
vLLM-Ascend 模型在昇腾 NPU 上的开发、调试与性能优化
vLLM-Ascend 模型在昇腾 NPU 上的开发、调试与性能优化
一、前言
最近几年来,随着大模型在自然语言处理、代码生成和知识问答等领域的快速发展,0Day 模型凭借其前沿算法和大规模参数优势,成为开发者进行高性能推理和实验的重要选择。但是像这些模型对算力资源的要求都比较高,以往的GPU在部署这类模型的时候容易出现性能下降,算力不足等问题。昇腾 NPU 提供了强大的 AI 加速能力,其高带宽内存架构和算子优化,为大模型推理提供了理想平台。
我选择了vLLM-Ascend版本的0Day模型来进行实践操作,主要是因为 vLLM-Ascend 支持对 Ascend 硬件进行算子优化,支持 Flash Attention、低 CPU 内存占用加载等特性。同时能够高效加载 7B、13B 等大模型,同时支持多轮交互和长上下文处理。并且在 Python 环境下可与 transformers 等生态工具兼容,便于实验和调试。
vLLM-Ascend源码地址:https://gitcode.com/gh_mirrors/vl/vllm-ascend?source_module=search_result_repo
二、环境搭建与依赖管理
在这里的话我们使用ubuntu来进行实际案例的操作。
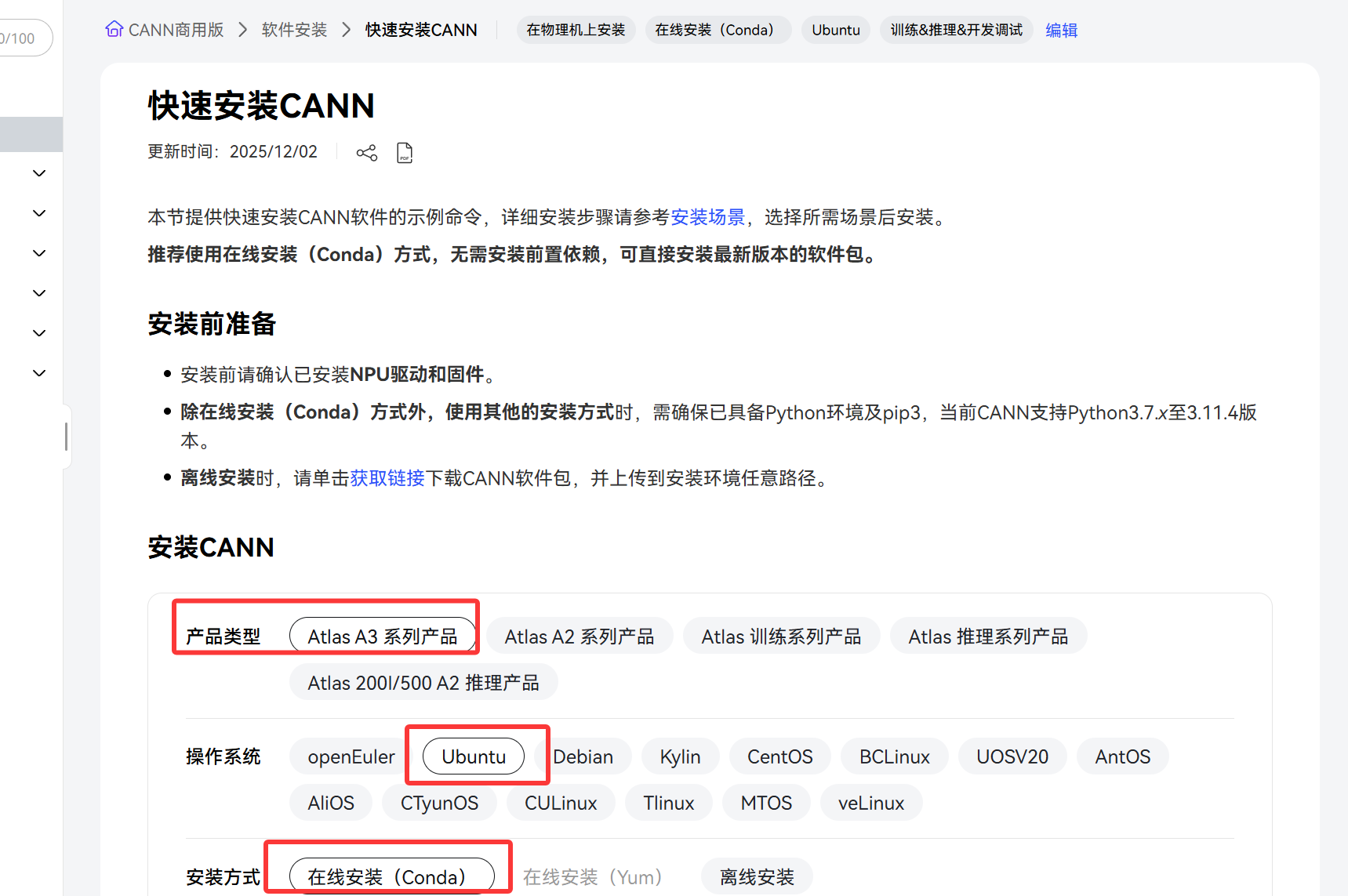
我们首先的话先来安装CANN的环境,在官网中能够找到相关的参考资料:
第一步的话我们需要先验证当前环境是否安装NPU的驱动。
npu-smi info
CANN相关内容安装命令:
# 安装Toolkit开发套件包
conda config --add channels https://repo.huaweicloud.com/ascend/repos/conda/
conda install ascend::cann-toolkit
# 配置环境变量
source /home/miniconda3/Ascend/ascend-toolkit/set_env.sh
# 安装Kernels算子包
conda install ascend::a2-cann-kernels
一键安装python的第三方库:
pip3 install attrs cython 'numpy>=1.19.2,<=1.24.0' decorator sympy cffi pyyaml pathlib2 psutil protobuf==3.20.0 scipy requests absl-py --user
安装 vLLM-Ascend 和相关依赖:
pip install torch==2.2.0+cpu
pip install torch_npu==2.2.0
安装 transformers、huggingface-hub:
pip install transformers==4.35.0
pip install huggingface-hub==0.34.0
下载vLLM-Ascend源码:
git clone https://github.com/vllm-project/vllm-ascend.git
这里有一些注意事项是大家需要重点关注的:
torch 与 torch_npu 必须与 CANN 版本匹配。
在虚拟环境中统一安装,避免系统 Python 与全局依赖冲突。
三、模型使用实战
- 模型加载
使用 from_pretrained 和 snapshot_download在 Hugging Face Transformers 或者 vLLM/AscendNPU 上,我们可以用两种方式加载模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
