
昇腾系列--yolo26移植:使用atc将模型yolo26转换成om,基于昇腾310推理并计算MAP,误差达到千分之一
本文介绍ATC工具使用,yolo26模型转换,模型移植,以及模型MAP计算方法,最终验证om模型精度与原始模型pt精度误差达到千分之一
一、环境搭建
环境信息
|
ultralytics |
8.4.3 |
| pytorch |
2.9.1 |
| cann |
8.0.1 |
| HDK |
24.1.1.3 |
| 硬件信息 | Atlas300I |
driver安装包下载:A300-3010-npu-driver_24.1.1.3_linux-aarch64.run
fireware安装包下载:A300-3010-npu-firmware_7.5.0.9.220.run
cann安装包下载:Ascend-cann-toolkit_8.0.1_linux-aarch64.run
基础环境搭建参考:Qwen2.5-Omni-7B环境搭建及aisbench压测指导
yolo26移植代码开源地址:yolo26-npu
二、模型转换
1、将模型yolo26s.pt导出onnx格式
python3 pth2onnx.py --pt ./models/yolo26s.pt
pth2onnx.py 源代码如下:
import argparse
from ultralytics import YOLO
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--pt', default="./models/yolo26s.pt", help='pt file')
args = parser.parse_args()
model = YOLO(args.pt)
onnx_model = model.export(format="onnx", dynamic=True, simplify=True, opset=11)
if __name__ == '__main__':
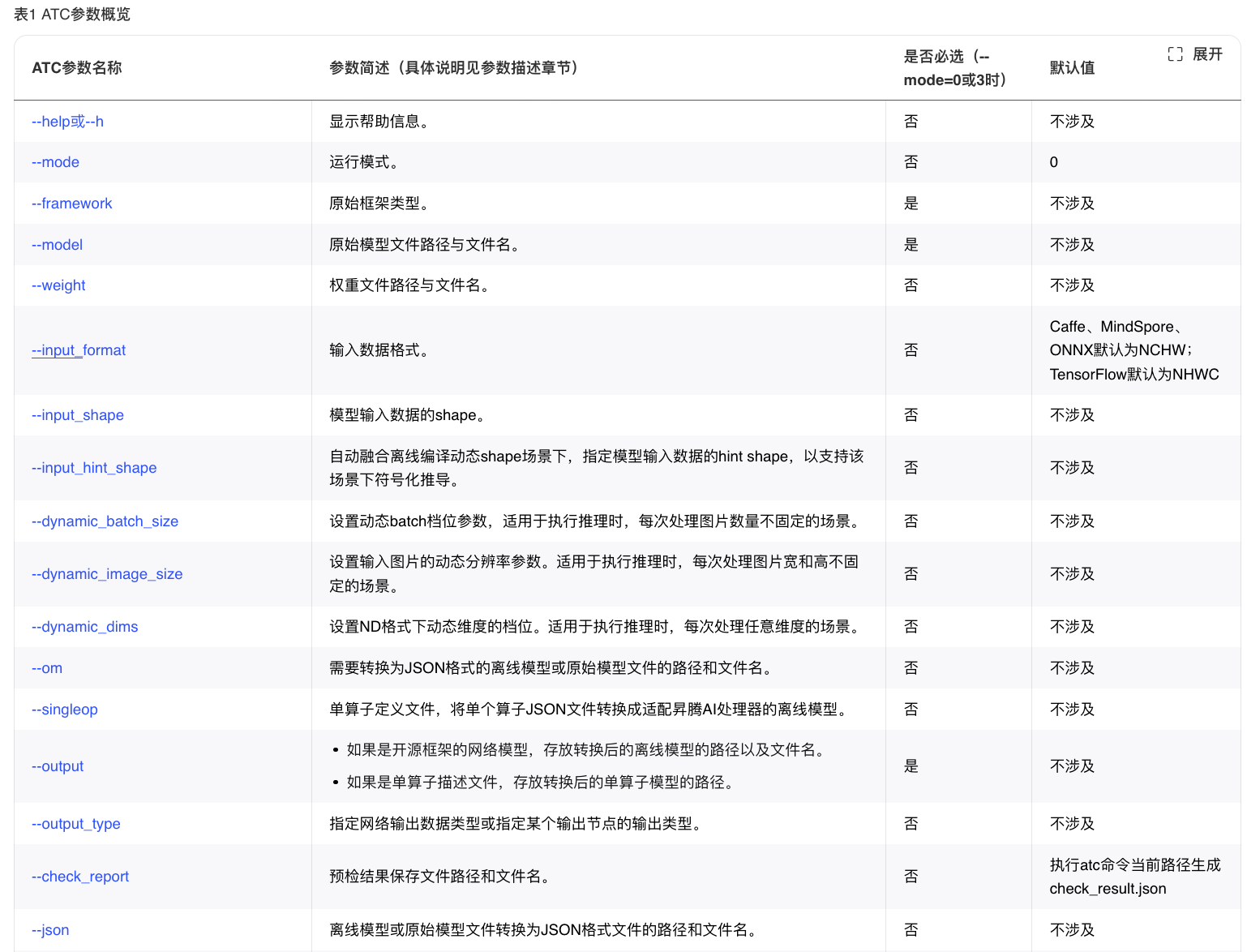
main()2、atc工具使用说明
文档地址:ATC工具(8.5.0)参数说明
3、将onnx模型转换成om
atc --framework=5 \
--model=./models/yolo26s.onnx \
--input_format=NCHW \
--input_shape='images:1,3,640,640'\
--output_type=FP32 \
--output=./models/yolo26s_bs1 \
--log=info \
--soc_version=Ascend310
--input_shape: 模型入参尺寸 1*3*640*640
--input_format: 模型入参格式,N 是batchsize,C 图像通道,H 图像高,W 图像宽
--output_type: 模型输出数值是FP32
--soc_version: 推理环境使用的芯片型号
| 推理设备 | soc_version |
| Atlas300I | Ascend310 |
|
Atlas300V |
Ascend310P3 |
|
Atlas300I Pro |
Ascend310P3 |
| Atlas300V Pro | Ascend310P3 |
| Atlas300I Duo | Ascend310P3 |
| Atlas800T A2 | Ascend910B3 |
| Atlas800I A2 | Ascend910B4 |
三、模型推理
推理脚本inference.py代码如下:
