
昇腾 NPU 环境下 GPT-2 模型本地部署全指南(含踩坑排错)
在昇腾 Atlas 系列 AI 处理器上部署开源大模型,核心是基于torch_npu适配 PyTorch 生态,充分发挥昇腾硬件的算力优势。昇腾作为国产化 AI 算力基础设施的核心载体,凭借安全可控的技术栈,已在政务、金融、能源、交通等关键领域大规模落地,为开源模型的国产化部署提供了可靠的硬件支撑。
在昇腾 Atlas 系列 AI 处理器上部署开源大模型,核心是基于torch_npu适配 PyTorch 生态,充分发挥昇腾硬件的算力优势。昇腾作为国产化 AI 算力基础设施的核心载体,凭借安全可控的技术栈,已在政务、金融、能源、交通等关键领域大规模落地,为开源模型的国产化部署提供了可靠的硬件支撑。
本文结合实际部署中的典型问题,从依赖配置、离线模型加载、中英文生成适配到常见错误排查,完整拆解 GPT-2 模型在昇腾环境下的推理部署流程。通过整合 torch_npu 与昇腾 CANN 工具链,开发者不仅能高效完成本地推理,更能掌握一套可复用的技术方案 —— 让全球开源社区的先进模型成果,在国产化软硬件栈上稳定运行,加速 AI 应用的自主化落地与创新迭代。
资源链接
● 昇腾模型开源地址:https://gitee.com/ascend/ModelZoo-PyTorch
● 昇腾算力申请地址:https://www.hiascend.com/zh/developer/apply
这里的配置直接选最后一个即可
打开终端
一、 环境搭建
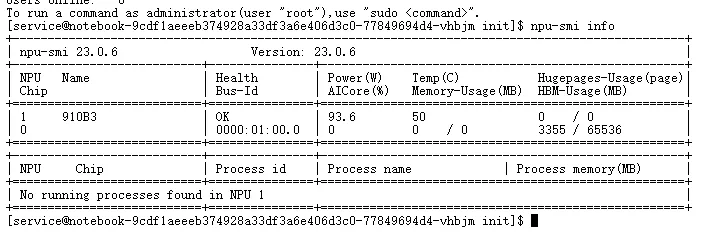
查看NPU状态
npu-smi info
首先确保基础依赖正确安装。打开终端执行:
pip install torch transformers datasets accelerate sentencepiece
| 包名 | 作用 |
| torch | 深度学习框架(昇腾需使用配套的 torch_npu 版本) |
