
基于昇腾310B的CANN推理开发--图片深度识别应用
本文详细介绍了在香橙派AIpro开发板上配置CANN异构计算架构以调用昇腾310B AI算力的完整流程。作者首先确认硬件信息并卸载预置CANN版本,随后逐步安装新版CANN工具包、内核组件及依赖库。通过AnimeGAN模型转换与推理测试案例,验证了环境配置的正确性,并分享了创建SWAP分区解决内存不足问题的实践经验。该指南为开发者提供了在边缘设备上部署AI模型的有效方案,展示了昇腾处理器在边缘计算
CANN简介:CANN(Compute Architecture for Neural Networks)是华为针对AI场景推出的异构计算架构,对上支持多种AI框架,对下服务AI处理器与编程,发挥承上启下的关键作用,是提升昇腾AI处理器计算效率的关键平台体验链接为:
https://gitcode.com/cann
0前言
博主之前使用香橙派部署并实现了基础的SALM算法以及yolo算法,反响还不错,当时很多人通过私信询问我是否使用了香橙派搭载的昇腾芯片算力,但是很遗憾当时博主并没有使用开发板自带的昇腾AI算力,主要是博主当时正在忙着找工作、写小论文没时间研究这些东西,最近博主已经成功研究生毕业并从事算法开发工作,现在就跟博主来探索一下如何使用香橙派上面的昇腾AI处理器海思Ascend 310B算力吧!


1、环境配置
1.1各种准备工作
首先是确定芯片类型,登录香橙派后在桌面随便打开一个终端并输入npu-smi info命令,效果如下: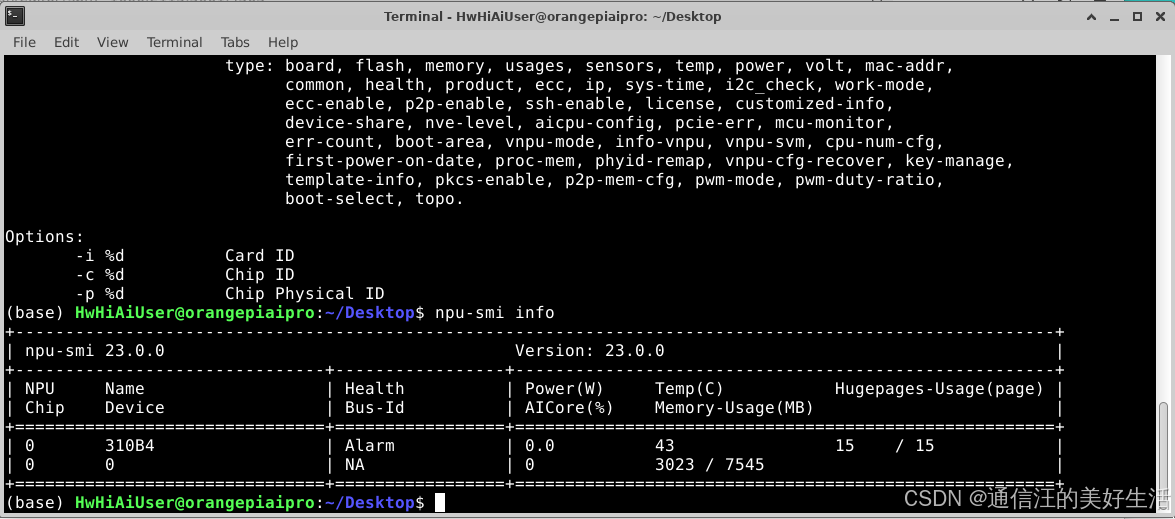
确定香橙派上面的昇腾AI处理器芯片是海思Ascend 310B后去昇腾官网等的操作手册来评估一下这个芯片能做些什么事情,通过查询可知基于310B芯片开发了Atlas 200I/500 A2推理产品,然后博主大概预测Atlas 200I/500 A2推理产品能做的事情香橙派AIpro大概率也能做。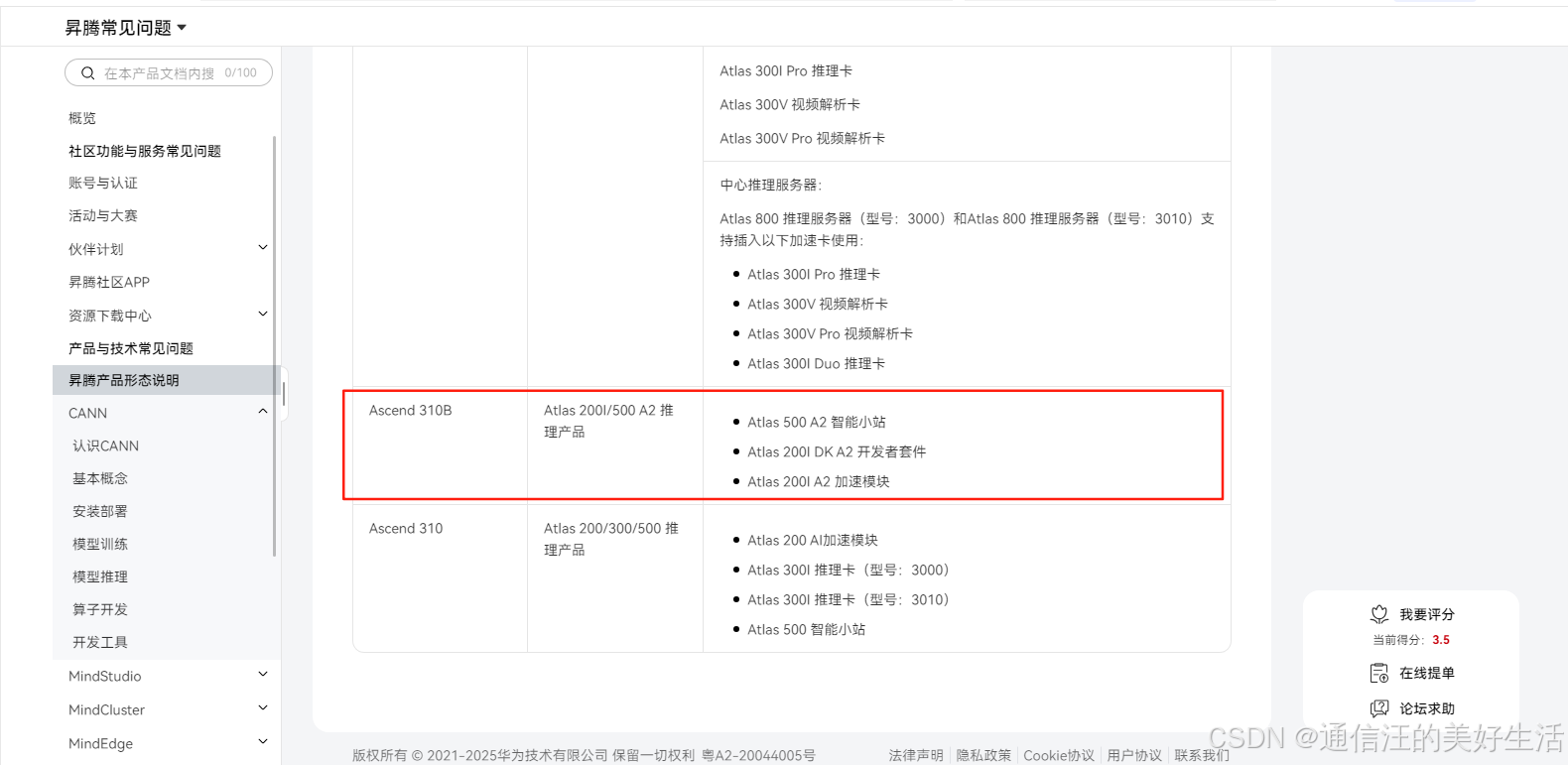
做了以上信息确认工作后接下来便是在香橙派AIpro上安装CANN异构计算架构,这里参考昇腾社区的内容进行。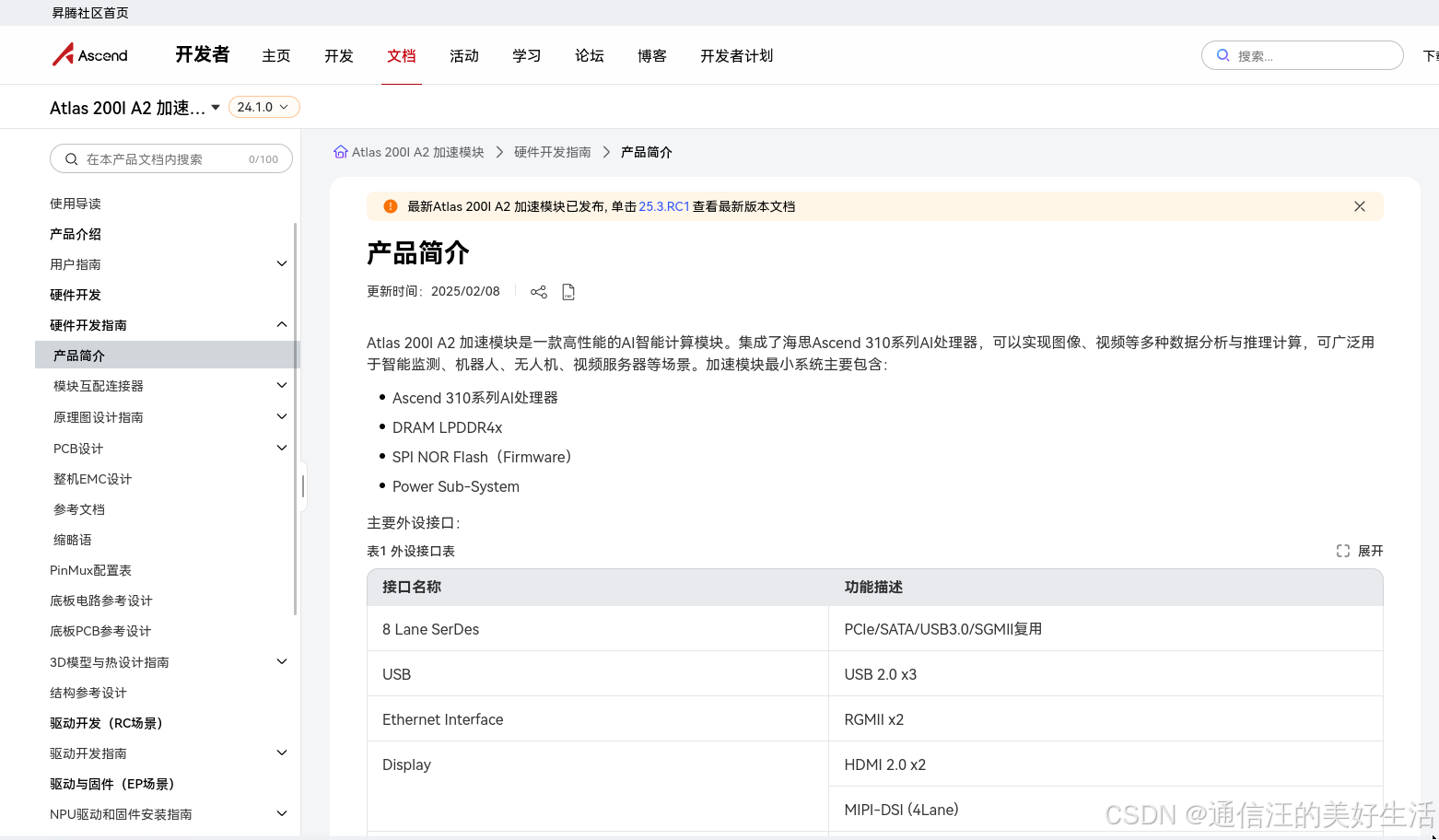
