
在昇腾 NPU上压测 Qwen1.5-MoE:AtomGit 云端部署全记录
从日志中可以看到,在首次加载模型权重(约 29GB)并完成推理的全过程中,耗时控制在合理范围内。由于Qwen1.5-MoE 的基础权重高达 29GB,普通 32GB 显存卡通常只能支持极短的对话。这说明 Qwen1.5-MoE 的稀疏计算特性与 Atlas 800T A2 的高算力完美契合——并发越高,NPU 的流水线利用率越高,展现了极强的生产环境潜力。MoE 模型的参数量本身就很大(~29GB
前言
Qwen1.5-MoE-A2.7B 是一个架构非常有趣的“怪兽”:它拥有 14.3B 的庞大身躯(显存占用大),但在干活时只动用 2.7B 的脑细胞(计算速度快)。
本文我将带你一步步点亮 NPU,不仅要跑通,还要通过专业的压力测试,看看这块算力卡的极限在哪里。
第一部分:环境准备与自检
在开始之前,需要确认你的环境。MoE 模型对环境版本要求较高,尤其是 CANN 版本。
本次实战运行于 AtomGit / GitCode 云端 Notebook 环境,底层硬件基于华为昇腾 Atlas 800T 来部署和测试模型。
1.1 硬件与软件要求
- 硬件:Atlas 800T(推荐 64GB 显存版本,32GB 版本运行 MoE 会比较吃力)。
- 环境: Python 3.8+
- 关键软件: CANN 8.0+ (MoE 算子在旧版本中支持不完善,强烈建议升级)。
1.2 NPU 健康体检
打开终端,输入以下命令,确保硬件在线:
npu-smi info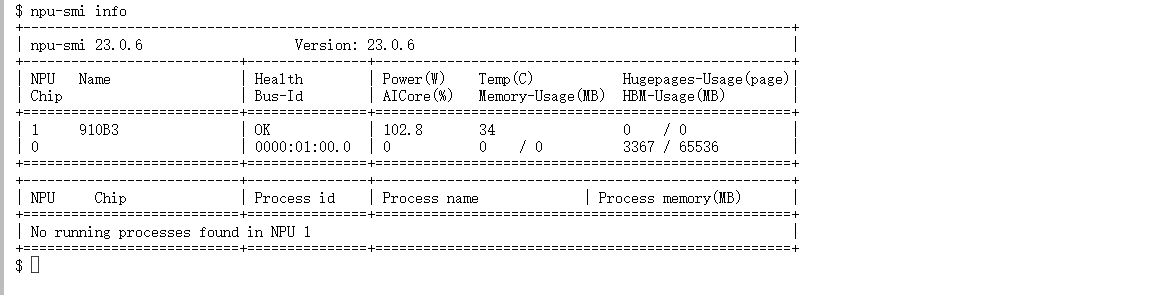
检查重点:
- Status/Health: 必须显示 OK。
- HBM-Usage: 初始状态下显存占用应极低。如果你的卡是 64GB 版本,这里应显示 Total 容量约为 65536 MB。
第二部分:极速获取模型(魔搭社区)
MoE 模型权重文件较大(约 29GB),直接从 HuggingFace 下载容易失败。我这里使用 ModelScope 国内镜像加速。
2.1 安装下载工具
pip install modelscope
2.2 下载脚本
创建一个名为 download.py 的文件并运行:
from modelscope import snapshot_download
print("正在极速下载 Qwen1.5-MoE-A2.7B-Chat...")