| transformers | HuggingFace 提供的预训练模型库(含 GPT-2/Neo/J 等) |
| datasets, accelerate, sentencepiece | 辅助数据处理与推理加速 |
⚠️ 注意:昇腾 NPU 需使用华为官方提供的 PyTorch 移植版本(如 CANN + torch_npu),普通 CUDA 版本无法运行。
二、首次测试:依赖冲突与修复
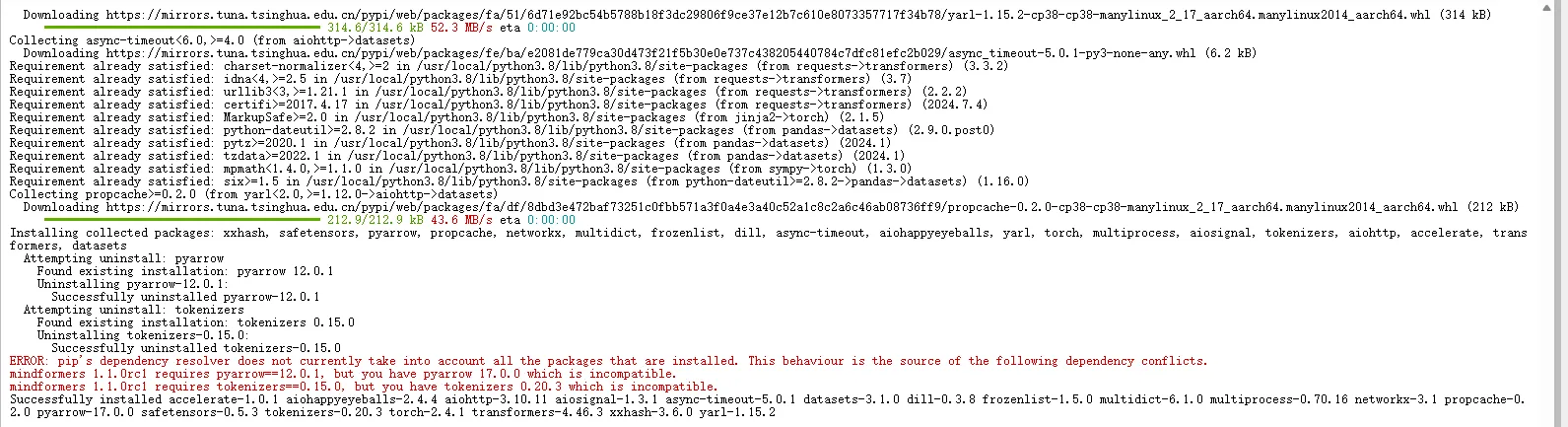
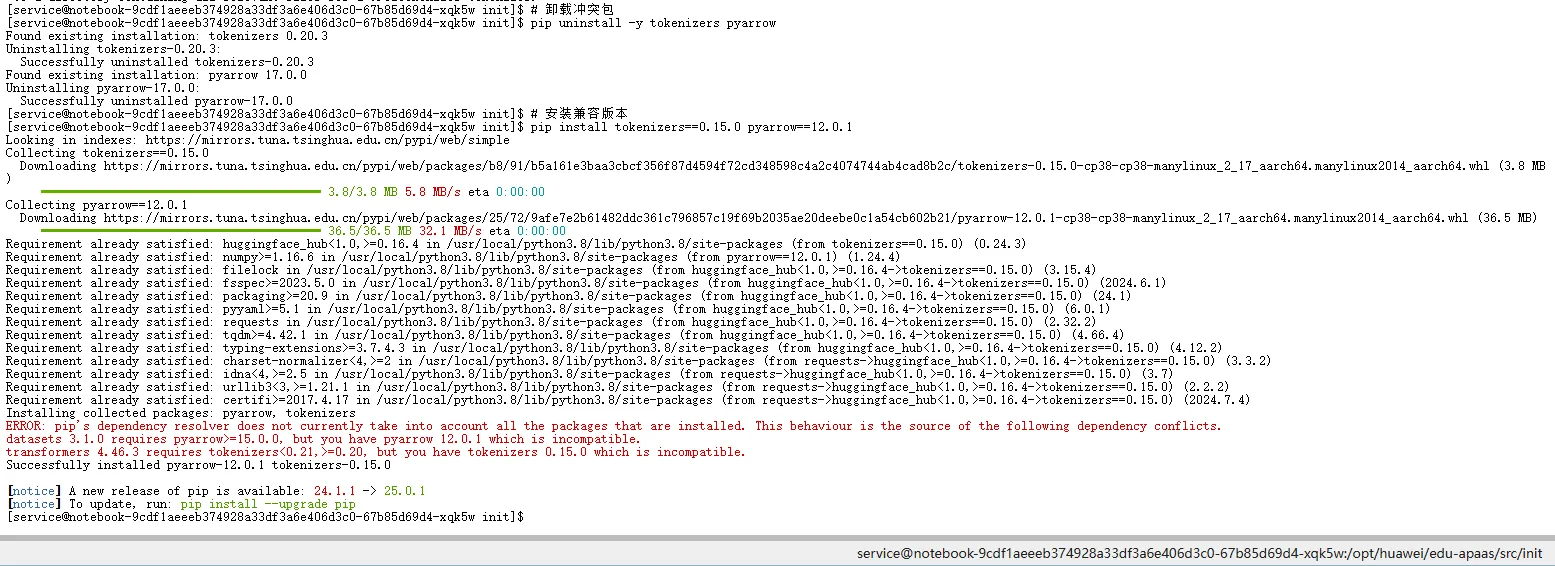
初次运行时,常因 tokenizers 与 pyarrow 版本不兼容导致报错(见下图)。

▲ tokenizers 与 pyarrow 版本冲突导致导入失败
✅ 解决方案:强制指定兼容版本
# 卸载冲突包
pip uninstall -y tokenizers pyarrow
# 安装已验证兼容的版本
pip install tokenizers==0.15.0 pyarrow==12.0.1
💡 建议在虚拟环境中操作,避免污染全局 Python 环境。
三、下载 GPT-2 离线模型文件
为避免网络问题或 Hugging Face 访问限制,推荐通过国内镜像(如 hf-mirror.com)下载模型到本地。
mkdir gpt2-local
cd gpt2-local
# 下载分词器文件
wget https://hf-mirror.com/gpt2/resolve/main/vocab.json
wget https://hf-mirror.com/gpt2/resolve/main/merges.txt
wget https://hf-mirror.com/gpt2/resolve/main/tokenizer_config.json