import os
import json
import argparse
import torch
import numpy as np
from ais_bench.infer.interface import InferSession
from ultralytics.models.yolo.detect import DetectionPredictor
from ultralytics import YOLO
### patch cpu lettebox begin #####
def patch_pre_transform(self, im):
same_shapes = len({x.shape for x in im}) == 1
self.model.pt = False
letterbox = LetterBox(self.imgsz, auto=same_shapes and self.model.pt, stride=self.model.stride)
return [letterbox(image=x) for x in im]
from ultralytics.data.augment import LetterBox
from ultralytics.engine.predictor import BasePredictor
BasePredictor.pre_transform = patch_pre_transform
### patch cpu lettebox end #####
class OM_Conf():
def __init__(self):
self.pt=False
self.stride = 32
self.fp16 = False
self.overrides = {'task': 'detect', 'data': '/usr/local/lib/python3.10/dist-packages/ultralytics/cfg/datasets/coco.yaml', 'imgsz': 640, 'single_cls': False, 'model': './mo
dels/yolo26s_bs1.om', 'conf': 0.25, 'batch': 1, 'save': True, 'mode': 'predict', 'save_txt': True}
self.names = {0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11:
'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe', 24:
'backpack', 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard', 32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball
glove', 36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup', 42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'app
le', 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair', 57: 'couch', 58: 'potted plant', 59: 'bed', 60:
'dining table', 61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'ref
rigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'}
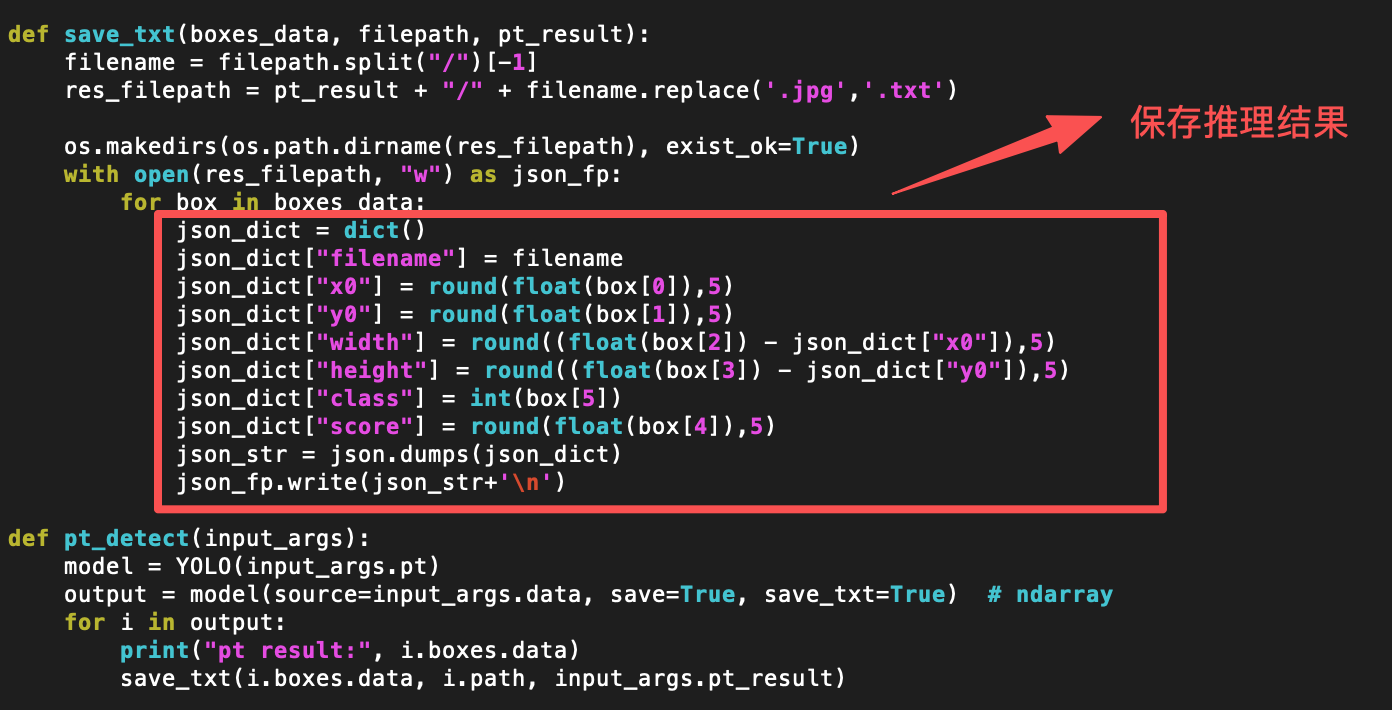
def save_txt(boxes_data, filepath, pt_result):
filename = filepath.split("/")[-1]
res_filepath = pt_result + "/" + filename.replace('.jpg','.txt')
os.makedirs(os.path.dirname(res_filepath), exist_ok=True)
with open(res_filepath, "w") as json_fp:
for box in boxes_data:
json_dict = dict()
json_dict["filename"] = filename
json_dict["x0"] = round(float(box[0]),5)
json_dict["y0"] = round(float(box[1]),5)
json_dict["width"] = round((float(box[2]) - json_dict["x0"]),5)
json_dict["height"] = round((float(box[3]) - json_dict["y0"]),5)
json_dict["class"] = int(box[5])
json_dict["score"] = round(float(box[4]),5)
json_str = json.dumps(json_dict)
json_fp.write(json_str+'\n')
def pt_detect(input_args):
model = YOLO(input_args.pt)
output = model(source=input_args.data, save=True, save_txt=True) # ndarray
for i in output:
print("pt result:", i.boxes.data)
save_txt(i.boxes.data, i.path, input_args.pt_result)
def om_detect(input_args):
om_model = InferSession(int(input_args.device_id), input_args.om)
#data
om_conf = OM_Conf()
dp = DetectionPredictor(overrides=om_conf.overrides)
dp.model = om_conf
dp.setup_source(input_args.data)
for dp.batch in dp.dataset:
paths, im0s, s = dp.batch
# Preprocess
im = dp.preprocess(im0s)
# Inference
im = np.ascontiguousarray(im).astype(np.float32) # contiguous
preds = om_model.infer([im])
preds_tensor = torch.from_numpy(preds[0])
# Postprocess
output = dp.postprocess(preds_tensor, im, im0s)
