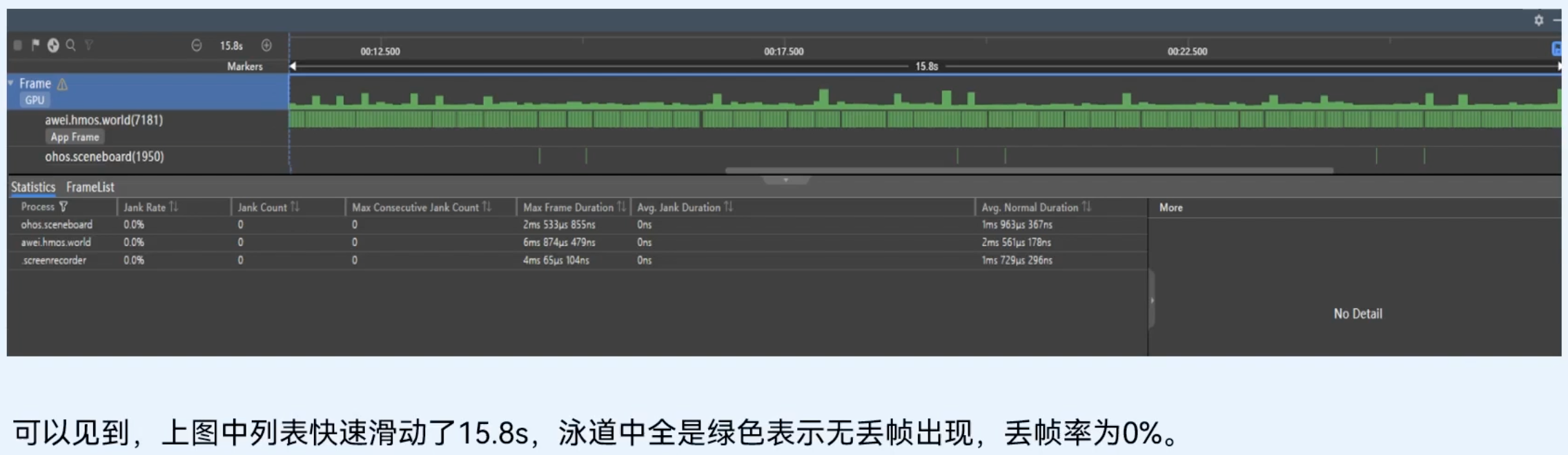
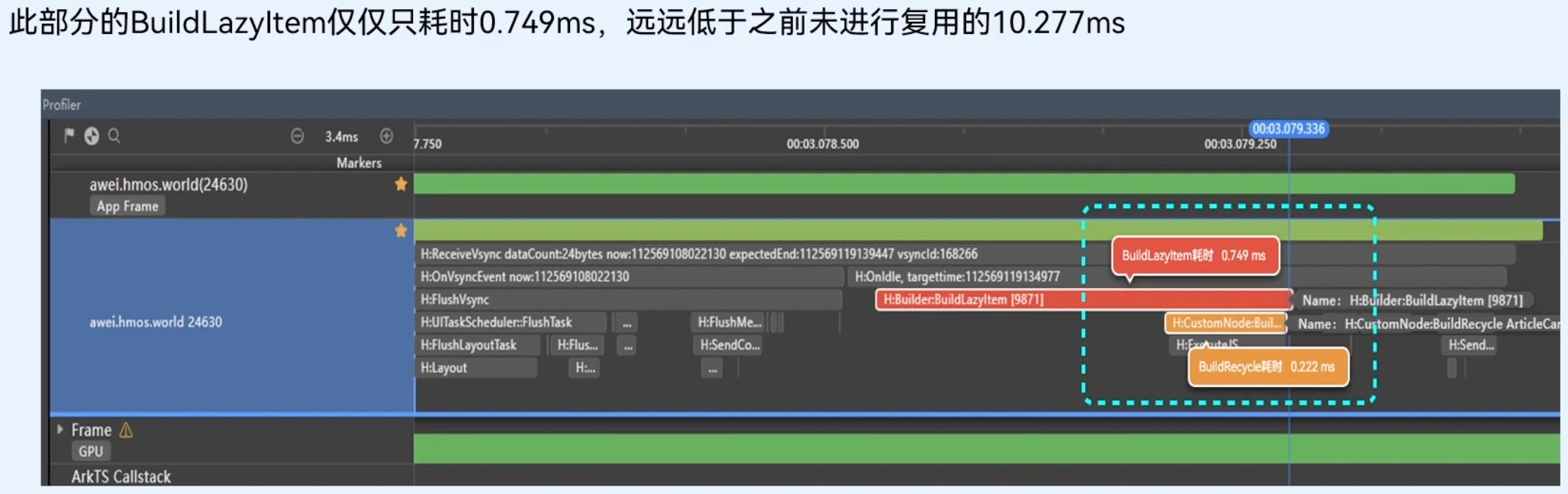
组件复用前、后长列表性能对比
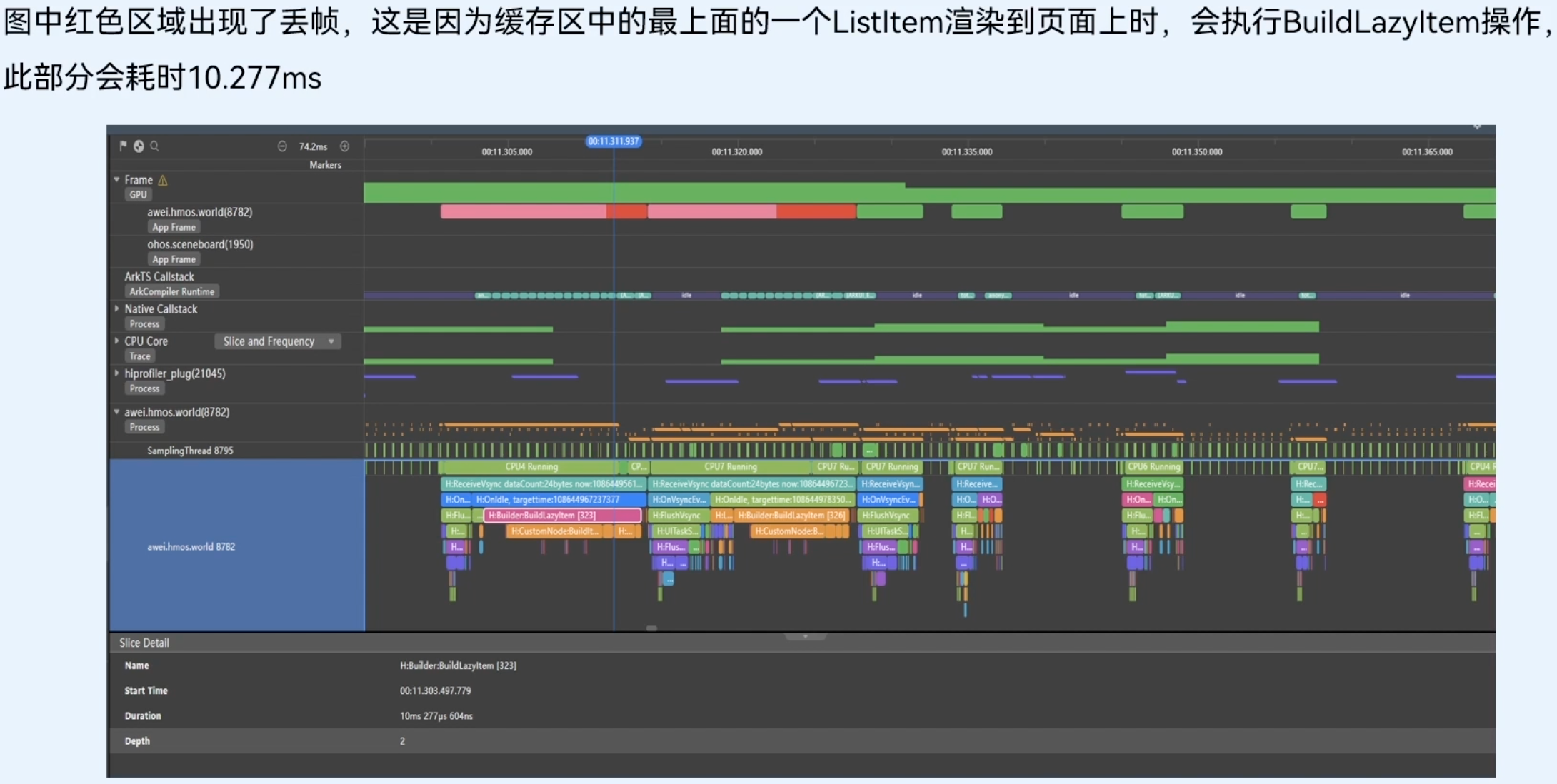
List列表开启了组件复用,不会执行BuildLazyltem这个耗时操作(耗时10.277ms),后续创建新组件节点时,会直接复用缓存区中的节点(耗时0.97ms),这样就大幅节约了组件重新创建的时间。

