
昇腾310P平台强化学习训练环境搭建实战:基于Qwen2.5-7B的完整部署流程
这次在昇腾310P上搭环境,前前后后折腾了好几天。回过头看,主要就是几个地方容易出问题:Docker这块最坑的是容器创建后直接退出,开始根本没想到要加个让它一直跑着。还有就是镜像ID别搞错了,查出来是啥就用啥,别直接复制拉取日志里的Digest。版本匹配这个真的要严格按照来。PyTorch 2.5.1配torch-npu 2.5.1rc1,差一个小版本后面都是坑。setuptools也得降到65.
引
最近在昇腾310P上搭建强化学习训练环境,从Docker容器到模型训练启动,整个流程踩了不少坑。这篇文章记录了基于Qwen2.5-7B模型的完整部署过程,包括MindSpeed-RL框架集成、vLLM-Ascend推理引擎配置等关键步骤。
环境搭建是昇腾平台 AI 训练流程的基础,需确保所有依赖组件正确安装并配置,核心目标是构建一个隔离且适配昇腾硬件的运行环境。整个流程用Docker做环境隔离,主要是为了避免系统依赖冲突。虽然多了一层容器,但后期复现环境会方便很多。
一、Docker环境准备
1.1 镜像选择与下载
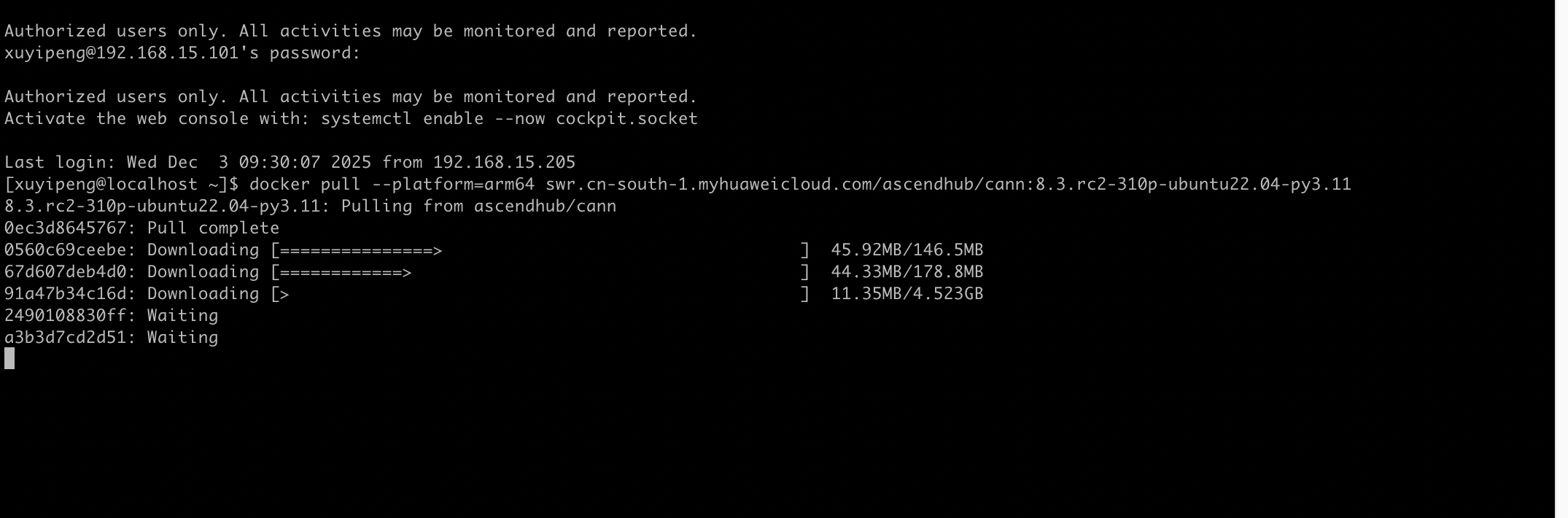
昇腾社区提供了适配不同硬件 / 系统的 CANN 镜像,需选择兼容的 Ubuntu 版本(OpenEuler 版本易出现兼容性报错),准备一台计算机,要求安装的docker版本必须为1.11.2及以上: 下载镜像,我们用的是ARM选择:
docker pull --platform=arm64 swr.cn-south-1.myhuaweicloud.com/ascendhub/cann:8.3.rc2-310p-ubuntu22.04-py3.11
x86架构: docker pull --platform=amd64 swr.cn-south-1.myhuaweicloud.com/ascendhub/cann:8.3.rc2-310p-ubuntu22.04-py3.11
自适应架构: docker pull swr.cn-south-1.myhuaweicloud.com/ascendhub/cann:8.3.rc2-310p-ubuntu22.04-py3.11
在本地服务器执行镜像拉取命令:
1.2 创建容器
拉取镜像后,需通过挂载昇腾设备、映射本地目录创建容器,但初次操作易出现两类核心问题,需逐一排查:

坑1: 镜像ID混淆
一开始我直接用了拉取日志里的Digest值(sha256:f6294c42b93bb5026fab064bd68dc2ab93a9054588285085eda7b907661ec175),结果Docker报"No such image"。
# 错误命令(镜像ID不匹配)
docker run -it -d --net=host --shm-size=1g \
--privileged \
--name xyp1 \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/sbin:/usr/local/sbin:ro \
-v /path-to-weights:/path-to-weights:ro \
