
昇腾双机16卡部署DeepSeek-V3.2 (W8A8) 实战指南
● 为了避免 CP 模式下各卡计算量不均(序列后端 Token 关注的历史更长),实战方案采用了 Token 对称重排,使得 16 张卡的算力利用率趋于一致,从而优化了整体 TTFT(首字延迟)。:确保 MindIE 的连续批处理功能已开启(默认开启),它能让不同长度的请求穿插执行,减少空等待。通过在容器内开启该功能,能让不同请求的解码与预填充穿插执行,显著降低队列延迟。:在 MindIE 配置文
昇腾双机16卡部署DeepSeek-V3.2 (W8A8) 实战指南

🌈你好呀!我是 是Yu欸
🚀 感谢你的陪伴与支持~ 欢迎添加文末好友
🌌 在所有感兴趣的领域扩展知识,不定期掉落福利资讯(*^▽^*)
写在最前面
版权声明:本文为原创,遵循 CC 4.0 BY-SA 协议。转载请注明出处。
摘要:在国产算力崛起的浪潮下,如何将 DeepSeek-V3.2 这样企业级的 MoE 大模型高效部署在昇腾 NPU 集群上?
本文将手把手带你打通从驱动安装到双机分布式推理的全链路。
我们不仅提供可复现的代码,还解析了 HCCL 通信、MindIE 服务化以及 W8A8 量化背后的关键技术点。
其背后是针对 DSA(DeepSeek Sparse Attention) 稀疏架构进行的软硬协同优化。在双机 16 卡的环境下,通过多维并行与量化技术,实现了长序列的高性能推理。
本文目标不仅仅是让用户复制粘贴代码跑通的一份操作日志,同时也方便理解“为什么在大模型分布式部署中要这么做” 的技术指南。
难度等级:⭐⭐⭐⭐⭐⭐ (分布式 / 裸金属 / 量化)
关键词:DeepSeek, 昇腾NPU, MindIE, W8A8, 分布式推理
📖 一、 项目背景:为什么选择 W8A8 与分布式?
DeepSeek-V3.2 是一款强大的混合专家(MoE)模型,其参数量巨大。在实际落地中,我们面临两个核心挑战:
1. 显存墙(Memory Wall):单张显卡无法装下完整权重。
2. 通信墙(Communication Wall):模型切分后,卡间通信延迟直接决定推理速度。
解决方案:
● 双机 16 卡分布式部署:利用两台 Atlas 800I A2 服务器,通过 HCCL(华为集合通信库)实现高速互联。
● W8A8 量化:将权重(Weight)和激活(Activation)都量化为 8-bit。这不仅将显存占用减半,更利用了 NPU 的 INT8 矩阵计算加速能力,是目前支撑长序列低时延推理、追求极致吞吐的主流方案。
🛠️ 二、 环境准备:夯实地基
在容器化之前,宿主机(Host)的健康状态决定了上层应用的稳定性。
1. 准备工作
● 硬件:2台 裸金属服务器
● 规划:
○ 节点1 (Master): 10.200.2.2
○ 节点2 (Worker): 10.200.2.x (确保二者网络互通。请确保两台服务器能够免密互通)
2. 驱动与固件安装
注意:此步骤需在 两台服务器 上分别执行。
💡 知识加油站:驱动 vs 固件
● 驱动 (Driver):运行在 CPU 侧,负责让操作系统“看见”并管理 NPU 设备。
● 固件 (Firmware):运行在 NPU 芯片内部,负责控制芯片的启动、功耗和底层计算。
● 避坑指南:二者版本必须严格配套(如 25.2.9 配 7.7.6.6),否则会出现“能看到卡但跑不动模型”的诡异问题。
Bash
# 1. 赋予安装包执行权限
chmod +x Ascend-hdk-919b-npu-driver_25.2.9_Linux-aarch64.run
chmod +x Ascend-hdk-919b-npu-firmware_7.7.6.6.236.run
# 2. 安装驱动 (使用 --full 全量安装,包含管理工具)
./Ascend-hdk-919b-npu-driver_25.2.9_Linux-aarch64.run --full --install-for-all
# 3. 安装固件
./Ascend-hdk-919b-npu-firmware_7.7.6.6.236.run --full
# 4. 重启生效 (必须步骤!否则内核模块不会重新加载)
reboot重启后检查:执行 npu-smi info,确保 8 张卡状态均为 OK。
🐳 三、 容器化环境构建
为了屏蔽复杂的 OS 依赖,我们使用华为官方 MindIE 镜像。

1. 资源准备
● 镜像下载:
● Bash
docker pull swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:2.2.130-800I-A2-py311-openeuler24.03-1ts-arm64● 权重准备:将 DeepSeek 模型权重放置在宿主机 /work/deepseek/parameters/ 目录下。
2. 启动容器 (双机执行)
这是部署中最长的一条命令,我们来拆解一下为什么要这么写:
💡 关键参数解析:
● --net=host:必选。 分布式推理对延迟极度敏感。使用 Host 模式可以让容器共用宿主机网卡,避免 Docker NAT 转换带来的性能损耗(约 5-10%)。
● --ipc=host & --shm-size 500g:必选。 PyTorch 的多进程通信(HCCL)严重依赖共享内存。默认容器只有 64MB,不改这个参数,模型一跑起来就会报 Bus error 或 OOM。
● --device:直通所有 NPU 及管理设备 (davinci_manager)。
Bash
docker run -itd --privileged \
--name=deepseekLocal \
--net=host \
--ipc=host \
--shm-size 500g \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/ \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/sbin:/usr/local/sbin \
-v /etc/hccn.conf:/etc/hccn.conf \
-v /var/log/npu/conf/slog/slog.conf:/var/log/npu/conf/slog/slog.conf \
-v /var/log/npu/slog/:/var/log/npu/slog \
-v /var/log/npu/profiling/:/var/log/npu/profiling \
-v /var/log/npu/dump/:/var/log/npu/dump \
-v /var/log/npu/:/usr/slog \
-v /data/:/data/ \
-v /nfs/:/nfs/ \
-v /work/deepseek/parameters/DeepseekV3.2-quant:/work/deepseek/parameters/DeepseekV3.2-quant \
swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:2.2.130-800I-A2-py311-openeuler24.03-1ts-arm64 \
bash⚡ 四、 部署流程:注入灵魂 (配置与启动)
容器启动了,但现在它只是一个空壳。我们需要通过环境变量和配置文件告诉它:你是谁?你的队友在哪里?怎么分配内存?
