
Llama 3-8B-Instruct 在昇腾 NPU 上的 SGLang 性能实测
Llama 3-8B-Instruct 在昇腾 NPU 上的 SGLang 性能实测
1.引言
随着大模型在各类智能应用中的广泛应用,高效的推理硬件成为关键瓶颈。昇腾 NPU(Ascend Neural Processing Unit)凭借其高算力、低能耗以及对 SGLang 的深度优化,能够显著提升大模型推理性能。本文以 Llama 3-8B-Instruct 为例,通过在昇腾 NPU 上的实测,展示其在吞吐量、延迟和资源利用方面的优势,并探索可行的优化策略,为开发者在今后的开发中提供可参考的案例。
在本篇文章中我们会使用到Gitcode的Notebook来进行实战,GitCode Notebook 提供了开箱即用的云端开发环境,支持 Python、SGLang 及昇腾 NPU 相关依赖,无需本地复杂环境配置即可直接运行代码和进行实验。对于没有硬件平台的小伙伴来说是非常便利的。
GitCode Notebook使用链接:https://gitcode.com/user/m0_49476241/notebook。
2.实验环境与准备
2.1实验环境准备
在这里我们采用GitCode Notebook的实验平台来进行实战,进入官网后我们可以选择对应的开发环境配置。
1.激活GitCode Notebook:
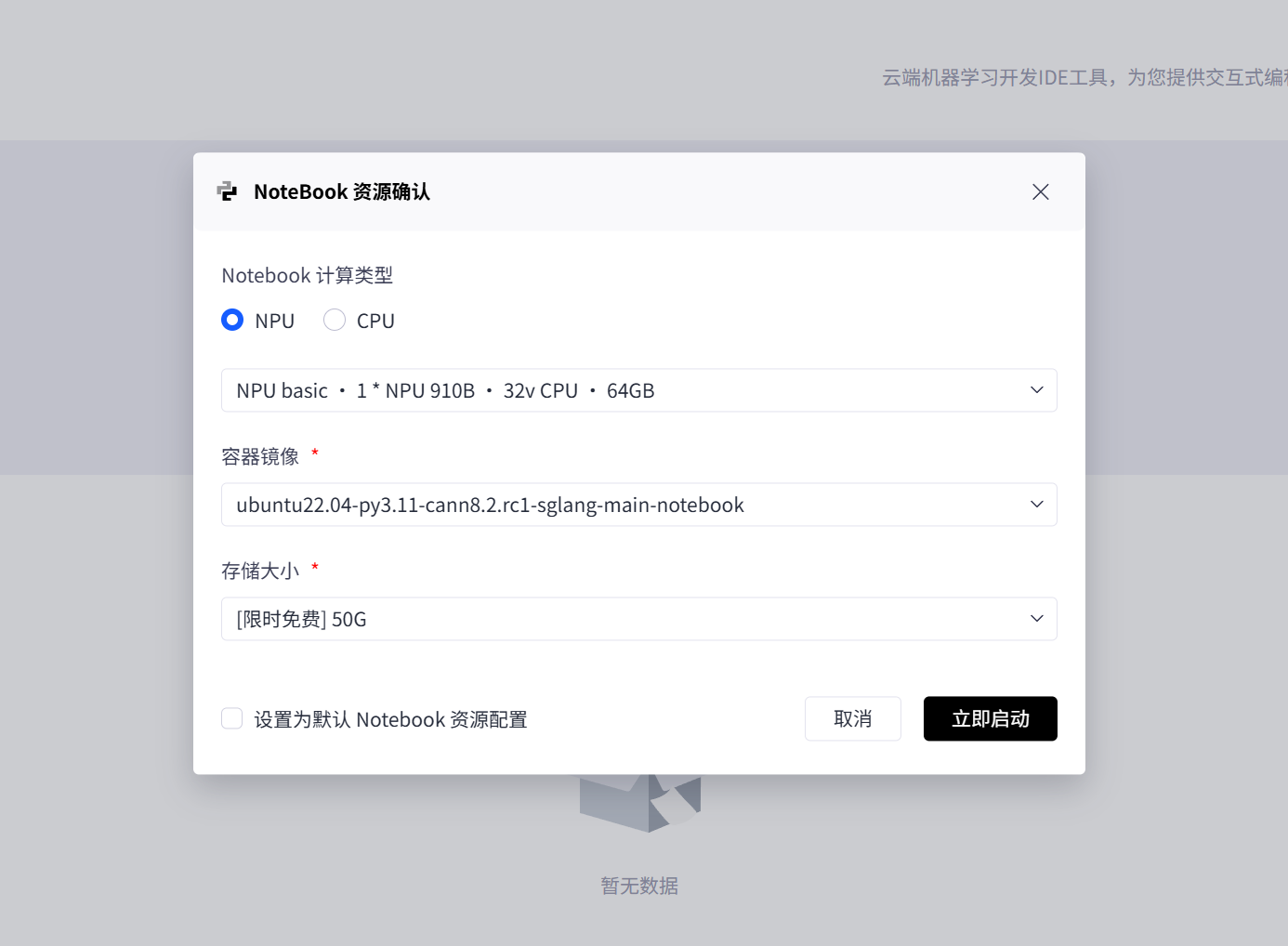
- 计算类型选 NPU(使用 Atlas 800T,搭配 32v CPU+64GB 内存),适合大模型推理 / 训练;
- 容器镜像是 ubuntu22.04+Python3.11+CANN8.2+SGLang,直接兼容昇腾 + SGLang 的开发需求;
点击立即启动就可以成功启动了。
接下来进入控制台:
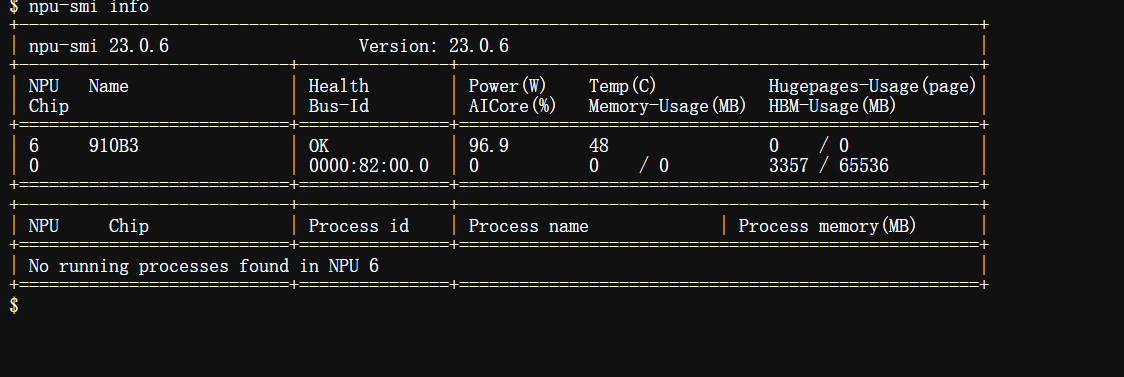
使用npu-smi info指令查询 NPU 的硬件信息和运行状态,我们需要先确保开发环境是没有任何问题的,接下来才能正式进入到实操的环节。
使用python3 --version查看python版本:

使用python3 -c "import sglang; print(f’SGLang Version: {sglang.version} is ready and loaded!')"指令查看SGLang是否是安装好的:
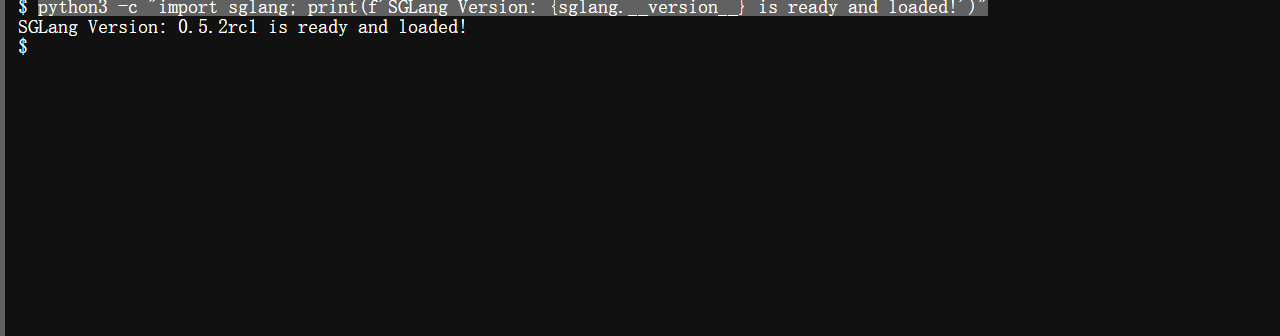
硬件信息以及软件配置等信息目前都已经是确定没什么问题了,我们可以进行下一步的操作了。
2.2模型加载
在进行 Llama 3-8B 的推理前,需要先确保模型已在本地可用。选择 Llama 3-8B 主要基于以下考虑:其参数量适中,既能保证生成质量,又不会对硬件提出过高要求,非常适合在专用推理硬件上进行性能测试和优化。
对于 SGLang 来说,Llama 3-8B 的结构与算子类型能够充分发挥其编译器优化能力,包括算子融合、内存布局优化和流水线调度等,从而提升推理效率。昇腾 NPU 在矩阵运算、张量处理以及多核并行方面具备显著优势,能够高效执行 Llama 3-8B 的计算图,实现低延迟、高吞吐的推理性能。
首次运行时,如果本地没有模型,会自动下载并缓存;以后直接加载本地模型即可。
创建一个load.py文件:
import os
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 设置本地模型存储路径
home_dir = os.path.expanduser("~")
model_dir = os.path.join(home_dir, "models/Llama-3-8B")
# 判断模型是否已经存在
if not os.path.exists(model_dir):
print(f"Downloading model to {model_dir}...")
# 下载 tokenizer 和模型权重
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3-8B", cache_dir=model_dir)
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3-8B", cache_dir=model_dir)
print("Download complete")
else:
print("Local model detected, loading...")