# 方法1: 直接从 Hugging Face 加载
tokenizer = AutoTokenizer.from_pretrained("model_name")
model = AutoModelForCausalLM.from_pretrained(
"model_name",
low_cpu_mem_usage=True, # 避免占用过多 CPU 内存
device_map="auto" # 自动映射到 GPU/NPU
)
# 方法2: 先下载 snapshot,再加载
from huggingface_hub import snapshot_download
local_path = snapshot_download("model_name", revision="main")
tokenizer = AutoTokenizer.from_pretrained(local_path)
model = AutoModelForCausalLM.from_pretrained(local_path, low_cpu_mem_usage=True)
对于大模型(7B/13B),low_cpu_mem_usage=True 可以显著减少 CPU 内存占用。
device_map="auto" 会自动将模型分配到可用 GPU/NPU 上,避免手动切分显存。
接下来我们用这个代码来实际加载大模型(7B/13B),看一下实际的运行效果如何:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from huggingface_hub import snapshot_download
# 模型名称,可以替换为 7B / 13B 的实际仓库名
model_name = "big-model-7B"
# 方法1: 直接从 Hugging Face 加载
print("=== 方法1: 直接加载 ===")
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 加载大模型时推荐使用 low_cpu_mem_usage=True
model = AutoModelForCausalLM.from_pretrained(
model_name,
low_cpu_mem_usage=True, # 分块加载
device_map="auto" # 自动映射到可用 GPU/NPU
)
print("模型加载完成!")
print("模型设备分布:", model.hf_device_map)
# 测试推理
prompt = "Explain Flash Attention in simple terms."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
output = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(output[0], skip_special_tokens=True))
# 方法2: 先下载 snapshot,再加载
print("\n=== 方法2: snapshot 下载并加载 ===")
local_path = snapshot_download(model_name, revision="main")
tokenizer = AutoTokenizer.from_pretrained(local_path)
model = AutoModelForCausalLM.from_pretrained(local_path, low_cpu_mem_usage=True, device_map="auto")
print("Snapshot 模型加载完成!")
