
【AI小智后端部分(三)】
以下代码包含了编码,保存,加载,解码等,解码部分为opus_to_wav_filePS: 两组save和loadxxx_custom系列:通用、跨语言、推荐生产环境用,手动定义字节格式,适合数据交互 / 长期存储;非xxx_custom系列:Python 专属、快捷、仅调试 / 纯 Python 场景用,依赖 pickle 序列化,不通用;1、添加 funasr 依赖将这些添加到requireme
AI小智后端部分(三)
链接: B站Up
opus解码
以下代码包含了编码,保存,加载,解码等,解码部分为opus_to_wav_file
import os
import uuid
import wave
from typing import List
import pickle
import numpy as np
import opuslib_next
from pydub import AudioSegment
class Opus_Encode:
"""
Opus音频编解码工具类
主要功能:
1. 将MP3/WAV等音频文件编码为Opus帧数据
2. 保存/加载Opus帧数据(自定义二进制格式/pickle序列化)
3. 将Opus帧数据解码并保存为WAV音频文件
"""
def __init__(self):
# 基础音频参数配置(16kHz、单声道、16位采样宽度)
self.sample_rate = 16000
self.channel = 1
self.sample_width = 2
# Opus编码专用参数
self.opus_sample_rate = 16000
self.opus_channel = 1
self.opus_sample_width = 2
self.opus_frame_time = 60 # Opus帧时长(毫秒)
self.opus_frame_size = int(self.opus_sample_rate * self.opus_frame_time / 1000) # 每帧采样数
def audio_to_opus(self, audio_file_path):
"""
将音频文件(MP3/WAV)编码为Opus帧数据
:param audio_file_path: 输入音频文件路径
:return: 二元组(Opus帧数据列表, 音频总时长秒数)
"""
# 获取文件后缀并去除小数点
file_type = os.path.splitext(audio_file_path)[1]