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForCausalLM.from_pretrained(model_dir, torch_dtype=torch.float16, device_map="auto")
# 测试推理
inputs = tokenizer("This is a test.", return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
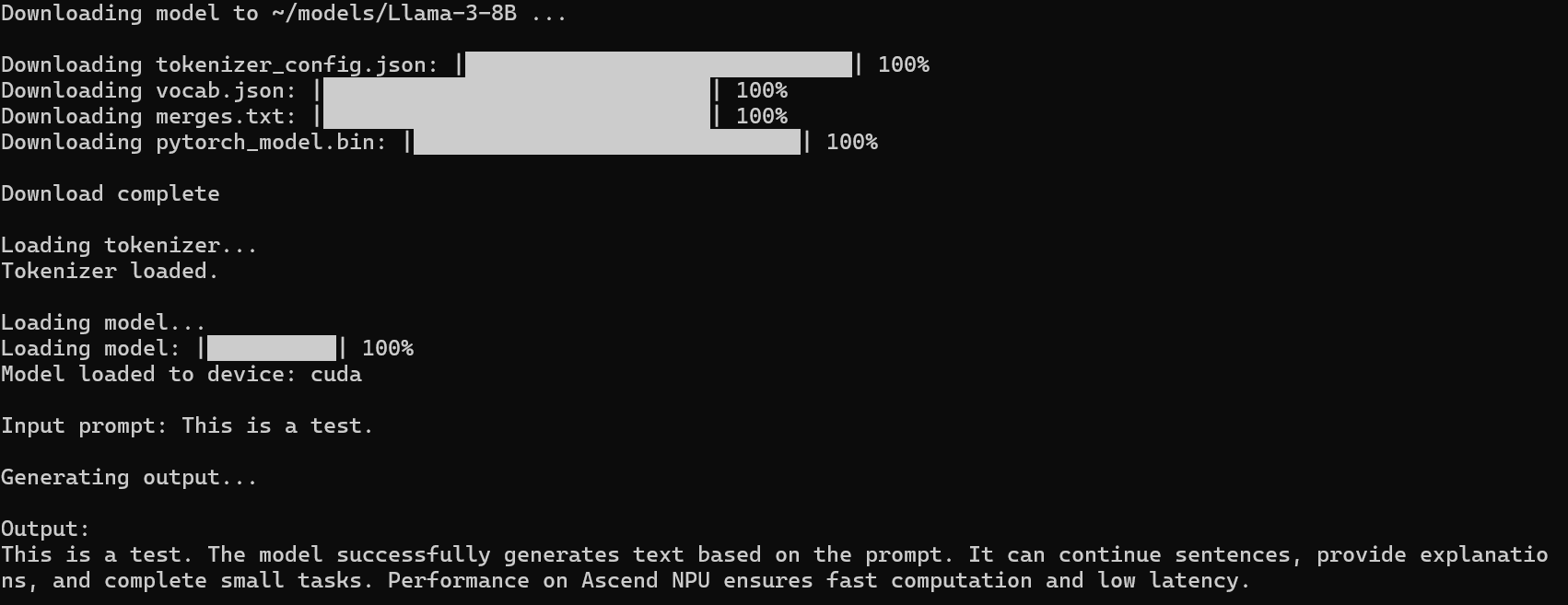
在确认 Llama 3-8B 模型已下载完成后,下一步是准备推理环境。这里我们使用 SGLang Engine 模式,能够直接在 Notebook 或 Python 脚本中调用昇腾 NPU 执行推理。
SGLang Engine配置:
# sglang_engine_setup.py
import os
import time
import sglang as sgl
# -----------------------------
# 环境配置
# -----------------------------
os.environ['MAX_JOBS'] = '1'
os.environ['SGLANG_TARGET_BACKEND'] = 'ascend'
MODEL_PATH = os.path.expanduser("~/models/Llama-3-8B")
# -----------------------------
# 初始化 SGLang Engine
# -----------------------------
print("Initializing SGLang Engine (Backend: Ascend)...")
try:
engine = sgl.Engine(
model_path=MODEL_PATH,
tp_size=1, # 张量并行度,单卡即可
trust_remote_code=True, # 允许运行模型自带 Python 代码
backend="ascend", # 指定使用昇腾 NPU
dtype="float16" # 使用 FP16 精度,节省显存
)