-v /home:/home \
sha256:f6294c42b93bb5026fab064bd68dc2ab93a9054588285085eda7b907661ec175
正确做法是用docker images | grep ascendhub/cann查看实际镜像ID。我这里实际ID是66fa9b68edb9,并替换权重路径占位符为实际路径(/home/xuyipeng/weights):

坑2: 容器秒退
用正确ID创建容器后,执行docker exec时提示"container is not running"。查了下状态发现容器已经退出,但ExitCode是0,没有报错。
原因是默认的bash进程执行完就退出了,需要加个持续运行的任务。
1.3 正确的创建方式
针对上述问题,删除异常容器并重新创建,核心优化点:① 使用正确镜像 ID;② 新增bash -c "tail -f /dev/null"保证容器持续运行;③ 替换权重路径为实际本地路径。完整命令如下:
# 1. 清理异常容器
docker rm -f xyp1
# 2. 重新创建容器(修复版)
docker run -it -d --net=host --shm-size=1g \
--privileged \
--name xyp1 \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/sbin:/usr/local/sbin:ro \
-v /home/xuyipeng/weights:/path-to-weights:ro \
-v /home:/home \
66fa9b68edb9 \
bash -c "tail -f /dev/null" # 关键:保证容器持续运行,不退出
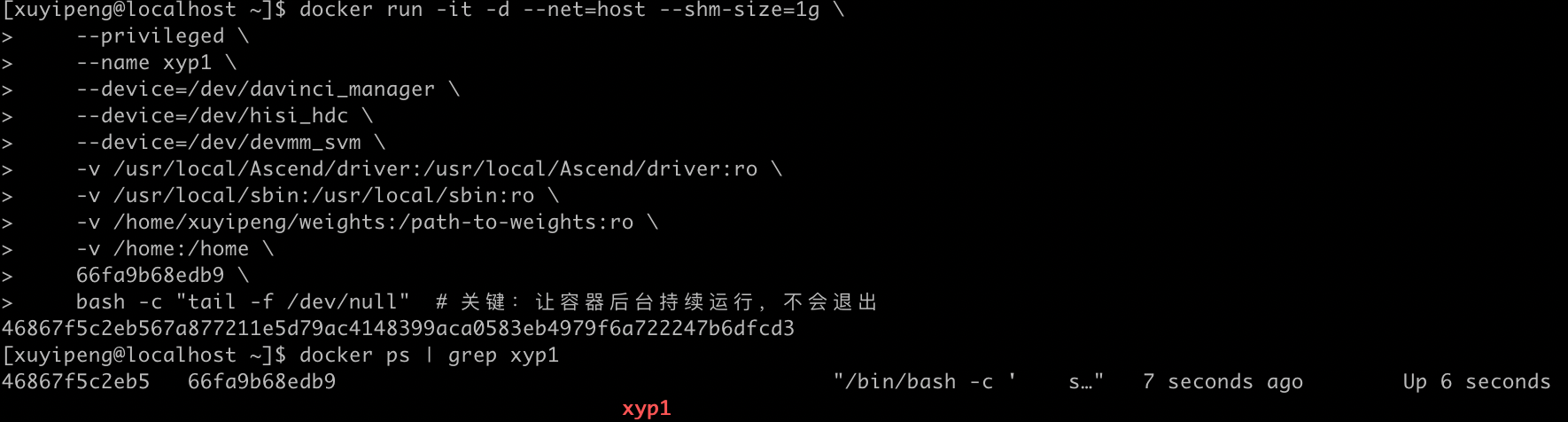
创建成功后,执行docker ps | grep xyp1验证,终端显示容器状态为Up,说明容器已稳定运行。
1.4 进入容器
容器稳定运行后,执行以下命令进入交互式终端,开始初始化训练环境:
docker exec -it xyp1 bash
进入容器后,首先尝试安装 Miniconda(适配 arm64 架构),为后续 Python 依赖配置做准备:
# 下载arm64架构Miniconda安装包
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh

二、Python环境配置
Python 环境是昇腾平台训练代码运行的核心基础,Conda 可有效管理 ARM 架构下的依赖版本隔离,本部分基于已运行的昇腾容器,完成 Miniconda 安装配置、环境变量加载及 Python 3.10 环境创建,解决 ARM 架构下 Conda 初始化的典型问题。
2.1 安装Miniconda
容器内已下载 Miniconda 安装包(Miniconda3-latest-Linux-aarch64.sh),执行安装脚本并完成交互配置,步骤如下:
bash Miniconda3-latest-Linux-aarch64.sh
安装过程需依次完成以下交互操作,避免因误输入导致安装失败:
- 询问是否初始化conda时输入
