
DeepSeek-V3 MTP多token预测
作者:昇腾实战派MTP:Multi Token Prediction(多Token预测)
作者:昇腾实战派
DeepSeek知识地图:https://blog.csdn.net/weixin_45216014/article/details/156450562?spm=1011.2415.3001.5331
MTP:Multi Token Prediction(多Token预测)
一、MTP方法的作用
核心思想:通过解码阶段的优化,将1-token的生成,转变成multi-token的生成,从而提升训练和推理的性能。具体来说,在训练阶段,一次生成多个后续token,可以一次学习多个位置的label,进而有效提升样本的利用效率,提升训练速度;在推理阶段通过一次生成多个token,实现成倍的推理加速来提升推理性能。
二、MTP 方法的一些探索
(1)Blockwise Parallel Decoding
paper:Blockwise Parallel Decoding for Deep Autoregressive Models
Google在18年发表在NIPS上的论文:重点研究推理阶段加速的方法
模型结构:
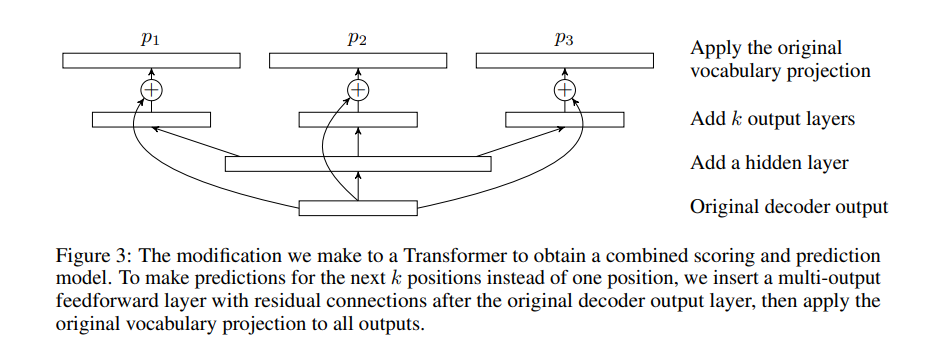
Transformer 修改细节: 为让模型一次预测未来 k 个位置(而非 1 个),在原始解码器输出层后加入带残差连接的多输出前馈层,再对所有输出应用原始词表映射。这一修改使模型融合了评分与预测功能,优化了解码流程,适用于需要批量预测的场景(如并行解码)。
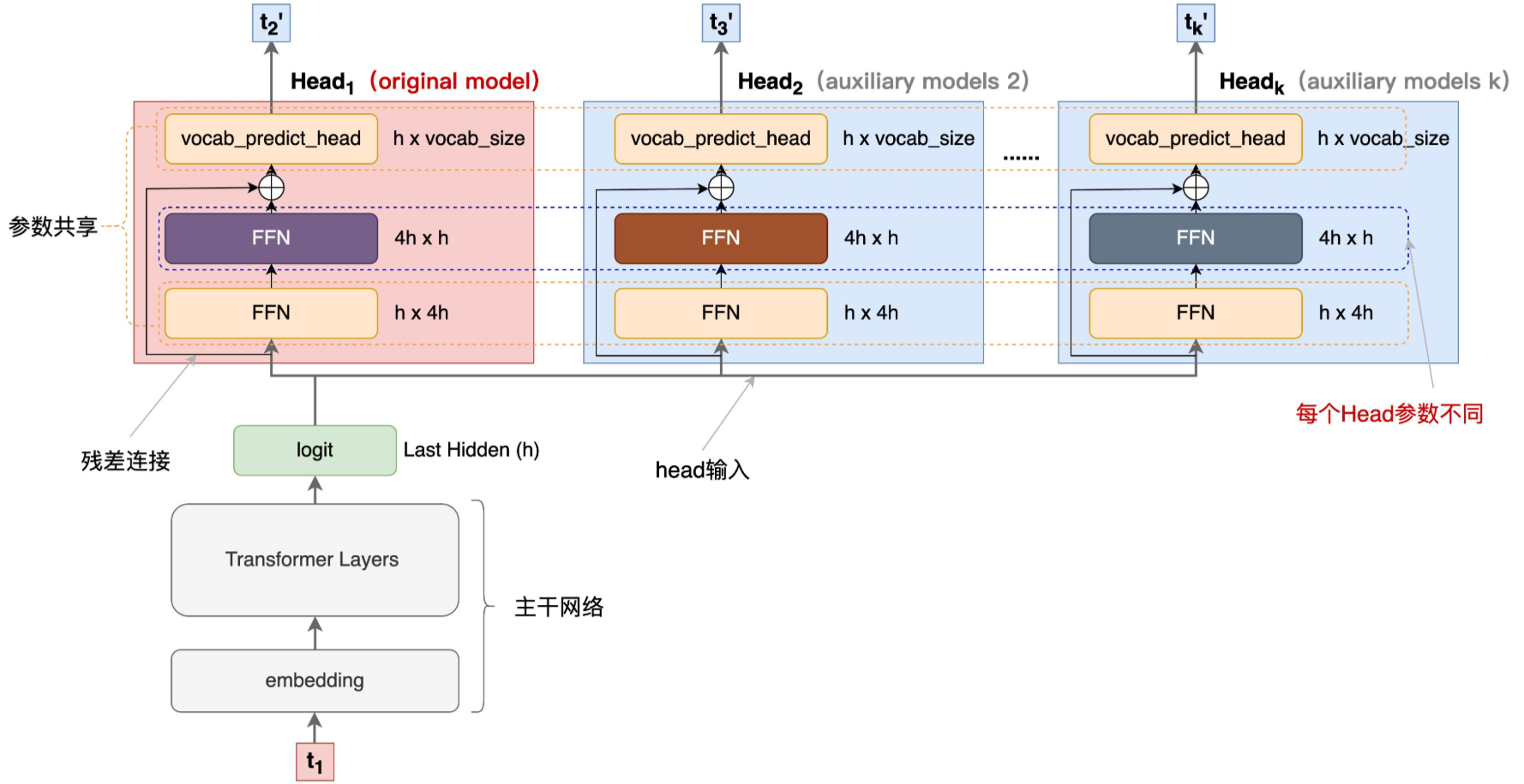
为了更直观的理解,补充embedding、Transformer Layers、FFN等模型结构:
-
主干网络是训练好的多层decode-only的Transformer网络,经过多层前向计算后,最终隐层输出 h h h 维度的 l o g i t logit logit 。
-
l o g i t logit logit 上面接了多个输出Head,每个Head负责预估一个token, H e a d 1 Head_1 Head1 负责预估 next token, H e a d 2 Head_2 Head2 负责预估 next next token , 以此类推
-
每个Head 有三层:
- 首先是**一个共享的FFN层,将logit做宽映射(** h → 4 h h \to 4h h→4h );
- 然后再过一个FFN层,将logit维度还原( 4 h → h 4h \to h 4h→h ),注意,这层FFN每个Head是特化的、非共享的。该层计算的结果再与原始模型的logit做残差连接;
