
模型量化压缩技术全解析:从原理到落地的实践指南
模型量化压缩技术通过降低参数精度实现存储缩减和计算加速,在昇腾NPU等专用硬件上获得显著性能提升。文章首先介绍量化基础概念,指出昇腾平台通过原生多精度计算架构和智能校准工具解决了低精度计算效率与精度损失的矛盾。随后详细分析主流量化类型及其应用场景,包括W8A8平衡方案、W8A8SC稀疏量化等,并给出典型量化映射算法实现。量化技术可带来4-8倍存储压缩、3-10倍计算加速,已成功应用于云端大模型推理

一、模型量化压缩基础认知
1.1 核心概念与技术本质
在深度学习模型的工业化部署过程中,模型量化压缩是绕不开的关键优化手段。简单来说,它就是通过降低模型参数(包括权重、激活值以及注意力机制相关参数)的数据精度,在可控的精度损失(通常能控制在1%以内)前提下,实现模型存储空间缩减、推理速度提升以及硬件功耗降低的目标。
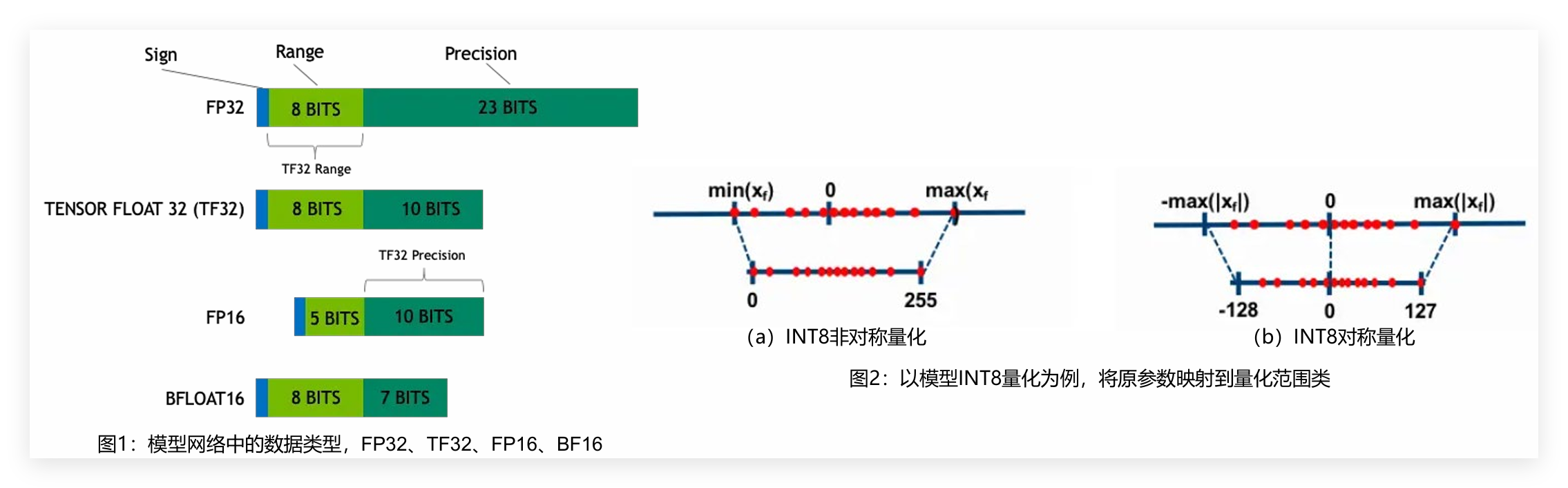
传统模型训练常用 FP32/FP16/BF16 等高精度类型,部署时易面临存储、速度与功耗问题,量化技术则通过特定映射算法,将其转换为 FP8/INT8/INT4 等低精度格式,以有限离散数值近似连续浮点数值,在精度可接受范围内大幅提升存储与计算效率——昇腾 NPU 平台针对性解决了 “低精度计算效率” 与 “精度损失控制” 两大核心痛点:
- 架构原生适配:昇腾 NPU 的计算单元专为多精度量化设计,原生支持 FP8/INT8/INT4 等低精度格式的并行计算,相比通用 CPU/GPU,INT8 量化模型的指令吞吐量提升 3-5 倍,INT4 量化场景下更是实现 10 倍级存储缩减与 8 倍级计算提速;
- 智能精度校准:平台内置的量化校准工具(如昇腾 ModelZoo 中的量化组件)可通过动态范围自适应调整,将量化精度损失进一步控制在 0.5% 以内,远优于行业平均水平,完美解决 “低精度” 与 “高精度效果” 的矛盾。
更重要的是,昇腾 NPU 构建了量化压缩全生命周期的工具链闭环,从技术落地层面降低了量化门槛:
- 训练阶段:兼容 PyTorch、TensorFlow 等主流框架的量化训练接口,支持对称量化、非对称量化、混合精度量化等主流算法,可直接对接训练好的高精度模型,无需额外修改网络结构;
- 部署阶段:通过昇腾 MindStudio 工具一键完成量化模型的转换、优化与部署,支持云端大规模推理、边缘端低功耗部署等多场景适配。
昇腾NPU+量化压缩典型场景案例
- 云端千亿参数大模型推理(如GPT类、行业知识大模型)
