
昇腾MindSpeed RL的Remove padding和动态批量大小特性代码解析
Remove padding在大语言模型训练过程中,输入数据通常由长度不一的序列组成。为了支持批处理,传统方案通过在 batch 内对所有序列填充(padding)至相同长度实现。这种方式虽然方便模型计算,但会引入大量无效计算,尤其当短序列远多于长序列时,训练效率显著下降。为了解决上述问题,引入了remove_padding 特性,通过对有效 token 部分拼接(packing)后计算,有效消除
在大语言模型训练过程中,输入数据通常由长度不一的序列组成。为了支持批处理,传统方案通过在 batch 内对所有序列填充(padding)至相同长度实现。这种方式虽然方便模型计算,但会引入大量无效计算,尤其当短序列远多于长序列时,训练效率显著下降。
为了解决上述问题,引入了remove_padding 特性,通过对有效 token 部分拼接(packing)后计算,有效消除了 padding token 带来的资源浪费,提升了训练效率。
更详细的原理介绍,请参考:remove_padding
动态批量大小
在使用remove_padding技术拼接多个序列以提高训练效率时,若不加限制地拼接过多序列,可能导致拼接后的总 token 数量超出 GPU 显存容量,进而发生 OOM(Out Of Memory)错误。
为此,引入了Dynamic Batch Size(动态批大小)特性:根据每条样本的实际 token 长度,动态地划分多个 micro batch,确保每个子 batch 拼接后的 token 总数不超过指定的最大值 max_packing_token_size。该机制在保持高吞吐的同时,有效避免显存溢出问题。
更详细的原理介绍,请参考:动态批大小(Dynamic Batch Size)
下面对这两个特性的代码实现做深入解读。
应用范围
在数据输入模型前后做处理
特性整体处理流程
模型处理前:
- batch拆成microbatches,两种拆法
- 普通拆分:使用_split_batches拆分,按照micro_batch_size来分
- use_dynamic_bsz(动态批大小):使用_split_batches_with_dynamic_bsz拆分(使用动态批大小算法)
- remove_padding处理,把每个microbatch拼接成一个seqence(mbs=1)
模型处理
|
output = model(input_ids=input_ids, attention_mask=None, position_ids=position_ids) |
模型处理后:
- 恢复remove_padding处理
- 恢复use_dynamic_bsz处理
代码介绍
remove_padding
mindspeed_rl/utils/remove_padding.py
preprocess_packed_seqs
|
def preprocess_packed_seqs( input_ids: torch.Tensor, labels: torch.Tensor, attention_mask_1d: torch.Tensor, tp_size: int ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]: """ 处理逻辑: ● 输入的input_ids,忽略原来的padding,根据tp_size先padding,使每个seq能被tp_size整除,然后把所有padding后的seq拼接到一起。label处理和input_ids对应(类似)。 ● 记录position_ids_packed用于后面做模型输入。 ● 记录seqlens_in_batch、cu_seqlens_padded用于后面恢复原始input_ids的格式。 输入: ● input_ids:tensor,shape为(batch_size, seq_len),存放的是token IDs ● attention_mask_1d:tensor,shape为 (batch_size, seq_len),其中的1表示token,0表示padding ● tp_size: 为了使seq_len能被tp_size整除,会做padding 输出:可参照上图 ● input_ids_packed: shape为(1, pack_length),处理后的新input_ids。 ● position_ids_packed:会作为模型的输入(对应参数position_ids,用于生成postion_embedding)。shape为(1, pack_length),记录每个padding后的seq的位置。 ● seqlens_in_batch:shape为 (batch_size,),记录每个sequence的原始seq_len(不算padding),用于后面恢复原始输入shape ● cu_seqlens_padded:shape为 (batch_size+1,) 记录每个子padding后的seq的起止位置,用于后面恢复原始输入shape。 """ |
输入:
- input_ids:shape为 (batch_size, seq_len)的tensor,存放的是token IDs
- attention_mask_1d:shape为 (batch_size, seq_len)的tensor,其中的1表示token,0表示padding
- tp_size: 为了使seq_len能被tp_size整除,会做padding,需要知道tp_size
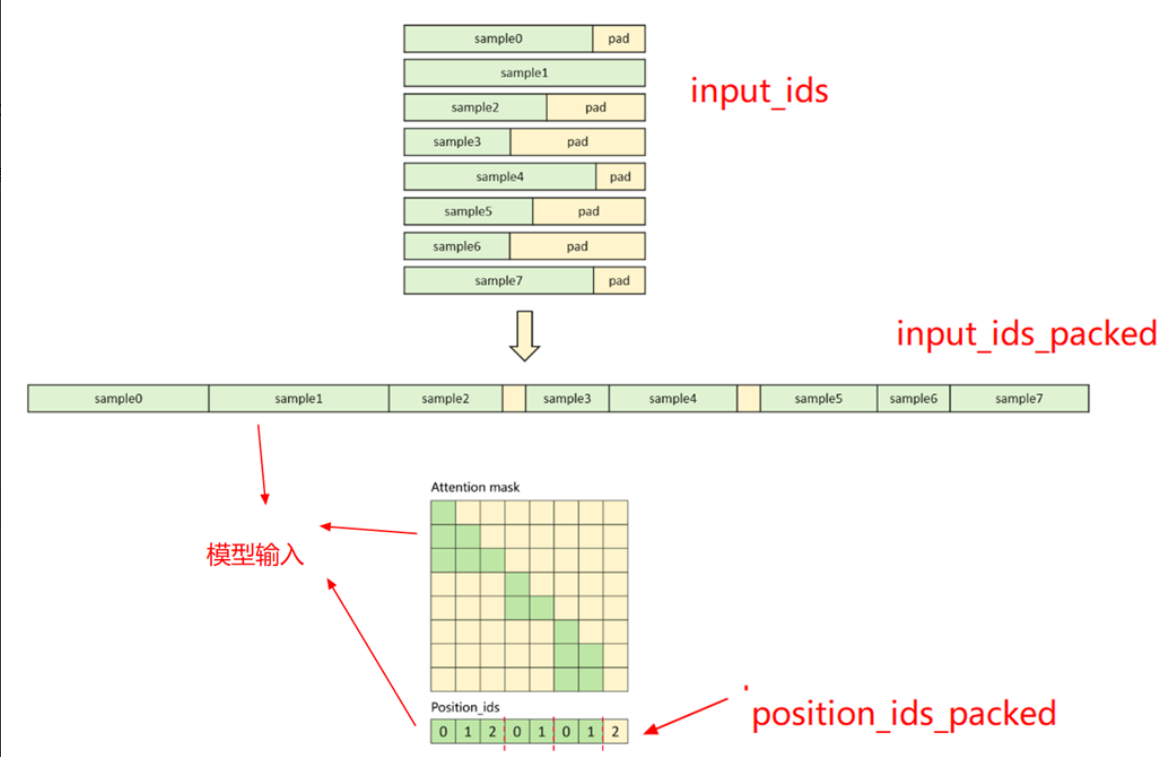
处理逻辑:
- 输入的input_ids,忽略原来的padding,会根据tp_size先padding,使每个seq能被tp_size整除。
- 然后把所有padding后的seq拼接到一起。label处理和input_ids对应(类似)。
- 记录position_ids_packed用于后面计算。
- 记录seqlens_in_batch、cu_seqlens_padded用于后面恢复原始input_ids的格式。