优化4:布局优化
列表不同于其他布局,包含了大量重复循环的Listltem,所以对每一个Listltem的布局优化格外重要。错误的布局方式可能会导致组件树和嵌套层数过多,在创建和布局绘制阶段产生较大的性能开销,导致界面卡顿。合理使用布局,减少嵌套层数,能提高布局效率。

布局过度嵌套会导致应用内存增加,且会影响应用的帧率导致丢帧增加,所以开发者在写列表这类循环组件的代码时,需要特别考虑对其布局进行优化。一般而言布局的最大嵌套层级控制在5-8层左右即可,过度的优化布局会导致代码开发难度加大,代码不易于阅读理解,增加后续的维护成本,不利于多设备的适配,且也不会带来特别显著的性能提升。

课程总结
使用LazyForEach懒加载这项技术后,相比ForEach这种加载方式,在列表数据量较小(100条内)且数据一次性全量加载不是性能瓶颈时,两者各项性能指标差异不大。但当列表数据较长特别是达到10000条数据量后,ForEach的上述4项性能指标会有“指数级别”的显著劣化,滑动会出现明显的卡顿,甚至会出现应用crash等现象;而LazyForEach因为采用了懒加载技术能明显减少首屏完全显示所用时间,降低应用的独占内存,提高页面滑动帧率,带来更好的性能。在10000条数据量下,其各项对比指标数据如下所示:


作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 1
1 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)