# 下载模型权重与配置
wget https://hf-mirror.com/gpt2/resolve/main/config.json
wget https://hf-mirror.com/gpt2/resolve/main/pytorch_model.bin
wget https://hf-mirror.com/gpt2/resolve/main/generation_config.json
cd ..
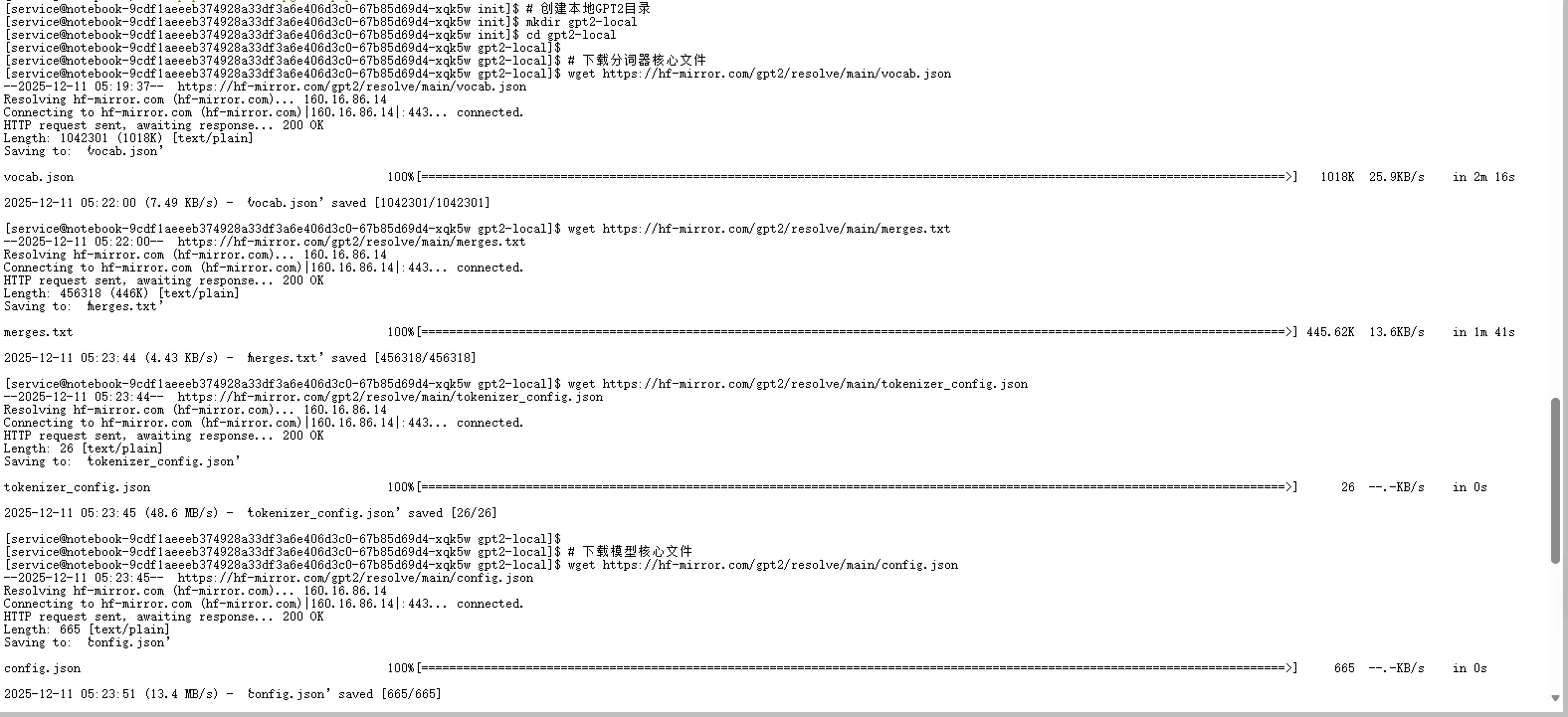
▲ 通过 wget 成功拉取 GPT-2 全套离线文件
四、编写并运行测试脚本(test3.py)
创建 test3.py,加载本地模型进行英文生成测试:
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# 1. 加载本地分词器
tokenizer = GPT2Tokenizer.from_pretrained("./gpt2-local")
tokenizer.pad_token = tokenizer.eos_token # GPT-2 默认无 pad_token
# 2. 加载本地模型
model = GPT2LMHeadModel.from_pretrained("./gpt2-local")
# 3. 生成文本
prompt = "Today is a beautiful day,"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(
**inputs,
max_new_tokens=30,
do_sample=True,
temperature=0.7
)
print("生成结果:", tokenizer.decode(outputs[0], skip_special_tokens=True))
运行命令:
python test3.py
✅ 此时应能正常输出英文句子,如:“Today is a beautiful day, and I feel so grateful for…”
