
昇腾环境部署Cosyvoice
本文详细介绍了在ARM架构(aarch64)和昇腾310P显卡环境下部署CosyVoice2语音模型的完整流程。主要内容包括:1)基于CANN 8.2的Docker环境配置;2)从ModelZoo和GitHub获取源码并进行平台适配;3)模型权重下载与版本管理;4)特殊依赖(Pynini/WeTextProcessing)的源码编译安装。重点解决了语音模型部署中的环境适配问题,特别是通过OpenF
一、环境准备
操作架构:ARM(aarch64)
显卡型号:昇腾310P(Ascend310P3)
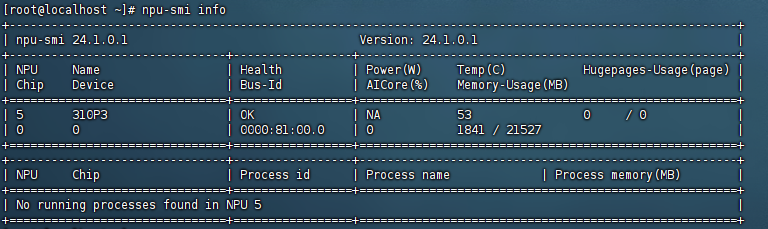
教程所需环境:
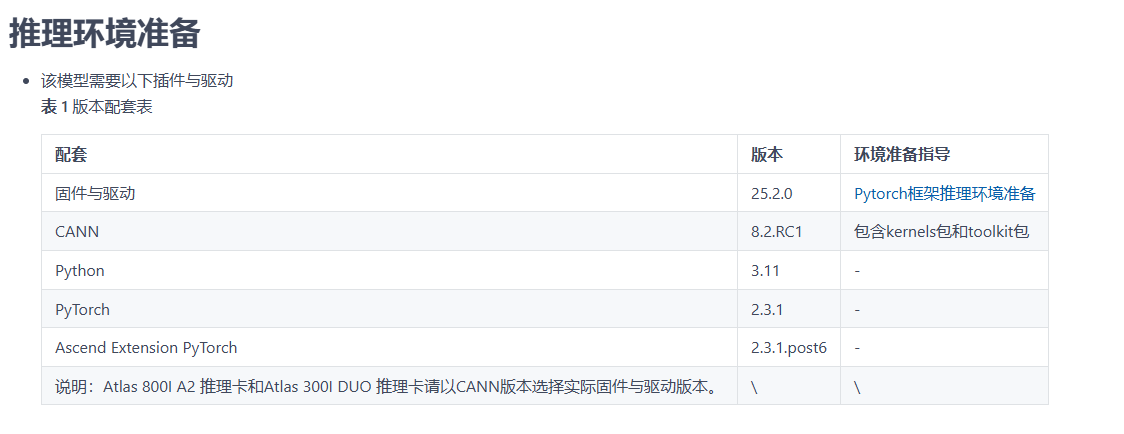
从华为官网找到适配版本镜像:https://www.hiascend.com/developer/ascendhub/detail/17da20d1c2b6493cb38765adeba85884

启动容器
#下载镜像
docker pull swr.cn-south-1.myhuaweicloud.com/ascendhub/cann:8.2.rc1-310p-ubuntu22.04-py3.11
#启动容器
docker run -itd --net=host \
--device=/dev/davinci0 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
--shm-size=32g \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /var/log/npu/:/usr/slog \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /root/cosyvoice:/workspace \
--name cosyvoice \
7c8c48dc2e1b \
/bin/bash
进入容器
docker exec -it cosyvoice bash
cd /workspace
二、源码获取
1、克隆ModelZoo仓库
ModelZoo-PyTorch,昇腾旗下的开源AI模型平台,涵盖计算机视觉、自然语言处理、语音、推荐、多模态、大语言模型等方向的AI模型及其基于昇腾机器实操案例。
Ascend ACL_PyTorch,提供了经典和主流算法模型实现昇腾服务器推理的端到端流程。
git clone https://gitee.com/ascend/ModelZoo-PyTorch.git
cd ModelZoo-PyTorch/ACL_PyTorch/built-in/audio/CosyVoice2
2、获取CosyVoice源码
# 克隆CosyVoice源码
git clone https://github.com/FunAudioLLM/CosyVoice
cd CosyVoice
# 切换到指定 commit(确保代码兼容性)
git reset --hard fd45708
# 拉取子模块(Matcha-TTS等)
git submodule update --init --recursive
# 应用平台补丁(platform为300I或800I,根据硬件选择)
export platform=300I
git apply ../${platform}/diff_CosyVoice_${platform}.patch
# 复制推理脚本
cp ../infer.py ./
# 克隆transformers库并切换版本
git clone https://github.com/huggingface/transformers.git
cd transformers
git checkout v4.37.0
cd ..