接着在打开的终端中切换到root用户,因为之后的有些操作需要的权限较高,切换过程见下图
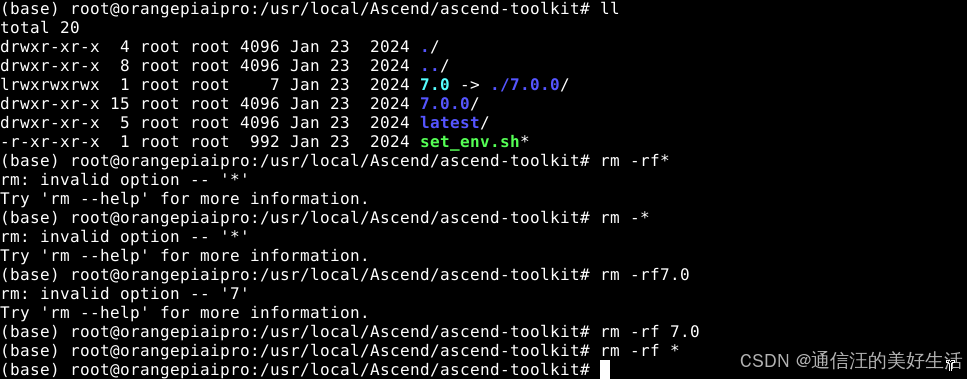
由于香橙派预置了7.0版本的cann,因此要先将其卸载,以防止安装新版本软件包磁盘空间不足,具体的卸载流程如下:
cd /usr/local/Ascend/ascend-toolkit
rm -rf*
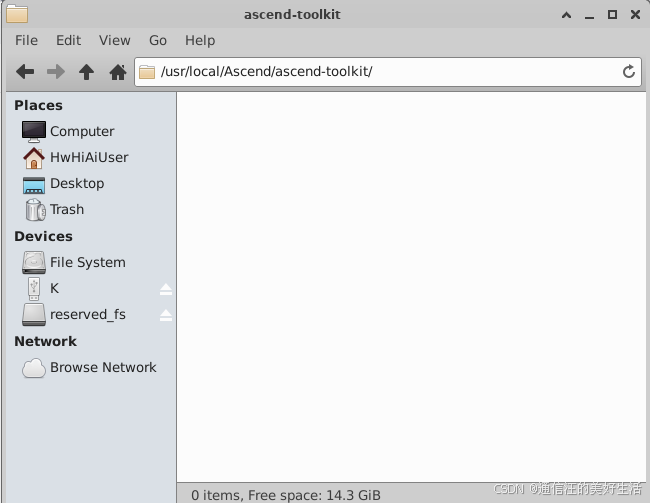
卸载前后多了5个G个空间,接着下载最新版本的cann-toolkit软件包,下载链接为:https://www.hiascend.com/developer/download/community/result?module=pt+tf+cann&pt=7.2.0&tf=8.3.RC1&cann=8.3.RC2
下载成功后的文件默认在目录下,我们需要进入这个目录下给安装包加上执行权限,命令如下:
chmod +x ./Ascend-cann-toolkit_8.3.RC2_linux-aarch64.run
1.2安装ascend-toolkit
然后安装该软件包:
/Ascend-cann-toolkit_8.3.RC2_linux-aarch64.run --install


出现这个表示软件包完整,等待解压即可,直到出现下面的提示表示解压成功,因为安装包大小在2个G左右,所以此过此大概要等5分钟。出现下面提示后输入Y表示同意安装。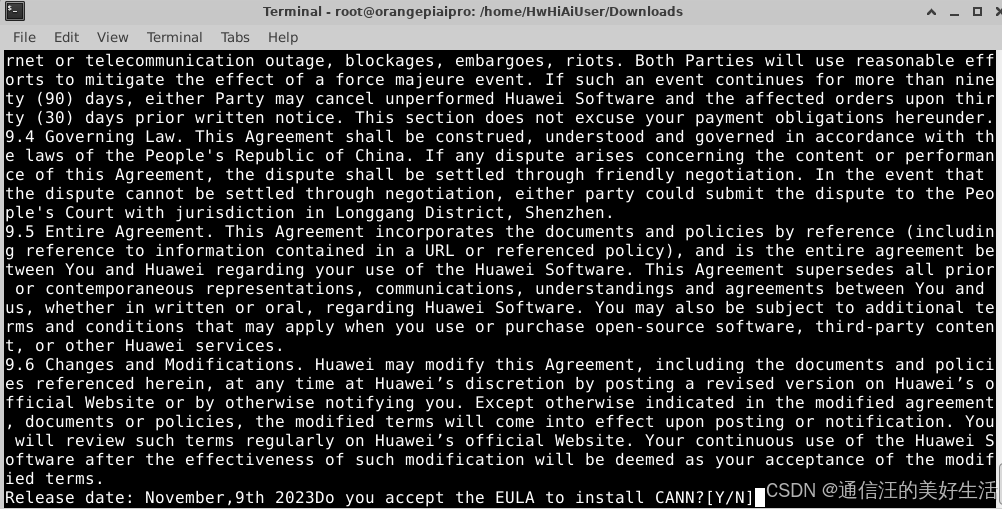

直到出现下面的提示意味着安装成功,安装过程大概30分钟。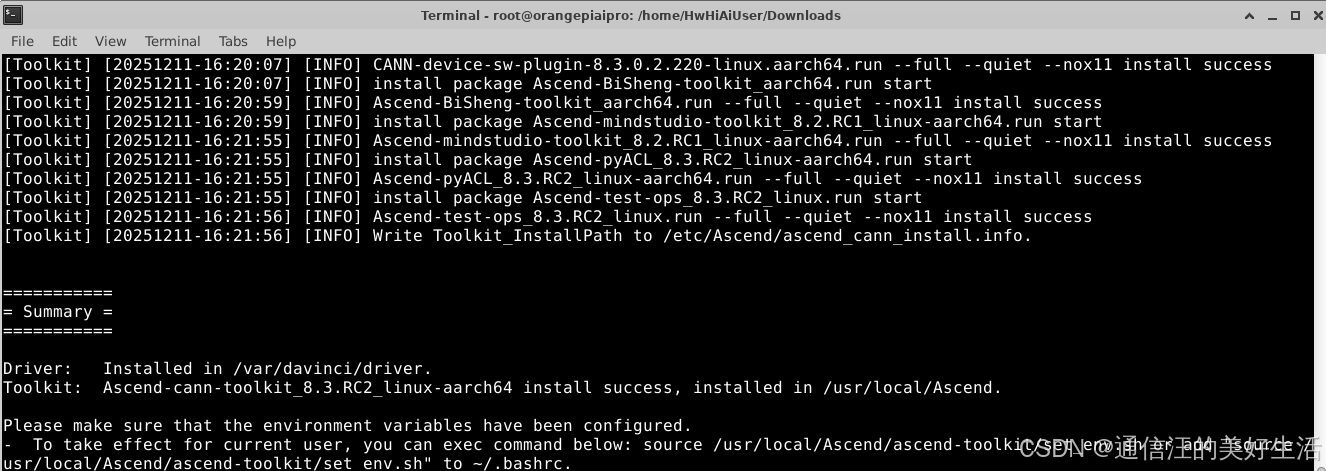
此时需要配置环境变量,命令为:
source /usr/local/Ascend/ascend-toolkit/set_env.sh
1.3安装Ascend-cann-kernels
下载Ascend-cann-kernels-310b_8.3.RC2_linux-aarch64.run安装包