if file_type:
file_type = file_type.lstrip(".")
# 加载音频并统一格式:单声道、16kHz采样率、16位采样宽度
audio = AudioSegment.from_file(audio_file_path, format=file_type)
audio = audio.set_channels(self.channel).set_frame_rate(self.sample_rate).set_sample_width(self.sample_width)
# 计算音频总时长(秒)
duration = len(audio) / 1000
# 获取音频原始PCM字节数据
raw_data = audio.raw_data
print(f"音频PCM数据长度:{len(raw_data)} 字节")
# 初始化Opus编码器(音频场景)
encoder = opuslib_next.Encoder(self.opus_sample_rate, self.opus_channel, opuslib_next.APPLICATION_AUDIO)
frame_num = self.opus_frame_size
# 计算每帧的字节数(采样数*声道数*采样宽度)
frame_bytes_size = frame_num * self.opus_channel * self.opus_sample_width
opus_datas = []
# 按帧切分PCM数据并逐帧编码
for i in range(0, len(raw_data), frame_bytes_size):
chunk = raw_data[i:i+frame_bytes_size]
chunk_len = len(chunk)
# 不足一帧的部分补0对齐
if chunk_len < frame_bytes_size:
chunk += b'\x00' * (frame_bytes_size - chunk_len)
# 转换为int16格式后编码为Opus数据
np_frame = np.frombuffer(chunk, dtype=np.int16)
np_bytes = np_frame.tobytes()
opus_data = encoder.encode(np_bytes, frame_num)
opus_datas.append(opus_data)
return opus_datas, duration