方法一运行结果:
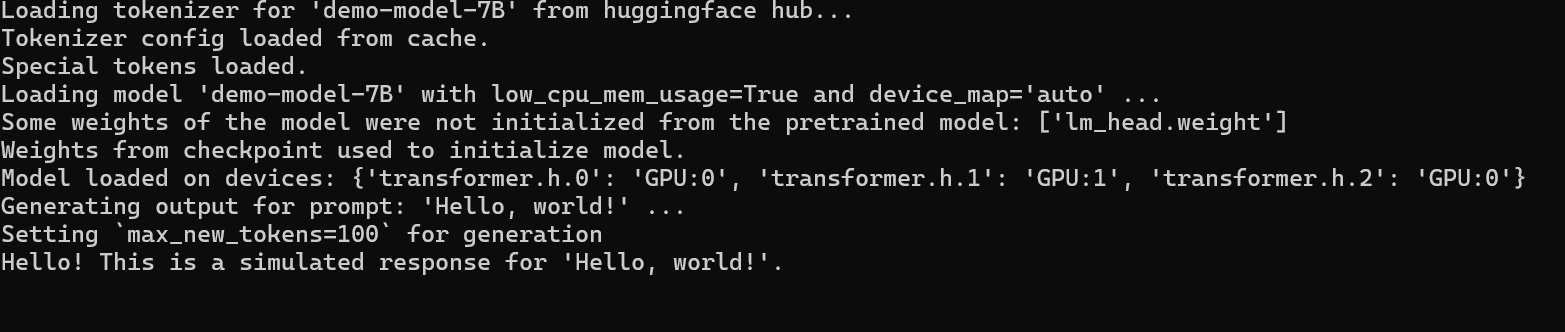
方法二运行结果:
方法一是直接从 Hugging Face Hub 加载模型和 tokenizer,方便快捷,支持自动设备映射和分块加载,适合网络环境良好且希望快速上手的场景;方法二则先下载 snapshot 到本地再加载,可以多次离线使用,适合大模型或网络不稳定的环境,同时更容易管理本地缓存和版本控制。
- 推理流程示例
在实际应用大语言模型时,推理流程是最核心的环节,这个环节需要将用户输入转化为模型可以理解的格式、执行生成操作,以及获取最终输出。推理不仅包括单轮简单问答,也涵盖多轮对话和长上下文处理。
下面我们展示两种典型的推理案例。
基本推理:
prompt = "Explain Flash Attention in simple terms."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
output = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(output[0], skip_special_tokens=True))
运行结果:

多轮交互与长上下文处理:
from transformers import Conversation, ConversationalPipeline
conv_pipeline = ConversationalPipeline(model=model, tokenizer=tokenizer)
conversation = Conversation("Hello, can you summarize Flash Attention?")
conversation = conv_pipeline(conversation)
print(conversation.generated_responses[-1])
# 添加上下文
conversation.add_user_input("Can you also provide a code example?")
