
[嵌入式AI从0开始到入土]19_vllm Ascend初体验(通过源码安装)
本文介绍了在华为昇腾(Ascend)NPU上安装vLLM-Ascend插件的方法,支持大语言模型高效推理。vLLM-Ascend通过模块化设计和动态注册机制兼容昇腾硬件,无需修改底层代码。环境准备包括本地/云端NPU设备检查,推荐Ubuntu 22.04/Python 3.9-3.11。安装步骤涵盖卸载旧版本、配置镜像源、源码编译vLLM及安装vLLM-Ascend插件。测试环节提供了示例代码,并
前言
- vLLM 专注于高吞吐量和低延迟的 LLM 推理,核心创新是 PagedAttention 技术,通过优化 KV Cache。
- 内存管理实现高效显存利用。 vLLM Ascend 是一个社区维护的硬件插件,用于在昇腾 NPU 上无缝运行 vLLM。
- vllm-ascend通过 Python 的模块化 + vLLM 的硬件抽象接口 + 动态后端注册机制,实现了与 vLLM 的无缝兼容。
- 正是这种方式,使得vllm可以更加轻松的兼容其他的国产算力芯片,而无需在意其硬件底层实现。
- 芯片产商也可以更好的注重算力芯片的底层优化,而不必特意为了上层应用去做适配。
- 本文参考文档:https://vllm-ascend-cn.readthedocs.io/zh-cn/latest/installation.html
一、环境准备
1. 本地NPU环境
当前vllm-ascend项目支持的硬件设备如下:
- Atlas A2 训练系列(Atlas 800T A2,Atlas 900 A2 PoD,Atlas 200T A2
Box16,Atlas 300T A2) - Atlas 800I A2 推理系列(Atlas 800I A2)
- Atlas A3 Training series (Atlas 800T A3, Atlas 900 A3 SuperPoD, Atlas
9000 A3 SuperPoD) - Atlas 800I A3 Inference series (Atlas 800I A3)
[Experimental] Atlas 300I Inference series (Atlas 300I Duo)
2. 云端NPU环境
这里我测试了gitcode的notebook环境和魔乐社区的体验空间,虽然遇到一点问题,这里特地感谢@Yikun 兄弟和群友们的支持,目前已经成功运行了示例模型的推理代码。我也提交了PR,完善了相关文档说明,希望能够帮助到大家。
| 平台 | 测试成功的镜像 | 备注 |
|---|---|---|
| gitcode | ubuntu22.04-py3.11-cann8.2.rc1-sglang-main-notebook | 需要手动通过源码安装 |
| modelers | vllm:openeuler-python3.9-cann8.2.RC1-openmind1.0.0 | 预装vllm_ascend 0.9.2版本 |
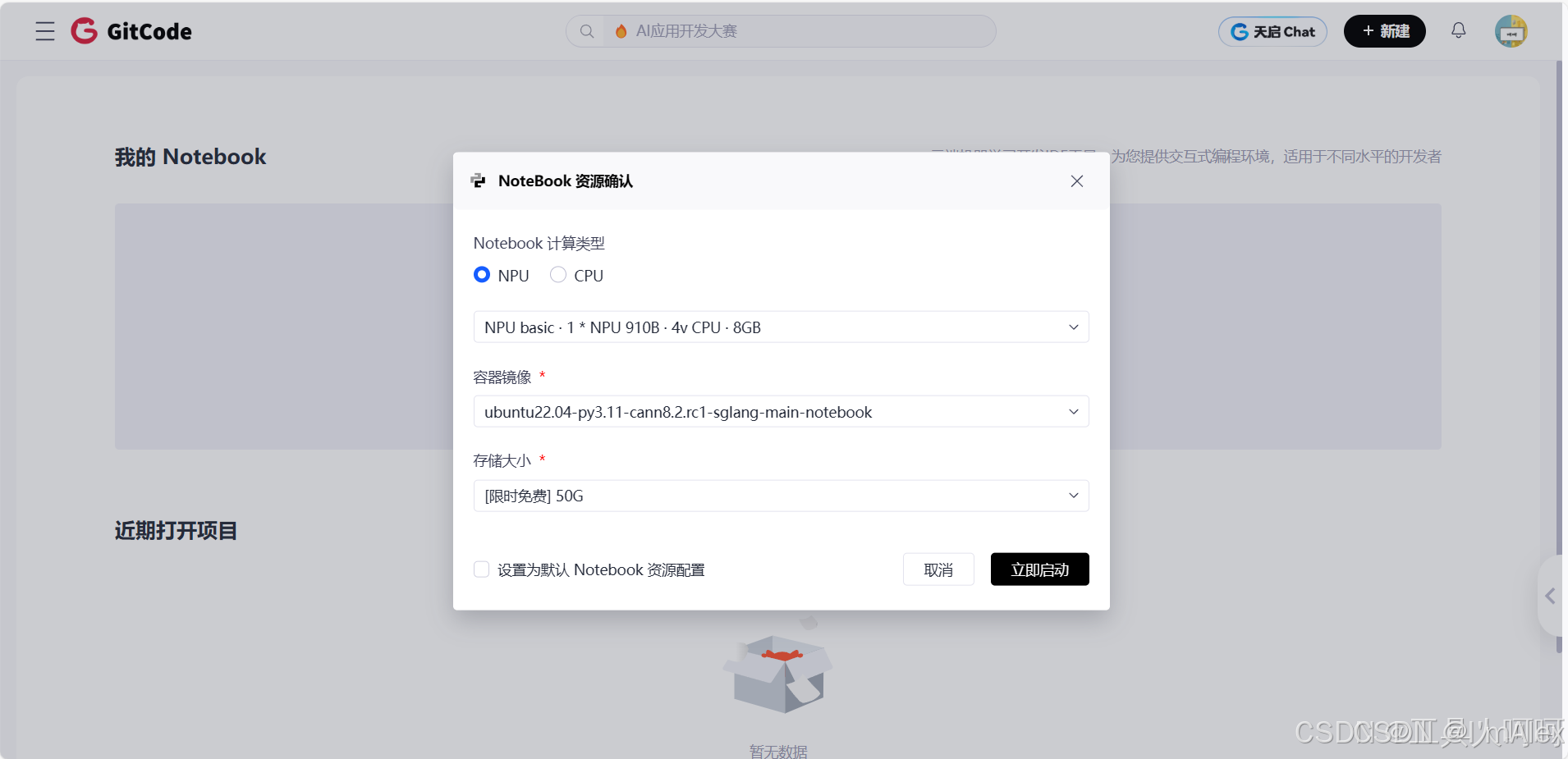
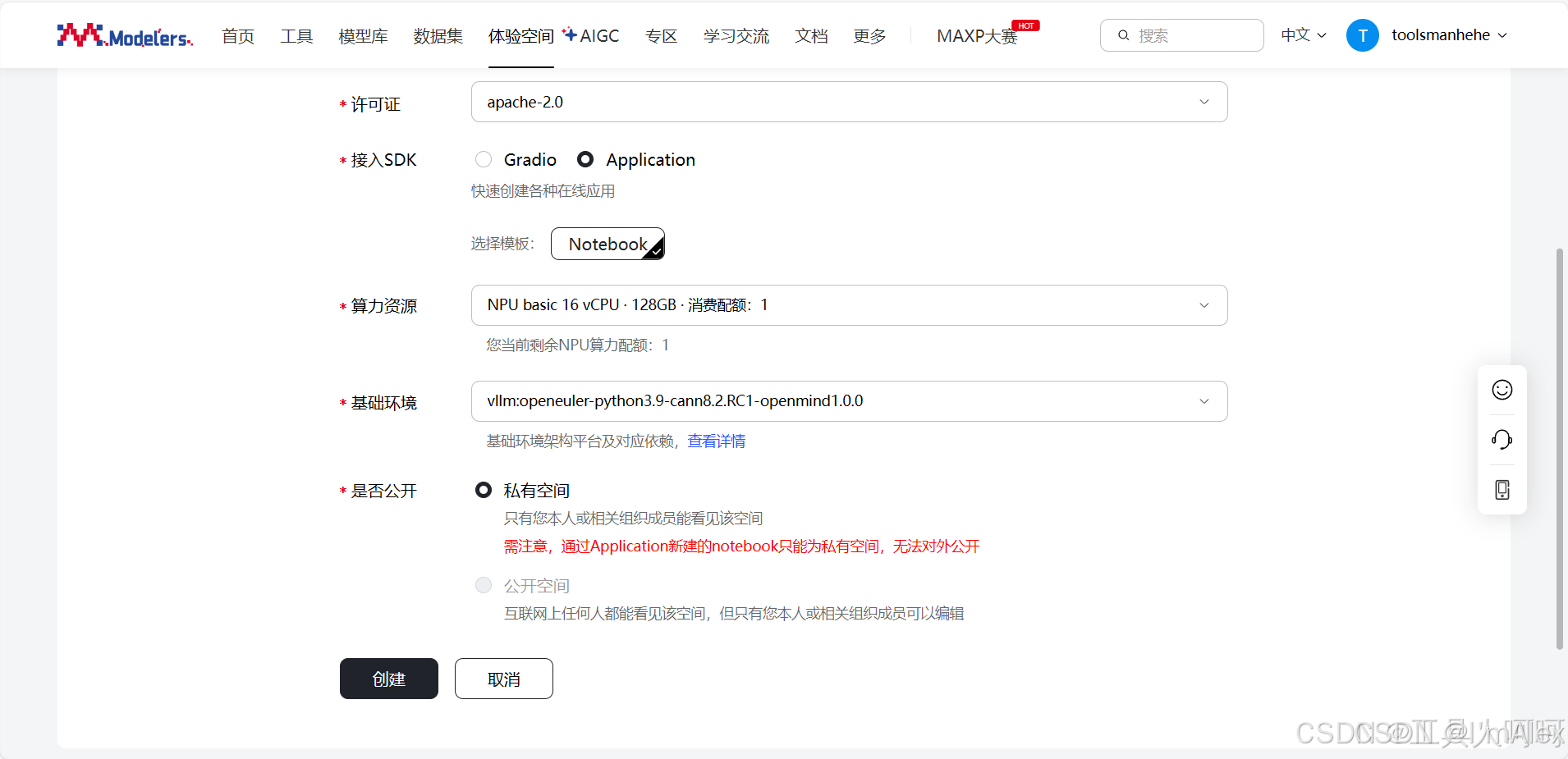
二、 通过源码安装vllm-ascend
-
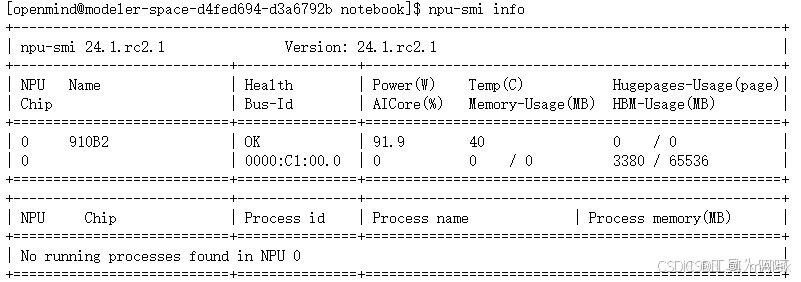
首先登录我们的NPU环境,执行npu-smi info确认计算卡Health健康度为OK。
-
确认python版本,根据vllm-ascend文档,需要保证3.9<=python3 --version< 3.12。
-
卸载torch、torch-npu、vllm和vllm_ascend。很多问题都是由于老版本没有卸载干净导致的。建议多执行几次。
pip uninstall torch torch-npu vllm vllm_ascend
pip list | grep torch # 确认卸载
pip list | grep vllm # 确认卸载
- 配置pip镜像源
pip config set global.index-url https://mirrors.huaweicloud.com/repository/pypi/simple/
- 拉取vllm源码并安装
git clone --depth 1 --branch v0.11.0rc3 https://github.com/vllm-project/vllm
cd vllm
VLLM_TARGET_DEVICE=empty pip install -v -e .
