
从零开始学昇腾Ascend C算子开发-第四章保姆级文章:第二十篇:Sub算子实现详解
本文介绍了Sub算子(Subtraction Operator)的实现方法,这是一种用于张量逐元素相减的元素级算子。文章基于0_helloworld项目展示了如何通过修改Add算子来实现Sub算子,主要区别在于将Add API替换为Sub API。实现过程包括核函数编写、内存管理(使用TPipe和TQue)以及完整的计算流程(CopyIn、Compute、CopyOut三个阶段)。Sub算子具有元
概述
Sub算子(Subtraction Operator)是元素级算子的一种,用于实现两个张量的逐元素相减。Sub算子与Add算子非常相似,主要区别在于使用的API不同:Add使用Add API,而Sub使用Sub API。本文将在Add算子的基础上,展示如何实现Sub算子,并同步更新0_helloworld项目的代码。
完整示例代码:
https://download.csdn.net/download/feng8403000/92484255
免费下载啊。
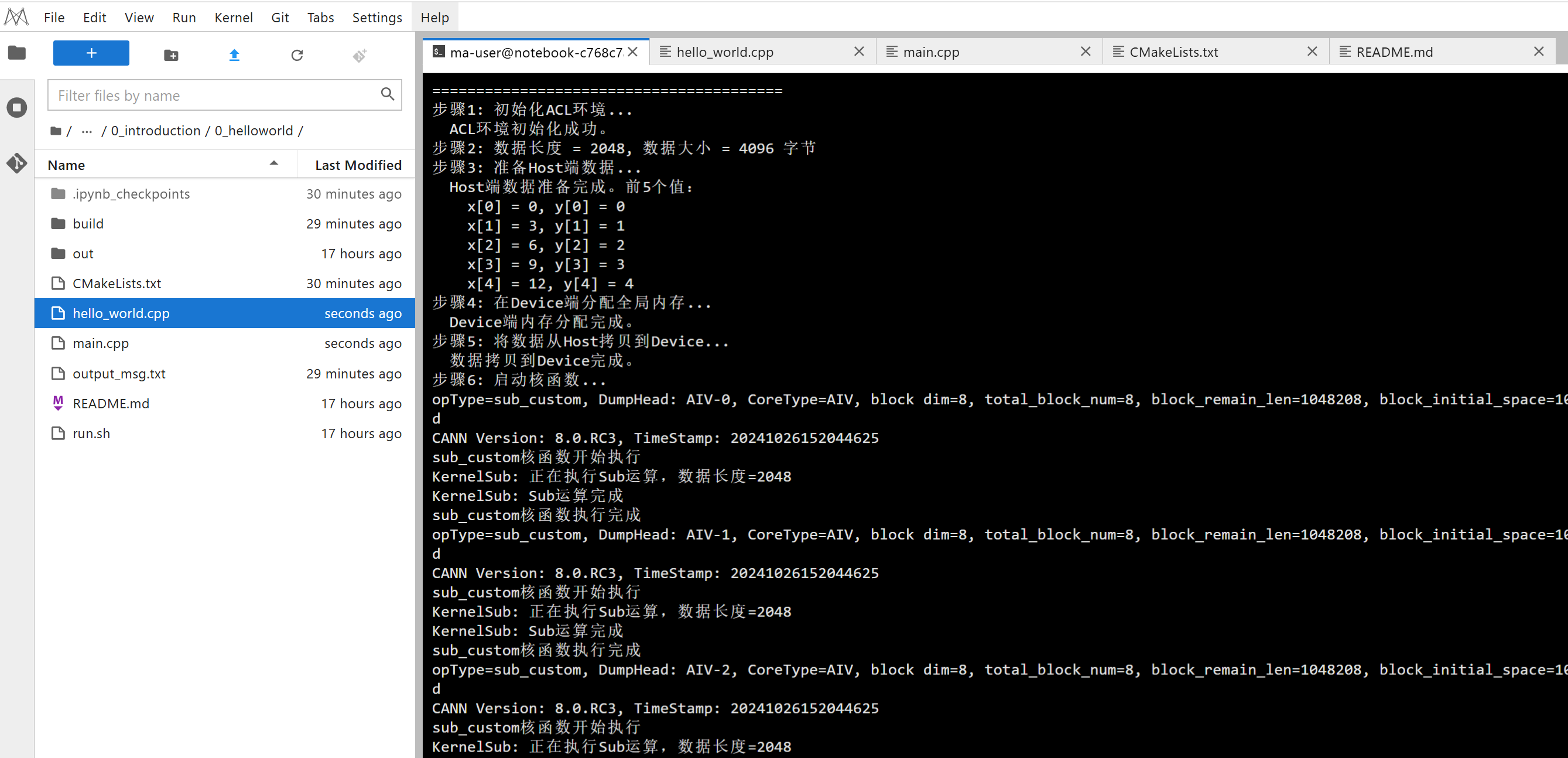
完整示例效果
什么是Sub算子
Sub算子(Subtraction Operator)是元素级算子(Element-wise Operator)的一种,它对两个输入张量的对应位置元素进行相减运算,生成输出张量。数学表达式为:
output[i] = input1[i] - input2[i]
其中,i表示元素在张量中的索引位置。
Sub算子的特点
- 元素独立性:每个输出元素只依赖于对应位置的输入元素,元素之间没有依赖关系
- 易于并行化:由于元素独立性,可以充分利用多核并行计算
- 易于向量化:可以使用向量指令同时处理多个元素
- 内存访问模式简单:顺序访问,缓存友好
Sub算子的应用场景
- 残差计算:计算两个特征图的差值
- 梯度计算:在反向传播中计算梯度差值
- 特征对比:比较两个特征图的差异
- 广播减法:支持不同形状张量的广播相减
基于0_helloworld实现Sub算子
我们将基于0_helloworld项目来实现Sub算子。由于Sub算子与Add算子非常相似,我们只需要将Add API替换为Sub API即可。
项目结构
在0_helloworld项目基础上,我们需要修改以下文件:
0_helloworld/
├── CMakeLists.txt # 编译配置文件(基本不变)
├── hello_world.cpp # 修改核函数实现(Add改为Sub)
├── main.cpp # 修改主程序(Add改为Sub,更新验证逻辑)
└── run.sh # 运行脚本(基本不变)
第一步:核函数实现(hello_world.cpp)
Sub算子的实现与Add算子几乎完全相同,只需要将Add API替换为Sub API:
/**
* @file hello_world.cpp
*
* Sub算子实现 - 基于0_helloworld项目修改
* 对应第二十篇:Sub算子实现详解
*/
#include "kernel_operator.h"
constexpr uint32_t TOTAL_LENGTH = 2048;
/**
* Sub算子Kernel类
* 使用TPipe和TQue来管理LocalTensor的内存分配
*/
class KernelSub {
public:
__aicore__ inline KernelSub() {}
/**
* 初始化函数
* @param x 第一个输入张量的全局内存地址(被减数)
* @param y 第二个输入张量的全局内存地址(减数)
* @param z 输出张量的全局内存地址(差)
*/
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
// 1. 创建GlobalTensor对象,绑定全局内存
xGm.SetGlobalBuffer((__gm__ half *)x, TOTAL_LENGTH);
yGm.SetGlobalBuffer((__gm__ half *)y, TOTAL_LENGTH);
zGm.SetGlobalBuffer((__gm__ half *)z, TOTAL_LENGTH);
// 2. 初始化TPipe和TQue,用于管理LocalTensor的内存
// InitBuffer会为队列分配内存空间
pipe.InitBuffer(inQueueX, 1, TOTAL_LENGTH * sizeof(half));
pipe.InitBuffer(inQueueY, 1, TOTAL_LENGTH * sizeof(half));
pipe.InitBuffer(outQueueZ, 1, TOTAL_LENGTH * sizeof(half));
}
/**
* 处理函数,执行完整的Sub算子流程
*/
__aicore__ inline void Process()
{
CopyIn(); // 从全局内存拷贝到本地内存
Compute(); // 执行Sub计算
CopyOut(); // 从本地内存拷贝回全局内存
}
private:
/**
* CopyIn阶段:从全局内存拷贝数据到本地内存
*/
__aicore__ inline void CopyIn()
{
// 从队列中分配LocalTensor(内存由TQue管理)
AscendC::LocalTensor<half> xLocal = inQueueX.AllocTensor<half>();
AscendC::LocalTensor<half> yLocal = inQueueY.AllocTensor<half>();
// 从GlobalTensor拷贝到LocalTensor
AscendC::DataCopy(xLocal, xGm, TOTAL_LENGTH);
AscendC::DataCopy(yLocal, yGm, TOTAL_LENGTH);
// 将LocalTensor放入队列(用于后续的Compute阶段)
inQueueX.EnQue(xLocal);
inQueueY.EnQue(yLocal);
}
/**
* Compute阶段:执行Sub计算
*/
__aicore__ inline void Compute()
{
// 从队列中取出LocalTensor
AscendC::LocalTensor<half> xLocal = inQueueX.DeQue<half>();
AscendC::LocalTensor<half> yLocal = inQueueY.DeQue<half>();
// 为输出分配LocalTensor
AscendC::LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>();
// 打印调试信息(在NPU端)