- 最后再将结果送入到词表投影层(vocabulary projection 包括一个线性变换和一个Softmax),预估每个词的概率分布,最终通过某种采样方法(如:greedy,beam search等)生成token。注意,这个词表投影层是原预训练网络(original model)的投影矩阵+Softmax,多Head是共享的。
-
主干网络+ H e a d 1 Head_1 Head1 是original model,也就是pretrain的模型。其他Head是论文说的辅助网络(auxiliary model)
从上图,我们可以看到,输入一个 t 1 t_1 t1 并行的多个头一次输出 t 2 ′ , t 3 ′ , . . . t k ′ t_2^{'}, t_3^{'}, ... t_k^{'} t2′,t3′,...tk′
理解了网络细节,再看看论文中的并行推理过程就很好理解了。推理过程,论文中给出了三阶段描述,如图所示:
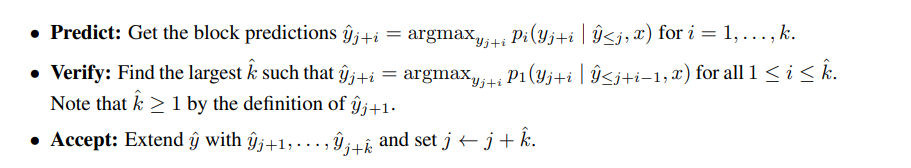
推理过程:
- 阶段1:predict (预测) ,利用 k k k 个Head一次生成 k k k 个token,每个Head生成一个token
- 阶段2:verify(验证), 将原始的序列和生成的 k k k 个token拼接,组成 P a i r < s e q u e n c e _ i n p u t , l a b e l > Pair<sequence\_input, label> Pair<sequence_input,label> ,如上图Verify阶段,黑框里是 s e q u e n c e _ i n p u t sequence\_input sequence_input ,箭头指向的是要验证的 l a b e l label label 。将组装的 k k k 个 P a i r < s e q u e n c e _ i n p u t , l a b e l > Pair<sequence\_input, label> Pair<sequence_input,label> 组成一个Batch,一次发给 H e a d 1 Head_1 Head1 做校验(Check H e a d 1 Head_1 Head1 生成的token是否跟 l a b e l label label 一致)
- 阶段3:accept(接受) : 选择 H e a d 1 Head_1 Head1 预估结果与 l a b e l label label 一致的最长的 k k k 个token,作为可接受的结果。
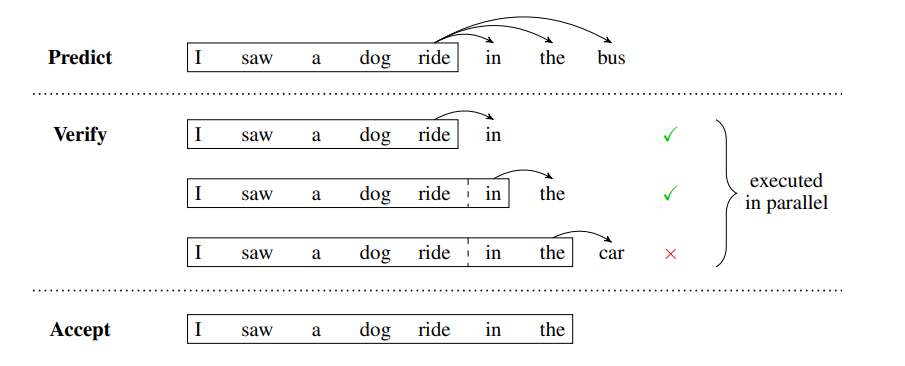
推理的加速效果:
- 原生成方法:token-by-token生成,需要 m m m 步执行
- 本文的方法: 每 k k k 个token执行一次上述三阶段过程,predict阶段执行1步产出多个Head的输出, verify阶段并行执行1步,accept阶段不耗时。所以最终需要 2 m / k 2 m / k 2m/k 步执行