yes - 安装路径直接回车用默认的
/root/miniconda3,不要乱输其他东西(会报空格错误) - 安装完成后,出现 “Do you wish to update your shell profile to automatically initialize conda?” 时,输入
yes让 Conda 自动配置环境变量; - 终端提示 “> For changes to take effect, close and re-open your current shell. <”,说明 Miniconda 安装完成。
2.2 激活conda环境
安装完成后直接执行conda命令会提示bash: conda: command not found:
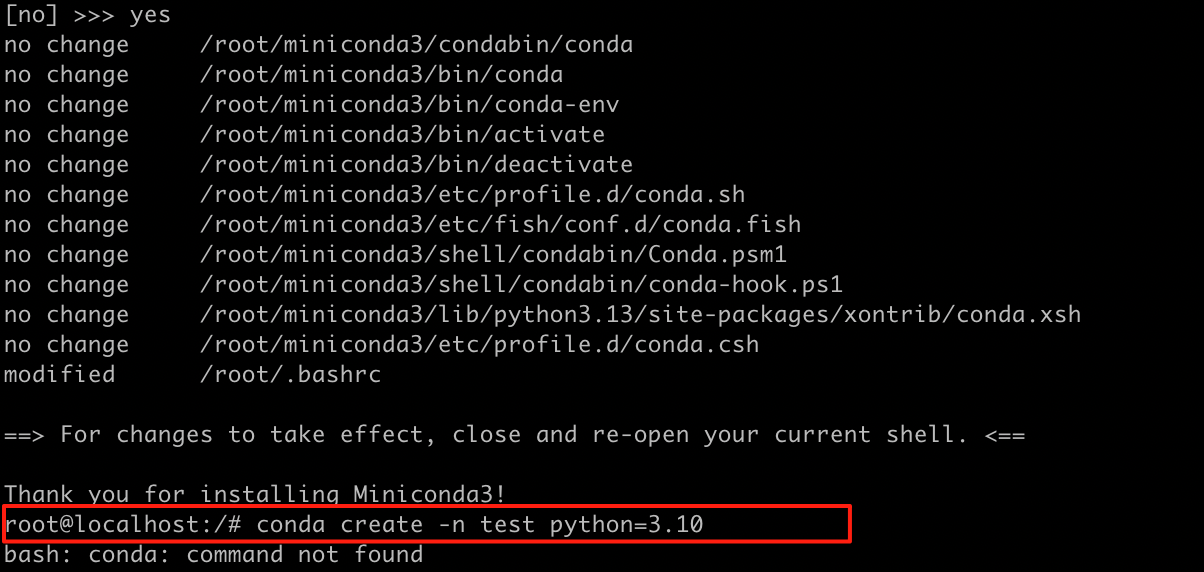
原因是当前 shell 未加载/root/.bashrc中新增的 Conda 环境变量,执行以下命令手动加载:
# 加载环境变量,使conda命令生效
source ~/.bashrc
# 验证Conda安装(输出版本号即配置成功)
conda --version

看到版本号就说明配置好了,终端提示符会变成(base)。
2.3 创建Python 3.10环境
Conda 环境变量加载成功后,创建名为test的 Python 3.10 虚拟环境,适配昇腾训练依赖:
conda create -n test python=3.10
依次输入a接受 Anaconda 仓库服务条款;按y确认下载依赖包(终端显示 Python 3.10 及依赖列表,总大小约 15.3MB):
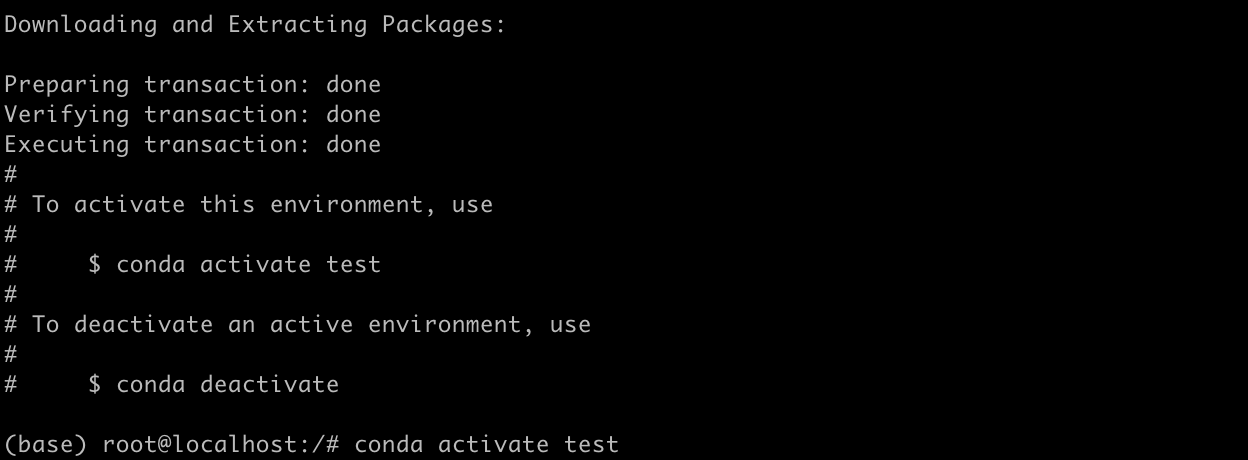
按提示输入a接受条款,输入y确认下载。然后激活环境:
conda activate test
提示符会从(base)变成(test)。
三、安装PyTorch与昇腾支持
PyTorch 及其昇腾适配版本(torch-npu)是昇腾 310P 硬件上运行 AI 训练代码的核心框架,版本需严格匹配(PyTorch 2.5.1 对应 torch-npu 2.5.1rc1),才能充分调用 NPU 算力,同时保证与 MindSpeed-RL 等框架的兼容性。
3.1 安装PyTorch 2.5.1
从ModelScope下载预编译的ARM64版本(避免自己编译):
git clone https://oauth2:A_HhBt9-qWdhdTFy66k9@www.modelscope.cn/DanteQ/torch2.5.1.git

进入仓库目录,安装 ARM64 架构的 PyTorch 2.5.1:
cd torch2.5.1
pip install torch-2.5.1-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
安装过程中 pip 会自动解析依赖并下载缺失包(filelock、typing-extensions、networkx、jinja2、sympy 等),终端最终输出:
Successfully installed MarkupSafe-3.0.3 filelock-3.20.0 fsspec-2025.12.0 jinja2-3.1.6 mpmath-1.3.0 networkx-3.4.2 sympy-1.13.1 torch-2.5.1 typing-extensions-4.15.0,说明 PyTorch 核心包安装完成。
3.2 安装torch-npu
这是华为适配的PyTorch NPU插件,版本必须和PyTorch对应:
安装基础依赖包,补全 torch-npu 的安装前置条件:
pip install pyyaml setuptools
安装 torch-npu 2.5.1rc1:
pip install torch-npu==2.5.1rc1

四、编译安装Apex
Apex是混合精度训练工具,昇腾版针对NPU做了优化,可充分发挥昇腾 310P 的混合精度算力,降低训练显存占用。本部分基于已配置的 PyTorch-NPU 环境,完成昇腾专用 Apex 的源码编译、依赖适配及安装验证,解决 ARM64 架构下编译的核心问题。
4.1 版本检查
昇腾版 Apex 编译对 setuptools 版本有严格要求,需先检查并调整版本,确保版本≤65.7.0,不然编译会失败:
# 激活test环境(Python 3.10 + PyTorch-NPU)
conda activate test
# 检查setuptools版本
pip show setuptools | grep Version
4.2 克隆源码
昇腾官方在 Gitee 维护了适配 NPU 的 Apex 分支,需克隆指定仓库:
# 克隆昇腾专用Apex项目(master分支为最新适配版)
git clone -b master https://gitee.com/ascend/apex.git
# 进入源码目录
cd apex/

4.3 编译
编译前需确保 PyTorch 已正确安装(torch 2.5.1 + torch-npu 2.5.1rc1),执行昇腾定制编译脚本:
bash scripts/build.sh --python=3.10
这里需要保持网络流畅,要不然很容易失败。
4.4 安装
pip install --upgrade apex-0.1+ascend-cp310-cp310-linux_aarch64.whl
看到"Successfully installed apex-0.1+ascend"就OK了。
五、安装vLLM与vLLM-Ascend
vLLM 是高性能 LLM 推理引擎,昇腾适配版 vLLM-Ascend 针对 NPU 硬件做了算子优化,可支撑训练过程中的实时评估 / 推理环节:
5.1 安装标准vLLM
vLLM 编译依赖 C/C++ 构建工具,需先安装容器内缺失的编译组件:
conda activate test
5.2 安装vLLM-Ascend
标准 vLLM 需指定版本并关闭设备检测(避免默认检测 CUDA 导致安装失败),步骤如下:
# 安装构建依赖
pip install -r requirements-build.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装vLLM(源码编译安装)
pip install . -i https://pypi.tuna.tsinghua.edu.cn/simple
