
昇腾MindSpeed MM多模态大模型微调实战指南
摘要 MindSpeed MM是昇腾平台专属多模态大模型训练套件,适配910B/910C芯片,从计算、内存、通信、并行四个维度深度优化,解决通用框架性能瓶颈。该套件兼容Megatron、DeepSpeed等生态,采用模块化设计,支持30余种主流多模态模型,覆盖文本/图像转视频、图文/视频理解等任务。其技术架构分为三层:底层基于昇腾芯片整合CANN、HCCL等工具;核心加速模块提供并行优化、内存优化

一、套件概述:昇腾原生多模态训练利器
1.1 套件定位与核心价值

MindSpeed MM 是昇腾平台专属多模态大模型训练套件,适配 910B/910C 芯片,从计算、内存、通信、并行四维度深度优化,解决通用框架性能瓶颈。兼容 Megatron、DeepSpeed 等生态,模块化设计,支持 30 余种主流多模态模型(如 OpenSoraPlan、Qwen2.5-VL),覆盖文本 / 图像转视频、图文 / 视频理解等任务,工具链成熟,适配科研与企业落地。
1.2 技术架构与核心组件
采用“硬件 - 加速 - 应用”` 三层架构,各层优化落地:
- 底层基础层:基于昇腾芯片,整合 CANN、HCCL、毕昇编译器,支持 PyTorch/MindSpore,实现模型与硬件高效适配,无需手动调参。

- 核心加速模块层(MindSpeed Core):核心优化引擎,含四大能力:
- 并行优化:自动适配 TP+PP 等混合并行,突破单卡算力限制;
- 内存优化:通过压缩、重计算等降低显存占用,支持更大参数量模型;
- 通信优化:减少多节点通信开销,提升集群效率;
- 计算优化:融合算子 + 昇腾亲和优化,提升单卡计算速度。
- 上层套件层:含三大核心模块:
- 模型模块:预置 10 余种模型,无缝接入 Diffusers 生态;
- 数据工程模块:统一处理图文视频数据,简化预处理;
- 训练与推理模块:支持全参 / LoRA 微调、断点续训、在线推理,适配不同需求。
1.3 支持模型与特性矩阵
- 模型覆盖范围
我整理了一下它支持的模型,大概有30多种,涵盖了多模态生成、多模态理解、语音识别这些常见任务类型,不同模型的参数量、支持的任务和集群配置都不一样。