AscendC::printf("KernelSub: 正在执行Sub运算,数据长度=%u\n", TOTAL_LENGTH);
// 执行Sub计算:zLocal = xLocal - yLocal
AscendC::Sub(zLocal, xLocal, yLocal, TOTAL_LENGTH);
// 打印完成信息
AscendC::printf("KernelSub: Sub运算完成\n");
// 将结果放入输出队列
outQueueZ.EnQue<half>(zLocal);
// 释放输入LocalTensor(归还给队列管理)
inQueueX.FreeTensor(xLocal);
inQueueY.FreeTensor(yLocal);
}
/**
* CopyOut阶段:从本地内存拷贝结果回全局内存
*/
__aicore__ inline void CopyOut()
{
// 从输出队列中取出结果LocalTensor
AscendC::LocalTensor<half> zLocal = outQueueZ.DeQue<half>();
// 从LocalTensor拷贝回GlobalTensor
AscendC::DataCopy(zGm, zLocal, TOTAL_LENGTH);
// 释放LocalTensor(归还给队列管理)
outQueueZ.FreeTensor(zLocal);
}
private:
// TPipe用于管理内存和流水线
AscendC::TPipe pipe;
// TQue用于管理LocalTensor的分配和释放
// TPosition::VECIN表示输入队列,VECOUT表示输出队列
// 1表示队列的缓冲区数量
AscendC::TQue<AscendC::TPosition::VECIN, 1> inQueueX;
AscendC::TQue<AscendC::TPosition::VECIN, 1> inQueueY;
AscendC::TQue<AscendC::TPosition::VECOUT, 1> outQueueZ;
// GlobalTensor用于访问全局内存
AscendC::GlobalTensor<half> xGm;
AscendC::GlobalTensor<half> yGm;
AscendC::GlobalTensor<half> zGm;
};
/**
* Sub算子核函数
*
* @param x 第一个输入张量的全局内存地址(被减数)
* @param y 第二个输入张量的全局内存地址(减数)
* @param z 输出张量的全局内存地址(差)
*/
extern "C" __global__ __aicore__ void sub_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
AscendC::printf("sub_custom核函数开始执行\n");
KernelSub op;
op.Init(x, y, z);
op.Process();
AscendC::printf("sub_custom核函数执行完成\n");
}
代码详解
关键修改点:Add API → Sub API
与Add算子相比,Sub算子的唯一区别在于Compute阶段使用的API:
// Add算子
AscendC::Add(zLocal, xLocal, yLocal, TOTAL_LENGTH); // zLocal = xLocal + yLocal