输出:可参照上图
- input_ids_packed: shape为(1, pack_length),处理后的新input_ids
- position_ids_packed:会作为模型的输入(对应参数position_ids,用于生成postion_embedding)。shape为(1, pack_length),记录每个padding后的seq的位置。如上图第一个seq对应位置填充(0,1,2),第二个seq对应位置填充(0,1),第三个seq对应位置填充(0,1,2)(其中2是padding的位置,上图黄色的格子)
- seqlens_in_batch:shape为 (batch_size,),记录每个sequence的原始seq_len(不算padding),用于后面恢复原始输入shape
- cu_seqlens_padded:shape为 (batch_size+1,) 记录每个子padding后的seq的起止位置,用于后面恢复原始输入shape。
postprocess_packed_seqs
|
def postprocess_packed_seqs( output: torch.Tensor, seqlens_in_batch: torch.Tensor, cu_seqlens_padded: torch.Tensor, seq_len: int, prompt_length: torch.Tensor = None ) -> torch.Tensor: """ 输入: ● output: shape为(1, pack_length, ...),preprocess_packed_seqs处理后的input_ids_packed经过模型后的输出 ● seqlens_in_batch:shape为 (batch_size,),preprocess_packed_seqs计算结果 ● cu_seqlens_padded:shape为 (batch_size+1,),preprocess_packed_seqs计算结果 ● seq_len:int类型,preprocess_packed_seqs处理之前的input_ids的seq_len(最长的seq的长度,包括padding),用于恢复preprocess_packed_seqs处理前的shape
输出: ● output_new:shape为(batch_size, seq_len, ...),为恢复后的输出 """ |
输入:
- output: shape为(1, pack_length, ...),比如preprocess_packed_seqs处理后的input_ids_packed经过模型后的输出
- seqlens_in_batch:shape为 (batch_size,),preprocess_packed_seqs计算结果
- cu_seqlens_padded:shape为 (batch_size+1,) ,preprocess_packed_seqs计算结果
- seq_len:int类型,preprocess_packed_seqs处理之前的input_ids的seq_len(最长的seq的长度,包括padding),用于恢复preprocess_packed_seqs处理前的shape
- prompt_length:可选,用于truncation操作,不配置不做truncation
输出:
- output_new:shape为(batch_size, seq_len, ...)。为恢复后的输出
动态批大小
mindspeed_rl/utils/seqlen_balancing.py
rearrange_micro_batches
|
def rearrange_micro_batches(seqlen_list: List[int], max_token_len: int, dynamic_max_batch_size=None, dp_group=None): |
输入:
- seqlen_list:batch中每个item的prompt_len+response_len
- max_token_len:配置max_packing_token_size的值,用于限制每个micro_batch经过remove_padding拼接后的总长度
|
# Calculate the minimum number of bins total_sum_of_seqlen = sum(seqlen_list) k_partitions = (total_sum_of_seqlen + max_token_len - 1) // max_token_len #先计算batch中所有seq的长度和,再除max_token_len,得到要分的micro_batch的数量,每个macro_batch使用remove_padding拼接序列后,长度不会超过限制。k_partitions就是分几份 |
- dynamic_max_batch_size:配置dynamic_max_batch_size的值,用于限制k_partitions(batch切分成几份)
|
if dynamic_max_batch_size is not None: k_partitions = max(k_partitions, (len(seqlen_list) + dynamic_max_batch_size - 1) // dynamic_max_batch_size) |
输出:
- partitions (List[List[int]]):列表中存的是每个partition(micro_batch)的原始序列的index,用于后面恢复。比如:
- 假设原始batch的seqlen_list为[1,2,2,5,3,7,6,3]
- partition后得到partitions为[[0,5],[1,6],[2,3],[4,7]],其中数字是在seqlen_list中的index。也就是按照长度这样分组[[1,7],[2,6],[2,5],[3,3]],尽量保持分组后总长度平均。
