
OpenAI加速整合音频AI模型,为语音主导的个人AI设备“打地基”
【摘要】OpenAI正系统性地整合其音频AI技术栈,旨在弥合当前语音与文本模型间的性能鸿沟。此举不仅是为提升ChatGPT的语音交互体验,更是为其未来以“语音优先”为核心的个人AI硬件设备铺设关键技术基石,标志着公司正从云端模型供应商向软硬一体的个人AI平台战略性转型。
【摘要】OpenAI正系统性地整合其音频AI技术栈,旨在弥合当前语音与文本模型间的性能鸿沟。此举不仅是为提升ChatGPT的语音交互体验,更是为其未来以“语音优先”为核心的个人AI硬件设备铺设关键技术基石,标志着公司正从云端模型供应商向软硬一体的个人AI平台战略性转型。

引言
在大型语言模型(LLM)的浪潮之巅,OpenAI的名字几乎与文本生成和理解划上了等号。然而,近期的种种迹象表明,这家AI巨头的目光已悄然越过屏幕上的文字,投向了一个更具沉浸感和即时性的交互维度——语音。据多方消息证实,OpenAI内部正在进行一场深刻的技术变革,其核心是全面整合并强化其音频AI能力。
这并非一次简单的功能迭代或模型升级,而是一场深思熟虑的战略布局。其最终目标,是为一类全新的、以语音交互为主导的个人AI设备构建坚实的技术地基。这意味着OpenAI的雄心已不再局限于打造一个存在于云端的“最强大脑”,而是要将这个大脑延伸到用户的日常环境中,成为一个无处不在、时刻伴随的智能伙伴。本文将深入剖析OpenAI在音频AI领域的现状、面临的技术挑战、整合举措,以及这一系列动作背后所昭示的,关于下一代个人计算平台的宏大构想。
一、 战略转向:从云端大模型到个人AI终端

OpenAI的此次行动,本质上是一次从软件服务向“软硬一体”生态的战略延伸。其背后的驱动力,源于对当前人机交互模式局限性的深刻洞察,以及对未来AI应用形态的前瞻性判断。
1.1 交互范式的演进需求
基于App的交互模式,无论在移动端还是桌面端,都存在一个固有的“边界”。用户需要主动发起、切换应用、输入指令,交互过程存在明显的断点。而一个理想的AI助手,应当是环境感知和持续在线的,能够无缝融入用户的工作与生活流。
语音,作为人类最自然的交流方式,是打破这一边界的最佳媒介。一个以语音为核心的AI设备,可以解放用户的双手和双眼,在驾驶、运动、烹饪等场景下提供即时帮助,实现真正的“伴随式智能”。这正是OpenAI瞄准的下一片蓝海,即从“工具型AI”向“伴侣型AI”的转变。
1.2 “语音优先”的硬件构想
OpenAI的硬件规划并非单一产品,而是一个涵盖多种形态的AI伴随式助手产品线。这些构想中的设备,其共同特点是弱化甚至取消传统屏幕,将交互重心彻底转移到听觉和语音上。
-
智能眼镜:将视觉信息与语音指令结合,实现环境理解与实时信息叠加,例如实时翻译、物体识别或导航指示。
-
无屏幕智能音箱:作为家庭环境的AI中枢,专注于通过对话完成复杂的任务调度、信息查询和家居控制。
-
可穿戴设备(如AI Pin):形态极简,通过持续的语音交互和环境感知,提供主动式、个性化的信息提醒与服务。
-
智能笔:在记录的同时,通过语音进行内容整理、摘要和扩展创作。
这些硬件形态的设计哲学,都指向一个核心,即让AI的调用成本无限趋近于零。用户无需再寻找手机、解锁、打开App,只需一个简单的唤醒词或一个自然的提问,就能立即获得AI的服务。