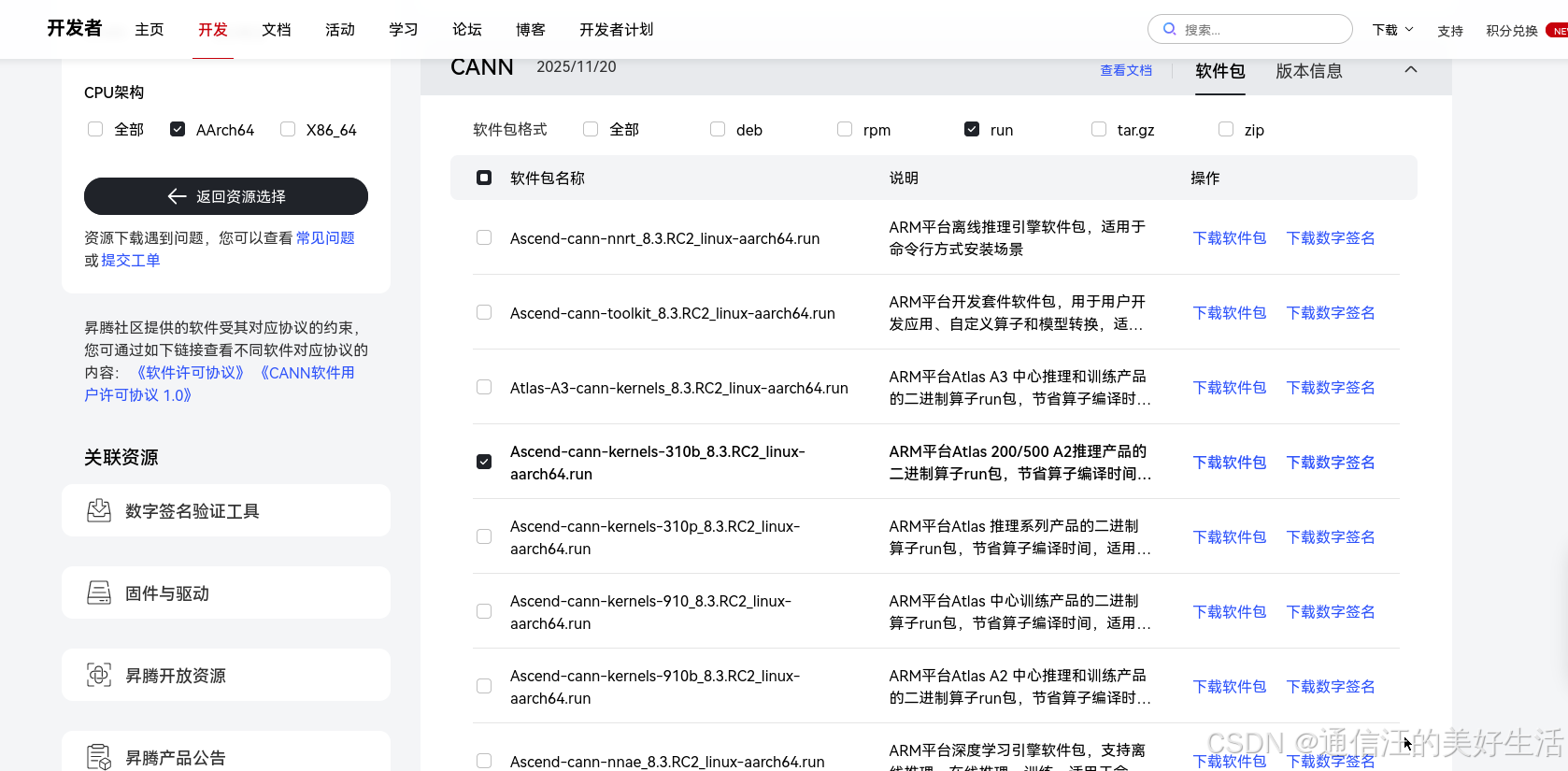
同第一部分,找到该文件并赋予执行权限,然后开始安装即可,具体命令如下:
chmod +x Ascend-cann-kernels-310b_8.3.RC2_linux-aarch64.run
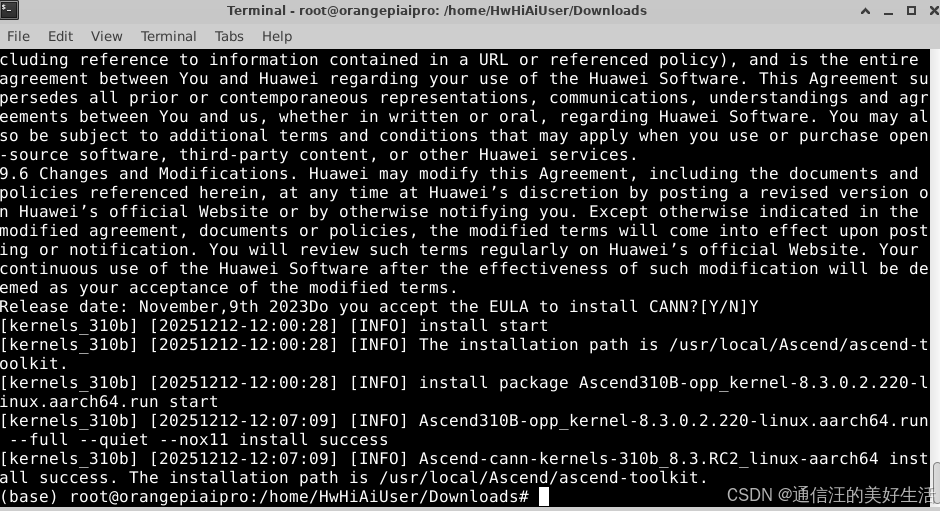
./Ascend-cann-kernels-310b_8.3.RC2_linux-aarch64.run --install
安装过程输出如下:
chmod +x Ascend-cann-kernels-310b_8.3.RC2_linux-aarch64.run
./chmod +x Ascend-cann-kernels-310b_8.3.RC2_linux-aarch64.run --install
1.4安装各种运行需要的第三方依赖库
1.4.1安装g++
安装命令如下:
sudo apt updatesudo apt install
-y g++ build-essential
证是否安装成功使用g++ --version这个命令,输出如下,值得注意的是安装过程中出现了额外的“警告”和“扫描进程”的信息这是正常的系统维护输出,不影响 g++ 的安装。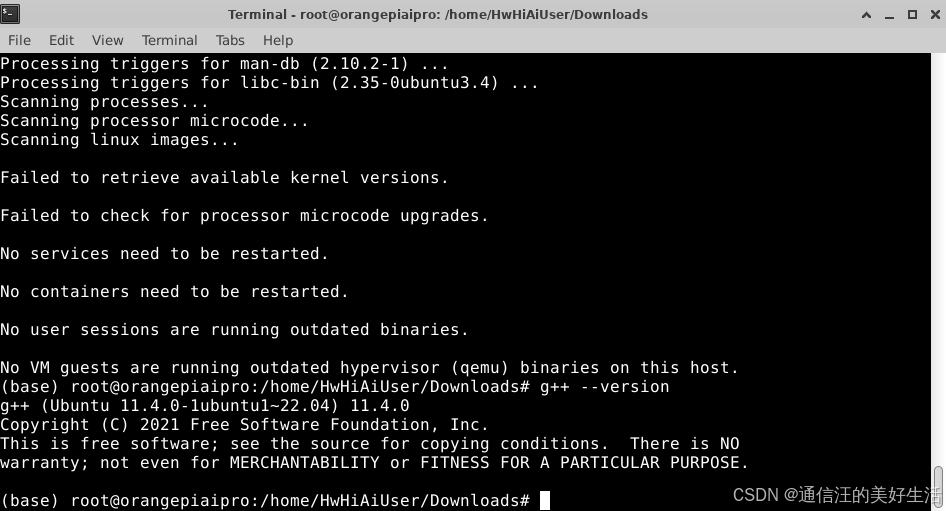
1.4.2安装Python第三方库
接着安装所需的第三方库,顺序如下:
(1)设置环境变量,配置程序编译依赖的头文件,库文件路径。“/usr/local/Ascend”请替换“Ascend-cann-toolkit”包的实际安装路径。
export DDK_PATH=/usr/local/Ascend/ascend-toolkit/latest
export NPU_HOST_LIB=$DDK_PATH/runtime/lib64/stub
export THIRDPART_PATH=${DDK_PATH}/thirdpart
export PYTHONPATH=${THIRDPART_PATH}/python:$PYTHONPATH
export DDK_PATH=/usr/local/Ascend/ascend-toolkit/latest