- 推理加速效果: m → 2 m / k m \to 2m/k m→2m/k ,当 k = 4 k=4 k=4 的时候,推理可提速1倍
(2)Meta’s MTP
paper : Better & Faster Large Language Models via Multi-token Prediction
这是meta 于2024年4月发表的一篇论文。
针对训练阶段和推理阶段的优化:
- 训练阶段:通过预测多步token,迫使模型学到更长的token依赖关系,从而更好理解上下文,避免陷入局部决策的学习模式。同时一次预测多个token,可大大提高样本的利用效率,相当于一次预估可生成多个<predict, label>样本,来更新模型,有助于模型加速收敛。
- 推理阶段:并行预估多个token,可提升推理速度
模型结构: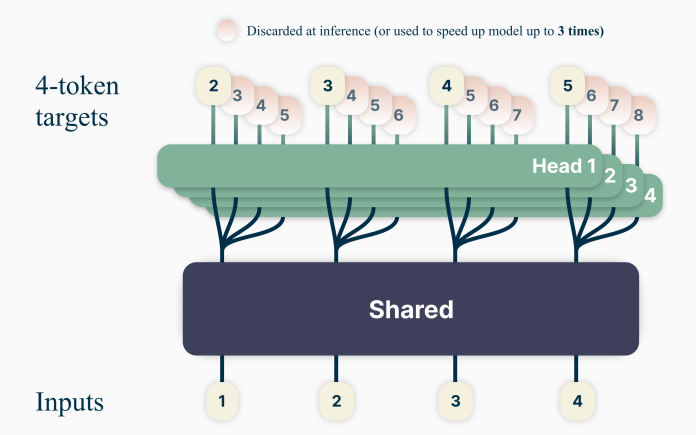
- 主干网络就是训练好的decoder-only的多层Transformer的网络, t t t 个输入token x t : 1 = x t , . . . , x 1 x_{t:1} = x_t, ..., x_1 xt:1=xt,...,x1 经过主干网络计算,最终输出隐层表示: z t : 1 z_{t:1} zt:1 (来自于 x t : 1 x_{t:1} xt:1 编码结果)。
- z t : 1 z_{t:1} zt:1 上面接了多输出Head,每个Head负责预估一个token, H e a d 1 Head_1 Head1 负责预估 next token, H e a d 2 Head_2 Head2 负责预估 next next token , 以此类推
- Head 是一个Transformer层(包括 MHA + 2层FFN),且每个Head的Transformer层是独立的,非共享的,经过这层处理后的结果记作: f h i ( z t : i ) f_{h_i}(z_{t:i}) fhi(zt:i)
- 最后再将 f h i ( z t : i ) f_{h_i}(z_{t:i}) fhi(zt:i) 送入到词表投影层( f u f_u fu 包括1个投影矩阵+1个Softmax),预估每个词的概率分布。最终通过某种采样方法(如:greedy,beam search等)生成token。注意,这个词表投影层是原预训练网络(original model)的投影矩阵+Softmax,多Head是共享的。
为了更直观的理解,补充embedding、Transformer层、MHA、FFN等模型结构: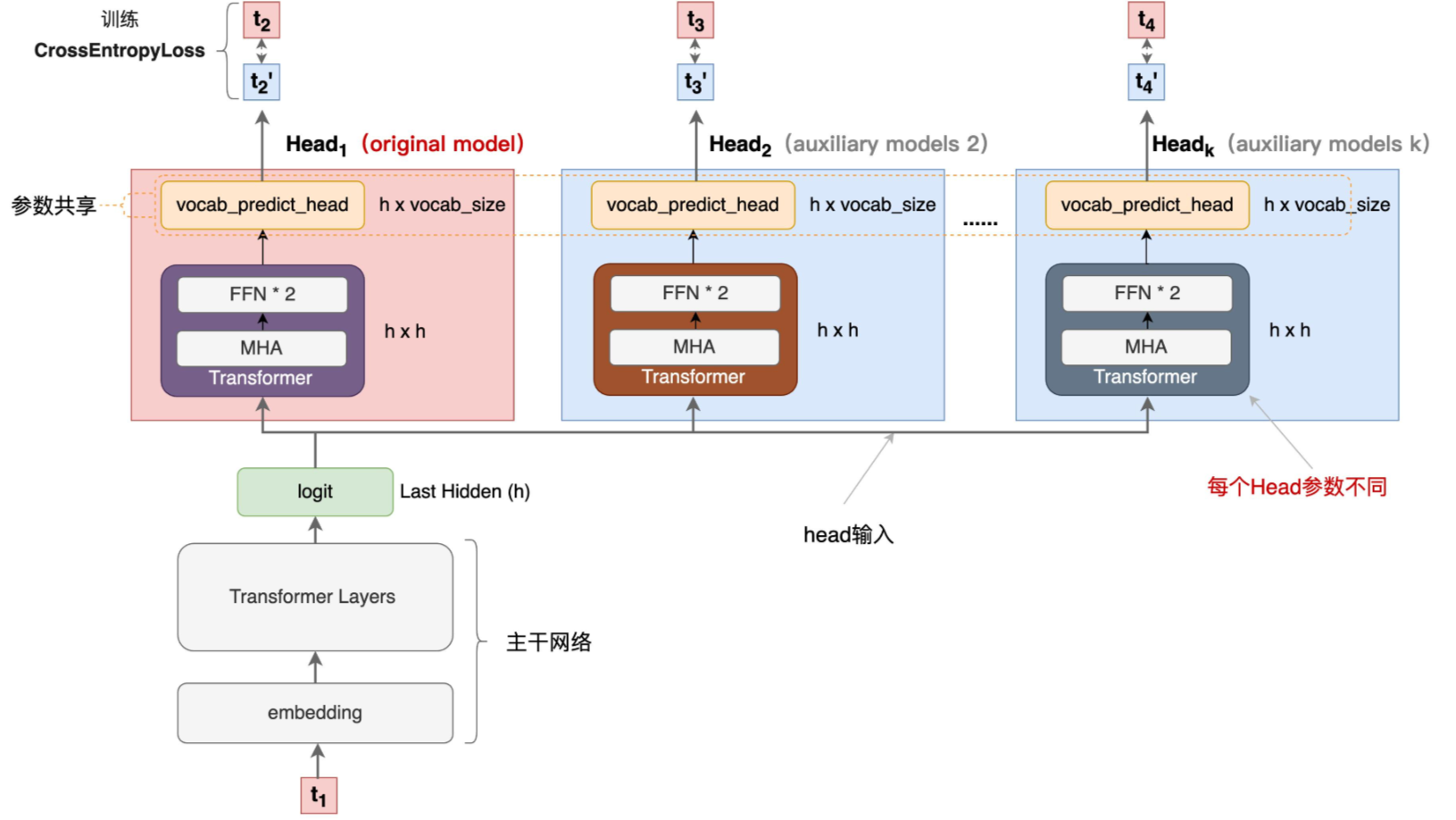
损失函数理解:
- 标准的单head预测输出的损失函数:

已给定的序列 x t : 1 = x t , ⋯ , x 1 x_{t:1} = x_t, \cdots , x_1 xt:1=xt,⋯,x1 的条件下,预测 x t + 1 x_{t+1} xt+1 的损失函数如上 - 多head预测输出任务的损失函数:

通过执行 “多标记预测” 任务,让模型在训练语料库的每个位置上,一次性预测 n 个未来标记。 - 为简化计算,我们假设大型语言模型 P θ P_\theta Pθ 使用共享主干网络,生成观察到的上下文 x t : 1 x_{t:1} xt:1 的潜在表示 z t : 1 z_{t:1} zt:1,再输入到 n 个独立的头部网络,以并行预测 n 个未来标记。这引出了多标记预测交叉熵损失的分解:

三、MTP原理
DeepSeekV3论文:2412.19437
DeepSeek V3的MTP策略旨在提高主模型的性能,因此在推理过程中,可以忽略MTP模块,主模型依然可以独立且正常地运行。此外,也可以利用这些MTP模块进行推测解码,以进一步提升生成的速度。且论文中也强调,在实现上保留了序列推理的连接关系(causal chain),如图中,从一个Module链接到后继Module的箭头。
模型结构:
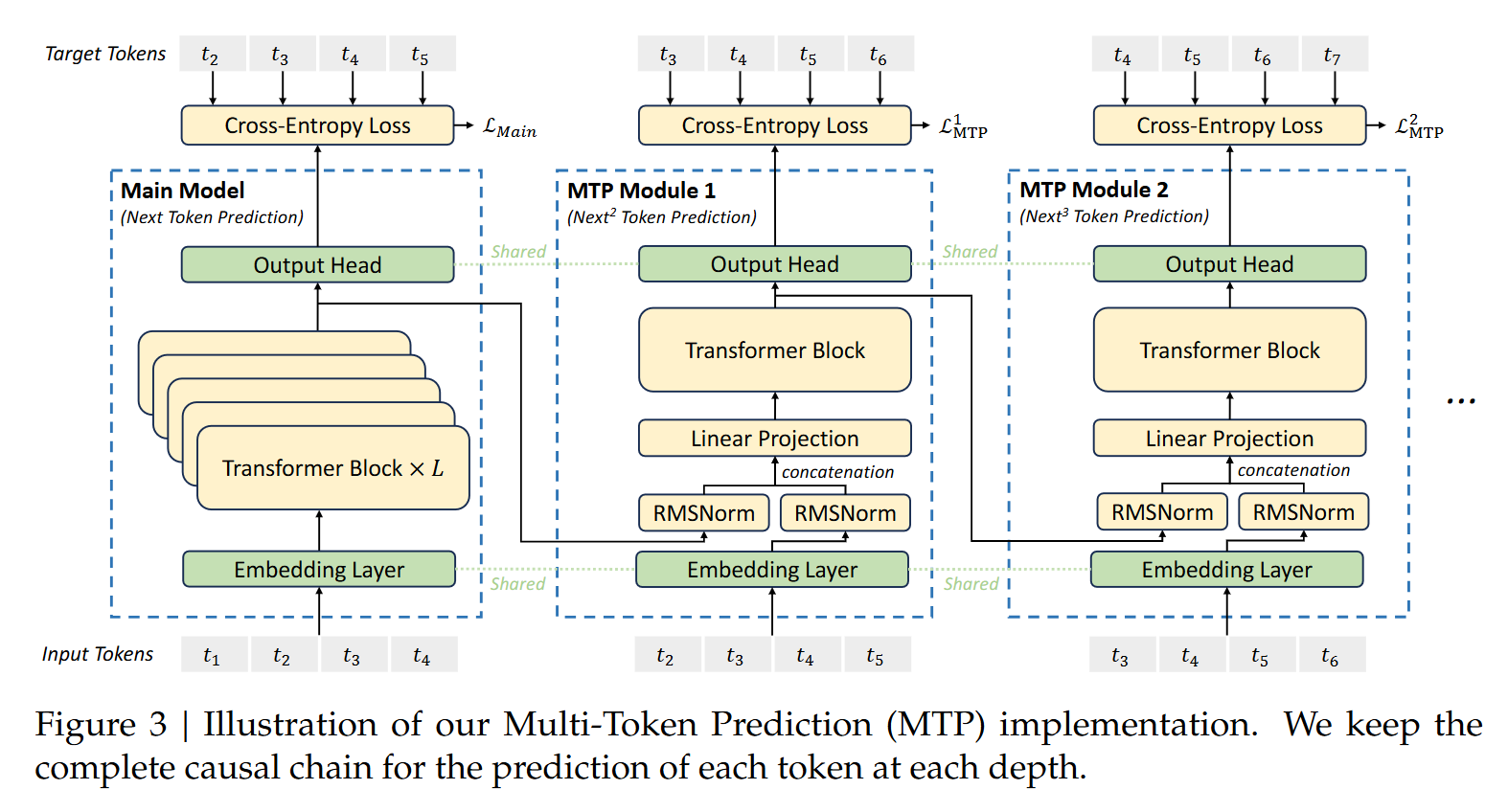
训练过程中MTP模块的工作流程:
-
输入token首先接入一层共享的embedding layer,输出的维度是 ( S × h e a d _ d i m ) (S \times head\_dim) (S×head_dim)
将单词转换为对应的索引(index)主要依靠分词器(tokenizer)和词汇表(vocab)来完成:
- 构建词汇表:词汇表是一个包含了所有可能出现在文本中的 token(可以是一个词、一个词组或者一个字符 )列表。在构建时,会对大量训练文本进行统计分析,将出现的不同 token 整理出来,并为每个 token 分配一个唯一的整数编号,即索引。例如,词汇表大小为 10000,那么 token 的索引范围就是 0 - 9999。
- 文本分词:使用分词器对输入文本进行处理,将其分解为一系列的 token。不同的大模型可能采用不同的分词算法
- 映射索引:分词完成后,分词器会根据构建好的词汇表,将每个 token 映射为对应的索引。如果分词后的某个 token 在词汇表中存在,就直接获取其对应的索引;若不存在,则通常会被映射为一个表示未知词的特殊索引(如 “” 对应的索引) 。
Embedding层结构: Embedding 层本质上是一个可学习的矩阵,通常表示为 E,其形状为 ( V , d m o d e l ) (V, d_{model}) (V,dmodel),其中 V 是词汇表的大小,也就是所有可能的单词的数量; d m o d e l d_{model} dmodel 是 Embedding 向量的维度,也就是每个单词要被转换为的向量的长度。这个矩阵的每一行对应词汇表中一个单词的向量表示。