处理逻辑:
- 通过对seqlen_list的序列长度排序,再分组,来保证每个分组(micro_batch)的seq_len和比较平均
- max_token_len和dynamic_max_batch_size的限制逻辑上面讲了
|
def rearrange_micro_batches(seqlen_list: List[int], max_token_len: int, dynamic_max_batch_size=None, dp_group=None): ...... # 根据总序列长度和指定的max_token_len,计算最少分几组,每组长度不超过max_token_len total_sum_of_seqlen = sum(seqlen_list) k_partitions = (total_sum_of_seqlen + max_token_len - 1) // max_token_len # 根据dynamic_max_batch_size的限制,再算可以分几组,然后综合上面的结果取最大值 if dynamic_max_batch_size is not None: k_partitions = max(k_partitions, (len(seqlen_list) + dynamic_max_batch_size - 1) // dynamic_max_batch_size) #如果指定dp_group,可以在dp_group内同步k_partitions,保证dp_group内划分分组数一致 if dist.is_initialized(): k_partitions = torch.tensor([k_partitions], device='npu') dist.all_reduce(k_partitions, op=dist.ReduceOp.MAX, group=dp_group) k_partitions = k_partitions.cpu().item() #使用karmarkar_karp算法来划分分组 partitions = karmarkar_karp(seqlen_list=seqlen_list, k_partitions=k_partitions, equal_size=False) #返回indexes列表,其中存的是每个partition(micro_batch)在原始序列中的index,用于后面恢复 return partitions |
参考示例
参考代码
mindspeed_rl/models/base/base_training_engine.py
mindspeed_rl/models/loss/grpo_actor_loss_func.py
mindspeed_rl/models/loss/base_loss_func.py
主要代码简介
- BaseTrainingEngine实现了:
- update: actor.update_actor会调到update
- forward(forward_only):actor.compute_log_prob、reference.compute_log_prob会调到forward
- _forward_backward_batch:上面update和forward的主要逻辑,都通过调用_forward_backward_batch来实现
- _forward_backward_batch又会调到loss计算逻辑GRPOActorLossFunc.compute_loss,以及BaseLossFunc.compute_log_probs
分步骤介绍
总体入口:
_forward_backward_batch
|
def _forward_backward_batch(self, batch: Dict[str, torch.Tensor], forward_only: bool = False): #按照动态批大小算法切分batch if self.use_dynamic_bsz: batches, indices = self._split_batches_with_dynamic_bsz(batch, self.max_packing_token_size, self.dynamic_max_batch_size) #普通batch切分方法,按照micro_batch_size切分 else: batches = self._split_batches(batch, batch_size=self.micro_batch_size, shuffle_mini_batch=self.shuffle_mini_batch) ...... data_iter = iter(batches) ...... # batch should be a list of batches inside micro-batches #数据前后向处理 losses_reduced = self.forward_backward_func( forward_step_func=forward_step, data_iterator=data_iter, model=self.model, num_microbatches=n_micro_batch, seq_length=self.micro_batch_size * seq_len if self.use_remove_padding else seq_len, micro_batch_size=1 if self.use_remove_padding else self.micro_batch_size, forward_only=forward_only, collect_non_loss_data=forward_only, ) #动态批大小算法反向操作,恢复数据原始分组 # Reverse the batch index to be the same outside if self.use_dynamic_bsz and forward_only and post_process: losses_reduced_list = torch.cat(losses_reduced, dim=0) indices = list(itertools.chain.from_iterable(indices)) revert_indices = get_reverse_idx(indices) losses_reduced = [losses_reduced_list[[idx, ]] for idx in revert_indices] return losses_reduced |