1.3 构建闭环生态的战略意图
通过自研硬件,OpenAI试图构建一个从底层模型、中间层API到终端设备和用户体验的完整闭环生态。这一战略的价值体现在多个层面。
-
数据飞轮:自有硬件能够采集到更真实、更多样化的第一方交互数据,特别是带有丰富上下文情景的语音数据,这将为其模型的持续迭代提供无可比拟的养料。
-
体验控制:软硬一体化可以确保从语音识别、模型响应到语音合成的每一个环节都得到极致优化,避免因第三方硬件或系统限制而导致的用户体验折损。
-
平台卡位:在AI原生时代,谁能定义下一代个人计算平台,谁就掌握了未来的流量入口和生态主导权。OpenAI此举,是在智能手机之后,抢先为“AI原生个人设备”这一新品类下定义、立标准。
二、 技术鸿沟:当前音频AI模型的现实困境
尽管战略蓝图宏大,但要实现理想中的语音交互体验,OpenAI必须首先正视并解决其当前音频技术栈中存在的“硬伤”。最核心的问题在于,其语音功能与文本功能背后,存在着一条明显的性能鸿沟。
2.1 “双核”架构的内在矛盾
目前,当用户与ChatGPT进行语音对话时,其体验并非由一个统一的端到端模型驱动。整个流程被拆分为几个独立的模块,形成了一个事实上的“双核”或“多核”架构。
-
语音转文本 (ASR):用户的语音首先被一个ASR模型(如Whisper的变体)转换成文本。
-
文本理解与生成 (LLM):转换后的文本被发送给核心的文本大模型(如GPT-4o)进行理解和处理,并生成文本回复。
-
文本转语音 (TTS):LLM生成的文本回复,再被一个独立的TTS模型转换为语音,播放给用户。
这种分立式的架构虽然在工程上易于实现和解耦,但却带来了诸多难以回避的体验问题,使其语音版本的能力远逊于文本版本。
2.2 性能短板的三个维度
这条技术鸿沟具体体现在以下三个关键维度,它们共同构成了发展语音硬件的核心技术短板。
|
性能维度 |
具体表现 |
对个人AI设备体验的影响 |
|---|---|---|
|
响应延迟 (Latency) |
端到端延迟较高,用户说完话后需要明显等待才能听到回复,对话缺乏流畅感和即时性。延迟主要来自ASR、LLM推理和TTS三个环节的累加。 |
严重破坏对话的自然感,无法实现快速、实时的“一问一答”。对于需要即时反馈的场景(如导航、同声传译)是致命的。 |
|
准确性与深度 (Accuracy & Depth) |
ASR模块可能出现识别错误,导致LLM的输入信息失真。更重要的是,语音交互丢失了文本输入时的精确性和可编辑性,LLM无法完全理解语音中的语调、停顿、重音等副语言信息,导致理解深度下降。 |
导致“答非所问”或理解偏差,AI的智能感大打折扣。无法处理复杂或带有情绪色彩的口语化表达,使得交互停留在浅层信息问答。 |
|
自然度与表现力 (Naturalness & Expressiveness) |
TTS模型生成的语音虽然清晰,但往往缺乏真实的情感和自然的韵律(Prosody),听起来仍有“机器味”。难以根据对话内容和上下文,动态调整语气和情感。 |
使得AI助手的形象冰冷、刻板,难以建立用户的情感连接。在播报故事、新闻或进行安慰性对话时,体验尤为不佳。 |
2.3 架构差异的根源