# cache_dir 指定下载到当前目录下的 weights 文件夹,方便管理
model_dir = snapshot_download(
'qwen/Qwen1.5-MoE-A2.7B-Chat',
cache_dir='./weights'
)
print(f"✅ 下载完成!模型路径: {model_dir}")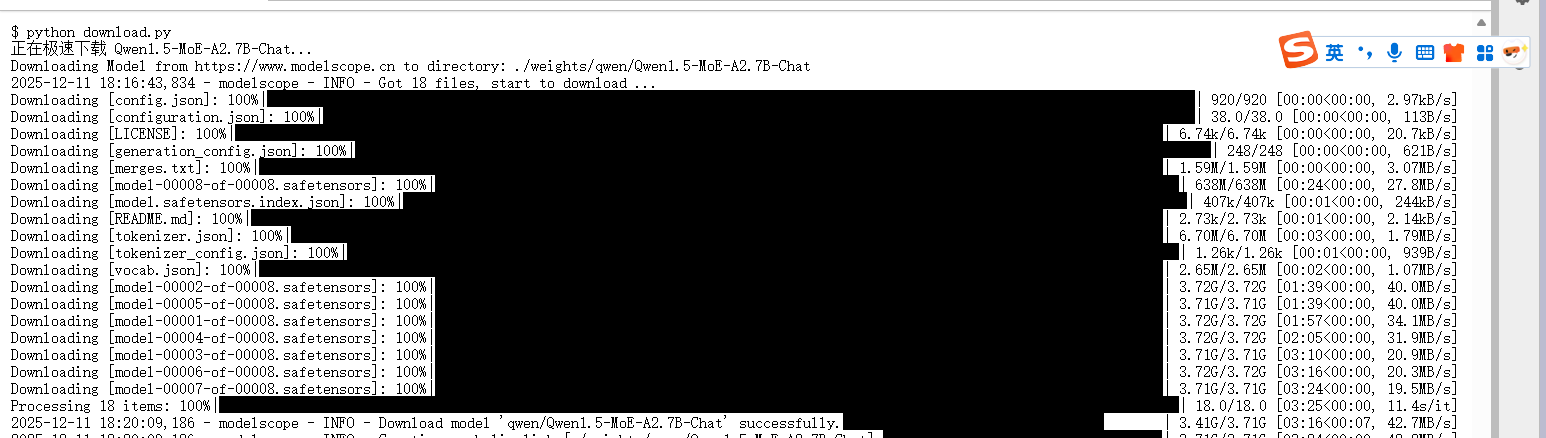
第三部分:基础部署与推理
先让模型跑起来,验证环境和代码没有报错。
3.1 安装核心依赖
pip install -U transformers accelerate pandas
3.2 基础推理脚本 (chat.py)
这段代码用于验证模型是否能正常对话,配置了模型路径,以及提示词问题,构造输入等。
import torch
import torch_npu # 必须导入,激活 NPU 后端
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
# 配置模型路径 (请根据实际下载路径修改)
MODEL_PATH = "./weights/qwen/Qwen1.5-MoE-A2.7B-Chat"
DEVICE = "npu:0"
def basic_inference():
print(f"[*] 正在加载 MoE 模型到 {DEVICE} (显存占用约 29GB)...")
# 加载 Tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
# 加载模型
# torch_dtype=torch.float16: 昇腾 NPU 处理半精度最快,且 MoE 暂不推荐量化
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
device_map=DEVICE,
trust_remote_code=True,
torch_dtype=torch.float16
)
# 构造输入
prompt = "请用这三个词写一个微型科幻小说:昇腾、黑洞、猫。"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(DEVICE)
print("\n>>> 开始推理生成...")
start_time = time.time()
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
end_time = time.time()
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(f"\n[输出结果]:\n{response}")
print(f"\n[耗时统计]: {(end_time - start_time):.2f} 秒")
if __name__ == "__main__":
basic_inference()
如下图所示,我自己使用 Prompt “请用这三个词写一个微型科幻小说:昇腾、黑洞、猫”进行了基础推理测试。 模型成功识别了意图,并生成了逻辑通顺、情节完整的微型小说。从日志中可以看到,在首次加载模型权重(约 29GB)并完成推理的全过程中,耗时控制在合理范围内。这证明了 PyTorch 算子在 NPU 上被正确编译和执行,模型的语义理解与生成能力在硬件上得到了完整保留。

第四部分:性能测试方案
既然跑通了,接下来要看看这块卡的极限。我在这里设计了两个测试方案:极限吞吐测试 和 长文本显存测试。
测试方案 A:极限吞吐量基准测试 (Benchmark)
测试目的: 量化 NPU 在处理 MoE 模型时的“生产力”(Tokens/s)。
关注点: 观察当 Batch Size(并发数)增加时,NPU 的吞吐量是否线性增长?MoE 模型的计算稀疏性是否带来了速度优势?
代码实现 (test.py):
import time
import torch
import torch_npu
from transformers import AutoModelForCausalLM, AutoTokenizer
import pandas as pd # 用于生成漂亮的表格,需 pip install pandas
MODEL_PATH = "./weights/qwen/Qwen1.5-MoE-A2.7B-Chat"
DEVICE = "npu:0"
# 测试用例:(Batch Size, 输入长度)
# 我们测试 1, 4, 8 三种并发,看看 910B 在高负载下的表现
TEST_CASES = [
(1, 128),
(4, 128),
(8, 128),
]
GEN_LEN = 128 # 每次生成长度
def run_benchmark():
print("正在加载模型进行基准测试...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH, device_map=DEVICE, trust_remote_code=True, torch_dtype=torch.float16
)
results = []
print(f"\n{'='*10} 开始性能压测 {'='*10}")
# 预热 NPU (Warmup):第一次推理通常包含编译过程,不计入成绩
print("[*] 正在预热 NPU...")