forward_step
其中forward_backward_func调用了forward_step
|
def forward_step(batch_iter, model): ....... if self.use_remove_padding: #remove padding前处理 input_ids, position_ids, process_batch, seqlens_in_batch, cu_seqlens_padded, index = self._get_forward_batch_info(batch_iter) #数据输入模型处理 output = model(input_ids=input_ids, attention_mask=None, position_ids=position_ids) output.div_(self.temperature) #模型输出的使用(包括后处理) return output, partial(self.loss_func.compute_loss, batch=process_batch, forward_only=forward_only, use_remove_padding=self.use_remove_padding, seqlens_in_batch=seqlens_in_batch, cu_seqlens_padded=cu_seqlens_padded, seq_len=seq_len, use_dynamic_bsz=self.use_dynamic_bsz, actual_micro_batch_size=batch_size / n_micro_batch, index=index) ...... |
模型处理前:
use_dynamic_bsz
- batch拆成microbatches,两种拆法
- 普通拆分:使用_split_batches拆分,按照micro_batch_size来分
- use_dynamic_bsz(动态批大小):使用_split_batches_with_dynamic_bsz拆分(使用动态批大小算法)
|
#mindspeed_rl.models.base.base_training_engine.BaseTrainingEngine._forward_backward_batch if self.use_dynamic_bsz: batches, indices = self._split_batches_with_dynamic_bsz(batch, self.max_packing_token_size, self.dynamic_max_batch_size) else: batches = self._split_batches(batch, batch_size=self.micro_batch_size, shuffle_mini_batch=self.shuffle_mini_batch) |
- _split_batches_with_dynamic_bsz调用了rearrange_micro_batches来做batch拆分。保证后面remove_padding处理后的seq不会太长导致OOM
|
#mindspeed_rl.models.base.base_training_engine.BaseTrainingEngine._split_batches_with_dynamic_bsz def _split_batches_with_dynamic_bsz(batch: Dict, max_packing_token: int, dynamic_max_batch_size: int) -> tuple[List[Dict], List[List[int]]]: seq_len_list = [] #计算batch中数据的prompt_length+response_length生成seq_len_list for prompt_len, response_len in zip(batch['prompt_length'], batch['response_length']): seq_len_list.append(prompt_len.item() + response_len.item()) #调用rearrange_micro_batches获取冲切分后的分组 partitions = rearrange_micro_batches(seq_len_list, max_packing_token, dynamic_max_batch_size=dynamic_max_batch_size) #将batch数据按照新分组方式重组 batches = [] for key, tensors in batch.items(): for batch_idx, partition in enumerate(partitions): if batch_idx >= len(batches): batches.append({}) batches[batch_idx][key] = tensors[partition] #返回新分组、以及新分组数据对应原始序列中的index,用于后面恢复 return batches, partitions |
remove_padding
- remove_padding处理,把每个microbatch拼接成一个sequence(mbs=1)
|
