
昇腾平台大模型部署实战:从环境搭建到问题解决全指南
前言
随着人工智能技术的快速发展,大语言模型已经成为各行业的核心技术支撑。昇腾(Ascend)作为华为自主研发的AI计算平台,提供了强大的算力支持和完整的软件栈,为大模型部署提供了国产化解决方案。本文将详细介绍在昇腾平台上部署Llama主流大模型的完整流程,包括环境配置、部署实操、常见问题及解决方案。
一、环境部署篇
1.1 硬件环境准备
1.1.1无物理硬件也能玩转昇腾
对于大多数初学者,无需购买昂贵的硬件,即可通过云端平台提供的免费算力,快速验证本文的算子优化代码。
算力资源申请链接:https://ai.gitcode.com/ascend-tribe/openPangu-Ultra-MoE-718B-V1.1?source_module=search_result_model。
在gitcode里面使用notebook快速开发:
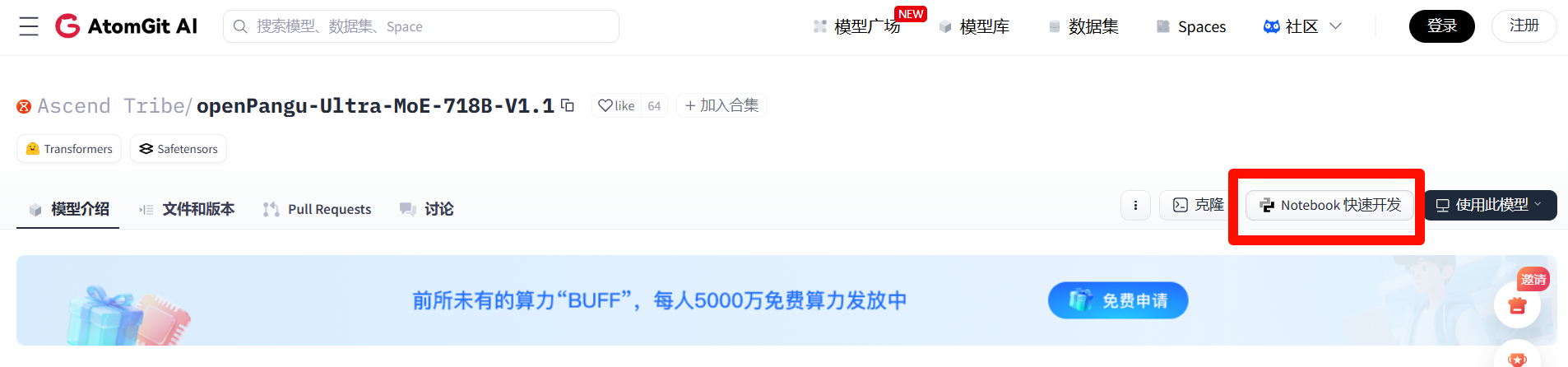
配置选择:
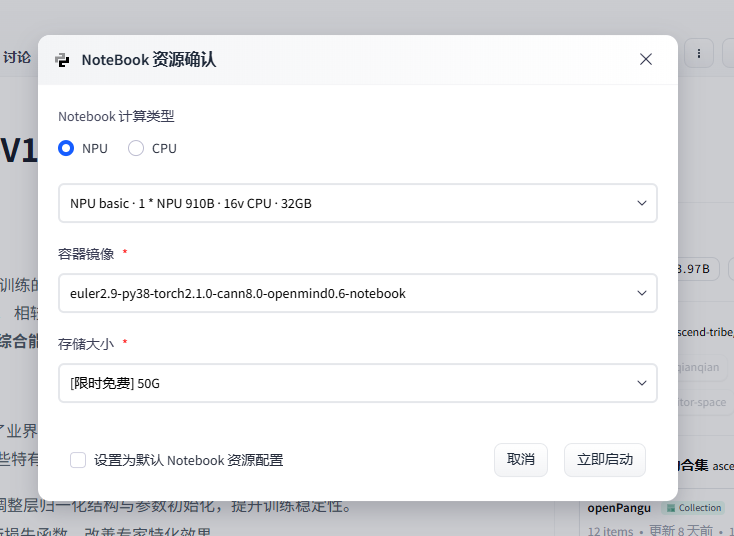