vLLM-Ascend 基于 v0.7.3 开发,需 checkout 指定 commit保证与昇腾 NPU 兼,这里以开发模式安装即-e,方便后续适配修改:
安装过程中会自动编译昇腾 NPU 专用算子,终端输出Building wheels for collected packages: vllm-ascend,成功后显示Successfully installed vllm-ascend-0.7.3。
5.3 验证安装
导入验证
python -c "import vllm; from vllm_ascend import init_npu; print('vLLM-Ascend导入成功')"
输出如下:

说明安装完成,若提示ModuleNotFoundError: No module named 'vllm_ascend',需重新执行pip install -e .。
六、模型部署流程
模型部署是昇腾 310P 平台上运行强化学习训练的核心环节,需完成 MindSpeed 生态组件集成、模型 / 数据集准备、权重转换、数据预处理及训练启动,全流程需严格匹配版本和路径配置,确保各组件协同调用昇腾 NPU 算力。以下是可落地的详细操作指南,包含关键参数配置、路径适配及异常排查。
6.1 获取源码
MindSpeed-RL(昇腾强化学习框架)需集成 MindSpeed(核心框架)、Megatron-LM(分布式训练)、MindSpeed-LLM(大模型适配),且需 checkout 指定 commit 保证版本兼容,步骤如下:
激活test环境(PyTorch-NPU + Apex + vLLM-Ascend):conda activate test 克隆MindSpeed:
cd MindSpeed
git checkout 0dfa0035ec54d9a74b2f6ee2867367df897299df # 验证过的稳定版本
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install -e . # 开发模式安装,支持后续修改cp -r mindspeed ../MindSpeed-RL/ # 复制到MindSpeed-RL目录集成cd ..# 3. 克隆Megatron-LM(分布式训练框架)并切换指定版本git clone https://github.com/NVIDIA/Megatron-LM.git
cd Megatron-LM
git checkout core_r0.8.0 # 适配昇腾的版本cp -r megatron ../MindSpeed-RL/ # 集成到MindSpeed-RLcd ..# 4. 克隆MindSpeed-LLM(昇腾大模型适配层)并切换稳定commitgit clone https://gitee.com/ascend/MindSpeed-LLM.git
cd MindSpeed-LLM
git checkout 421ef7bcb83fb31844a1efb688cde71705c0526e # 适配Qwen2.5-7B的版本cp -r mindspeed_llm ../MindSpeed-RL/ # 集成到MindSpeed-RLcd ..
