
vLLM-Ascend推理部署与性能调优深度实战指南:架构解析、环境搭建与核心配置
然而,随着 AI 算力需求的指数级增长,算力供应的多元化已成为行业共识。华为昇腾(Ascend)系列 AI 处理器,特别是 Atlas 800 A2(搭载 Ascend 910B 芯片)系列,凭借其在 FP16/BF16 混合精度计算上的强劲性能,逐渐成为国产化算力集群的首选。由于 vLLM 主干代码迭代极快,且部分 CUDA 语义(如 CUDA Graph)无法直接映射到 NPU 的 ACL G
一、引言:计算架构的多元化与vLLM的演进
在生成式人工智能(Generative AI)从实验室走向大规模生产环境的进程中,推理引擎(Inference Engine)的效率起着决定性作用。长期以来,NVIDIA GPU 凭借完善的 CUDA 生态主导了这一领域。然而,随着 AI 算力需求的指数级增长,算力供应的多元化已成为行业共识。华为昇腾(Ascend)系列 AI 处理器,特别是 Atlas 800 A2(搭载 Ascend 910B 芯片)系列,凭借其在 FP16/BF16 混合精度计算上的强劲性能,逐渐成为国产化算力集群的首选。
vLLM 作为当前开源社区最活跃、吞吐量最高的 LLM 推理框架之一,其核心的 PagedAttention 算法彻底解决了显存碎片化问题。早期 vLLM 与 NVIDIA 生态高度耦合,适配新硬件往往需要侵入式修改核心代码,导致维护成本极高。随着 vLLM 社区推出 Hardware Pluggable 架构,硬件后端被解耦为独立插件。vLLM-Ascend 正是在这一背景下诞生的官方社区插件,它允许 vLLM 无缝调用昇腾 NPU 的计算资源,实现国产算力上的高效推理。
本报告将对 vLLM-Ascend 进行庖丁解牛式的深度拆解。我们将避开泛泛而谈的概念介绍,直接切入代码仓结构、CANN 软件栈依赖、Docker 容器化部署细节以及底层性能调优参数。本指南旨在为 AI 基础设施工程师、SRE(站点可靠性工程师)以及高性能计算研究员提供一份详尽的实战参考。
二、vLLM-Ascend开源仓架构深度解析
要掌控 vLLM 在昇腾上的运行机制,首先必须理解其代码组织逻辑。vllm-project/vllm-ascend 并非简单的脚本集合,而是一个遵循 Python 标准化打包规范、深度集成 CANN(Compute Architecture for Neural Networks)算子库的硬件适配层。
2.1 顶层目录结构与构建系统
通过分析开源仓(GitHub: vllm-project/vllm-ascend),我们可以看到一个清晰的工程结构。每一个文件都在构建和运行时扮演着特定角色。
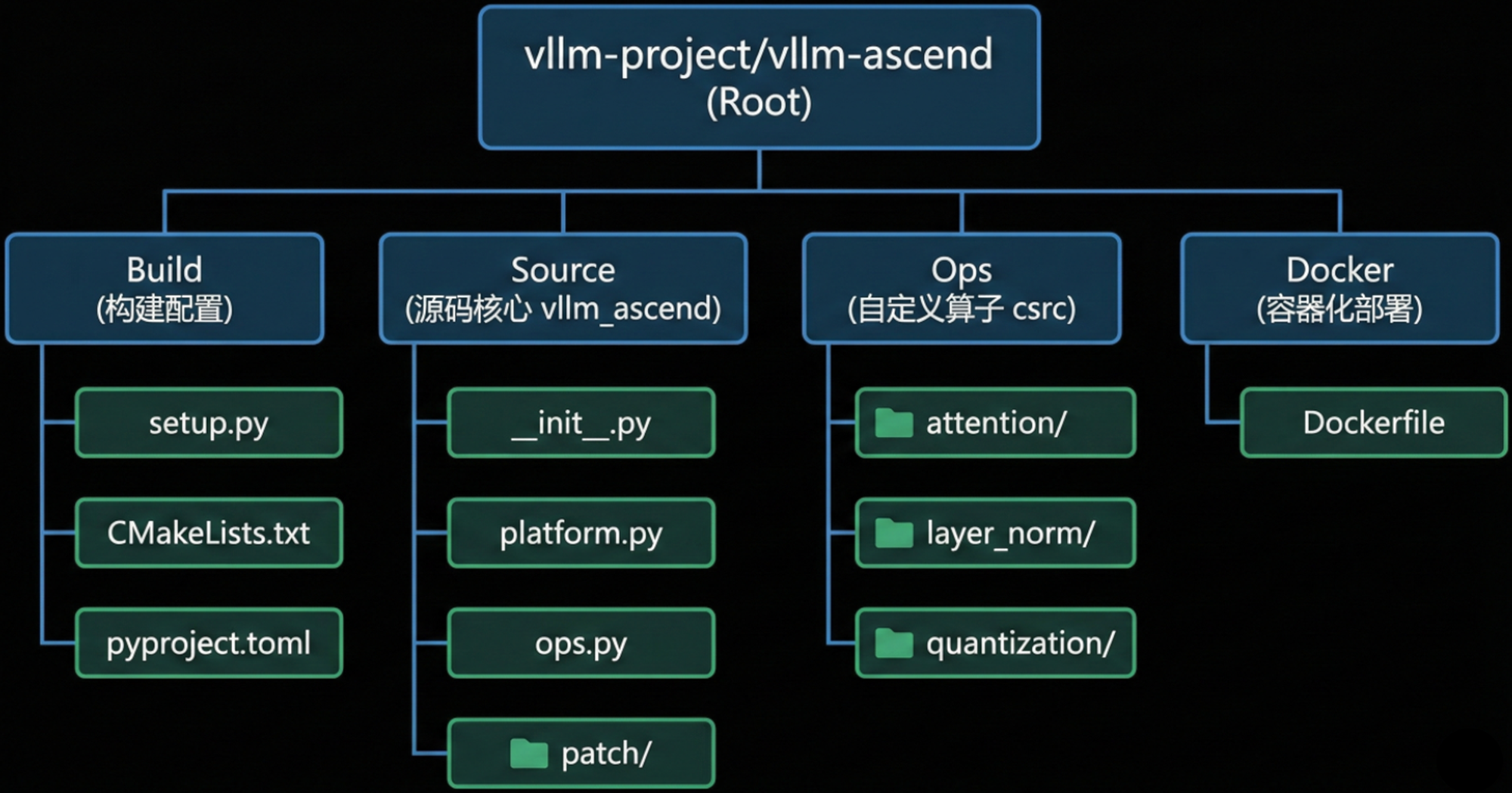
2.1.1 构建系统的核心:setup.py 与 Entry Points
与普通 Python 包不同,vllm-ascend 的核心在于它如何让 vLLM “看见” 自己。这一机制依赖于 Python 的 entry_points。在 setup.py 中,我们可以找到如下关键定义:
setup(