// Sub算子
AscendC::Sub(zLocal, xLocal, yLocal, TOTAL_LENGTH); // zLocal = xLocal - yLocal
Sub API详解
void Sub(LocalTensor<DTYPE> &dst,
const LocalTensor<DTYPE> &src1,
const LocalTensor<DTYPE> &src2,
uint32_t count);
功能:执行向量减法运算
参数:
dst:输出张量,存储计算结果src1:第一个输入张量(被减数)src2:第二个输入张量(减数)count:参与计算的元素个数
执行:dst[i] = src1[i] - src2[i],i = 0, 1, ..., count-1
支持的数据类型:half, float, int8_t, int16_t, int32_t等
性能特点:
- 使用向量指令,可以同时处理多个元素
- 对于half类型,通常可以同时处理256个元素
- 计算和内存访问可以流水线化
第二步:主程序实现(main.cpp)
修改main.cpp,将Add改为Sub,并更新数据验证逻辑:
/**
* @file main.cpp
*
* Sub算子主程序 - 基于0_helloworld项目修改
* 对应第二十篇:Sub算子实现详解
*/
#include "acl/acl.h"
#include <stdio.h>
#include <stdlib.h>
#include <cstdint>
// 使用编译系统生成的头文件来调用核函数
// 这个头文件会在编译kernels库时自动生成
// 注意:需要先编译kernels库,然后才能编译main
#include "aclrtlaunch_sub_custom.h"
// half类型在CPU端使用uint16_t表示(16位浮点数)
using half_t = uint16_t;
int32_t main(int argc, char const *argv[])
{
printf("========================================\n");
printf("Sub算子测试 - 开始运行...\n");
printf("========================================\n");
// 1. 初始化ACL环境
printf("步骤1: 初始化ACL环境...\n");
aclInit(nullptr);
int32_t deviceId = 0;
aclrtSetDevice(deviceId);
aclrtStream stream = nullptr;
aclrtCreateStream(&stream);
printf(" ACL环境初始化成功。\n");
// 2. 数据长度
constexpr uint32_t TOTAL_LENGTH = 2048;
constexpr size_t dataSize = TOTAL_LENGTH * sizeof(half_t);
printf("步骤2: 数据长度 = %u, 数据大小 = %zu 字节\n", TOTAL_LENGTH, dataSize);
// 3. 准备Host端数据(简化:直接使用简单的值)
printf("步骤3: 准备Host端数据...\n");