- MindSpeed MM多模态模型支持特性概览
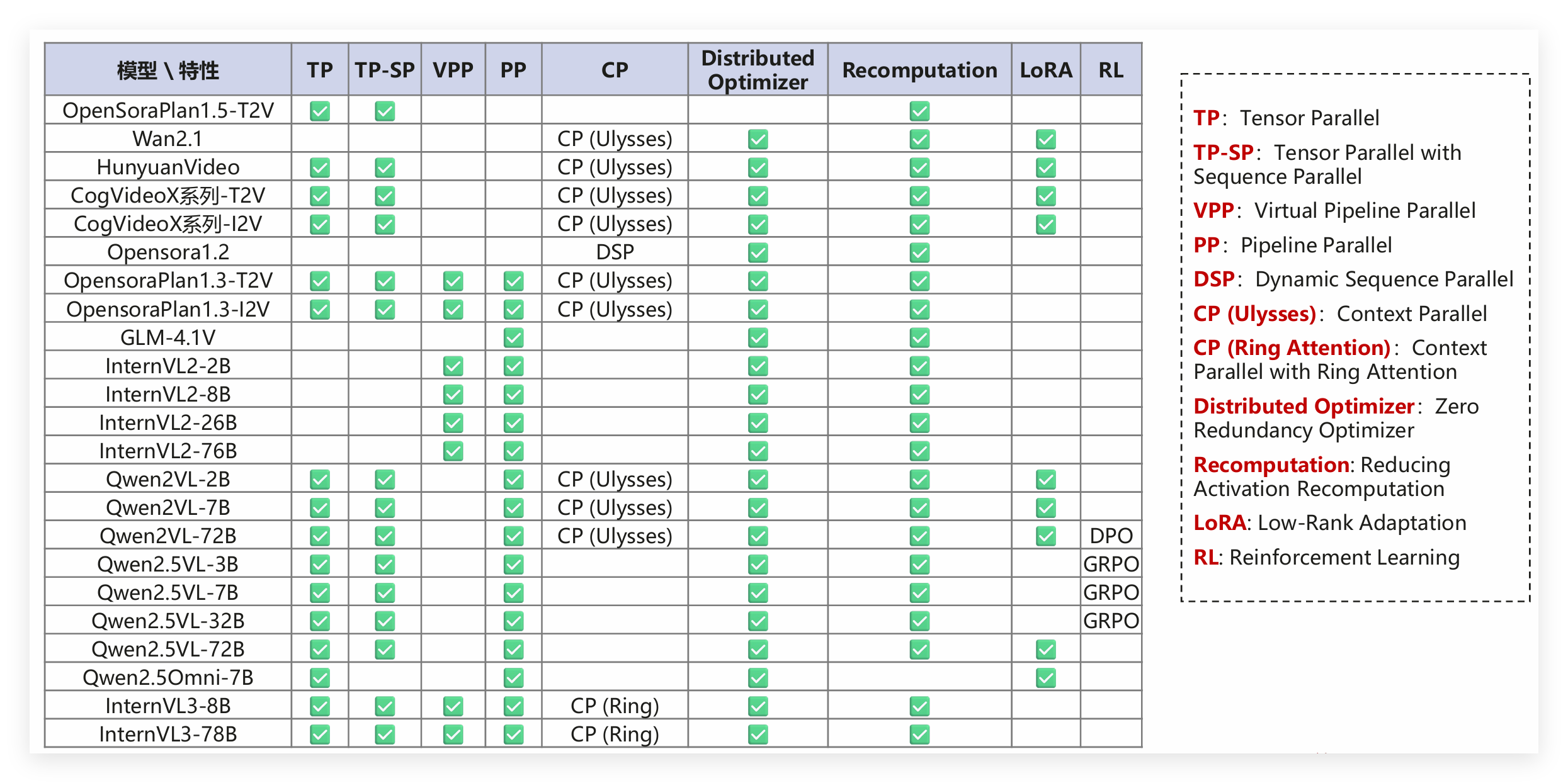
这里解释下几个关键术语,避免新手踩坑:TP(Tensor Parallel)是张量并行,CP(Context Parallel)是上下文并行,DSP(Dynamic Sequence Parallel)是动态序列并行,LoRA(Low-Rank Adaptation)是低秩适配,适合小数据集微调,RL(Reinforcement Learning)是强化学习,多用于模型效果迭代。
二、前置准备:环境部署与配置
2.1 版本配套关系
环境配置最关键的就是版本匹配,MindSpeed MM支持Atlas 800T A2等昇腾训练硬件形态,软件版本配套表如下
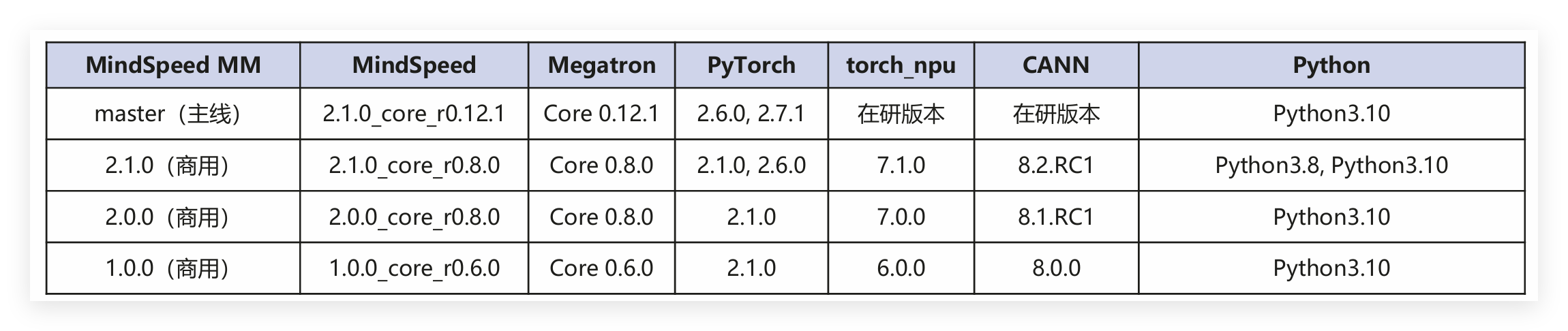
这里给大家个建议,新手优先选商用版本,稳定性更高,不容易出问题;如果需要用新模型、新特性,再考虑主线版本,不过主线版本可能会有一些未完善的地方,需要多留意官方更新。
2.2 硬件环境要求
- 训练硬件:推荐用Atlas 800T A2这类昇腾训练服务器,单节点至少要8张昇腾910B/910C芯片,支持多节点集群部署,我之前用单节点8卡训练7B模型刚好,训练72B模型就需要多节点了;
- 存储要求:一定要预留足够的存储空间,数据集、模型权重、训练日志都很占地方,建议至少留100GB空闲空间,我上次训练时因为存储空间不够,中途报错,只能重新清理空间再训练,特别耽误时间;
- 网络要求:多节点训练的话,网络很关键,建议用InfiniBand高速网络,不然节点间通信会很慢,影响训练效率,我之前用普通网络做2节点训练,速度比InfiniBand慢了一半。
2.3 环境安装步骤
我以MindSpeed MM master版本、Python3.10、昇腾910B芯片为例,把环境安装流程拆解开,每一步都标注了注意事项:
- 驱动固件安装
驱动固件是基础中的基础,必须先装对,不然后面根本识别不到NPU设备。一定要根据自己的硬件型号和系统版本选对应版本。