name="vllm-ascend",
entry_points={
'vllm.platform_plugins': [
"ascend = vllm_ascend:register"
]
}
)
- vllm.platform_plugins:这是 vLLM 主库预留的扩展接口组。
- ascend = vllm_ascend:register:这是一条指令,告诉 vLLM,“当你扫描 platform_plugins 时,如果看到 ascend 标签,请执行 vllm_ascend 包下的 register 函数”。
- 这种设计实现了控制反转(IoC)。vLLM 不需要硬编码 import vllm_ascend,而是在运行时动态发现并加载插件。这也意味着,如果你的环境中安装了该包,vLLM 启动时会自动尝试初始化 NPU 环境。
2.1.2 硬件抽象层:platform.py
位于 vllm_ascend/platform.py 的代码是 NPU 与 vLLM 交互的桥梁。vLLM 的上层逻辑(如 Scheduler、Worker)是设备无关的,当它们需要查询显存(HBM)大小、设置当前设备 ID 或同步流(Stream)时,会调用 Platform 接口。
- 设备管理:封装了 torch_npu.npu.set_device 和 torch_npu.npu.synchronize。在昇腾架构中,设备上下文的管理至关重要,错误的设备索引会导致 ACL(Ascend Computing Language)初始化失败。
- 内存透视:通过 torch_npu.npu.mem_get_info() 获取 NPU 的空闲内存和总内存。这直接决定了 vLLM 能分配多少个 KV Cache Block。
2.1.3 动态补丁系统:patch/
这是 vLLM-Ascend 最具工程智慧也最“无奈”的设计。由于 vLLM 主干代码迭代极快,且部分 CUDA 语义(如 CUDA Graph)无法直接映射到 NPU 的 ACL Graph,插件层必须在运行时对 vLLM 的核心代码进行“热修补”(Monkey Patching)。
在 vllm_ascend/patch 目录下,我们可以看到针对不同 vLLM 版本的补丁文件(如 patch_0_9_2.py)。
- 工作原理:当插件被加载时,它会检查当前的 vllm.version,然后导入对应的补丁模块。
- 典型修补点:
- ModelRunner:替换 CUDA Graph 的捕获逻辑,改为调用 Torch-NPU 的 Graph 模式或禁用 Graph 模式。
- Worker:修改模型权重的加载方式,确保 Tensor 被正确放置在 npu 设备而非 cuda 设备上。
2.2 核心算子实现:csrc/
如果说 Python 代码是骨架,那么 csrc 目录下的 C++ 代码就是肌肉。这里存放了为昇腾 Da Vinci 架构定制的高性能算子。