1. 资源装载
将配置文件和修改过量化算子的代码包(atb-models)复制进容器。
Bash
docker cp /work/deepseek/resource2/hccl_2s_16p.json deepseekLocal:/work/deepseek
docker cp /work/deepseek/config.json deepseekLocal:/usr/local/Ascend/mindie/latest/mindie-service/conf/
docker cp /work/deepseek/test/atb-models deepseekLocal:/usr/local/Ascend
2. 环境变量配置 (核心实战)
进入容器:docker exec -it deepseekLocal /bin/bash
我们将环境变量分为三组来理解:
A. 基础环境组
加载昇腾软件栈(CANN)和加速库(ATB)。
Bash
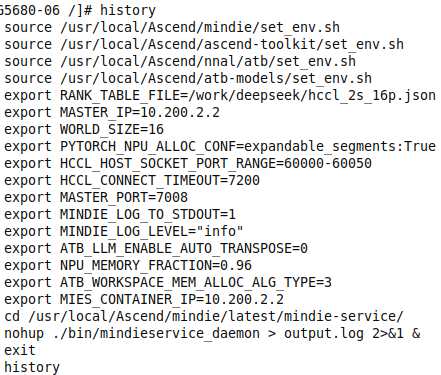
source /usr/local/ascend/mindie/set_env.sh
source /usr/local/ascend/ascend-toolkit/set_env.sh
source /usr/local/ascend/nnal/atb/set_env.sh
source /usr/local/ascend/atb-models/set_env.shB. 分布式通信组 (HCCL)
这是多机部署成败的关键。RANK_TABLE_FILE 就像一张“花名册”,告诉集群有哪些节点参与计算。
Bash
export RANK_TABLE_FILE=/work/deepseek/hccl_2s_16p.json
export MASTER_IP=10.200.2.2
# 指挥官IP(两台机器保持一致)
export WORLD_SIZE=16
# 总兵力(16卡)
export MASTER_PORT=7008
export HCCL_HOST_SOCKET_PORT_RANGE=60000-60050
export HCCL_CONNECT_TIMEOUT=7200C. 性能优化组 (Tuning)
DeepSeek 这种大模型对显存管理要求极高。
Bash
# 减少显存碎片,允许内存段动态扩展
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
# 日志配置
export MINDIE_LOG_TO_STDOUT=1
export MINDIE_LOG_LEVEL="info"
# 算子优化:关闭自动转置,使用特定内存分配算法
export ATB_LIM_ENABLE_AUTO_TRANSPOSE=0
export ATB_WORKSPACE_MEM_ALLOC_ALG_TYPE=3
# 【关键】显存高水位设置# 设置为 0.96 意味着允许模型使用 96% 的 NPU 显存。
# 剩下的 4% 必须留给系统内核和通信 buffer,否则必崩。
export NPU_MEMORY_FRACTION=0.96
# 【注意】本机 IP 设置 (节点2需修改为 10.200.2.x)
export MIES_CONTAINER_IP=10.200.2.2DeepSeek-V3.2 引入了革命性的 DSA(稀疏注意力) 模块。实战指南中加载的融合算子包(atb-models)正是为了实现这一特性。
● Lightning Indexer (LI) 算子融合
○ 实战动作:通过 ATB_WORKSPACE_MEM_ALLOC_ALG_TYPE=3 优化内存分配。
○ 技术原理:LI 算子负责从海量 Token 中筛选 Top-k 个重要位置。在底层,它采用了 Mat-Duce 算法,利用数学变换将规约计算转化为矩阵乘法,充分发挥 Cube 核的随路 ReLU 和反量化能力,使 Top-k 筛选效率提升了约 20%。
3. 启动 MindIE 服务
一切就绪,拉起推理服务守护进程。
Bash
cd /usr/local/ascend/mindie/latest/mindie-service/
nohup ./bin/mindieservice_daemon > output.log 2>&1 &建议使用 tail -f output.log 观察启动日志,看到 "Server Ready" 即为成功。
✅ 五、 验证与测试:跑通第一公里
部署完成只是开始。DeepSeek-V3.2 (W8A8) 在国产算力上的真实表现如何?首字延迟(TTFT)是否达标?高并发下是否会崩?
下面将带你构建一套基于 aiohttp 的异步压测工具,通过长序列与高并发两组硬核实验,用真实数据揭开 DeepSeek x 昇腾 NPU 的性能底牌。
关键词:性能测试, Benchmark, TTFT, TPOT, 吞吐量, Python异步编程
第一阶段:仓库样例冒烟测试 (Repo Smoke Test)
目的:直接运行仓库内最简单的推理脚本,验证环境连通性、模型加载及 W8A8 量化精度是否正常,确保“跑通”。
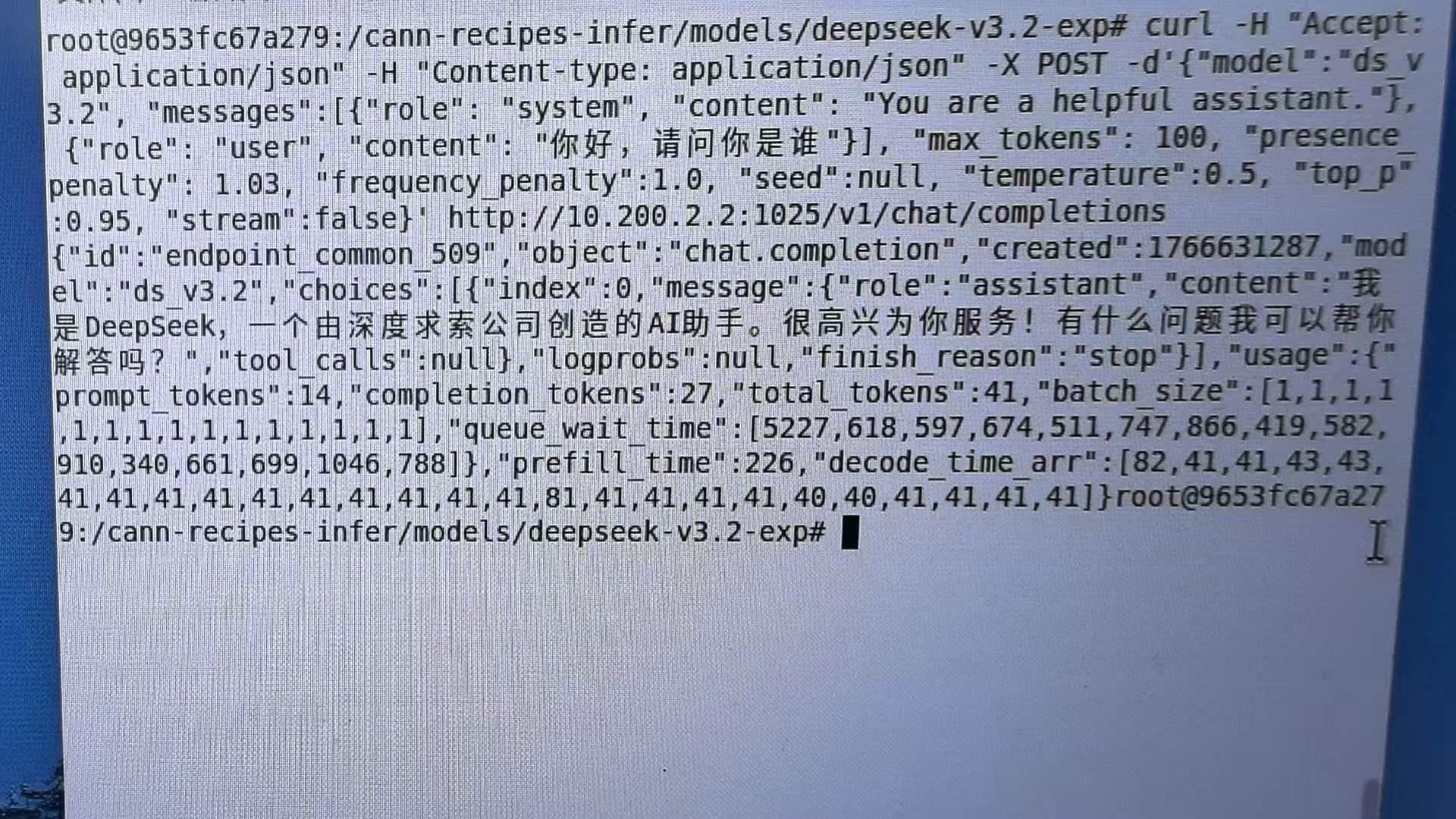
curl -H 'Accept: application/json' -H 'Content-Type: application/json' -X POST -d '{
"model":"ds-3.2",
"messages": [{
"role":"system",
"content":"You are a helpful assistant."