print("om result:", output[0].boxes.data)
save_txt(output[0].boxes.data, output[0].path, input_args.om_result)
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--data', default='./data', help='data path')
parser.add_argument('--pt', default='./models/yolo26s.pt', help='pt model path')
parser.add_argument('--om', default='./models/yolo26s_bs1.om', help='om model path')
parser.add_argument('--pt_result', default='./pt-result', help='pt model result path')
parser.add_argument('--om_result', default='./om-result', help='om model result path')
parser.add_argument('--device_id', default='0', help='device id')
input_args = parser.parse_args()
pt_detect(input_args)
om_detect(input_args)
if __name__ == '__main__':
main()
om模型推理逻辑与ultralytics保持一致:
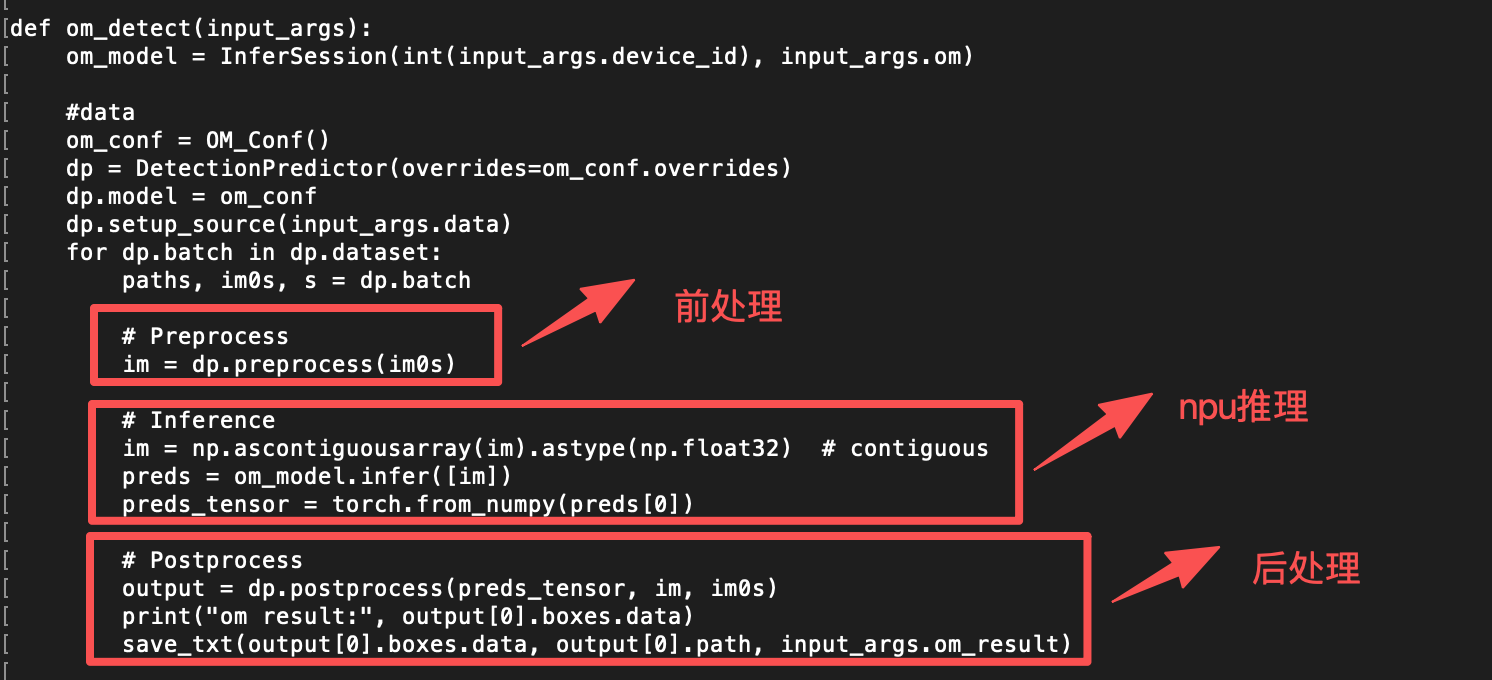
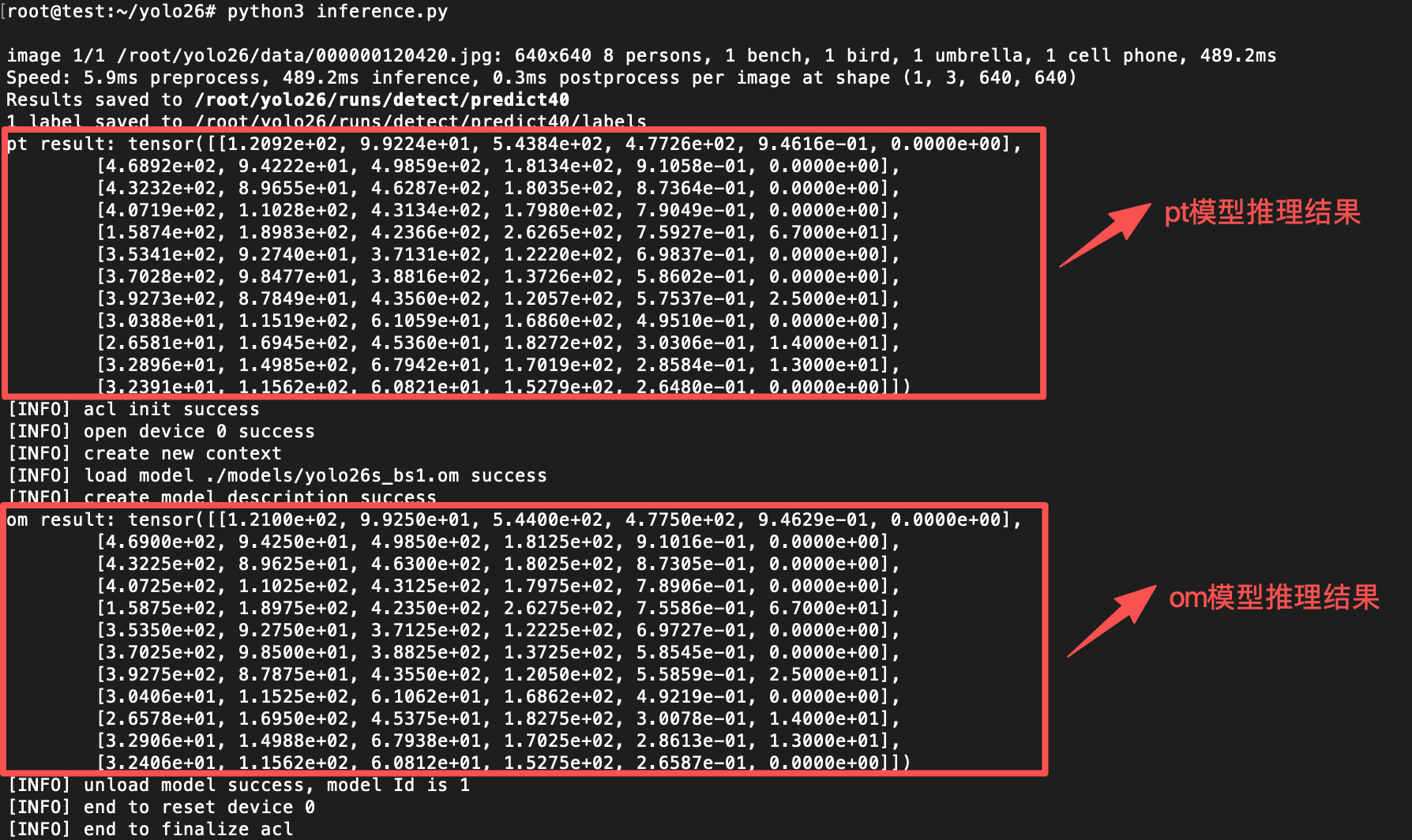
执行推理脚本并查看pt模型和om模型的推理结果
python3 inference.py
推理结果验证yolo26s.pt 和yolo26s_bs1.om 的推理结果一致
四、计算MAP
1、推理val2017数据集,并保存推理结果
每张图片保存一个推理结果

Map值计算,采用COCO数据集自带MAP计算方法,eval_map.py代码如下:
#!/usr/bin/python
import sys
import os
import json
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
# If necessary, pre-define category and its id
PRE_DEFINE_CATEGORIES = {0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: '
fire hydrant', 11: 'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear',
22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard', 32: 'sports ball'
, 33: 'kite', 34: 'baseball bat', 35: 'baseball glove', 36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup', 42: 'fork
', 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'don