half_t *host_x = (half_t *)malloc(dataSize);
half_t *host_y = (half_t *)malloc(dataSize);
half_t *host_z = (half_t *)malloc(dataSize);
// 初始化简单的测试数据(使用简单的整数值,便于验证)
// Sub: x[i] - y[i] = z[i]
// 使用简单的值:x[i] = i*3, y[i] = i, 期望结果 z[i] = i*2
for (uint32_t i = 0; i < TOTAL_LENGTH; i++) {
host_x[i] = (half_t)((i * 3) & 0xFFFF); // 被减数
host_y[i] = (half_t)(i & 0xFFFF); // 减数
}
printf(" Host端数据准备完成。前5个值:\n");
for (uint32_t i = 0; i < 5; i++) {
printf(" x[%u] = %u, y[%u] = %u\n", i, host_x[i], i, host_y[i]);
}
// 4. 在Device端分配全局内存
printf("步骤4: 在Device端分配全局内存...\n");
void *device_x = nullptr;
void *device_y = nullptr;
void *device_z = nullptr;
aclrtMalloc(&device_x, dataSize, ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMalloc(&device_y, dataSize, ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMalloc(&device_z, dataSize, ACL_MEM_MALLOC_HUGE_FIRST);
printf(" Device端内存分配完成。\n");
// 5. 将数据从Host拷贝到Device
printf("步骤5: 将数据从Host拷贝到Device...\n");
aclrtMemcpy(device_x, dataSize, host_x, dataSize, ACL_MEMCPY_HOST_TO_DEVICE);
aclrtMemcpy(device_y, dataSize, host_y, dataSize, ACL_MEMCPY_HOST_TO_DEVICE);
printf(" 数据拷贝到Device完成。\n");
// 6. 调用核函数
printf("步骤6: 启动核函数...\n");
constexpr uint32_t blockDim = 8;
// 使用编译系统生成的宏来调用核函数
ACLRT_LAUNCH_KERNEL(sub_custom)(blockDim, stream, device_x, device_y, device_z);
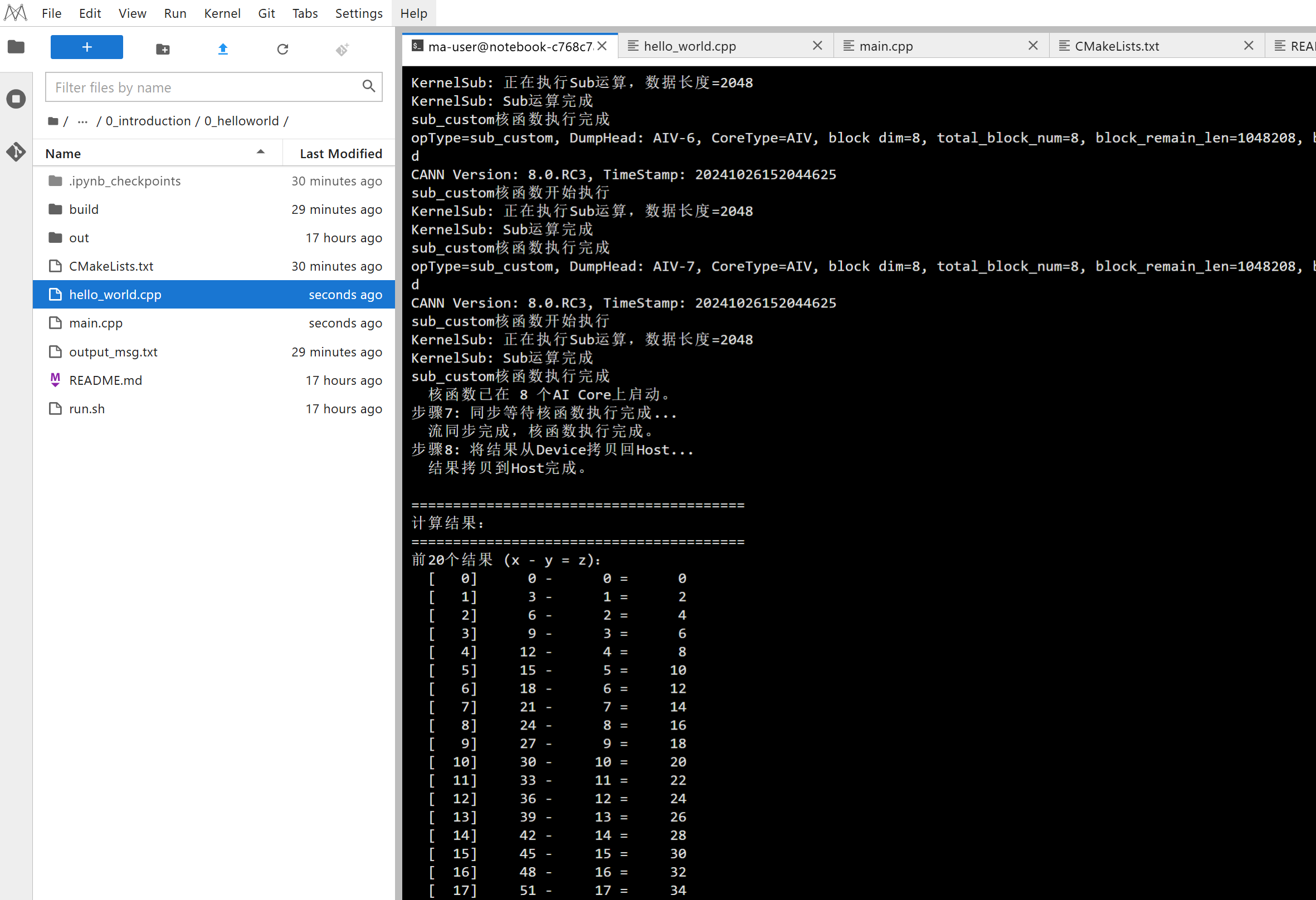
printf(" 核函数已在 %u 个AI Core上启动。\n", blockDim);
// 7. 同步等待核函数执行完成
printf("步骤7: 同步等待核函数执行完成...\n");
aclrtSynchronizeStream(stream);
printf(" 流同步完成,核函数执行完成。\n");