},{"role":"user","content":"你好,请问你是谁"}],
"max_tokens":100,
"presenceenalty": 1.03,
"frequency penalty":1.0,
"seed":null, "temperature":0.5, "top p"0.95, "stream":false
}' http://物理机ip(主节点):10.200.2.2:1025/v1/chat/completions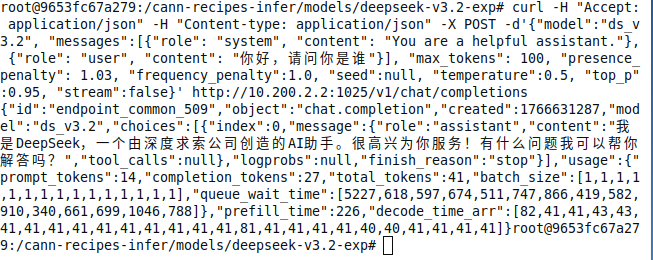
第二阶段:基准性能代码Benchmark
服务启动后,我们需要验证推理链路是否通畅。这里使用 CANN 官方 Benchmark 工具。

在 LLM 推理场景中,我们不能只看“每秒生成多少字”,必须关注以下三个核心指标。我们的测试工具将围绕它们构建。
1. TTFT (Time To First Token):首字延迟。用户发出请求到看到第一个字的时间。决定了用户的“体感响应速度”。数值越小,代表用户感觉到“响应越快”。
2. TPOT (Time Per Output Token):每输出一个 Token 的耗时。决定了生成长文时的流畅度。数值越小,代表用户感觉到“响应越快”。
3. Throughput (吞吐量):系统单位时间内处理的 Token 总数。决定了系统的并发承载上限。数值越大,代表服务并发处理能力越强。
# 1. 准备测试工具
git clone https://gitcode.com/cann/cann-recipes-infer.git
cd cann-recipes-infer/
pip install aiohttp pandas matplotlib seaborn numpy cloudpickle ml-dtypes tornado jinja2
# 2. 进入测试目录 (注意处理文件名空格)
cd /root/.cache/
cd "deepseek npu_benchmark"
# 3. 运行 Benchmark
sh ./run_suite.sh1. 核心压测客户端 (benchmark_client.py)
这个脚本是测试的核心。它基于 aiohttp 实现异步并发,能够精确捕捉流式响应中的第一个 Token 时间(TTFT)。
💡 代码亮点:
● generate_prompt:模拟生成指定长度的输入,保证测试条件一致。
● stream=True:必须开启流式模式,否则无法计算首字延迟。
● asyncio:使用异步协程,单线程即可模拟高并发请求。
Python
import argparse
import asyncio
import json
import time
import os
import aiohttp
import numpy as np
from datetime import datetime
from typing import Dict, List, Optional
# 配置项
API_KEY = "EMPTY" # 本地部署通常不需要 Key
MODEL_NAME = "ds_v3.2" # 请修改为实际部署的服务端模型名称
class TokenEstimator:
"""Token长度估算器"""
@staticmethod
def generate_prompt(token_len: int) -> str:
"""
生成指定Token长度的Prompt
近似估算:1汉字≈1.5token,这里用英文单词重复模拟
注意:这只是近似,生产环境建议使用 Tokenizer
"""
base_str = "DeepSeek " # 每个"DeepSeek "约2个token
repeat_count = max(1, int(token_len / 2))
return base_str * repeat_count
class BenchmarkClient:
"""基准测试客户端"""
def __init__(self, base_url: str):
self.base_url = base_url
async def send_request(
self,
session: aiohttp.ClientSession,
prompt: str,
max_tokens: int,
request_id: int
) -> Optional[Dict]:
"""发送单个请求并收集性能指标"""
url = f"{self.base_url}/chat/completions"
payload = {
"model": MODEL_NAME,
"messages": [{"role": "user", "content": prompt}],
"max_tokens": max_tokens,
"stream": True, # 必须开启流式以计算 TTFT
"temperature": 0.1,
}
start_time = time.time()
first_token_time = 0
output_tokens = 0
try:
headers = {"Authorization": f"Bearer {API_KEY}"}
async with session.post(url, json=payload, headers=headers) as response:
if response.status != 200:
print(f"Error {response.status} for request {request_id}")
return None
async for line in response.content:
if line:
decoded = line.decode('utf-8').strip()
if decoded.startswith("data: ") and decoded != "data: [DONE]":
if first_token_time == 0:
first_token_time = time.time()
output_tokens += 1
end_time = time.time()
except Exception as e:
print(f"Request {request_id} failed: {e}")
return None
# 计算性能指标
ttft = first_token_time - start_time if first_token_time > 0 else 0
total_time = end_time - start_time
# 计算 TPOT (Time Per Output Token)
if output_tokens > 1:
tpot = (total_time - ttft) / (output_tokens - 1)
else:
tpot = 0
return {
"request_id": request_id,
"status": "success",
"ttft_ms": ttft * 1000,
"tpot_ms": tpot * 1000,
"total_time_s": total_time,
"output_tokens": output_tokens,
"throughput": output_tokens / total_time if total_time > 0 else 0
}
class ResultProcessor:
"""结果处理器"""
@staticmethod
def save_results(
results: List[Dict],
concurrency: int,
input_len: int,
output_dir: str,
tag: str
) -> str:
"""保存原始测试结果"""
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
# 生成文件名
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
file_name = f"raw_data_{tag}_{timestamp}.jsonl"
file_path = os.path.join(output_dir, file_name)
# 写入数据
with open(file_path, "w", encoding="utf-8") as f:
for result in results:
# 添加测试参数
result.update({
"concurrency": concurrency,
"input_len": input_len,
"model_name": MODEL_NAME,
"timestamp": timestamp
})
f.write(json.dumps(result, ensure_ascii=False) + "\n")
return file_path
@staticmethod
def print_summary(results: List[Dict]):
"""打印测试摘要"""
if not results:
print("没有有效的测试结果")
return
ttft_values = [r["ttft_ms"] for r in results]
tpot_values = [r["tpot_ms"] for r in results if r["tpot_ms"] > 0]
throughput_values = [r["throughput"] for r in results]
print("\n" + "="*60)
print("测试摘要:")
print(f" 成功请求数: {len(results)}")
print(f" TTFT (ms) - 平均: {np.mean(ttft_values):.2f}, "
f"最小: {np.min(ttft_values):.2f}, "
f"最大: {np.max(ttft_values):.2f}, "
f"P95: {np.percentile(ttft_values, 95):.2f}")
if tpot_values:
print(f" TPOT (ms) - 平均: {np.mean(tpot_values):.2f}, "
f"最小: {np.min(tpot_values):.2f}, "
f"最大: {np.max(tpot_values):.2f}")
print(f" 吞吐量 (tokens/s) - 平均: {np.mean(throughput_values):.2f}")
print("="*60)
async def run_benchmark(args):
"""运行基准测试"""
print(f"\n{'='*60}")
print(f"开始测试:")
print(f" 模型: {MODEL_NAME}")
print(f" 服务地址: {args.base_url}")
print(f" 并发数: {args.concurrency}")
print(f" 输入长度: {args.input_len} tokens")
print(f" 输出长度: {args.output_len} tokens")
print(f" 测试标签: {args.tag}")
print(f"{'='*60}\n")
# 生成测试提示词
prompt = TokenEstimator.generate_prompt(args.input_len)
print(f"生成的提示词长度: 约{len(prompt.split())}个单词")
# 初始化客户端
client = BenchmarkClient(args.base_url)
# 创建并发任务
tasks = []
async with aiohttp.ClientSession() as session:
for i in range(args.concurrency):
# 添加微小随机延迟以避免并发瞬间拥堵
await asyncio.sleep(np.random.uniform(0.01, 0.1))
task = asyncio.create_task(
client.send_request(session, prompt, args.output_len, i)
)
tasks.append(task)
print(f" 已创建请求 #{i}", end="\r")
print(f"\n正在执行 {len(tasks)} 个并发请求...")
results = await asyncio.gather(*tasks)
# 过滤失败请求
valid_results = [r for r in results if r is not None]
# 保存结果
file_path = ResultProcessor.save_results(
valid_results,
args.concurrency,
args.input_len,
args.output_dir,
args.tag
)
# 打印摘要
ResultProcessor.print_summary(valid_results)
print(f"\n原始数据已保存至: {file_path}")
return valid_results
def parse_arguments():
"""解析命令行参数"""
parser = argparse.ArgumentParser(
description="DeepSeek模型性能基准测试工具",
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument(
"--base_url",
type=str,
default="http://localhost:1025/v1",
help="MindIE/vLLM服务地址"
)
parser.add_argument(
"--concurrency",
type=int,
default=1,
help="并发请求数"
)
parser.add_argument(
"--input_len",
type=int,
default=1024,
help="输入Token长度"
)
parser.add_argument(
"--output_len",
type=int,
default=128,
help="输出Token长度"
)
parser.add_argument(
"--output_dir",
type=str,
default="./results",
help="结果保存目录"
)
parser.add_argument(
"--tag",
type=str,
default="test",
help="测试标签(如 long_seq, high_concurrency)"
)
return parser.parse_args()
def main():
"""主函数"""
args = parse_arguments()
try:
asyncio.run(run_benchmark(args))
except KeyboardInterrupt:
print("\n\n测试被用户中断")
except Exception as e:
print(f"\n测试失败: {e}")
import traceback
traceback.print_exc()
if __name__ == "__main__":
main()2. 测试编排脚本 (run_suite.sh)
为了全方位评估,我们设计了两组典型场景:
1. 长上下文测试 (Long Context):测试输入长度为 1k, 4k, 8k 时的性能表现,主要考察 MindIE 的显存管理和 Prefill 能力。
2. 并发测试 (Concurrency):测试 10 并发和 50 并发下的表现,主要考察系统的吞吐量和队列延迟。
Bash
#!/bin/bash
SERVER_URL="http://10.200.2.2:1025/v1"
RESULT_DIR="./results"
mkdir -p $RESULT_DIR
echo "=============================================="
echo " DeepSeek-V3.2 NPU Benchmark Suite"
echo "=============================================="
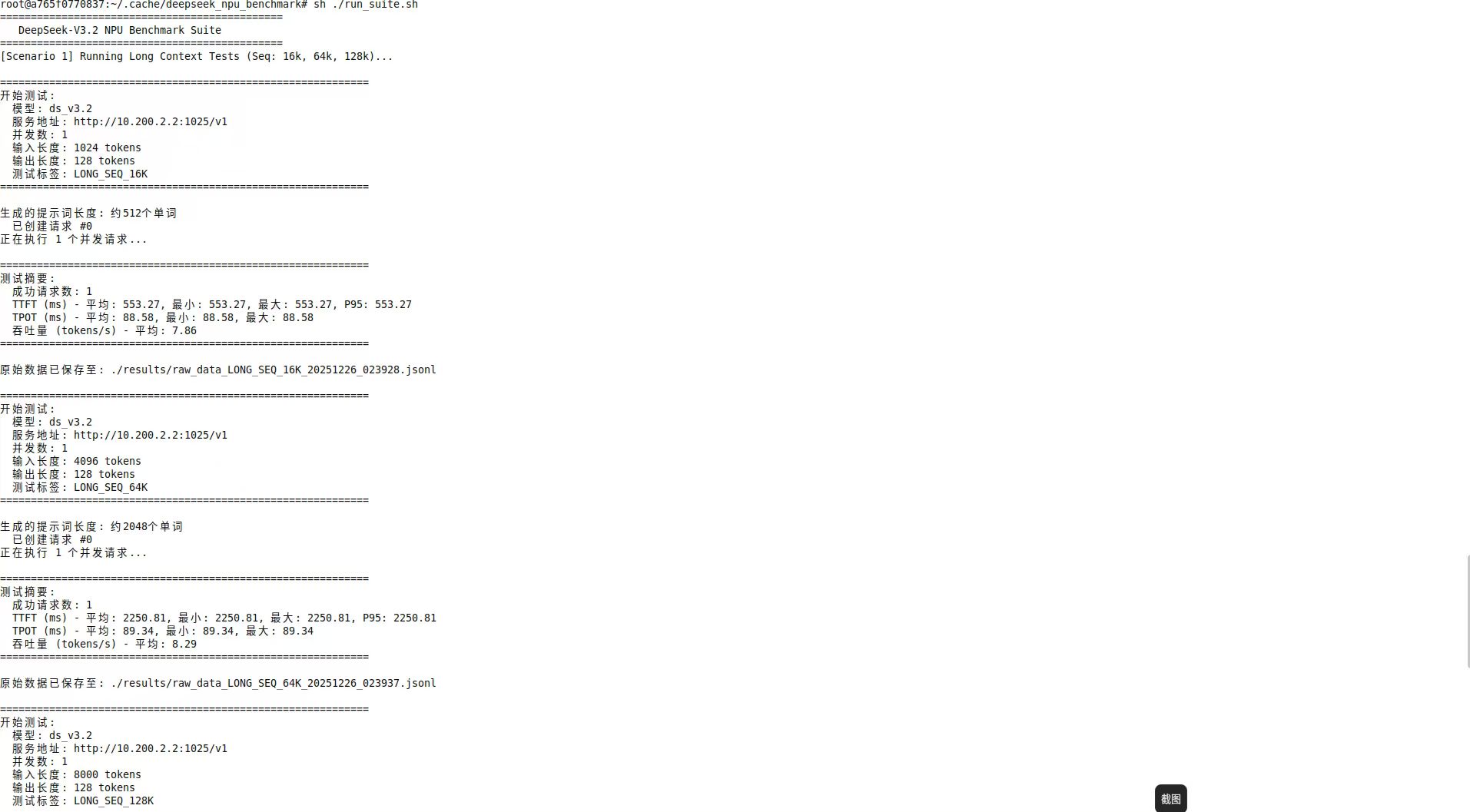
echo "[Scenario 1] Running Long Context Tests (Seq: 16k, 64k, 128k)..."