造成这种性能差距的根本原因,在于模型架构和训练目标的本质不同。文本大模型经过海量文本数据的训练,精于逻辑推理、知识整合和语言组织。而ASR和TTS模型则专注于声学信号与文本之间的映射,其训练数据和模型结构都与LLM有很大差异。将这几个“专科医生”临时拼凑在一起,自然难以达到一个“全科圣手”的水平。
因此,要为语音主导的个人AI设备“打地基”,OpenAI的首要任务,就是填平这条技术鸿沟,让语音交互的体验无限逼近甚至超越文本交互。
三、 破局之路:OpenAI的音频技术栈整合与演进

面对上述挑战,OpenAI并未采取修修补补的策略,而是从组织架构、模型研发和技术路线上进行了系统性的变革,旨在打造一个原生、高效、统一的音频AI技术栈。
3.1 组织协同:集中力量办大事
实现技术突破的第一步,是打破内部壁垒。据报道,OpenAI在近几个月内,已将其负责音频技术的产品、工程和研究团队进行了深度整合。
-
目标统一:所有相关团队不再是为各自的模块(ASR、TTS)负责,而是共同为一个统一的“卓越音频体验”目标努力。
-
资源集中:顶尖的研究人员和工程师被抽调出来,组成攻坚小组,专注于解决音频模型的核心难题,如延迟、多模态理解和自然度。
-
敏捷迭代:跨职能团队的协使得从研究发现、工程实现到产品测试的循环大大缩短,加速了新模型的迭代速度。
这种组织上的调整,是其技术战略得以高效执行的关键保障,确保了公司上下在音频AI方向上形成合力。
3.2 模型演进:从分离到融合
OpenAI的技术路线图,清晰地指向了从分离式模型向更紧密耦合,乃至最终统一的模型架构演进。其目标是让“语音版ChatGPT”和“文本版ChatGPT”共享一个大脑或紧密协作的大脑。
3.2.1 近期举措:发布专用模型与API
在通往最终目标的过程中,OpenAI采取了务实的“小步快跑”策略。2025年3月以来,公司密集发布了一系列关键的音频AI模型和API,这既是技术成果的展示,也是对未来技术栈的模块化构建。
-
语音转文本模型:
gpt-4o-transcribe和gpt-4o-mini-transcribe,专注于提升ASR的准确性和多语言处理能力,为后续的理解提供高质量的文本输入。 -
文本转语音模型:
gpt-4o-mini-tts,致力于提升语音合成的自然度和效率。 -
实时语音模型:GPT-Realtime,这是其技术演进中的一个里程碑。该模型的核心特性是低延迟和强指令执行能力,专为实时对话场景设计。
3.2.2 核心突破:GPT-Realtime的技术内涵
GPT-Realtime的发布,标志着OpenAI在解决延迟和自然度问题上取得了显著进展。其技术突破可能体现在以下几个方面。
-
流式处理 (Streaming):模型不再需要等待用户说完一整句话才开始处理。ASR、NLU(自然语言理解)和TTS模块可以实现流式、并行的工作,即在用户说话的同时,系统就已经开始识别、理解并准备生成回复。
-
端到端优化:虽然内部可能仍是多个模块,但这些模块经过了深度的协同优化。例如,ASR的中间结果可以直接被NLU模块利用,而无需等待最终文本;LLM的生成也可以是token-by-token地流式传输给TTS模块。
-
预测与抢占:更先进的模型甚至可以根据用户已说出的部分内容,预测其意图,并提前开始生成回复的部分内容,从而在用户话音刚落时就能立即响应。