# 替换qwen2模型文件
cp ../${platform}/modeling_qwen2.py ./transformers/src/transformers/models/qwen2
三、下载模型权重
本案例以CosyVoice2-0.5B为例,其他权重请自行适配。将下载下来的权重放在CosyVoice目录下。
因cosyvoice2在2025年4月底更新过一次代码权重,因此下载时需要指定commit id,下载之前的权重。
1、克隆权重仓库并切换版本
# 克隆CosyVoice2-0.5B权重
git clone https://www.modelscope.cn/iic/CosyVoice2-0.5B.git
cd CosyVoice2-0.5B
# 切换到指定commit(2025年4月前权重)
git checkout 9bd5b08fc085bd93d3f8edb16b67295606290350
2、拉取大文件权重(依赖git-lfs)
# 安装git-lfs
apt update
apt-get install -y git-lfs
#初始化
git lfs install
# 拉取权重
git lfs pull
3、下载额外spk权重
本用例采用sft预训练音色推理,请额外下载spk权重放到权重目录下
apt install wget
wget https://www.modelscope.cn/models/iic/CosyVoice-300M-SFT/resolve/master/spk2info.pt
cd ..
文件目录结构大致如下:
📁 CosyVoice2/
|── 📁 300I
|── 📄 diff_CosyVoice_300I.patch
|── 📄 modeling_qwen2.py
|── 📁 800I
|── 📄 diff_CosyVoice_800I.patch
|── 📄 modeling_qwen2.py
|── 📁 CosyVoice
|── 📁 cosyVoice源码文件 # cosyVoice的源码文件,此处不一一列举
├── 📁 CosyVoice-0.5B/ # 权重文件
├── 📁 transformers/ # transformers库,里面修改modeling_qwen2.py文件
|── 📄 infer.py # 推理脚本
│── 📄 requirements.txt # 依赖库
└── 📄 modify_onnx.py # 模型转换脚本
四、安装依赖
1、安装python依赖
直接执行会报错。
# 安装Python依赖,是CosyVoice2下的requirements
pip3 install -r ../requirements.txt
此时pynini库会报错,要源码编译pynini
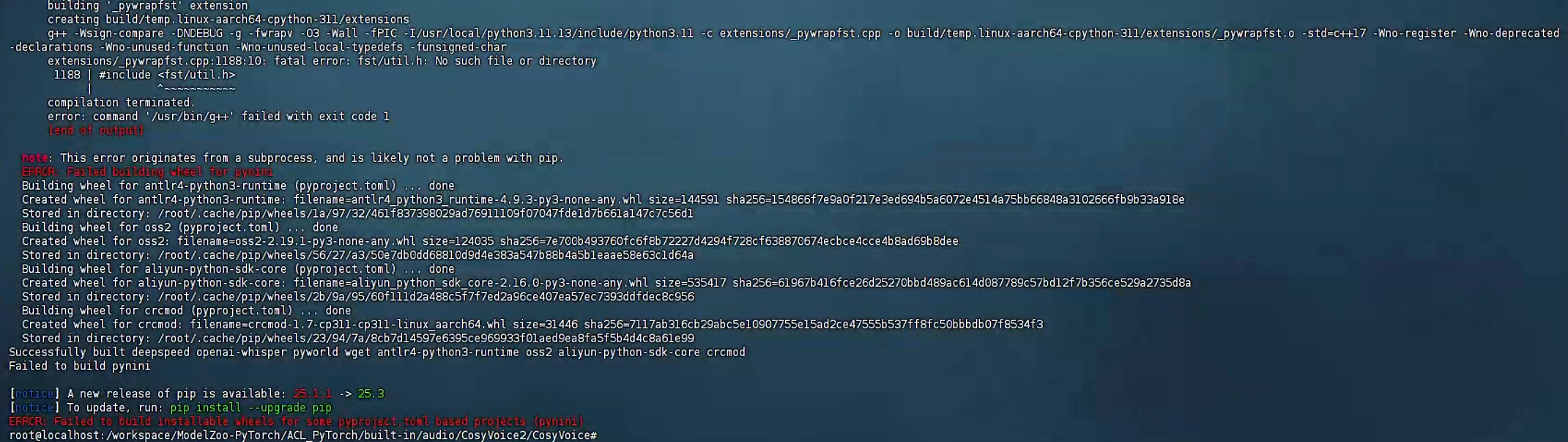