# 下载驱动固件(需从华为昇腾官网获取对应版本)
# 安装驱动
bash Ascend-hdk-*-npu-driver_*.run --full --force
# 安装固件
bash Ascend-hdk-*-npu-firmware_*.run --full
安装完成后,一定要用npu-smi info命令验证下,能看到芯片信息就说明驱动装好了,这一步别省,避免后面发现问题再回头排查。
- CANN工具链安装
CANN是昇腾平台的核心软件栈,算子开发、模型训练都离不开它。安装时要注意系统架构,aarch64和x86_64版本不能混用。
# 下载CANN工具链(aarch64或x86_64版本,根据系统架构选择)
bash Ascend-cann-toolkit_8.2.RC1_linux-aarch64.run --install
bash Ascend-cann-kernels-*_8.2.RC1_linux-aarch64.run --install
# 配置环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 安装nnal包
bash Ascend-cann-nnal_8.2.RC1_linux-aarch64.run --install
source /usr/local/Ascend/nnal/atb/set_env.sh
这里重点提醒下,版本迭代快,包名可能会有差异,一定要根据实际下载的包名修改命令,安装完后必须执行source命令配置环境变量,不然系统识别不到CANN相关工具。
- 代码仓拉取与目录创建
# 拉取MindSpeed-MM代码仓
git clone https://gitee.com/ascend/MindSpeed-MM.git
cd MindSpeed-MM
# 拉取Megatron-LM仓库并复制到MindSpeed-MM目录
git clone https://github.com/NVIDIA/Megatron-LM.git
cd Megatron-LM
git checkout core_v0.12.1
cp -r megatron ../MindSpeed-MM/
cd ..