def save_opus_raw_custom(self, opus_frames, output_path):
"""
自定义格式保存Opus帧数据(4字节大端序帧长度 + 帧数据)
:param opus_frames: Opus帧数据列表
:param output_path: 输出文件路径
"""
with open(output_path, 'wb') as f:
for frame in opus_frames:
f.write(len(frame).to_bytes(4, byteorder='big'))
f.write(frame)
print(f"Saved raw opus data to {output_path}")
def load_opus_raw_custom(self, input_path):
"""
加载自定义格式保存的Opus帧数据
:param input_path: 输入文件路径
:return: Opus帧数据列表
"""
frames = []
with open(input_path, 'rb') as f:
data = f.read()
index = 0
while index < len(data):
# 读取4字节帧长度(大端序)
frame_len = int.from_bytes(data[index:index + 4], byteorder='big')
index += 4
# 读取对应长度的帧数据
frame = data[index:index + frame_len]
index += frame_len
frames.append(frame)
return frames
def save_opus_raw(self, opus_frames, output_path):
"""
使用pickle序列化保存Opus帧列表(完整Python列表结构)
:param opus_frames: Opus帧数据列表
:param output_path: 输出文件路径
"""
with open(output_path, 'wb') as f:
pickle.dump(opus_frames, f)
print(f"Saved raw opus data to {output_path}")
def load_opus_raw(self, input_path):
"""
加载pickle序列化的Opus帧列表
:param input_path: 输入文件路径