// 8. 将结果从Device拷贝回Host
printf("步骤8: 将结果从Device拷贝回Host...\n");
aclrtMemcpy(host_z, dataSize, device_z, dataSize, ACL_MEMCPY_DEVICE_TO_HOST);
printf(" 结果拷贝到Host完成。\n");
// 9. 打印结果
printf("\n========================================\n");
printf("计算结果:\n");
printf("========================================\n");
printf("前20个结果 (x - y = z):\n");
for (uint32_t i = 0; i < 20 && i < TOTAL_LENGTH; i++) {
printf(" [%4u] %6u - %6u = %6u\n",
i, host_x[i], host_y[i], host_z[i]);
}
// 简单验证:检查前几个结果
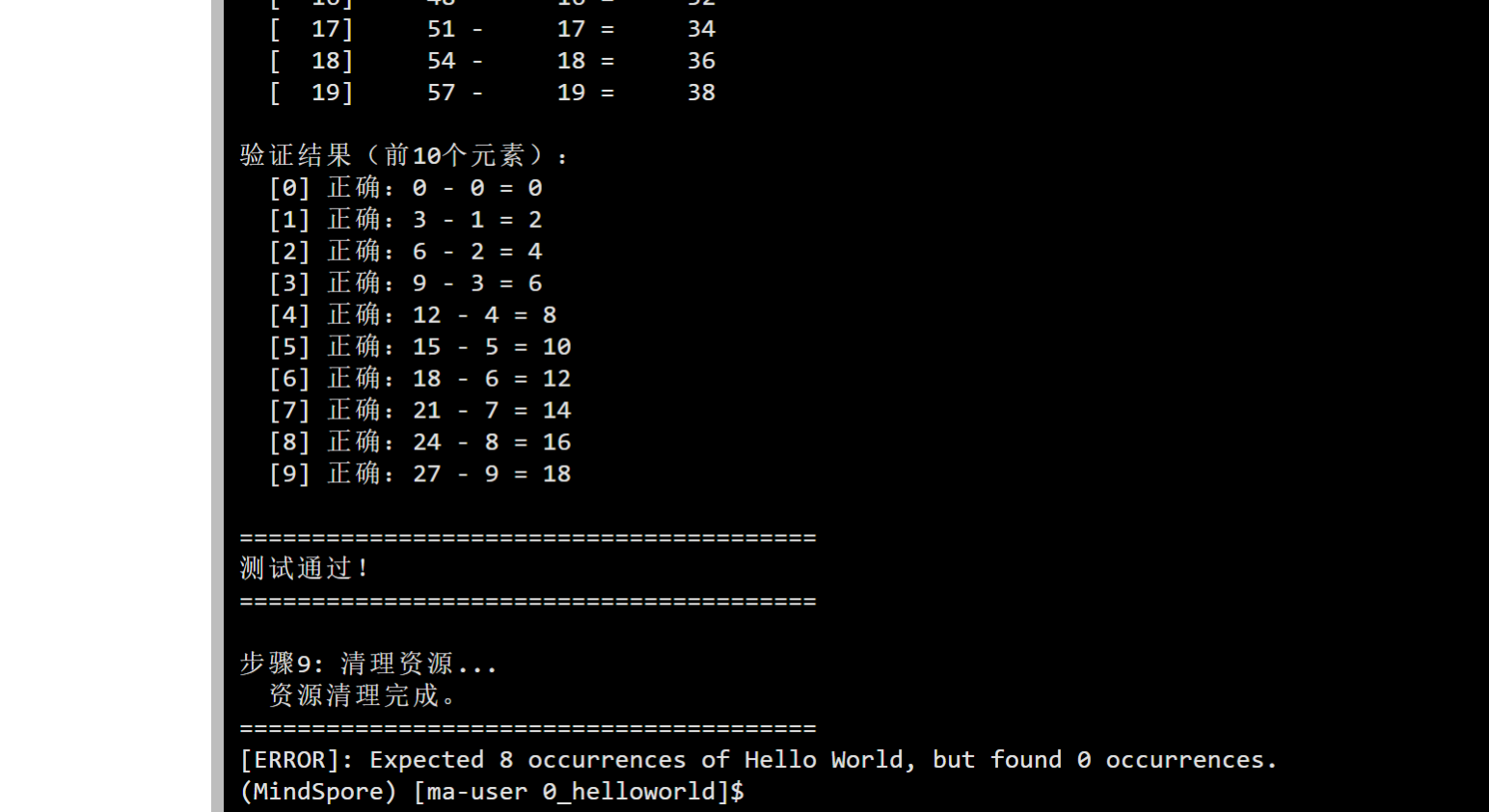
printf("\n验证结果(前10个元素):\n");
bool all_ok = true;
for (uint32_t i = 0; i < 10 && i < TOTAL_LENGTH; i++) {
uint32_t expected = host_x[i] - host_y[i]; // Sub: x - y
uint32_t got = host_z[i];
if (expected != got) {
printf(" [%u] 错误:期望值 %u,实际值 %u\n", i, expected, got);
all_ok = false;
} else {
printf(" [%u] 正确:%u - %u = %u\n", i, host_x[i], host_y[i], got);
}
}
printf("\n========================================\n");
if (all_ok) {
printf("测试通过!\n");
} else {
printf("测试失败!\n");
}
printf("========================================\n");
// 10. 清理资源
printf("\n步骤9: 清理资源...\n");
free(host_x);
free(host_y);
free(host_z);
aclrtFree(device_x);
aclrtFree(device_y);
aclrtFree(device_z);
aclrtDestroyStream(stream);
aclrtResetDevice(deviceId);
aclFinalize();
printf(" 资源清理完成。\n");
printf("========================================\n");
return all_ok ? 0 : 1;
}
主程序关键修改点
- 头文件:从
aclrtlaunch_add_custom.h改为aclrtlaunch_sub_custom.h - 核函数调用:从
ACLRT_LAUNCH_KERNEL(add_custom)改为ACLRT_LAUNCH_KERNEL(sub_custom) - 数据初始化:更新为Sub算子的测试数据模式