2、安装特殊依赖:WeTextProcessing与pynini(依赖OpenFST)
【Pynini和WeTextProcessing的作用】
Pynini 和 WeTextProcessing 是两个用于文本规范化(Text Normalization, TN)和发音转换(如G2P,Grapheme-to-Phoneme)的工具,主要作用是将非标准文本(如数字、符号、缩写等)转换为语音合成(TTS)或语音识别(ASR)系统可处理的规范化形式
在语音模型中的协作流程
-
输入文本 → WeTextProcessing:
- 先进行语言检测、分词、非标准文本规范化(如"¥100"转"一百元")。
-
中间文本 → Pynini:
- 对规范化后的文本执行G2P转换(如"苹果" →
/p ing g uo/)。
- 对规范化后的文本执行G2P转换(如"苹果" →
-
输出 → 语音模型(TTS/ASR):
- 将音素序列输入声学模型生成语音(TTS),或匹配语音特征(ASR)
语音模型Cosyvoice2、Index-TTS中都会用到Pynini和WeTextProcessing, pip直接安装会报各种错,以下是通过openFST的源码编译安装。
# 安装工具
apt-get install -y sox git gcc g++ make cmake
# 下载安装包并解压
wget https://www.openfst.org/twiki/pub/FST/FstDownload/openfst-1.8.3.tar.gz
tar -zxvf openfst-1.8.3.tar.gz;cd openfst-1.8.3
# 进入目录后编译安装
./configure --enable-far --enable-mpdt --enable-pdt
make -j$(nproc)
make install
# 确认动态库文件存在:
ls /usr/local/lib/libfstmpdtscript.so.26
# 配置动态库路径
export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH
ldconfig
pip install pynini==2.1.6
# 安装WeTextProcessing
pip3 install WeTextProcessing==1.0.4.1
# 回到CosyVoice目录,重新安装一次
cd /workspace/ModelZoo-PyTorch/ACL_PyTorch/built-in/audio/CosyVoice2/CosyVoice
pip3 install -r ../requirements.txt
3、安装msit工具(解决ais_bench导入失败)
# 克隆msit工具仓库
git clone https://gitee.com/ascend/msit.git
cd msit/msit
pip install .