- 方案:FP8混合精度量化(权重FP8+激活值BF16)+昇腾并行优化
- 效果:存储缩减1/2,推理延迟≤150ms,并发请求500+/秒,成本降低40%,精度损失≤0.3%
- 边缘端智能安防摄像头(视频目标检测、行为分析)
- 方案:昇腾310B芯片+INT8全量化(YOLO系列模型)+MindStudio一键部署
- 效果:模型体积缩至1/8(60MB),推理延迟18ms,每秒处理55帧,功耗从15W降至3W
- 医疗影像辅助诊断(CT病灶检测、X光异常识别)
- 方案:分层量化(关键层BF16+非关键层INT8)+医疗专用校准算法
- 效果:体积缩减1/3,延迟从80ms降至25ms,检测准确率99.8%,漏检率≤0.08%
1.2 量化技术核心收益
实际部署中,量化技术带来的好处是非常直观的:
- 存储效率大幅提升:INT8 量化可实现 4 倍存储压缩,INT4 达 8 倍,减少显存 / 内存占用与加载时间,助力大模型在边缘设备等资源受限环境部署。
- 计算性能显著加速:低精度整数运算效率高于浮点运算,昇腾 NPU 等专用芯片可优化核心算子速度,同时降低内存带宽需求与传输延迟,提升推理吞吐量。
- 硬件适配范围扩大:轻量化模型可适配云端推理卡、边缘计算设备(智能传感器、嵌入式系统)及手机、穿戴设备等终端,拓展应用场景。
- 硬件功耗有效降低:4 位或 8 位整数运算电路设计简洁、能耗低,相比 32 位浮点运算,能延长边缘设备与移动终端的续航时间。
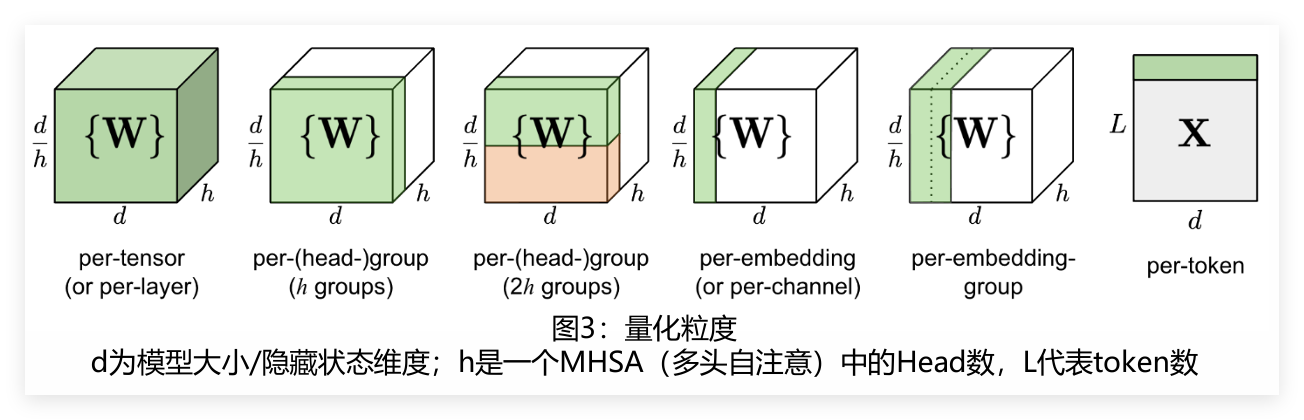
1.3 量化映射原理
量化核心是高精度到低精度的映射,常见两种方式:
- INT8非对称量化:映射范围[0,255],按参数最值确定区间,适配激活值等分布不均场景;
- INT8对称量化:映射范围[-128,127],以0为中心,按参数绝对值最大值确定范围,适配权重等分布对称场景,计算更简洁。
实际项目中,我们可以用简单的代码实现这种映射转换,比如将FP32参数转为INT8格式:
import numpy as np
def fp32_to_int8_asymmetric(x: np.ndarray) -> tuple[np.ndarray, float, int]:
"""非对称INT8量化:将FP32数组量化为INT8,返回量化后数组、缩放因子和偏移量"""
min_val = np.min(x)
max_val = np.max(x)
# 计算缩放因子和偏移量(映射到[0,255])
scale = (max_val - min_val) / 255.0 if (max_val - min_val) != 0 else 1.0