ut', 55: 'cake', 56: 'chair', 57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: '
keyboard', 67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 't
eddy bear', 78: 'hair drier', 79: 'toothbrush'}
CATEGORY_ID = {0: 1, 1: 2, 2: 3, 3: 4, 4: 5, 5: 6, 6: 7, 7: 8, 8: 9, 9: 10, 10: 11, 11: 13, 12: 14, 13: 15, 14: 16, 15: 17, 16: 18, 17: 19, 18: 20, 19: 21, 20: 22,
21: 23, 22: 24, 23: 25, 24: 27, 25: 28, 26: 31, 27: 32, 28: 33, 29: 34, 30: 35, 31: 36, 32: 37, 33: 38, 34: 39, 35: 40, 36: 41, 37: 42, 38: 43, 39: 44, 40: 46, 41:
47, 42: 48, 43: 49, 44: 50, 45: 51, 46: 52, 47: 53, 48: 54, 49: 55, 50: 56, 51: 57, 52: 58, 53: 59, 54: 60, 55: 61, 56: 62, 57: 63, 58: 64, 59: 65, 60: 67, 61: 70,
62: 72, 63: 73, 64: 74, 65: 75, 66: 76, 67: 77, 68: 78, 69: 79, 70: 80, 71: 81, 72: 82, 73: 84, 74: 85, 75: 86, 76: 87, 77: 88, 78: 89, 79: 90}
def get_filename_as_int(filename):
try:
filename = filename.replace("\\", "/")
filename = os.path.splitext(os.path.basename(filename))[0]
return int(filename)
except:
raise ValueError("Filename %s is supposed to be an integer." % (filename))
def get_default_dict():
return {"image_id": -1, "category_id": -1, "bbox": [], "score": 0}
def xml2json(xml_files):
json_out = []
for xml_file in xml_files:
f = open(xml_file)
line = f.readline()
if len(line) == 0:
#print(xml_file)
continue
one = json.loads(line)
filename = one["filename"]
## The filename must be a number
image_id = get_filename_as_int(filename)
while line:
t_dict = get_default_dict()
t_dict['image_id'] = image_id
t_dict['category_id'] = CATEGORY_ID[one["class"]]
t_dict['bbox'] = [one['x0'], one['y0'], one['width'], one['height']]
t_dict['score'] = one['score']
json_out.append(t_dict)
line = f.readline()
if len(line) == 0:
break
one = json.loads(line)
f.close()
return json_out
def get_img_id(cocoDt_json):
ls = []
myset = []
for anno in cocoDt_json:
ls.append(anno['image_id'])
myset = {}.fromkeys(ls).keys()
return myset
'''
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.317
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.562
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.321
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.162
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.343
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.448
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.278
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.438
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.464
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.275
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.497
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.625
'''
def eval_compute(cocoDt_json,cocoGt_file):
cocoGt = COCO(cocoGt_file)#取得标注集中coco json对象
imgIds = get_img_id(cocoDt_json)
cocoDt = cocoGt.loadRes(cocoDt_json)#取得结果集中image json对象
imgIds = sorted(imgIds)#按顺序排列coco标注集image_id
cocoEval = COCOeval(cocoGt, cocoDt, "bbox")
cocoEval.params.imgIds = imgIds#参数设置
cocoEval.evaluate()#评价
cocoEval.accumulate()#积累
cocoEval.summarize()#总结
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(
description="Convert Pascal VOC annotation to COCO format."