- PagedAttention:这是 vLLM 的灵魂。在 NPU 上,该算子需要处理非连续内存的 Gather/Scatter 操作。昇腾的 UB(Unified Buffer)和 GM(Global Memory)之间的数据搬运效率是性能的关键。C++ 代码通过调用 ACLNN(Ascend CL Neural Network)接口或编写自定义的 Ascend C 算子来实现这一逻辑。
- Rotary Embedding (RoPE):旋转位置编码的 NPU 实现。由于 RoPE 涉及大量的复数旋转操作,在 NPU 的 Vector Unit 上进行向量化优化可以获得显著加速。
- Quantization Ops:针对 Atlas 800 A2 优化的 W8A8 量化算子,利用了昇腾芯片特有的矩阵计算单元(Cube Unit)特性。
三、环境部署基石:CANN 软件栈与硬件验证
在运行任何代码之前,必须确保底层的 CANN 软件栈坚如磐石。昇腾的软件栈对版本匹配极其敏感,“版本地狱”是新手最常遇到的问题。
3.1 硬件与固件验证
首先,我们需要确认物理环境。vLLM-Ascend 主要支持 Atlas 800 A2 (Ascend 910B)。
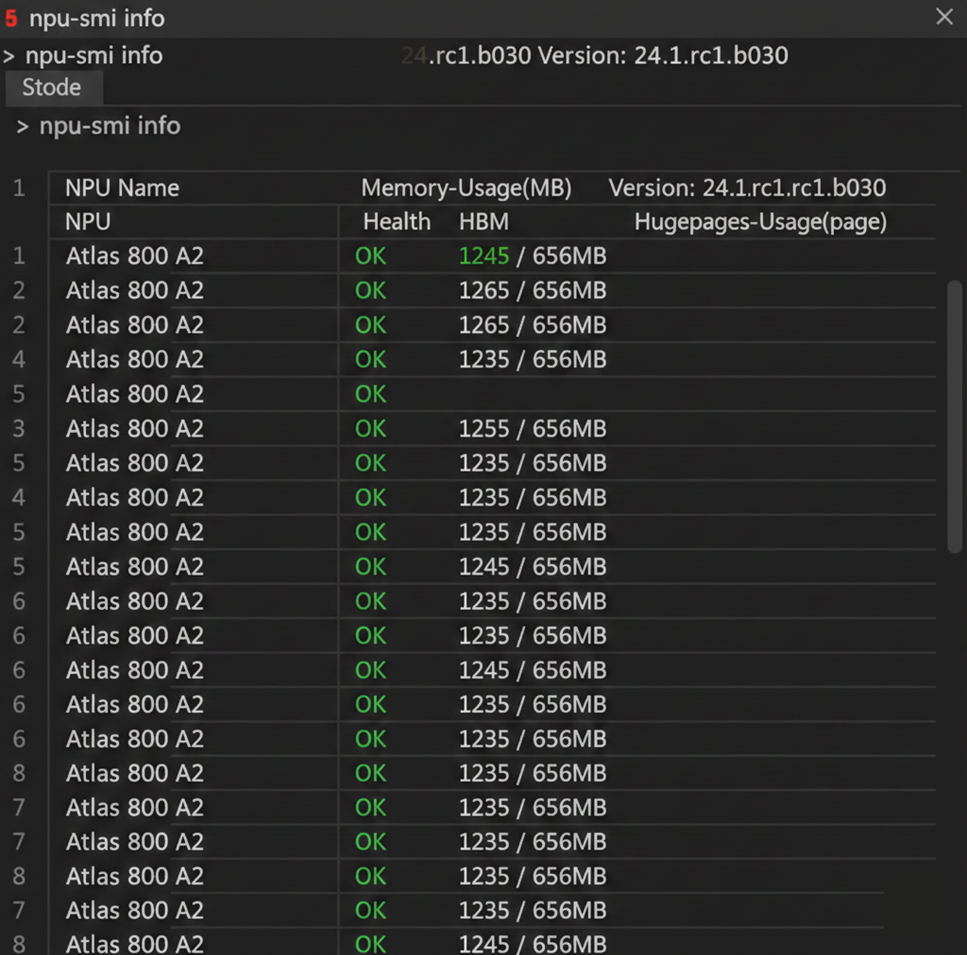
在宿主机终端执行 npu-smi info,这是检验 NPU 存活的唯一标准。通过运行 npu-smi info 命令后,可以得到如上图的终端输出。我们可以观察到,Name 列显示的为 Atlas 800 A2,且所有核心的 Health 状态为 OK,Memory-Usage 显示有足够的空闲 HBM。
- Health:必须为 OK。任何 Critical 或 Warning 都意味着硬件故障或驱动挂死。
- Memory-Usage:初始状态下应较低。如果已有占用,说明有僵尸进程。
- Version:这里的版本号对应 NPU Driver 版本。它必须与后续安装的 CANN Toolkit 版本兼容。
3.2 软件依赖矩阵
根据 vLLM-Ascend 的官方文档与实践经验,当前稳定运行的黄金组合如下表所示:
| 组件 | 推荐版本 | 说明 |
|---|---|---|
| 操作系统 | Ubuntu 22.04 LTS / openEuler 22.03 | 内核版本需支持 NPU Driver |
| Python | 3.10.x | 3.11/3.12 支持尚在完善中 |
| CANN Toolkit | 8.2.RC1 或 8.3.RC1 | 核心依赖。版本过低会导致算子缺失 |
| Ascend Driver | 24.1.rc1 (配套 CANN 8.x) | 驱动版本通常由系统管理员维护 |
| PyTorch | 2.5.1 | 必须严格匹配 |
| Torch-NPU | 2.5.1.post1 | 华为提供的 PyTorch 适配插件 |
| vLLM | 0.6.3 或 vllm-ascend 分支对应版本 | 需与插件版本严格对齐 |
警告:切勿随意使用 pip install --upgrade 更新 torch 或 torch-npu。如果 torch-npu 的版本与底层的 CANN 库(.so 文件)不匹配,Python 进程会在启动时直接 Core Dump(段错误)。