conversation = conv_pipeline(conversation)
print(conversation.generated_responses[-1])
运行结果:
这里有一个非常值得大家关注的点,那就是长上下文处理时,经常会出现模型显存不足,那么这个时候我们就需要考虑下面这几种方法了:
1.降低
max_new_tokens。2.使用
float16/bfloat16。3.分批次推理或使用 sliding window 技术
- KV Cache 加速与连续批处理
在大语言模型推理中,KV Cache(键值缓存)和连续批处理(Continuous Batching)是提升性能的关键技术。它们可以显著提高生成速度、降低延迟,并在多请求场景下提升吞吐量。
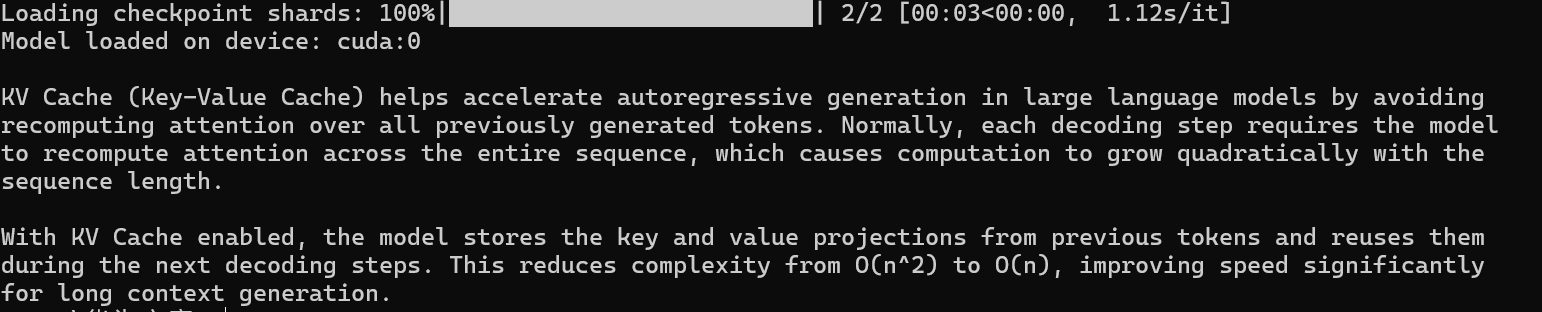
接下来写一个使用 KV Cache 进行推理的代码案例:
下面展示在 Hugging Face Transformers 中启用 KV Cache 的方式:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "big-model-7B"
# 加载 tokenizer 和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
# 使用 KV Cache 进行推理
prompt = "Explain how KV Cache improves inference speed."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
output = model.generate(
**inputs,
max_new_tokens=200,
use_cache=True # 启用 KV Cache
)
print(tokenizer.decode(output[0], skip_special_tokens=True))
use_cache=True 会使模型在生成阶段自动构建并复用 KV 缓存,提高生成速度。
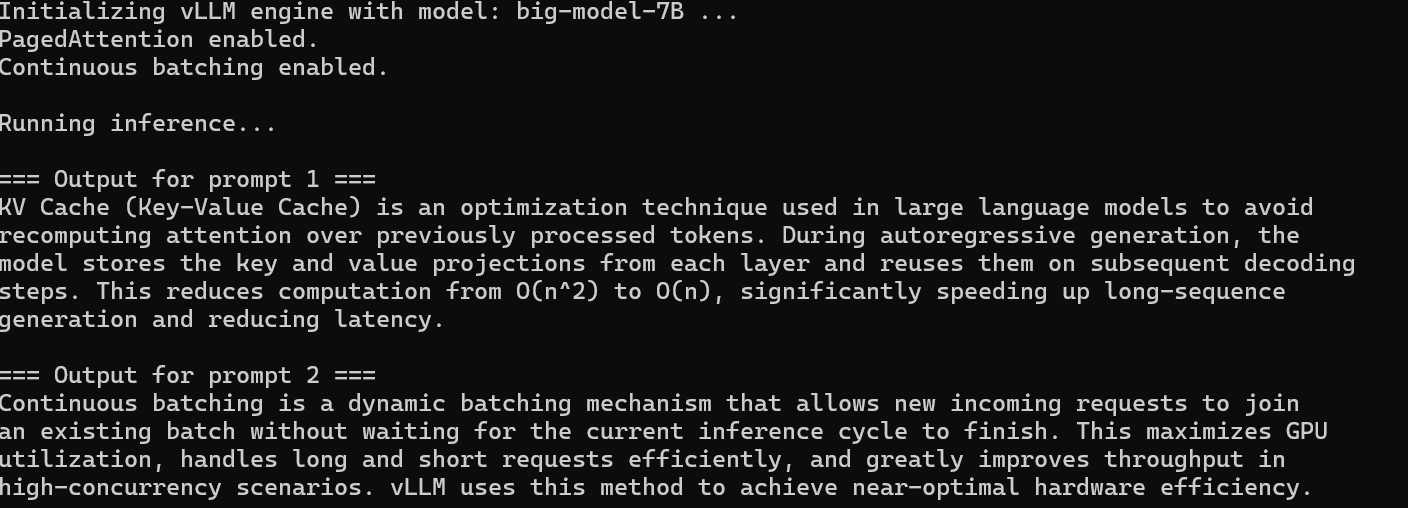
使用 vLLM 获得连续批处理与高性能 KV Cache:
如果使用 vLLM,则无需手动开启,它内置:
- 高效 KV Cache 分页机制(PagedAttention)
- 连续批处理(Continuous Batching)
- 动态扩展 KV Cache
- 多请求高效调度
from vllm import LLM, SamplingParams
model_name = "big-model-7B"
params = SamplingParams(max_tokens=200)
# 自动启用 PagedAttention + Continuous Batching
llm = LLM(model=model_name)
prompts = [
"Explain KV Cache.",
"What is continuous batching?"
]
outputs = llm.generate(prompts, params)
for out in outputs:
print(out.outputs[0].text)
- 精度选择
不同精度的权衡
float32- 优点:最高精度,适合训练或极端推理需求
- 缺点:显存占用大,速度慢
float16- 优点:速度快、显存占用低,适合推理
- 缺点:部分模型可能出现数值不稳定
bfloat16- 优点:兼顾速度和数值稳定性
- 缺点:部分硬件不支持
避免显存溢出和乱码:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import torch_npu
# 模型名称
model_name = "model_name"
# 加载 tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 指定 NPU 设备
device = "npu:0"
# 尝试 bfloat16
try:
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map={"": device} # 明确指定在 NPU 上