下面是一个简化的Mermaid流程图,展示了传统架构与基于GPT-Realtime的流式架构在处理流程上的差异。
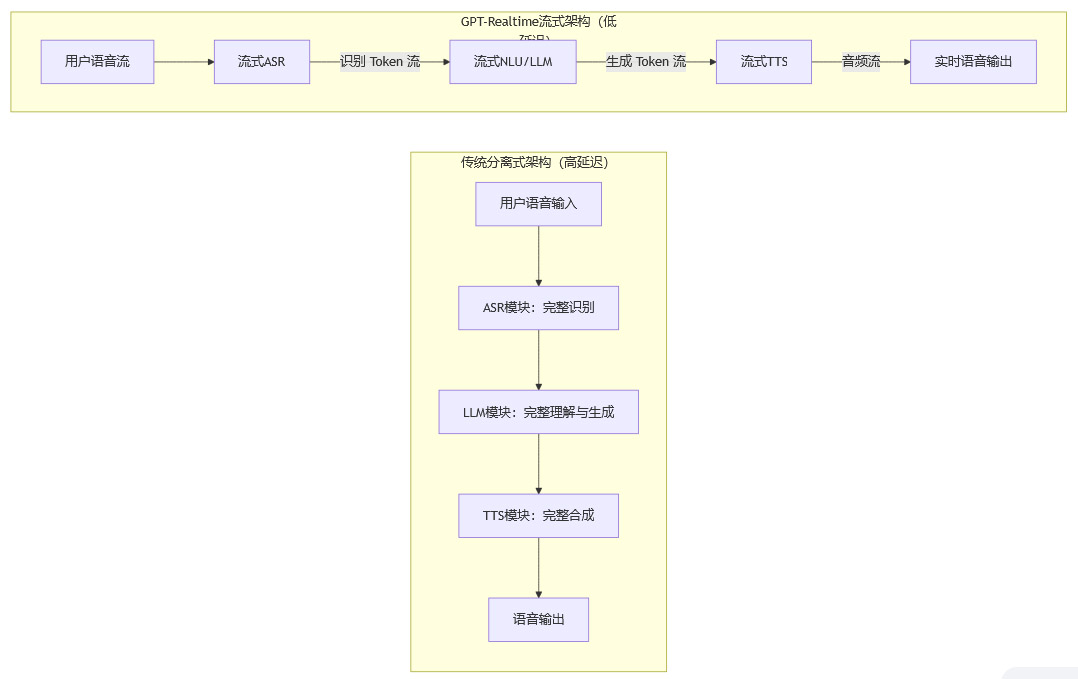
通过开放Realtime API,OpenAI不仅向开发者社区展示了其技术实力,更重要的是,它在为未来的自家硬件构建一个强大的第三方应用生态基础。开发者可以利用这套API构建各种商用语音系统,提前熟悉和适应OpenAI的音频技术范式。
3.3 技术链路的全面构建
除了核心模型,OpenAI还在围绕个人AI设备的需求,打造一条完整的音频技术链路。
-
实时语音识别 (ASR):不仅要准,还要快,并且具备强大的抗噪声能力和多口音适应性。
-
文本转语音 (TTS):追求的不仅是清晰,更是情感、韵律和个性化。未来的TTS或许可以模仿用户的声音,或根据对话场景切换不同的“虚拟人格”。
-
对话管理 (Dialogue Management):在多轮对话中保持上下文一致性,理解指代、省略和隐含意图,处理打断和话题切换。
-
多模态理解 (Multimodal Understanding):这是实现真正智能的关键。未来的设备需要将听到的(语音)与看到的(通过摄像头)信息结合起来。例如,当用户指着一瓶花问“这是什么花?”时,AI需要同时处理语音指令和视觉输入才能正确回答。GPT-4o的发布已经展示了这种强大的多模态融合能力,这无疑是为其硬件产品量身打造的核心功能。
实时性是贯穿整条技术链路的核心指标。对于一个“伴随式助手”而言,任何可感知的延迟都会打破沉浸感。OpenAI的目标,是将端到端的语音交互延迟压缩到接近人类自然对话的水平(通常在200-300毫秒内),同时不牺牲其背后大模型的复杂推理和深度理解能力,这是一个巨大的技术挑战。
四、 多模态融合:超越纯粹的语音交互
如果说优化音频模型是为新设备铺设“地基”,那么多模态能力的深度融合则是构建其上层建筑、实现颠覆性体验的关键。OpenAI的野心绝非仅仅打造一个更会“听”和“说”的ChatGPT,而是要创造一个能够像人一样,通过多种感官综合理解世界并与之交互的AI。
4.1 从语音命令到情境对话
纯粹的语音交互,本质上仍是一种“命令-响应”模式,AI是被动的执行者。而真正智能的助手,必须能够理解对话发生时的完整情境(Context)。这个情境,绝大部分是由视觉信息构成的。
-
没有视觉,AI无法理解用户指着某个物体说的“这个是什么?”。
-
没有视觉,AI无法在用户进行物理操作(如修理器械、烹饪)时,提供精准的、与现实世界同步的指导。
-
没有视觉,AI无法捕捉到对话中非语言的交流线索,如手势、表情,从而丧失了更深层次的共情能力。
因此,语音和视觉的结合,不是简单的功能叠加,而是实现从“工具”到“伙伴”质变的必要条件。
4.2 GPT-4o:为新硬件量身打造的多模态引擎
OpenAI近期发布的GPT-4o模型,其最重要的特性就是原生的、端到端的多模态能力。它可以在一个统一的神经网络中,无缝地处理和推理文本、音频和图像。这绝非巧合,可以看作是OpenAI在为未来的硬件产品,提前亮出的“软件王牌”。
GPT-4o的出现,意味着底层技术已经能够支持以下这类过去难以想象的交互场景:
-
实时视觉问答:用户通过智能眼镜的摄像头直播一场球赛,同时向AI提问“刚才那个进球的球员是谁?”,AI能够结合实时视频画面和语音问题,迅速给出答案。