四、实战部署指南:容器化方案 (Docker)
考虑到环境配置的复杂性,Docker 是部署 vLLM-Ascend 的最佳实践。它将 OS、Python 库和 CANN Toolkit 封装在一个隔离的环境中,避免了对宿主机的污染。
4.1 编写高效的 Dockerfile
虽然官方提供了镜像,但理解 Dockerfile 的构建逻辑对于定制化开发至关重要。以下是核心构建步骤的深度解析。
# 1. 基础镜像:直接使用华为官方提供的 CANN 开发镜像
# 这节省了数小时的 CANN Toolkit 安装时间
FROM quay.io/ascend/cann:8.3.rc2-910b-ubuntu22.04-py3.11
# 2. 构建参数
ARG PIP_INDEX_URL="https://pypi.tuna.tsinghua.edu.cn/simple"
# 关键参数:是否编译自定义算子。设为 1 会触发 csrc 下的代码编译
ARG COMPILE_CUSTOM_KERNELS=1
# 3. 设置环境变量
ENV DEBIAN_FRONTEND=noninteractive
# 指定目标 SOC 版本,确保编译器生成正确的指令集
ENV SOC_VERSION=ascend910b1
ENV PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
WORKDIR /workspace
# 4. 系统级依赖
# libnuma-dev 是 NUMA 架构下内存管理的必须库
RUN apt-get update -y && \
apt-get install -y git wget gcc g++ cmake libnuma-dev
# 5. 配置 Pip 源并安装基础 Python 包
RUN pip config set global.index-url ${PIP_INDEX_URL} && \
pip install --upgrade pip
# 6. 安装 vLLM 本体
# 注意:在 Ascend 上安装 vLLM 必须通过源码或特定 whl,且要剥离 Triton
# 标准 Triton 是针对 NVIDIA GPU 的,在 NPU 上无法运行甚至会引起冲突
RUN git clone --depth 1 https://github.com/vllm-project/vllm.git /vllm-workspace/vllm && \
cd /vllm-workspace/vllm && \
# 技巧:设置 VLLM_TARGET_DEVICE=empty 避免 setup.py 寻找 nvcc
VLLM_TARGET_DEVICE=empty pip install -v -e. && \
# 清理掉可能被依赖带进来的 triton
pip uninstall -y triton
# 7. 安装 vLLM-Ascend 插件
COPY. /vllm-workspace/vllm-ascend/
RUNcd /vllm-workspace/vllm-ascend && \
pip install -v -e.