)
parser.add_argument("--xml_dir", default='./om-result', help="Directory path to xml files.", type=str)
parser.add_argument("--instances_file", default='/data/LLMs/instances_val2017.json', help="COCO format instances_val2017.json.", type=str)
args = parser.parse_args()
xml_files= []
for root, dirs, files in os.walk(args.xml_dir):
for file in files:
xml_files.append(os.path.join(root, file))
# If you want to do train/test split, you can pass a subset of xml files to convert function.
print("Number of xml files: {}".format(len(xml_files)))
detJson = xml2json(xml_files)
eval_compute(detJson, args.instances_file)注意:yolo26s.pt 推理的标签与val2017数据集的标签需要映射
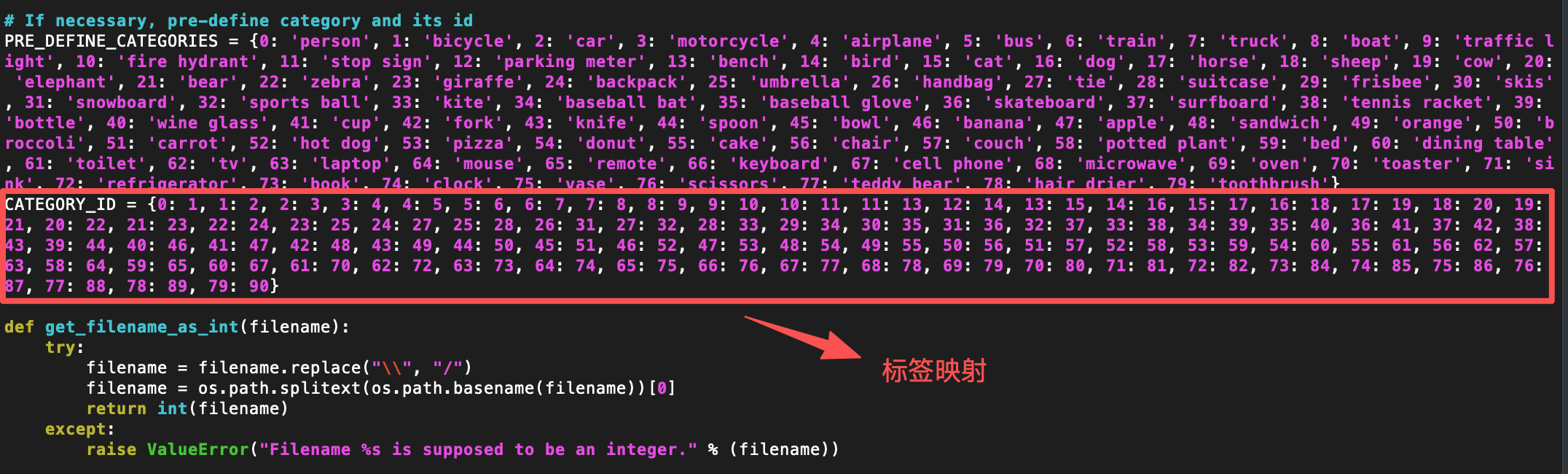
计算pt模型推理结果的MAP值
python3 eval_map.py --xml_dir pt-result/
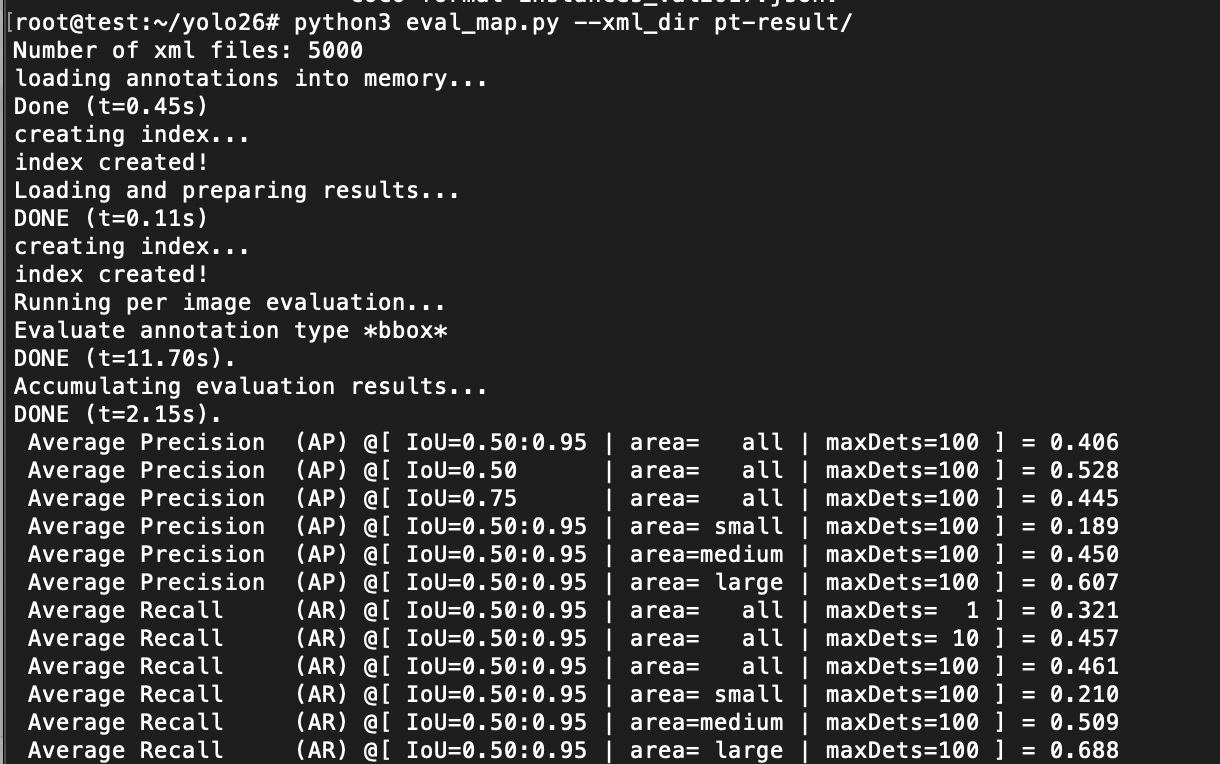
计算om模型推理结果的MAP值
python3 eval_map.py --xml_dir om-result/
yolo26模型的MAP值汇总,精度误差控制在千分之一以内
| 模型 |
pt 格式 MAP(0.50:0.95) |
om 格式 MAP(0.50:0.95) |
误差 |
| yolo26n | 0.33 | 0.33 | 0 |
| yolo26s | 0.406 | 0.405 | 0.001 |
| yolo26m | 0.455 | 0.454 | 0.001 |
| yolo26l | 0.469 | 0.469 | 0 |
| yolo26x | 0.499 | 0.498 | 0.001 |

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 21
21 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)