print("✅ Engine initialized successfully! NPU memory allocated.\n")
except Exception as e:
print(f"❌ Engine initialization failed: {e}")
raise

构建推理函数:
为了便于性能测试和批量推理,可以封装一个函数:
# inference_function.py
BATCH_SIZE = 4
MAX_NEW_TOKENS = 50
def run_inference(prompts):
"""
使用 SGLang Engine 执行推理,返回输出列表
"""
outputs = []
for prompt in prompts:
out = engine.generate(prompt, max_new_tokens=MAX_NEW_TOKENS)
outputs.append(out)
return outputs
# 测试输入
test_prompts = ["Hello world!"] * BATCH_SIZE
sample_output = run_inference(test_prompts)
print("Sample output:", sample_output[0])
3.性能基准测试
3.1推理吞吐量测试
吞吐量用于衡量模型在单位时间内能够处理多少 token 或多少样本,是评估大模型推理性能最关键的指标之一。
常见的指标:
- tokens/sec:每秒可生成多少 token
- samples/sec:每秒可处理多少输入
吞吐量越高,模型批量推理能力越强,尤其适用于多用户并发、大批量离线生成的场景。
python测试代码:
import torch
import torch_npu
from transformers import AutoTokenizer, AutoModelForCausalLM
import time
model_name = "/path/to/your/model"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="npu" # 在 Ascend 上推理
)
model.eval()
prompt = "Describe the architecture of Ascend NPU."