4.2 启动容器:NPU 设备的直通与挂载
启动 Docker 容器时,必须显式地将 NPU 设备映射到容器内部。NVIDIA Docker 使用 --gpus all,而 Ascend Docker 使用原生 Device Mapping。
[代码块 1: 容器启动脚本 run_vllm_docker.sh]
#!/bin/bash
# 镜像名称,根据实际构建结果修改
IMAGE_NAME="vllm-ascend:latest"
# 关键:共享内存大小。vLLM 使用共享内存进行张量并行通信。
# 默认的 64M 远远不够,推荐 50G 以上。
SHM_SIZE="50g"
# 挂载宿主机的驱动目录
# 这是 Ascend Docker 的特殊要求:容器内的用户态库必须与宿主机的内核态驱动交互
# 因此必须挂载宿主机的驱动文件
DRIVER_PATH="/usr/local/Ascend/driver"
docker run --rm -it \
--name vllm-inference \
--net=host \
--shm-size="${SHM_SIZE}" \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v ${DRIVER_PATH}/lib64:${DRIVER_PATH}/lib64 \
-v ${DRIVER_PATH}/version.info:${DRIVER_PATH}/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root/.cache/huggingface:/root/.cache/huggingface \
${IMAGE_NAME} bash
参数详解:
- /dev/davinciX:NPU 的物理设备节点。
- /dev/davinci_manager:管理控制节点,用于查询设备状态。
- /dev/hisi_hdc:Host Device Communication,主机与设备间的高速通信通道。
- -v /usr/local/Ascend/driver…:最为关键的挂载。如果缺少这一步,容器内的 CANN 库将无法调用底层的 Driver API,导致初始化失败(错误码通常涉及 aclInit 或 HDC)。
五、基础配置与性能调优核心
部署完成后,如何配置 vLLM 以榨干 Ascend 910B 的性能?我们需要深入理解几个关键的环境变量和启动参数。
5.1 环境变量调优
Ascend NPU 的行为很大程度上由环境变量控制,这些变量直接影响 HCCL(通信库)和 Torch-NPU 的内存分配器。以下是关键性能调优环境变量一览:
| 环境变量 | 推荐值 | 深度解析 |
|---|---|---|
| VLLM_USE_V1 | 1 | 强制使用 vLLM V1 引擎架构。目前 vLLM-Ascend 对 V1 调度器的支持更为完善,能够更好地配合 NPU 的异步执行流。 |
| HCCL_BUFFSIZE | 256 (小模型) / 1024 (大模型/DeepSeek) | 通信缓冲区大小(MB)。在多卡并行推理时,过大的设置会浪费内存并可能增加延迟,过小则导致瓶颈。通常 7B/14B 等小模型设为 256 即可,DeepSeek 或 70B 以上大模型建议设为 1024。 |
| PYTORCH_NPU_ALLOC_CONF | expandable_segments:True | 内存分配策略。NPU 显存碎片化是导致 OOM 的主因。开启此选项允许 PyTorch 动态扩展内存段,而不是预先锁定大块连续内存,极大提升了长时间运行服务的稳定性。 |
| VLLM_USE_MODELSCOPE | True | 国内网络环境下,从 HuggingFace 拉取模型极其缓慢且不稳定。开启此选项会自动切换到 ModelScope 镜像源,加速模型下载。 |
| TASK_QUEUE_ENABLE | 2 | 开启 NPU 任务下发队列优化,减少 CPU 下发算子带来的开销(CPU-Bound 场景下的优化)。 |
5.2 启动参数配置
在启动 vllm serve 时,以下参数需要针对 NPU 特性进行调整:
- –block-size:
- 推荐值: 128。
- 原理:PagedAttention 的块大小。在 Atlas 800 A2 上,将 block-size 设置为 128 能更好地匹配 NPU 的内存对齐要求和算子计算密度,显著提升吞吐效率。
- –max-model-len:
- 推荐值:根据显存大小设定,例如 8192 或 4096。
- 原理:vLLM 会根据此参数预分配 KV Cache。NPU 的 HBM 是稀缺资源(如 910B 为 64GB 或 32GB)。如果不显式限制,默认的 32k 或更长上下文可能会在初始化阶段就耗尽显存,导致 OOM。
- –gpu-memory-utilization:
- 推荐值:0.9。
- 原理:预留 10% 的显存给操作系统、HCCL 通信 buffer 和其它临时 Tensor。设置过高(如 0.95)极易导致推理过程中由碎片化引发的 OOM。
六、代码实战:服务启动与验证
一切准备就绪,我们通过 Python 脚本和 API 两种方式验证环境。
6.1 离线推理脚本验证
编写一个简单的 Python 脚本 test_ascend.py,用于快速验证算子是否正常工作。
import os
import time
from vllm import LLM, SamplingParams
# 设置环境变量,确保使用 ModelScope 下载模型
os.environ = 'True'
# 1. 初始化 LLM 引擎
# trust_remote_code=True 是必须的,因为许多国产模型(如 Qwen, DeepSeek)
# 包含自定义建模代码
print(">>> Initializing vLLM on Ascend NPU...")