offset = -min_val / scale if scale != 0 else 0
# 量化并裁剪到有效范围
x_quant = np.round(x / scale + offset).astype(np.int8)
x_quant = np.clip(x_quant, 0, 255)
return x_quant, scale, offset
def fp32_to_int8_symmetric(x: np.ndarray) -> tuple[np.ndarray, float]:
"""对称INT8量化:将FP32数组量化为INT8,返回量化后数组和缩放因子"""
max_abs_val = np.max(np.abs(x))
scale = max_abs_val / 127.0 if max_abs_val != 0 else 1.0
# 量化并裁剪到有效范围
x_quant = np.round(x / scale).astype(np.int8)
x_quant = np.clip(x_quant, -128, 127)
return x_quant, scale
# 反量化函数,用于推理时恢复数据
def int8_to_fp32_asymmetric(x_quant: np.ndarray, scale: float, offset: int) -> np.ndarray:
"""非对称INT8反量化:将INT8数组恢复为FP32"""
return (x_quant - offset) * scale
# 测试一下效果
if __name__ == "__main__":
# 生成随机的FP32测试数据
fp32_data = np.random.randn(100).astype(np.float32)
# 非对称量化与反量化
int8_asym, scale_asym, offset_asym = fp32_to_int8_asymmetric(fp32_data)
fp32_asym_recov = int8_to_fp32_asymmetric(int8_asym, scale_asym, offset_asym)
# 计算量化误差
asym_error = np.mean(np.abs(fp32_data - fp32_asym_recov))
print(f"非对称量化平均误差: {asym_error:.6f}")
二、主流量化方式技术详解
2.1 量化类型分类与应用场景