# 创建日志、数据、权重存储目录
mkdir logs data ckpt
- Python环境配置
# 创建conda环境
conda create -n msmm_env python=3.10
conda activate msmm_env
# 安装PyTorch和torch_npu(需从昇腾官网下载对应版本)
pip install torch-2.7.1-cp310-cp310-manylinux_2_28_aarch64.whl
pip install torch_npu-2.7.1*-cp310-cp310-manylinux_2_28_aarch64.whl
# 安装apex库(昇腾适配版本)
git clone https://gitee.com/ascend/apex.git
cd apex
pip install -e .
cd ..
# 安装MindSpeed加速库
git clone https://gitee.com/ascend/MindSpeed.git
cd MindSpeed
git checkout 6d63944cb2470a0bebc38dfb65299b91329b8d92
pip install -r requirements.txt
pip3 install -e .
cd ..
# 安装MindSpeed-MM依赖
pip install -e .
2.4 关键环境变量配置
环境变量很关键,直接影响训练性能和稳定性。
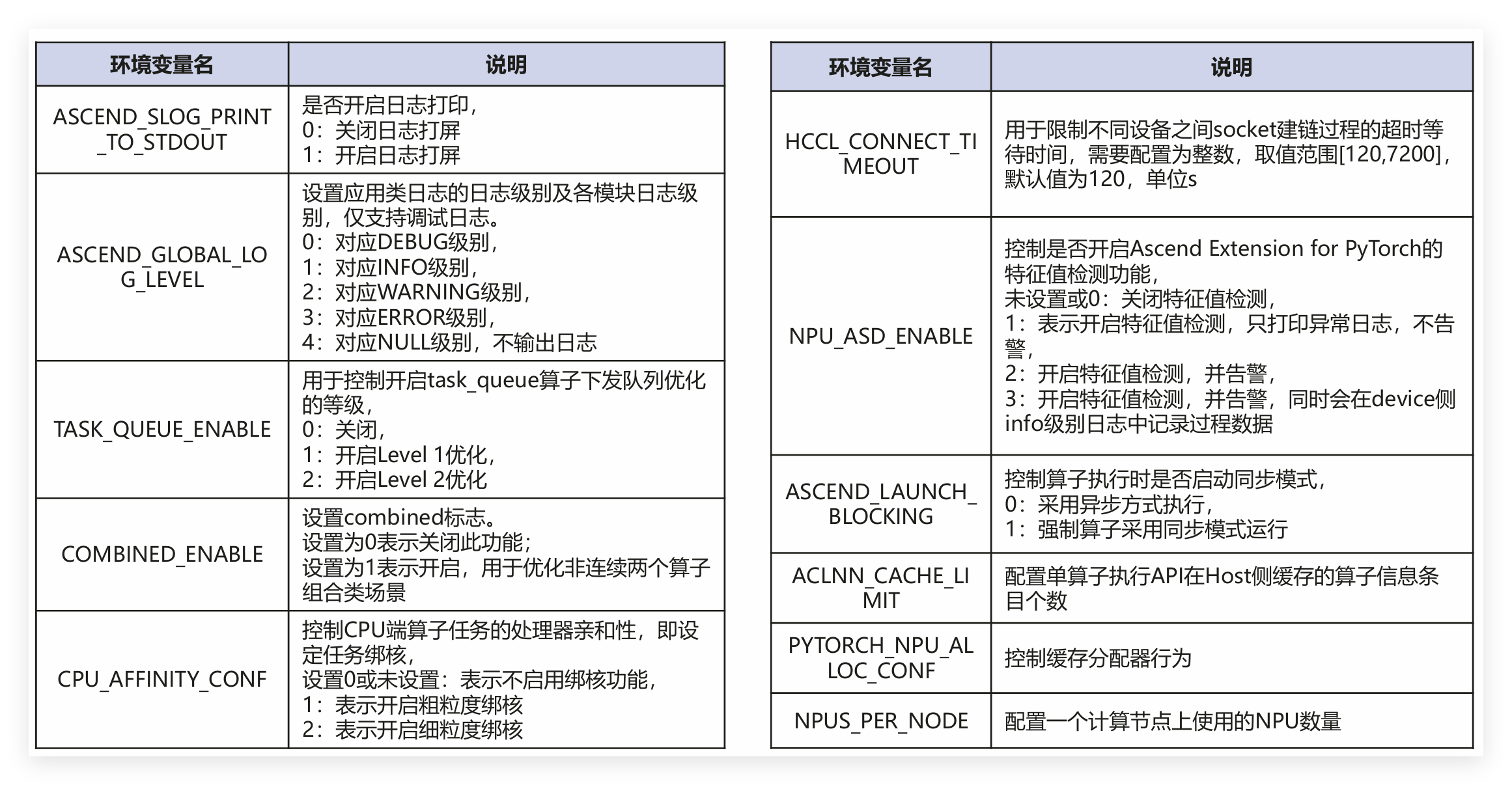
设置环境变量可以用export 环境变量名=配置值命令临时设置,也可以写在启动脚本里,每次启动自动加载,建议写在脚本里,避免每次训练都要重新设置,节省时间。
三、微调全流程:从数据准备到模型评测
3.1 数据准备与处理
- 数据集下载
- 图像数据集:常用的是COCO2017数据集,包含训练集、验证集和测试集,下载后解压到
./data/COCO2017目录,路径里别包含中文和特殊字符,不然会加载失败; - 描述文件:LLaVA-Instruct-150K数据集的描述文件很常用,里面有图像对应的文本指令,下载后保存到
./data目录,记得核对文件完整性,避免缺漏。
- 数据格式转换
LLaVA-Instruct-150K格式的数据套件不直接支持,需要用自带的转换脚本转换成MLLM格式,命令很简单:
python examples/qwen2vl/llava_instruct_2_mllm_demo_format.py
转换后会生成./data/mllm_format_llava_instruct_data.json文件。这里给大家个小技巧,测试阶段可以在data.json里设置dataset_param.basic_parameters.max_samples参数,只读取少量数据快速验证流程,避免因为数据格式问题浪费大量时间,正式训练时再把这个参数删掉,读取全部数据。
- 数据配置文件修改
修改data.json中的数据集路径和预处理参数,确保模型能正确加载数据:
"dataset_param": {
"dataset_type": "huggingface",
"preprocess_parameters": {
"model_name_or_path": "./ckpt/hf_path/Qwen2.5-VL-7B-Instruct"
},
"basic_parameters": {
"dataset_dir": "./data",
"dataset": "./data/mllm_format_llava_instruct_data.json",
"cache_dir": "./data/cache_dir",
"max_samples": 1000 // 测试阶段使用,正式训练移除
}
}
3.2 模型权重转换
这里有个关键步骤,MindSpeed MM对部分原始网络的结构名称做了修改,所以Hugging Face格式的预训练权重不能直接用,必须用mm-convert工具转换,这个工具还支持PP(Pipeline Parallel)权重的重切分,很实用。
- 下载原始权重
从Hugging Face下载Qwen2.5-VL-7B-Instruct模型权重,保存至./ckpt/hf_path/Qwen2.5-VL-7B-Instruct目录:
git clone https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct ./ckpt/hf_path/Qwen2.5-VL-7B-Instruct
- 权重转换命令
mm-convert Qwen2_5_VLConverter hf_to_mm \
--cfg.mm_dir "ckpt/mm_path/Qwen2.5-VL-7B-Instruct" \
--cfg.hf_config.hf_dir "ckpt/hf_path/Qwen2.5-VL-7B-Instruct" \
--cfg.parallel_config.llm_pp_layers [[12,16]] \
--cfg.parallel_config.vit_pp_layers [[32,0]] \
--cfg.parallel_config.tp_size 1
给大家解释下几个关键参数,避免配置错误,我之前因为参数写错,转换后的权重加载失败,排查了半天才找到问题:
mm_dir:转换后权重的保存目录,建议和原始权重目录区分开,避免混淆;hf_dir:原始Hugging Face权重目录,确保路径正确,权重文件完整;llm_pp_layers:LLM模块在每个卡上的切分层数,必须和model.json里的pipeline_num_layers一致,不然会维度不匹配;vit_pp_layers:ViT模块在每个卡上的切分层数,也要和model.json里的配置一致;tp_size:张量并行数量,要和微调启动脚本里的配置对应上。
3.3 模型微调配置与启动
- 微调脚本参数配置
微调脚本的参数配置很关键,直接影响训练效果和稳定性,我以examples/qwen2.5vl/finetune_qwen2_5_vl_7b.sh为例,给大家标注下关键参数的设置技巧:
# 权重加载与保存路径
LOAD_PATH="ckpt/mm_path/Qwen2.5-VL-7B-Instruct"
SAVE_PATH="save_dir"
# 训练参数配置
GPT_ARGS="
--no-load-optim \ # 不加载优化器状态,首次训练建议开启
--no-load-rng \ # 不加载随机数状态,首次训练建议开启
--no-save-optim \ # 不保存优化器状态,减少存储占用
--no-save-rng \ # 不保存随机数状态,减少存储占用
--log-interval 1 \ # 日志打印间隔,每1步打印一次
--save-interval 5000 \ # 模型保存间隔,每5000步保存一次
--log-tps \ # 打印每秒吞吐tokens量
"
# 分布式训练配置
source /usr/local/Ascend/ascend-toolkit/set_env.sh
NPUS_PER_NODE=8 # 单节点NPU数量
MASTER_ADDR=localhost # 主节点地址
MASTER_PORT=29501 # 主节点端口
NNODES=1 # 节点总数
NODE_RANK=0 # 当前节点序号
WORLD_SIZE=$(($NPUS_PER_NODE * $NNODES)) # 总进程数
- ViT模块重计算配置(可选)
默认情况下ViT模块是冻结的,如果想放开ViT训练,建议启用重计算功能,这样能降低显存占用,不过会稍微牺牲一点训练速度, trade-off很值得。修改model.json里的vision_encoder部分即可:
"vision_encoder": {
"freeze": false, // 放开ViT训练
"recompute_granularity": "selective", // 重计算模式:full/selective
"recompute_method": "uniform", // 重计算层数计算方法:uniform/block
"recompute_num_layers": 1 // 重计算层数,仅full模式有效
}
full模式:会对TransformerLayer里的layernorm、attention、mlp等所有组件都进行重计算,可以配置重计算层数,显存节省效果更明显;selective模式:只对attention的core_attention组件进行重计算,不用配置层数,速度比full模式快一点,显存节省效果稍差。
- 启动微调训练
bash examples/qwen2.5vl/finetune_qwen2_5_vl_7b.sh
启动后可以实时查看日志,重点关注loss变化、训练速度和显存占用。如果出现显存溢出,是很常见的问题,不用慌,优先尝试启用重计算,效果不明显再降低batch size,或者增大梯度累积步数,一般都能解决。
3.4 模型推理与效果验证
微调完成后,一定要做推理验证,看看模型效果是否符合预期,这一步能及时发现问题,避免后续评测白忙活:
- 推理配置修改