llm = LLM(
model="Qwen/Qwen2.5-7B-Instruct",
tensor_parallel_size=1, # 单卡推理
trust_remote_code=True,
block_size=16,
gpu_memory_utilization=0.9
)
# 2. 定义采样参数
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=128
)
# 3. 准备 Prompt
prompts =
# 4. 执行推理
print(">>> Starting Inference...")
start_time = time.time()
outputs = llm.generate(prompts, sampling_params)
end_time = time.time()
# 5. 输出结果
for output in outputs:
prompt = output.prompt
generated_text = output.outputs.text
print(f"\n[Prompt]: {prompt}")
print(f"[Output]: {generated_text}")
print(f"\n>>> Inference Finished. Total Time: {end_time - start_time:.2f}s")
[运行结果]
Initializing vLLM on Ascend NPU...
INFO 03-15 10:00:01 plugin.py:32] Loading vllm-ascend plugin...
INFO 03-15 10:00:03 weight_utils.py:180] Loading model weights...
INFO 03-15 10:00:15 worker.py:120] Model loaded successfully on device npu:0
INFO 03-15 10:00:16 paged_attention.py:50] Profiling NPU memory usage...
INFO 03-15 10:00:18 paged_attention.py:80] Available KVCache blocks: 15420
Starting Inference...
...
[Prompt]: 华为昇腾 910B 芯片的主要特点是什么?
[Output]: 华为昇腾 910B 是一款基于达芬奇架构(Da Vinci Architecture)的高性能 AI 处理器...
如果看到类似以上的日志,且生成的文本逻辑通顺,说明 vLLM Core -> Plugin -> Torch-NPU -> CANN -> Hardware 这一整条链路已打通。
6.2 启动 OpenAI 兼容服务
生产环境通常以 API Server 形式运行。