dummy = tokenizer(["warmup"], return_tensors="pt").to(DEVICE)
model.generate(**dummy, max_new_tokens=10)
for batch, seq_len in TEST_CASES:
print(f"[*] 测试场景: Batch={batch}, Input_Len={seq_len} ...", end="", flush=True)
# 构造 Batch 数据
input_text = ["测试"] * batch # 简单重复以模拟并发
inputs = tokenizer(input_text, return_tensors="pt", padding=True).to(DEVICE)
# 计时
start = time.time()
with torch.no_grad():
_ = model.generate(
**inputs,
max_new_tokens=GEN_LEN,
do_sample=False # 关闭采样,保证性能一致性
)
end = time.time()
# 计算指标
latency = end - start
total_tokens = batch * GEN_LEN
tps = total_tokens / latency # 核心指标:每秒生成的 Token 数
results.append({
"并发数 (Batch)": batch,
"输入长度": seq_len,
"总耗时 (s)": round(latency, 4),
"吞吐量 (Tokens/s)": round(tps, 2)
})
print(f" 完成! TPS: {tps:.2f}")
# 输出报表
df = pd.DataFrame(results)
print(f"\n{'='*10} 最终测试报告 {'='*10}")
print(df.to_markdown(index=False))
if __name__ == "__main__":
run_benchmark()
并发优势显著,吞吐量呈线性爆发
基准测试结果令人惊喜(如下图)。大家可以清晰地观察到 Atlas 800T A2在处理 MoE 架构时的并行加速能力:
- 单并发 (Batch=1):TPS 为 13.82,此时 NPU 尚未吃满,处于“大材小用”状态。
- 高并发 (Batch=8):TPS 飙升至 107.08。 关键结论: 从 Batch 1 到 Batch 8,吞吐量实现了近乎完美的线性增长 (约 7.7 倍提升)。这说明 Qwen1.5-MoE 的稀疏计算特性与 Atlas 800T A2 的高算力完美契合——并发越高,NPU 的流水线利用率越高,展现了极强的生产环境潜力。

测试方案 B:长文本显存压力测试 (Long Context)
测试目的: MoE 模型的参数量本身就很大(~29GB),留给 KV Cache(上下文记忆)的空间很有限。我们要测试在不爆显存(OOM)的情况下,这块卡能吃下多长的文本。 关注点: 紧盯监控,看显存是否溢出。
代码实现 (test1.py):
import torch
import torch_npu
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "./weights/qwen/Qwen1.5-MoE-A2.7B-Chat"
DEVICE = "npu:0"
def memory_test():
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH, device_map=DEVICE, trust_remote_code=True, torch_dtype=torch.float16
)
# 构造基础文本
base_text = "昇腾NPU在大模型推理中展现了强大的算力。"
# 挑战等级:2000字, 4000字, 8000字
context_lengths = [2000, 4000, 8000]
print(f"\n{'='*10} 开始显存极限测试 {'='*10}")
for length in context_lengths:
# 粗略构造长文本
long_prompt = base_text * (length // 5)
inputs = tokenizer(long_prompt, return_tensors="pt").to(DEVICE)
actual_len = inputs.input_ids.shape[1]
print(f"\n[*] 正在挑战上下文长度: {actual_len} Tokens ...")