维度变换过程: 当输入的单词索引序列进入 Embedding 层时,Embedding 层会根据这些索引从 Embedding 矩阵中选取对应的行。具体来说,对于输入序列中的每个索引 i,Embedding 层会取出 Embedding 矩阵 E 的第 i 行作为该单词的向量表示。
-
对于第 i i i 个token t i t_i ti 和第 k k k 个预测深度(就是预测第 i + k + 1 i+k+1 i+k+1的token ** t i + k + 1 t_{i+k+1} ti+k+1** ):
-
我们首先将第 k − 1 k-1 k−1 层的的隐层输出 h i k − 1 ∈ R d h_i^{k-1} \in \mathbb R^d hik−1∈Rd 做归一化处理 R M S N o r m ( h i k − 1 ) RMSNorm(h_i^{k-1}) RMSNorm(hik−1)
-
再对第 i + k i+k i+k 位置的token embedding: E m b ( t i + k ) ∈ R d Emb(t_{i+k}) \in \mathbb R^d Emb(ti+k)∈Rd 做归一化处理 R M S N o r m ( E m b ( t i + k ) ) RMSNorm(Emb(t_{i+k})) RMSNorm(Emb(ti+k))
-
将上述两个结果concat后,通过投影矩阵 M k ∈ R d × 2 d M_k \in \mathbb R^{d \times 2d} Mk∈Rd×2d 做一层线性变换得到 h i ′ k ∈ R d h_i^{'k} \in \mathbb R^d hi′k∈Rd
上述过程如下公式所示(当 k = 1 k=1 k=1 时, h i k − 1 h_i^{k-1} hik−1 对main model的隐层表征)
h i ′ k = M k [ R M S N o r m ( h i k − 1 ) ; R M S N o r m ( E m b ( t i + k ) ) ] \Large h_i^{'k} = M_k[RMSNorm(h_i^{k-1}); RMSNorm(Emb(t_{i+k}))] hi′k=Mk[RMSNorm(hik−1);RMSNorm(Emb(ti+k))]
-
再将 h i ′ k h_i^{'k} hi′k 输入到Transformer层,获得第 k k k 个预测深度的输出: h i k h_i^{k} hik 。如公式所示
h 1 : T − k k = T R M k ( h 1 : T − k ′ k ) \Large h_{1:T-k}^k = TRM_k(h_{1:T-k}^{'k}) h1:T−kk=TRMk(h1:T−k′k)
其中
T表示输入序列长度,i:j表示切片操作(包括左右边界)。Q:这里的下表切片 ( 1 : T − k ) (1:T-k) (1:T−k) 是什么意思?