- 验证逻辑:从
x + y改为x - y
第三步:修改CMakeLists.txt
CMakeLists.txt不需要修改,因为文件名仍然是hello_world.cpp,只是内容改为了Sub算子实现。
Sub算子与Add算子的对比
相同点
- 代码结构完全相同:都使用
KernelAdd/KernelSub类,都使用TPipe和TQue管理内存 - 内存管理方式相同:都使用相同的LocalTensor分配和释放方式
- 数据流相同:CopyIn → Compute → CopyOut三个阶段
- 调用方式相同:都使用
ACLRT_LAUNCH_KERNEL宏
不同点
-
API不同:
- Add使用
AscendC::Add() - Sub使用
AscendC::Sub()
- Add使用
-
数学运算不同:
- Add:
z[i] = x[i] + y[i] - Sub:
z[i] = x[i] - y[i]
- Add:
-
测试数据不同:
- Add:
x[i] = i, y[i] = i*2, z[i] = i*3 - Sub:
x[i] = i*3, y[i] = i, z[i] = i*2
- Add:
Sub API详解
Sub API函数签名
void Sub(LocalTensor<DTYPE> &dst,
const LocalTensor<DTYPE> &src1,
const LocalTensor<DTYPE> &src2,
uint32_t count);
参数说明
- dst:输出张量,存储计算结果
dst[i] = src1[i] - src2[i] - src1:第一个输入张量(被减数)
- src2:第二个输入张量(减数)
- count:参与计算的元素个数
支持的数据类型
- 浮点类型:
half,float - 整数类型:
int8_t,int16_t,int32_t
性能特点
- 使用向量指令,可以同时处理多个元素
- 对于half类型,通常可以同时处理256个元素
- 计算和内存访问可以流水线化
- 与Add API性能相当
基于0_helloworld项目的修改步骤
步骤1:修改hello_world.cpp
将Add算子改为Sub算子:
- 将
KernelAdd类名改为KernelSub - 将
AddAPI改为SubAPI - 将
add_custom函数名改为sub_custom - 更新printf中的提示信息(Add改为Sub)
步骤2:修改main.cpp
- 将头文件从
aclrtlaunch_add_custom.h改为aclrtlaunch_sub_custom.h - 将
ACLRT_LAUNCH_KERNEL(add_custom)改为ACLRT_LAUNCH_KERNEL(sub_custom) - 更新数据初始化逻辑(改为Sub的测试数据)
- 更新验证逻辑(从
x + y改为x - y) - 更新所有printf中的提示信息(Add改为Sub)
步骤3:编译和运行
cd samples/operator/ascendc/0_introduction/0_helloworld
bash run.sh -v Ascend910B4
预期输出
如果运行成功,应该看到类似以下的中文输出:
========================================
Sub算子测试 - 开始运行...