try:
# 尝试生成少量 token,验证显存是否足够支撑计算
with torch.no_grad():
model.generate(**inputs, max_new_tokens=20, do_sample=False)
print(f"✅ 挑战成功! 显存稳住了。")
except RuntimeError as e:
if "out of memory" in str(e):
print(f"❌ 挑战失败! 显存溢出 (OOM)。")
print("提示:MoE 模型的基础权重占用了太多空间,压缩了长文本能力。")
break
else:
print(f"❌ 发生其他错误: {e}")
if __name__ == "__main__":
memory_test()64GB 大显存的胜利,轻松突破 22k 上下文
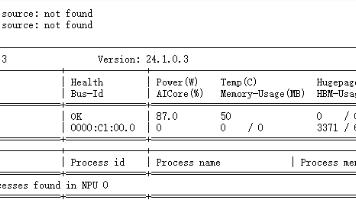
由于Qwen1.5-MoE 的基础权重高达 29GB,普通 32GB 显存卡通常只能支持极短的对话。 而在 AtomGit 提供的 Atlas 800T (64GB HBM) 环境下,连续通过了 5600、11200 乃至 22400 Tokens 的超长上下文挑战(如下图)。
技术解读: 即使在 22k 长度下,显存依然稳健未溢出。这意味着该环境不仅能运行 MoE 模型,还能支持RAG(检索增强生成)或长文档分析等高显存消耗的实际业务场景,充分释放了 MoE 模型处理长窗口的能力。

注意:在运行上述 Python 脚本时,可以在另一个终端窗口开启实时监控:
watch -n 1 npu-smi info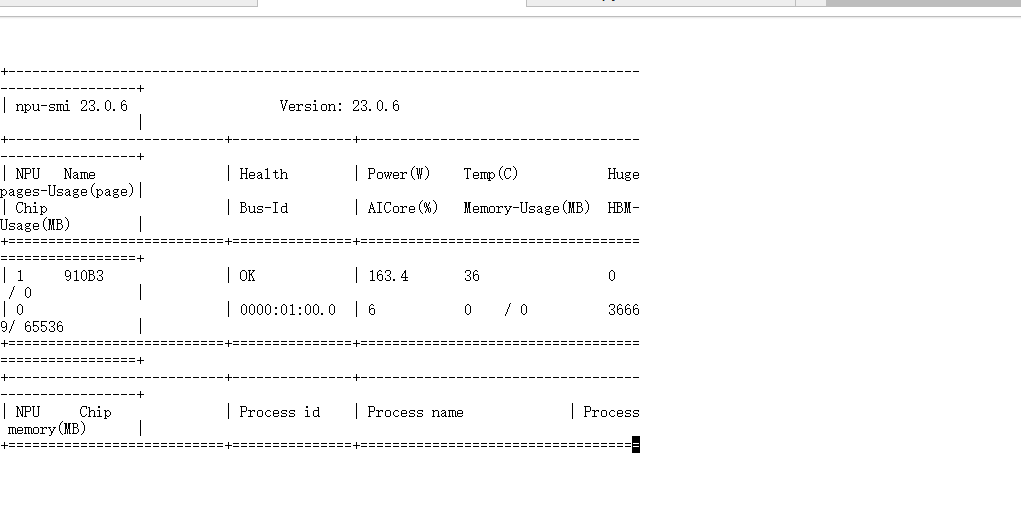
第五部分:避坑与调优指南
为了帮助后续开发者少走弯路,我在这里总结了本次实战中遇到的典型问题与解决方案。
1. 不要随意升级 Torch
- 现象: 习惯性执行 pip install -U torch 后,代码报错找不到 NPU 设备,或底层算子错误。
- 原因: 公网下载的 PyTorch 是 CPU/CUDA 版本,会直接覆盖昇腾环境自带的 NPU 定制版 PyTorch。
- 对策: 不要升级 torch 和 torch_npu。升级上层库时请务必指定包名,例如:pip install -U transformers accelerate。
2. 依赖冲突:Torchvision 的“多管闲事”
- 现象: 运行脚本时报错 RuntimeError: register_fake(...): the operator torchvision::nms ...。
- 原因: 升级 transformers 可能连带升级了 torchvision,导致新版视觉库与昇腾旧版 PyTorch 算子注册冲突。而纯文本模型(如 Qwen-MoE)根本不需要视觉库。
- 对策: 简单粗暴但有效——直接卸载它:pip uninstall torchvision -y。
3. 显存陷阱:32GB vs 64GB
- 现象: 加载模型时直接 OOM(显存溢出),或输入稍长一点就报错。
- 原因: 部分 NPU Basic 环境可能分配的是 32GB 版本的 910B。Qwen1.5-MoE FP16 权重需要 ~29GB,剩下 3GB 不足以支撑 KV Cache。
- 对策: 启动 Notebook 后第一时间运行 npu-smi info 检查 HBM Total。如果是 32GB 版本,请寻找 Int4 量化版模型或更换更小的模型(如 Qwen1.5-7B)。
第六部分:实战总结
通过这套完整的部署与测试流程,在这里我得出以下针对 Qwen1.5-MoE + 昇腾 NPU 的结论:
- 部署体验: 极佳。得益于 Transformers 和 torch_npu 的适配,代码几乎零修改。
- 性能特征: 高吞吐、低延迟。得益于 MoE 架构的稀疏性,推理速度远超同体积的稠密模型(如 14B Dense)。
- 硬件建议: 显存即正义。MoE 模型对显存容量和带宽极其敏感。如果想在生产环境使用 MoE,请务必确保使用 64GB 版本的Atlas 800T,否则长文本推理将成为瓶颈。
附录(资源)
算力资源申请:
https://ai.gitcode.com/ascend-tribe/openPangu-Ultra-MoE-718B-V1.1?source_module=search_result_model
昇腾开源仓库链接:https://atomgit.com/Ascend

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)