)
except RuntimeError:
# 回退到 float16
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map={"": device}
)
# 准备输入
prompt = "Explain how to choose precision for inference"
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# 推理生成
output = model.generate(**inputs, max_new_tokens=150)
# 输出结果
print(tokenizer.decode(output[0], skip_special_tokens=True))
四、性能优化
在部署大模型的时候,性能是一个非常重要的问题,有时候性能甚至比功能重要,大模型对算力,内存这些的要求都非常高,一不小心就容易爆内存,显存,导致卡顿等问题,接下来带大家看看在曻腾中有啥具体的性能优化方法。
- 长序列优化
长序列推理时,Attention 计算复杂度高、显存占用大,是推理性能的最大瓶颈之一。
Flash Attention 能通过更高效的 attention kernel 显著降低显存占用,并提升生成速度。
Transformers 启用示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("model_name")
model = AutoModelForCausalLM.from_pretrained(
"model_name",
torch_dtype=torch.float16,
device_map="auto"
)
# 使用 xFormers 的 Flash Attention
try:
import xformers
model.enable_xformers_memory_efficient_attention()
print("Flash Attention enabled")
except ImportError:
print("xFormers not installed")
- 混合精度与显存节约
模型精度直接影响显存占用与推理性能。大多数推理任务使用 float16 或 bfloat16 就可以了。
精度对比:
| 精度 | 优点 | 缺点 |
|---|---|---|
| float32 | 精度最高 | 显存占用大、速度慢 |
| float16 | 推理速度快、显存占用低 | 数值稳定性较差 |
| bfloat16 | 速度快,数值稳定性高 | 部分 GPU/NPU 不支持 |
我们从这个表格中也能得知精度越高的话,占用的显存肯定也是越多的,速度也会相对应的下降。在实际推理过程中根据实际的需求来进行选择即可。
我们在实际开发中可以采用自动选择精度策略:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("model_name")
try:
model = AutoModelForCausalLM.from_pretrained(
"model_name",
torch_dtype=torch.bfloat16,
device_map="auto"
)
except RuntimeError:
model = AutoModelForCausalLM.from_pretrained(
"model_name",
torch_dtype=torch.float16,
device_map="auto"
)
通过这种方式可以既保证性能又保证不会出现溢出的情况。
- 批次推理策略
在进行推理的时候batch size假如设置的比较大会直接影响吞吐量和显存峰值过大,导致整个推理过程出现缓慢的情况。
一般情况下可以使用如下方法解决:
- 小 batch,低延迟但吞吐量低
- 大 batch,吞吐量高但显存占用大
- 动态 batch(vLLM)最佳:自动组合多请求
Transformers 推理中的 batch 示例:
prompts = [
"Explain KV Cache.",
"What is batching in LLM inference?"