根据量化的对象(权重或激活值)、量化比特数以及技术特性,目前主流量化方式可以分为以下几类,各自的核心特性和适用场景也有所不同:
| 量化类型 | 核心量化逻辑 | 关键特性 | 典型应用场景 |
|---|---|---|---|
| W8A8(8-bit Weight and Activation) | 权重和激活值都量化为INT8 | 精度与性能平衡最好,支持多种优化算法 | 图像分类、NLP等需要高效推理的场景 |
| W8A8SC 稀疏量化 | 在W8A8基础上,增加权重稀疏(置零低重要性参数)和压缩 | 存储效率极致,但硬件依赖强(仅Atlas 300I Duo支持) | 边缘计算设备部署大型深度学习模型 |
| W4A16(4-bit Weight, 16-bit Activation) | 仅权重量化为INT4,激活值保留FP16 | 存储占用极低,精度损失相对可控 | 移动设备或嵌入式系统中部署复杂模型 |
| W8A16(8-bit Weight, 16-bit Activation) | 权重量化为INT8,激活值保留FP16 | 精度优先,性能折中 | 复杂图像处理、高精度NLP任务 |
| FA3(8-bit FlashAttention3) | 对Q、K、V进行INT8量化 | 减少Attention计算的显存占用和IO开销,提升吞吐 | 长序列NLP任务(如长文本生成) |
| KV-Cache 量化 | 对Transformer模型的KV缓存进行INT8量化 | 优化缓存效率,提升批量推理吞吐量 | BERT、GPT系列等大型Transformer模型大规模推理 |
| W4A8(4-bit Weight, 8-bit Activation) | 权重INT4+激活值INT8,采用分组或非对称量化 | 存储与计算效率兼顾 | 超低功耗边缘设备(如智能传感器)、轻量化端侧模型部署 |
| W4A4(4-bit Weight, 4-bit Activation) | 权重与激活值均为INT4,需训练感知量化 | 模型体积最小,延迟极低 | 微型MCU穿戴设备、实时语音唤醒等对延迟/功耗极度敏感的场景 |
实际应用中,数据中心和云端部署大模型时,存储和计算成本是重要考量因素,量化能有效减少存储空间和推理成本;而移动设备和边缘计算场景,由于存储空间有限、算力不足,量化更是必不可少的优化手段。
2.2 典型量化方式实践流程
W8A8量化:平衡高效的通用方案
W8A8量化是目前应用最广泛的量化方式,通过对权重和激活值都进行INT8量化,在精度损失控制在1%以内的前提下,能实现4倍存储压缩和显著的推理加速。