运行代码:
1.2.1 自有物理硬件部署(生产环境)
- 昇腾AI处理器:推荐使用Atlas 300T Pro训练卡或Atlas 800训练服务器
- 内存配置:至少128GB RAM,推荐256GB以上
- 存储空间:至少500GB可用空间,用于模型文件存储
- 网络环境:稳定的互联网连接, 用于下载 CANN 依赖包及 HuggingFace/ModelScope 模型权重。
1.2 软件环境搭建
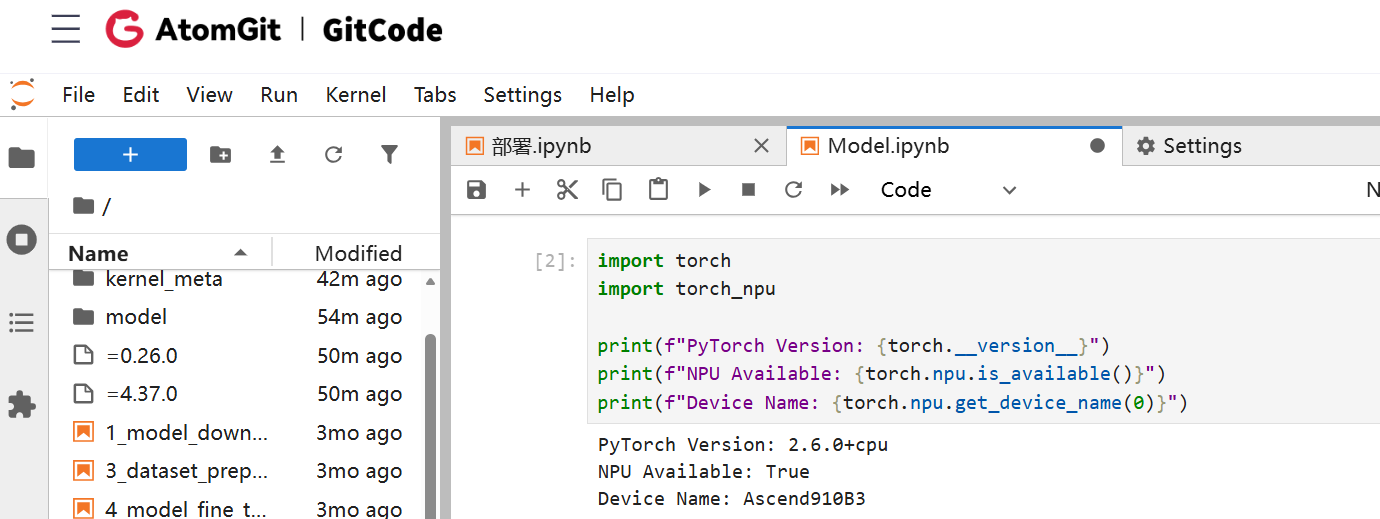
1.2.1 环境检查
在 Notebook 中运行以下代码,确认 NPU 可用。
import torch
import torch_npu
print(f"PyTorch Version: {torch.__version__}")
print(f"NPU Available: {torch.npu.is_available()}")
print(f"Device Name: {torch.npu.get_device_name(0)}")