:return: Opus帧数据列表
"""
with open(input_path, 'rb') as f:
opus_frames = pickle.load(f)
return opus_frames
def opus_to_wav_file(self, opus_data: List[bytes]) -> str:
"""
将Opus帧数据解码并保存为WAV文件
:param opus_data: Opus帧数据列表
:return: 生成的WAV文件路径
"""
# 生成唯一文件名并指定保存路径(tmp目录)
file_name = f"{uuid.uuid4().hex}.wav"
file_path = os.path.join("tmp/", file_name)
# 初始化Opus解码器(16kHz、单声道)
decoder = opuslib_next.Decoder(16000, 1)
pcm_data = []
# 逐帧解码Opus数据
for opus_frame in opus_data:
try:
pcm_frame = decoder.decode(opus_frame, self.opus_frame_size)
pcm_data.append(pcm_frame)
except opuslib_next.OpusError as e:
print(f"Opus解码失败: {e}")
# 将解码后的PCM数据写入WAV文件
with wave.open(file_path, "wb") as wf:
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(16000)
wf.writeframes(b"".join(pcm_data))
return file_path
if __name__ == '__main__':
# 实例化编解码工具
opus = Opus_Encode()
# 1. 编码:MP3文件转Opus帧数据
opus_data, duration = opus.audio_to_opus("../../test.mp3")
print(f"音频总时长:{duration} 秒")
# 2. 保存:Opus帧数据写入自定义格式文件
opus.save_opus_raw_custom(opus_data, "output.opus")
# 3. 加载:从自定义格式文件读取Opus帧数据
opus_data1 = opus.load_opus_raw_custom("output.opus")