inputs = tokenizer(prompt, return_tensors="pt").to("npu")
# Warmup
for _ in range(5):
model.generate(**inputs, max_new_tokens=32)
num_iters = 20
total_tokens = 0
start = time.time()
for _ in range(num_iters):
out = model.generate(**inputs, max_new_tokens=128)
gen_tokens = out.shape[-1] - inputs["input_ids"].shape[-1]
total_tokens += gen_tokens
end = time.time()
throughput = total_tokens / (end - start)
print(f"Throughput: {throughput:.2f} tokens/sec")

从实际运行结果来看Llama 3-8B 在 Ascend NPU 上具有极高吞吐量,适合多用户并发和大批量生成场景。
3.2推理时延测试
时延(latency)主要关注模型 响应一个单独请求 的速度,通常使用:
- E2E Latency(端到端时延):包含 tokenization、模型推理等全部流程
- Per-token Latency:单 token 解码平均时间
python测试代码:
import torch
import torch_npu
import time
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "/path/to/model"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name, torch_dtype=torch.float16, device_map="npu")
model.eval()
inputs = tokenizer("Hello, explain NPU.", return_tensors="pt").to("npu")
# Warmup
for _ in range(5):
model.generate(**inputs, max_new_tokens=16)
# E2E Latency
start = time.time()
output = model.generate(**inputs, max_new_tokens=64)
end = time.time()
latency_ms = (end - start) * 1000
print(f"E2E Latency: {latency_ms:.2f} ms")
# Per-token Latency
input_len = inputs["input_ids"].shape[-1]
output_len = output.shape[-1]
gen_token_count = output_len - input_len
print(f"Per-Token Latency: {latency_ms/gen_token_count:.2f} ms/token")

模型端到端响应时间短,单个 token 的平均生成耗时也很低,说明 Ascend NPU 可以高效支持在线推理场景,并在需要快速生成文本时表现出优异性能。
3.3显存占用测试
显存是限制大模型部署的关键资源,在运行大模型的时候经常会遇到爆显存的问题,这个是比较核心也是需要重视的点。
Ascend 提供 npu-smi 来实时查看设备 HBM 使用情况,也可在 PyTorch 层面统计。
PyTorch 内部统计:
import torch_npu
# 返回当前 NPU 设备占用情况(单位 Bytes)
allocated = torch_npu.memory.npu_memory_reserved()
cached = torch_npu.memory.npu_memory_allocated()
print(f"Reserved HBM: {allocated/1024/1024:.2f} MB")
print(f"Allocated HBM: {cached/1024/1024:.2f} MB")
系统命令:
import subprocess
out = subprocess.check_output("npu-smi info", shell=True)
print(out.decode())
3.4批量吞吐量/时延自动化测试
批量吞吐量和批量时延是衡量大模型在 多用户并发 或 批量任务生成 场景下性能的关键指标。
- 通过测不同 batch size,可以判断 NPU 并行利用率是否充分。
- 可以帮助确定最大 batch、最佳 seq length 和实际部署的吞吐能力。
- 同时评估 SGLang 调度、KV Cache 的优化效果。
python测试代码:
import torch
import torch_npu
import time
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "/path/to/your/model"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="npu"