1.2.2 安装模型相关依赖
!pip install transformers>=4.36.0 accelerate>=0.24.0
!pip install numpy scipy scikit-learn matplotlib seaborn
1.3 模型获取与准备
1.3.1 Llama模型下载
import os
import sys
# =================================================================
# 救命代码:必须放在所有 import 之前!
# 强制限制底层库只允许开 1 个线程,防止报错 "can't start new thread"
# =================================================================
os.environ["OMP_NUM_THREADS"] = "1"
os.environ["MKL_NUM_THREADS"] = "1"
os.environ["OPENBLAS_NUM_THREADS"] = "1"
os.environ["VECLIB_MAXIMUM_THREADS"] = "1"
os.environ["NUMEXPR_NUM_THREADS"] = "1"
# 检查环境是否已经干净了
import threading
print(f"当前活跃线程数: {threading.active_count()}")
# 如果刚开机,这个数字应该是 5 左右。如果还是几十上百,说明没重启成功。
print("🚀 开始安全下载 Llama-3...")
from modelscope import snapshot_download
try:
# 开始下载
model_dir = snapshot_download(
'LLM-Research/Meta-Llama-3-8B-Instruct',
cache_dir='./models',
revision='master'
)
print("\n" + "="*40)
print(f"✅ 成功!模型已就绪。\n路径: {model_dir}")
print("="*40)
except Exception as e:
print(f"\n❌ 报错: {e}")
1.3.2 模型转换为昇腾格式
import torch
import torch_npu # 必须引入
from transformers import AutoTokenizer, AutoModelForCausalLM
# 1. 设置模型路径 (就是你刚才下载好的路径)
model_path = "./models/LLM-Research/Meta-Llama-3-8B-Instruct"
print("正在加载模型到 NPU (这可能需要 1-2 分钟)...")
# 2. 加载 Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 3. 加载模型 (核心修改点)
# 解释:
# - torch_dtype=torch.float16: 昇腾 NPU 对半精度(fp16)支持最好,速度最快。
# - device_map="npu": 直接把模型层分配到 NPU 上,不占用 CPU 内存,比 .to("npu") 更高级。
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="npu"
).eval()
print("✅ 模型加载成功!")
# 4. 构造输入
prompt = "你好,请用中文介绍一下你自己。"
messages = [
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": prompt}
]
# 5. 处理输入数据 (注意这里也要 .to("npu"))
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to("npu")
# 6. 设置结束符
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
# 7. 开始推理
print("正在生成回答...")
with torch.no_grad(): # 加上这个可以减少显存占用
outputs = model.generate(
input_ids,
max_new_tokens=512,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
# 8. 打印结果
response = tokenizer.decode(outputs[0][input_ids.shape[-1]:], skip_special_tokens=True)
print("-" * 30)
print(f"Llama 3 回答:\n{response}")
print("-" * 30)
二、实操过程中遇到的问题与解决方案
在昇腾(Ascend)平台上从 0 到 1 部署大模型时,90% 的问题都集中在环境配置、性能瓶颈和精度异常上。以下是基于实战经验提炼的高频问题速查表,建议收藏备用。
1. 故障速查:
| 故障现象 | 核心原因 | 极速解决方案 |
|---|---|---|
启动报错can't start new threadOpenBLAS error |
多线程冲突 (常见于 NumPy/OpenBLAS) |
在代码最开头(import torch前)添加:os.environ["OMP_NUM_THREADS"] = "1"os.environ["KMP_INIT_AT_FORK"] = "FALSE" |