#mindspeed_rl.models.base.base_training_engine.BaseTrainingEngine._forward_backward_batch def _forward_backward_batch(...): ... elif self.use_remove_padding: input_ids, position_ids, process_batch, seqlens_in_batch, cu_seqlens_padded, index = self._get_forward_batch_info(batch_iter) ... #mindspeed_rl.models.base.base_training_engine.BaseTrainingEngine._get_forward_batch_info def _get_forward_batch_info(self, batch_iter): batch = next(batch_iter) input_ids = batch['input_ids'] ...... attention_mask_1d = generate_mask(input_ids, batch['prompt_length'] + batch['response_length']).to(input_ids.device) ...... if self.use_remove_padding: tp_size = get_parallel_state().get_tensor_model_parallel_world_size() if self.megatron_config.context_parallel_algo == "megatron_cp_algo": multi = 2 * tp_size * cp_size else: multi = tp_size * cp_size
input_ids, position_ids, labels, seqlens_in_batch, cu_seqlens_padded = preprocess_packed_seqs( input_ids=input_ids, labels=labels, attention_mask_1d=attention_mask_1d, tp_size=multi) |
模型处理
模型处理调用的是BaseTrainingEngine._forward_backward_batch,其中关键是下面代码
forward_backward_func
|
#mindspeed_rl.models.base.base_training_engine.BaseTrainingEngine._forward_backward_batch losses_reduced = self.forward_backward_func( forward_step_func=forward_step, data_iterator=data_iter, model=self.model, num_microbatches=n_micro_batch, seq_length=self.micro_batch_size * seq_len if self.use_remove_padding else seq_len, micro_batch_size=1 if self.use_remove_padding else self.micro_batch_size, forward_only=forward_only, collect_non_loss_data=forward_only, ) |
其中self.forward_backward_func又调用了下面的forward_step,使用forward_backward_func时候传入的参数注意以下几个:
- seq_length:如果使用remove_padding,seq_length=self.micro_batch_size * seq_len(因为remove_padding会把micro_batch中的seq都拼接,所以长度有变化)
- micro_batch_size:如果使用remove_padding,micro_batch_size=1,因为因为remove_padding会把micro_batch中的seq都拼接成了一个seq,所以micro_batch中只有一个条目
forward_step
注意loss_func.compute_loss参数,传入以下参数用于恢复remove_padding
- seqlens_in_batch=seqlens_in_batch,
- cu_seqlens_padded=cu_seqlens_padded,
- seq_len=seq_len,
并传入以下两个变量,用于使能remove_padding和use_dynamic_bsz的相关操作
- use_remove_padding=self.use_remove_padding,
- use_dynamic_bsz=self.use_dynamic_bsz,
|
#mindspeed_rl.models.base.base_training_engine.BaseTrainingEngine._forward_backward_batch def forward_step(batch_iter, model): ....... if self.use_remove_padding: #remove padding前处理 input_ids, position_ids, process_batch, seqlens_in_batch, cu_seqlens_padded, index = self._get_forward_batch_info(batch_iter) #数据输入模型处理 output = model(input_ids=input_ids, attention_mask=None, position_ids=position_ids) output.div_(self.temperature) #模型输出的使用(包括后处理) return output, partial(self.loss_func.compute_loss, batch=process_batch, forward_only=forward_only, use_remove_padding=self.use_remove_padding, seqlens_in_batch=seqlens_in_batch, cu_seqlens_padded=cu_seqlens_padded, seq_len=seq_len, use_dynamic_bsz=self.use_dynamic_bsz, actual_micro_batch_size=batch_size / n_micro_batch, index=index) ...... |