# 安装benchmark和surgeon组件
msit install benchmark
msit install surgeon
cd /workspace/ModelZoo-PyTorch/ACL_PyTorch/built-in/audio/CosyVoice2/CosyVoice
五、模型转换(ONNX→OM)
1、修改ONNX模型结构
# 回到CosyVoice2目录
cd /workspace/ModelZoo-PyTorch/ACL_PyTorch/built-in/audio/CosyVoice2
# 执行修改脚本(参数为权重目录)
python3 modify_onnx.py ./CosyVoice/CosyVoice2-0.5B/
# 生成修改后的模型:./CosyVoice2-0.5B/speech_token_md.onnx
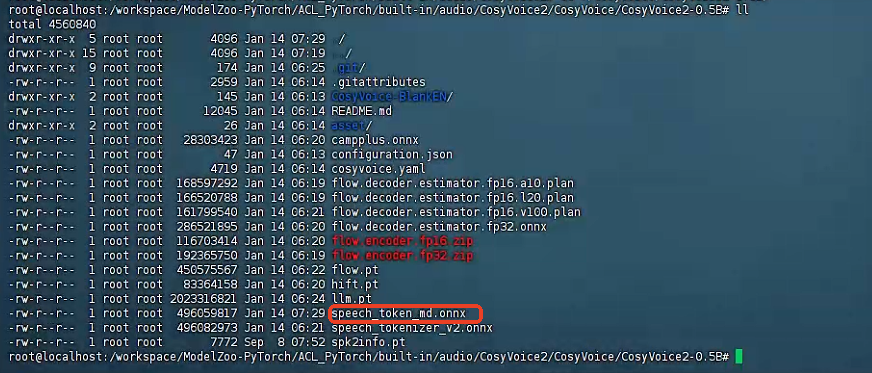
2、配置昇腾环境变量
# 加载昇腾工具链环境
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 确认芯片型号
export soc_version=Ascend310P3
3、使用ATC工具转换模型
# 转换speech_token模型
atc --framework=5 \
--soc_version=$soc_version \
--model ./CosyVoice2-0.5B/speech_token_md.onnx \
--output ./CosyVoice2-0.5B/speech \