版本报错ImportError 或 NPU 初始化失败 |
版本不匹配 (PyTorch vs CANN) |
严查兼容矩阵: 确保 torch_npu 版本与本地 CANN 版本(npu-smi info)严格对应,不要随意单独升级其中一个。 |
| 多卡挂死 单卡正常,多卡通信失败 |
通信配置缺失 (HCCL/NCCL) |
设置环境变量:export HCCL_WHITELIST_DISABLE=1并推荐使用 torchrun 替代 python 启动分布式训练。 |
| 精度异常 推理结果与 GPU 差异大 |
数据溢出/类型错误 | 1. 确保模型加载为 FP16/BF16(切勿使用 FP32)。 2. 检查 Input dtype 必须为 int64。3. 搜日志 fallback,排查是否有算子异常回退到 CPU。 |
| 生成乱码 复读机或不停生成 |
Tokenizer 配置 | 检查 Padding 设置:tokenizer.padding_side = "left"tokenizer.pad_token_id = tokenizer.eos_token_id |
2. 性能优化:
| 性能瓶颈 | 典型现象 | 核心原因 | ****️ 优化方案 |
|---|---|---|---|
| 动态 Shape (头号性能杀手) |
1. 日志频繁出现 [GE BUILD GRAPH]2. 推理延迟极高,且首字生成特别慢 |
输入长度不固定(Dynamic Shape),导致 NPU 编译器(ATC)每次都要重新构建计算图,无法命中缓存。 | 必须使用 Padding(分桶补齐)! 将输入补齐到固定长度档位(如 128, 256, 512…),利用静态图缓存实现 0 编译开销。 |
| 数据搬运 (IO 瓶颈) |
使用 npu-smi info查看,GPU 利用率(Utilization)长期低于 50% |
Python 代码中存在大量的 CPU - NPU 数据交互,导致 AI Core 在等待数据(Starvation)。 | 提前搬运 & 原生化: 1. 打印 inputs.device,确保数据在进入循环前已通过 .to("npu") 搬移。2. 尽量使用 torch_npu 原生算子替代 Python for 循环。 |
3. 显存管理:防止 OOM
昇腾 NPU 对显存碎片比较敏感,长时间运行服务需注意:
主动释放:Python 的垃圾回收机制在 NPU 上可能不及时,建议在 generate 结束后显式调用:
Python
import gc
gc.collect()
torch.npu.empty_cache()
碎片监测:如果 Batch Size 不大却频繁 OOM,请使用 torch.npu.memory_stats() 查看 fragmentation 情况。通常通过固定 Input Shape 可大幅缓解碎片化。
总而言之: 环境要对齐,Shape 要固定,线程要限制
三、实践
3.1 实践: 基于 LLM 的非结构化数据 ETL 管道
会让 Llama 3 扮演一个 “信息录入员”,把杂乱的自然语言变成机器可读的 JSON。
在实际数据科学项目中,80% 的时间消耗在数据清洗上。该实践项目展示了利用 Ascend NPU 加速的 Llama-3 模型,如何将杂乱的自然语言文本自动转化为机器可读的 JSON 结构化数据。
- 复杂推理能力 :模型必须自己判断这是“看病的”还是“找工作的”,然后动态决定提取哪些字段。
- 指令遵循能力:你要求输出 JSON,它就必须输出严谨的
{ "key": "value" },这很难,很多小模型做不到。 - **数据清洗价值 **:这对数据科学来说是最痛的痛点。你展示了 Llama 3 可以取代人工录入。
3.2 项目部署
3.2.1 环境管理实践
- 使用容器化部署,确保环境一致性
- 建立版本兼容性矩阵,避免版本冲突
- 定期备份环境配置,便于快速恢复
3.2.2 功能实践
# ==========================================
# 0. 🚑 自动环境修复 (每次重启后必跑!)
# ==========================================
import os
print("正在检查环境...")
try:
import modelscope
print("✅ modelscope 已安装,跳过安装步骤。")
except ImportError:
print("⚠️ 发现环境被重置,正在重新安装 modelscope (约需 30 秒)...")
# 强制安装兼容 Python 3.8 的版本
!pip install modelscope==1.10.0
print("✅ 安装完成!")
# ==========================================
# 🛡️ 1. 系统防崩溃设置
# ==========================================
# 防止 OpenBLAS 线程冲突导致死机
os.environ["OMP_NUM_THREADS"] = "1"
os.environ["MKL_NUM_THREADS"] = "1"
import torch
import json
from transformers import AutoTokenizer, AutoModelForCausalLM
from modelscope import snapshot_download
# ==========================================
# 2. 加载模型 (自动获取路径)
# ==========================================
print("\n🔍 正在准备模型...")
