
GLM-Z1系列模型基于MindSpore的推理部署指南
随着大语言模型技术的演进,智谱AI推出的GLM-Z1系列模型在智能体、推理和编码等场景展现出强大能力。昇思MindSpore作为全场景深度学习框架,为昇腾硬件提供了高效的推理支持。本文基于实际部署经验,介绍如何在MindSpore环境下完成GLM-Z1系列模型的推理部署,涵盖环境配置、模型加载与性能测试等关键步骤。同步首发!智谱开源GLM-4-0414全部6个模型并上线昇思、魔乐开源社区 | 昇思
——作者:昇腾实战派
背景概述
随着大语言模型技术的演进,智谱AI推出的GLM-Z1系列模型在智能体、推理和编码等场景展现出强大能力。昇思MindSpore作为全场景深度学习框架,为昇腾硬件提供了高效的推理支持。本文基于实际部署经验,介绍如何在MindSpore环境下完成GLM-Z1系列模型的推理部署,涵盖环境配置、模型加载与性能测试等关键步骤。
相关内容:同步首发!智谱开源GLM-4-0414全部6个模型并上线昇思、魔乐开源社区 | 昇思MindSpore社区
环境信息
硬件信息:
- 服务器型号:Atlas 800I A2推理服务器
软件信息:
使用镜像中软件版本即可,无需修改
拉取镜像
首先下载昇思MindSpore推理容器镜像:
docker pull swr.cn-central-221.ovaijisuan.com/mindformers/mindspore_glm_z1:20250414
若拉取超时,可参考相关文档调整网络配置。
创建容器
创建启动脚本docker_start.sh并写入以下内容:
docker run -it --privileged --name=GLM-Z1-MS --net=host \
--shm-size 500g \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device /dev/devmm_svm \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/sbin:/usr/local/sbin \
-v /etc/hccn.conf:/etc/hccn.conf \
-v /home:/weight \ #挂不挂都ok
swr.cn-central-221.ovaijisuan.com/mindformers/mindspore_glm_z1:20250414
/bin/bash
执行脚本启动容器:
bash docker_start.sh
下载权重
从魔乐社区下载模型权重文件:
- GLM-4-32B-Base-0414: https://modelers.cn/models/MindSpore-Lab/GLM-4-32B-Base-0414
- GLM-Z1-Rumination-32B-0414: https://modelers.cn/models/MindSpore-Lab/GLM-Z1-Rumination-32B-0414
- GLM-Z1-32B-0414: https://modelers.cn/models/MindSpore-Lab/GLM-Z1-32B-0414
- GLM-Z1-9B-0414: https://modelers.cn/models/MindSpore-Lab/GLM-Z1-9B-0414
- GLM-4-32B-0414: https://modelers.cn/models/MindSpore-Lab/GLM-4-32B-0414
- GLM-4-9B-0414: https://modelers.cn/models/MindSpore-Lab/GLM-4-9B-0414
以9B模型为例,下载至指定目录:
cd /home/work/GLM-Z1-9B-0414
git clone https://modelers.cn/MindSpore-Lab/GLM-Z1-9B-0414.git
文件结构如下
GLM-Z1-9B-0414
├── config.json # 模型json配置文件
├── tokenizer.model # 词表model文件
├── tokenizer_config.json # 词表配置文件
├── predict_glm4_z1_9b.yaml # 模型yaml配置文件
└── weights
├── model-xxxxx-of-xxxxx.safetensors # 模型权重文件
├── tokenizer.json # 模型词表文件
├── xxxxx # 若干其他文件
└── model.safetensors.index.json # 模型权重映射文件
下载后需对比文件大小与仓库中文件大小的关系,以保证权重完整
du -sh *
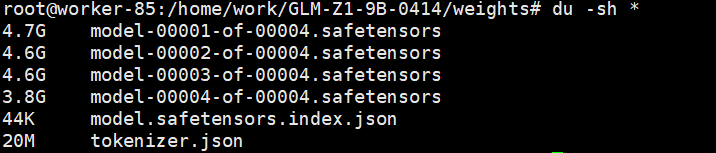
若权重过小或者报如下错误,说明权重没下载完全,只保留LFS指针
ValueError: ChatGLM4Tokenizer: invalid literal for int() with base 10: ‘https://git-lfs.github.com/spec/v1’ 2025-09-18 06:23:40,335 [ERROR] model.py:42 - [Model] >>> return initialize error result: {‘status’: ‘error’, ‘npuBlockNum’: ‘0’, ‘cpuBlockNum’: ‘0’}