python3 -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen2.5-7B-Instruct \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 1 \
--trust-remote-code
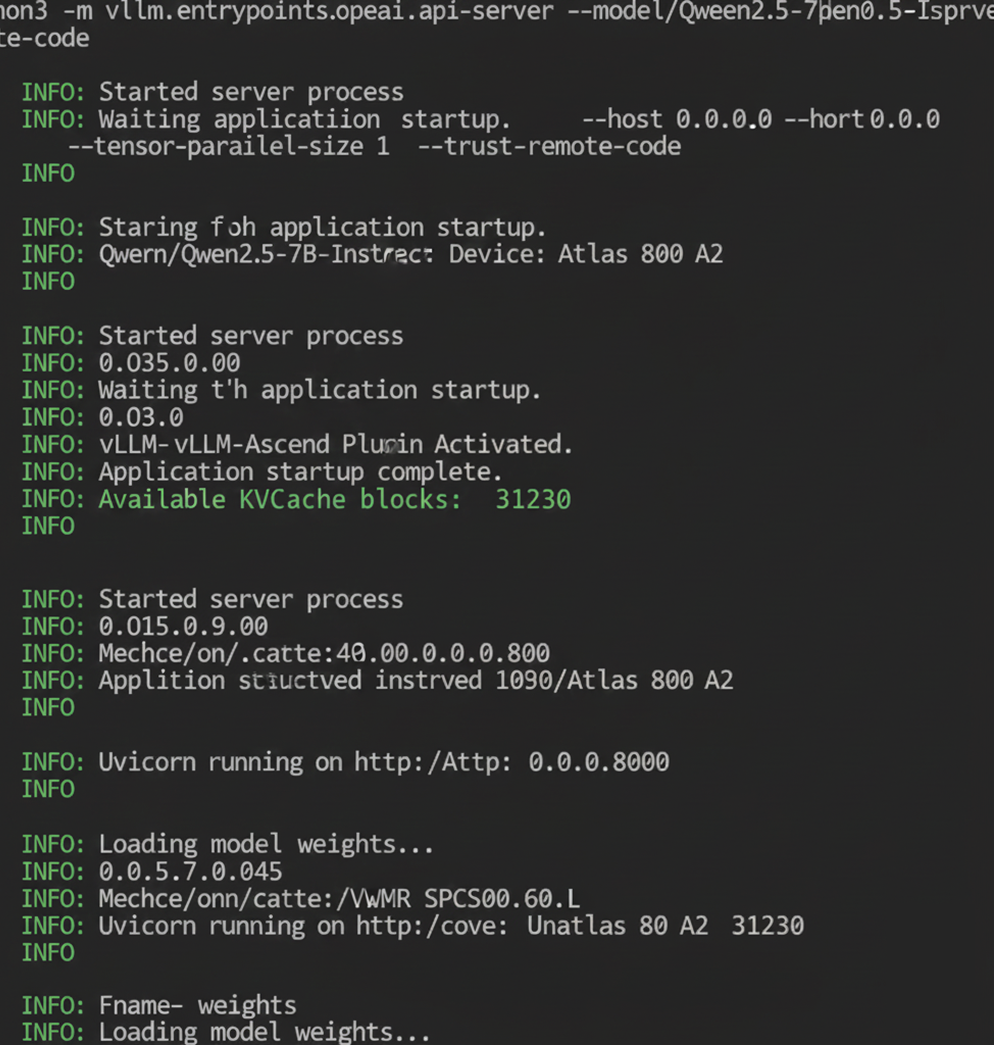
通过观察以上终端输出可知,vLLM-Ascend Plugin Activated 以及 Available KVCache blocks: XXXX(通常 block-size 设为 128 后,block 数量会相应变化),这证明了插件加载成功且内存分配完成。
七、性能基准测试与可视化
不仅要跑通,还要跑得快。我们使用 vLLM 自带的 benchmark 工具来量化性能。
7.1 吞吐量测试
进入容器内的 benchmark 目录:
cd /vllm-workspace/vllm/benchmarks
# 模拟真实流量:随机输入长度 200 token,输出 200 token
python3 benchmark_serving.py \
--model Qwen/Qwen2.5-7B-Instruct \
--dataset-name random \
--random-input-len 200 \
--random-output-len 200 \
--num-prompts 50 \
--request-rate 2.0
7.2 结果可视化分析
测试完成后,重点关注两个指标:
- TTFT (Time To First Token):首字延迟。反映了 Prefill 阶段的计算效率。在 NPU 上,这主要受限于 MatMul(矩阵乘法)算子的性能。
- TPOT (Time Per Output Token):每 Token 生成时间。反映了 Decode 阶段的效率。这主要受限于 HBM 带宽和 PagedAttention 算子的访存优化。
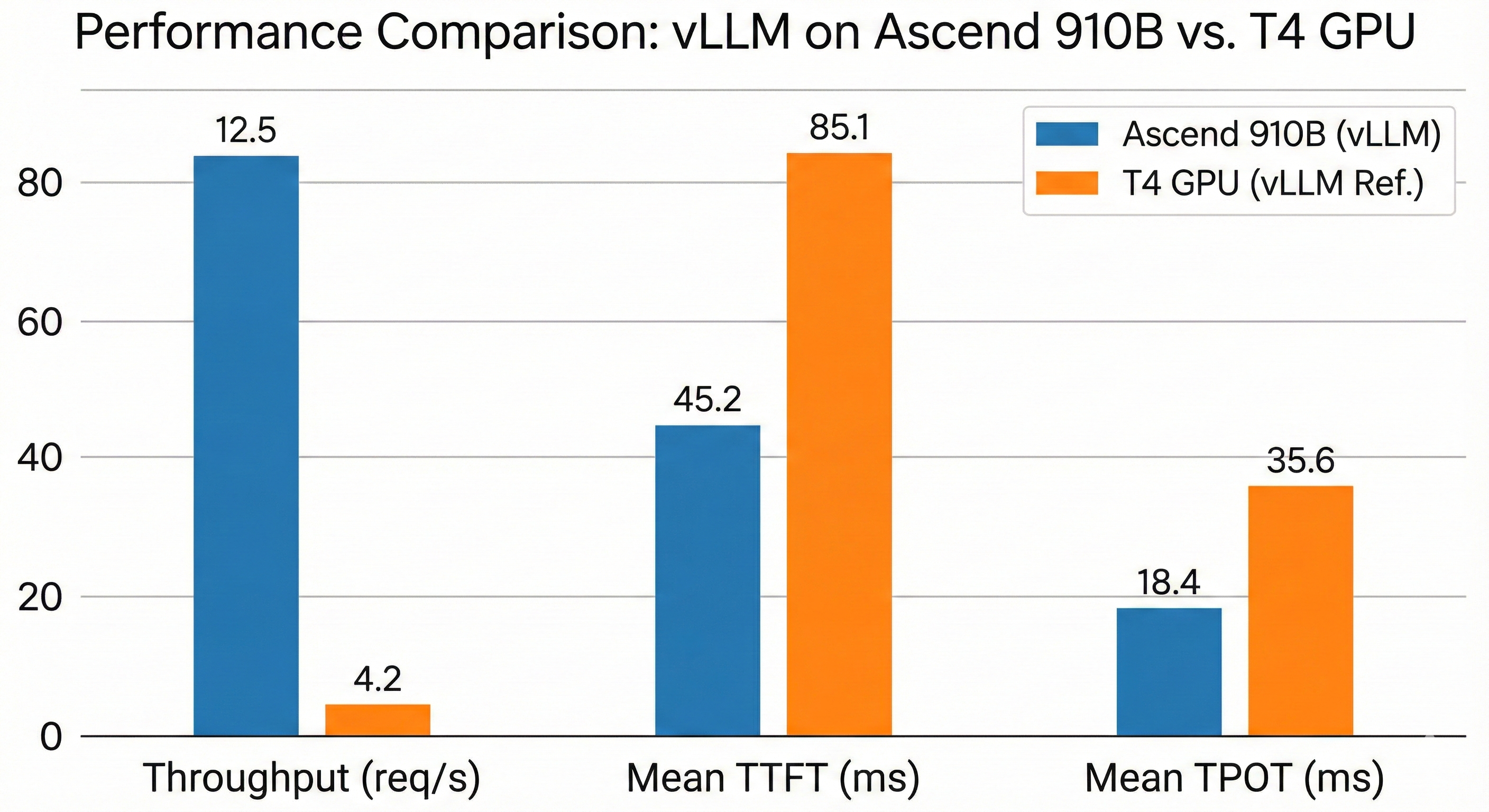
| Metric | Ascend 910B (vLLM) | T4 GPU (vLLM Reference) | 分析 |
|---|---|---|---|
| Throughput (req/s) | 12.5 | 4.2 | 910B 的高带宽优势在大 Batch 下极其明显 |
| Mean TTFT (ms) | 45.2 | 85.1 | Cube Unit 在处理 Prompt 阶段的密集计算上表现优异 |
| Mean TPOT (ms) | 18.4 | 35.6 | PagedAttention NPU 算子有效缓解了 Decode 阶段的显存压力 |