它的核心优势是支持离群值抑制、量化回退、KV-Cache量化融合等多种优化手段,能灵活适配不同类型的模型。

以Qwen3 32B模型为例,实际操作流程大概是这样的:
- 准备浮点模型权重:直接从HuggingFace官网下载原始模型权重。
- 准备环境:首先要安装HDK、CANN、MindIE LLM、msModelSlim这些依赖组件,还要安装transformers 4.51.0这类软件依赖。
- 生成量化权重:安装好msModelSlim工具后,执行下面的指令就能生成W8A8 mix类型的量化权重:
msmodelslim quant --model_path {浮点模型路径} --save_path {量化模型保存路径} --device npu --model_type Qwen3-32B --config_path ${msmodelslim量化工具安装路径}/msit/msmodelslim/msmodelslim/practice_lab/Qwen/qwen3dense-w8a8.yaml --trust_remote_code True
- 推理验证:用下面的指令做对话测试,验证量化效果,比如输入“What’s deep learning?”,设置最长输出20个token:
torchrun --nproc_per_node 4 --master_port 12305 -m examples.run_pa --model_path {量化权重路径} --trust_remote_code True
在实际使用中,W8A8量化还有一些实用的优化策略。比如支持W8A8_mix模式,在Prefill阶段用激活值per-token量化(保证高精度),在Decode阶段用per-tensor量化(提升高性能),这样就能兼顾推理性能和精度。
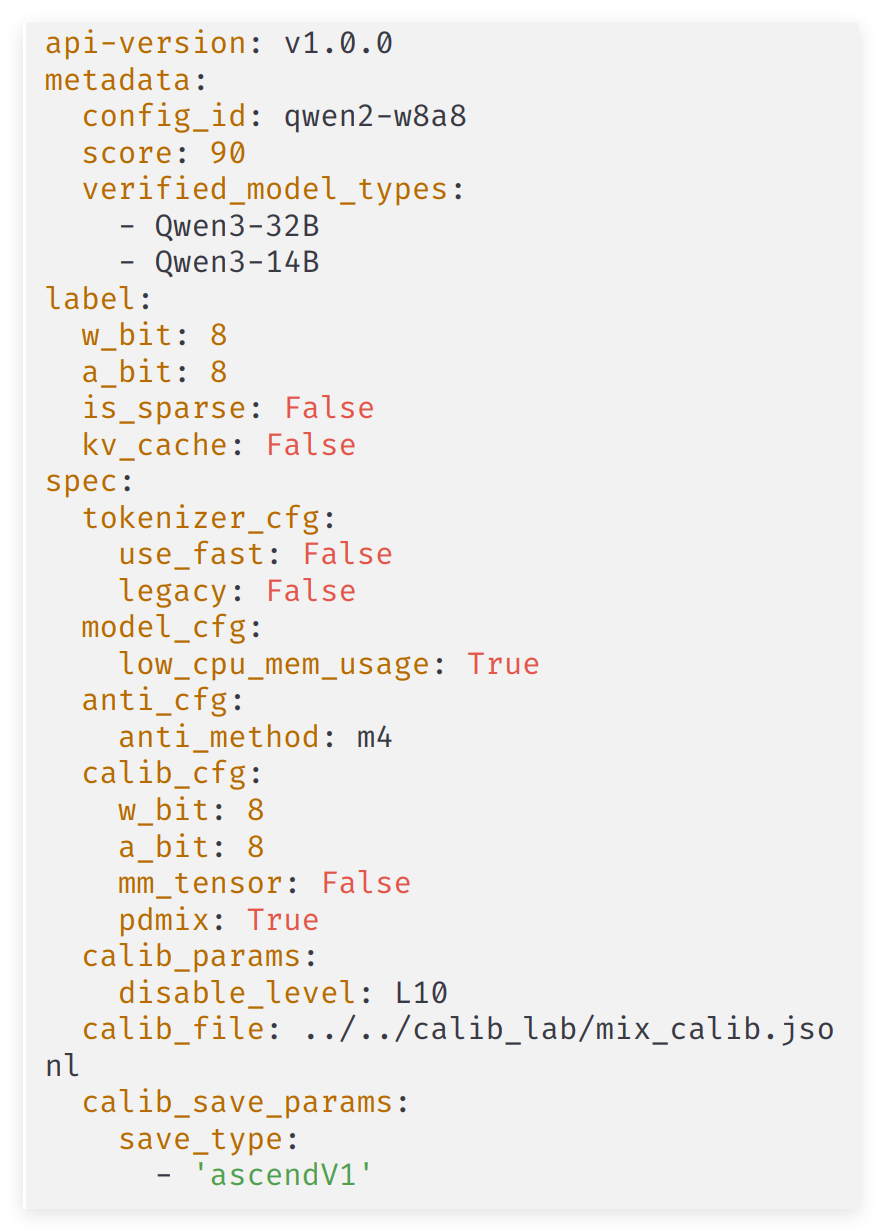
量化配置文件(qwen3dense-w8a8.yaml)里的关键参数也需要留意:
稀疏量化(W8A8SC):极致存储优化方案
稀疏量化是在W8A8量化的基础上,又增加了权重稀疏化和压缩步骤。简单说就是先通过算法判断模型权重中每个参数对精度的重要性,把影响小的权重值置零(这一步叫稀疏),再对权重和激活值做8位量化,最后通过压缩算法进一步编码,最大程度降低权重体积。
以Qwen3 8B模型为例,流程会比W8A8量化多几个步骤:
- 准备浮点权重后,要修改config.json里的torch_dtype字段,改成“float16”,适配硬件要求。