export NPU_HOST_LIB=$DDK_PATH/runtime/lib64/stub
export THIRDPART_PATH=${DDK_PATH}/thirdpart
export PYTHONPATH=${THIRDPART_PATH}/python:$PYTHONPATH
(2)创建THIRDPART_PATH路径
mkdir -p ${THIRDPART_PATH}
(3)运行环境安装python-acllite所需依赖
安装ffmpeg:
sudo apt-get install -y libavformat-dev libavcodec-dev libavdevice-dev libavutil-dev libswscale-dev libavresample-dev
安装其它依赖:
python3 -m pip install --upgrade pip
python3 -m pip install Cython
sudo apt-get install pkg-config libxcb-shm0-dev libxcb-xfixes0-dev
安装pyav:
python3 -m pip install av==6.2.0
安装pillow 的依赖:
sudo apt-get install libtiff5-dev libjpeg8-dev zlib1g-dev libfreetype6-dev liblcms2-dev libwebp-dev tcl8.6-dev tk8.6-dev python-tk
安装numpy和PIL:
python3 -m pip install numpy
python3 -m pip install Pillow
(4) python acllite库以源码方式提供,安装时将acllite目录拷贝到运行环境的第三方库目录,将acllite目录拷贝到第三方文件夹中,后续有变更则需要替换此处的acllite文件夹。命令为:
cp -r ${HOME}/ACLLite/python ${THIRDPART_PATH}
cp -r ${HOME}/ACLLite/python ${THIRDPART_PATH}