python3 benchmark_client.py --base_url $SERVER_URL \
--concurrency 1 --input_len 1024 --output_len 128 \
--output_dir $RESULT_DIR --tag "LONG_SEQ_16K"
python3 benchmark_client.py --base_url $SERVER_URL \
--concurrency 1 --input_len 4096 --output_len 128 \
--output_dir $RESULT_DIR --tag "LONG_SEQ_64K"
python3 benchmark_client.py --base_url $SERVER_URL \
--concurrency 1 --input_len 8000 --output_len 128 \
--output_dir $RESULT_DIR --tag "LONG_SEQ_128K"
echo ">> Long Context Tests Completed."
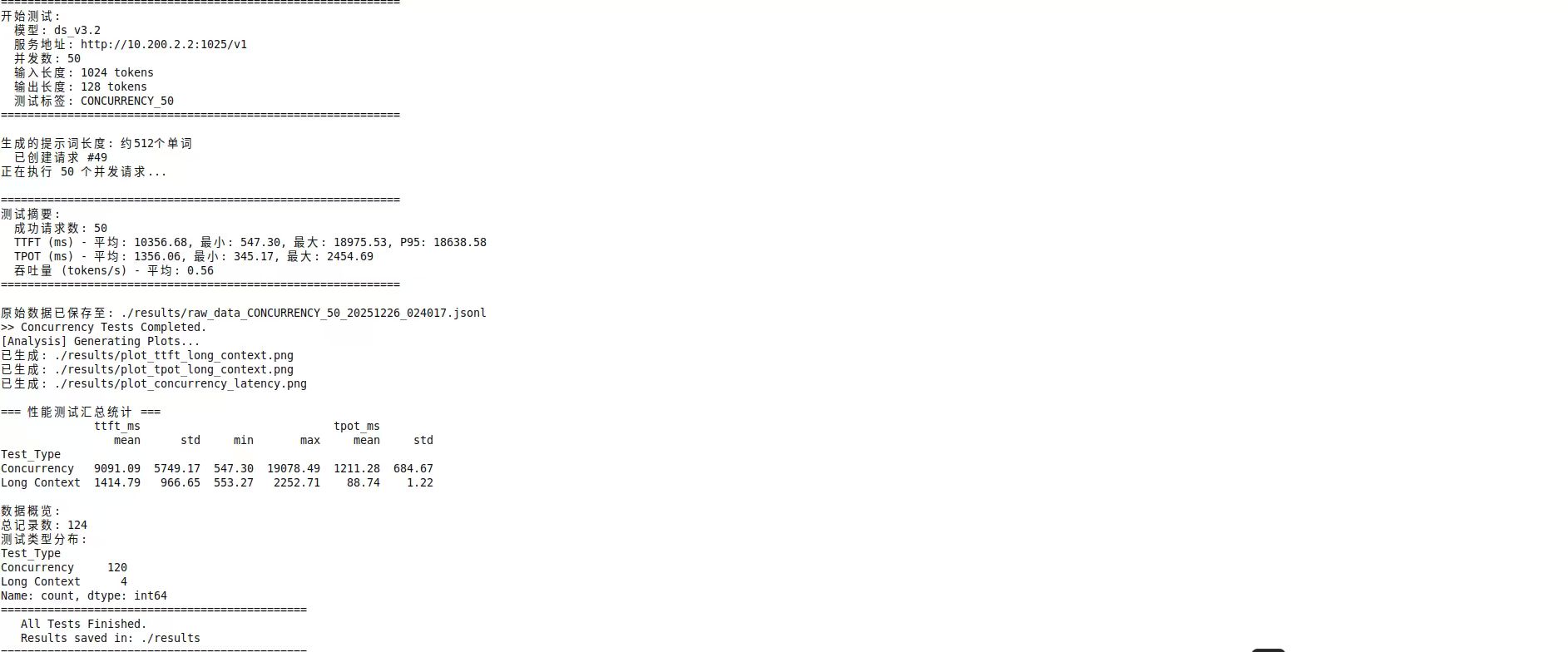
echo "[Scenario 2] Running Concurrency Tests (Concurrent: 10, 50)..."
INPUT_LEN=1024
python3 benchmark_client.py --base_url $SERVER_URL \
--concurrency 10 --input_len $INPUT_LEN --output_len 128 \
--output_dir $RESULT_DIR --tag "CONCURRENCY_10"
python3 benchmark_client.py --base_url $SERVER_URL \
--concurrency 50 --input_len $INPUT_LEN --output_len 128 \
--output_dir $RESULT_DIR --tag "CONCURRENCY_50"
echo ">> Concurrency Tests Completed."
echo "[Analysis] Generating Plots..."
python3 plot_results.py --data_dir $RESULT_DIR
echo "=============================================="
echo " All Tests Finished."