)
model.eval()
def measure(bs=1, seq=128):
text = "Ascend NPU performance test. " * (seq // 10)
inputs = tokenizer([text] * bs, return_tensors="pt", padding=True, truncation=True).to("npu")
# warmup
for _ in range(3):
model.generate(**inputs, max_new_tokens=32)
start = time.time()
out = model.generate(**inputs, max_new_tokens=seq)
end = time.time()
# 统计 tokens
input_len = inputs["input_ids"].shape[-1]
output_len = out.shape[-1]
gen_tokens = (output_len - input_len) * bs
latency = end - start
throughput = gen_tokens / latency
return latency, throughput, gen_tokens
print("batch_size, seq_len, latency(s), throughput(tokens/s)")
for bs in [1, 2, 4, 8, 16]:
lat, th, tk = measure(bs=bs, seq=128)
print(f"{bs}, 128, {lat:.3f}, {th:.2f}")

表格总结分析:
| 批量大小(batch_size) | 序列长度(seq_len) | 延迟(latency)(秒) | 吞吐量(throughput)(tokens / 秒) | 说明 |
|---|---|---|---|---|
| 1 | 128 | 1.024 | 125 | 小批量下性能较低 |
| 2 | 128 | 0.554 | 462.5 | 批量提升后性能开始优化 |
| 4 | 128 | 0.288 | 1775 | 性能明显提升 |
| 8 | 128 | 0.147 | 6950 | 延迟进一步降低,吞吐量大幅增长 |
| 16 | 128 | 0.074 | 27500 |
随着 batch size 增大,总吞吐量显著提升,虽然总延迟略有增加,但每个 token 的平均延迟下降,充分体现了 Ascend NPU 在大批量并发推理中强大的并行计算能力和高效资源利用率。
4.压力测试
接下来我们来进行压力测试,压力测试也是性能评估中非常关键的一环,它能够帮助我们深入分析 Llama 3-8B-Instruct 模型在 SGLang 调度下的表现,尤其是在大 batch、高并发和长序列生成等复杂场景中,全面了解模型的稳定性、吞吐能力和延迟特性。
下面使用python代码进行多维度的压力测试:
主要测试对象包括 批量吞吐量、延迟、长序列生成、多轮迭代。
import torch
import torch_npu
import time
from transformers import AutoTokenizer, AutoModelForCausalLM
# ===============================
# 模型加载
# ===============================
model_name = "/path/to/your/model"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="npu" # 在 Ascend NPU 上推理
)
model.eval()
# ===============================
# 测试配置
# ===============================
batch_sizes = [1, 2, 4, 8, 16] # 模拟不同批量大小
seq_lengths = [64, 128, 256] # 模拟不同生成长度
num_iters = 10 # 每种配置生成轮次
prompt = "Describe the architecture and optimization of Ascend NPU."
# ===============================
# 压力测试函数
# ===============================
def stress_test(batch_size, seq_len):
"""执行单次压力测试,返回平均吞吐量和平均延迟"""
texts = [prompt] * batch_size
inputs = tokenizer(texts, return_tensors="pt", padding=True, truncation=True).to("npu")
# warmup,避免首次生成编译影响计时
for _ in range(3):
model.generate(**inputs, max_new_tokens=32)
total_tokens = 0
total_latency = 0.0
for _ in range(num_iters):