pip3 install attrs cython 'numpy>=1.19.2,<=1.24.0' decorator sympy cffi pyyaml pathlib2 psutil protobuf==3.20.0 scipy requests absl-py --user
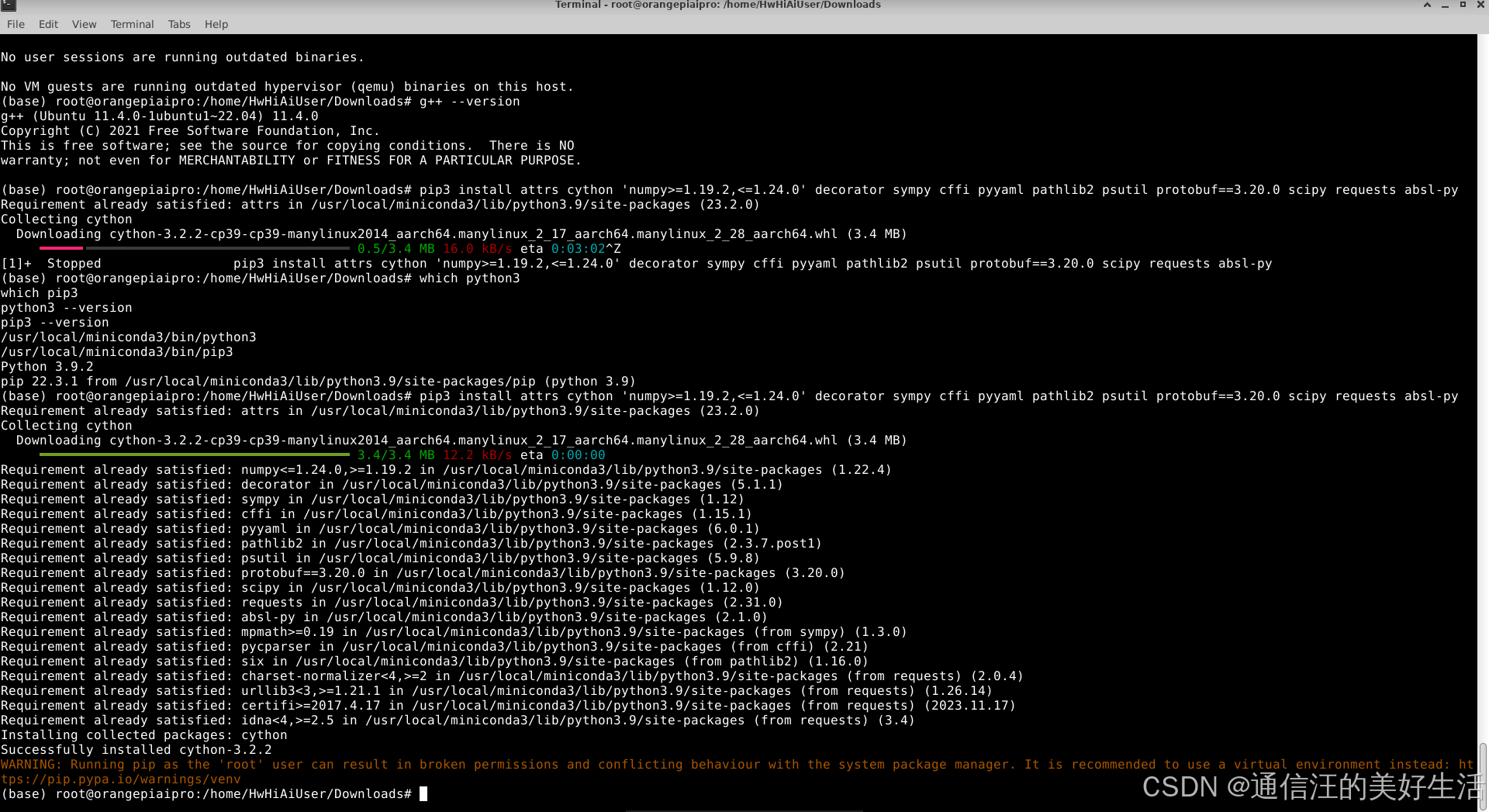
以上命令会安装最新版本或指定版本的依赖,至此第一部分CANN最新社区版安装并环境配置成功,接下来是一个实例测试验证是否安装成功。
2.ACLHelloWorld样例
这部分我将基于CANN完成ACLHelloWorld样例,验证CANN安装的完整性,展示如何基于CANN快速开发实现昇腾算力的使用。
2.1设置环境变量
配置程序编译依赖的头文件与库文件路径,任意打开一个文件输入下面命令即可:
export DDK_PATH=/usr/local/Ascend/ascend-toolkit/latest export NPU_HOST_LIB=$DDK_PATH/runtime/lib64/stub
2.2编译样例源码
执行以下命令编译样例源码。
cd scriptsbash sample_build.sh
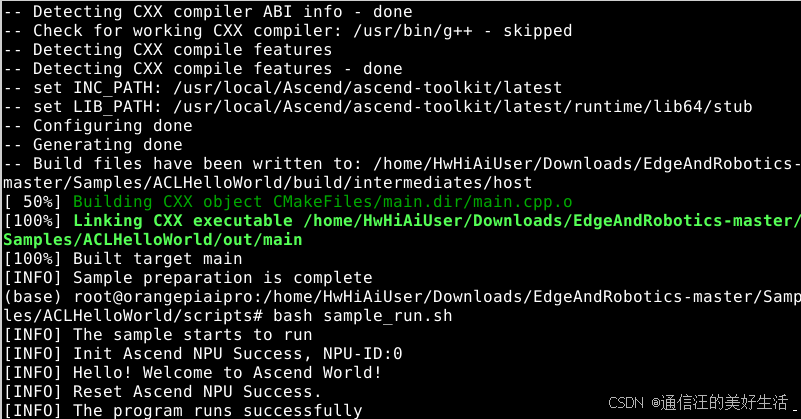
2.3运行样例
执行以下脚本运行样例:
bash sample_run.sh
执行成功后,在终端屏幕上的提示信息示例如下:
[INFO] The sample starts to run
[INFO] Init Ascend NPU Success, NPU-ID:0
[INFO] Hello! Welcome to Ascend World!
[INFO] Reset Ascend NPU Success.
3、图像风格迁移与图片深度识别
这部分我将基于CANN的一系列算子来完成两个推理样例,第一个主要是以昇腾样例仓为基础,验证CANN安装的完整性,展示如何基于CANN快速开发实现昇腾算力的使用。第二个则为进阶难度部署目前比较火的Depth Anything V2,算是我个人对310b的一次算力性能摸底吧!