# 4. 解码:Opus帧数据转WAV文件
opus.opus_to_wav_file(opus_data1)
PS: 两组save和load
xxx_custom系列:通用、跨语言、推荐生产环境用,手动定义字节格式,适合数据交互 / 长期存储;
非xxx_custom系列:Python 专属、快捷、仅调试 / 纯 Python 场景用,依赖 pickle 序列化,不通用;
解码后的 wav 喂给本地 asr
1、添加 funasr 依赖
funasr==1.2.6
torch==2.2.2
torchaudio==2.2.2
将这些添加到requirement.txt里,然后
打开终端;
激活名为ai-server的 conda 环境;conda activate ai-server
通过requirements.txt文件安装项目依赖库。pip install -r requirements.txt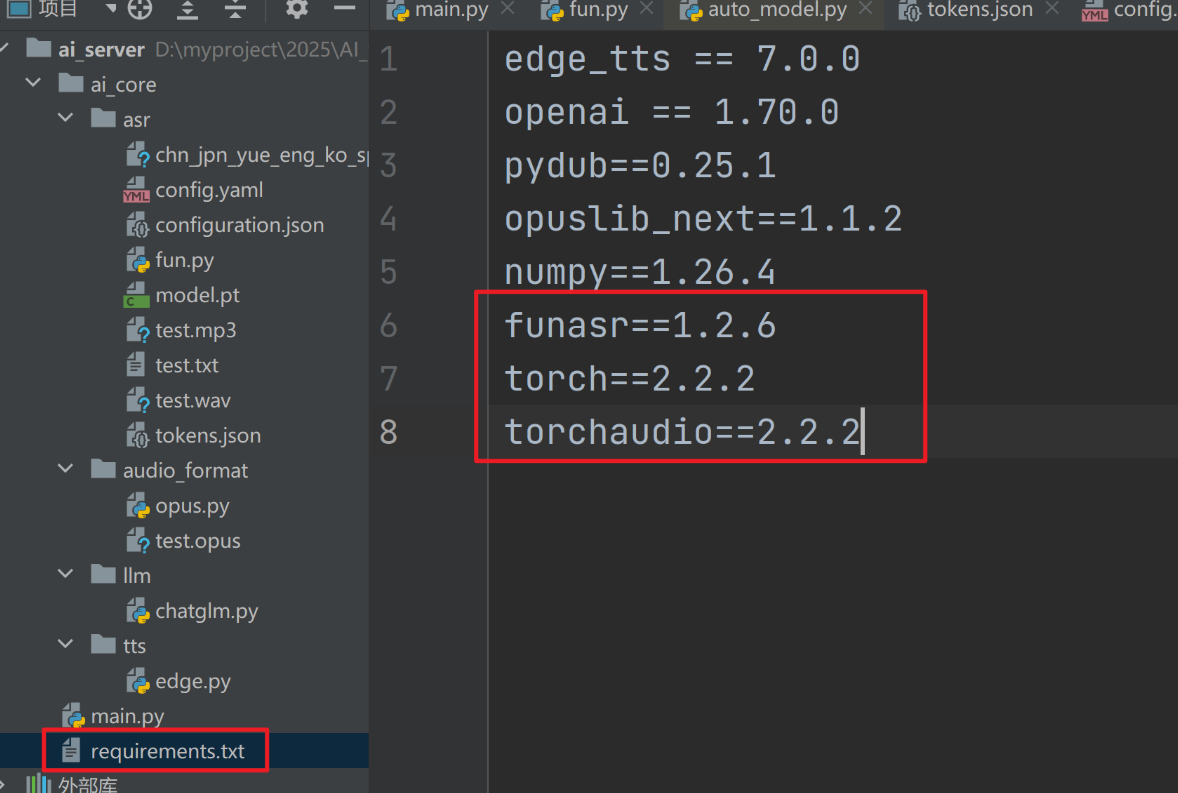
大概作用:
torchaudio处理音频数据 → 交给funasr(基于torch运行) → 输出语音识别结果
2、下载模型文件
为了保证版本通义建议下载我网盘的(推荐下载这个)链接: (来自B站Up)https://pan.baidu.com/s/1CglNzlWdvEI4Tjp-S3xFRA 提取码: 77cd
网下载(下载了我网盘就不要去官网下载了)https://modelscope.cn/models/iic/SenseVoiceSmall/files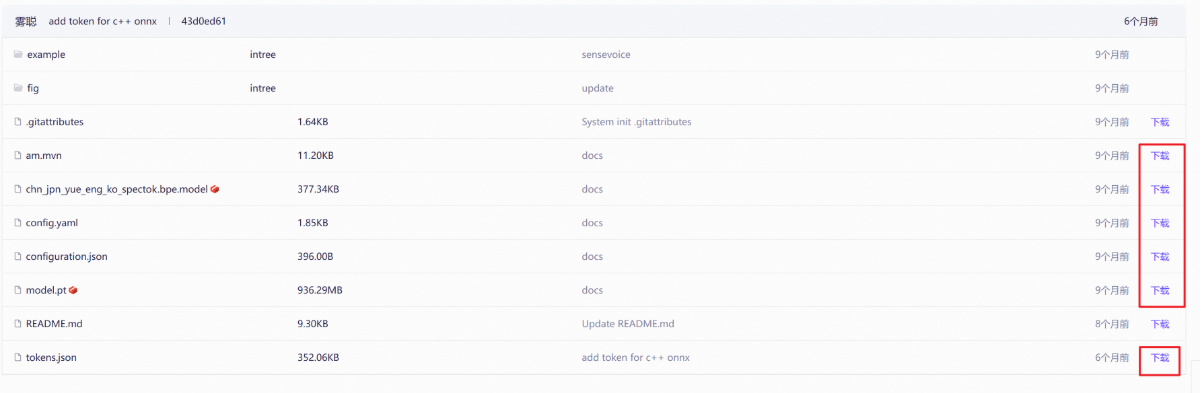
3、将下载的模型文件放到工程目录中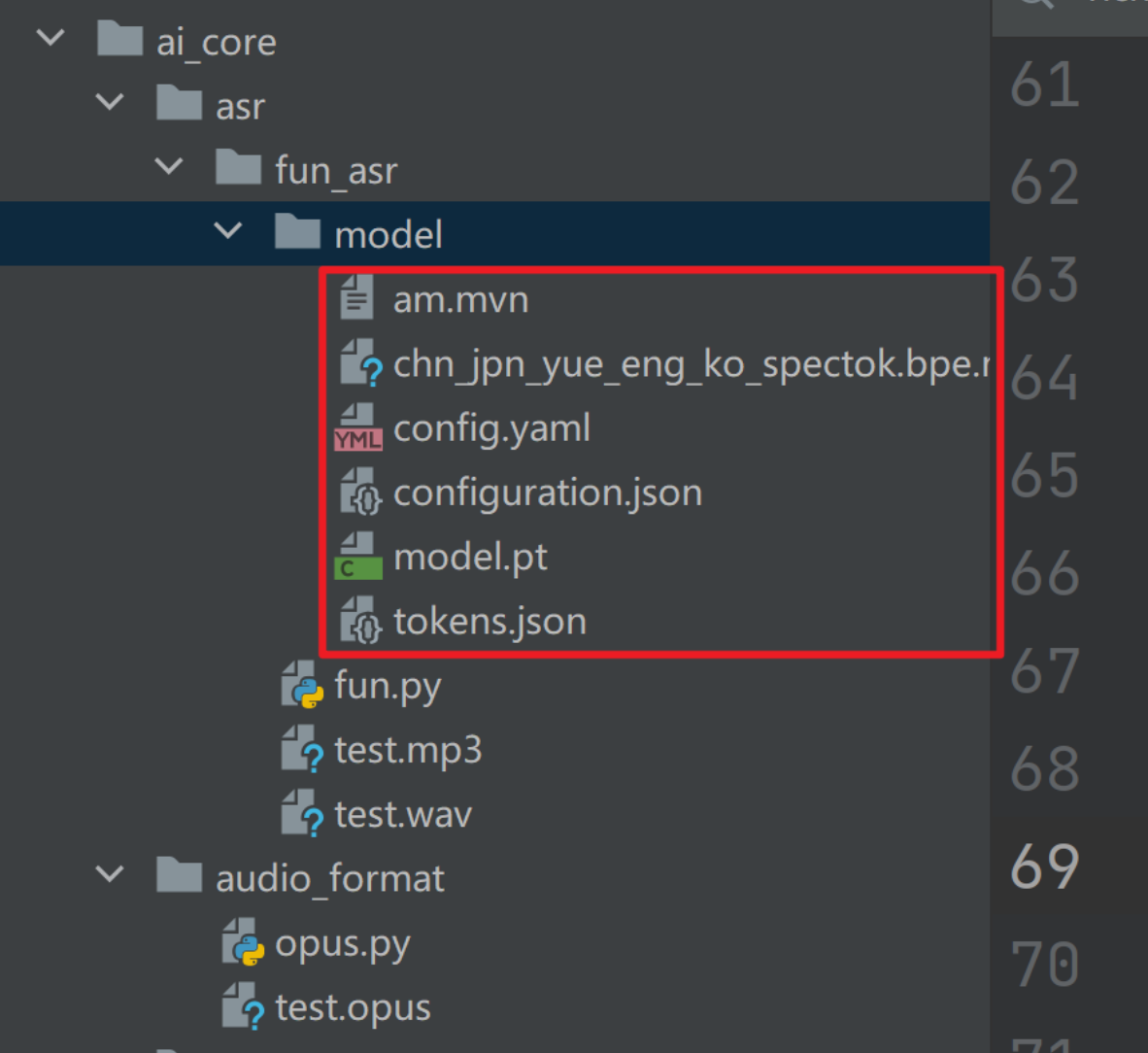
4、编写代码执行推理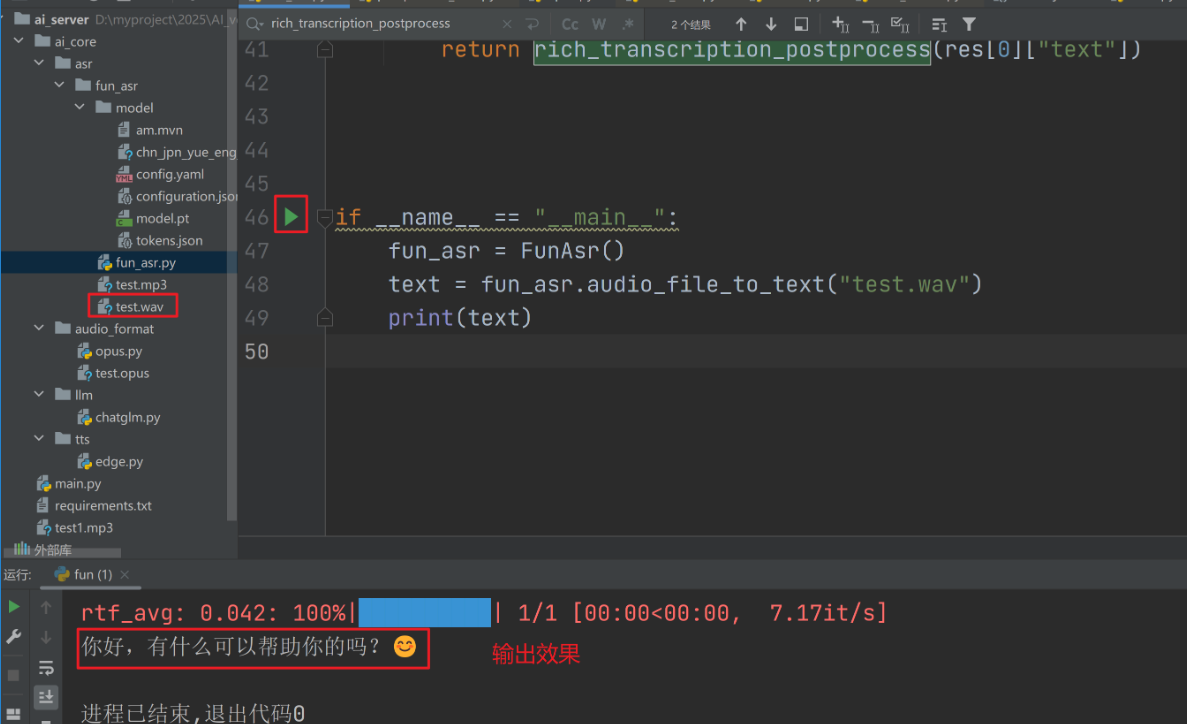
import os
from typing import List
from funasr import AutoModel
import torch
from funasr.utils.postprocess_utils import rich_transcription_postprocess
class FunAsr:
"""基于FunASR的语音识别工具类"""
def __init__(self):