模型处理后:
恢复remove_padding处理
- 如下面例子在计算compute_log_probs完,调用postprocess_packed_seqs恢复remove_padding处理
|
#mindspeed_rl.models.loss.base_loss_func.BaseLossFunc.compute_log_probs log_probs = compute_log_probs(output, labels) ...... if use_remove_padding: log_probs_allgather = get_tensor_allgather_cp_with_pack(log_probs, cp_size, index) seqlens_in_batch = kwargs.get('seqlens_in_batch', None) cu_seqlens_padded = kwargs.get('cu_seqlens_padded', None) seq_len = batch['responses'].shape[-1] log_probs = postprocess_packed_seqs(log_probs_allgather, seqlens_in_batch, cu_seqlens_padded, seq_len, prompt_length=batch['prompt_length']) if not skip_entropy: entropy = vocab_parallel_entropy(output) entropy = postprocess_packed_seqs(entropy, seqlens_in_batch, cu_seqlens_padded, seq_len, prompt_length=batch['prompt_length']) else: entropy = torch.zeros_like(log_probs) return log_probs, entropy |
恢复use_dynamic_bsz处理
- 计算完grpo loss,如果使用了dynamic_bsz,要对policy_loss结果做特别处理(可能是为了做一下loss的归一化,有时候实际的batchsize在变化)
|
#mindspeed_rl.models.loss.grpo_actor_loss_func.GRPOActorLossFunc.compute_loss # compute policy loss pg_loss, pg_clipfrac, ppo_kl, kl_loss, entropy_loss = self._compute_grpo_policy_loss(old_log_prob=old_log_prob, log_prob=log_probs, ref_log_prob=ref_log_prob, advantages=advantages, entropy=entropy, eos_mask=response_mask, cliprange=self.clip_ratio, kl_ctrl=self.kl_ctrl, kl_penalty=self.kl_penalty, entropy_coeff=self.entropy_coeff) use_dynamic_bsz = kwargs.get('use_dynamic_bsz', False) actual_micro_batch_size = kwargs.get('actual_micro_batch_size', None) if use_dynamic_bsz and not forward_only: policy_loss = pg_loss * (batch['responses'].size(0) / actual_micro_batch_size) else: policy_loss = pg_loss |
- _forward_backward_batch最后,对use_dynamic_bsz做了恢复。使用的indices参数是模型处理前调用_split_batches_with_dynamic_bsz的返回。此处调用了get_reverse_idx用于帮助恢复use_dynamic_bsz。
|
#mindspeed_rl.models.base.base_training_engine.BaseTrainingEngine._forward_backward_batch # Reverse the batch index to be the same outside if self.use_dynamic_bsz and forward_only and post_process: losses_reduced_list = torch.cat(losses_reduced, dim=0) indices = list(itertools.chain.from_iterable(indices)) revert_indices = get_reverse_idx(indices) losses_reduced = [losses_reduced_list[[idx, ]] for idx in revert_indices] |

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)