A:先理解下 h i k h_i^{k} hik 是第 i i i 个token在第 k k k 预测深度上输出的表征,是要预测序列中第 i + k + 1 i+k+1 i+k+1位置的token。由于序列总长度为 T T T ,加上最后一个eos token,所以第 k k k 预测深度最长处理的输入token位置 i i i 应该满足 ( i + k + 1 ≤ T + 1 ) (i + k+1 \le T+1) (i+k+1≤T+1)。 所以第 k k k 预测头能接受的 i i i 的范围为: i ≤ T − k i \le T -k i≤T−k ,也就是 i ∈ [ 1 , T − k ] i \in [1, T-k] i∈[1,T−k] 。 -
最后将 h i k h_i^{k} hik 通过一个各Module共享的映射矩阵 O u t H e a d ∈ R V × d OutHead \in \mathbb R^{V \times d} OutHead∈RV×d 变换,再过 s o f t m a x ( . ) softmax(.) softmax(.) 处理,计算出词表 V V V 维度的输出概率,这里注意: h k i h_k^i hki 的 l a b e l label label 是对应 i + 1 + k i+1+k i+1+k 位置的token。如公式所示
p i + k + 1 k = O u t H e a d ( h i k ) \Large p_{i+k+1}^k = OutHead(h_i^k) pi+k+1k=OutHead(hik)
共享输出头将计算第k个token的概率分布 p i + k + 1 k ∈ R V p_{i+k+1}^k ∈ R^V pi+k+1k∈RV ,V是词汇表大小。
-
损失函数的计算:
通过CrossEntropyLoss计算每个MTP Module Head的损失,计算交叉熵损失 L M T P k L_{MTP}^k LMTPk :
L M T P k = C r o s s E n t r o p y ( P 2 + k : T + 1 k , t 2 + k : T + 1 ) = − 1 T ∑ i = 2 + k T + 1 log P i k [ t i ] \Large L_{MTP}^k = CrossEntropy(P_{2+k:T+1}^k, t_{2+k:T+1}) = -\frac{1}{T} \sum_{i=2+k}^{T+1} \log P_i^k[t_i] LMTPk=CrossEntropy(P2+k:T+1k,t2+k:T+1)=−T1i=2+k∑T+1logPik[ti]
其中T表示输入序列长度, t i t_i ti 表示第i个位置的真实标记, P i k [ t i ] P_i^k[t_i] Pik[ti] 表示由第k个MTP模块给出的 t i t_i ti 的相应预测概率。
再解释下上述公式下标, 2 + k : T + 1 2+k : T+1 2+k:T+1 表示label范围的下标