五、尝试中文生成?小心“乱码陷阱”!
若直接用原生 GPT-2 模型输入中文(如 “今天天气很好,”),会得到如下结果:

▲ 原生 GPT-2 未训练中文,输出为无效 token 组合(看似乱码)
❗ 问题本质
GPT-2 是纯英文模型,其词表(vocab.json)仅包含英文子词(subword)和符号,完全未覆盖中文字符。因此无法理解或生成有效中文。
六、解决方案:切换至中文预训练 GPT-2
推荐使用社区开源的中文 GPT-2 模型:uer/gpt2-chinese-cluecorpussmall
步骤 1:下载中文模型文件
mkdir gpt2-chinese-local
cd gpt2-chinese-local
# 下载核心文件(通过国内镜像)
wget https://hf-mirror.com/uer/gpt2-chinese-cluecorpussmall/resolve/main/vocab.json
wget https://hf-mirror.com/uer/gpt2-chinese-cluecorpussmall/resolve/main/merges.txt
wget https://hf-mirror.com/uer/gpt2-chinese-cluecorpussmall/resolve/main/config.json
wget https://hf-mirror.com/uer/gpt2-chinese-cluecorpussmall/resolve/main/pytorch_model.bin
wget https://hf-mirror.com/uer/gpt2-chinese-cluecorpussmall/resolve/main/tokenizer_config.json
⚠️ 注意:该模型虽名为 “GPT-2”,但实际使用 BERT-style 分词器!