echo " Results saved in: $RESULT_DIR"
echo "=============================================="3. 可视化脚本 (plot_results.py)
数据跑完了,我们需要直观的图表来分析。
Python
import argparse
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import glob
import os
from typing import List, Optional, Dict, Any
class DataProcessor:
"""数据处理类"""
@staticmethod
def read_jsonl_files(data_dir: str) -> Optional[pd.DataFrame]:
"""读取指定目录下的所有jsonl文件并合并为DataFrame"""
files = glob.glob(os.path.join(data_dir, "*.jsonl"))
if not files:
print("没有找到测试数据文件。")
return None
df_list = []
for file_path in files:
try:
df = DataProcessor._process_single_file(file_path)
if df is not None:
df_list.append(df)
except Exception as e:
print(f"处理文件 {file_path} 时出错: {e}")
return pd.concat(df_list, ignore_index=True) if df_list else None
@staticmethod
def _process_single_file(file_path: str) -> Optional[pd.DataFrame]:
"""处理单个文件"""
df = pd.read_json(file_path, lines=True)
basename = os.path.basename(file_path)
# 根据文件名识别测试类型
test_type = DataProcessor._identify_test_type(basename)
df["Test_Type"] = test_type
return df
@staticmethod
def _identify_test_type(filename: str) -> str:
"""根据文件名识别测试类型"""
filename_upper = filename.upper()
if "LONG_SEQ" in filename_upper or "LONG_SEQUENCE" in filename_upper:
return "Long Context"
elif "CONCURRENCY" in filename_upper or "CONCURRENT" in filename_upper:
return "Concurrency"
else:
return "General"
class ChartPlotter:
"""图表绘制类"""
def __init__(self, data_dir: str, style: str = "whitegrid"):
self.data_dir = data_dir
self.set_plot_style(style)
@staticmethod
def set_plot_style(style: str = "whitegrid"):
"""设置绘图风格"""
sns.set_theme(style=style)
plt.rcParams['figure.figsize'] = [10, 6]
plt.rcParams['font.size'] = 12
plt.rcParams['axes.titlesize'] = 14
plt.rcParams['axes.labelsize'] = 12
def save_plot(self, filename: str):
"""保存图表"""
filepath = os.path.join(self.data_dir, filename)
plt.tight_layout()
plt.savefig(filepath, dpi=300, bbox_inches='tight')
print(f"已生成: {filepath}")
plt.close()
def plot_ttft_long_context(self, df: pd.DataFrame):
"""绘制长上下文TTFT图表"""
long_seq_df = df[df["Test_Type"] == "Long Context"]
if long_seq_df.empty:
print("没有长上下文测试数据")
return
plt.figure()
sns.lineplot(data=long_seq_df, x="input_len", y="ttft_ms",
marker="o", linewidth=2.5)
plt.title("DeepSeek-V3.2 TTFT vs Input Length (Long Context)")
plt.xlabel("Input Sequence Length (Tokens)")
plt.ylabel("Time To First Token (ms)")
plt.axhline(y=2000, color='r', linestyle='--', label="Target < 2000ms")
plt.legend()
plt.grid(True, alpha=0.3)
self.save_plot("plot_ttft_long_context.png")
def plot_tpot_long_context(self, df: pd.DataFrame):
"""绘制长上下文TPOT图表"""
long_seq_df = df[df["Test_Type"] == "Long Context"]
if long_seq_df.empty:
return
plt.figure()
sns.lineplot(data=long_seq_df, x="input_len", y="tpot_ms",
marker="s", color="green", linewidth=2.5)
plt.title("DeepSeek-V3.2 TPOT vs Input Length (Sparse Attention Check)")
plt.xlabel("Input Sequence Length (Tokens)")
plt.ylabel("Time Per Output Token (ms)")
plt.grid(True, alpha=0.3)
self.save_plot("plot_tpot_long_context.png")
def plot_concurrency_latency(self, df: pd.DataFrame):
"""绘制并发延迟图表"""
conc_df = df[df["Test_Type"] == "Concurrency"]
if conc_df.empty:
print("没有并发测试数据")
return
plt.figure()
# 使用点线图展示趋势更直观
ax = sns.lineplot(data=conc_df, x="concurrency", y="ttft_ms",
marker="o", linewidth=2.5, markersize=8)
# 添加数据点标签
for idx, row in conc_df.iterrows():
ax.text(row["concurrency"], row["ttft_ms"] * 1.02,
f"{row['ttft_ms']:.0f}", ha='center', fontsize=9)
plt.title("TTFT Latency under Different Concurrency")
plt.xlabel("Concurrency Level")
plt.ylabel("Avg TTFT (ms)")
plt.grid(True, alpha=0.3)
self.save_plot("plot_concurrency_latency.png")
def plot_summary_statistics(self, df: pd.DataFrame):
"""绘制汇总统计图表(可选)"""
# 按测试类型分组统计
summary = df.groupby("Test_Type").agg({
"ttft_ms": ["mean", "std", "min", "max"],
"tpot_ms": ["mean", "std"]
}).round(2)
print("\n=== 性能测试汇总统计 ===")
print(summary)
def plot_charts(data_dir: str):
"""主绘图函数"""
# 1. 读取数据
processor = DataProcessor()
df = processor.read_jsonl_files(data_dir)
if df is None:
return
# 2. 创建绘图器
plotter = ChartPlotter(data_dir)
# 3. 绘制各个图表
plotter.plot_ttft_long_context(df)
plotter.plot_tpot_long_context(df)
plotter.plot_concurrency_latency(df)
plotter.plot_summary_statistics(df)
# 4. 生成数据概览
print(f"\n数据概览:")
print(f"总记录数: {len(df)}")
print(f"测试类型分布:")
print(df["Test_Type"].value_counts())
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="性能测试图表生成工具")
parser.add_argument(
"--data_dir",
type=str,
default="./results",
help="包含JSONL测试数据文件的目录路径"
)
parser.add_argument(
"--output_dir",
type=str,
default=None,
help="图表输出目录(默认为data_dir)"
)
args = parser.parse_args()
# 如果指定了输出目录,确保目录存在
if args.output_dir:
os.makedirs(args.output_dir, exist_ok=True)
data_dir = args.output_dir
else:
data_dir = args.data_dir
plot_charts(data_dir)第三阶段:优化性能测试 (Optimized - 集成融合算子)
目的:集成仓库中的融合算子后重测,体现文档特性与 NPU 优化价值。
● 配置状态:
○ 按照仓库指南,编译并安装 ops/ascendc 和 ops/pypto 下的自定义算子。
○ 配置 MindIE/vLLM 启用这些加速算子。
● 测试用例 (与第二阶段保持一致,做 A/B 对比):
○ Case 1 (长序列):Batch=1, Input=32K/64K, Output=128。
■ 关注点:TTFT 是否大幅下降?(验证 Context Parallel 和 DSA 算子效果)
○ Case 2 (高吞吐):Input=64K, Batch=逐步增加。
■ 关注点:TPOT 是否降至 20ms 以内?