起始下标 2 + k 2+k 2+k :MTP Model 1 是预测 next next的token,也就是输入第一个token是 t 1 t_1 t1 ,预测第一个label token是 t ( 2 + 1 ) = t 3 t_{(2+1)} = t_3 t(2+1)=t3 ,以此类推, MTP Model k,输入第一个token是 t 1 t_1 t1, 预测第一个token是 t 2 + k t_{2+k} t2+k 【每个MTP可以最先输出的token,就是Main Model输入第一个token的时候】
结束下标 T + 1 T+1 T+1 :所有sequence样本默认在原序列上额外增加的一个eos token,所以token下标为序列长度 T + 1 T+1 T+1
最后,计算所有深度上MTP损失的平均值,并乘以权重因子λ以获得总体MTP损失 L M T P L_{MTP} LMTP ,它作为DeepSeek-V3的附加训练目标:
L M T P = λ D ∑ k = 1 D L M T P k \Large L_{MTP} = \frac{\lambda}{D} \sum_{k=1}^{D} L_{MTP}^k LMTP=Dλk=1∑DLMTPk
四、MTP的代码走读
mindspeed_llm/tasks/models/transformer/multi_token_predication.py · Ascend/MindSpeed-LLM - 码云 - 开源中国
MindSpeed-LLM-master/mindspeed_llm/core/models/gpt/gpt_model.py:
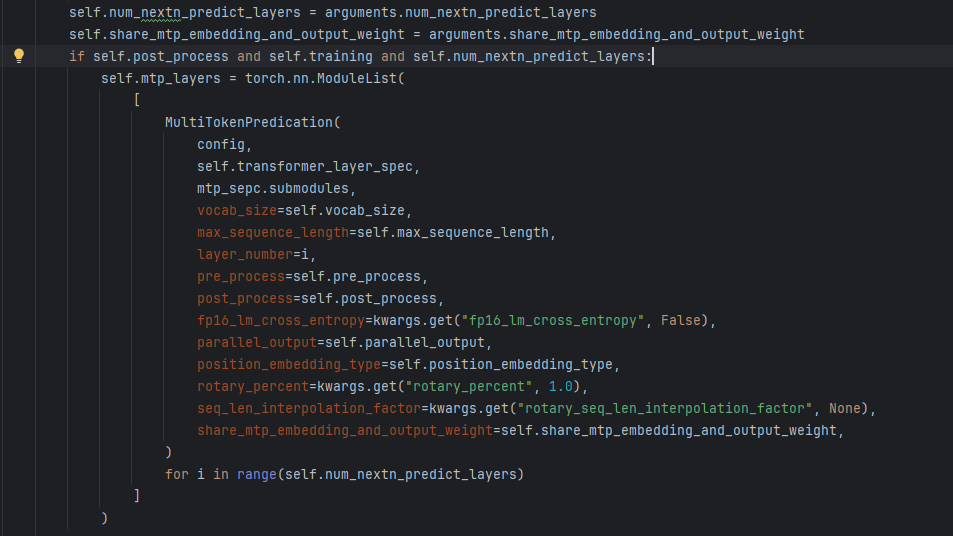
代码解释: 用于构建多 token 预测层(MultiTokenPredication)的部分,主要功能是根据配置动态创建多个模型层。
-
从外部传入的参数
arguments 中获取两层关键配置:-
num_nextn_predict_layers:定义需要创建的多 token 预测层数量。 -
share_mtp_embedding_and_output_weight:标识是否共享 MTP(Multi-Token Prediction,多 token 预测)模块的嵌入层和输出层权重。
-
-
检查三个条件:
-
self.post_process:是否开启后处理(如对模型输出的额外处理逻辑:loss计算等)。 -
self.training:模型是否处于训练模式。 -
self.num_nextn_predict_layers > 0:是否需要创建多 token 预测层。
若条件满足,使用
torch.nn.ModuleList 创建一个可管理的层列表mtp_layers,用于存储后续创建的多 token 预测层。 -
MindSpeed-LLM-master/mindspeed_llm/tasks/models/spec/mtp_spec.py:
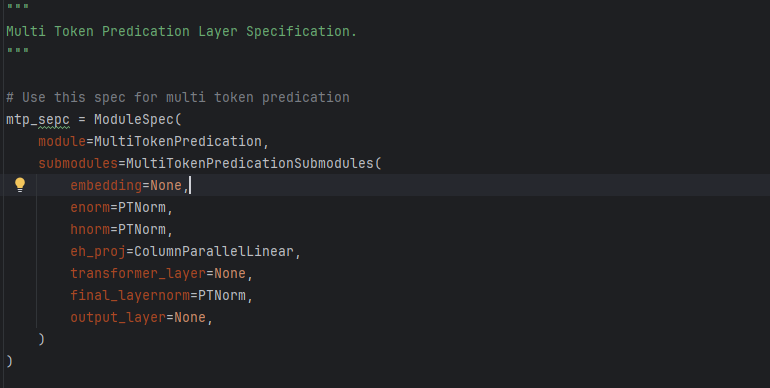
代码解释: 定义了多 token 预测层的规格,用于配置模型中多 token 预测相关模块
-
ModuleSpec:定义模块的规格类,用于配置模型组件。 -
module=MultiTokenPredication:指定该规格对应的模块类是MultiTokenPredication,即多 token 预测的主模块。 -
submodules=MultiTokenPredicationSubmodules(...):配置子模块,包含多 token 预测所需的各个组件:-