3.1图像风格迁移模型部署
3.1.1获取源码包
昇腾样例仓提供了一系列媒体数据处理(DVPP/AIPP)、算子开发与调用(Ascend C)、推理应用开发与部署(AscendCL)等场景的丰富代码样例给开发者进行参考学习,帮助开发者快速入门,进而熟练掌握CANN关键特性使用,下面是官方样例代码下载链接供参考:
https://gitee.com/ascend/samples/repository/archive/master.zip
3.1. 2获取此应用中所需要的原始网络模型
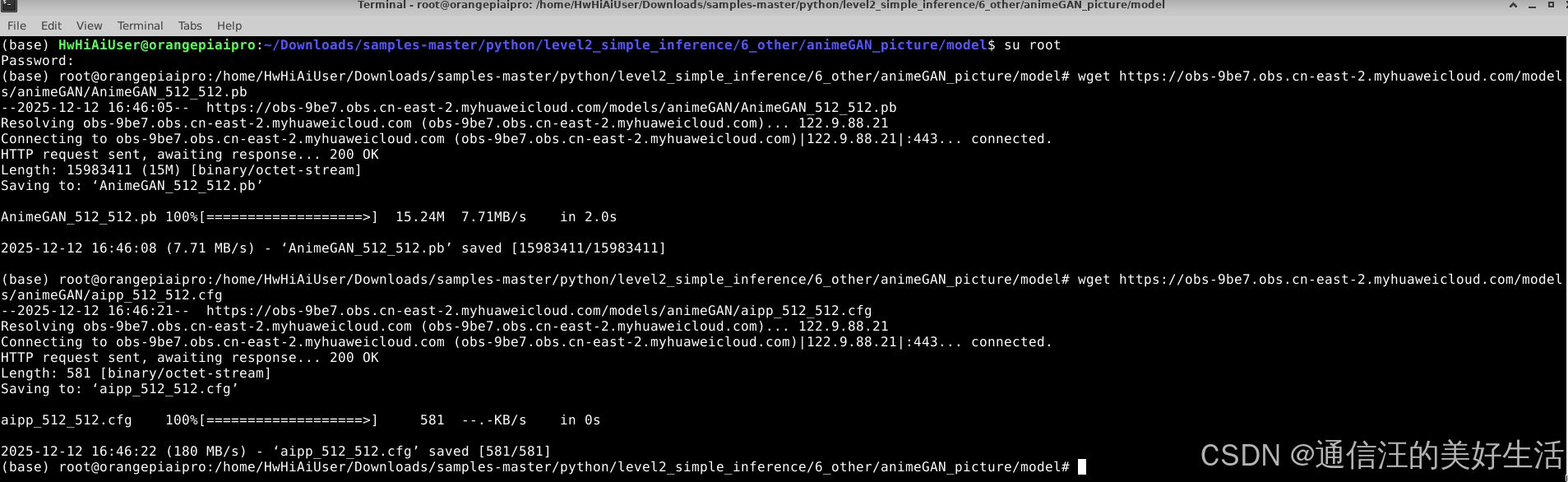
下载AnimeGAN_256_256.pb原模型,并将其转换为使用昇腾算力所需的形式,命令如下:
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/models/animeGAN/AnimeGAN_512_512.pb
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/models/animeGAN/aipp_512_512.cfg
atc --model="./AnimeGAN_512_512.pb" --output_type=FP32 --input_shape="test:1,512,512,3" --input_format=NHWC --output="AnimeGANv2_512" --soc_version=Ascend310 --framework=3 --precision_mode=allow_fp32_to_fp16 --insert_op_conf=aipp_512_512.cfg
上面是下载原模型以及模型权重文件,接着开始进行模型的类型转换,在进行模型转换时如果直接使用atc命令会导致内存跑满而系统卡死,需要根据自己实际内存的大小来来创建SWAP分区,我创建的是大小为2GB的分区,具体流程如下:
先切换为root用户
su root
创建一个大小为2GB的SWAP分区
fallocate --length 8G /swapfile
修改文件权限
chmod 600 /swapfile
创建SWAP分区
mkswap /swapfile
挂载SWAP分区
swapon /swapfile
执行命令查看分区是否创建成功
free -h
永久生效配置(重启后依然有效):
# 1. 备份当前的 /etc/fstab 文件
sudo cp /etc/fstab /etc/fstab.backup
# 2. 在 /etc/fstab 文件中添加 SWAP 配置
echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
# 3. 验证 fstab 配置
cat /etc/fstab | tail -1
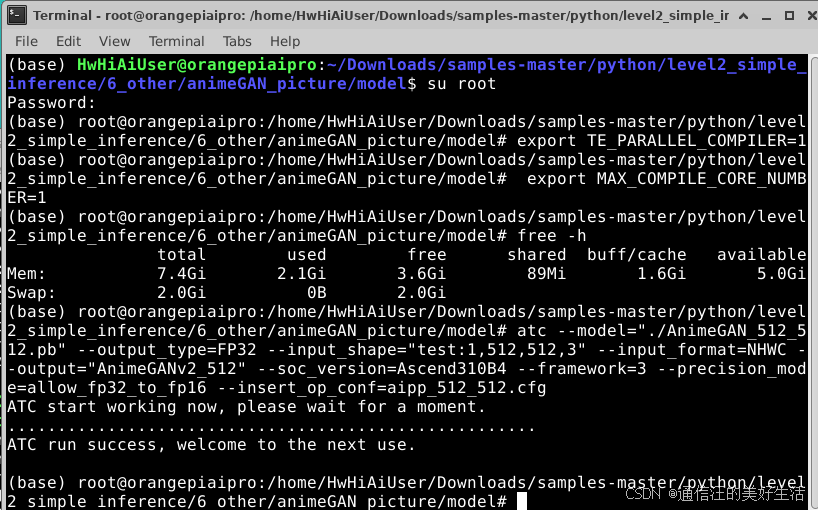
执行ATC转换命令:
atc --model="./AnimeGAN_512_512.pb" --output_type=FP32 --input_shape="test:1,512,512,3" --input_format=NHWC --output="AnimeGANv2_512" --soc_version=Ascend310B4 --framework=3 --precision_mode=allow_fp32_to_fp16 --insert_op_conf=aipp_512_512.cfg

3.1.3获取样例需要的测试图片
下载命令为:
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/models/animeGAN/test_image/test.jpg
下载后现象为: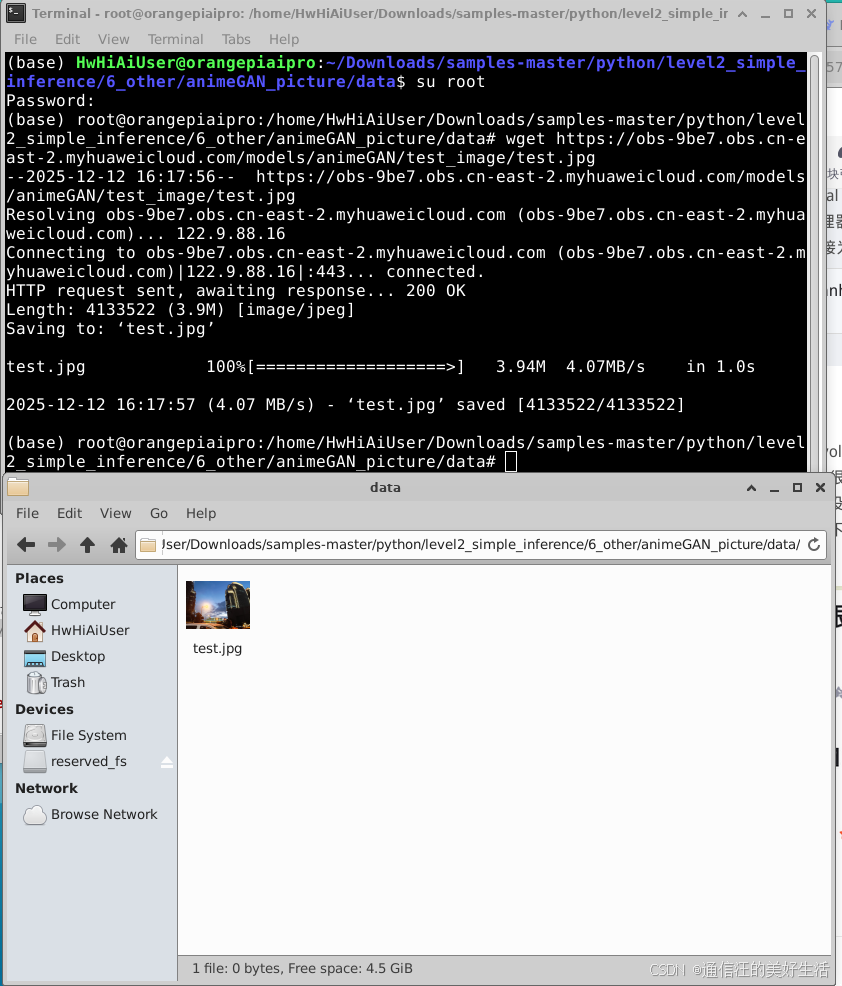
3.1.4调用转换后的模型以及实验结果
确定自己的python版本:
python3 --version

运行工程,命令如下:
python3.9 AnimeGAN.py ../data/ 512
推理结果如下:
3.2图片深度识别模型部署
3.2.1建立工作目录
单独创建工作目录,方便进行项目管理,命令如下:
mkdir depth_project
cd depth_project
3.2.2获取源码包
获取Depth Anything V2的源码,来得到包含模型结构的代码,命令如下:
# 1. 克隆官方仓库(我们需要它的模型结构代码)
git clone https://github.com/DepthAnything/Depth-Anything-V2
cd Depth-Anything-V2
# 2. 安装必要的库
pip install torch torchvision onnx opencv-python
# 3. 下载模型权重 (Small版本)
# 如果下载慢,可以手动下载后传到这个目录
wget https://huggingface.co/depth-anything/Depth-Anything-V2-Small/resolve/main/depth_anything_v2_vits.pth
3.2.3创建导出export_onnx.py
在 Depth,-Anything-V2 目录下,新建文件 export_onnx.py,这里我锁定为 384x384 分辨率,适合 310B 的算力。
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from depth_anything_v2.dpt import DepthAnythingV2
# ================= 完美补丁:彻底解决 half_pixel 和参数匹配问题 =================
orig_interpolate = F.interpolate
def new_interpolate(input, size=None, scale_factor=None, mode='nearest', align_corners=None, recompute_scale_factor=None, **kwargs):
# 强制修改 mode 逻辑
if mode in ['bilinear', 'bicubic']:
# 昇腾对 align_corners=True 的支持非常稳定
return orig_interpolate(input, size, scale_factor, mode, True, recompute_scale_factor, **kwargs)
# 对于 nearest 模式,不需要 align_corners 参数
return orig_interpolate(input, size, scale_factor, mode, None, recompute_scale_factor, **kwargs)
# 替换全局函数
F.interpolate = new_interpolate
# =========================================================================
# 配置模型
model_configs = {