- [可选]x86环境或arm环境安装torch-npu失败的情况下,需要配置pip的额外索引。
pip config set global.extra-index-url "https://download.pytorch.org/whl/cpu/ https://mirrors.huaweicloud.com/ascend/repos/pypi"
- 安装vllm-ascend。
- 这里会从pytorch下载torch,可能会比较慢,可以复制链接通过其他下载工具下载后,通过
pip install ./torchxxxxx.whl安装后,再执行下面的命令安装。 - 如遇torch-npu报错没有这个版本,可以执行上一步的命令添加额外索引解决。
- 这里会从pytorch下载torch,可能会比较慢,可以复制链接通过其他下载工具下载后,通过
pip install vllm-ascend==0.11.0rc0
三、 模型推理测试
- 新建一个test.py文件,内容如下:
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
# Create a sampling params object.
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# Create an LLM.
llm = LLM(model="Qwen/Qwen2.5-0.5B-Instruct")
# Generate texts from the prompts.
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
- 使用
python3 test.py命令启动推理,如果输出如下,则说明vllm-ascend安装成功。 3. 我相信,你已经报错了,可以参考本文最后章节中的列举的问题和对应的解决办法。
3. 我相信,你已经报错了,可以参考本文最后章节中的列举的问题和对应的解决办法。
问题
1. The global thread pool has not been initialized.: ThreadPoolBuildError
现象(仅取最后几行):
File "/home/service/.local/lib/python3.11/site-packages/transformers/tokenization_utils_fast.py", line 553, in _batch_encode_plus
encodings = self._tokenizer.encode_batch(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
pyo3_runtime.PanicException: The global thread pool has not been initialized.: ThreadPoolBuildError { kind: IOError(Os { code: 11, kind: WouldBlock, message: "Resource temporarily unavailable" }) }