embedding=None:嵌入层,这里先设为None,可能在后续根据模型整体配置动态设置。 -
enorn=PTNorm:对输入进行归一化的层,PTNorm是具体的归一化实现(如层归一化)。 -
hnorm=PTNorm:对隐藏层输出进行归一化的层。 -
eh_proj=ColumnParallelLinear:列并行线性层,用于投影变换,常见于大规模模型并行计算中,优化矩阵乘法效率。 -
transformer_layer=None:Transformer 层,设为None,可能由外部配置传入具体实现。 -
final_layernorm=PTNorm:最终的层归一化,对输出进行归一化处理。 -
output_layer=None:输出层,同样设为None,后续根据需求配置。
-
MindSpeed-LLM-master/mindspeed_llm/tasks/models/transformer/multi_token_predication.py: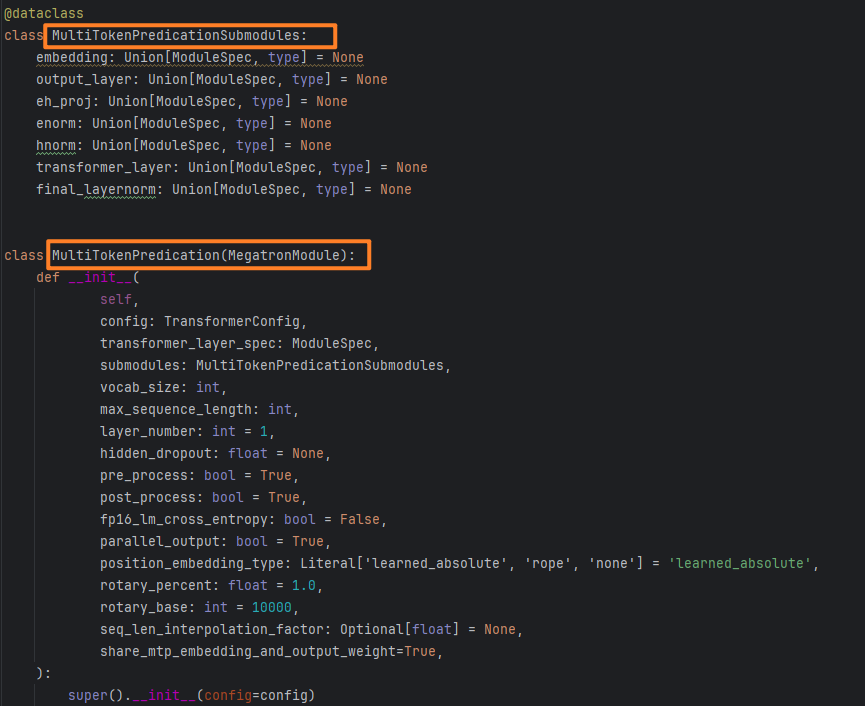
代码解释:这段代码通过 MultiTokenPredictionSubmodules 数据类管理多 Token 预测模块的子组件配置,通过 MultiTokenPredication 类定义多 Token 预测模块的初始化逻辑,接收模型配置、子模块规格等参数,为构建多 Token 预测功能提供基础框架
MultiTokenPredictionSubmodules 数据类定义多 Token 预测模块的子模块配置结构。MultiTokenPredication 类继承自MegatronModule,是基于 Megatron 框架的模块,用于多 Token 预测功能实现的主类。
MindSpeed-LLM-master/mindspeed_llm/core/models/gpt/gpt_model.py:
在def gpt_model_forward模型前向中:
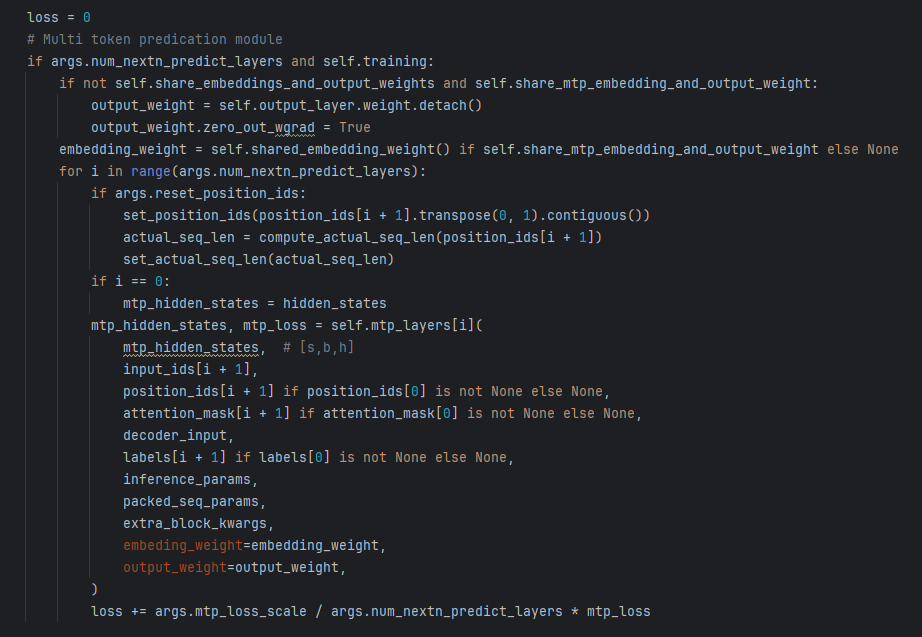
代码解释:这段代码是多 Token 预测(MTP)模块在训练阶段的核心逻辑,主要用于计算 MTP 模块的损失并累加到总损失中
-
初始化损失与条件判断: 确认配置中是否启用了 MTP 模块并处于处于训练模式,才会进入MTP模块的逻辑
-
权重处理: 处理 MTP 模块的嵌入层和输出层权重共享逻辑
若不共享模型整体的嵌入层与输出层权重,但共享 MTP 模块的嵌入层和输出层权重,分离并处理输出层权重(
detach() 用于脱离计算图根据是否共享 MTP 模块的嵌入层权重,获取嵌入层权重
embedding_weight,供后续 MTP 层使用 -
循环计算每个 MTP 层的损失:
将当前 MTP 层的损失
mtp_loss 按比例(args.mtp_loss_scale 为损失缩放因子,除以 MTP 层数保证每一层贡献均衡)累加到总损失loss 中。
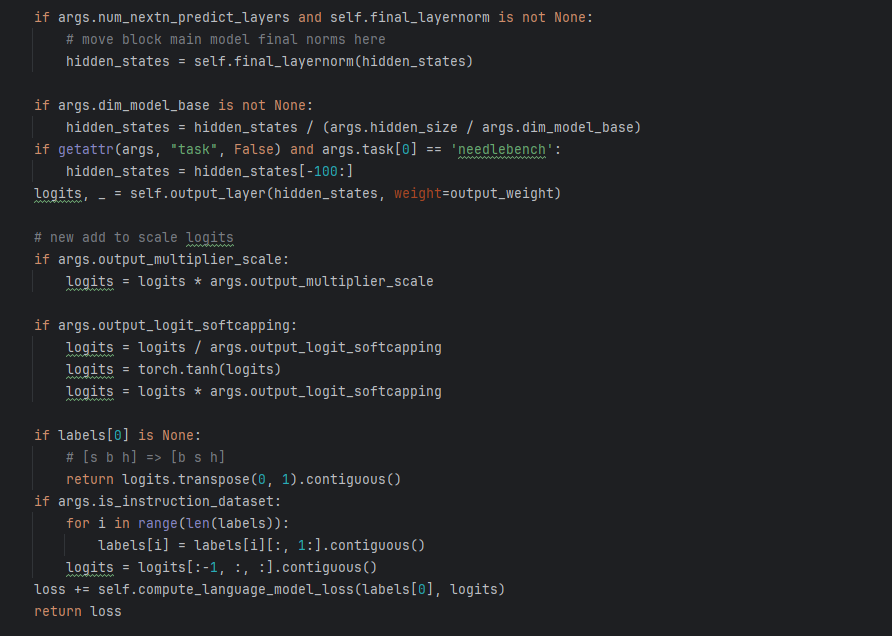
代码解释: 计算main module的logits已经总的loss损失计算

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)