-
动态交互式指导:用户在学习弹奏吉他,AI可以通过摄像头观察其手型,并通过语音实时提醒“你的无名指按弦位置偏了半厘米”。
-
情感化语音生成:AI在看到用户疲惫的表情后,其语音回复的语调会自动变得更加轻柔和关切。
这种多模态的融合,将交互的带宽和深度提升了数个量级。下表对比了单模态与多模态交互在能力上的根本差异。
|
交互维度 |
单模态语音交互 (当前) |
多模态融合交互 (未来) |
|---|---|---|
|
信息输入 |
仅限语音指令和文本 |
语音、实时视频流、图像、文本 |
|
情境理解 |
依赖对话历史,对物理世界无感知 |
深刻理解物理环境、物体、用户行为和状态 |
|
交互模式 |
被动问答,命令执行 |
主动感知、预测意图、情境化协作 |
|
能力边界 |
知识查询、内容生成、简单任务 |
复杂物理任务指导、实时环境翻译、情感陪伴 |
4.3 统一模型:通往通用人工智能的必经之路
最终,OpenAI的技术路线图指向的是一个完全统一的多模态模型。在这个模型中,不同模态的数据不再需要预先转换成某种中间表示(如文本),而是可以直接在同一个高维空间中进行处理和推理。这将彻底消除模态转换带来的信息损失和延迟,使得AI的感知和反应速度达到甚至超越人类的水平。这不仅是打造终极个人AI设备的技术前提,也被认为是通往通用人工智能(AGI)的关键路径之一。
五、 前路漫漫:技术挑战与产业博弈

尽管OpenAI的愿景激动人心,技术储备也日益雄厚,但要将这一构想变为现实,并成功推向市场,其面前依然横亘着重重挑战。这不仅是技术上的攻坚,更是商业和生态上的激烈博弈。
5.1 个人设备的三难困境
任何试图将强大AI能力塞入小型个人设备的公司,都必须直面一个经典的工程“三难困境”(Trilemma):性能、功耗和隐私三者之间难以兼得。
-
性能 (Performance):运行像GPT-4o这样的大模型需要巨大的算力。完全在云端处理,会引入不可避免的网络延迟,破坏实时体验。完全在端侧处理,目前的小型芯片性能和内存还远远不够。如何进行有效的端云协同(Cloud-Edge Collaboration),将对延迟不敏感的复杂推理放在云端,将需要快速响应的简单任务和感知处理放在端侧,是一个极其复杂的系统工程问题。
-
功耗 (Power Consumption):个人AI设备需要“永远在线、永远感知”(Always-on, Always-aware)。麦克风、摄像头等传感器持续工作,加上本地芯片的推理运算,将对电池续航构成严峻考验。没有任何用户会接受一个每隔两三小时就需要充电的“智能伙伴”。低功耗设计将成为决定产品成败的生命线。
-
隐私 (Privacy):一个持续记录用户所见所闻的设备,引发的隐私担忧是前所未有的。数据的所有权归谁?如何存储和使用?如何防止滥用和攻击?OpenAI必须给出一套令人信服的、透明的隐私保护方案。端侧计算在这里扮演了关键角色,将敏感数据尽可能地保留在本地处理,是赢得用户信任的重要一步。
5.2 生态构建与“杀手级应用”
一款新硬件平台的成功,离不开繁荣的开发者生态和不可替代的“杀手级应用”。
-