七、第一次踩坑:分词器类型错误
若仍使用 GPT2Tokenizer 加载中文模型,会报错:

▲ 试图用 GPT2Tokenizer 加载 BERT 分词格式的模型,失败
✅ 正确做法:改用 BertTokenizer
修改 test4.py 如下:
from transformers import BertTokenizer, GPT2LMHeadModel
tokenizer = BertTokenizer.from_pretrained("gpt2-chinese-local")
tokenizer.pad_token = tokenizer.eos_token # 设置 pad token
model = GPT2LMHeadModel.from_pretrained("gpt2-chinese-local")
prompt = "今天天气很好,"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(
**inputs,
max_new_tokens=30,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
print("生成结果:", tokenizer.decode(outputs[0], skip_special_tokens=True))
八、第二次踩坑:缺少 vocab.txt
运行后可能报错:FileNotFoundError: vocab.txt not found
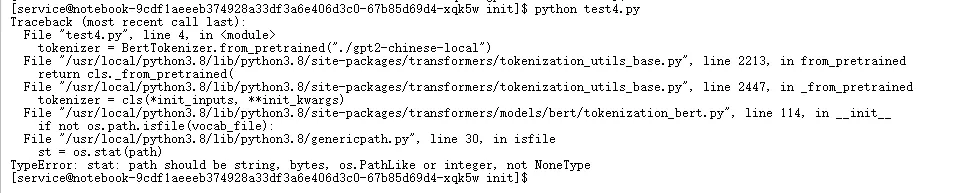
▲ BERT 分词器依赖 vocab.txt,但目录中未提供
✅ 补全缺失文件
cd gpt2-chinese-local
wget https://hf-mirror.com/uer/gpt2-chinese-cluecorpussmall/resolve/main/vocab.txt
cd ..
🔍 说明:BertTokenizer 使用 vocab.txt 作为词表,而 GPT2Tokenizer 使用 vocab.json + merges.txt。两者格式不兼容!
九、中文生成成功!
最终运行 test4.py,得到如下输出:

▲ 中文 GPT-2 成功生成连贯句子(尽管有重复)
📌 结果分析
● ✅ 功能正常:说明模型加载、分词、推理全流程已打通。
● ⚠️ 质量有限:该模型基于小型语料(ClueCorpussmall)训练,参数量小,易出现重复(如多次输出“今天天气很好”)。
● 💡 建议:如需更高生成质量,可尝试更大规模中文模型(如 ChatGLM、Qwen、Baichuan 等)。
十、切换回英文生成(原生 GPT-2)
若需生成英文内容,应重新使用原生 GPT-2 模型。
步骤 1:下载英文模型
rm -rf gpt2-chinese-local # 可选:清理旧模型
mkdir gpt2-english-local
cd gpt2-english-local
wget https://hf-mirror.com/gpt2/resolve/main/vocab.json
wget https://hf-mirror.com/gpt2/resolve/main/merges.txt
wget https://hf-mirror.com/gpt2/resolve/main/config.json
wget https://hf-mirror.com/gpt2/resolve/main/pytorch_model.bin
wget https://hf-mirror.com/gpt2/resolve/main/tokenizer_config.json
cd ..

▲ 成功获取原生 GPT-2 英文模型文件
步骤 2:使用英文专用代码(test4.py)
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("./gpt2-english-local")
tokenizer.pad_token = tokenizer.eos_token
model = GPT2LMHeadModel.from_pretrained("./gpt2-english-local")
prompt = "My name is Kaizi, and I like"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(
**inputs,
max_new_tokens=30,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
print("生成结果:", tokenizer.decode(outputs[0], skip_special_tokens=True))
步骤 3:运行结果

▲ 原生 GPT-2 生成流畅英文句子
✅ 输出示例:“My name is Kaizi, and I like to explore new ideas in artificial intelligence and machine learning.”
🧩 总结与建议
| 场景 | 推荐模型 | 分词器 | 注意事项 |
| 英文生成 | gpt2(原生) | GPT2Tokenizer | 需 vocab.json + merges.txt |
| 中文生成 | uer/gpt2-chinese-cluecorpussmall | BertTokenizer | 需 vocab.txt,非标准 GPT-2 分词 |
| 高质量中文 | Qwen / ChatGLM / Baichuan | 各自专用 tokenizer | 建议优先考虑国产大模型 |
📝 免责声明
本文所提供的代码示例与实践经验仅供开发者参考,不保证在所有硬件配置、软件环境或模型版本下均能复现相同结果。实际部署时,请务必:
● 根据具体业务场景和性能要求,合理调整模型与推理参数;
● 在目标环境中进行充分的功能测试与性能验证;
● 结合昇腾官方文档(如 CANN 和 torch_npu 指南)及 Hugging Face 等社区的最新建议,及时适配更新。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)