# 获取当前文件所在目录,拼接模型存放路径
self.current_dir = os.path.dirname(os.path.abspath(__file__))
self.model_dir = os.path.join(self.current_dir, "model") # 模型文件存放在当前目录的model子文件夹
# 加载FunASR模型(指定VAD最大单段时长、设备为GPU)
self.model = AutoModel(
model=self.model_dir,
vad_kwargs={"max_single_segment_time": 30000}, # VAD单段最长30秒
device="cuda:0", # 使用第0块GPU
disable_update=True,
hub="hf",
)
def audio_file_to_text(self, file_path):
"""将音频文件转为文字"""
# 执行语音识别推理
res = self.model.generate(
input=file_path, # 输入音频文件路径
language="auto" # 自动识别语言
)
# 对识别结果做后处理(格式化输出)
return rich_transcription_postprocess(res[0]["text"])
if __name__ == "__main__":
# 实例化工具类并测试识别
fun_asr = FunAsr()
text = fun_asr.audio_file_to_text("test.wav") # 识别test.wav文件
print(text) # 打印识别结果
1.初始化环节(__init__方法)
自动定位本地存放的 FunASR 预训练模型文件夹(当前代码文件同级的model目录);
加载语音识别模型,并配置核心参数:
用 GPU(cuda:0)运行模型(提升识别速度);
长音频自动切分成 30 秒以内的片段识别;
禁用模型自动更新,保证运行稳定。
2.核心识别环节(audio_file_to_text 方法)
接收一个 WAV 音频文件路径作为输入;
调用 FunASR 模型的generate方法执行语音识别(自动识别音频语言);
对识别结果做后处理(格式化文本、修正识别误差),返回最终的文字内容。
3.测试环节(主函数)
实例化工具类,对test.wav这个音频文件做识别;
打印出识别后的文字结果。
5、验证效果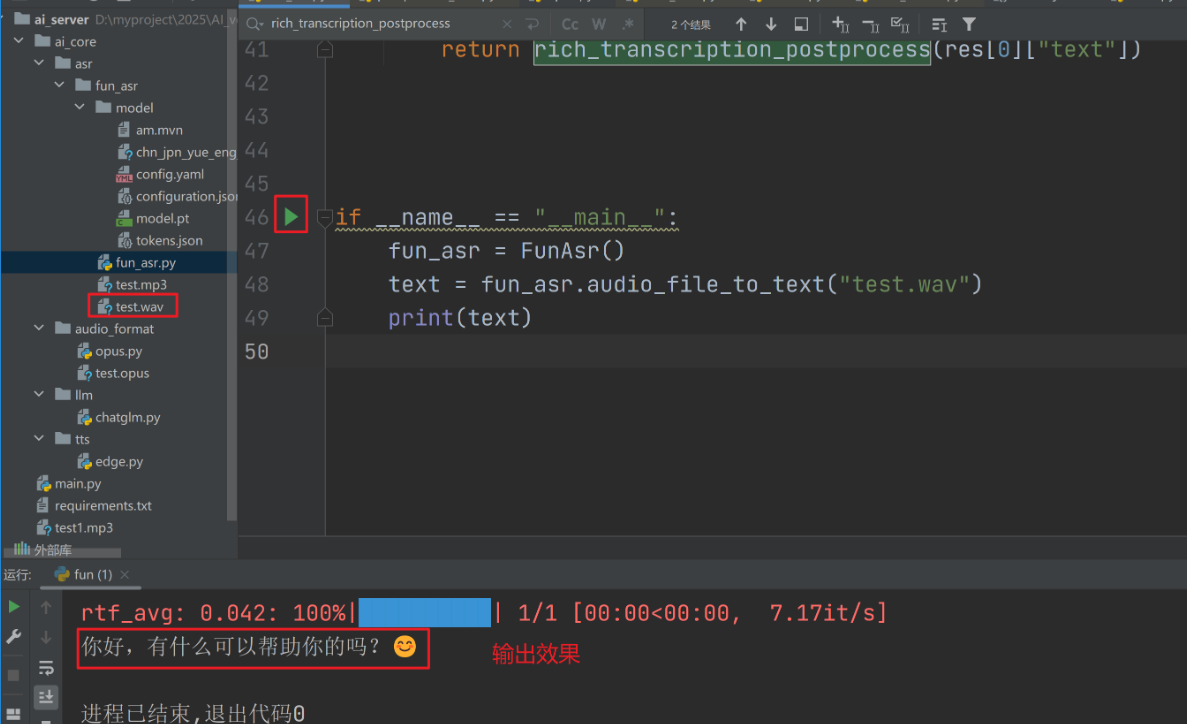