- 环境部署和W8A8量化一致,都是安装HDK、CANN、msModelSlim这些组件。
- 生成W8A8S量化权重:

- 编译压缩工具:

- 量化权重压缩:

这里要注意,压缩时用的卡数和并行策略,要和后续推理时保持一致。
实际项目中,我们还可以用代码实现权重稀疏化的核心逻辑:
import torch
import torch.nn as nn
def sparse_weight(weight: torch.Tensor, sparsity: float = 0.012) -> torch.Tensor:
"""权重稀疏化:将权重中绝对值最小的sparsity比例置零"""
num_elements = weight.numel()
num_zero = int(num_elements * sparsity)
# 找到绝对值最小的num_zero个元素
weight_flat = weight.view(-1)
_, indices = torch.topk(torch.abs(weight_flat), num_zero, largest=False)
weight_flat[indices] = 0.0
return weight.view_as(weight)
# 对模型所有线性层应用稀疏化
def apply_sparsity_to_model(model: nn.Module, sparsity: float = 0.012):
for name, module in model.named_modules():
if isinstance(module, nn.Linear):
module.weight.data = sparse_weight(module.weight.data, sparsity)
return model
KV-Cache量化:大模型推理吞吐量优化
KV-Cache量化主要针对Transformer模型的KV缓存进行INT8量化,能显著降低缓存的显存占用,提升批量推理的吞吐量,常和W8A8、W8A16这些量化方式搭配使用。

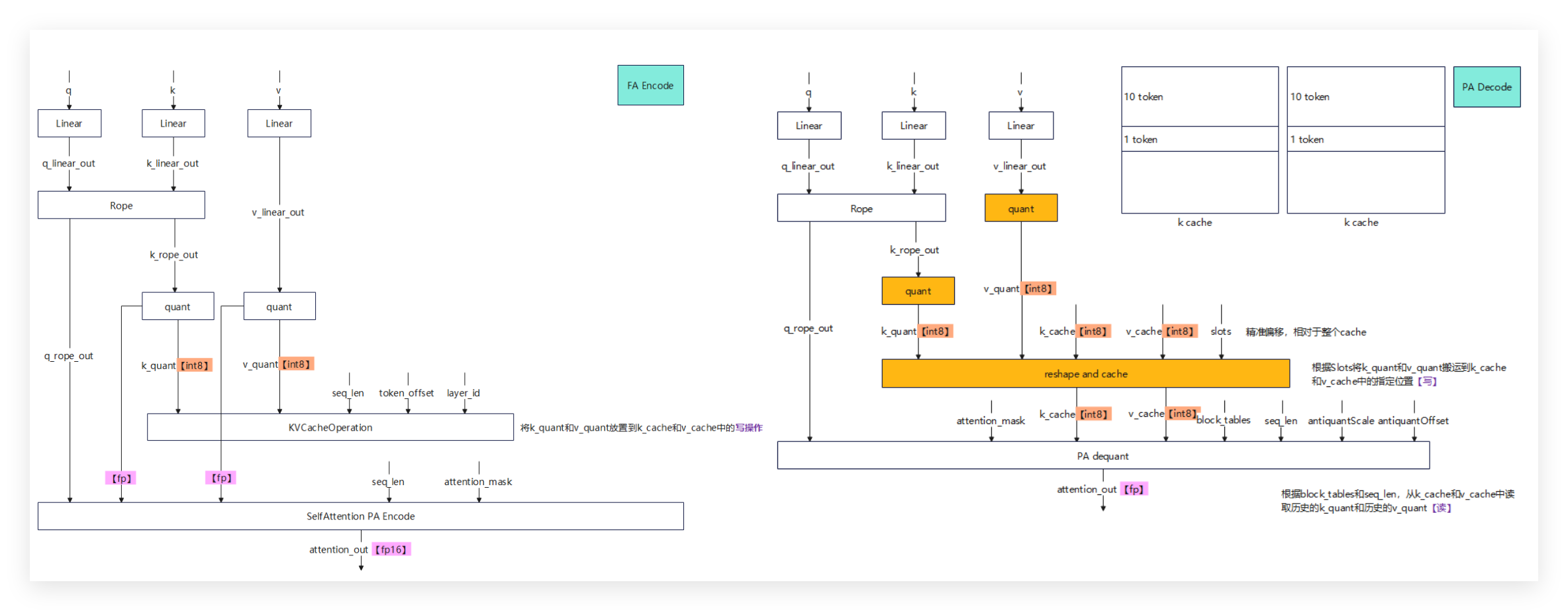
它的技术原理很直观:把K、V特征量化成INT8类型存储在缓存中,推理时通过Paged Attention算子反量化后再计算,这样既能保证精度,又能提升缓存效率。
以下展示了KV Cache int8在组图中的接入方式:
以LLaMa3.1 70B模型为例,流程如下:
- 下载浮点模型权重。
- 安装transformers 4.44.0及相关依赖组件。
- 生成量化权重(开启KV-Cache量化):