推理配置重点是路径别搞反,我之前就犯过这个错,折腾了好久:修改examples/qwen2.5vl/inference_qwen2_5_vl_7b.json和inference_qwen2_5_vl_7b.sh,json文件里tokenizer的from_pretrained参数要指向原始Hugging Face权重目录,sh文件里的LOAD_PATH要指向转换后的权重目录(支持PP切分)。
- json文件:配置tokenizer加载路径,为原始Hugging Face权重路径;
- sh文件:配置模型加载路径,为转换后的权重路径(支持PP切分)。
- 启动推理
bash examples/qwen2.5vl/inference_qwen2_5_vl_7b.sh
启动后,模型会加载微调后的权重,输出对输入图文或视频的理解、生成内容,我们可以直观判断效果。我之前微调后的模型,在专业领域的问答准确率比原始模型提升了15%左右,效果很明显。
3.5 模型评测
推理只能直观判断效果,量化评测才是客观评价模型性能的关键。MindSpeed MM支持AI2D(test)、ChartQA(test)、Docvqa(val)、MMMU(val)四种数据集,我常用AI2D数据集做评测,效果很靠谱。
- 权重重切分
这里有个坑要注意,微调脚本和评测脚本的PP切分方式不一样,直接用微调后的权重会加载失败,必须先对权重进行重切分,命令和之前的权重转换类似,只是参数要改成目标并行配置:
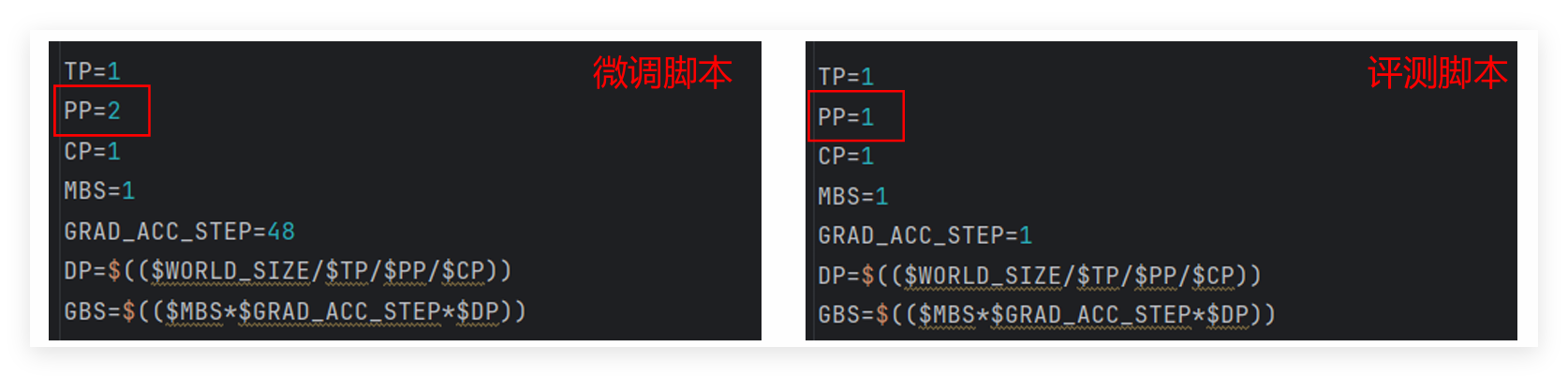
- 评测参数配置
然后修改examples/qwen2.5vl/evaluate_qwen2_5_vl_7b.json,重点配置这几个参数,别写错路径:

- 启动评测
# 安装评测依赖
pip install -e ".[evaluate]"
# 启动评测脚本
bash examples/qwen2.5vl/evaluate_qwen2_5_vl_7b.sh
四、总结与扩展应用
MindSpeed MM 核心优势显著,其全栈优化架构可充分发挥昇腾硬件算力,丰富的模型支持与易用工具链,大幅降低多模态模型微调门槛,新手与资深开发者均可快速完成从环境部署到推理评测的全流程。
其扩展能力强劲,实际场景验证有效:
- 垂直领域适配:医疗影像微调 Qwen2.5-VL 实现病灶识别,工业质检微调 InternVL 缺陷检测准确率超 90%,满足企业落地;
- 多模态 Agent 开发:结合 MindSpeed RL 套件做强化学习,可开发具备图文 / 视频理解与生成能力的智能 Agent;
- 跨模态迁移学习:借助预训练模型通用能力,少量领域数据即可适配新任务,降低数据标注成本。
总的来说,MindSpeed MM是一款非常优秀的多模态模型训练套件,尤其适合昇腾平台的用户,无论是科研实验还是产业落地,都能提供强大的支持。希望这篇实战笔记能帮助大家少踩坑、多提效。
注明:昇腾PAE案例库对本文写作亦有帮助。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)