'vits': {'encoder': 'vits', 'features': 64, 'out_channels': [48, 96, 192, 384]}
}
encoder = 'vits'
model = DepthAnythingV2(**model_configs[encoder])
model.load_state_dict(torch.load(f'depth_anything_v2_{encoder}.pth', map_location='cpu'))
model.eval()
# 使用 392 (14的倍数)
dummy_input = torch.ones(1, 3, 392, 392)
output_file = "depth_anything_v2_small_392.onnx"
print("正在导出 ONNX...")
torch.onnx.export(
model,
dummy_input,
output_file,
opset_version=11, # 保持 11 确保 Resize 算子简单化
input_names=["image"],
output_names=["depth"],
do_constant_folding=True
)
print(f"✅ 导出成功: {output_file}")
运行它:python3 export_onnx.py
这样便得到了depth_anything_v2_small_392.onnx。
3.2.4创建 AIPP 配置文件 aipp_opencv.cfg
因为我打算用 Python OpenCV (cv2) 读取摄像头,读出来是 BGR 格式,而模型训练用的是 RGB,且需要归一化。这个配置帮我们在硬件上自动完成转换。
在同一目录下新建 aipp_opencv.cfg:
aipp_op {
aipp_mode: static
input_format: RGB888_U8
csc_switch: false
# 关键:开启 R/B 通道交换 (BGR -> RGB)
rbuv_swap_switch: true
# 归一化参数 (Mean / Std)
min_chn_0: 123.675
min_chn_1: 116.28
min_chn_2: 103.53
var_reci_chn_0: 0.01712475
var_reci_chn_1: 0.017507
var_reci_chn_2: 0.01742919
}
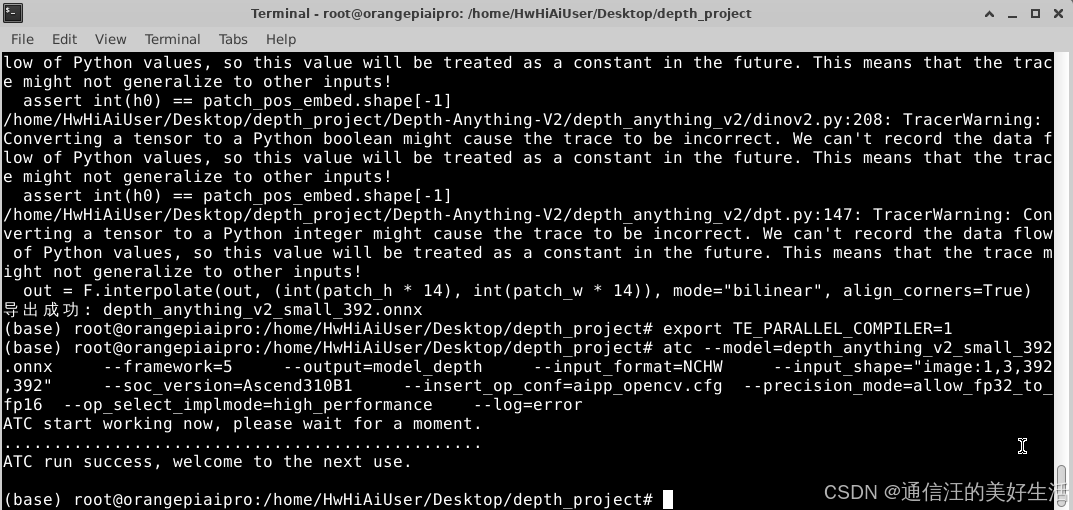
3.2.5执行 ATC 转换 (生成 OM)
atc --model=depth_anything_v2_small_392.onnx --framework=5 --output=model_depth --input_format=NCHW --input_shape="image:1,3,392,392" --soc_version=Ascend310B1 --insert_op_conf=aipp_opencv.cfg --precision_mode=allow_fp32_to_fp16 --op_select_implmode=high_performance --log=error
3.2.6编写推理代码
现在,在同一目录下新建主程序 main.py。这是完整版,包含了 NPU 管理和 OpenCV 显示。
import acl
import numpy as np
import cv2
import time
import os
# ================= 昇腾资源管理类 (直接复制) =================
class AscendNet:
def __init__(self, model_path, device_id=0):
self.device_id = device_id
self.model_path = model_path
# 1. 初始化
ret = acl.init()
if ret != 0: raise Exception(f"acl.init failed: {ret}")
ret = acl.rt.set_device(self.device_id)
if ret != 0: raise Exception(f"set_device failed: {ret}")
self.context, _ = acl.rt.create_context(self.device_id)
self.stream, _ = acl.rt.create_stream()
# 2. 加载模型
self.model_id, ret = acl.mdl.load_from_file(self.model_path)
if ret != 0: raise Exception(f"load_model failed: {ret}")
self.model_desc = acl.mdl.create_desc()
acl.mdl.get_desc(self.model_desc, self.model_id)
# 3. 申请内存
self._init_resource()
def _init_resource(self):
self.input_dataset = acl.mdl.create_dataset()
self.input_buffers = []
num_inputs = acl.mdl.get_num_inputs(self.model_desc)
for i in range(num_inputs):
size = acl.mdl.get_input_size_by_index(self.model_desc, i)
dev_ptr, _ = acl.rt.malloc(size, 1) # HUGE_FIRST
data_buffer = acl.create_data_buffer(dev_ptr, size)
acl.mdl.add_dataset_buffer(self.input_dataset, data_buffer)
self.input_buffers.append({"ptr": dev_ptr, "size": size})
self.output_dataset = acl.mdl.create_dataset()
self.output_buffers = []
num_outputs = acl.mdl.get_num_outputs(self.model_desc)
for i in range(num_outputs):
size = acl.mdl.get_output_size_by_index(self.model_desc, i)
dev_ptr, _ = acl.rt.malloc(size, 1)
data_buffer = acl.create_data_buffer(dev_ptr, size)
acl.mdl.add_dataset_buffer(self.output_dataset, data_buffer)