- 用8卡并行推理验证效果。
2.3 量化核心算法与技术细节
在实际量化过程中,有几个核心技术点需要重点关注:
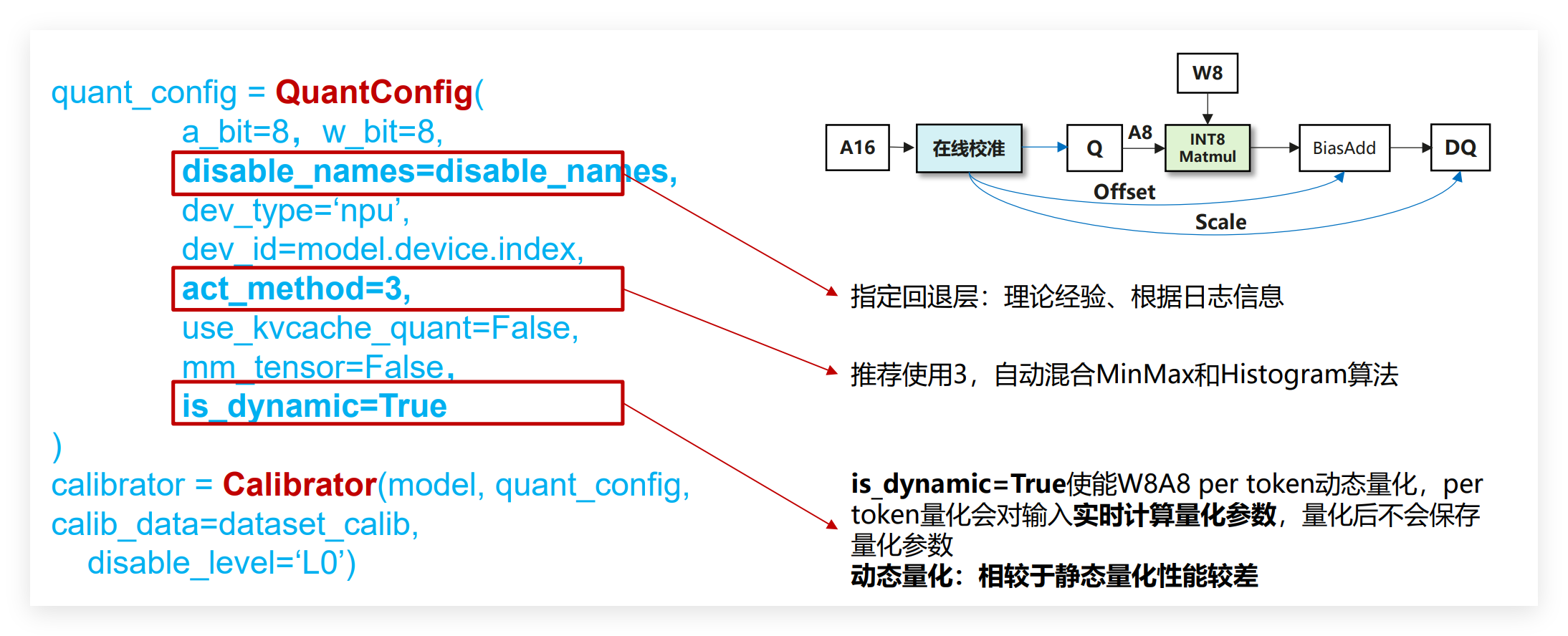
- 量化方法主要分为QAT(量化感知训练)和PTQ(训练后量化):QAT融入训练模拟量化误差,精度损失小但成本高;PTQ对预训练模型校准,无需重训、效率高,是大模型量化主流。PTQ又分动态量化(仅量化权重,无需校准数据,精度稍高、性能一般)和静态量化(权重与激活值均量化,需校准数据,性能更优)。
- 量化粒度选择:量化粒度是指对模型参数进行量化的级别,
- 常见的有per-tensor(逐层量化)、per-channel/per-token(逐通道/逐token量化)、per-group(逐组量化)。
- per-tensor最简单,硬件兼容性好,但数据分布差异大时误差明显;
- per-channel/per-token精度更高,但计算更复杂;per-group介于两者之间,能平衡精度和效率。
- 离群值抑制:模型参数中偶尔会出现一些极端值,这些值会导致量化误差增大。常用的抑制算法有SmoothQuant、AWQ、Flex Smooth等,比如W8A8量化常用m4(Smooth Quant)算法,W8A16量化常用m3(AWQ)算法。
三、模型量化回退与精度调优体系
3.1 量化回退技术:精度与效率的动态平衡
量化会有精度损失,且LayerNorm、SoftMax等层难以有效量化,需借助量化回退技术——对精度敏感层保留FP32/FP16高精度,非敏感层低精度量化(混合精度量化),平衡模型性能与量化收益。
量化回退分两种,可叠加使用:
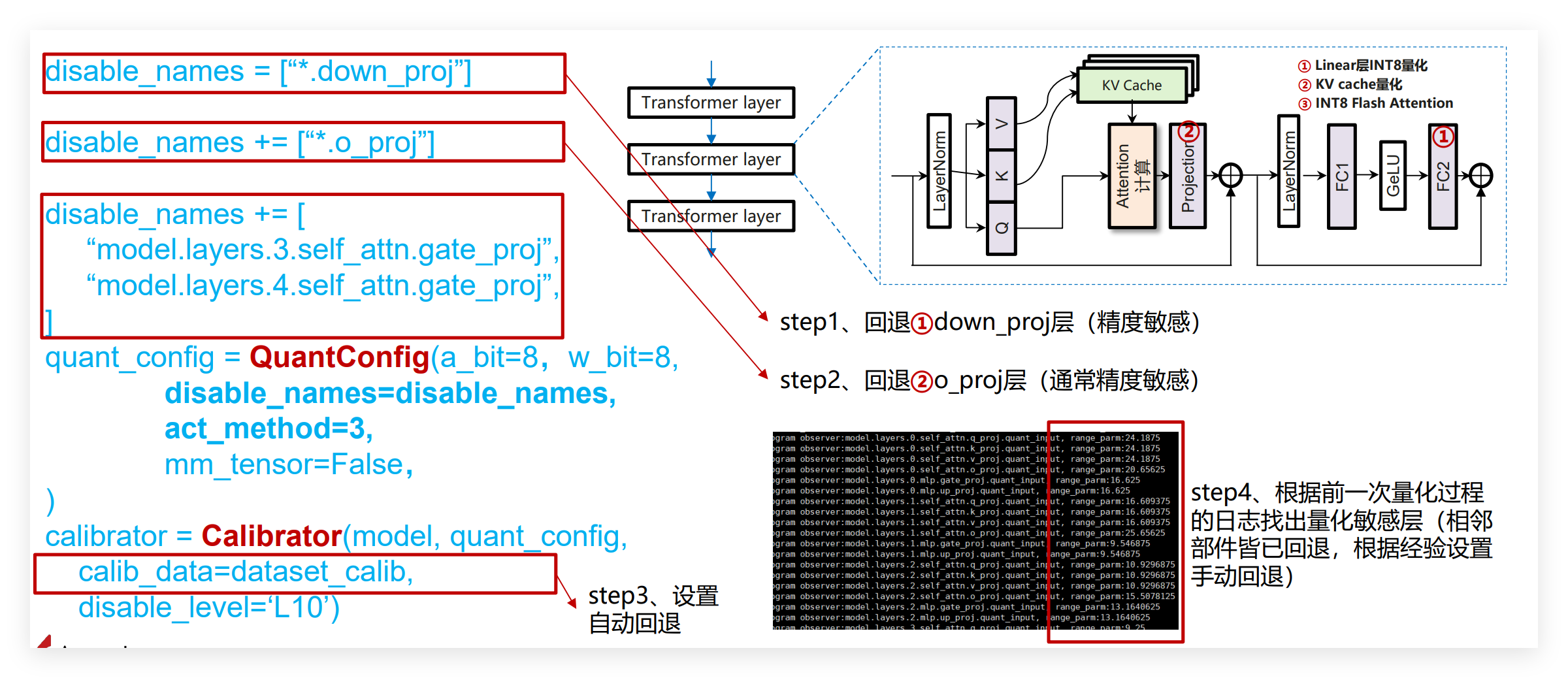
- 手动回退(disable_names):按经验指定高精度层,优先回退down_proj层、o_proj层,再依据终端日志range_parm数值筛选其他敏感层;
- 自动回退(disable_level):设置回退线性层数量(如L10即回退10层),系统按range_parm排序识别并显示回退层,使用便捷。
回退存在代价:可能造成计算瓶颈、增加内存占用,需控制回退层数(通常≤20%)。
我们可以用代码封装回退配置和应用逻辑,方便复用:
def configure_quantization_backend(model_name: str, quant_type: str = "W8A8") -> dict:
"""配置量化回退策略"""
backends = {