--input_shape="feats:1,128,-1;feats_length:1" \
--precision_mode allow_fp32_to_fp16
问题:ATC报错 python3-config --prefix执行失败
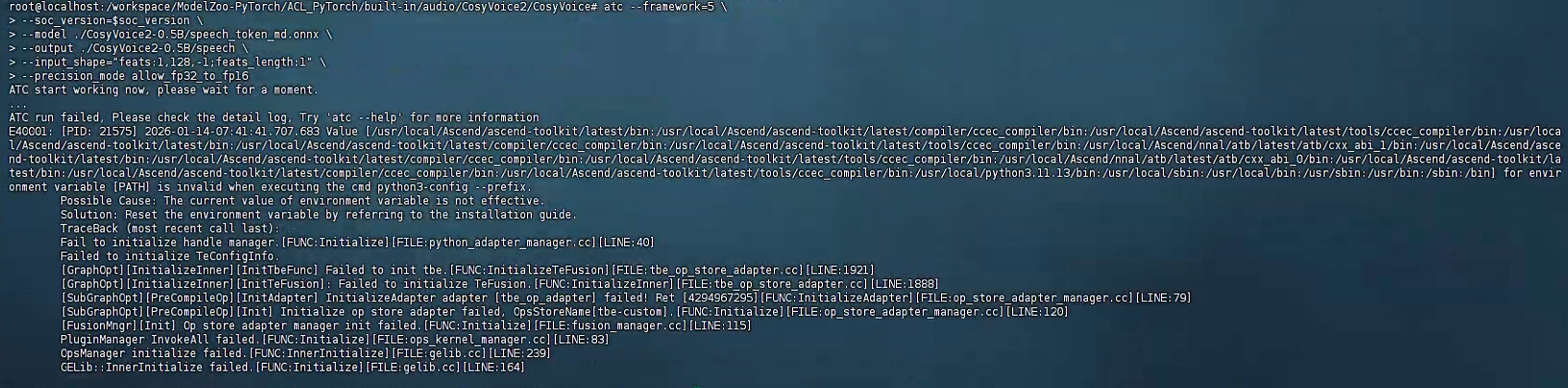
解决:
主要问题是找不到python3-config,因为容器安装的是python3.11-config
# 1. 先确认Python安装目录下是否有python3.11-config(通常会有版本号后缀)
ls /usr/local/python3.11.13/bin/python3.11-config
# 2. 如果存在,创建软链接(映射为python3-config)
ln -sf /usr/local/python3.11.13/bin/python3.11-config /usr/local/python3.11.13/bin/python3-config
# 3. 再映射到系统路径(确保全局可调用)
ln -sf /usr/local/python3.11.13/bin/python3-config /usr/bin/python3-config
# 4. 验证是否可用(关键)
python3-config --prefix
# 正确输出:/usr/local/python3.11.13
将python3.11-config映射给python3-config就可以
转化其他两个模型
# 转换flow.decoder模型(动态shape)
atc --framework=5 \