执行以下命令完整下载:
#分文件依次下载
git lfs pull -I xxx
#全部下载
git lfs pull
启动MindIE
进入脚本目录并启动服务:
cd /home/work/mindformers/scripts
bash run_mindie.sh --model-name GLM-Z1-9B-0414 --model-path /home/work/GLM-Z1-9B-0414 --max-prefill-batch-size 1
tail -f output.log
# 当log日志中出现 `Daemon start success!` ,表示服务启动成功。
bash run_mindie.sh 会缺很多包需要一步一步安装,有几个特别报错
File “/usr/local/lib/python3.10/dist-packages/tritonclient/grpc/service_pb2_grpc.py”, line 9, in GRPC_VERSION = grpc.version AttributeError: module ‘grpc’ has no attribute ‘version’
pip install grpcio grpcio-tools
TypeError: cannot pickle ‘gevent._gevent_cqueue.Queue’ object
这个错误发生在 copy.copy(data_queue) 时,Python 的 copy 模块尝试复制一个 gevent 的队列对象,但失败了,因为 gevent 的 Queue 对象不能被序列化(pickle)或浅拷贝(copy)。在对应行(52行)
vim /usr/local/lib/python3.10/dist-packages/mindiebenchmark/common/datasetloaders/base_loader.py
self.data_queue = copy.copy(data_queue)
# 改为
self.data_queue = data_queue
rapidjson是一个C++解析库,但是也有Python版
pip install python-rapidjson
另开一个宿主机窗口,执行以下命令发送流式推理请求进行测试:
curl -w "\ntime_total=%{time_total}\n" -H "Accept: application/json" -H "Content-type: application/json" -X POST -d '{"inputs": "请介绍一个北京的景点", "parameters": {"do_sample": false, "max_new_tokens": 128}, "stream": false}' http://127.0.0.1:8090/generate_stream &
使用benchmark进行测试
调整测试配置:
vim /usr/local/lib/python3.11/site-packages/mindiebenchmark/config/synthetic_config.json
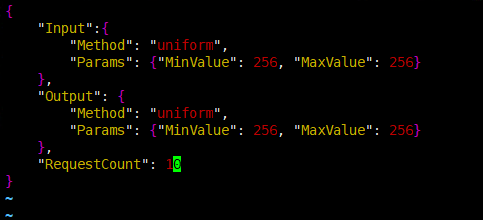
总请求数RequestCount 没要求的话一般设置成四倍并发。
在run_mindie.sh调整输出输出序列长度,如果在/usr/local/Ascend/mindie/latest/mindie-service/conf/config.json里修改会被覆盖。
cd /home/work/mindformers/scripts
vim run_mindie.sh
注意其中 maxSeqLen = maxInputTokenLen + maxIterTimes
启动benchmark
benchmark --DatasetPath /usr/local/lib/python3.10/dist-packages/mindiebenchmark/config/synthetic_config.json --DatasetType synthetic \
--ModelName GLM-Z1-9B-0414 --ModelPath /home/work/GLM-Z1-9B-0414 \
--TestType engine --Http http://141.61.22.85:8090 \
--Concurrency 100 --Tokenizer True
常见问题
可能会遇到的报错:
查看日志
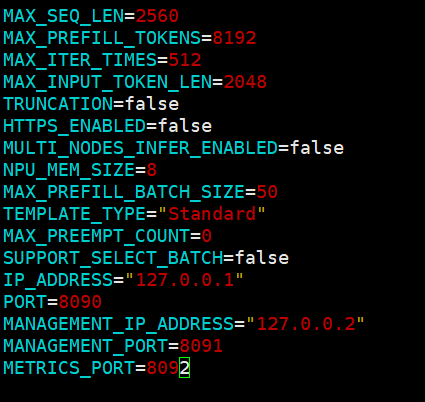
vim /usr/local/Ascend/mindie/latest/mindie-service/logs/mindservice.log

发现是端口冲突,调整PORT、MANAGEMENT_PORT和METRICS_PORT为可用端口(如8090)。
/home/work/mindformers/scripts
vim run_mindie.sh
测试完成后,可查看日志分析性能指标。通过上述步骤,可顺利完成GLM-Z1系列模型的部署与验证。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)