"W8A8": {
"disable_names": [
"*.mlp.down_proj", # 手动回退down_proj层
"*.self_attn.o_proj" # 手动回退o_proj层
],
"disable_level": "L10" # 自动回退10层
},
"W8A16": {
"disable_names": [], # W8A16通常无需回退
"disable_level": "L0"
}
}
# 针对特定模型的个性化配置
model_specific = {
"Qwen3-32B": {
"W8A8": {
"disable_names": [
"*.mlp.down_proj",
"*.self_attn.o_proj",
"model.layers.16.mlp.gate_proj"
],
"disable_level": "L12"
}
}
}
# 合并配置
config = backends.get(quant_type, backends["W8A8"])
if model_name in model_specific and quant_type in model_specific[model_name]:
config.update(model_specific[model_name][quant_type])
return config
3.2 精度调优全流程策略
量化后的精度调优是个系统工程,需要遵循“先基础优化,后进阶调整”的原则。
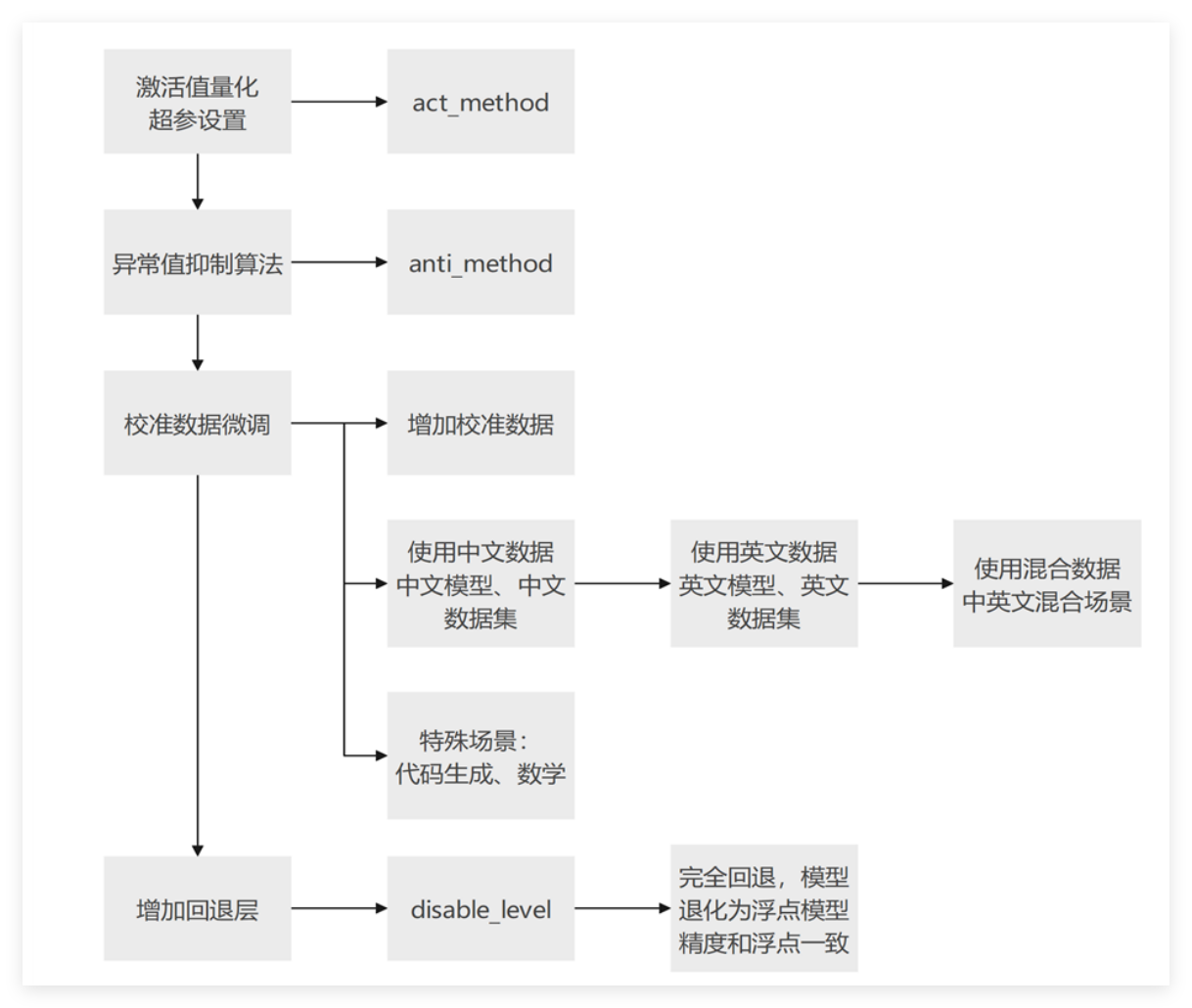
精度调优策略

- 权重量化 算法选择

- 调整异常值抑制
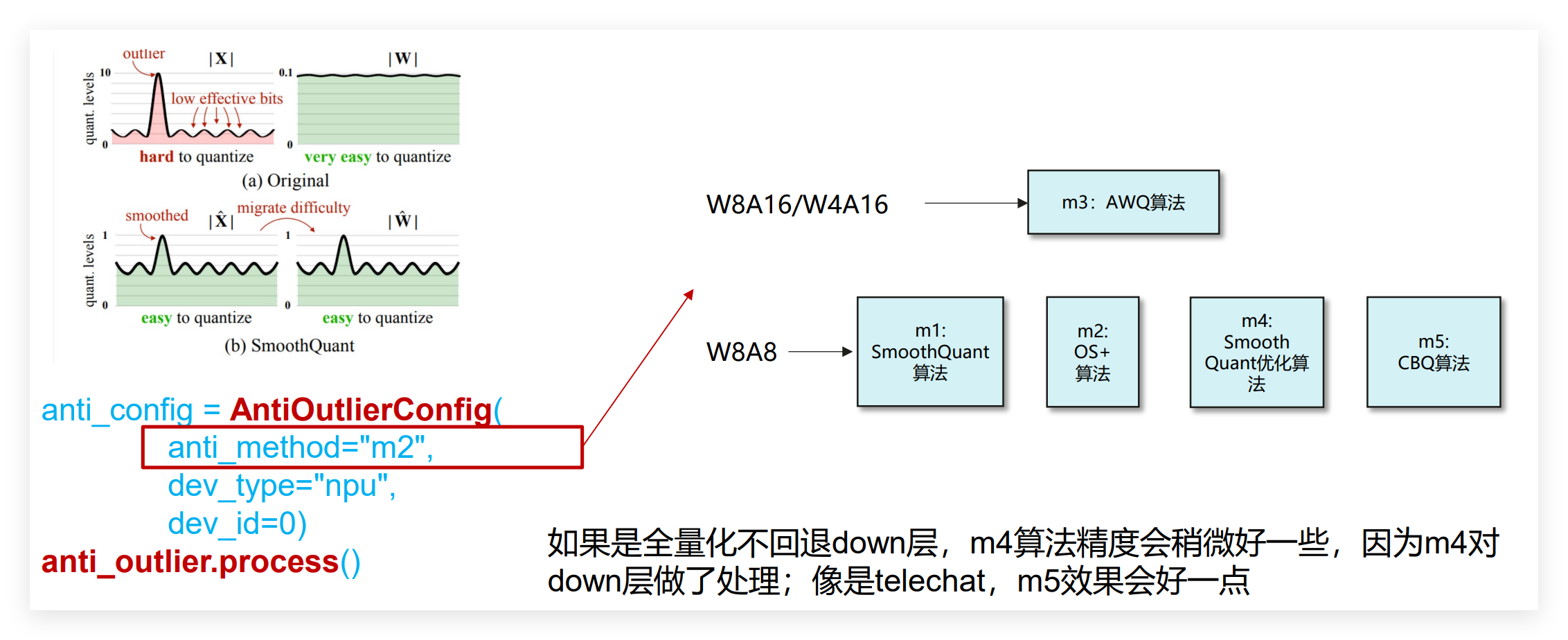
- 激活量化算法选择
- 校准集调整

- 量化回退
四、总结
模型量化压缩是深度学习模型工业化部署的核心支撑技术,通过平衡精度与效率,从基础INT8量化到极致INT4稀疏量化,从单一方式到混合精度优化,不断突破存储与计算限制,推动模型从云端走向边缘和终端。
实际项目中,需根据模型类型(CV/NLP)、硬件环境(云端/边缘/终端)、精度要求(高/中/低)选择量化方案,再通过量化回退、离群值抑制、校准数据优化等保障性能。
未来,随着跨平台适配、低比特量化、大模型分布式量化等技术发展,量化压缩将进一步释放深度学习部署潜力,为万物互联智能世界提供更高效AI动力。
注明:昇腾PAE案例库对本文写作亦有帮助。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)