--soc_version=$soc_version \
--model ./CosyVoice2-0.5B/flow.decoder.estimator.fp32.onnx \
--output ./CosyVoice2-0.5B/flow \
--input_shape="x:2,80,-1;mask:2,1,-1;mu:2,80,-1;t:2;spks:2,80;cond:2,80,-1"
# 转换分档模型(流式输出用)
atc --framework=5 \
--soc_version=$soc_version \
--model ./CosyVoice2-0.5B/flow.decoder.estimator.fp32.onnx \
--output ./CosyVoice2-0.5B/flow_static \
--input_shape="x:2,80,-1;mask:2,1,-1;mu:2,80,-1;t:2;spks:2,80;cond:2,80,-1" \
--dynamic_dims="100,100,100,100;200,200,200,200;300,300,300,300;400,400,400,400;500,500,500,500;600,600,600,600;700,700,700,700" \
--input_format=ND
六、模型推理验证
1、配置推理环境变量
# 指定NPU设备
export ASCEND_RT_VISIBLE_DEVICES=0
# 添加依赖库路径
export PYTHONPATH=third_party/Matcha-TTS:$PYTHONPATH
export PYTHONPATH=transformers/src:$PYTHONPATH
2、执行推理
# 流式输出推理(结果保存为sft_i.wav)
python3 infer.py --model_path=./CosyVoice2-0.5B --stream_out
报错1:这个错误是 ruamel.yaml 版本问题导致的。hyperpyyaml 与 ruamel.yaml 版本不兼容。
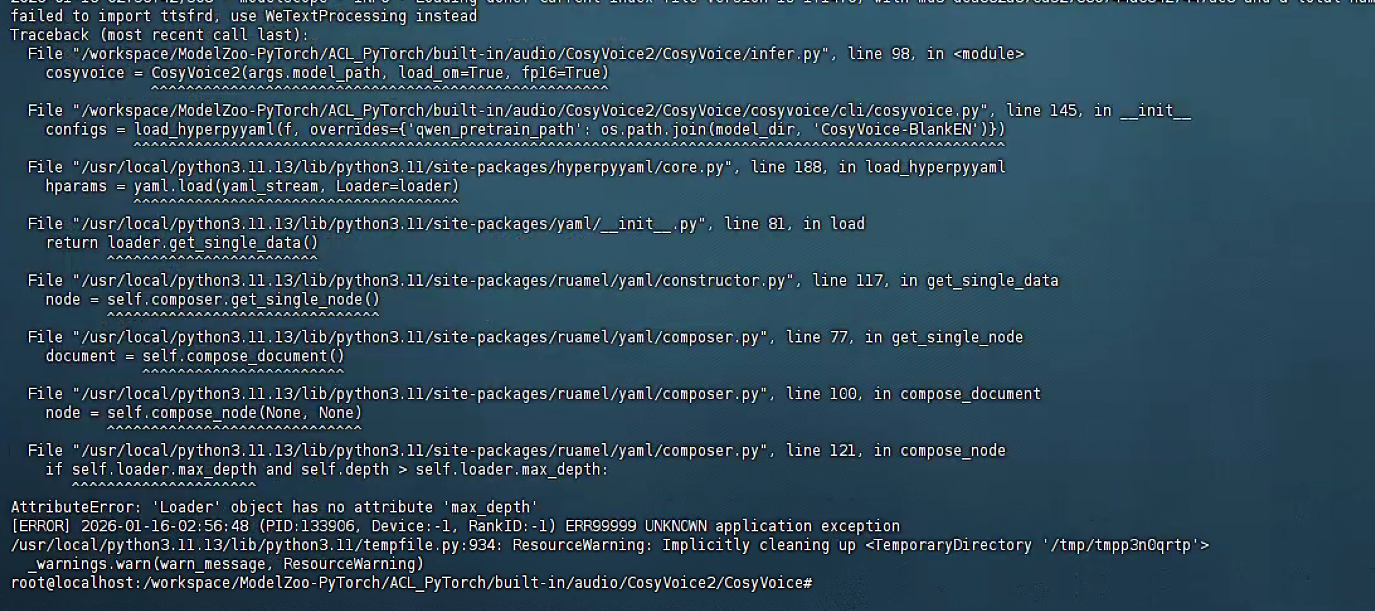
解决方案:降级ruamel.yaml
pip install ruamel.yaml==0.17.21 --force-reinstall
报错2:缺失tokenizers
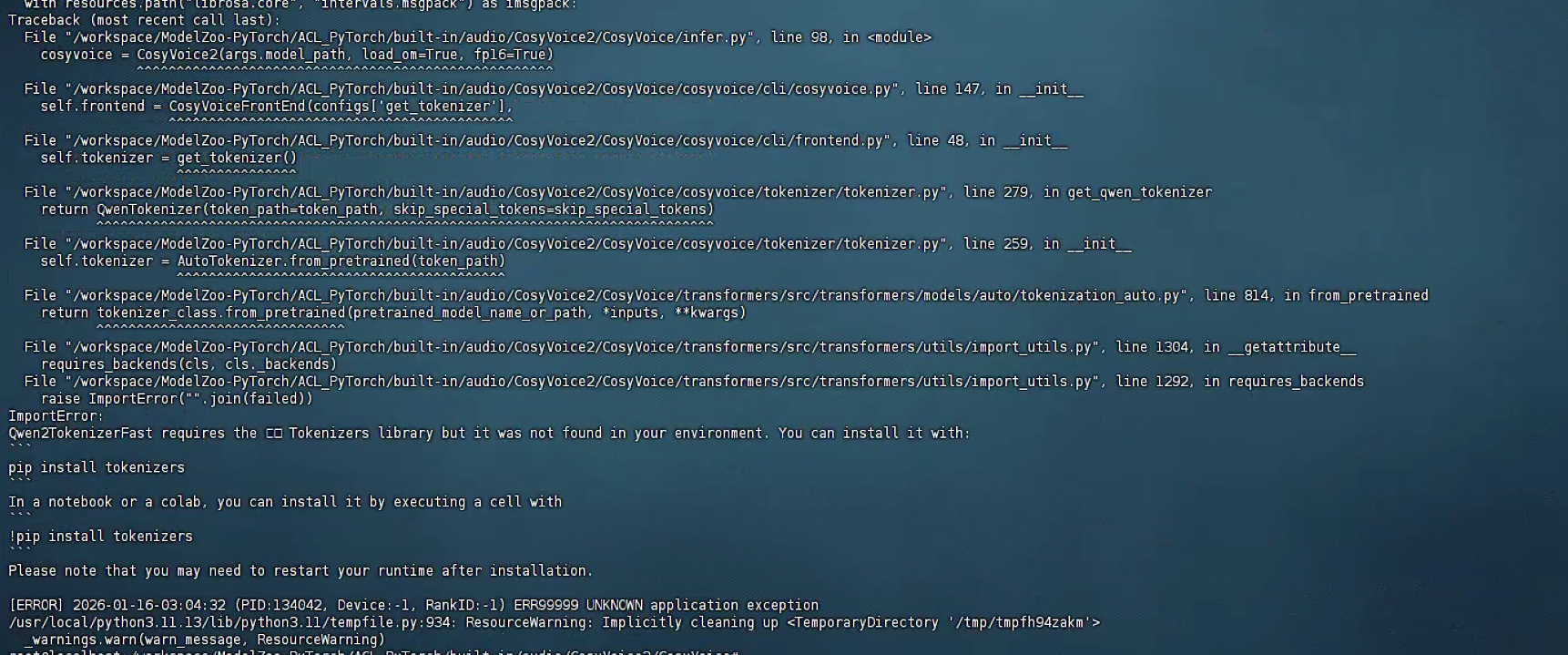
解决方案:安装 tokenizers 到兼容版本
pip install tokenizers==0.15.0
报错3:编译出错且卡住不动
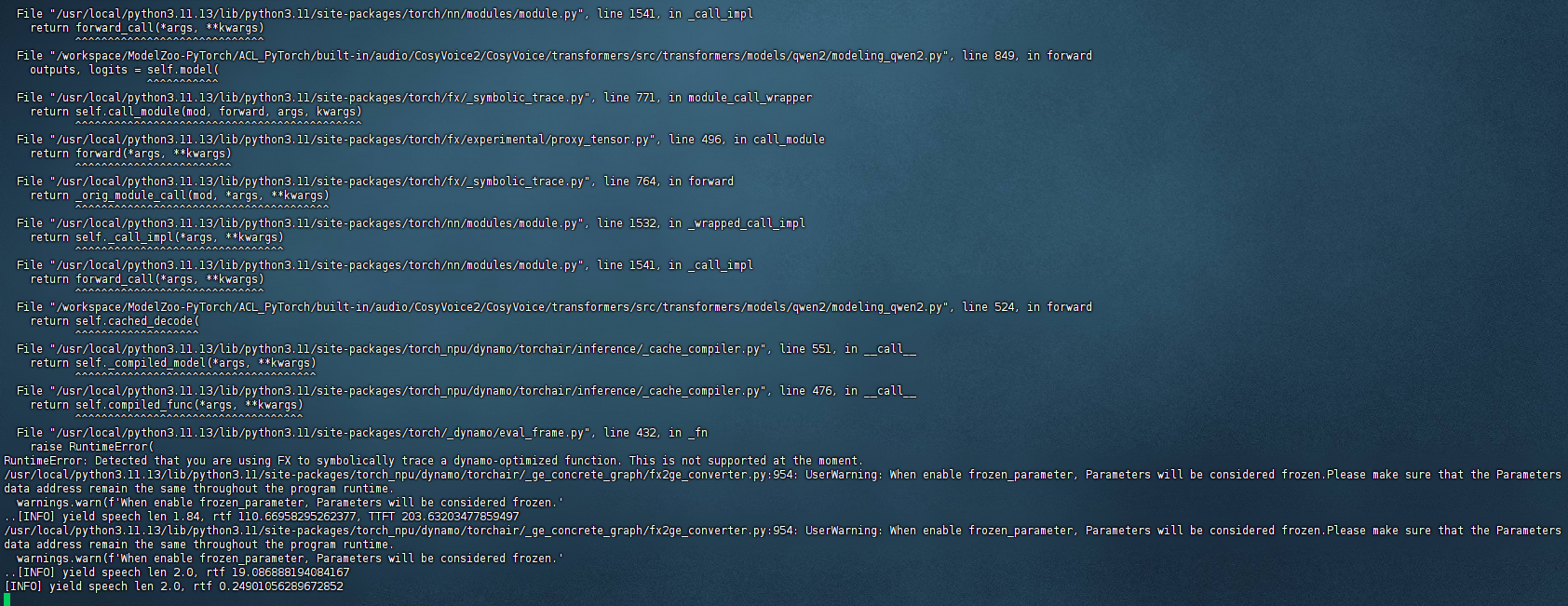
在LLM推理线程中出现了一个错误:RuntimeError: Detected that you are using FX to symbolically trace a dynamo-optimized function. 这是一个PyTorch编译相关的问题。
解决办法:将infer代码中关于torch.compile部分注释掉


作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)