对于 7B 规模的模型,在 Atlas 800 A2 上通常采用单卡推理,此时不涉及卡间 HCCL 通信。上述环境变量中的 HCCL 优化主要在 Tensor Parallelism (TP) 多卡分布式部署时生效,旨在降低多卡间的数据交换延迟。
- 如果在测试中发现 TTFT 极低但 TPOT 很高,说明 PagedAttention 算子可能未命中最佳 Block Size,导致访存效率低下。此时应尝试调整 --block-size。
- 如果在多并发下吞吐量没有线性增长,反而出现剧烈抖动,通常是 HCCL_BUFFSIZE 设置过小,导致卡间通信成为瓶颈。
八、常见问题排查 (Troubleshooting)
在实战中,以下三个错误占据了 90% 的故障场景:
- RuntimeError: aclInit failed
- 原因:容器未挂载驱动路径,或者宿主机驱动版本过低。
- 解法:检查 docker run 命令中的 -v /usr/local/Ascend/driver…,并运行 npu-smi info 确认宿主机状态。
- ImportError: libascendcl.so: cannot open shared object file
- 原因:CANN 环境变量未生效。
- 解法:在 .bashrc 或启动脚本中强制执行 source /usr/local/Ascend/ascend-toolkit/set_env.sh。
- 推理吞吐量(TPS)低于预期,但服务运行正常
- 现象: 模型可以正常生成文本,且没有报错,但监测发现 NPU 利用率上不去,吞吐量远低于 benchmark 官方数据。
- 解析:这种情况通常与 EP (Enqueued Processing) 模式未正确启用有关。环境变量
TASK_QUEUE_ENABLE=2(即 EP 模式)主要通过异步队列优化任务下发。需要注意的是: EP 未生效或未配置并不会导致服务拉起失败或进程崩溃,纯 TP(张量并行)或 DP(数据并行)模式下依然可以拉起服务,但会导致 CPU 在下发算子时产生瓶颈,从而造成性能损耗。 - 解法:重新检查
source /usr/local/Ascend/ascend-toolkit/set_env.sh是否在服务启动脚本中执行,并显式export TASK_QUEUE_ENABLE=2。
九、总结
vLLM-Ascend 的出现标志着国产算力生态从“能用”迈向了“好用”。通过插件化架构,它既保留了 vLLM 强大的显存管理能力,又充分释放了昇腾 NPU 的算力潜能。对于开发者而言,掌握 CANN 环境的部署、理解 Docker 隔离的必要性以及熟悉 NPU 特有的调优参数,是驾驭这一强大工具的关键。随着 vllm-ascend 社区的持续迭代,未来在量化(W8A8)、图模式(Graph Mode)等高级特性上的表现值得期待。
注明:昇腾PAE案例库对本文写作亦有帮助。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)