[ERROR] 2025-10-19-16:20:04 (PID:2604, Device:-1, RankID:-1) ERR99999 UNKNOWN applicaiton exception
ERROR 10-19 16:20:06 [core_client.py:564] Engine core proc EngineCore_DP0 died unexpectedly, shutting down client.
2. cannot import name LLM from vllm(unknown location)
现象:
解决方案:
这个报错,是因为把vllm安装到/home/openmind了,然后执行脚本,也是在/home/openmind那个目录,默认就会先搜索当前路径下的vllm。但这个其实是源码目录,vllm/vllm/init.py,多了一层。
我们只需要保证推理代码和拉取的vllm项目不在同一个目录,并且执行推理程序的时候,不在vllm项目源码同级目录下就可以了,上面截图的问题,我们只需要下面两步即可正常推理了:
cd volume/notebook
pythopn3 test.py
3. ModuleNotFoundError: No module named vllm.plugins.lora_resolvers
现象:
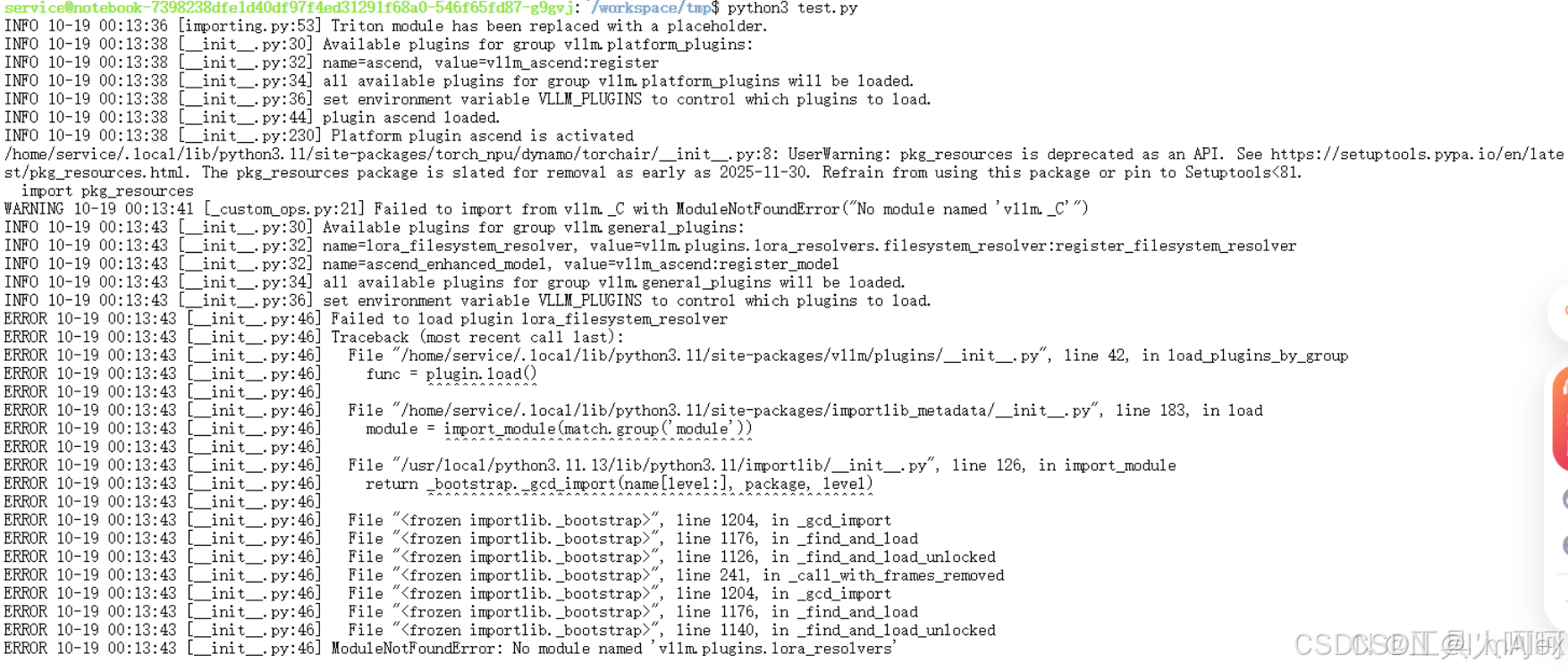
解决方法:
此问题可能是由于当前环境中存在老版本的vllm库没有卸载干净,直接安装了新版本的vllm导致的。我们只需要执行几次卸载命令,然后参考上面的文档安装就可以了。
pip uninstall torch torch-npu vllm vllm_ascend
4. Failed to inport from vllm._C with ModuleNotFoundError
现象:

解决方案:
这个警告是因为在NPU上执行时导入GPU算子失败了,不会影响到NPU上的正常推理。
- huggingface连接超时
解决办法:
export VLLM_USE_MODELSCOPE=true
pip install modelscope
总结
本次主要是介绍如何在华为昇腾(Ascend)NPU 上通过源码方式安装并运行 vLLM-Ascend 插件,以支持大语言模型(LLM)的高效推理的方法和相关注意事项。
vllm-ascend的出现,使得在昇腾上部署大语言模型更加的容易,基于插件机制,使得几乎不需要修改代码,在vllm推理时便可以自动调用昇腾的算力。
虽然目前在体验上仍有许多不足,会遇到许多不可预料的错误,但我相信随着社区开发者们的不断贡献下,vllm-ascend项目正在不断的迭代升级,这个项目会越来越好用,部署会越来越简单。笔者期待未来在项目的Contributors中能看到大家的id。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 18
18 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)