# 这一步很快,因为硬盘里的模型文件还在,不需要重新下载 15GB
model_dir = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct', cache_dir='./models', revision='master')
if 'model' not in globals() or 'tokenizer' not in globals():
print("🚀 正在加载模型到 NPU...")
tokenizer = AutoTokenizer.from_pretrained(model_dir)
# 关键修复:设置 Pad Token,防止报错
tokenizer.pad_token_id = tokenizer.eos_token_id
tokenizer.padding_side = 'left'
model = AutoModelForCausalLM.from_pretrained(
model_dir,
torch_dtype=torch.float16,
device_map="npu"
).eval()
print("✅ 模型加载完毕!")
else:
print("✅ 模型已在内存中,直接使用!")
# ==========================================
# 3. 实战案例:非结构化数据 ETL (文本转 JSON)
# ==========================================
# 模拟杂乱的输入数据
raw_data_inputs = [
# 案例 1:杂乱的医疗记录
"""
患者张伟,男,45岁。昨日夜间出现急性腹痛,位置在右下腹。
体温38.5度,伴有恶心呕吐。白细胞计数12000。
既往有高血压病史,长期服用硝苯地平。
初步诊断为急性阑尾炎,建议立即手术。
""",
# 案例 2:非标准的求职简历
"""
我是李娜,2020年毕业于北京大学计算机系硕士。
之前在字节跳动工作了3年,担任高级算法工程师。
精通Python, PyTorch, C++。
期望薪资是50k,希望能去上海发展。
邮箱:lina_code@example.com
"""
]
print(f"\n📂 准备处理 {len(raw_data_inputs)} 条非结构化文本...\n")
# 定义 System Prompt (强制 JSON 输出)
system_instruction = """
你是一个专业的数据结构化助手。
请从用户的输入文本中提取关键实体信息,并严格以 JSON 格式输出。
不要包含任何多余的解释文字,只输出 JSON。
如果是医疗文本,提取:{姓名, 年龄, 症状, 诊断, 建议}
如果是简历文本,提取:{姓名, 学历, 技能, 期望薪资, 联系方式}
"""
# 开始抽取
for i, text in enumerate(raw_data_inputs):
print(f"🔍 正在抽取第 {i+1} 条数据...")
# 构造 Prompt
text_input = tokenizer.apply_chat_template(
[{"role": "system", "content": system_instruction},
{"role": "user", "content": text}],
tokenize=False,
add_generation_prompt=True
)
# 转换为 Tensor
inputs = tokenizer(text_input, return_tensors="pt").to("npu")
# 推理
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=256,
do_sample=False, # 关闭随机采样,保证 JSON 格式稳定
temperature=0.1
)
# 解码
response = tokenizer.decode(outputs[0][inputs.input_ids.shape[1]:], skip_special_tokens=True)
# 打印结果
print("-" * 40)
print(f"📄 [原始文本]:\n{text.strip()}")
print(f"\n🧩 [结构化 JSON 输出]:")
print(response.strip())
print("-" * 40 + "\n")
print("✅ 数据结构化任务完成!")