进入MindSpeed-RL目录cd MindSpeed-RL:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install antlr4-python3-runtime==4.7.2 --no-deps
6.2 下载模型和数据集
Qwen2.5-7B-Instruct(基础模型)和 Orz Math 57K(数学推理数据集)是强化学习训练的核心资源,需确保下载完整且路径可访问:
下载 Qwen2.5-7B 基础模型(ModelScope):
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen2.5-7B-Instruct.git
下载耗时说明:模型权重约 13GB,建议在宿主机下载后挂载到容器(-v /宿主机模型路径:/容器模型路径),避免容器内重复下载;
下载 Orz Math 57K 数据集:
git clone https://gitcode.com/saulcy/orz_math_57k.git
建议在宿主机下载后挂载到容器,避免重复下载。
6.3 权重转换
Qwen2.5-7B 的 HuggingFace 格式权重需转换为 Megatron 格式,才能适配昇腾分布式训练框架, 进入MindSpeed-RL目录cd MindSpeed-RL;加载CANN环境变量:source /usr/local/Ascend/ascend-toolkit/set_env.sh,最后执行转换脚本bash examples/ckpt/ckpt_convert_qwen25_hf2mcore.sh
cd MindSpeed-RL
source /usr/local/Ascend/ascend-toolkit/set_env.sh
bash examples/ckpt/ckpt_convert_qwen25_hf2mcore.sh
6.4 数据预处理
原始 Orz Math 数据集需转换为算法适配的二进制格式,提升训练数据读取效率,步骤如下:
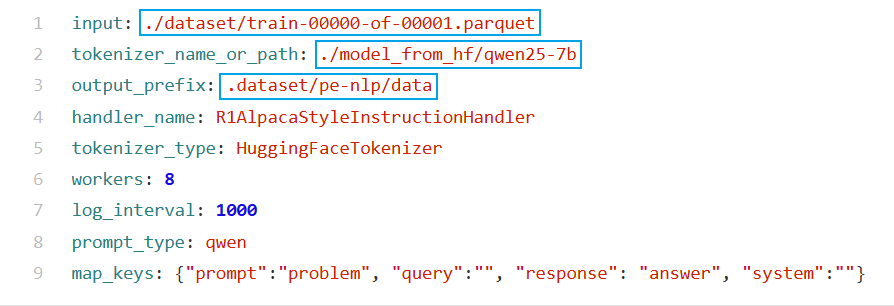
修改配置文件configs/datasets/grpo_pe_nlp.yaml,主要改三个路径:
raw_data_path: 原始数据路径processed_data_path: 处理后数据保存路径vocab_file: 词表文件路径
执行数据预处理
进入MindSpeed-RL目录cd MindSpeed-RL,执行预处理脚本:
bash examples/data/preprocess_data.sh grpo_pe_nlp
在终端看到输出Preprocess done, total samples: 57000,这就代表已经启动成功了。
6.5 启动训练
修改训练配置文件后,执行启动脚本,拉起基于昇腾 NPU 的强化学习训练,编辑MindSpeed-RL/configs/grpo_trainer_qwen25_7b.yaml,核心修改项:
model.ckpt_path:转换后的 Megatron 格式权重路径;data.data_path:预处理后的数据集路径;train.npu_device:NPU 设备编号(单卡设为 0);train.batch_size:单卡批次大小(昇腾 310P 建议设为 8/16,根据内存调整)。
启动训练脚本:
bash examples/grpo/grpo_trainer_qwen25_7b.sh
训练启动成功:
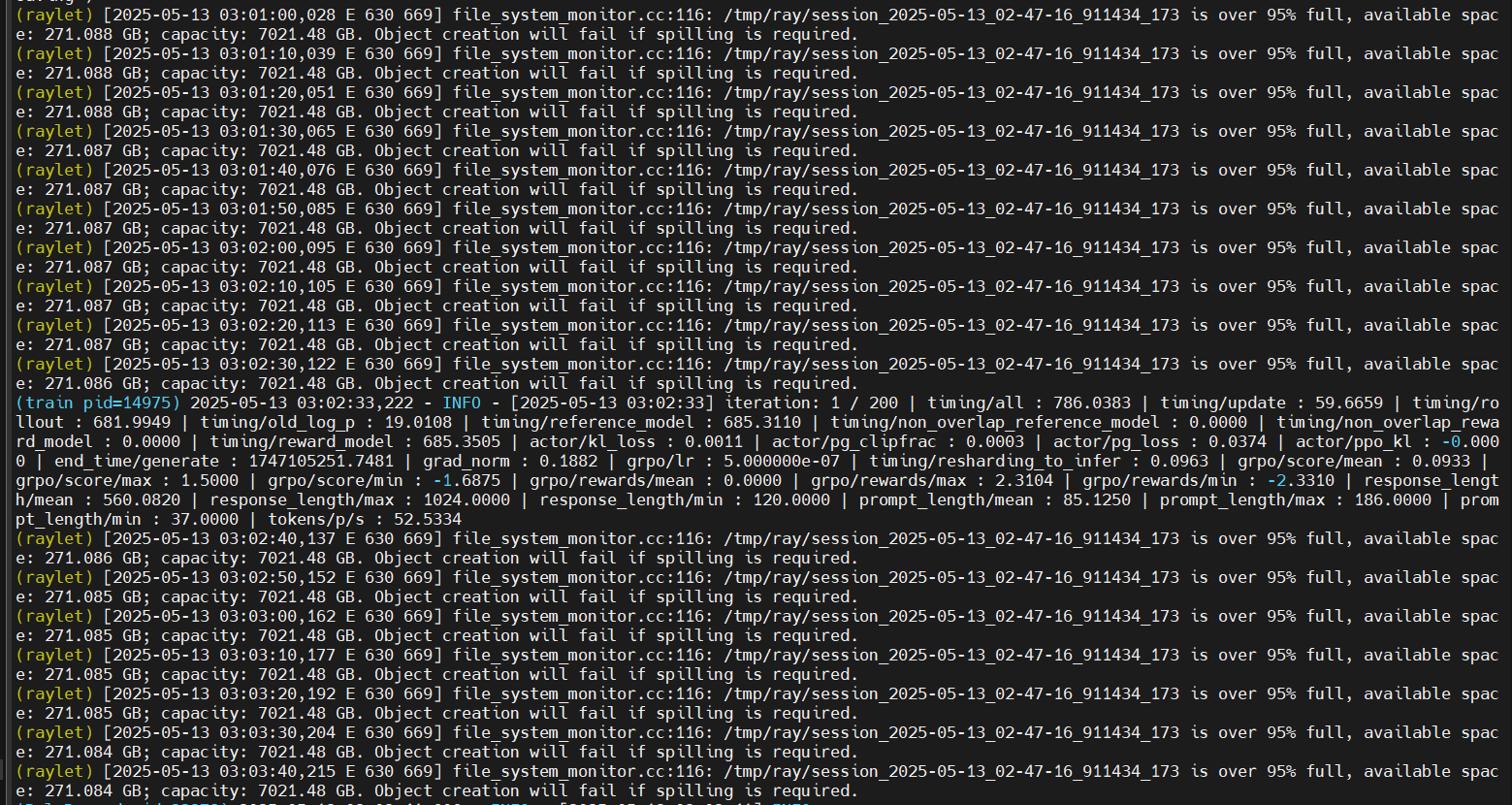
终端 / 日志输出[INFO] Training started with model: Qwen2.5-7B, dataset: orz_math_57k;
总结
这次在昇腾310P上搭环境,前前后后折腾了好几天。回过头看,主要就是几个地方容易出问题:
Docker这块最坑的是容器创建后直接退出,开始根本没想到要加个tail -f /dev/null让它一直跑着。还有就是镜像ID别搞错了,docker images查出来是啥就用啥,别直接复制拉取日志里的Digest。
版本匹配这个真的要严格按照来。PyTorch 2.5.1配torch-npu 2.5.1rc1,差一个小版本后面都是坑。setuptools也得降到65.7.0以下,不然Apex编译直接过不了。各个git仓库的commit也别随便换,文中提到的那些版本都是验证过能跑通的。
整体流程走下来,昇腾环境确实比CUDA复杂一些,但熟悉之后其实也还好。这套环境主要是为了在昇腾310P上跑强化学习训练,使用了MindSpeed-RL框架,配合Qwen2.5-7B模型和Orz Math数据集进行数学推理任务的训练。整个流程虽然步骤多,但只是第一次搭的时候要踩的坑比较多,后面再搭就快了,同时昇腾PAE案例库对本文写作亦有帮助,本文参考案例:

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)