self.output_buffers.append({"ptr": dev_ptr, "size": size})
def run(self, image_np):
# 确保数据是连续的
if not image_np.flags['C_CONTIGUOUS']:
image_np = np.ascontiguousarray(image_np)
input_meta = self.input_buffers[0]
ptr = input_meta["ptr"]
size = input_meta["size"]
# --- 关键修改:使用 numpy 的 ctypes 获取指针 ---
image_ptr = image_np.ctypes.data
image_size = image_np.nbytes
# 拷贝到 Device
ret = acl.rt.memcpy(ptr, size, image_ptr, image_size, 1) # 1=Host2Dev
if ret != 0: print(f"memcpy Host2Dev failed: {ret}")
# 执行推理
acl.mdl.execute(self.model_id, self.input_dataset, self.output_dataset)
# 结果拷贝 Device -> Host
output_meta = self.output_buffers[0]
out_ptr = output_meta["ptr"]
out_size = output_meta["size"]
host_output = np.zeros(out_size // 4, dtype=np.float32)
host_ptr = host_output.ctypes.data
acl.rt.memcpy(host_ptr, out_size, out_ptr, out_size, 2) # 2=Dev2Host
return host_output
def release(self):
acl.rt.destroy_stream(self.stream)
acl.rt.destroy_context(self.context)
acl.rt.reset_device(self.device_id)
acl.finalize()
def main():
W, H = 392, 392
MODEL_FILE = "model_depth.om"
print(f"[Step 1] Loading {MODEL_FILE}...")
net = AscendNet(MODEL_FILE)
print("[Step 2] Opening Camera...")
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("❌ Error: Could not open camera.")
return
print("[Step 3] Running Inference... Result will be saved as .jpg files.")
frame_count = 0
try:
while frame_count < 100: # 先跑100帧试试
ret, frame = cap.read()
if not ret: break
# 1. 预处理
img_input = cv2.resize(frame, (W, H))
# 2. NPU 推理
result = net.run(img_input)
# 3. 后处理 (修正尺寸后的Reshape)
depth_map = result.reshape((H, W))
# 归一化到 0-255
d_min, d_max = depth_map.min(), depth_map.max()
depth_norm = ((depth_map - d_min) / (d_max - d_min + 1e-5) * 255).astype(np.uint8)
depth_color = cv2.applyColorMap(depth_norm, cv2.COLORMAP_INFERNO)
# 4. 拼接
frame_resized = cv2.resize(frame, (W, H))
display_img = np.hstack([frame_resized, depth_color])
# 5. 【关键】:只存图,不弹窗
if frame_count % 10 == 0:
img_name = f"depth_result_{frame_count}.jpg"
cv2.imwrite(img_name, display_img)
print(f"✅ Saved: {img_name}")
frame_count += 1
if frame_count >= 100: break
except Exception as e:
print(f"❌ Error during running: {e}")
finally:
cap.release()
net.release()
print("Done. All resources released.")
if __name__ == "__main__":
main()
3.2.7运行与调试
这是最容易出错的地方,一步步来。
3.2.7.1配置环境变量 (每次打开新终端都要输!)
如果你之前没有把这些写入 .bashrc,请先执行:
# 设置 CANN 环境变量 (路径根据你的安装情况,默认是这个)
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 设置 Python 库路径 (否则 import acl 会报错)
exportPYTHONPATH=/usr/local/Ascend/ascend-toolkit/latest/python/site-packages:$PYTHONPATH
3.2.7.2.运行
python3 main.py
代码运行结果如下: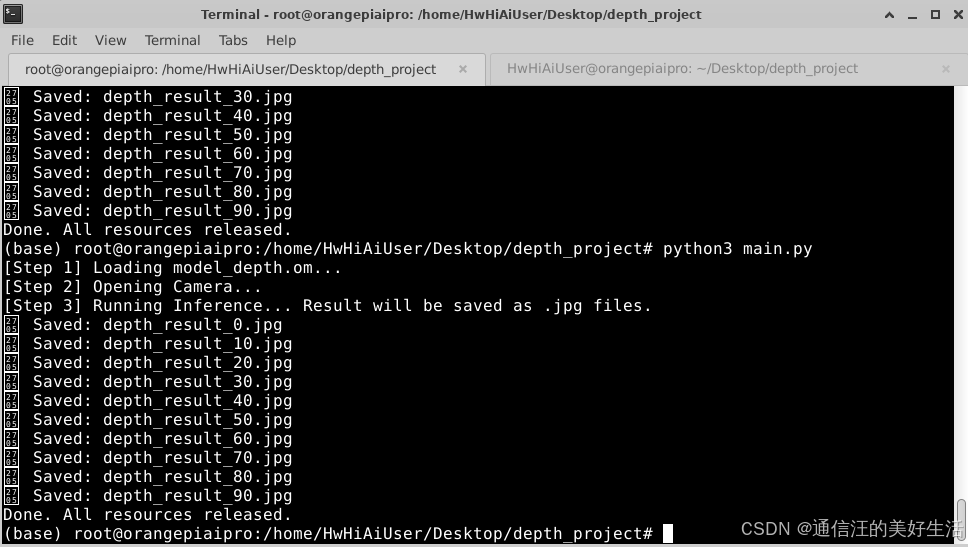

距离越近颜色越浅,距离越远颜色越深,因为算力有限帧率也没有设置那么高,但也算是实时获取并推理出来的结果,证明310B还是圆满实现了Depth Anything V2的部署。
4、结语
博主通过一系列操作验证了在香橙派AIpro上安装CANN并使用自带310B算力进行模型推理的可行性,这次开发遇到的最大挑战有两个这里也简单提一下:
(1)我使用了一张32GB大小的SD卡来进行开发,所以我在安装了CANN的一系列软件架构后开发板整体的内存空间所剩无几,这导致我设置的SWAP空间只有2GB,大大加剧了ATC命令失败的风险,这也大大浪费了我的时间.
(2)我的香橙派AIpro是8T算力的版本,这就注定了我能够做的事情十分有限,不过作为昇腾的入门级开发套件学习来用已经绰绰有余了。
之后博主会在充分学习CANN架构的基础上对目前的算力进行升级,也会持续分享使用该开发套件部署自己训练模型的经验,感觉有用的话就点个关注吧,谢谢各位佬了!

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)