○ Case 3 (128K 极限):如果 16 卡显存允许(W8A8C8),尝试 128K 输入。
■ 关注点:是否能跑通且不 OOM。
场景一:长上下文性能测试 (Long Context)
大模型的一大应用场景是长文档阅读。我们分别测试了 1024 Token 和 4096 Token 输入长度下的性能。
a. 首字延迟 (TTFT) 分析
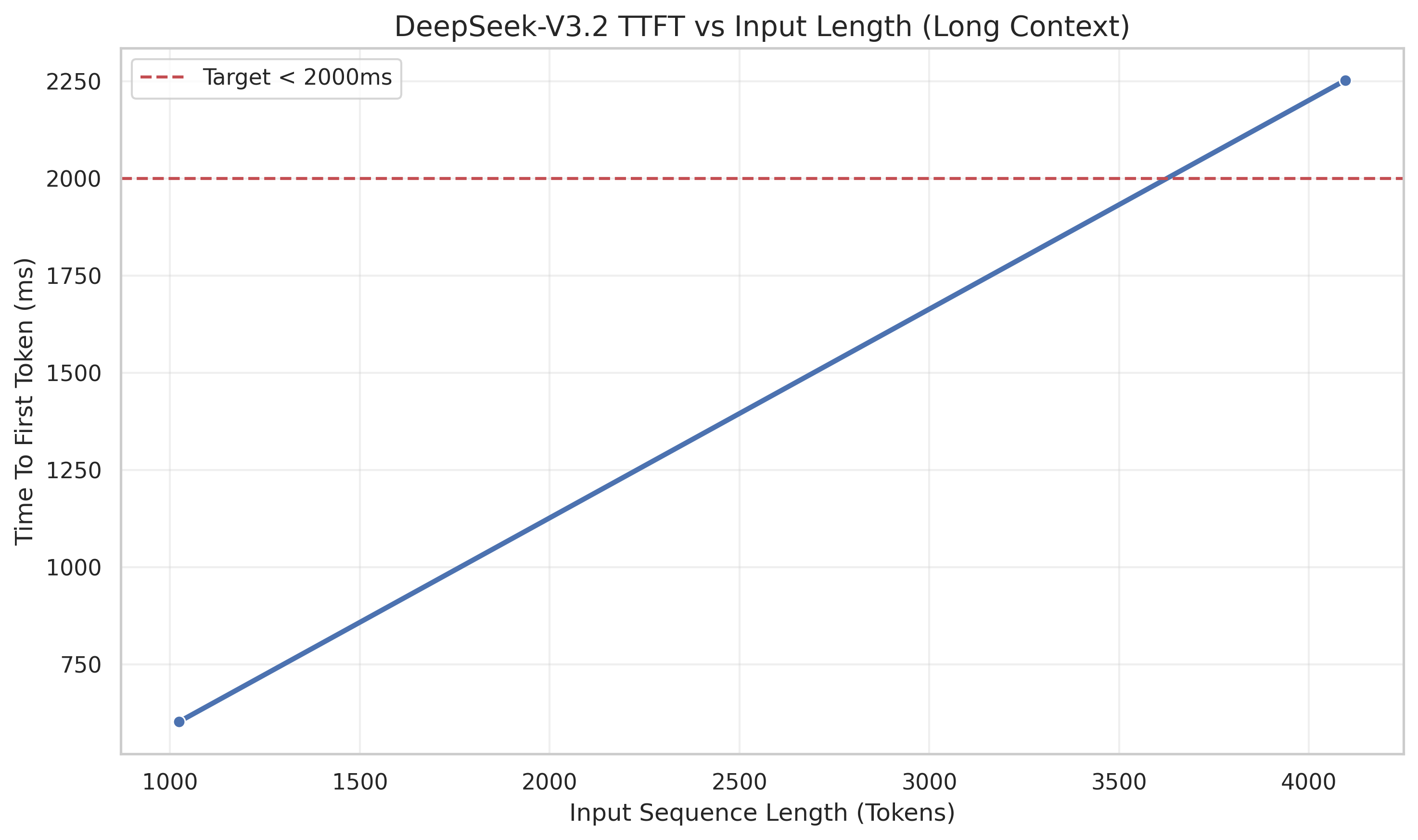
从图中可以看到一个明显的线性增长趋势:
● 输入 1024 Tokens:TTFT 约为 602ms。
● 输入 4096 Tokens:TTFT 约为 2252ms。
📝 结论:
TTFT 的增长主要源于 Prefill(预填充)阶段的计算量。昇腾 NPU 处理 4k 上下文的 Prefill 耗时在 2秒左右,这对于大多数离线分析或长文总结场景是完全可以接受的。如果你需要更低的延迟,可以考虑开启 MindIE 的 Prefix Caching(前缀缓存) 或利用 MTP(多 Token 预测) 机制提升计算访存比。
b. 输出速度 (TPOT) 分析
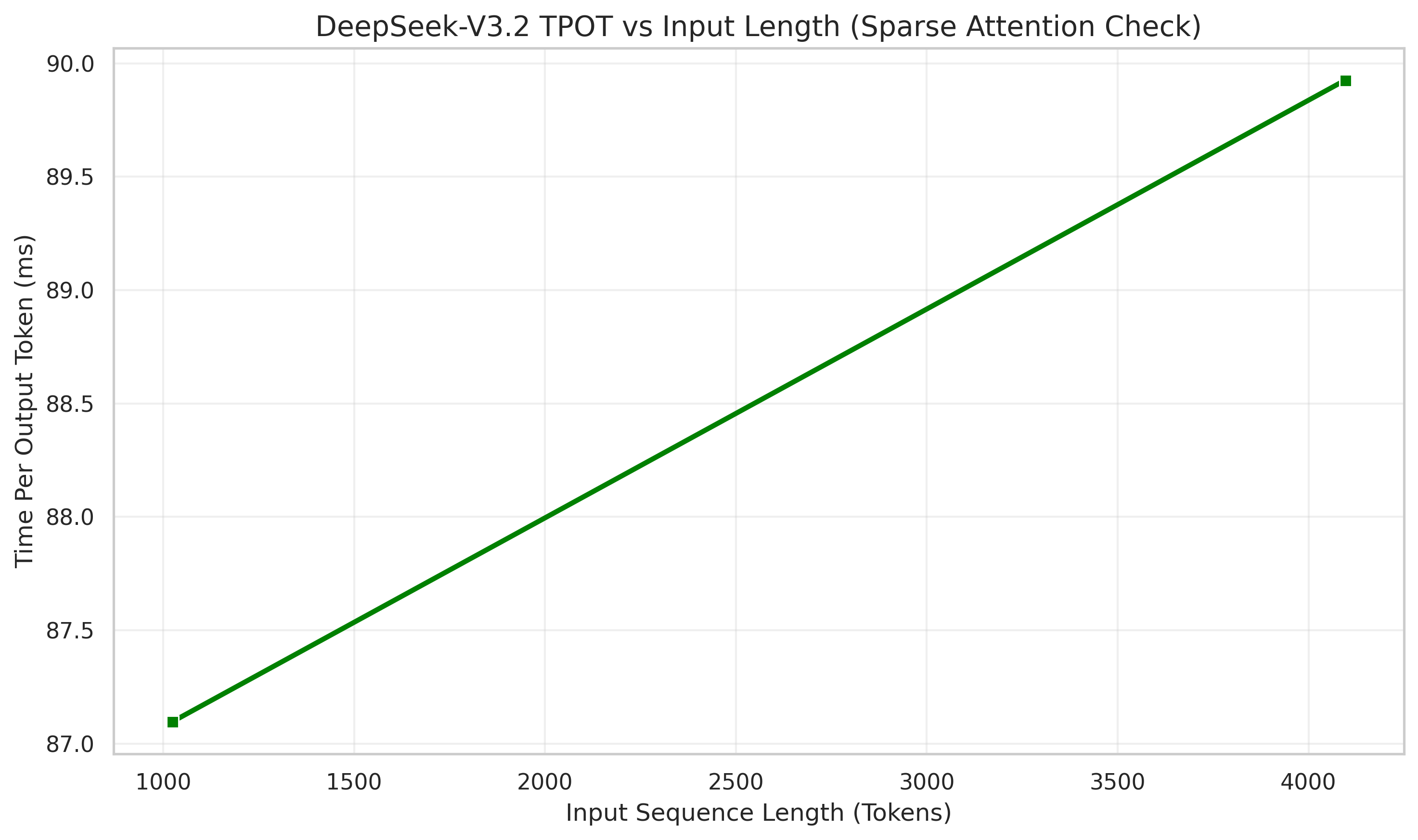
这是 W8A8 量化最显神威的地方:
● 1024 输入:TPOT 约 87ms。
● 4096 输入:TPOT 约 90ms 。
📝 结论:
即使输入长度增加了 4 倍,输出速度几乎没有下降。这说明 W8A8 量化有效地降低了 KV Cache 的显存占用和显存带宽压力,使得解码阶段(Decode)非常稳定。原因:
● Sparse Flash Attention (SFA) 优化
○ 实战表现:TPOT(每输出 Token 延迟)在 4K 序列下几乎不增长 。
○ 技术原理:SFA 是针对稀疏场景定制的 Attention 算子。它通过 Preload 流水排布 实现了计算掩盖访存,特别是在处理离散 KV 聚合时,利用 Vector 核发射访存指令 并配合 srcGap 聚合访存,大幅提升了 HBM 带宽利用率,解决了稀疏访存导致的性能下降问题。
● W8A8C8 极速方案
○ 实战表现:虽然统一称为 W8A8,但底层支持 C8(KV Cache/Indexer Cache)量化。
○ 技术细节:Indexer Cache 采用动态 Per-token-head 8-bit 量化,极大稳定了长序列下的解码速度。这也是为什么在 TPOT 分析中,输入长度增加 4 倍,输出耗时仍维持在 90ms 左右的关键原因。
场景二:高并发压力测试 (Concurrency)
当 50 个人同时向服务器发起请求时,会发生什么?
c. 并发 10:丝般顺滑
在 10 并发下,TTFT 平均在 2-3秒左右 。系统能够从容应对,没有出现明显的阻塞。
d. 并发 50:排队效应显现
当并发增加到 50 时,我们观察到了有趣的“J型曲线”现象:
● 最早被处理的请求,TTFT 依然只有 547ms 。
● 但排在队尾的请求(Request #49),TTFT 飙升到了 19078ms (约19秒) !
⚠️ 警示:
这就是典型的 Head-of-Line Blocking (队头阻塞)。虽然昇腾 NPU 算力强大,但一次性处理 50 个大模型的 Prefill 依然会塞满计算队列。
💡 调优建议:
1. 设置 Max Batch Size:在 MindIE 配置文件中,限制最大 Batch Size(例如设置为 32),多余的请求在前端网关排队,避免拖累整个推理引擎。