========================================
步骤1: 初始化ACL环境...
ACL环境初始化成功。
步骤2: 数据长度 = 2048, 数据大小 = 4096 字节
步骤3: 准备Host端数据...
Host端数据准备完成。前5个值:
x[0] = 0, y[0] = 0
x[1] = 3, y[1] = 1
x[2] = 6, y[2] = 2
...
步骤4: 在Device端分配全局内存...
Device端内存分配完成。
...
========================================
计算结果:
========================================
前20个结果 (x - y = z):
[ 0] 0 - 0 = 0
[ 1] 3 - 1 = 2
[ 2] 6 - 2 = 4
...
验证结果(前10个元素):
[0] 正确:0 - 0 = 0
[1] 正确:3 - 1 = 2
[2] 正确:6 - 2 = 4
...
========================================
测试通过!
========================================
同时,在NPU端也会打印调试信息:
sub_custom核函数开始执行
KernelSub: 正在执行Sub运算,数据长度=2048
KernelSub: Sub运算完成
sub_custom核函数执行完成
关键注意事项
1. API的选择
Sub算子使用Sub API,函数签名与Add API完全相同,只是运算不同:
// Add: z = x + y
AscendC::Add(zLocal, xLocal, yLocal, TOTAL_LENGTH);
// Sub: z = x - y
AscendC::Sub(zLocal, xLocal, yLocal, TOTAL_LENGTH);
2. 运算顺序
注意Sub算子的运算顺序:dst = src1 - src2,即第一个参数减去第二个参数。
3. 与Add算子的关系
Sub算子和Add算子的实现几乎完全相同,主要区别在于:
- 使用的API不同(
SubvsAdd) - 数学运算不同(减法 vs 加法)
- 应用场景不同
总结
本文详细介绍了Sub算子的实现,包括:
- Sub算子的定义:逐元素相减运算
- 实现方式:使用TPipe和TQue管理LocalTensor
- API详解:Sub API的使用方法和参数说明
- 与Add算子的对比:相同点和不同点
- 代码修改步骤:如何从Add算子改为Sub算子
Sub算子与Add算子非常相似,掌握了Add算子的实现后,实现Sub算子就非常简单了,只需要替换API即可。这体现了Ascend C算子开发的模块化和可复用性。
在下一篇文章中,我们将介绍Mul(乘法)和Div(除法)算子的实现,它们与Add和Sub算子的实现方式也非常相似。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252
社区地址:https://www.hiascend.com/developer

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 6
6 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)