生态壁垒:智能手机的成功,建立在iOS和Android两大成熟生态之上。OpenAI的设备需要从零开始构建自己的应用商店、开发者工具链和用户社区。如何吸引开发者为其一个前途未卜的新平台投入资源,是一个先有鸡还是先有蛋的难题。
-
价值主张:这款设备必须能做到一些智能手机“做不到”或“做不好”的事情。它需要一个足够强大的理由,让用户愿意在已经拥有手机、手表、电脑的情况下,再额外购买并佩戴一个新设备。这个“杀手级应用”是什么?是无缝的同声传译,是专家级的实时技能指导,还是前所未有的个性化AI伴侣?OpenAI需要找到并打磨好这个核心价值点。
5.3 巨头环伺的竞技场
个人AI设备赛道早已不是一片无人区,科技巨头们均已在此布局,虎视眈眈。OpenAI作为一个“新玩家”,将面临异常激烈的竞争。
|
竞争者 |
核心优势 |
主要挑战 |
代表产品/战略 |
|---|---|---|---|
|
Apple |
强大的硬件设计与供应链能力、庞大的高端用户群、成熟的操作系统与生态、品牌效应与隐私口碑 |
AI模型能力相对落后,生态封闭,Siri长期被诟病“不够智能” |
Vision Pro、iOS/Siri深度整合、自研芯片 |
|
|
领先的AI研究(Gemini)、Android操作系统的统治地位、强大的云服务与数据积累 |
硬件产品线较为混乱,生态碎片化,隐私问题常受质疑 |
Pixel手机、Google Assistant、Project Astra多模态AI助手 |
|
Meta |
在AR/VR领域布局最早最深、拥有强大的社交平台和内容生态 |
硬件盈利能力待验证,元宇宙概念遇冷,公众信任度较低 |
Meta Quest系列、Ray-Ban智能眼镜、Llama系列模型 |
|
OpenAI |
全球领先的大模型技术、强大的品牌认知度和开发者社区 |
缺乏硬件制造经验和供应链管理能力、无自有操作系统和分发渠道、商业模式尚在探索 |
ChatGPT、GPT-4o、与硬件厂商合作/自研设备 |
在这场博弈中,OpenAI的最大王牌是其顶尖的AI模型能力,而最大的短板则在于硬件和生态的从零起步。它能否将自己的“长板”发挥到极致,以颠覆性的AI体验来弥补硬件生态的不足,将是其成败的关键。
结语
OpenAI对音频AI模型的系统性整合,远不止是一次技术升级。它是一次清晰的战略宣言,宣告了公司将亲自下场,定义并主导下一代个人AI计算平台的决心。通过将强大的多模态AI能力,从云端注入到以语音为核心的个人设备中,OpenAI试图绕开现有的手机操作系统霸权,开辟一个全新的、AI原生的交互入口。
这条道路无疑充满挑战,从核心技术的工程落地,到用户隐私的保障,再到商业生态的构建,每一步都考验着这家AI明星公司的智慧与韧性。目前,新设备的具体形态、价格和上市时间仍笼罩在神秘的面纱之下。但可以确定的是,这场由OpenAI点燃的、围绕个人AI终端的战火,必将深刻重塑未来十年的人机交互范式,并决定谁能最终掌握通往通用人工智能时代的“个人门票”。
📢💻 【省心锐评】
OpenAI此举意在釜底抽薪,绕开手机操作系统,用“语音+硬件”构建原生AI入口,直接争夺下一代个人计算平台的定义权。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 27
27 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)