输出结果:
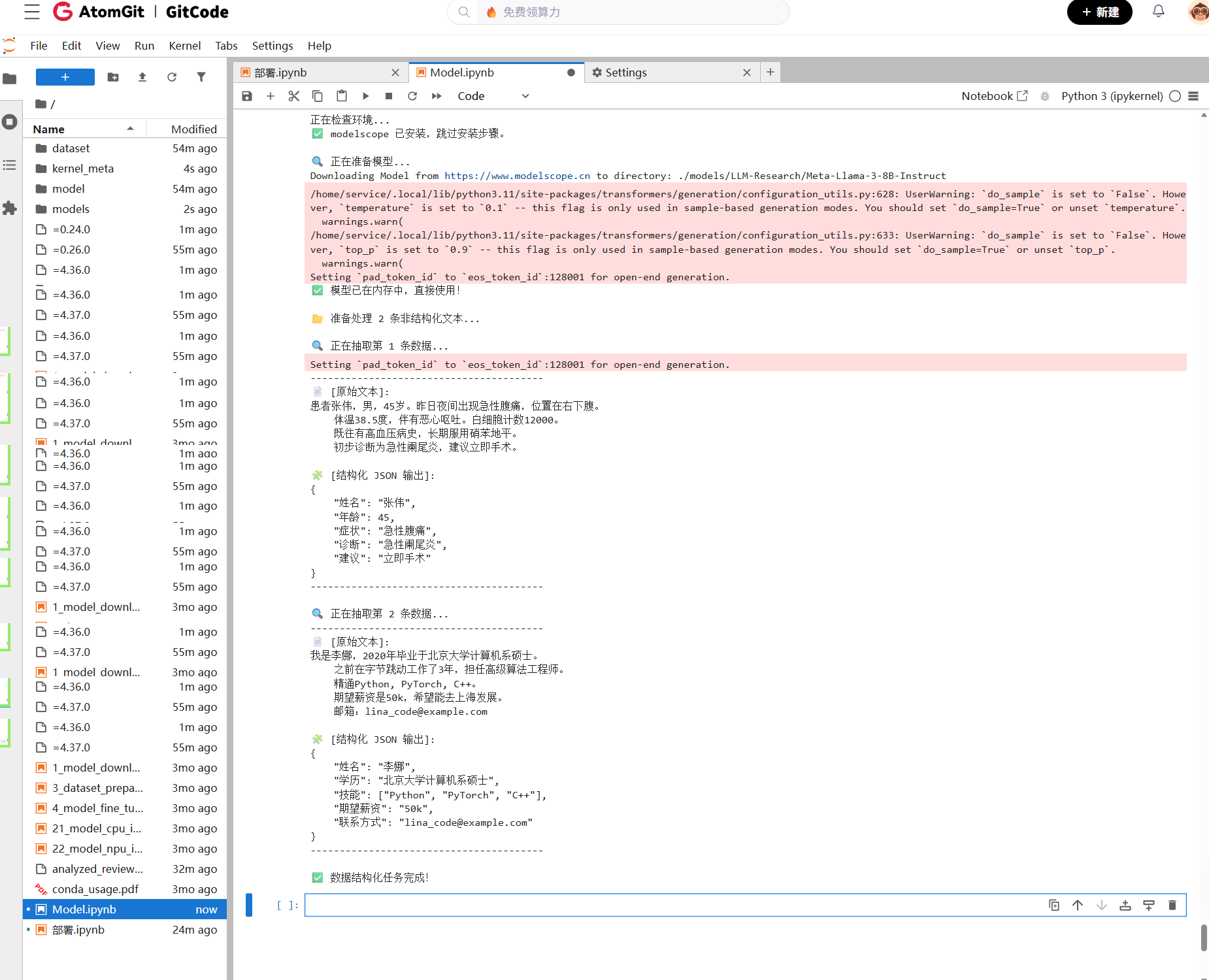
结果表明,模型具备极强的 Schema 感知能力,能够准确提取实体并忽略噪声信息,可作为企业级 ETL 管道的核心组件。
3.2.3 监控和调试实践
# 性能监控脚本
import time
import psutil
import torch_npu
def monitor_performance():
# 监控NPU使用率
npu_info = torch.npu.utilization()
# 监控内存使用
memory_info = psutil.virtual_memory()
# 监控温度
temperature = psutil.sensors_temperatures()
return {
'npu_utilization': npu_info,
'memory_usage': memory_info.percent,
'temperature': temperature
}
结语
本文从环境部署、模型加载、常见问题到调试方法,提供了一套可直接复制到生产环境的昇腾大模型(Llama)部署流程。实际部署中最常见的问题集中在版本兼容、显存管理和性能优化方面,建议将“最小化验证 + 逐模块排查”作为核心调试思路,以便及时发现问题根源并快速修复。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 16
16 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)