funASR 语音识别模型训练与推理整体流程
1.funASR 语音识别整体流程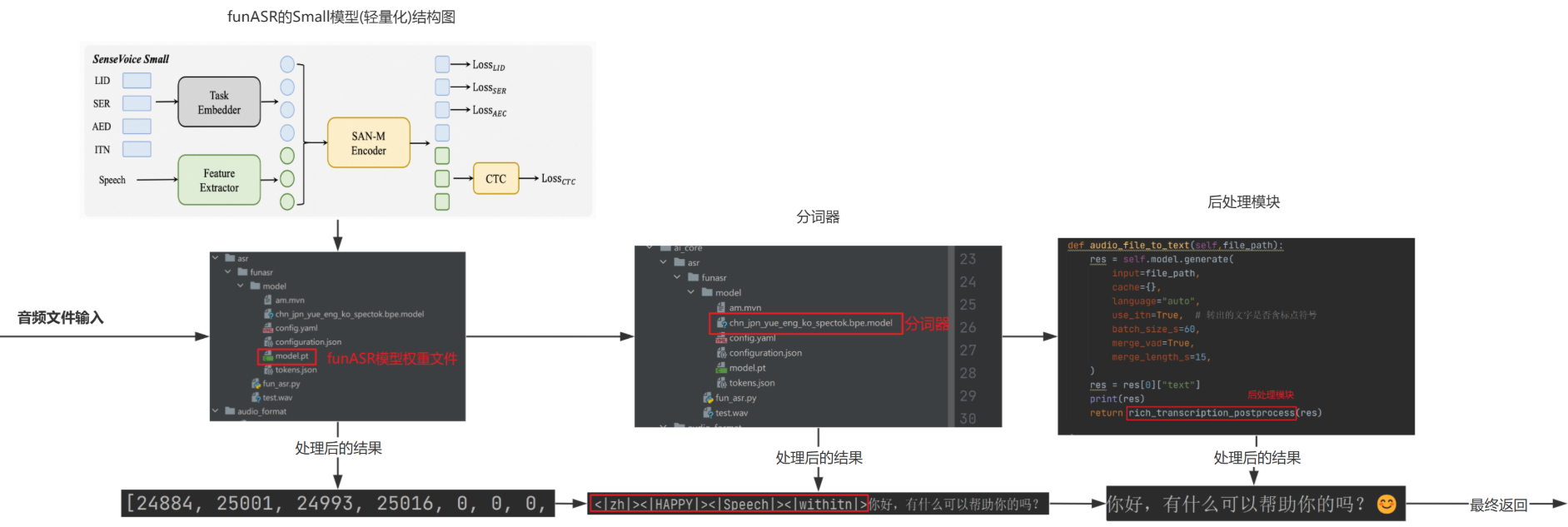
LID: 语言识别,如中文会输出标签 | zh|
SER: 情绪识别如开心 | HAPPY|
AED: 用于预测音频包含的事件标签
ITN: 归一化处理,例如加标点,或将三点五公斤转为 3.5kg
1.输入音频文件 → 经过模型内部的特征提取、多任务编码(同时做 LID 语言识别、SER 情绪识别等);
2.依赖模型文件 → 加载权重文件(model.pt)、分词器等资源,把音频转成中间编码;
3.输出多维度结果 → 不仅转文字,还会加上语言标签(如 | zh | 表示中文)、情绪标签(如 | HAPPY | 表示开心);
4.后处理优化 → 通过 ITN 归一化(加标点、格式转换),最终得到通顺的文字(比如 “你好,有什么可以帮助你的吗?😊”)。
2.模型训练示意图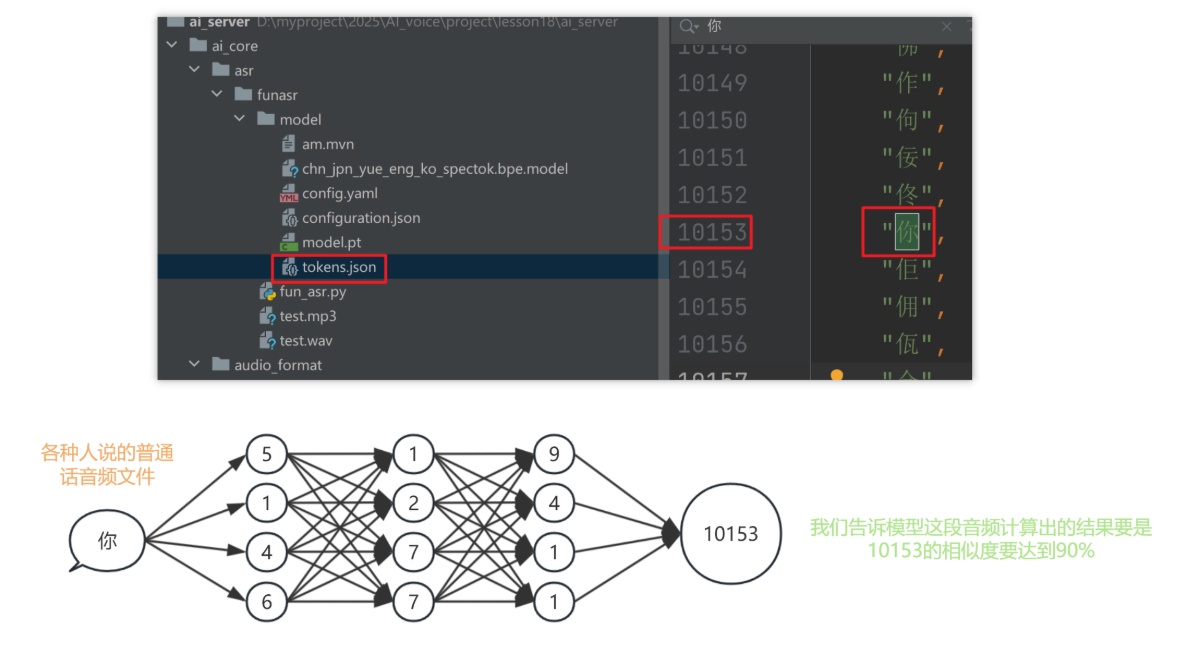
3.、代码佐证
import os
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
class FunAsr:
def __init__(self):
self.current_dir = os.path.dirname(os.path.abspath(__file__))
self.model_dir = os.path.join(
self.current_dir, # 当前文件所在目录
"model" # 目标子目录
)
self.model = AutoModel(
model=self.model_dir,
vad_kwargs={"max_single_segment_time": 30000},
# device="cuda:0",
disable_update=True,
hub="hf",
)
self.raw_outputs = {} # 存储模型原始输出
self.hooks = [] # 存储钩子句柄
def audio_file_to_text(self,file_path):
res = self.model.generate(
input=file_path,
cache={},
language="auto",
use_itn=True, # 转出的文字是否做了归一化(是否加标点,又或者是否将三点五转为3.5)
batch_size_s=60,