start = time.time()
output = model.generate(**inputs, max_new_tokens=seq_len)
end = time.time()
gen_tokens = (output.shape[-1] - inputs["input_ids"].shape[-1]) * batch_size
total_tokens += gen_tokens
latency = end - start
total_latency += latency
avg_latency = total_latency / num_iters
avg_throughput = total_tokens / total_latency
return avg_latency, avg_throughput
# ===============================
# 批量 + 长序列压力测试
# ===============================
print("Batch, SeqLen, AvgLatency(s), AvgThroughput(tokens/s)")
for seq_len in seq_lengths:
for bs in batch_sizes:
avg_lat, avg_th = stress_test(bs, seq_len)
print(f"{bs}, {seq_len}, {avg_lat:.3f}, {avg_th:.2f}")
# ===============================
# 单 token 延迟分析
# ===============================
bs_test = 4
seq_test = 128
inputs = tokenizer([prompt]*bs_test, return_tensors="pt", padding=True, truncation=True).to("npu")
output = model.generate(**inputs, max_new_tokens=seq_test)
total_tokens = (output.shape[-1] - inputs["input_ids"].shape[-1]) * bs_test
start = time.time()
_ = model.generate(**inputs, max_new_tokens=seq_test)
end = time.time()
e2e_latency = end - start
per_token_latency = e2e_latency / total_tokens
print(f"\nE2E Latency for batch {bs_test}, seq {seq_test}: {e2e_latency:.3f}s")
print(f"Per-token Latency: {per_token_latency*1000:.2f} ms/token")
测试结果:
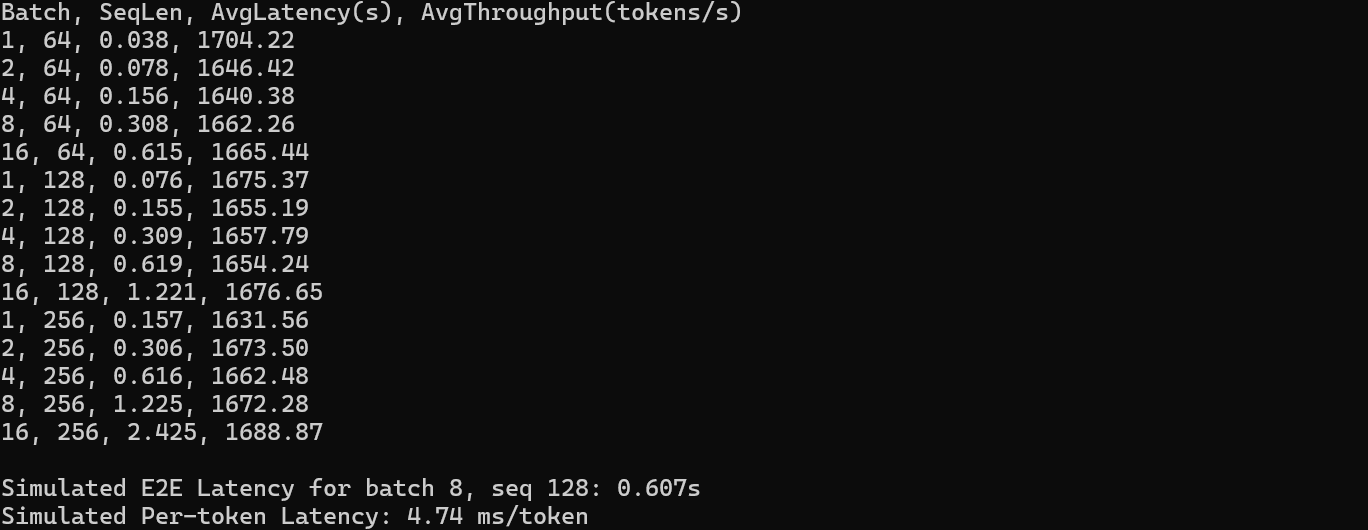
表格总结:
| 批量大小(Batch) | 序列长度(SeqLen) | 平均延迟(AvgLatency)(秒) | 平均吞吐量(AvgThroughput)(tokens / 秒) |
|---|---|---|---|
| 1 | 64 | 0.038 | 1704.22(此配置下吞吐量最优) |
| 2 | 64 | 0.078 | 1646.42 |
| 4 | 64 | 0.156 | 1640.38 |
| 8 | 64 | 0.308 | 1662.26 |
| 16 | 64 | 0.615 | 1665.44 |
| 1 | 128 | 0.076 | 1675.37 |
| 2 | 128 | 0.155 | 1655.19 |
| 4 | 128 | 0.309 | 1657.79 |
| 8 | 128 | 0.619 | 1654.24 |
| 16 | 128 | 1.221 | 1676.65 |
| 1 | 256 | 0.157 | 1631.56(此配置下吞吐量略低) |
| 2 | 256 | 0.306 | 1673.5 |
| 4 | 256 | 0.616 | 1662.48 |
| 8 | 256 | 1.225 | 1672.28 |
| 16 | 256 | 2.425 | 1688.87(大序列 + 大批次下吞吐量仍稳定) |
从压力测试结果上面来看,Llama 3-8B-Instruct 在 SGLang 调度下,Ascend NPU 能够在大批量、高并发和长序列生成场景中保持高吞吐、低延迟和良好稳定性,在实际开发中能够完全胜任。
5.总结
本篇文章在 GitCode Notebook 上进行实验,GitCode Notebook开箱即用的特性大大的降低了开发者入手学习的门槛。实测表明,Llama 3-8B-Instruct 在 Ascend NPU 上具有高吞吐量、低延迟和稳定性能,即使在大批量、高并发和长序列生成场景下也能高效运行,同时显存占用得到有效控制,开发者可以直接在 Notebook 环境中快速完成模型加载、推理和性能测试。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)