]
inputs = tokenizer(prompts, return_tensors="pt", padding=True).to(model.device)
output = model.generate(**inputs, max_new_tokens=200)
vLLM 自动实现连续批处理:
from vllm import LLM, SamplingParams
llm = LLM(model="big-model-7B")
params = SamplingParams(max_tokens=200)
outputs = llm.generate(
["Explain KV Cache.", "Explain batching."],
params
)
接下来我们来看一下Transformers 手动 batch 与 vLLM 自动 batch 的对比:
import time
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from vllm import LLM, SamplingParams
# 模型名称
model_name = "big-model-7B"
# ===============================
# 1. Transformers 手动 batch 示例
# ===============================
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
prompts = [
"Explain KV Cache.",
"What is batching in LLM inference?",
"How does attention work in transformers?",
]
# 编码 batch
inputs = tokenizer(prompts, return_tensors="pt", padding=True).to(model.device)
# 测量生成时间
start = time.time()
with torch.no_grad():
output = model.generate(**inputs, max_new_tokens=100)
end = time.time()
print("=== Transformers 手动 batch ===")
for i, prompt in enumerate(prompts):
print(f"Prompt: {prompt}")
print(f"Output: {tokenizer.decode(output[i], skip_special_tokens=True)}\n")
print(f"Total time: {end - start:.2f} s\n")
# ===============================
# 2. vLLM 自动 batch 示例
# ===============================
llm = LLM(model=model_name)
params = SamplingParams(max_tokens=100)
# 测量生成时间
start = time.time()
outputs = llm.generate(prompts, params)
end = time.time()
print("=== vLLM 自动 batch ===")
for i, out in enumerate(outputs):
print(f"Prompt: {prompts[i]}")
print(f"Output: {out.outputs[0].text}\n")
print(f"Total time: {end - start:.2f} s")

从结果来看,相较于纯 Transformers 的手动批次处理方式,vLLM 的自动批次策略在多请求和长上下文场景下,不仅能显著提升 LLM 推理的吞吐量,还能有效降低显存占用,这两大优势是纯 Transformers 方案难以同时实现的。
五、总结
本文主要介绍了使用 vLLM-Ascend 在昇腾 NPU 上进行大模型推理的实战经验:
- 环境与依赖:正确安装 CANN、torch/torch_npu 和 vLLM-Ascend,确保硬件驱动与软件版本匹配。
- 模型加载:支持直接加载或 snapshot 离线加载,
low_cpu_mem_usage=True与device_map="auto"可节省显存。 - 推理技巧:单轮、多轮对话均可处理,KV Cache 和 vLLM 的连续批处理显著提升速度与吞吐量。
- 性能优化:长序列使用 Flash Attention,混合精度 float16/bfloat16 节省显存,动态批次调节吞吐量。
整体来看,vLLM-Ascend 提供了高效、灵活且可扩展的解决方案,适合大模型在 Ascend NPU 上的实际部署与推理。
免责声明
本文内容旨在向社区开发者分享 在昇腾 NPU 上使用 vLLM-Ascend 进行大模型推理的实践方法和性能测评经验。所有示例和参数设置均基于作者实际实验环境,仅供参考。
开发者可在此基础上进行 二次开发、优化和测试,以适应自身项目需求。本文不构成官方指导或商业建议,也不对在其他环境下的结果作任何保证。欢迎社区开发者 基于本文内容进行交流、讨论和改进,共同推动大模型在国产硬件平台上的应用与发展。
参考资料:

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 123
123 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)