merge_vad=True,
merge_length_s=15,
)
res = res[0]["text"]
print(res)
return rich_transcription_postprocess(res)
def _register_hooks(self):
"""注册钩子到输出层(示例:Paraformer的CTC头部)"""
# 假设输出层是 model.ctc.ctc_lo
output_layer = self.model.model.ctc.ctc_lo
# 定义钩子函数
def hook_function(module, inputs, outputs):
# outputs 是 logits(未归一化的概率)
self.raw_outputs["ctc_logits"] = outputs.clone()
# 注册钩子
hook = output_layer.register_forward_hook(hook_function)
self.hooks.append(hook)
def _remove_hooks(self):
for hook in self.hooks:
hook.remove()
self.hooks.clear()
self.raw_outputs.clear()
if __name__ == "__main__":
funasr = FunAsr()
funasr._register_hooks()
res = funasr.audio_file_to_text("test.wav")
# 打印模型原始输出
if funasr.raw_outputs:
logits = funasr.raw_outputs["ctc_logits"]
print("模型传给分词器的原始 Logits 形状:", logits.shape) # 例如 [batch, seq_len, vocab_size]
# 获取 Token IDs(假设使用 argmax 解码)
token_ids = logits.argmax(dim=-1).squeeze().tolist()
print("Token IDs:", token_ids)
print(res)
与之前的代码相同,就是测试部分改了一些。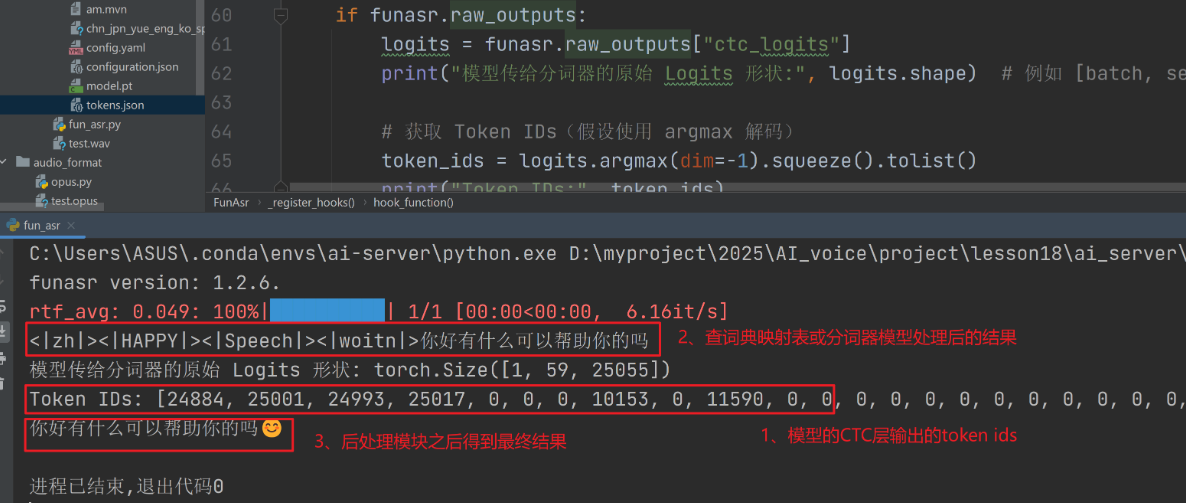

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)