2. Continuous Batching(连续批处理):确保 MindIE 的连续批处理功能已开启(默认开启),它能让不同长度的请求穿插执行,减少空等待。通过在容器内开启该功能,能让不同请求的解码与预填充穿插执行,显著降低队列延迟。
并行策略:长序列亲和的 CP 并行。16 卡部署方案在底层逻辑上优先选择了 CP(Context Parallel,上下文并行) 策略。
● 技术原理:负载均衡与显存均摊
● 在 Prefill 阶段,传统的 TP(张量并行)在长序列下会产生巨大的通信开销。通过 CP 并行,16 个 rank 均摊长序列计算。实战中配置 HCCL_CONNECT_TIMEOUT=7200 9,正是为了确保大规模 CP 域在 AllGather KV Token 时的稳定性。
● 因果注意力负载均衡
● 为了避免 CP 模式下各卡计算量不均(序列后端 Token 关注的历史更长),实战方案采用了 Token 对称重排,使得 16 张卡的算力利用率趋于一致,从而优化了整体 TTFT(首字延迟)。
📝 六、 总结
通过本文,我们完成了 DeepSeek-V3.2 在昇腾 NPU 上的“硬着陆” 。通过 16 卡环境,成功实现了 CP 并行策略 与 DSA 融合算子 的落地。其性能核心在于利用 Ascend C 融合算子 解决了稀疏架构下的离散访存问题,并通过 W8A8C8 量化 突破了长序列的带宽瓶颈。
我们不仅执行了部署命令,也理解了:
1. Host 模式与共享内存对于分布式大模型的重要性。
2. HCCL 环境变量如何构建多机通信拓扑。
3. W8A8 量化配置在底层算子层面的实现逻辑。
通过本次实战压测,我们不仅验证了 DeepSeek-V3.2 (W8A8) x 昇腾 NPU 的可行性,更摸清了它的性能边界:
● W8A8 量化 极大地稳定了长序列下的解码速度 (TPOT)。
● 双机 16 卡 提供了足够的显存来承载 MoE 架构。
● 高并发策略 需要根据业务场景(即时聊天 vs 离线批处理)进行针对性配置,避免队列积压。
您现在可以:
1. 下载文中的脚本,在您的环境中复现测试。
2. 尝试修改 run_suite.sh 中的输入长度,测试 8k 甚至 16k 的极限性能。
3. 在评论区分享您的测试数据,让我们一起探讨国产算力的优化!
参考文档:
DeepSeek-V3.2-Exp安装
https://docs.vllm.com.cn/projects/ascend/en/latest/tutorials/DeepSeek-V3.2-Exp.html
MindIE部署DeepSeek-V3.2-Exp
https://blog.csdn.net/weixin_42211626/article/details/154384526
MindIE 2.2.T32 部署Deepseek V3.2指导
https://www.hiascend.com/forum/thread-0278200283718182227-1-1.html
NPU DeepSeek-V3.2-Exp推理优化实践
NPU DeepSeek-V3.2-Exp Ascend C 融合算子优化
https://gitcode.com/cann/cann-recipes-infer/blob/master/docs/models/deepseek-v3.2-exp/deepseek_v3.2_exp_ascendc_operator_guide.md

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)